- Создание объектов базы данных в PostgreSQL

Содержание
- 2. Цели Создание простых и сложных представлений Получение информации из представлений Создание, изменение и использование последовательностей Создание
- 4. Объекты базы данных
- 5. Что такое представление?
- 6. Преимущества представлений Ограничивает доступ к данным Делает сложные запросы простыми Обеспечивает независимость данных Представляет одну и
- 7. Изменяемые представления Список FROM в запросе, определяющем представлении, должен содержать ровно один элемент, и это должна
- 8. Простые представления CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] [ RECURSIVE ] VIEW
- 9. Создание представлений CREATE VIEW comedies AS SELECT * FROM films WHERE kind = 'Comedy'; CREATE VIEW
- 10. Удаление представлений DROP VIEW [ IF EXISTS ] имя [, ...] [ CASCADE | RESTRICT ]
- 11. Последовательности
- 12. Последовательности Генерирует уникальные числовые значения Может быть использована для генерирования значений первичного ключа Упрощает логику приложения
- 13. Создание последовательности CREATE [ TEMPORARY | TEMP ] SEQUENCE [ IF NOT EXISTS ] имя [
- 14. Создание последовательности CREATE SEQUENCE IF NOT EXISTS serial AS bigint INCREMENT BY 1 MINVALUE 1 NO
- 15. Функции для работы с последовательностями nextval(regclass) - продвигает объект последовательности к следующему значению и возвращает это
- 16. Использование последовательности SELECT nextval('serial'); nextval --------- 1 INSERT INTO distributors VALUES (nextval('serial'), 'nothing');
- 17. Изменение последовательности ALTER SEQUENCE [ IF EXISTS ] имя [ AS тип_данных ] [ INCREMENT [
- 18. Изменение последовательности Вы должны быть владельцем последовательности или суперпользователем. Изменения вступят в силу только после того,
- 19. Индексы
- 20. Индексы Является объектом схемы. Индексы применяются в первую очередь для оптимизации производительности базы данных. Сокращает количество
- 21. Создание индекса Автоматически: Уникальный индекс создается автоматически при объявлении ограничений PRIMARY KEY или UNIQUE в описании
- 22. B-дерево B-деревья могут работать в условиях на равенство и в проверках диапазонов с данными ( =,
- 23. Хеш-индекс Хеш-индексы хранят 32-битный хеш-код. Хеш-индексы работают только с простыми условиями равенства. CREATE INDEX имя ON
- 24. GiST, SP-GiST индекс GiST — сокращение от «generalized search tree» Предназначен для работы с геоданными, массивами
- 25. GIN-индексы GIN-индексы представляют собой «инвертированные индексы», в которых могут содержаться значения с несколькими ключами, например массивы
- 26. BRIN-индексы Сокращение от Block Range INdexes, Индексы зон блоков. Хранят обобщённые сведения о значениях, находящихся в
- 27. Создание индекса CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ]
- 28. Параметры индекса UNIQUE - Указывает, что система должна контролировать повторяющиеся значения в таблице. CONCURRENTLY - PostgreSQL
- 29. Рекомендации По Созданию Индекса
- 30. Изменение индекса Изменение индекса определяется следующей командой: Перестроение индекса ALTER INDEX [ IF EXISTS ] имя
- 32. Скачать презентацию

Цели
Создание простых и сложных представлений
Получение информации из представлений
Создание, изменение и использование
Цели
Создание простых и сложных представлений
Получение информации из представлений
Создание, изменение и использование
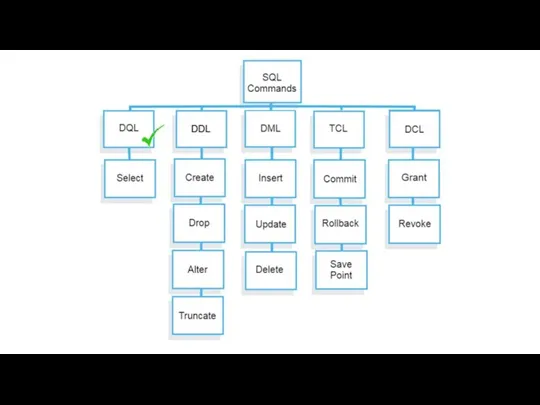

Объекты базы данных
Объекты базы данных
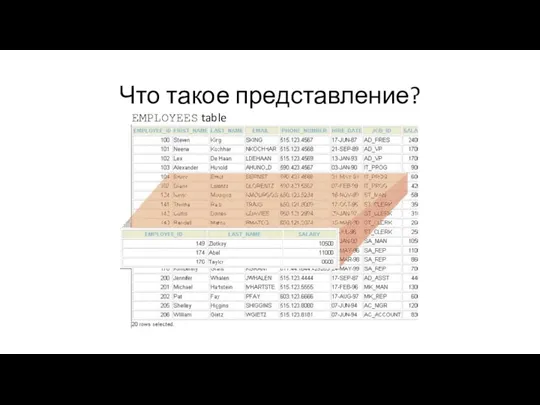
Что такое представление?
Что такое представление?
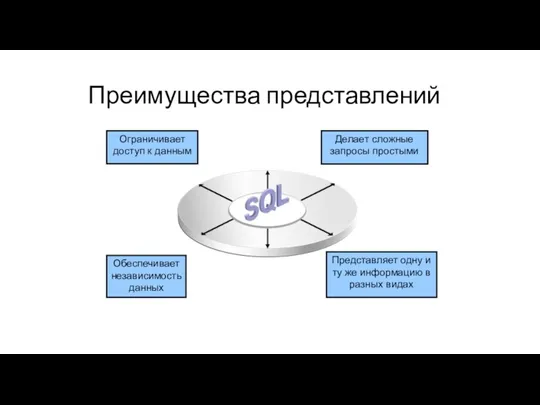
Преимущества представлений
Ограничивает доступ к данным
Делает сложные запросы простыми
Обеспечивает независимость данных
Представляет одну
Преимущества представлений
Ограничивает доступ к данным
Делает сложные запросы простыми
Обеспечивает независимость данных
Представляет одну

Изменяемые представления
Список FROM в запросе, определяющем представлении, должен содержать ровно один
Изменяемые представления
Список FROM в запросе, определяющем представлении, должен содержать ровно один
![Простые представления CREATE [ OR REPLACE ] [ TEMP |](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582370/slide-7.jpg)
Простые представления
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ]
Простые представления
CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ]

Создание представлений
CREATE VIEW comedies AS
SELECT *
FROM films
WHERE kind
Создание представлений
CREATE VIEW comedies AS
SELECT *
FROM films
WHERE kind
![Удаление представлений DROP VIEW [ IF EXISTS ] имя [,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582370/slide-9.jpg)
Удаление представлений
DROP VIEW [ IF EXISTS ] имя [, ...] [
Удаление представлений
DROP VIEW [ IF EXISTS ] имя [, ...] [

Последовательности
Последовательности

Последовательности
Генерирует уникальные числовые значения
Может быть использована для генерирования значений первичного ключа
Упрощает
Последовательности
Генерирует уникальные числовые значения
Может быть использована для генерирования значений первичного ключа
Упрощает
![Создание последовательности CREATE [ TEMPORARY | TEMP ] SEQUENCE [](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582370/slide-12.jpg)
Создание последовательности
CREATE [ TEMPORARY | TEMP ] SEQUENCE [ IF NOT
Создание последовательности
CREATE [ TEMPORARY | TEMP ] SEQUENCE [ IF NOT

Создание последовательности
CREATE SEQUENCE IF NOT EXISTS serial
AS bigint
INCREMENT BY
Создание последовательности
CREATE SEQUENCE IF NOT EXISTS serial
AS bigint
INCREMENT BY

Функции для работы с последовательностями
nextval(regclass) - продвигает объект последовательности к следующему
Функции для работы с последовательностями
nextval(regclass) - продвигает объект последовательности к следующему

Использование последовательности
SELECT nextval('serial');
nextval
---------
1
INSERT INTO distributors VALUES (nextval('serial'), 'nothing');
Использование последовательности
SELECT nextval('serial');
nextval
---------
1
INSERT INTO distributors VALUES (nextval('serial'), 'nothing');
![Изменение последовательности ALTER SEQUENCE [ IF EXISTS ] имя [](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582370/slide-16.jpg)
Изменение последовательности
ALTER SEQUENCE [ IF EXISTS ] имя
[ AS тип_данных
Изменение последовательности
ALTER SEQUENCE [ IF EXISTS ] имя
[ AS тип_данных

Изменение последовательности
Вы должны быть владельцем последовательности или суперпользователем.
Изменения вступят в
Изменение последовательности
Вы должны быть владельцем последовательности или суперпользователем.
Изменения вступят в

Индексы
Индексы

Индексы
Является объектом схемы.
Индексы применяются в первую очередь для оптимизации производительности базы
Индексы
Является объектом схемы.
Индексы применяются в первую очередь для оптимизации производительности базы

Создание индекса
Автоматически: Уникальный индекс создается автоматически при объявлении ограничений PRIMARY KEY
Создание индекса
Автоматически: Уникальный индекс создается автоматически при объявлении ограничений PRIMARY KEY

B-дерево
B-деревья могут работать в условиях на равенство и в проверках диапазонов
B-дерево
B-деревья могут работать в условиях на равенство и в проверках диапазонов

Хеш-индекс
Хеш-индексы хранят 32-битный хеш-код.
Хеш-индексы работают только с простыми условиями равенства.
CREATE INDEX
Хеш-индекс
Хеш-индексы хранят 32-битный хеш-код.
Хеш-индексы работают только с простыми условиями равенства.
CREATE INDEX

GiST, SP-GiST индекс
GiST — сокращение от «generalized search tree»
Предназначен для работы с
GiST, SP-GiST индекс
GiST — сокращение от «generalized search tree»
Предназначен для работы с

GIN-индексы
GIN-индексы представляют собой «инвертированные индексы», в которых могут содержаться значения с
GIN-индексы
GIN-индексы представляют собой «инвертированные индексы», в которых могут содержаться значения с

BRIN-индексы
Сокращение от Block Range INdexes, Индексы зон блоков.
Хранят обобщённые сведения о
BRIN-индексы
Сокращение от Block Range INdexes, Индексы зон блоков.
Хранят обобщённые сведения о
![Создание индекса CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582370/slide-26.jpg)
Создание индекса
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ]
[
Создание индекса
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ]
[

Параметры индекса
UNIQUE - Указывает, что система должна контролировать повторяющиеся значения в
Параметры индекса
UNIQUE - Указывает, что система должна контролировать повторяющиеся значения в

Рекомендации По Созданию Индекса
Рекомендации По Созданию Индекса

Изменение индекса
Изменение индекса определяется следующей командой:
Перестроение индекса
ALTER INDEX [ IF EXISTS
Изменение индекса
Изменение индекса определяется следующей командой:
Перестроение индекса
ALTER INDEX [ IF EXISTS
 Цифровые сети связи. Модуль 5
Цифровые сети связи. Модуль 5 Государственная система научно-технической информации
Государственная система научно-технической информации Текстовый редактор
Текстовый редактор Network foundations
Network foundations Компания Century Star Media Co
Компания Century Star Media Co Реляционная база данных. Bigdata. Основные понятия базы данных
Реляционная база данных. Bigdata. Основные понятия базы данных MrBeast
MrBeast Infogr.am. Сервис для визуализации данных
Infogr.am. Сервис для визуализации данных Вычисления в модели
Вычисления в модели Vue - прогрессивный фреймворк для создания пользовательских интерфейсов
Vue - прогрессивный фреймворк для создания пользовательских интерфейсов Unity скрипты
Unity скрипты Компьютерный текстовый документ как структура данных
Компьютерный текстовый документ как структура данных Компьютерные курсы. Создание трехмерных игр на движке Unity Юниум
Компьютерные курсы. Создание трехмерных игр на движке Unity Юниум Язык программирования PROLOG
Язык программирования PROLOG Кодирование звуковой информации
Кодирование звуковой информации Избранные задачи ЕГЭ по информатике
Избранные задачи ЕГЭ по информатике Windows 10
Windows 10 Сервисы Google
Сервисы Google Возможности искусственного интеллекта
Возможности искусственного интеллекта Управление информационными технологиями на предприятии
Управление информационными технологиями на предприятии Виды компьютерных вирусов. Антивирусные программы
Виды компьютерных вирусов. Антивирусные программы Тема 2. Каскадные таблицы стилей CSS
Тема 2. Каскадные таблицы стилей CSS Компьютерное моделирование
Компьютерное моделирование Комп'ютерна графіка. Графічні редактори
Комп'ютерна графіка. Графічні редактори Режимы и способы обработки данных
Режимы и способы обработки данных Ақпараттық жүйе
Ақпараттық жүйе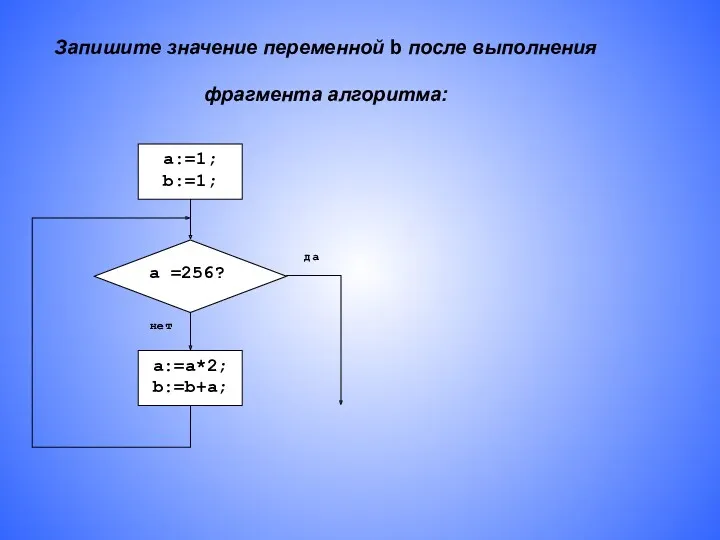 Значение переменной b после выполнения фрагмента алгоритма
Значение переменной b после выполнения фрагмента алгоритма Методическая инструкция. Создание годичного рассписания
Методическая инструкция. Создание годичного рассписания