- Создание куба в SQL Server 2005

Содержание
- 2. Цель: методом SQL Server Business Intelligence Development Studio создать реляционное хранилище для предметной области «Индекс РТС».
- 3. Задачи: 1. построить хранилище для индекса РТС с простыми измерениями; 1.1. создать решение для индекса РТС;
- 4. Работа с ХД в новой версии сервера разделена на несколько шагов: создания решения (solution); подключение к
- 5. Для выполнения этих действий есть два различных инструментария: 1) разработка производится с использованием SQL Server Business
- 6. 1.Создание решения
- 7. 1.1. Вызов SQL серверной среды интеллектуальных систем предприятия
- 8. 1.2. Команда создания нового проекта
- 9. 1.3. Выбор шаблона «Проект аналитических систем»
- 10. 2. Подключение к источнику данных (Data Source)
- 11. 2.1. Команды выбора нового источника данных
- 12. 2.2. Список существующих источников данных
- 13. 2.3. Выбор провайдера для реляционной базы данных типа Access
- 14. 2.4. Поиск имени источника данных (Базы данных - Access)
- 15. Стандартное окно поиска файла
- 16. 2.6. Окончание подключения к источнику данных. Создание имени источника
- 17. 2.7. Внешний вид папки Solution (Решение)
- 18. 3. Создание Data Source View Под Data Source View понимается срез источника, который будет использоваться для
- 19. 3.1. Команда на построения среза источника данных
- 20. 3.2. Выбор подключаемого источника данных
- 21. 3.3. Выбор таблиц для включения в срез
- 22. 3.4. Ввод имени подготовленного среза
- 23. 3.5. Вид представления среза в дизайнере
- 24. 4. Подключение дополнительных размерностей
- 25. 4.1. Дополнительные виды размерностей С точки зрения своих возможностей размерности в рассматриваемой версии OLAP-сервера (SQL Server
- 26. 4.2. Подключение размерности типа Дата Открытие среза
- 27. Вид окна «Добавление таблицы»
- 28. Вид дизайнера с добавленной таблицей Date
- 29. Вызов команды на построение нового измерения
- 30. Выбор метода построения измерения
- 31. Выбор представления
- 32. Выбор типа измерения
- 33. Установка соответствия периодов
- 34. Иерархии подключаемого измерения
- 35. 4.3. Расчет измерения Date
- 36. Процесс расчета измерения
- 37. 4.3. Просмотр измерения Date Команда на просмотр измерения
- 38. Просмотр размерности Дата
- 39. 4.4. Добавление размерности из таблицы фактов Добавление новой размерности
- 40. Выбор типа измерения
- 41. Выбор таблицы и её атрибутов для измерения
- 42. Атрибуты, включаемые в измерение
- 43. Состав измерения и его имя
- 44. Появилось добавленное измерение
- 45. 4.5. Расчет размерности из таблицы фактов
- 46. Расчет закончен
- 47. 4.6. Просмотр размерности из таблицы фактов
- 48. Просмотр добавленной размерности, созданной из таблицы фактов
- 49. 5. Создание куба
- 50. 5.1. Особенности показателей в кубах данных MS SQL Server 2005 Система агрегирования представляет собой внутренний механизм,
- 51. Показатели могут быть: ■ аддитивными (additive); ■ полуаддитивными (semiadditive); ■ неаддитивными (nonadditive).
- 52. Аддитивные показатели Аддитивные показатели, также называемые полноаддитивными, агрегируются со всеми размерностями, включенными в группы показателей. Говоря
- 53. Полуаддитивные показатели Полуаддитивные показатели агрегируются относительно некоторых (не всех) размерностей. Например, показатель, определяющий количество товара на
- 54. Неаддитивные показатели Неаддитивные показатели не агрегируются по размерностям, но могут быть посчитаны для любой ячейки куба.
- 55. 5.2. Особенности сохранения кубов ■ пространство на диске не выделяется под пустые ячейки; ■ выполняется сжатие
- 56. 5.3. Подключение простых размерностей К простым размерностям относятся: ■ размерности, состоящие из одной таблицы (сбалансированные и
- 57. Команда на создание нового куба
- 58. Выбор источника данных в виде реляционного хранилища
- 59. Распределение таблиц среза по измерениям и фактам куба
- 60. Окно определения фактов
- 61. Сохранение куба
- 62. 5.5. Расчет (процессинг) куба В панели Solution Explorer (Проводник решений) в проекте Analysis Services RTS-Data-2 на
- 63. Куб создан по именем RTS-Data-2.cube
- 64. 6. Подключение размерности типа «Время и Дата»
- 65. 6.1. Измерение «Дата» можно подключить двумя способами: 1) при построении куба указать, что это временное измерение
- 66. 6.2. Вид вкладки Dimension Usage (Использование размерности)
- 67. 6.3. Добавление нового измерения
- 68. 6.4. Подключаемое измерение (Дата)
- 69. 6.5. В измерениях появилась Date (Дата)
- 70. 6.6. Выбор типа связи
- 71. 7. Подключение к кубу размерности, созданной из таблицы фактов
- 72. 7.1. Команда на добавление новой размерности
- 73. 7.2. Выбор типа нового измерения
- 74. 7.3. Выбор необходимых атрибутов
- 75. 7.4. В списке измерений появилось вновь созданное (Fact_Dim)
- 76. 7.5. Панель Analysis Services RTS-Data-2.cube [Design] (Построитель (дизайнер) куба)
- 77. 7.6. Выбор связи нового измерения и факта
- 78. 7.7. После выбора связи пересечение между Fact_Dim и Fact должно стать определенным
- 80. Скачать презентацию

Цель:
методом SQL Server Business Intelligence Development Studio создать реляционное
Цель:
методом SQL Server Business Intelligence Development Studio создать реляционное

Задачи:
1. построить хранилище для индекса РТС с простыми измерениями;
1.1. создать
Задачи:
1. построить хранилище для индекса РТС с простыми измерениями;
1.1. создать

Работа с ХД в новой версии сервера разделена на несколько шагов:
создания
Работа с ХД в новой версии сервера разделена на несколько шагов:
создания

Для выполнения этих действий есть два различных инструментария:
1) разработка производится с
Для выполнения этих действий есть два различных инструментария:
1) разработка производится с

1.Создание
решения
1.Создание
решения
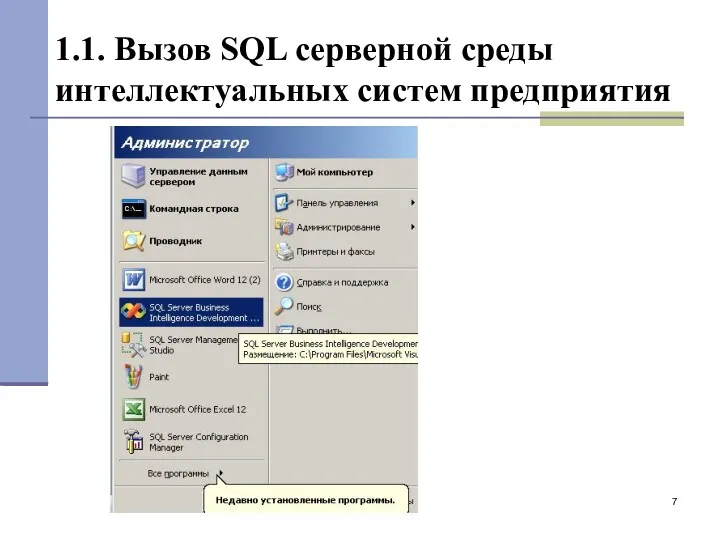
1.1. Вызов SQL серверной среды интеллектуальных систем предприятия
1.1. Вызов SQL серверной среды интеллектуальных систем предприятия
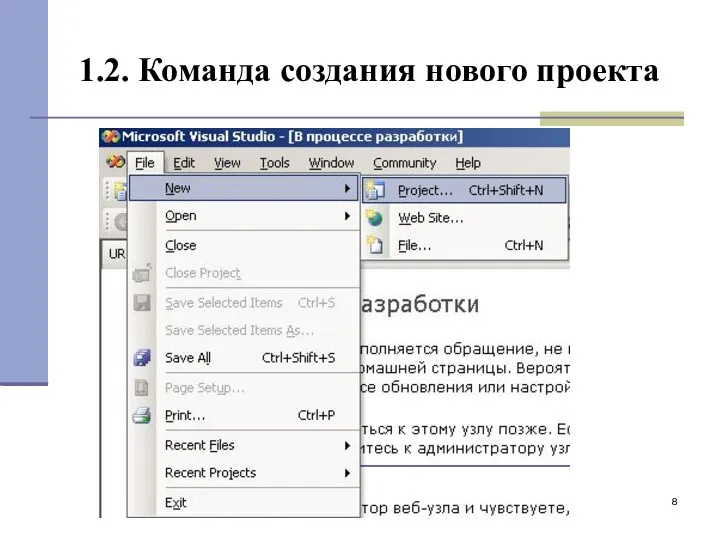
1.2. Команда создания нового проекта
1.2. Команда создания нового проекта
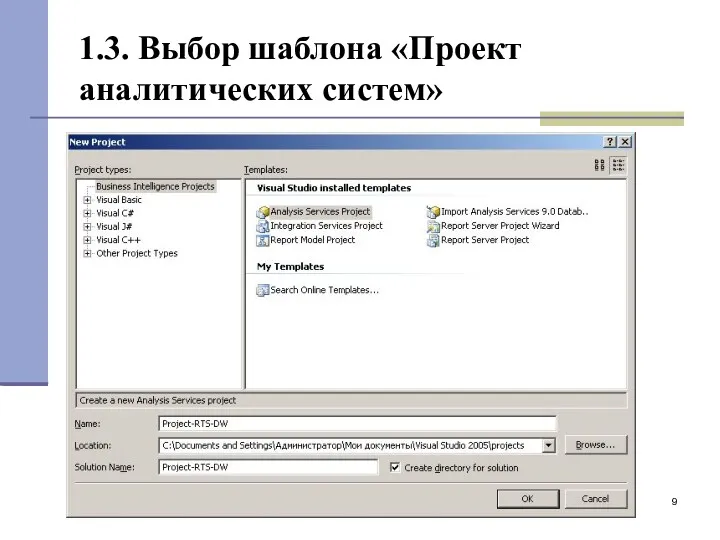
1.3. Выбор шаблона «Проект аналитических систем»
1.3. Выбор шаблона «Проект аналитических систем»

2. Подключение к источнику данных (Data Source)
2. Подключение к источнику данных (Data Source)
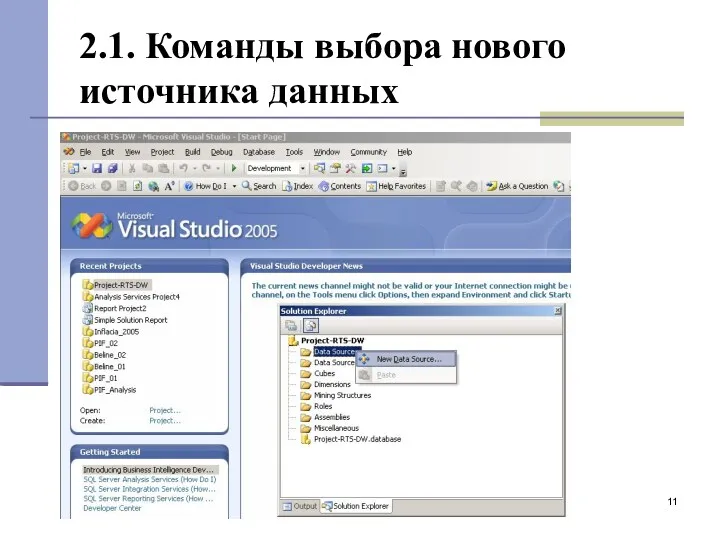
2.1. Команды выбора нового источника данных
2.1. Команды выбора нового источника данных
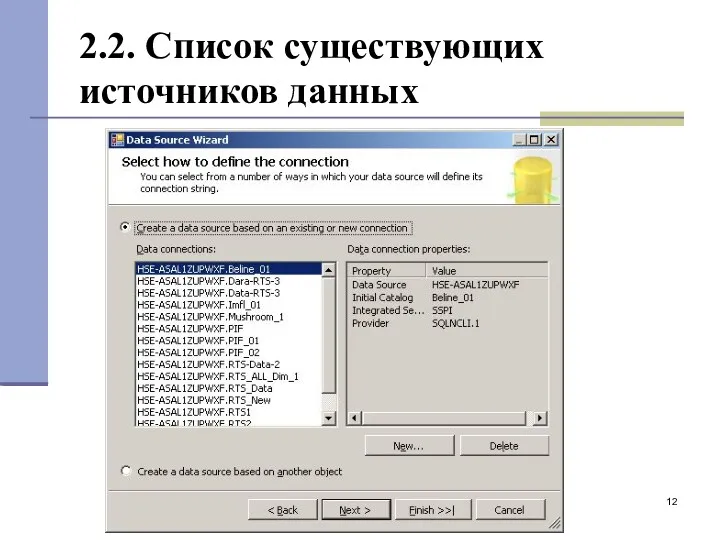
2.2. Список существующих источников данных
2.2. Список существующих источников данных
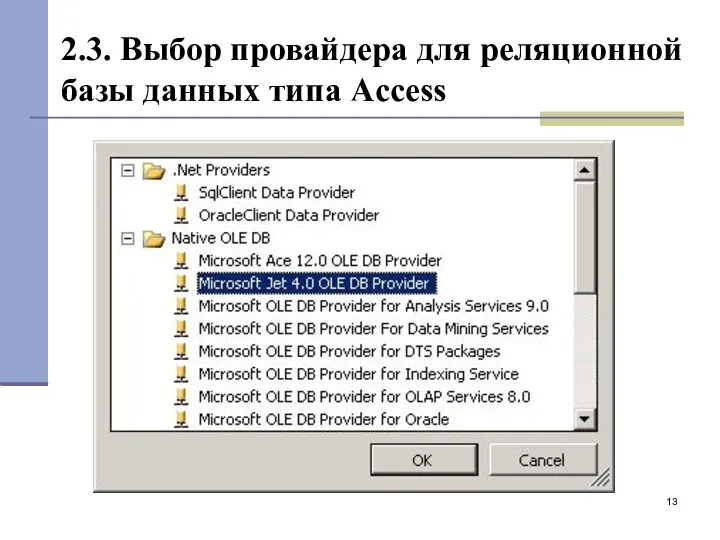
2.3. Выбор провайдера для реляционной базы данных типа Access
2.3. Выбор провайдера для реляционной базы данных типа Access
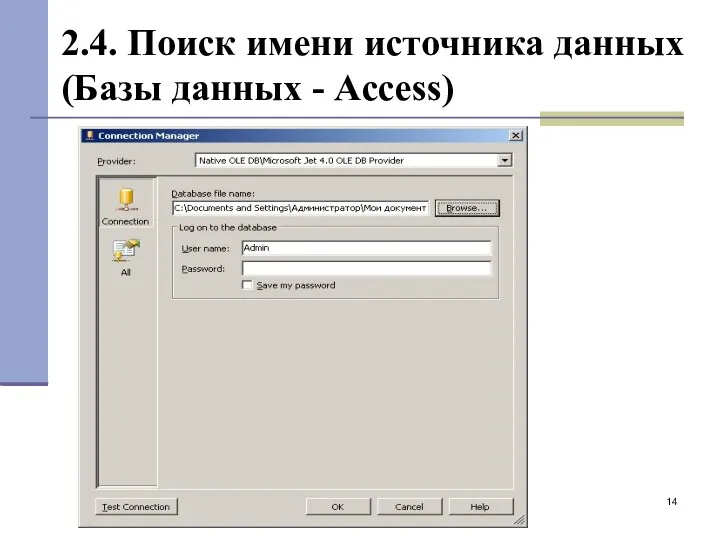
2.4. Поиск имени источника данных (Базы данных - Access)
2.4. Поиск имени источника данных (Базы данных - Access)
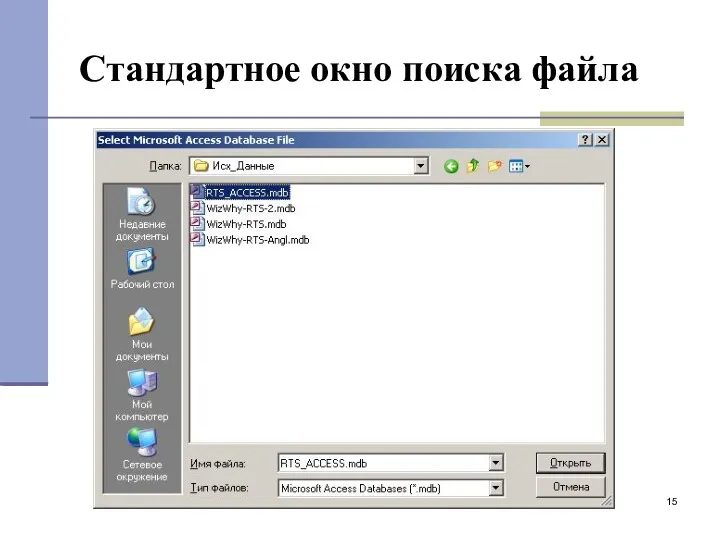
Стандартное окно поиска файла
Стандартное окно поиска файла
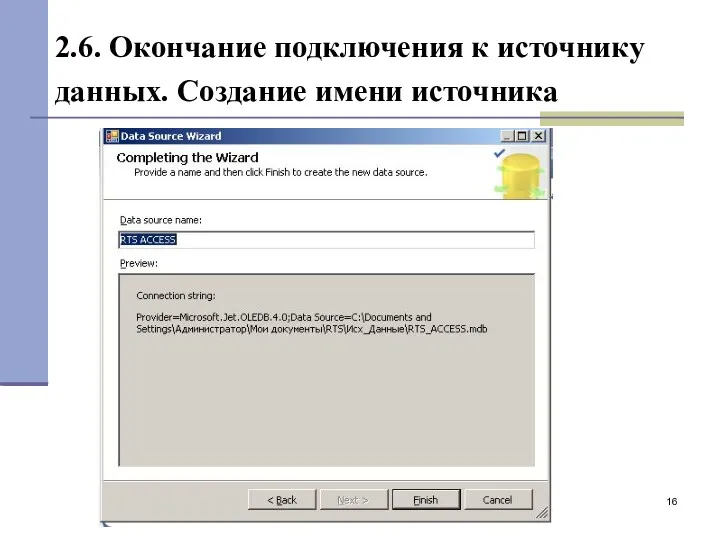
2.6. Окончание подключения к источнику данных. Создание имени источника
2.6. Окончание подключения к источнику данных. Создание имени источника
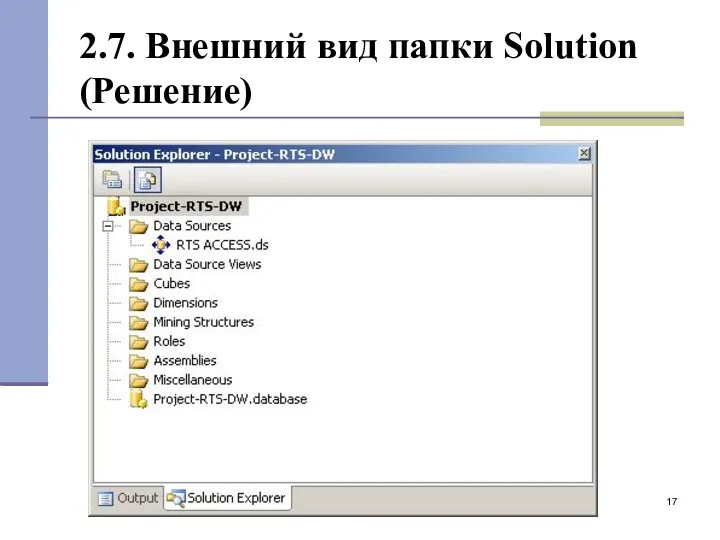
2.7. Внешний вид папки Solution (Решение)
2.7. Внешний вид папки Solution (Решение)

3. Создание Data Source View
Под Data Source View понимается срез
3. Создание Data Source View
Под Data Source View понимается срез
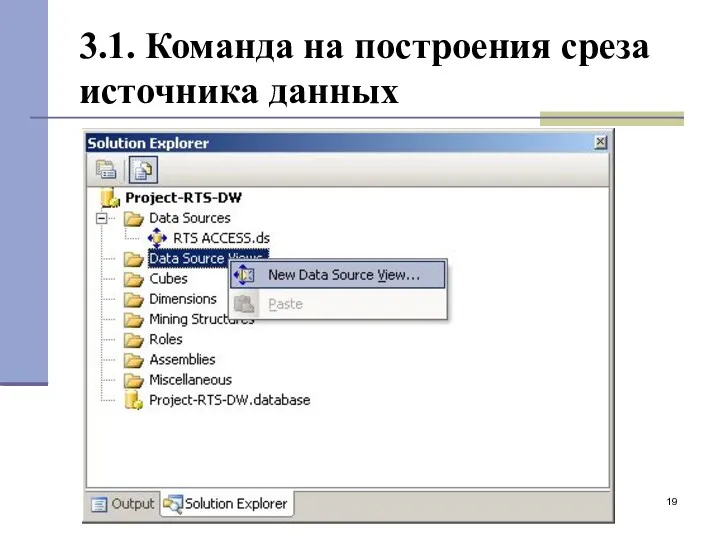
3.1. Команда на построения среза источника данных
3.1. Команда на построения среза источника данных
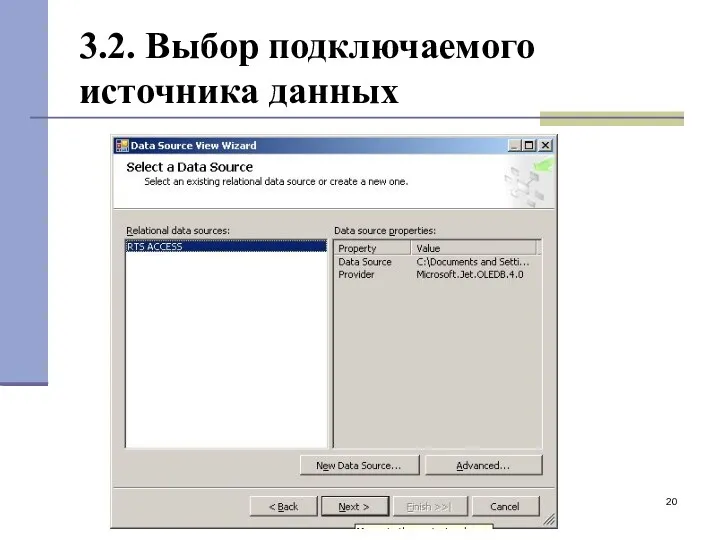
3.2. Выбор подключаемого источника данных
3.2. Выбор подключаемого источника данных
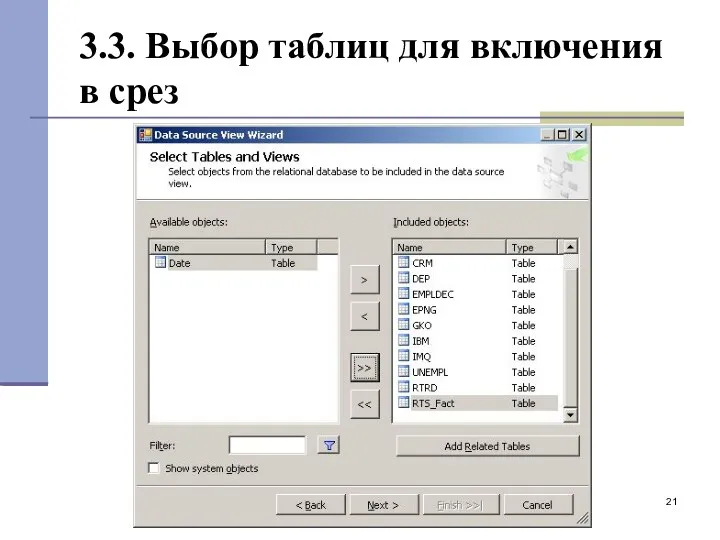
3.3. Выбор таблиц для включения в срез
3.3. Выбор таблиц для включения в срез
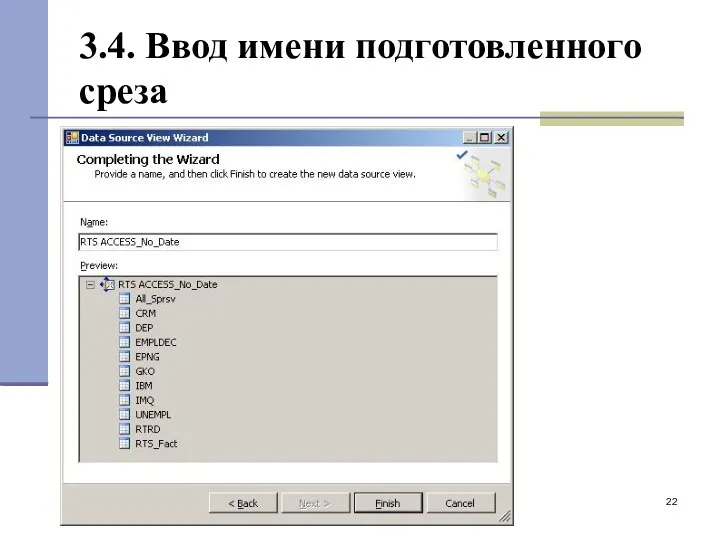
3.4. Ввод имени подготовленного среза
3.4. Ввод имени подготовленного среза
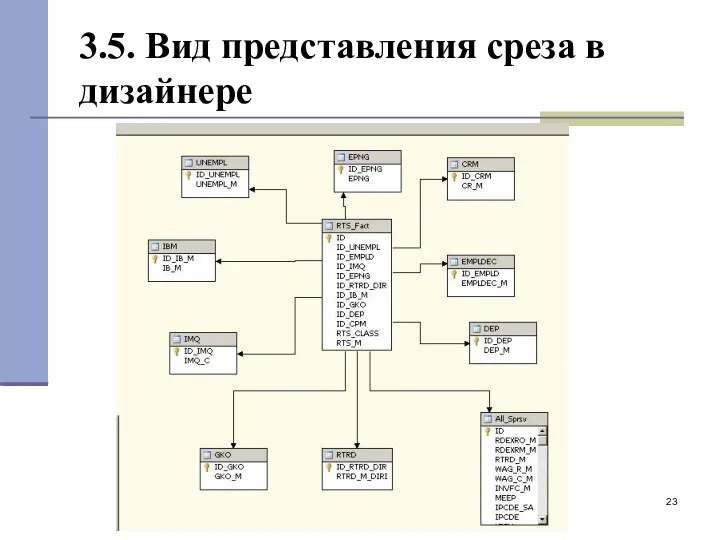
3.5. Вид представления среза в дизайнере
3.5. Вид представления среза в дизайнере

4. Подключение дополнительных размерностей
4. Подключение дополнительных размерностей

4.1. Дополнительные виды размерностей
С точки зрения своих возможностей размерности в
4.1. Дополнительные виды размерностей
С точки зрения своих возможностей размерности в
4.2. Подключение размерности типа Дата
Открытие среза
4.2. Подключение размерности типа Дата
Открытие среза
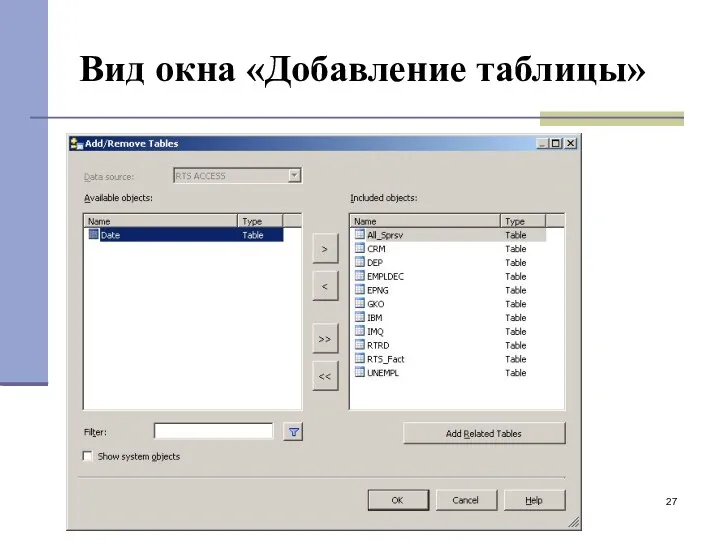
Вид окна «Добавление таблицы»
Вид окна «Добавление таблицы»

Вид дизайнера с добавленной таблицей Date
Вид дизайнера с добавленной таблицей Date
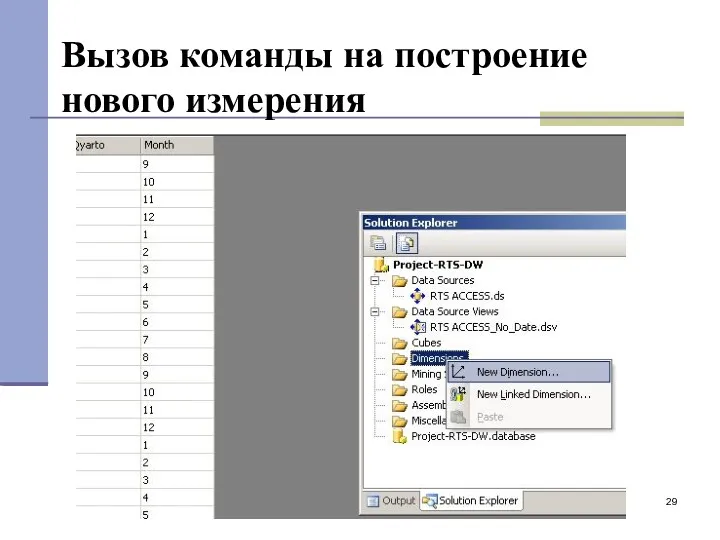
Вызов команды на построение нового измерения
Вызов команды на построение нового измерения
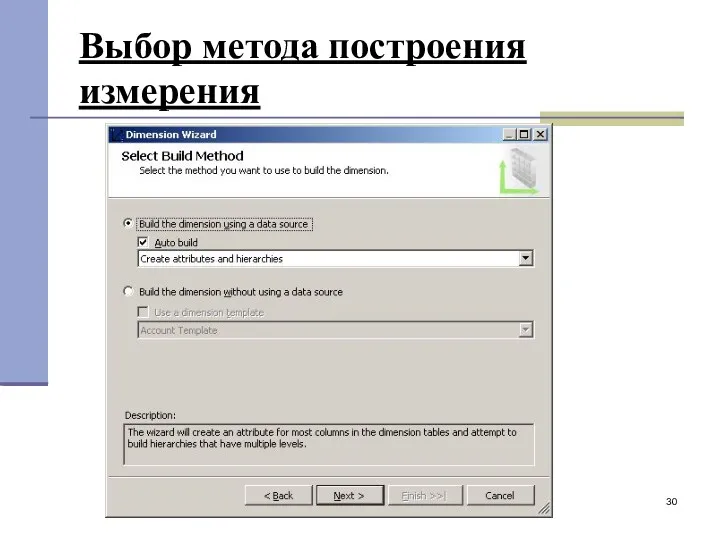
Выбор метода построения измерения
Выбор метода построения измерения
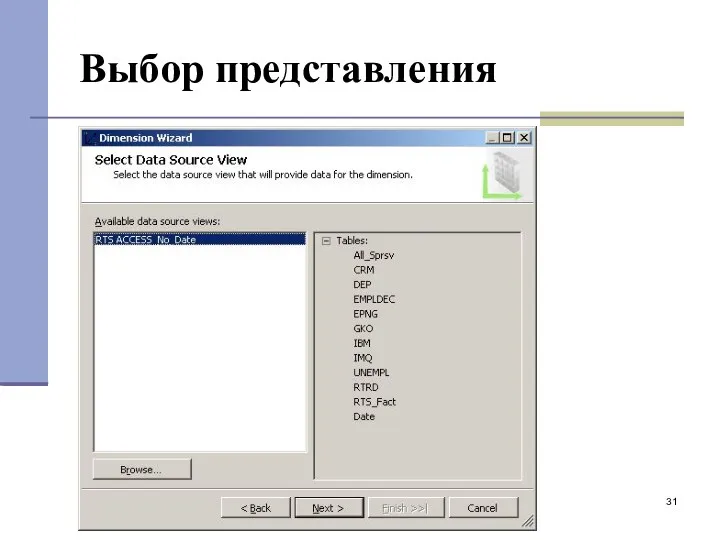
Выбор представления
Выбор представления
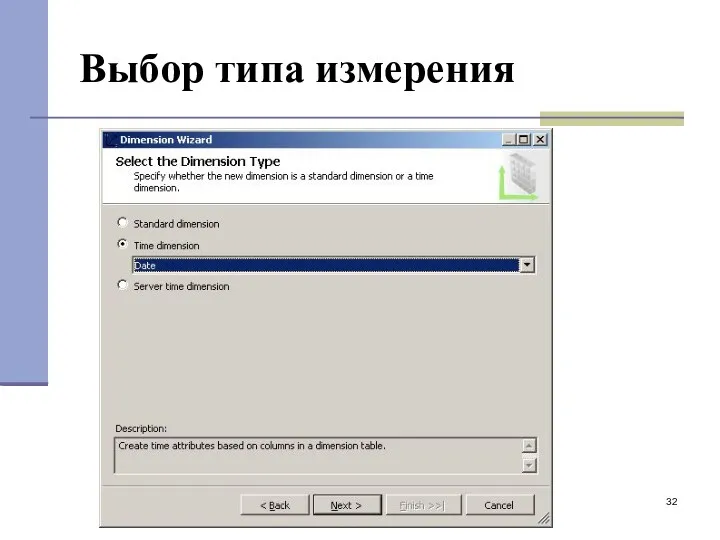
Выбор типа измерения
Выбор типа измерения
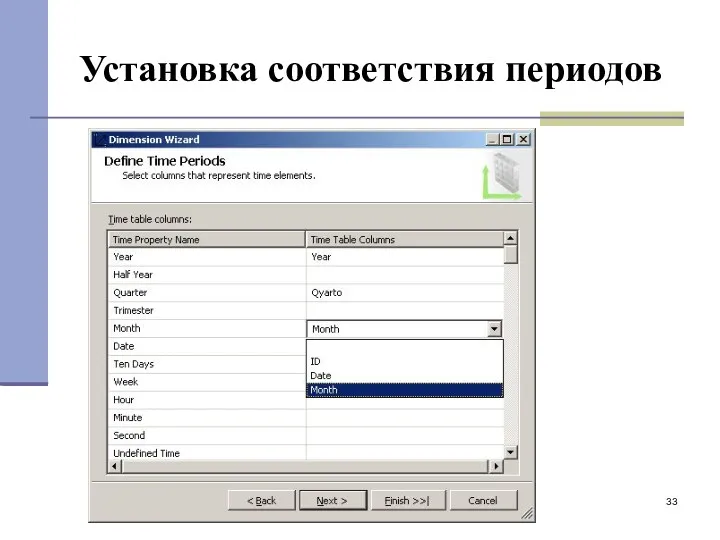
Установка соответствия периодов
Установка соответствия периодов
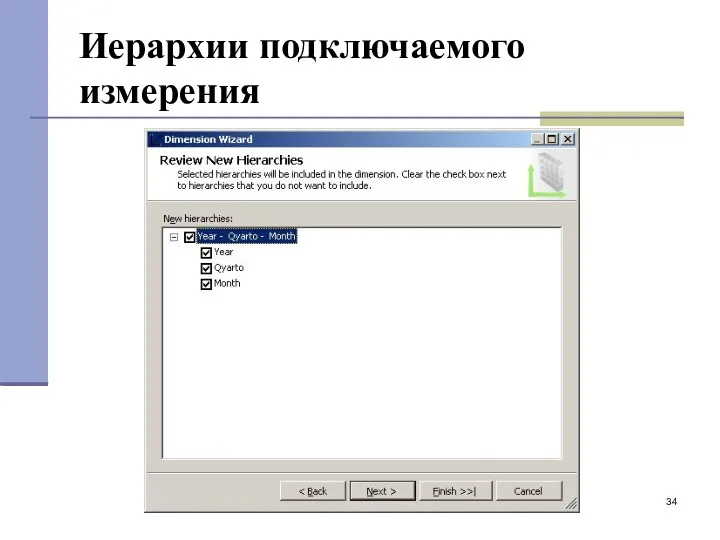
Иерархии подключаемого измерения
Иерархии подключаемого измерения
4.3. Расчет измерения Date
4.3. Расчет измерения Date
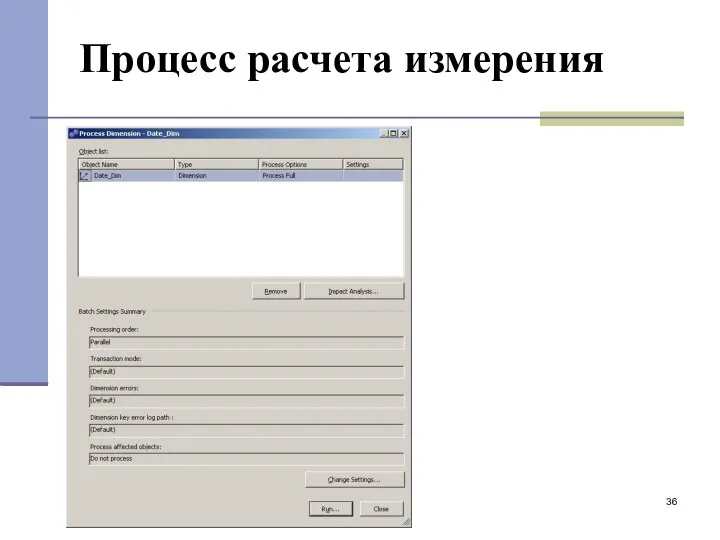
Процесс расчета измерения
Процесс расчета измерения
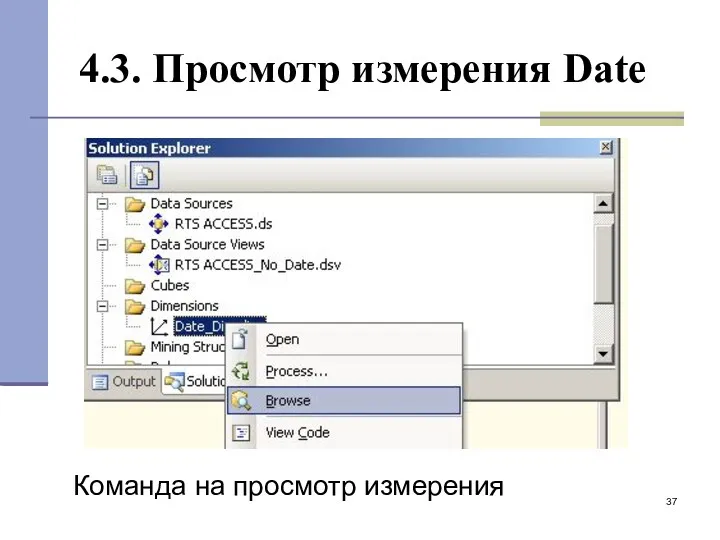
4.3. Просмотр измерения Date
Команда на просмотр измерения
4.3. Просмотр измерения Date
Команда на просмотр измерения
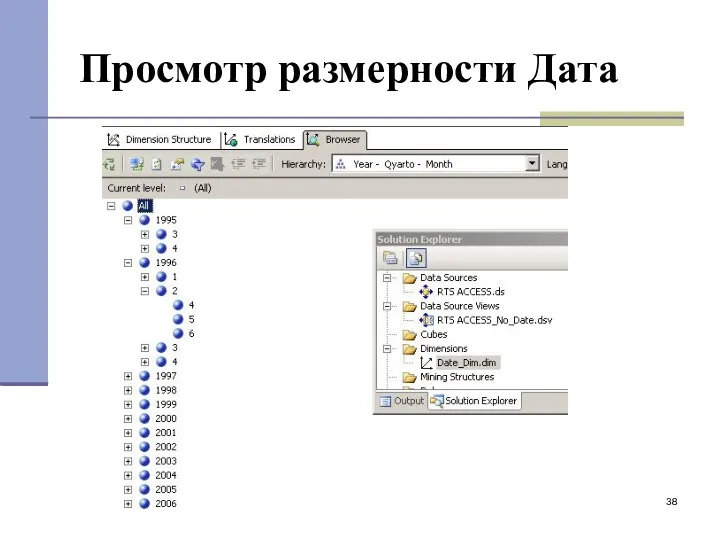
Просмотр размерности Дата
Просмотр размерности Дата
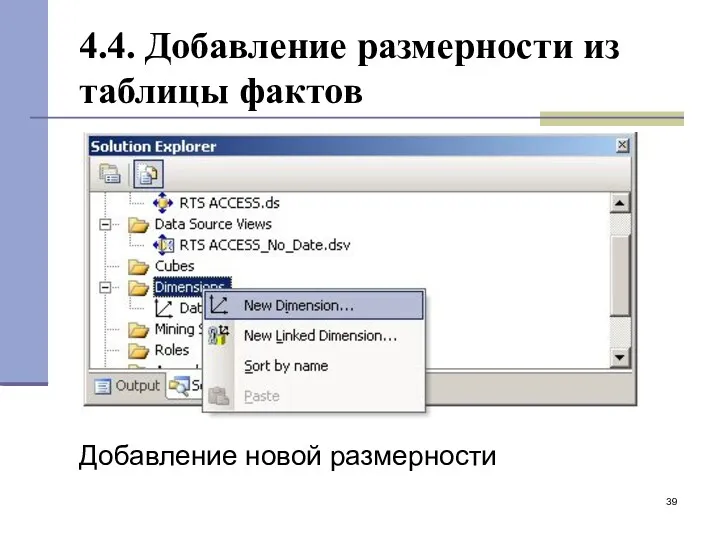
4.4. Добавление размерности из таблицы фактов
Добавление новой размерности
4.4. Добавление размерности из таблицы фактов
Добавление новой размерности
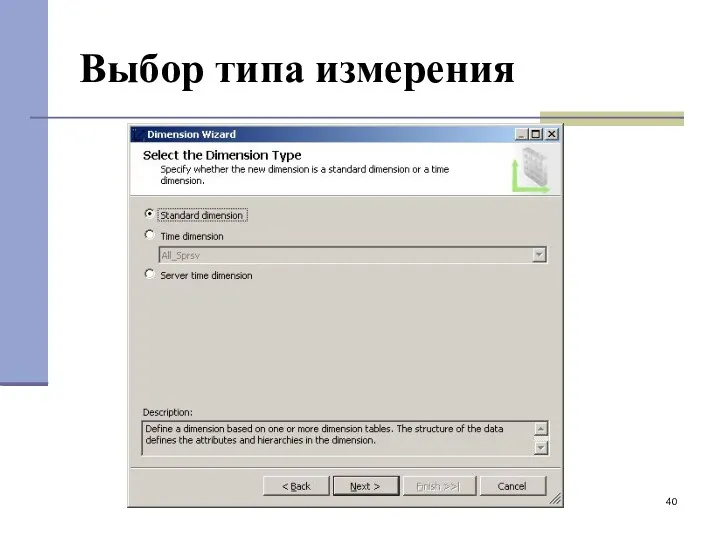
Выбор типа измерения
Выбор типа измерения
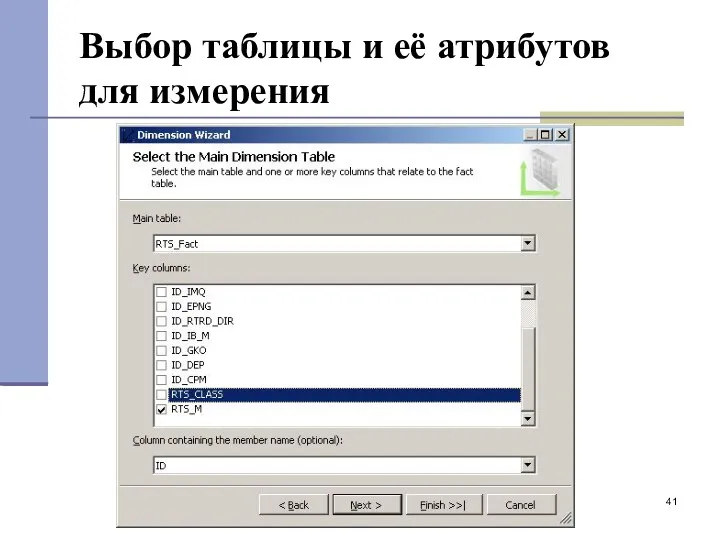
Выбор таблицы и её атрибутов для измерения
Выбор таблицы и её атрибутов для измерения
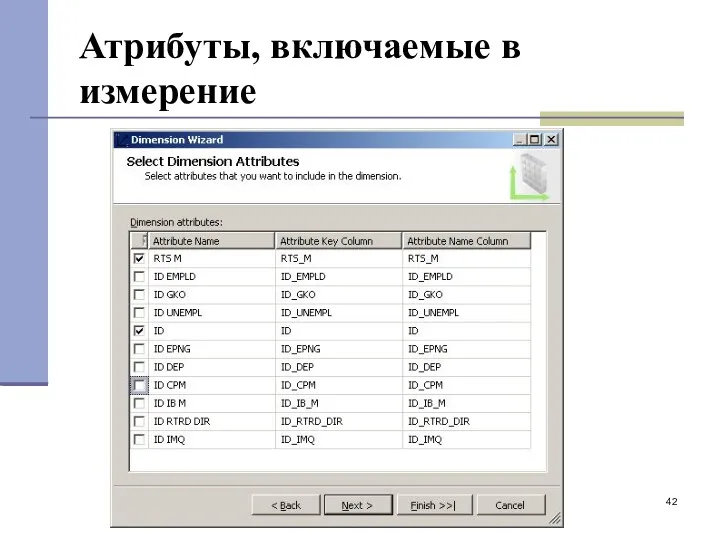
Атрибуты, включаемые в измерение
Атрибуты, включаемые в измерение
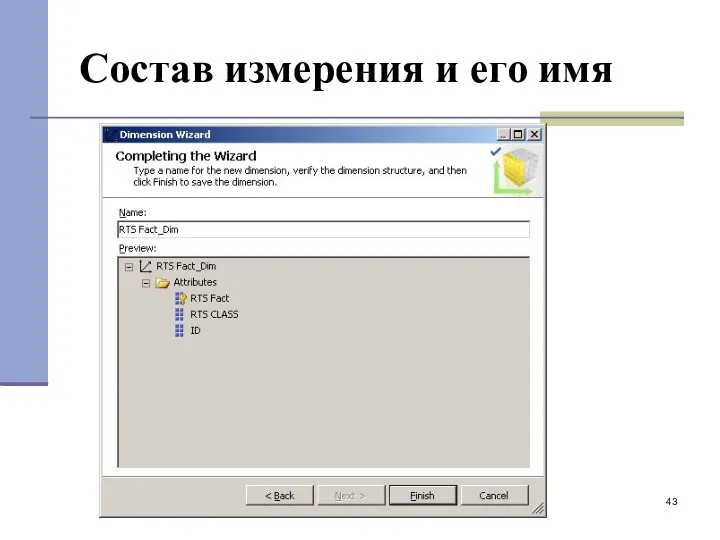
Состав измерения и его имя
Состав измерения и его имя
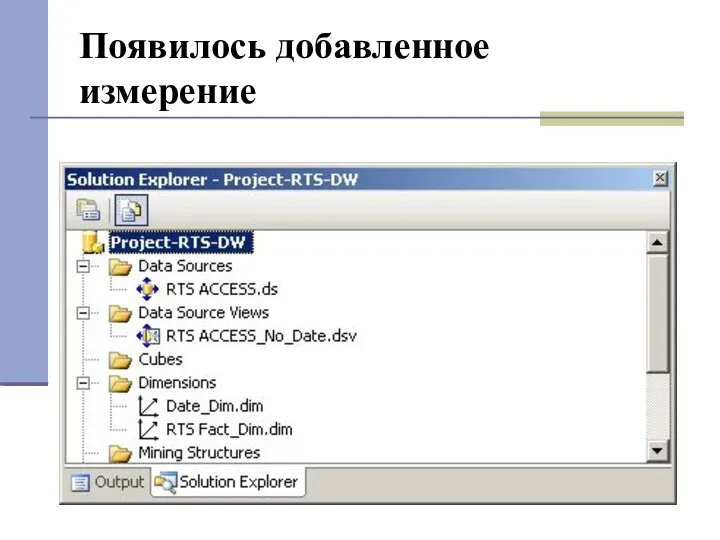
Появилось добавленное измерение
Появилось добавленное измерение
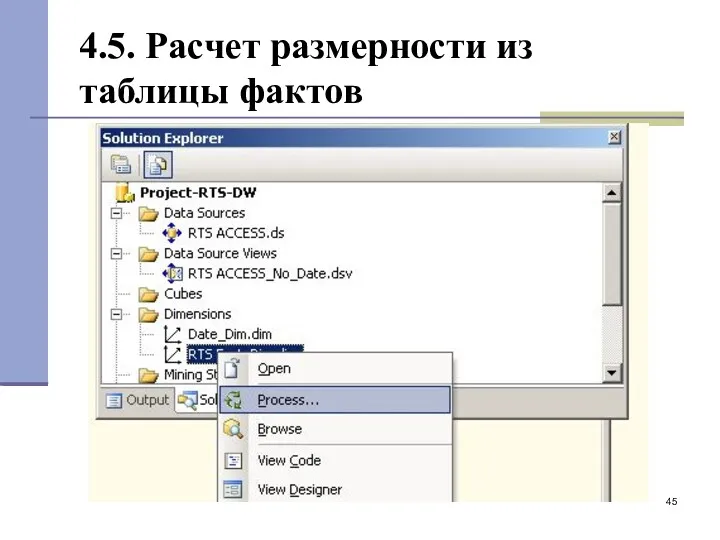
4.5. Расчет размерности из таблицы фактов
4.5. Расчет размерности из таблицы фактов
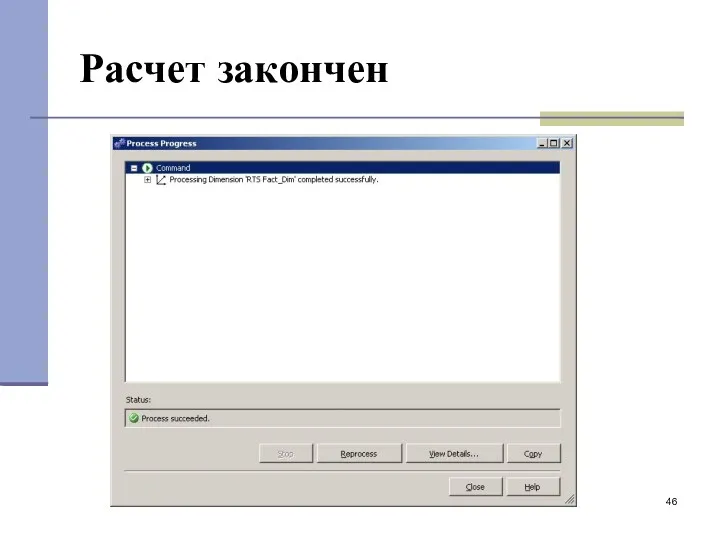
Расчет закончен
Расчет закончен
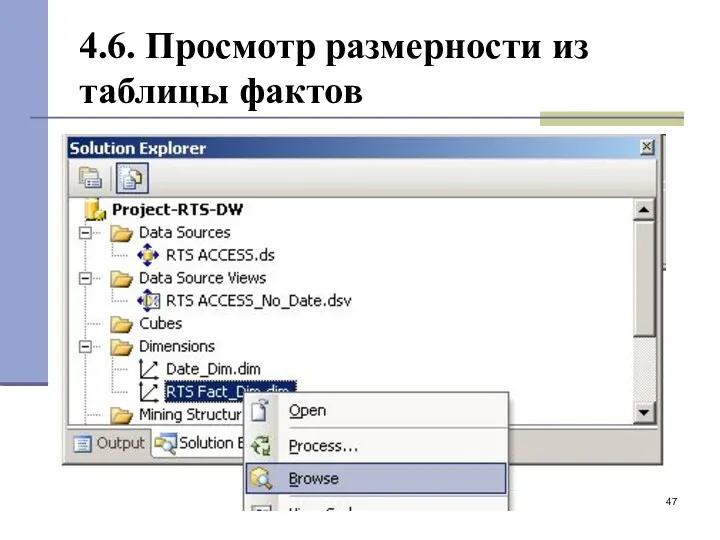
4.6. Просмотр размерности из таблицы фактов
4.6. Просмотр размерности из таблицы фактов
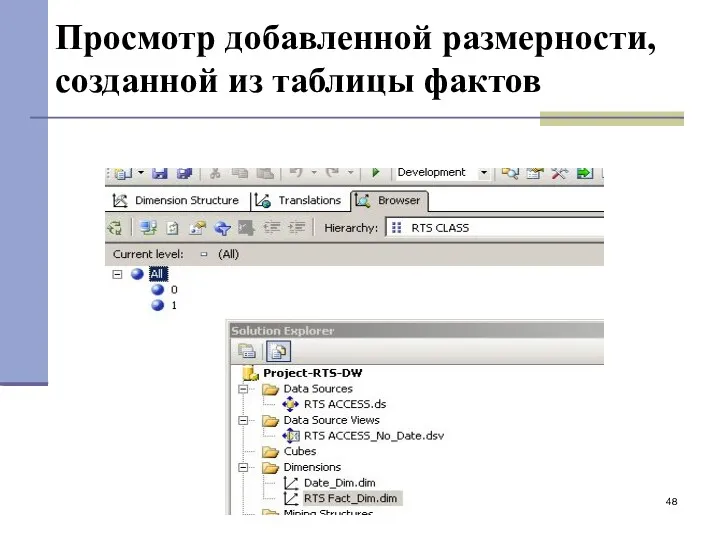
Просмотр добавленной размерности, созданной из таблицы фактов
Просмотр добавленной размерности, созданной из таблицы фактов

5. Создание куба
5. Создание куба

5.1. Особенности показателей в кубах данных MS SQL Server 2005
Система
5.1. Особенности показателей в кубах данных MS SQL Server 2005
Система

Показатели могут быть:
■ аддитивными (additive);
■ полуаддитивными (semiadditive);
■ неаддитивными (nonadditive).
Показатели могут быть:
■ аддитивными (additive);
■ полуаддитивными (semiadditive);
■ неаддитивными (nonadditive).

Аддитивные показатели
Аддитивные показатели, также называемые полноаддитивными, агрегируются со всеми размерностями, включенными
Аддитивные показатели
Аддитивные показатели, также называемые полноаддитивными, агрегируются со всеми размерностями, включенными

Полуаддитивные показатели
Полуаддитивные показатели агрегируются относительно некоторых (не всех) размерностей.
Например, показатель,
Полуаддитивные показатели
Полуаддитивные показатели агрегируются относительно некоторых (не всех) размерностей.
Например, показатель,

Неаддитивные показатели
Неаддитивные показатели не агрегируются по размерностям, но могут быть посчитаны
Неаддитивные показатели
Неаддитивные показатели не агрегируются по размерностям, но могут быть посчитаны

5.2. Особенности сохранения кубов
■ пространство на диске не выделяется под
5.2. Особенности сохранения кубов
■ пространство на диске не выделяется под

5.3. Подключение простых размерностей
К простым размерностям относятся:
■ размерности, состоящие из одной
5.3. Подключение простых размерностей
К простым размерностям относятся:
■ размерности, состоящие из одной
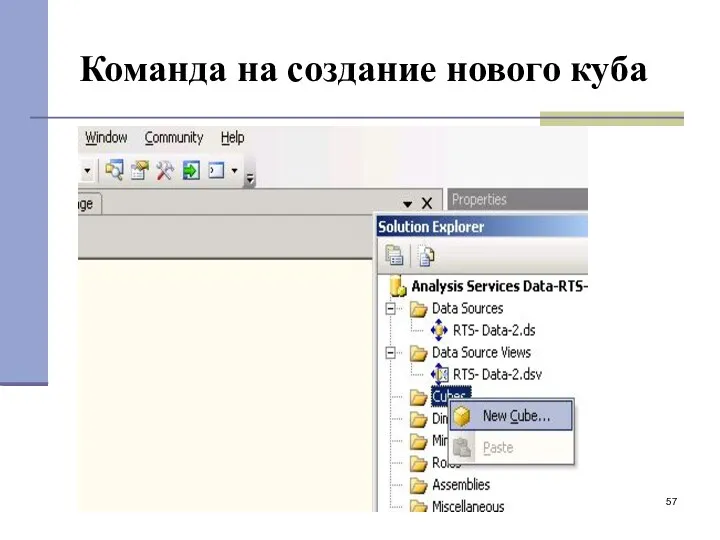
Команда на создание нового куба
Команда на создание нового куба
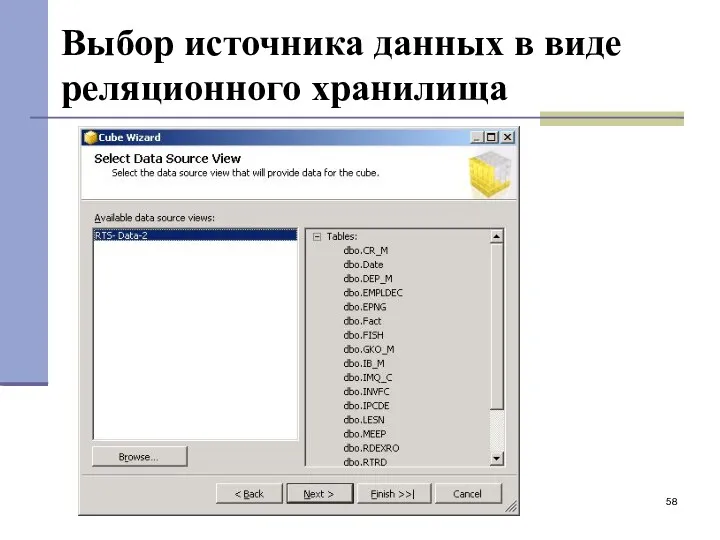
Выбор источника данных в виде реляционного хранилища
Выбор источника данных в виде реляционного хранилища
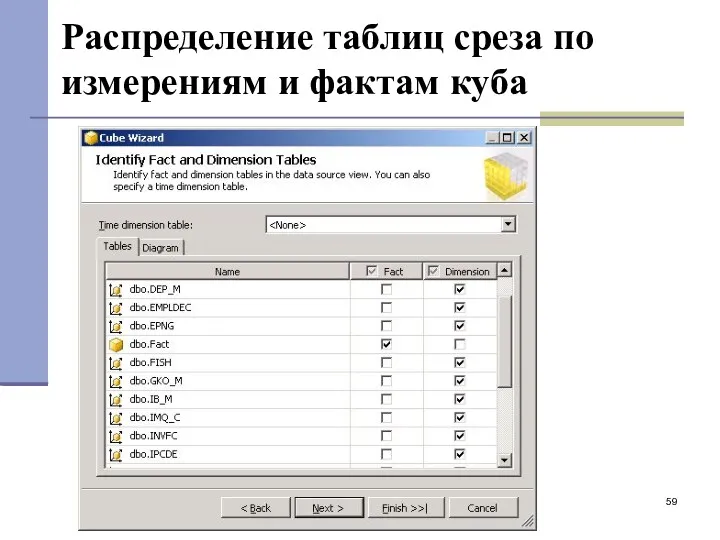
Распределение таблиц среза по измерениям и фактам куба
Распределение таблиц среза по измерениям и фактам куба
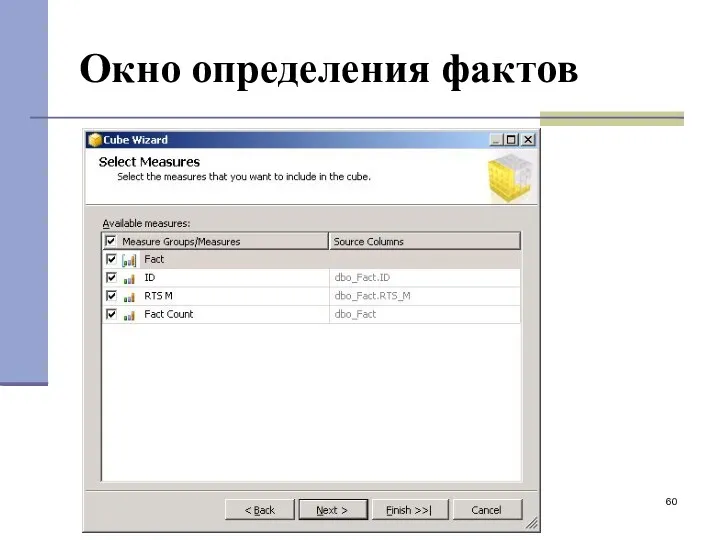
Окно определения фактов
Окно определения фактов
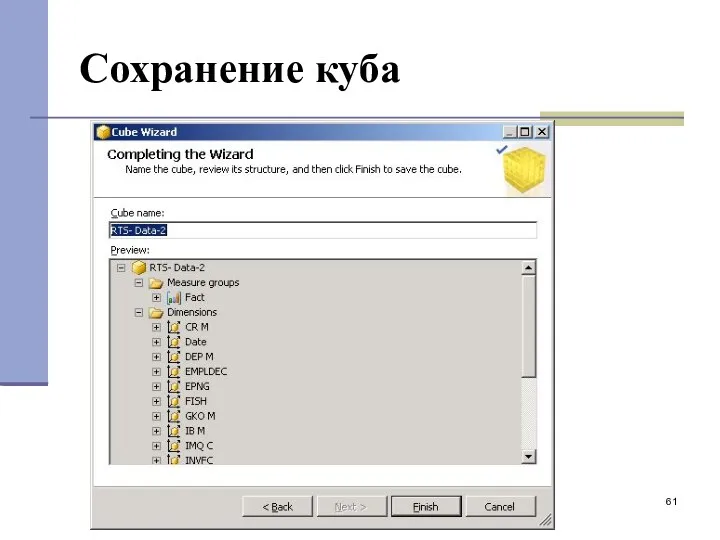
Сохранение куба
Сохранение куба

5.5. Расчет (процессинг) куба
В панели Solution Explorer (Проводник решений) в
5.5. Расчет (процессинг) куба
В панели Solution Explorer (Проводник решений) в
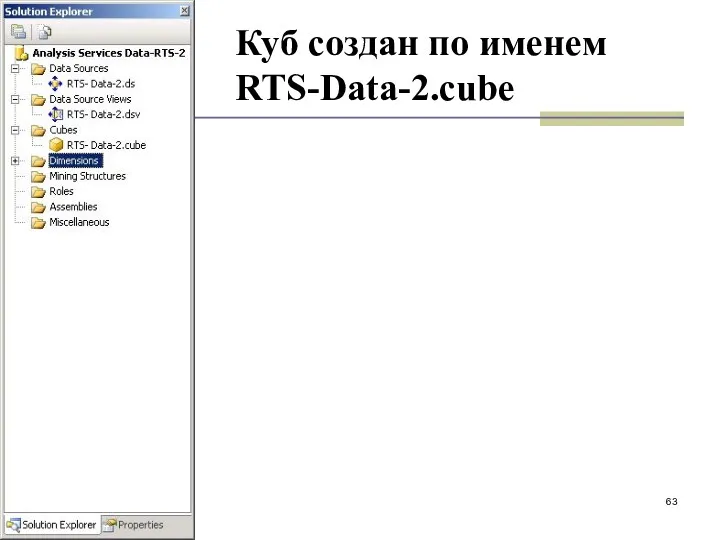
Куб создан по именем RTS-Data-2.cube
Куб создан по именем RTS-Data-2.cube

6. Подключение размерности типа «Время и Дата»
6. Подключение размерности типа «Время и Дата»

6.1. Измерение «Дата» можно подключить двумя способами:
1) при построении куба
6.1. Измерение «Дата» можно подключить двумя способами:
1) при построении куба
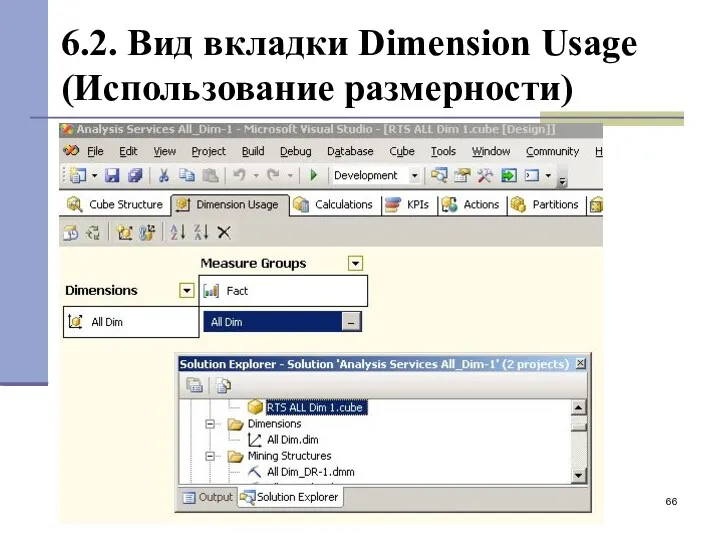
6.2. Вид вкладки Dimension Usage (Использование размерности)
6.2. Вид вкладки Dimension Usage (Использование размерности)
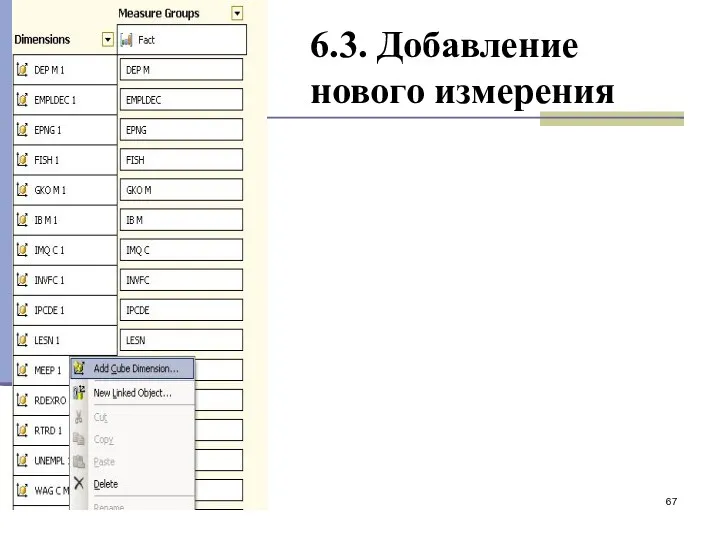
6.3. Добавление нового измерения
6.3. Добавление нового измерения
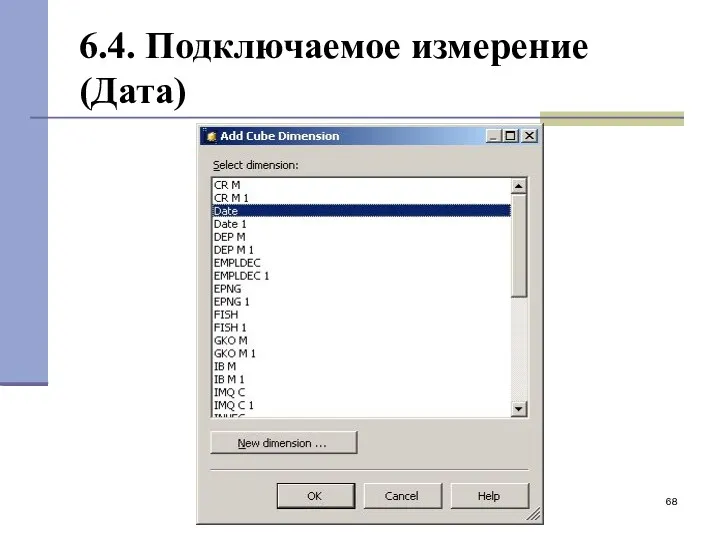
6.4. Подключаемое измерение (Дата)
6.4. Подключаемое измерение (Дата)
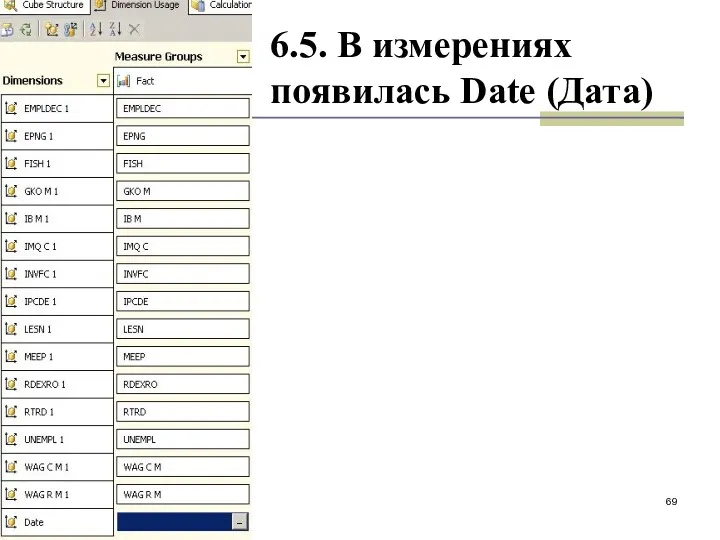
6.5. В измерениях появилась Date (Дата)
6.5. В измерениях появилась Date (Дата)
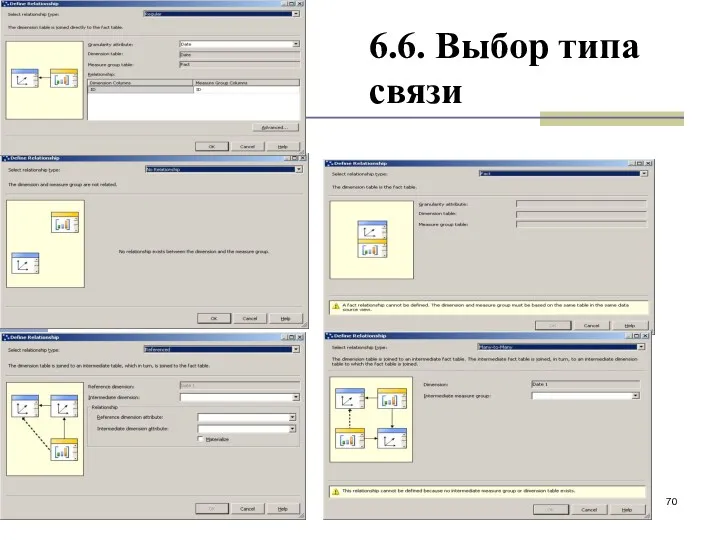
6.6. Выбор типа связи
6.6. Выбор типа связи

7. Подключение к кубу размерности, созданной из таблицы фактов
7. Подключение к кубу размерности, созданной из таблицы фактов
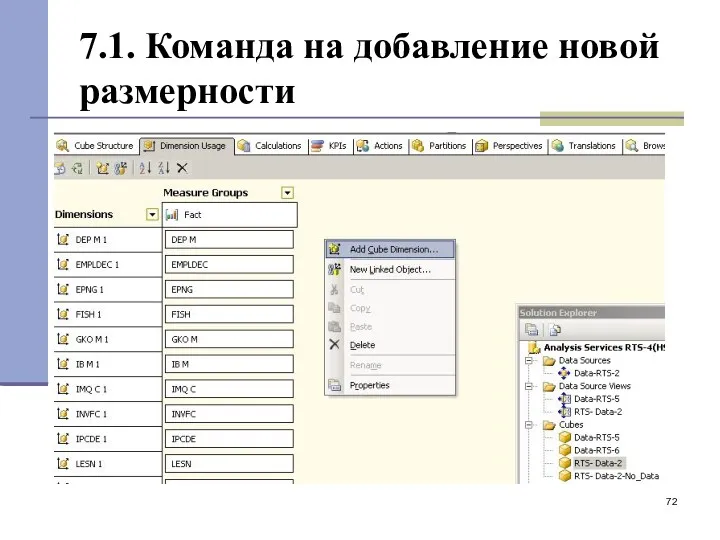
7.1. Команда на добавление новой размерности
7.1. Команда на добавление новой размерности
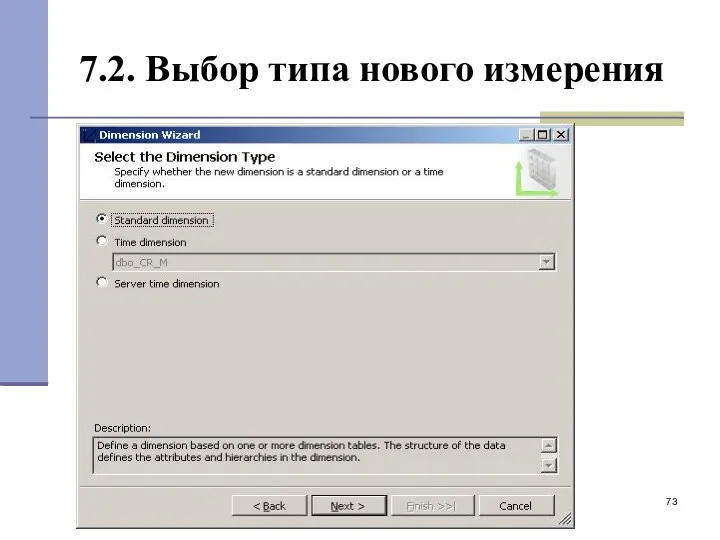
7.2. Выбор типа нового измерения
7.2. Выбор типа нового измерения
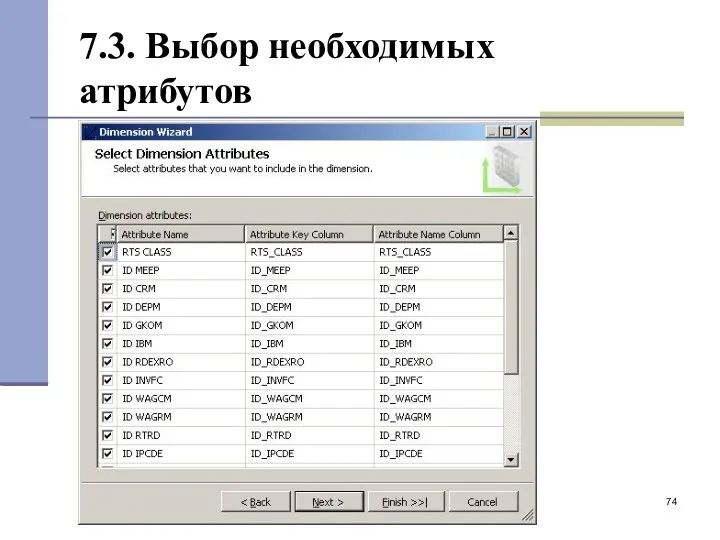
7.3. Выбор необходимых атрибутов
7.3. Выбор необходимых атрибутов
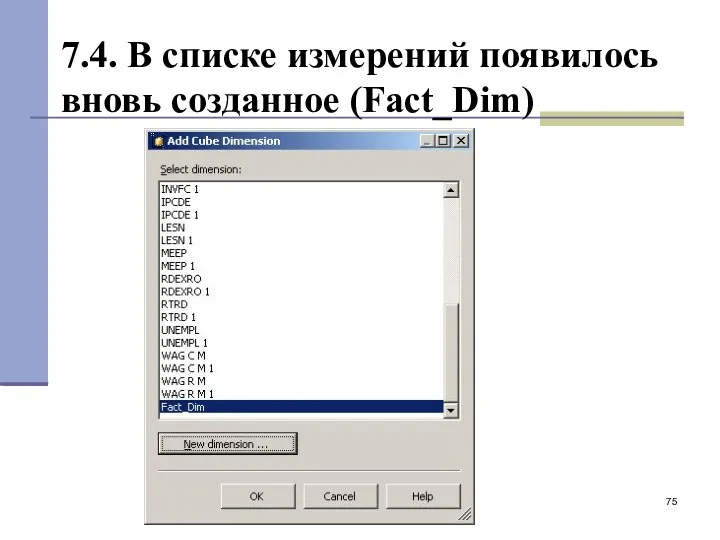
7.4. В списке измерений появилось вновь созданное (Fact_Dim)
7.4. В списке измерений появилось вновь созданное (Fact_Dim)
![7.5. Панель Analysis Services RTS-Data-2.cube [Design] (Построитель (дизайнер) куба)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/213816/slide-75.jpg)
7.5. Панель Analysis Services RTS-Data-2.cube [Design] (Построитель
(дизайнер) куба)
7.5. Панель Analysis Services RTS-Data-2.cube [Design] (Построитель
(дизайнер) куба)
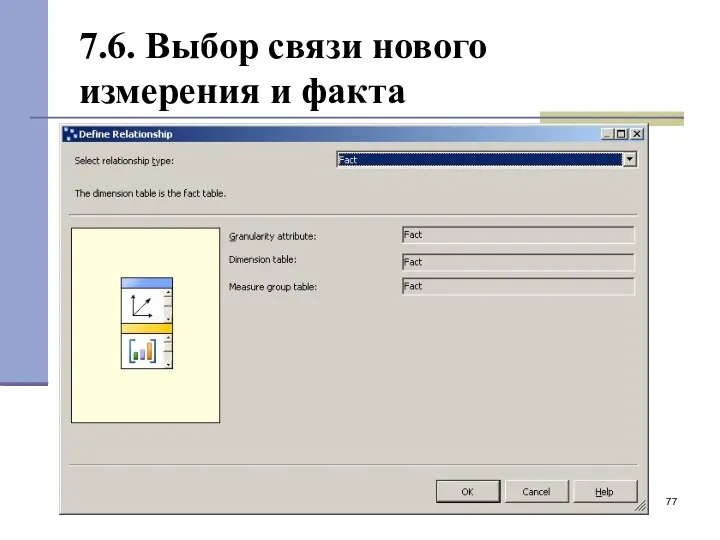
7.6. Выбор связи нового измерения и факта
7.6. Выбор связи нового измерения и факта
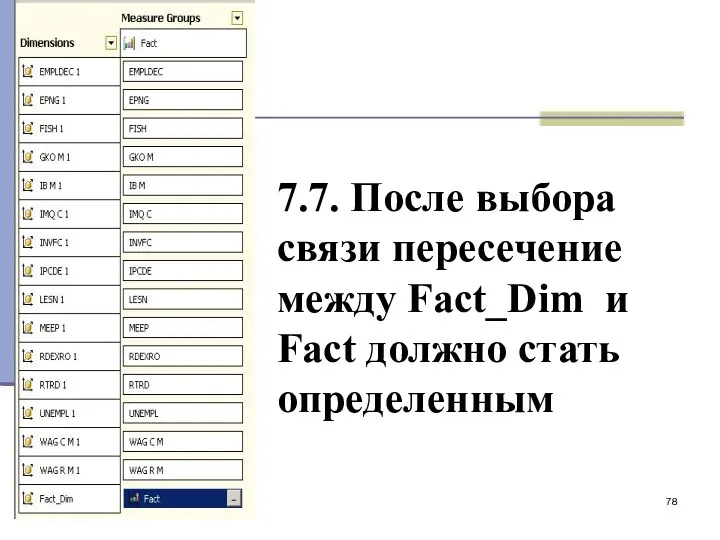
7.7. После выбора связи пересечение между Fact_Dim и Fact должно стать
7.7. После выбора связи пересечение между Fact_Dim и Fact должно стать
 Урок по информатике в 9 классе
Урок по информатике в 9 классе Информационная безопасность. Методы защиты информации
Информационная безопасность. Методы защиты информации Современные устройства ввода информации в ПК
Современные устройства ввода информации в ПК Автоматизована система - Ведення мережі об’єктів поштового зв’язку. Призначення системи
Автоматизована система - Ведення мережі об’єктів поштового зв’язку. Призначення системи Национальная стратегия США по развитию информационного общества
Национальная стратегия США по развитию информационного общества Внедрение Битрикс24 в сфере услуг
Внедрение Битрикс24 в сфере услуг Информатика и ИКТ
Информатика и ИКТ Git (гит) - распределенная система управления версиями Think Results
Git (гит) - распределенная система управления версиями Think Results Практика в пресс-службе ПГНИУ
Практика в пресс-службе ПГНИУ Програмування пристрою для контролю температури на базі мікроконтролера RISC-архітектури
Програмування пристрою для контролю температури на базі мікроконтролера RISC-архітектури Виртуализация и контейнеризация
Виртуализация и контейнеризация Автоматизированные системы управления в гостиничных предприятиях
Автоматизированные системы управления в гостиничных предприятиях Язык разметки гипертекста HTML
Язык разметки гипертекста HTML Сайт LOGOPEDSPB.RU. Ваш домашний логопед
Сайт LOGOPEDSPB.RU. Ваш домашний логопед Модели объектов и их назначение
Модели объектов и их назначение Операционные системы с сетевыми возможностями. (Тема 10)
Операционные системы с сетевыми возможностями. (Тема 10) Использование деловой графики для визуализации текстовой информации
Использование деловой графики для визуализации текстовой информации Графический редактор Paint
Графический редактор Paint 3D - моделирование и его применение
3D - моделирование и его применение Файловый менеджер Total Commander
Файловый менеджер Total Commander Создание игры в Construct 3
Создание игры в Construct 3 КуМИР – практикум Робот с автопроверкой
КуМИР – практикум Робот с автопроверкой Файлдар мен бумалар. Жарлықтар
Файлдар мен бумалар. Жарлықтар Региональная информационная система ОМС Республики Дагестан
Региональная информационная система ОМС Республики Дагестан Средства массовой информации
Средства массовой информации Роль аккаунт-менеджера
Роль аккаунт-менеджера Шифрование информации
Шифрование информации Компьютерные словари и системы перевода текстов
Компьютерные словари и системы перевода текстов