- Создание таблиц БД

Содержание
- 2. Синтаксис команды CREATE TABLE следующий: CREATE TABLE ( [( )], ( [( )]), …).
- 3. Значение длины поля зависит от типа данных. Если его не указывать, то СУБД сама назначает значение
- 4. Пример: CREATE TABLE STUDENTS (NOM_ZACH INTEGER, SFAM CHAR (20), SNAME CHAR (10), STIP DECIMAL)
- 5. Числовые типы Tочные числовые типы К категории точных числовых типов в SQL относятся те типы, значения
- 6. с плавающей запятой: float (от -1.79E + 308 до 1.79E + 308) и real (от -3.40E
- 7. DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого типа (до и после десятичной
- 8. Строковые типы В SQL Server предусмотрены две дублирующих разновидности полей для представления текстовых данных: поля Unicode
- 9. Всего в SQL Server предусмотрены следующие типы для текстовых данных: ∙ char/nchar - строковые данные фиксированной
- 10. При использовании типа Char значения длиной короче заданной дополняются пробелами до указанной длины. Максимальное значение длины
- 11. Если необходимо ввести значения большой длины можно использовать ключевое слово мах, что позволяет определять столбцы до
- 12. datetime (8 байт, точность до 3,33 миллисекунд); smalldatetime (4 байта, точность до минуты). В большинстве приложений
- 13. Тип данных UNIQUEIDENTIFIER используется для хранения глобальных уникальных идентификационных номеров.
- 14. SQL_VARIANT - Служит для хранения значений разных типов одновременно, таких как числовые значения, строки и даты.
- 15. Логический тип данных - хранит значения вида true/false (единица/ноль). В SQL Server он представлен типом данных
- 16. DATEDIFF ( datepart , startdate , enddate )─ возвращает интервал времени, прошедшего между двумя временными отметками
- 17. DATEPART ( datepart , date ) ─ возвращает целое число, представляющее собой указанную аргументом datepart часть
- 18. В ряде случаев функцию DATEPART можно заменить более простыми функциями. DAY ( date ) - целочисленное
- 20. Пользовательские типы данных. Могут использоваться при определении какого-либо специфического или часто употребляемого формата. Создание пользовательского типа
- 21. EXEC sp_addtype dt, DATETIME, 'NULL' Удаление пользовательского типа данных происходит в результате выполнения процедуры sp_droptype type
- 22. CREATE TYPE SSN FROM varchar(10) NOT NULL ;
- 23. Преобразование типов Для выполнения преобразований SQL Server содержит функции CONVERT и CAST, с помощью которых значения
- 24. Пример: SELECT ‘сегодня ‘ + CONVERT(VARCHAR(11),GETDATE()) CAST('1977.01.07‘ AS Datetime)
- 25. Оновные функции – поиск подстроки CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] ) - вырезка SUBSTRING (
- 26. Временные таблицы Временные таблицы похожи на обычные, однако они не предназначены для постоянного хранения данных. Они
- 27. В SQL Server существуют два типа временных таблиц: локальные и глобальные. Локальные временные таблицы доступны лишь
- 28. Создание ограничений
- 29. Декларативные ограничения при создании таблиц При создании таблиц могут быть заданы декларативные ограничения целостности атрибутов: значения
- 30. Например, на значение стипендии может быть наложено ограничение (стипендия должна находиться в пределах от 500 до
- 31. Возраст сотрудника должен быть не менее 18 лет: BIRTH_DAY DATE CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH_DAY)>=18)
- 32. При создании ограничений необходимо учитывать следующее: ограничение, определенное для одного поля может ссылаться только на это
- 33. ограничения DEFAULT должны быть ограничениями на уровне поля; ограничения CHECK на уровне поля могут ссылаться только
- 34. Пример ограничения на уровне таблицы CREATE TABLE TestTable ( id int DEFAULT 1 NOT NULL, vcName
- 35. Ограничение целостности, включаемое в определение столбца, может быть эквивалентным образом выражено в виде табличного ограничения целостности.
- 36. Часто для поля или группы полей требуется реализовать ограничение, связанное c уникальностью значений. В этом случае
- 37. Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен быть определен только один первичный ключ,
- 38. PRIMARY KEY(NOM_ZACH, PKOD)
- 39. Ссылочная целостность
- 42. Таблица USP подчинена двум другим таблицам: SUBJECTS и STUDENTS. При этом таблица USP связана с таблицей
- 43. Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN KEY) для полей NOM_ZACH и
- 44. Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД так, чтобы заставить внешний и родительский
- 45. Создадим таблицу USP с полем NOM_ZACH, и PKOD определенными в качестве внешних ключей: CREATE TABLE USP
- 46. Используя ограничения FOREIGN KEY, можно не указывать список полей родительского ключа, если родительский ключ имеет ограничение
- 47. В соответствии со стандартом, изменение или удаление значений родительского ключа не допускается. Это означает, что нельзя
- 49. При необходимости изменить или удалить текущее ссылочное значение родительского ключа существует следующие возможности: 1. Запретить изменения
- 50. Итак, изменения в родительском ключе можно разделить на ограниченные (NO ACTION), каскадируемые (CASCADE), пустые (SET NULL)
- 51. Предположим, что есть необходимость в изменении номера зачетной книжки, причем оценки должны сохраниться у этого же
- 52. CREATE TABLE USP (NOM_ZACH INTEGER NOT NULL, PKOD INTEGER, TNUM INTEGER, UDATE DATE , MARK INTEGER,
- 53. Если данные о студенте удаляются, удаление их должно быть выполнено сначала в подчинённой (USP), а затем
- 55. Изменение таблиц При необходимости в уже созданную таблицу можно внести изменения, например, добавить столбец. ALTER TABLE
- 56. Новое поле станет последним по порядку в таблице. Допускается добавление сразу нескольких полей. Они должны быть
- 57. В таблицу могут быть добавлены и новые ограничения с помощью команды ADD CONSTRAINT . Имя ограничения
- 58. Примеры: 1. Для добавления ограничения, задающего значение по умолчанию: ALTER TABLE USP ADD CONSTRAINT Def_Mark DEFAULT
- 59. Для получения информации об ограничениях используется системная процедура sp_helpconstraint имя_таблицы или sp_help имя ограничения.
- 60. Удаление столбцов и ограничений Из созданной таблицы можно удалить столбцы или ограничения. При удалении ограничений следует
- 61. Разрешение и запрет ограничений С помощью команды ALTER TABLE с предложениями ENABLE и DISABLE можно разрешать
- 62. Модификация столбцов Иногда при создании таблиц делают неверные предположения относительно типа данных, которые собираются хранить в
- 63. Удаление таблиц Удаление таблиц выполняется с помощью команды DROP TABLE. Для того чтобы иметь возможность удалить
- 64. Создание индексов Индекс - упорядоченный список полей или групп полей в таблице. Таблицы могут иметь огромное
- 65. Когда создаётся индекс для поля, база данных запоминает порядок всех значений этого поля в специальной области
- 67. С помощью индексов осуществляется доступ к данным наиболее оптимальным способом. В индексы следует включать поля, к
- 68. Для создания индекса используется оператор CREATE INDEX. Синтаксис: CREATE INDEX имя_индекса ON таблица (поле[, …n])
- 69. Таблица, для которой создаётся индекс, должна уже существовать и содержать имена индексируемых полей. При этом имя
- 70. Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое слово UNIQUE в операторе CREATE INDEX
- 71. Для удаления индекса используется команда DROP INDEX имя индекса Чтобы изменить индекс таблицы, необходимо удалить его
- 72. Кластеризованный индекс Использование опции Clustered index позволяет произвести так называемое кластерное индексирование, в результате чего будут
- 74. Скачать презентацию
![Синтаксис команды CREATE TABLE следующий: CREATE TABLE ( [( )], ( [( )]), …).](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/277597/slide-1.jpg)
Синтаксис команды CREATE TABLE следующий:
CREATE TABLE <имя таблицы>
(<имя поля1> <тип
Синтаксис команды CREATE TABLE следующий:
CREATE TABLE <имя таблицы>
(<имя поля1> <тип

Значение длины поля зависит от типа данных.
Если его не
Значение длины поля зависит от типа данных.
Если его не

Пример:
CREATE TABLE STUDENTS
(NOM_ZACH INTEGER,
SFAM CHAR (20),
SNAME CHAR (10),
STIP
Пример:
CREATE TABLE STUDENTS
(NOM_ZACH INTEGER,
SFAM CHAR (20),
SNAME CHAR (10),
STIP

Числовые типы
Tочные числовые типы
К категории точных числовых типов в SQL относятся
Числовые типы
Tочные числовые типы
К категории точных числовых типов в SQL относятся

с плавающей запятой:
float (от -1.79E + 308 до 1.79E +
с плавающей запятой:
float (от -1.79E + 308 до 1.79E +
![DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/277597/slide-6.jpg)
DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого
DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого

Строковые типы
В SQL Server предусмотрены две дублирующих разновидности полей для представления
Строковые типы
В SQL Server предусмотрены две дублирующих разновидности полей для представления

Всего в SQL Server предусмотрены следующие типы для текстовых данных:
∙ char/nchar
Всего в SQL Server предусмотрены следующие типы для текстовых данных:
∙ char/nchar

При использовании типа Char значения длиной короче заданной дополняются пробелами до
При использовании типа Char значения длиной короче заданной дополняются пробелами до

Если необходимо ввести значения большой длины можно использовать ключевое слово мах,
Если необходимо ввести значения большой длины можно использовать ключевое слово мах,

datetime (8 байт, точность до 3,33 миллисекунд);
smalldatetime (4 байта, точность
datetime (8 байт, точность до 3,33 миллисекунд);
smalldatetime (4 байта, точность

Тип данных UNIQUEIDENTIFIER используется для хранения глобальных уникальных идентификационных номеров.
Тип данных UNIQUEIDENTIFIER используется для хранения глобальных уникальных идентификационных номеров.

SQL_VARIANT -
Служит для хранения значений разных типов одновременно, таких как
SQL_VARIANT -
Служит для хранения значений разных типов одновременно, таких как

Логический тип данных - хранит значения вида true/false (единица/ноль).
В SQL
Логический тип данных - хранит значения вида true/false (единица/ноль).
В SQL

DATEDIFF ( datepart , startdate , enddate )─ возвращает интервал
DATEDIFF ( datepart , startdate , enddate )─ возвращает интервал
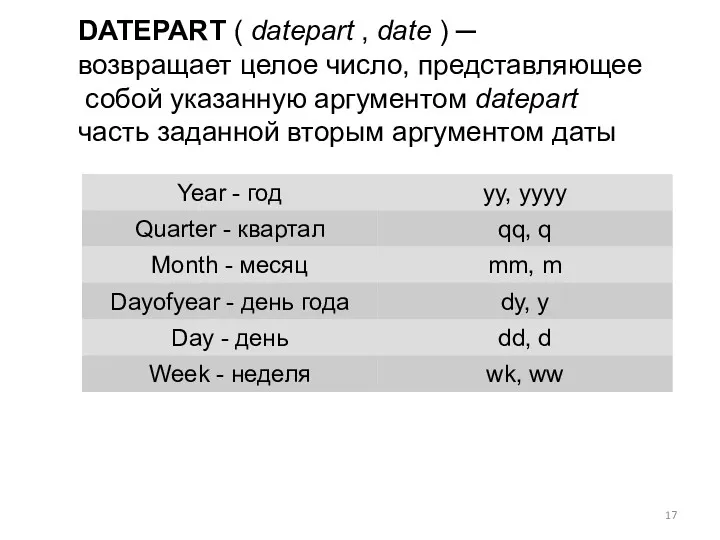
DATEPART ( datepart , date ) ─
возвращает целое число, представляющее
собой
DATEPART ( datepart , date ) ─
возвращает целое число, представляющее
собой

В ряде случаев функцию DATEPART можно заменить более простыми функциями.
DAY
В ряде случаев функцию DATEPART можно заменить более простыми функциями.
DAY


Пользовательские типы данных.
Могут использоваться при определении какого-либо специфического или часто
Пользовательские типы данных.
Могут использоваться при определении какого-либо специфического или часто

EXEC sp_addtype dt, DATETIME, 'NULL'
Удаление пользовательского типа данных происходит в
EXEC sp_addtype dt, DATETIME, 'NULL'
Удаление пользовательского типа данных происходит в

CREATE TYPE SSN
FROM varchar(10) NOT NULL ;
CREATE TYPE SSN
FROM varchar(10) NOT NULL ;

Преобразование типов
Для выполнения преобразований SQL Server содержит функции CONVERT и CAST,
Преобразование типов
Для выполнения преобразований SQL Server содержит функции CONVERT и CAST,

Пример:
SELECT ‘сегодня ‘ + CONVERT(VARCHAR(11),GETDATE())
CAST('1977.01.07‘ AS Datetime)
Пример:
SELECT ‘сегодня ‘ + CONVERT(VARCHAR(11),GETDATE())
CAST('1977.01.07‘ AS Datetime)

Оновные функции
– поиск подстроки
CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] )
- вырезка
Оновные функции
– поиск подстроки
CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] )
- вырезка

Временные таблицы
Временные таблицы похожи на обычные, однако они не
Временные таблицы
Временные таблицы похожи на обычные, однако они не

В SQL Server существуют два типа временных таблиц: локальные и
В SQL Server существуют два типа временных таблиц: локальные и

Создание ограничений
Создание ограничений

Декларативные ограничения при создании таблиц
При создании таблиц могут быть заданы
Декларативные ограничения при создании таблиц
При создании таблиц могут быть заданы

Например, на значение стипендии может быть наложено ограничение (стипендия должна
Например, на значение стипендии может быть наложено ограничение (стипендия должна

Возраст сотрудника должен быть
не менее 18 лет:
BIRTH_DAY DATE CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH_DAY)>=18)
Возраст сотрудника должен быть
не менее 18 лет:
BIRTH_DAY DATE CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH_DAY)>=18)

При создании ограничений необходимо учитывать следующее:
ограничение, определенное для одного поля может
При создании ограничений необходимо учитывать следующее:
ограничение, определенное для одного поля может

ограничения DEFAULT должны быть ограничениями на уровне поля;
ограничения CHECK на
ограничения DEFAULT должны быть ограничениями на уровне поля;
ограничения CHECK на

Пример ограничения на уровне таблицы
CREATE TABLE TestTable
( id int
Пример ограничения на уровне таблицы
CREATE TABLE TestTable
( id int

Ограничение целостности, включаемое в определение столбца, может быть эквивалентным образом выражено
Ограничение целостности, включаемое в определение столбца, может быть эквивалентным образом выражено

Часто для поля или группы полей требуется реализовать ограничение, связанное
Часто для поля или группы полей требуется реализовать ограничение, связанное

Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен
Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен

PRIMARY KEY(NOM_ZACH, PKOD)
PRIMARY KEY(NOM_ZACH, PKOD)

Ссылочная целостность
Ссылочная целостность
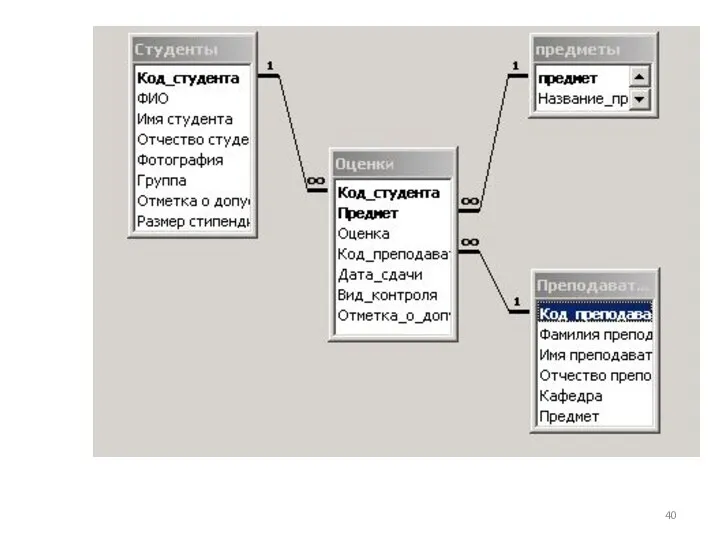
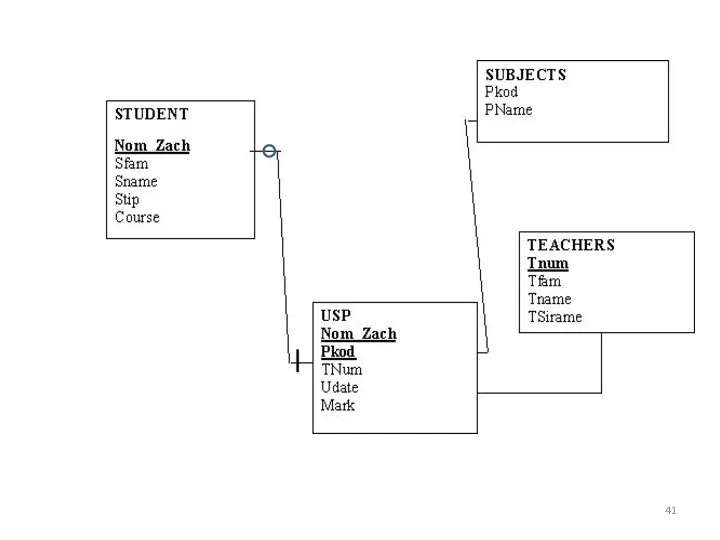

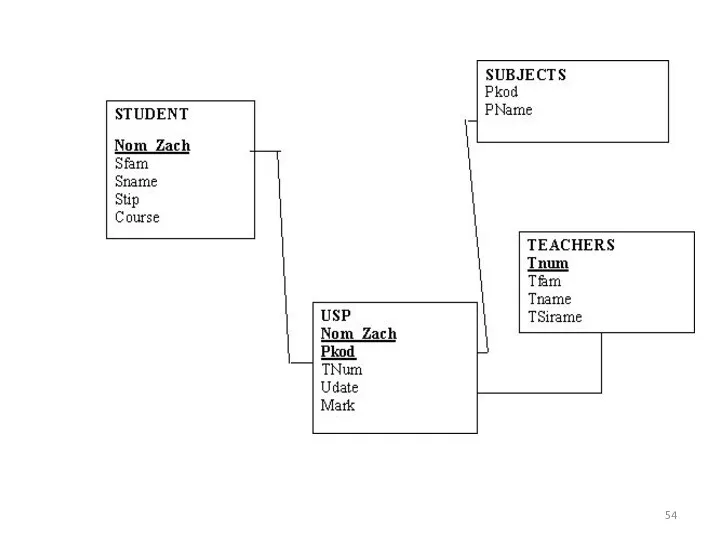
Таблица USP подчинена двум другим таблицам: SUBJECTS и STUDENTS. При
Таблица USP подчинена двум другим таблицам: SUBJECTS и STUDENTS. При

Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN
Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN

Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД
Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД

Создадим таблицу USP с полем NOM_ZACH, и PKOD определенными в качестве
Создадим таблицу USP с полем NOM_ZACH, и PKOD определенными в качестве

Используя ограничения FOREIGN KEY, можно не указывать список полей родительского
Используя ограничения FOREIGN KEY, можно не указывать список полей родительского

В соответствии со стандартом, изменение или удаление значений родительского ключа
В соответствии со стандартом, изменение или удаление значений родительского ключа
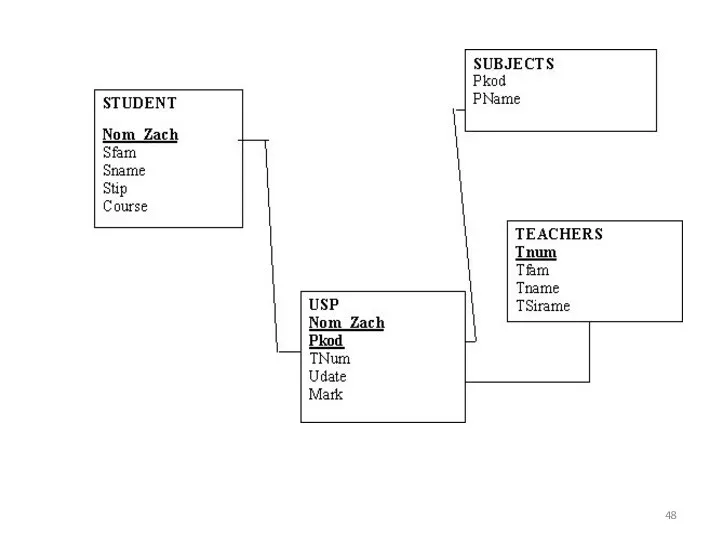

При необходимости изменить или удалить текущее ссылочное значение родительского ключа
При необходимости изменить или удалить текущее ссылочное значение родительского ключа

Итак, изменения в родительском ключе можно разделить на
ограниченные (NO ACTION),
Итак, изменения в родительском ключе можно разделить на
ограниченные (NO ACTION),

Предположим, что есть необходимость в изменении номера зачетной книжки, причем
Предположим, что есть необходимость в изменении номера зачетной книжки, причем

CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,

Если данные о студенте удаляются, удаление их должно быть выполнено
Если данные о студенте удаляются, удаление их должно быть выполнено

Изменение таблиц
При необходимости в уже созданную таблицу можно внести изменения, например,
Изменение таблиц
При необходимости в уже созданную таблицу можно внести изменения, например,

Новое поле станет последним по порядку в таблице. Допускается добавление
Новое поле станет последним по порядку в таблице. Допускается добавление

В таблицу могут быть добавлены и новые ограничения с помощью
В таблицу могут быть добавлены и новые ограничения с помощью

Примеры:
1. Для добавления ограничения, задающего значение по умолчанию:
ALTER TABLE USP
1. Для добавления ограничения, задающего значение по умолчанию:
ALTER TABLE USP

Для получения информации об ограничениях используется системная
процедура
sp_helpconstraint
Для получения информации об ограничениях используется системная
процедура
sp_helpconstraint

Удаление столбцов и ограничений
Из созданной таблицы можно удалить столбцы или
Удаление столбцов и ограничений
Из созданной таблицы можно удалить столбцы или

Разрешение и запрет ограничений
С помощью команды ALTER TABLE с предложениями
Разрешение и запрет ограничений
С помощью команды ALTER TABLE с предложениями

Модификация столбцов
Иногда при создании таблиц делают неверные предположения относительно типа
Модификация столбцов
Иногда при создании таблиц делают неверные предположения относительно типа

Удаление таблиц
Удаление таблиц выполняется с помощью команды DROP TABLE.
Удаление таблиц
Удаление таблиц выполняется с помощью команды DROP TABLE.

Создание индексов
Индекс - упорядоченный список полей или групп полей в
Создание индексов
Индекс - упорядоченный список полей или групп полей в

Когда создаётся индекс для поля, база данных запоминает порядок всех
Когда создаётся индекс для поля, база данных запоминает порядок всех
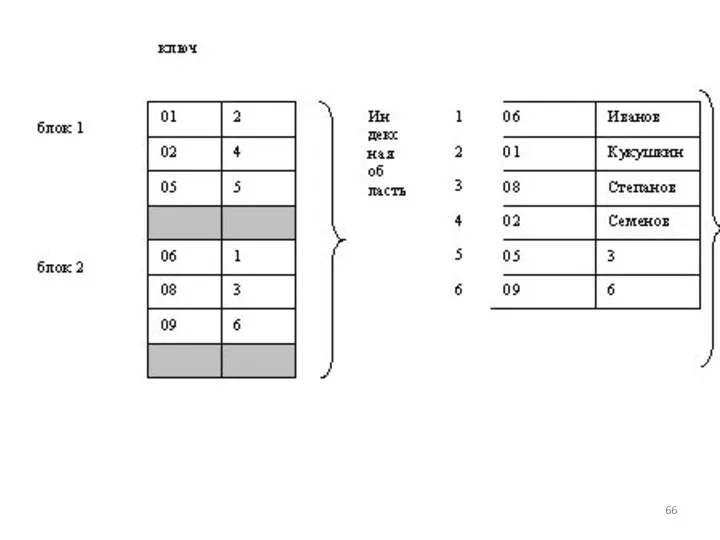

С помощью индексов осуществляется доступ к данным наиболее оптимальным способом.
С помощью индексов осуществляется доступ к данным наиболее оптимальным способом.
![Для создания индекса используется оператор CREATE INDEX. Синтаксис: CREATE INDEX имя_индекса ON таблица (поле[, …n])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/277597/slide-67.jpg)
Для создания индекса используется оператор CREATE INDEX.
Синтаксис:
CREATE INDEX имя_индекса ON таблица
Для создания индекса используется оператор CREATE INDEX.
Синтаксис:
CREATE INDEX имя_индекса ON таблица

Таблица, для которой создаётся индекс, должна уже существовать и содержать
Таблица, для которой создаётся индекс, должна уже существовать и содержать

Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое
Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое

Для удаления индекса используется команда
DROP INDEX имя индекса
Чтобы изменить индекс
Для удаления индекса используется команда
DROP INDEX имя индекса
Чтобы изменить индекс

Кластеризованный индекс
Использование опции Clustered index позволяет произвести так называемое кластерное
Кластеризованный индекс
Использование опции Clustered index позволяет произвести так называемое кластерное
 It’s a network. (Chapter 11)
It’s a network. (Chapter 11) Интернет-зависимость. Диагностика интернет-зависимости
Интернет-зависимость. Диагностика интернет-зависимости Пушкинский городской округ. Мобильное приложение
Пушкинский городской округ. Мобильное приложение Классификаторы технико-экономической и социальной информации
Классификаторы технико-экономической и социальной информации Программирование промышленных контроллеров ОВЕН ПЛК в пакете CoDeSys V2.3
Программирование промышленных контроллеров ОВЕН ПЛК в пакете CoDeSys V2.3 Циклические алгоритмические конструкции
Циклические алгоритмические конструкции Устройства памяти ЭВМ
Устройства памяти ЭВМ Основы безопасности жизнедеятельности в сети Интернет
Основы безопасности жизнедеятельности в сети Интернет Текстовые документы
Текстовые документы Основы работы в Adobe Photoshop и другие дизайн-программы
Основы работы в Adobe Photoshop и другие дизайн-программы 3. Java Persistence API. 5. Transaction Management
3. Java Persistence API. 5. Transaction Management Печатные работы сотрудников Уральского государственного медицинского университета. Выпуск 7
Печатные работы сотрудников Уральского государственного медицинского университета. Выпуск 7 Путешествие в страну Информатика
Путешествие в страну Информатика Печать документа
Печать документа Виртуальные машины. Удаленные рабочие столы. Специализированное программное обеспечение, применяемое в процессе тестирования
Виртуальные машины. Удаленные рабочие столы. Специализированное программное обеспечение, применяемое в процессе тестирования Жадные алгоритмы
Жадные алгоритмы Текстовый процессор Word 2003. (Тема 1.1)
Текстовый процессор Word 2003. (Тема 1.1) კომპიუტერის აპარატურული უზრუნველყოფა
კომპიუტერის აპარატურული უზრუნველყოფა Обзор алгоритмов и систем шифрования
Обзор алгоритмов и систем шифрования Создание блога
Создание блога Цифровая экономика и процессное управление предприятием. Лекция 5. Автоматизация предприятий
Цифровая экономика и процессное управление предприятием. Лекция 5. Автоматизация предприятий F# Succinct, Expressive, Functional
F# Succinct, Expressive, Functional Қазақстандағы медиа
Қазақстандағы медиа Исследование и разработка ИТ архитектуры для задач автоматизации процессов электронной коммерции
Исследование и разработка ИТ архитектуры для задач автоматизации процессов электронной коммерции ПЯВУ. Лекция 12. Элементы ООП
ПЯВУ. Лекция 12. Элементы ООП Криптографические методы защиты информации. Перспективные направления разработок
Криптографические методы защиты информации. Перспективные направления разработок Вкладені цикли. Покрокове введення та виведення даних. Лекція №8
Вкладені цикли. Покрокове введення та виведення даних. Лекція №8 Алгоритмы и контейнеры данных (C++)
Алгоритмы и контейнеры данных (C++)