- Структуры данных

Содержание
- 2. Структуры данных - это совокупность элементов данных и отношений между ними. При этом под элементами данных
- 3. Элемент структуры данных S:=(D,R), где S - структура данных, D – данные, R - отношения.
- 5. Структуры данных классифицируются: 1. По связанности данных в структуре - если данные в структуре связаны очень
- 6. СТАТИЧЕСКИЕ СТРУКТУРЫ Вектор (одномерный массив) - это чисто линейная упорядоченная структура, где отношение между ее элементами
- 7. Массив – структура, в которой элементами являются векторы (элементы которого тоже являются элементами массива)
- 8. Запись представляет из себя структуру данных последовательного типа, где элементы структуры расположены один за другим как
- 10. Элемент записи может включать в себя записи. В этом случае возникает сложная иерархическая структура данных.
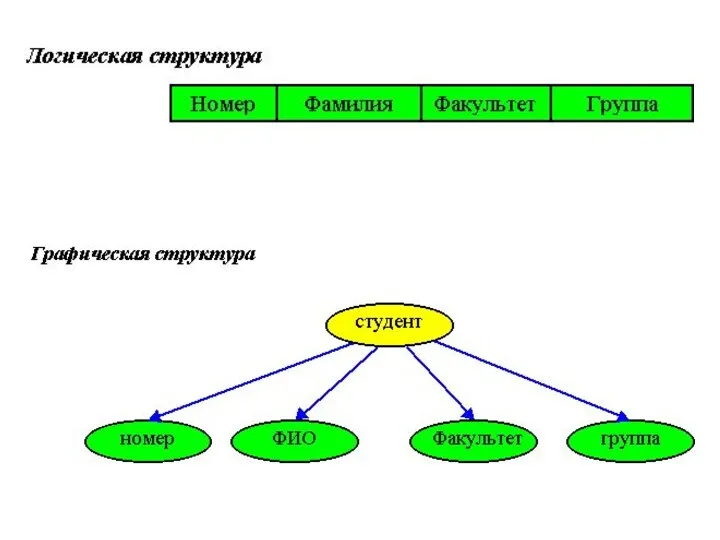
- 11. Логическая структура иерархической записи 1-ый уровень Студент = запись 2-ой уровень Номер 2-ой уровень Имя =
- 12. Основные операции над записями: Прочтение содержимого поля записи. Занесение информации в поле записи. Все операции, которые
- 13. Таблица - это конечный набор записей
- 14. Основные операции с таблицами: Поиск записи по заданному ключу. Занесение новой записи в таблицу.
- 15. Списки - это набор определенным образом связанных элементов данных, которые в общем случае могут быть разного
- 16. ПОЛУСТАТИЧЕСКИЕ СТРУКТУРЫ К полустатическим структурам данных относят, в принципе, динамические структуры (такие как стеки, очереди и
- 17. Структура вида LIFO (Last Input First Output - последним пришел, первым ушел ), при которой на
- 18. Операции, производимые над стеками: 1. Занесение элемента в стек. 2. Выборка элемента из стека. 3. Определение
- 19. Очередь – это структура вида FIFO (First In First Out - первым пришел, первым ушел). Очередь
- 20. Операции, производимые над очередью Операция insert (q,x) - помещает элемент х в конец очереди q. Операция
- 21. Пример работы c очередью при использовании стандартных процедур maxQ = 5 R = 0, F =
- 22. Убираем элементы A и B из очереди: Remove (q); Remove (q);
- 24. Убираем элементы С,D и E из очереди: Remove (q); Remove (q); Remove (q). Добавляем элементы D
- 25. Возникла абсурдная ситуация, при которой очередь является пустой (R
- 26. Одним из решений возникшей проблемы может быть модификация операции Remove (q) таким образом, что при удалении
- 27. Произведем вставку элементов A, B и C в очередь: Insert (q, A); Insert (q, B); Insert
- 28. Убираем элемент A из очереди: Remove (q)
- 29. Однако этот метод весьма непроизводителен. Каждое удаление требует перемещения всех оставшихся в очереди элементов. Кроме того,
- 30. Предположим, что очередь содержит три элемента - в позициях 3, 4 и 5 пятиэлементного массива. Хотя
- 31. Если теперь делается попытка поместить в очередь элемент G, то он будет записан в первую позицию
- 32. Одним из способов решения этой проблемы является введение соглашения, при котором значение F есть индекс элемента
- 33. Перед началом работы с кольцевой очередью в F и R устанавливается значение последнего индекса массива maxQ,
- 34. Основные операции с кольцевой очередью Вставка элемента q в очередь x Insert(q,x); Извлечение элемента из очереди
- 35. Переполнение очереди происходит в том случае, если весь массив уже занят элементами очереди, и при этом
- 36. Если произвести следующую вставку, то массив становится целиком заполненным, и попытка произвести еще одну вставку приводит
- 37. Одно из решений состоит в том, чтобы пожертвовать одним элементом массива и позволить очереди расти до
- 38. Дек Происходит от английского DEQ - Double Ended Queue (очередь с двумя концами). Дек можно рассматривать
- 39. Динамические структуры данных
- 40. Динамические структуры данных имеют две особенности: Заранее не определено количество элементов в структуре. Элементы динамических структур
- 41. P1 и P2 это указатели, содержащие адреса элементов, с которыми связаны соответствующие элементы структуры.
- 42. Связные списки С точки зрения логического представления различают линейные и нелинейные списки. К линейным спискам относятся
- 43. Односвязные списки Элемент односвязного списка содержит, как минимум, два поля: информационное поле (info) и поле указателя
- 44. Особенностью указателя является то, что он дает только адрес последующего элемента списка. Поле указателя последнего элемента
- 45. ТЕРМИНОЛОГИЯ p - указатель node(p) – узел, на который ссылается указатель p [при этом неважно в
- 46. Кольцевой односвязный список Кольцевой односвязный список получается из обычного односвязного списка путем присваивания указателю последнего элемента
- 47. Двусвязный список Двусвязный список характеризуется тем, что у любого элемента есть два указателя. Один указывает на
- 48. Фактически двусвязный список это два односвязных списка с одинаковыми элементами, записанные в противоположной последовательности.
- 49. Кольцевой двусвязный список Двусвязные списки получают следующим образом: в качестве значения поля R последнего элемента принимают
- 50. Простейшие операции над односвязными списками Вставка элемента в начало односвязного списка Удаление элемента из начала односвязного
- 51. Односвязный список, как самостоятельная структура данных Просмотр односвязного списка может производиться только последовательно, начиная с головы
- 52. Пример Необходимо вставить элемент X в существующий массив между 5-м и 6-м элементами.
- 53. Для проведения данной операции в массиве нужно сместить “вниз” все элементы, начиная с X6 - увеличить
- 54. Данная процедура в больших массивах может занимать значительное время. В противоположность этому, в связанном списке операция
- 55. Вставка и извлечение элементов из списка Сначала определяем элемент, после которого необходимо провести операцию вставки или
- 56. Примеры типичных операций над списками Задача 1 Требуется просмотреть список и удалить элементы, у которых информационные
- 57. Обозначим P - рабочий указатель; в начале процедуры P = Lst. Введем также указатель Q, который
- 58. Анимация решения задачи 1 Lst nil P Q 4 4 8 21 P Q P
- 59. Задача 2 Дан упорядоченный по возрастанию info - полей список. Необходимо вставить в этот список элемент
- 60. Анимация решения задачи 2 Lst nil P Q 4 9 8 21 X > info(P) =
- 61. Элементы заголовков в списках Для создания списка с заголовком в начало списка вводится дополнительный элемент, который
- 62. В заголовок списка часто помещают динамическую переменную, содержащую количество элементов в списке (не считая самого заголовка).
- 63. Если список пуст, то остается только заголовок списка. Удобно занести в информационное поле заголовка значение указателя
- 64. Нелинейные связанные структуры Двусвязный список может быть нелинейной структурой данных, если вторые указатели задают произвольный порядок
- 65. Можно выделить три отличительных признака нелинейной структуры: 1) Любой элемент структуры может ссылаться на любое число
- 66. Пример моделирования с помощью нелинейного списка Пусть имеется дискретная система, в графе состояния которой узлы -
- 67. Входной сигнал в систему это X. Реакцией на входной сигнал является выработка выходного сигнала Y и
- 68. Реализация графа в виде нелинейного списка
- 69. Рекурсивные структуры данных Рекурсивная структуры данных - структура данных, элементы которой являются такими же структурами данных
- 70. Деревья Дерево - нелинейная связанная структура данных. Дерево характеризуется следующими признаками: - дерево имеет один элемент,
- 71. Любой узел дерева может быть промежуточным либо терминальным (листом). На рисунке промежуточными являются элементы M1, M2;
- 72. Количество ветвей, растущих из узла дерева, называется степенью исхода узла (на рисунке для M1 степень исхода
- 73. Деревья могут классифицироваться по степени исхода : 1) если максимальная степень исхода равна m, то это
- 74. Представление деревьев Наиболее удобно деревья представлять в памяти ЭВМ в виде связанных списков. Элемент списка должен
- 75. Представление дерева в виде нелинейного списка
- 76. Бинарные деревья Согласно представлению деревьев в памяти ЭВМ каждый элемент бинарного дерева является записью, содержащей четыре
- 77. Формат элемента бинарного дерева
- 78. Упорядоченное бинарное дерево В упорядоченном бинарном дереве левый сын имеет ключ меньший, чем у отца, а
- 79. Получено идеально сбалансированное дерево - дерево, в котором левое и правое поддеревья имеют количество уровней, отличающихся
- 80. Сведение m-арного дерева к бинарному Неформальный алгоритм: 1.В любом узле дерева отсекаются все ветви, кроме крайней
- 81. Графическое пояснение алгоритма
- 82. Реализация полученного бинарного дерева с помощью нелинейного двусвязного списка
- 83. Основные операции с деревьями 1. Обход дерева. 2. Удаление поддерева. 3. Вставка поддерева. Для выполнения обхода
- 84. В зависимости от того, в какой последовательности выполняются эти три процедуры, различают три вида обхода. 1.Обход
- 85. A B C D E F G A-B-C-E-D-F-G – сверху вниз C-B-D-E-F-A-G – слева направо C-D-F-E-B-G-A
- 86. В зависимости от того, после какого по счету захода в узел он подвергается обработке, реализуется один
- 87. Операция удаления поддерева Необходимо указать узел, к которому подсоединяется удаляемое поддерево и указатель корня этого поддерева.
- 88. Операция вставки поддерева Необходимо знать адрес корня вставляемого поддерева и узел, к которому подвешивается поддерево. Установить
- 89. Создание дерева бинарного поиска Пусть заданы элементы с ключами: 14, 18, 6, 21, 1, 13, 15.
- 90. 14 18 tree q p v p 14, 18 К алгоритму построения дерева
- 91. К алгоритму построения дерева
- 92. Рекурсивные алгоритмы обхода (прохождения) бинарных деревьев 1. Сверху вниз А, В, С. 2. Слева направо или
- 94. Скачать презентацию

Структуры данных - это совокупность элементов данных и отношений между ними.
Структуры данных - это совокупность элементов данных и отношений между ними.
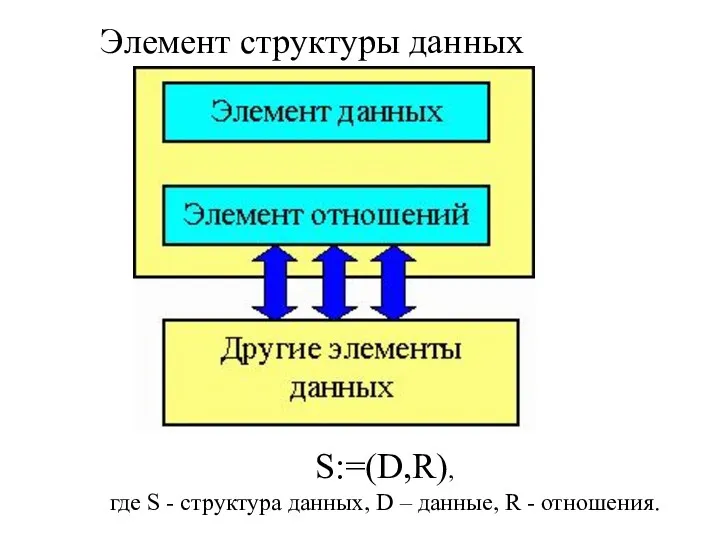
Элемент структуры данных
S:=(D,R),
где S - структура данных, D – данные,
Элемент структуры данных
S:=(D,R),
где S - структура данных, D – данные,

Структуры данных классифицируются:
1. По связанности данных в структуре
- если
Структуры данных классифицируются:
1. По связанности данных в структуре
- если

СТАТИЧЕСКИЕ СТРУКТУРЫ
Вектор (одномерный массив) - это чисто линейная упорядоченная структура, где
СТАТИЧЕСКИЕ СТРУКТУРЫ
Вектор (одномерный массив) - это чисто линейная упорядоченная структура, где

Массив – структура, в которой элементами являются векторы
(элементы которого тоже являются
Массив – структура, в которой элементами являются векторы
(элементы которого тоже являются

Запись представляет из себя структуру данных последовательного типа, где элементы структуры
Запись представляет из себя структуру данных последовательного типа, где элементы структуры
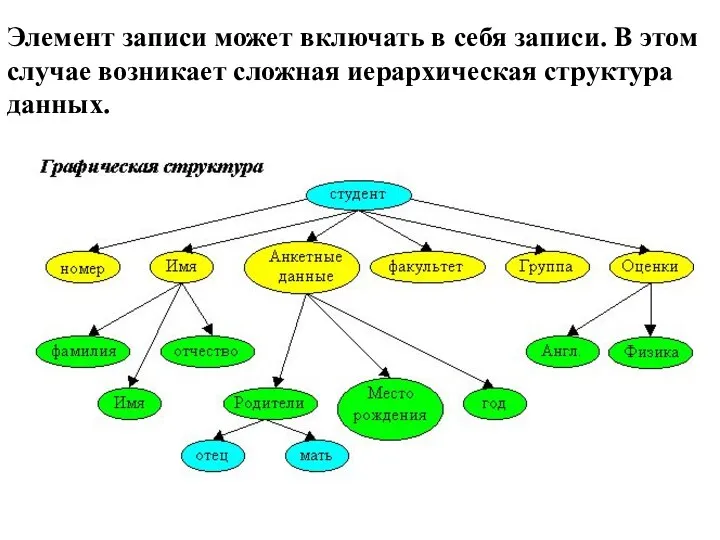
Элемент записи может включать в себя записи. В этом случае возникает
Элемент записи может включать в себя записи. В этом случае возникает

Логическая структура иерархической записи
1-ый уровень Студент = запись
2-ой уровень Номер
2-ой уровень
Логическая структура иерархической записи
1-ый уровень Студент = запись
2-ой уровень Номер
2-ой уровень

Основные операции над записями:
Прочтение содержимого поля записи.
Занесение информации в
Основные операции над записями:
Прочтение содержимого поля записи.
Занесение информации в
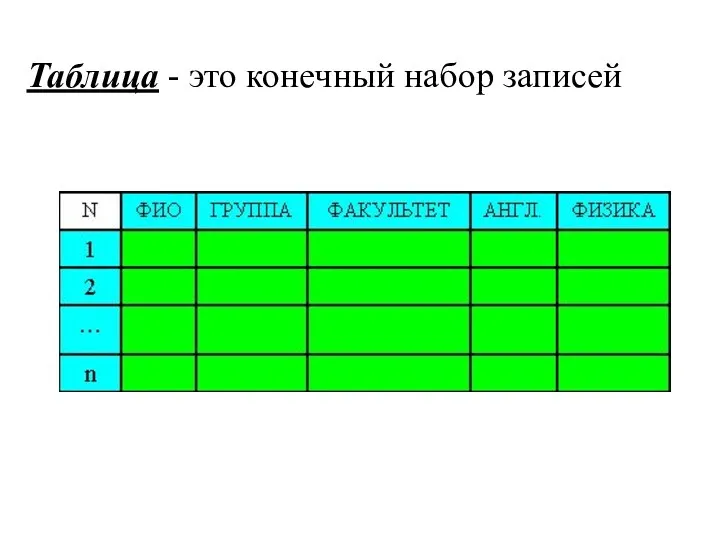
Таблица - это конечный набор записей
Таблица - это конечный набор записей

Основные операции с таблицами:
Поиск записи по заданному ключу.
Занесение
Основные операции с таблицами:
Поиск записи по заданному ключу.
Занесение

Списки - это набор определенным образом связанных элементов данных, которые в
Списки - это набор определенным образом связанных элементов данных, которые в

ПОЛУСТАТИЧЕСКИЕ СТРУКТУРЫ
К полустатическим структурам данных относят, в принципе, динамические структуры (такие
ПОЛУСТАТИЧЕСКИЕ СТРУКТУРЫ
К полустатическим структурам данных относят, в принципе, динамические структуры (такие
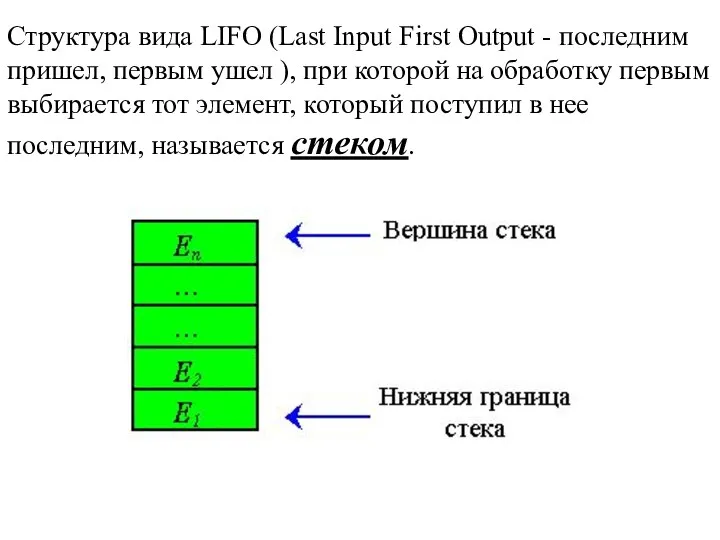
Структура вида LIFO (Last Input First Output - последним пришел, первым
Структура вида LIFO (Last Input First Output - последним пришел, первым

Операции, производимые над стеками:
1. Занесение элемента в стек.
2. Выборка элемента из
Операции, производимые над стеками:
1. Занесение элемента в стек.
2. Выборка элемента из

Очередь – это структура вида FIFO (First In First Out -
Очередь – это структура вида FIFO (First In First Out -

Операции, производимые над очередью
Операция insert (q,x) - помещает элемент х в
Операции, производимые над очередью
Операция insert (q,x) - помещает элемент х в

Пример работы c очередью при использовании стандартных процедур
maxQ = 5
R =
Пример работы c очередью при использовании стандартных процедур
maxQ = 5
R =
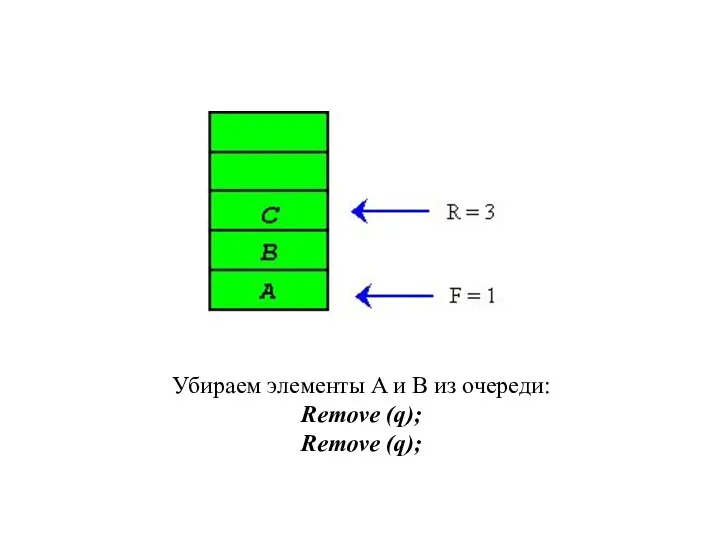
Убираем элементы A и B из очереди:
Remove (q);
Remove (q);
Убираем элементы A и B из очереди:
Remove (q);
Remove (q);
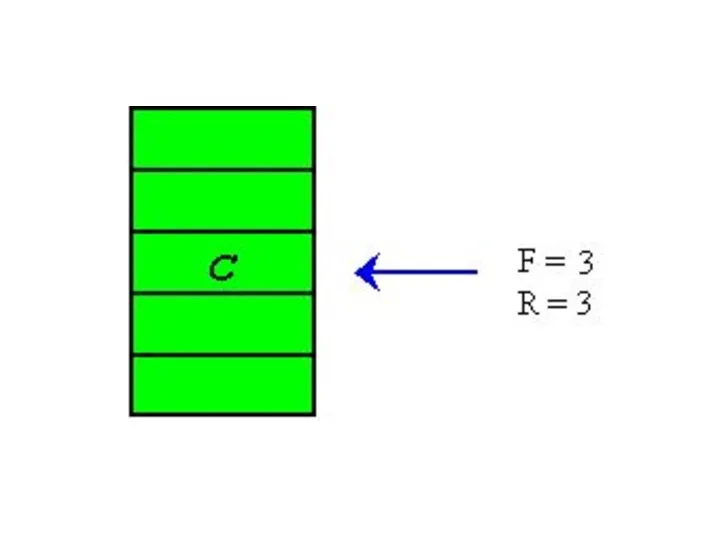
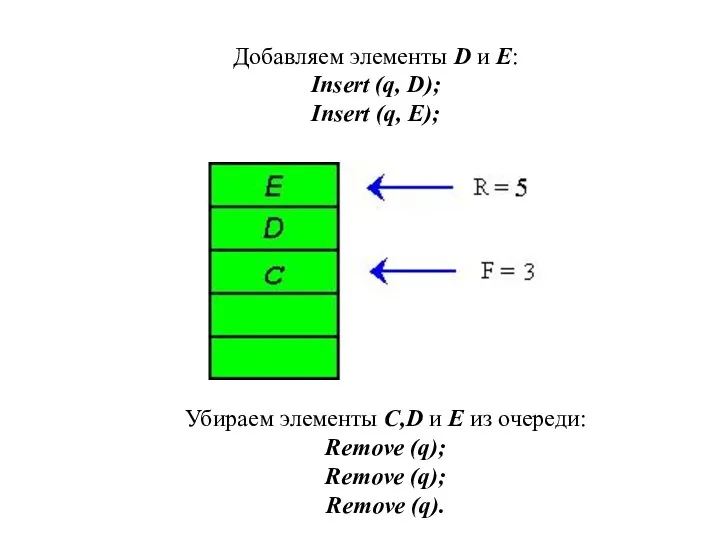
Убираем элементы С,D и E из очереди:
Remove (q);
Remove (q);
Remove (q).
Добавляем элементы
Убираем элементы С,D и E из очереди:
Remove (q);
Remove (q);
Remove (q).
Добавляем элементы

Возникла абсурдная ситуация, при которой очередь является пустой (R < F),
Возникла абсурдная ситуация, при которой очередь является пустой (R < F),
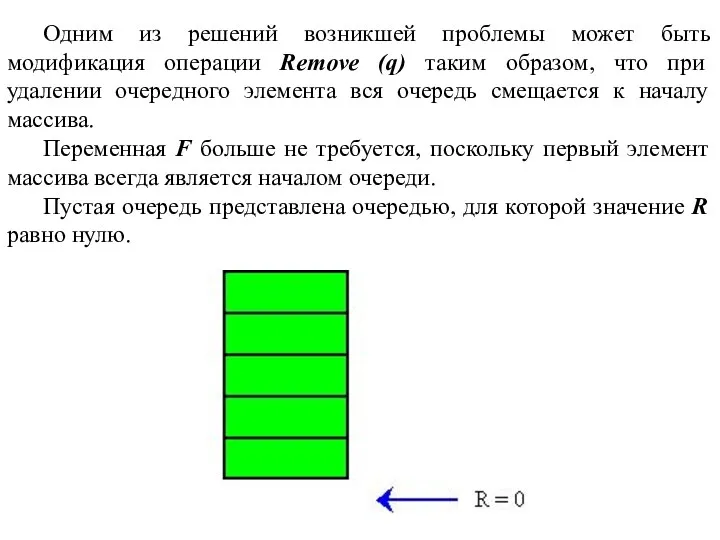
Одним из решений возникшей проблемы может быть модификация операции Remove (q)
Одним из решений возникшей проблемы может быть модификация операции Remove (q)
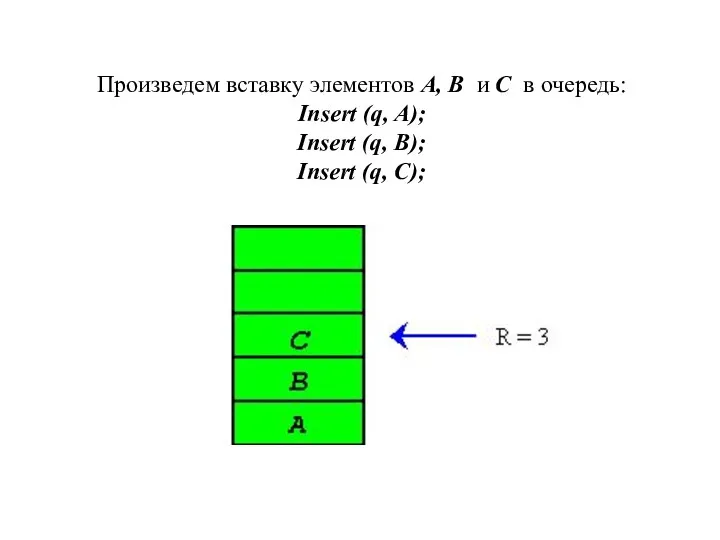
Произведем вставку элементов A, B и C в очередь:
Insert (q, A);
Insert
Произведем вставку элементов A, B и C в очередь:
Insert (q, A);
Insert
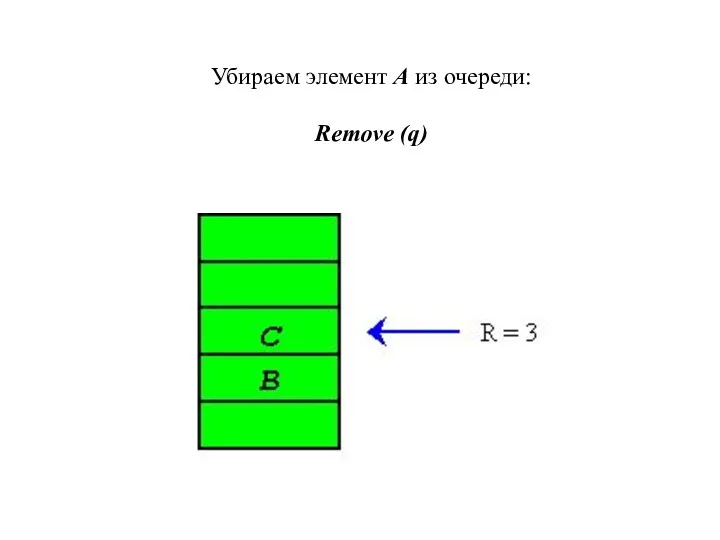
Убираем элемент A из очереди:
Remove (q)
Убираем элемент A из очереди:
Remove (q)

Однако этот метод весьма непроизводителен. Каждое удаление требует перемещения всех оставшихся
Однако этот метод весьма непроизводителен. Каждое удаление требует перемещения всех оставшихся
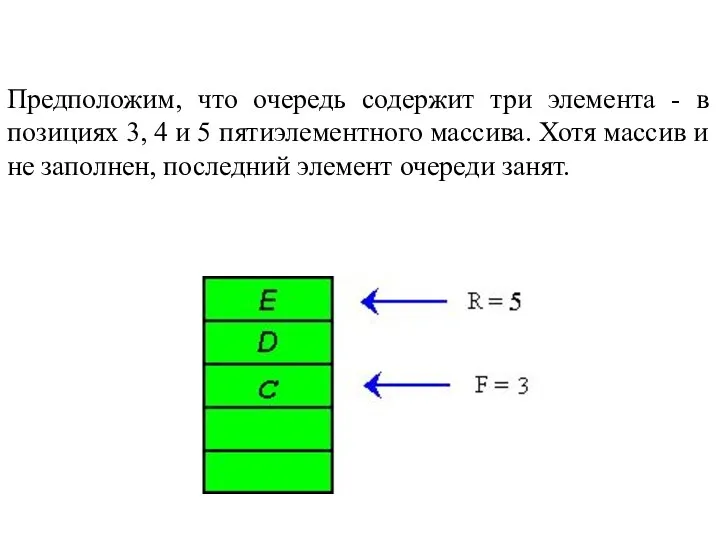
Предположим, что очередь содержит три элемента - в позициях 3, 4
Предположим, что очередь содержит три элемента - в позициях 3, 4
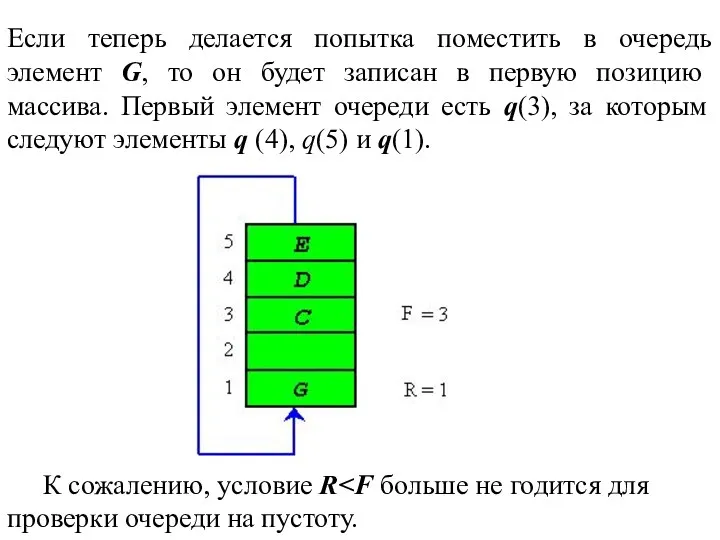
Если теперь делается попытка поместить в очередь элемент G, то он
Если теперь делается попытка поместить в очередь элемент G, то он

Одним из способов решения этой проблемы является введение соглашения, при котором
Одним из способов решения этой проблемы является введение соглашения, при котором

Перед началом работы с кольцевой очередью в F и R устанавливается
Перед началом работы с кольцевой очередью в F и R устанавливается

Основные операции с кольцевой очередью
Вставка элемента q в очередь x
Insert(q,x);
Основные операции с кольцевой очередью
Вставка элемента q в очередь x
Insert(q,x);
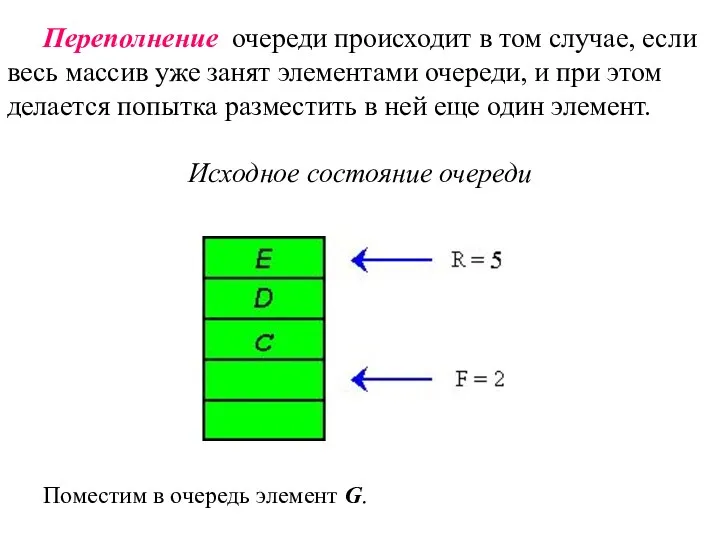
Переполнение очереди происходит в том случае, если весь массив уже занят
Переполнение очереди происходит в том случае, если весь массив уже занят
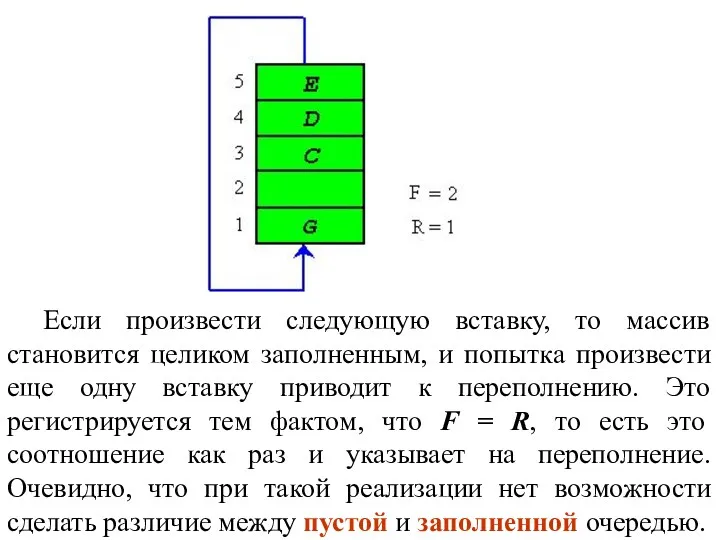
Если произвести следующую вставку, то массив становится целиком заполненным, и попытка
Если произвести следующую вставку, то массив становится целиком заполненным, и попытка

Одно из решений состоит в том, чтобы пожертвовать одним элементом массива
Одно из решений состоит в том, чтобы пожертвовать одним элементом массива
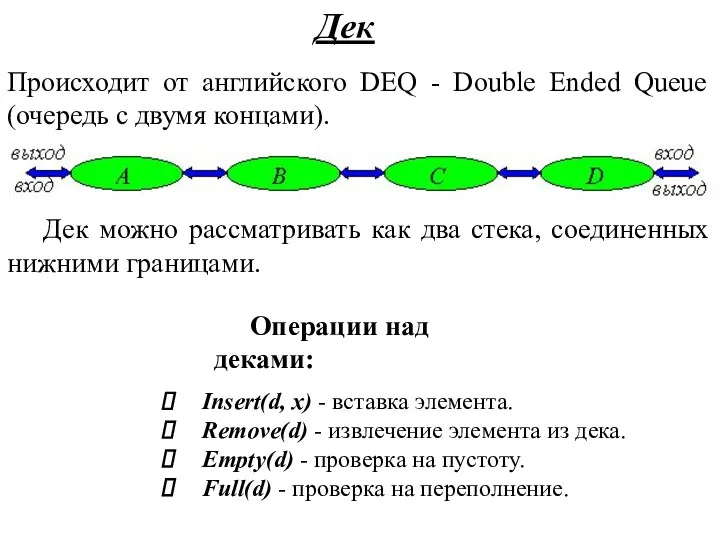
Дек
Происходит от английского DEQ - Double Ended Queue (очередь с
Дек
Происходит от английского DEQ - Double Ended Queue (очередь с

Динамические
структуры данных
Динамические
структуры данных

Динамические структуры данных имеют две особенности:
Заранее не определено количество
Динамические структуры данных имеют две особенности:
Заранее не определено количество
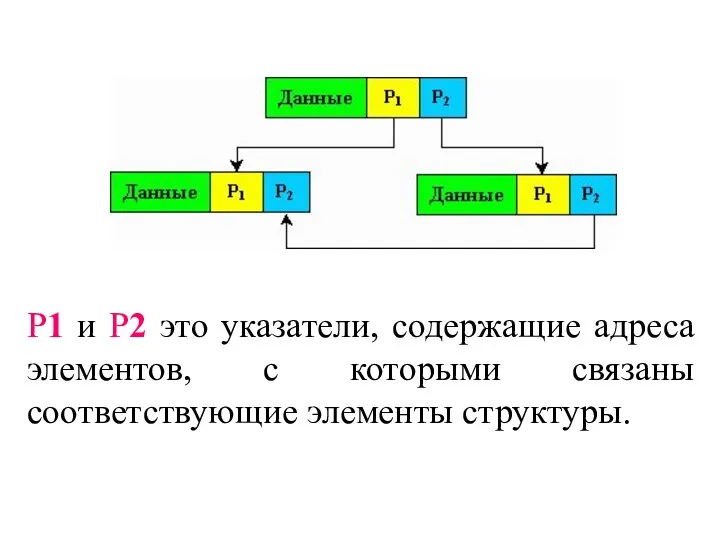
P1 и P2 это указатели, содержащие адреса элементов, с которыми связаны
P1 и P2 это указатели, содержащие адреса элементов, с которыми связаны

Связные списки
С точки зрения логического представления различают линейные и нелинейные
Связные списки
С точки зрения логического представления различают линейные и нелинейные
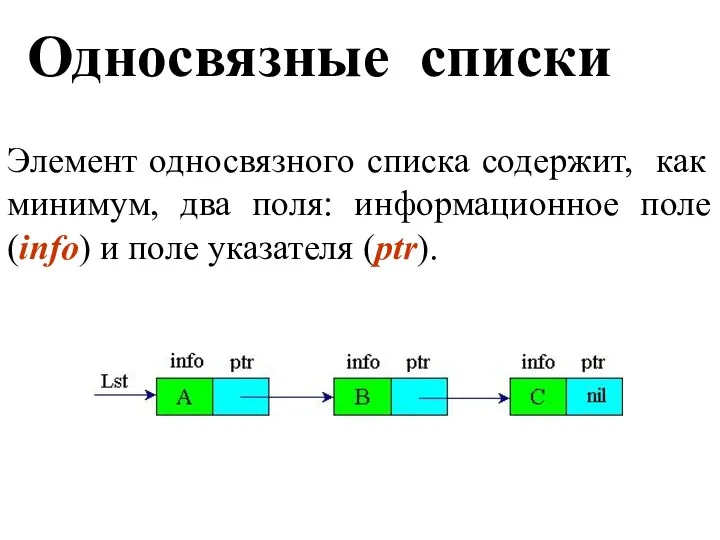
Односвязные списки
Элемент односвязного списка содержит, как минимум, два поля: информационное
Односвязные списки
Элемент односвязного списка содержит, как минимум, два поля: информационное

Особенностью указателя является то, что он дает только адрес последующего элемента
Особенностью указателя является то, что он дает только адрес последующего элемента

ТЕРМИНОЛОГИЯ
p - указатель
node(p) – узел, на который ссылается указатель p [при
ТЕРМИНОЛОГИЯ
p - указатель
node(p) – узел, на который ссылается указатель p [при
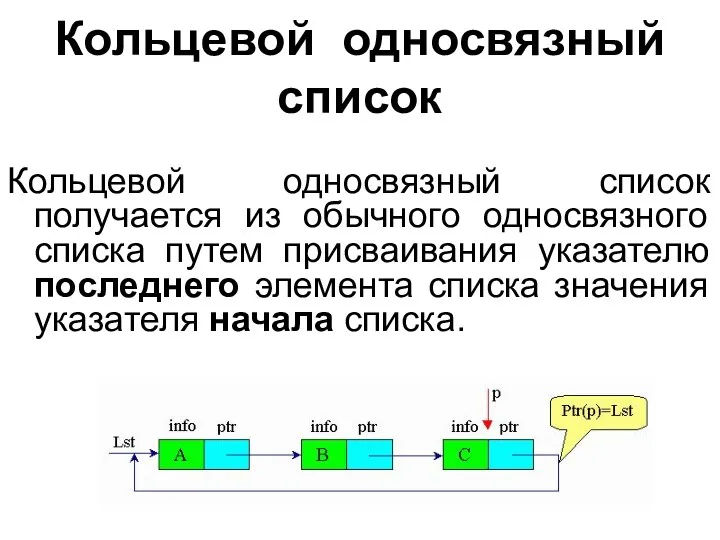
Кольцевой односвязный список
Кольцевой односвязный список получается из обычного односвязного списка
Кольцевой односвязный список
Кольцевой односвязный список получается из обычного односвязного списка

Двусвязный список
Двусвязный список характеризуется тем, что у любого элемента есть
Двусвязный список
Двусвязный список характеризуется тем, что у любого элемента есть
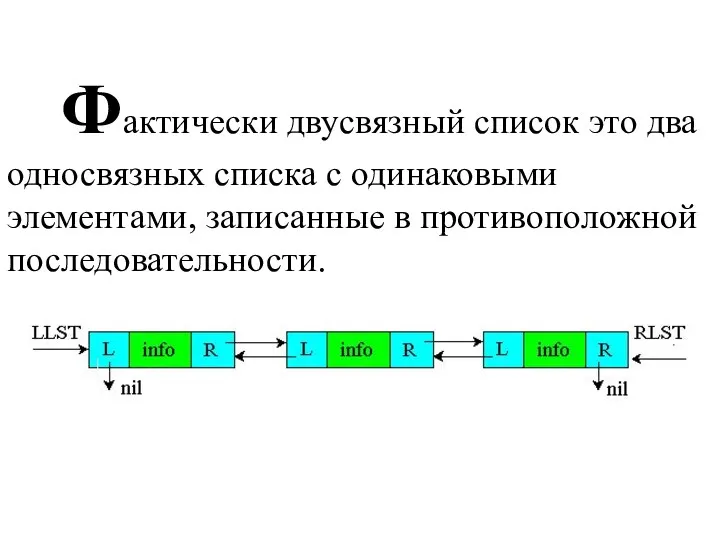
Фактически двусвязный список это два односвязных списка с одинаковыми элементами,
Фактически двусвязный список это два односвязных списка с одинаковыми элементами,
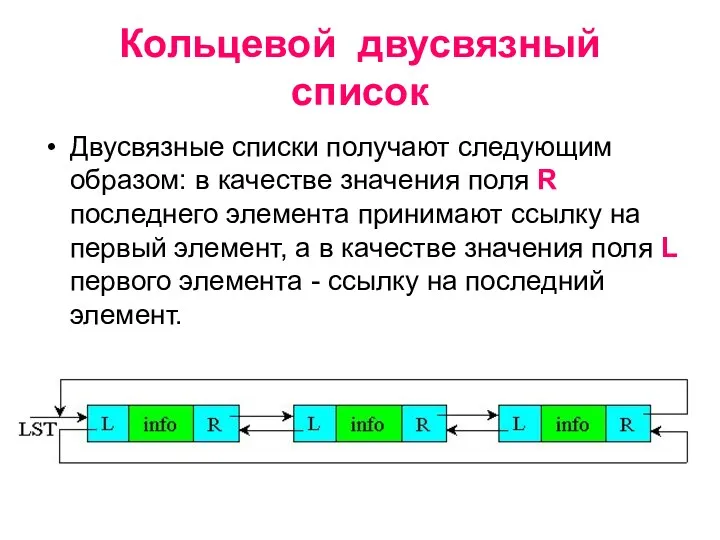
Кольцевой двусвязный список
Двусвязные списки получают следующим образом: в качестве значения
Кольцевой двусвязный список
Двусвязные списки получают следующим образом: в качестве значения

Простейшие операции
над односвязными списками
Вставка элемента в начало односвязного списка
Удаление
Простейшие операции
над односвязными списками
Вставка элемента в начало односвязного списка
Удаление

Односвязный список,
как самостоятельная структура данных
Просмотр односвязного списка может производиться
Односвязный список,
как самостоятельная структура данных
Просмотр односвязного списка может производиться
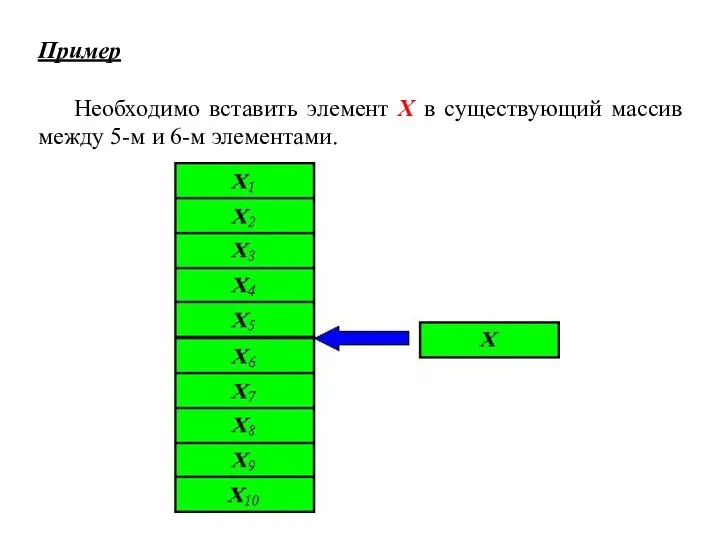
Пример
Необходимо вставить элемент X в существующий массив между 5-м и
Пример
Необходимо вставить элемент X в существующий массив между 5-м и
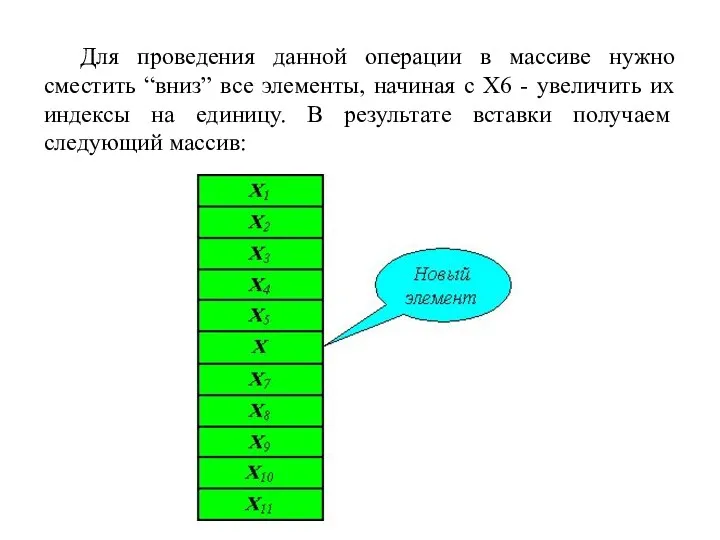
Для проведения данной операции в массиве нужно сместить “вниз” все элементы,
Для проведения данной операции в массиве нужно сместить “вниз” все элементы,

Данная процедура в больших массивах может занимать значительное время.
В противоположность
Данная процедура в больших массивах может занимать значительное время.
В противоположность
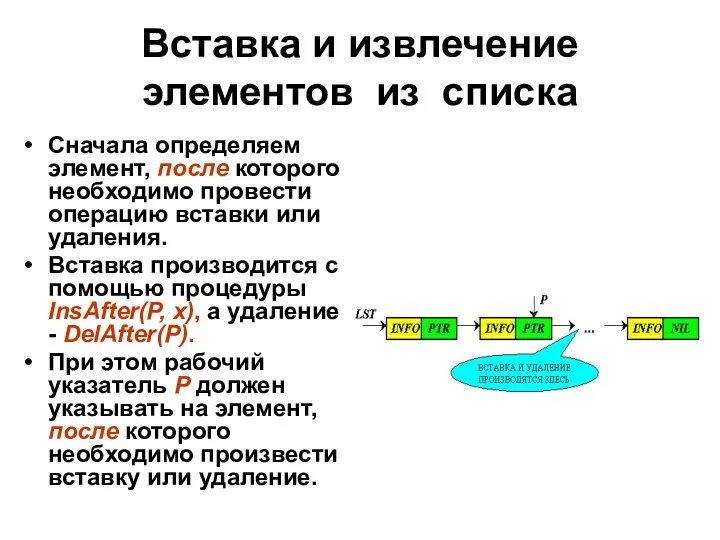
Вставка и извлечение элементов из списка
Сначала определяем элемент, после которого
Вставка и извлечение элементов из списка
Сначала определяем элемент, после которого

Примеры типичных операций над списками
Задача 1
Требуется просмотреть список и удалить
Примеры типичных операций над списками
Задача 1
Требуется просмотреть список и удалить

Обозначим P - рабочий указатель; в начале процедуры P = Lst.
Обозначим P - рабочий указатель; в начале процедуры P = Lst.
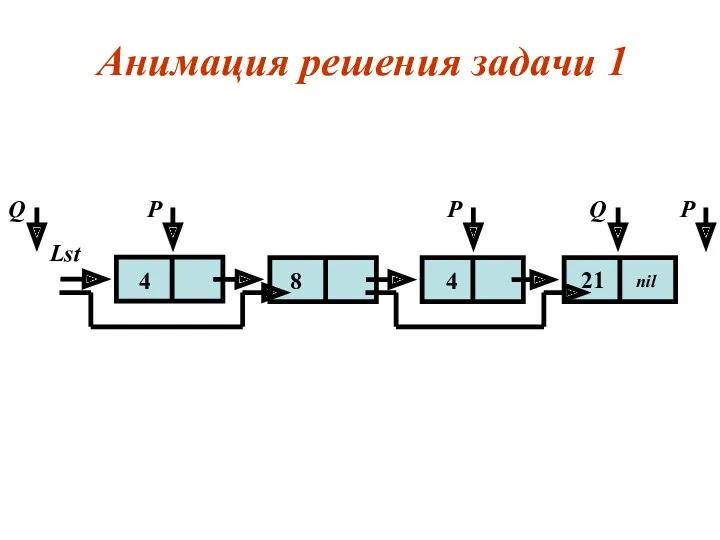
Анимация решения задачи 1
Lst
nil
P
Q
4
4
8
21
P
Q
P
Анимация решения задачи 1
Lst
nil
P
Q
4
4
8
21
P
Q
P

Задача 2
Дан упорядоченный по возрастанию info - полей список. Необходимо вставить
Задача 2
Дан упорядоченный по возрастанию info - полей список. Необходимо вставить
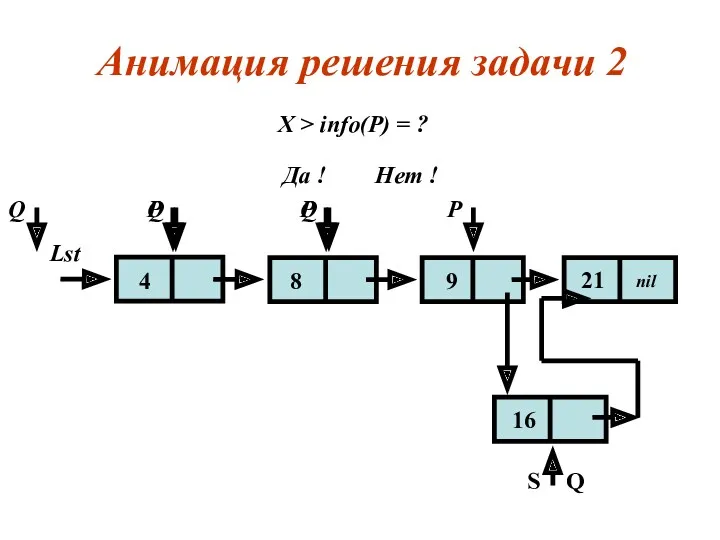
Анимация решения задачи 2
Lst
nil
P
Q
4
9
8
21
X > info(P) = ?
Да !
Q
P
Q
P
Нет !
16
S
Q
Анимация решения задачи 2
Lst
nil
P
Q
4
9
8
21
X > info(P) = ?
Да !
Q
P
Q
P
Нет !
16
S
Q

Элементы заголовков
в списках
Для создания списка с заголовком в начало
Элементы заголовков
в списках
Для создания списка с заголовком в начало
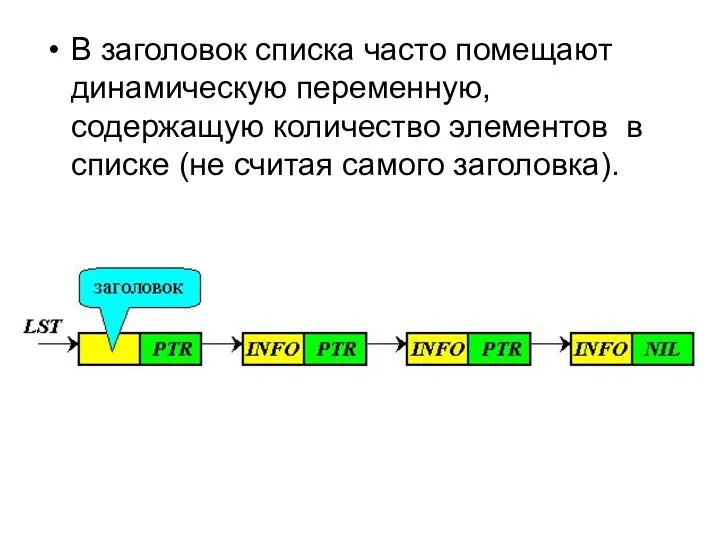
В заголовок списка часто помещают динамическую переменную, содержащую количество элементов в
В заголовок списка часто помещают динамическую переменную, содержащую количество элементов в

Если список пуст, то остается только заголовок списка.
Удобно занести в
Если список пуст, то остается только заголовок списка.
Удобно занести в
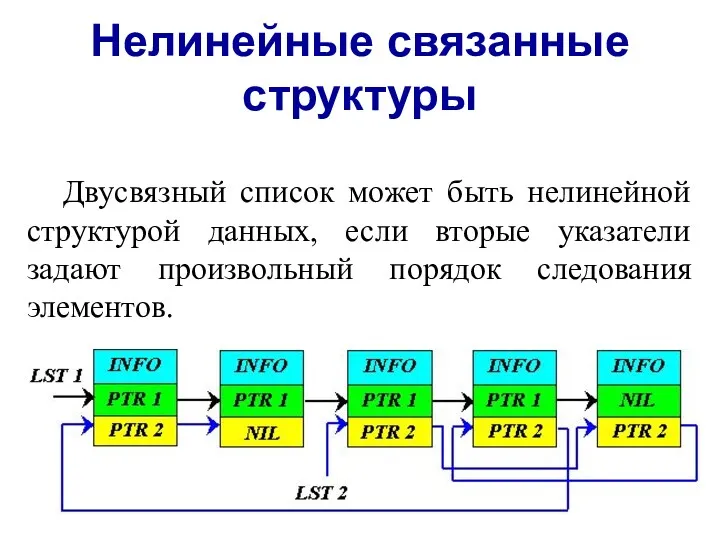
Нелинейные связанные структуры
Двусвязный список может быть нелинейной структурой данных, если
Нелинейные связанные структуры
Двусвязный список может быть нелинейной структурой данных, если

Можно выделить три отличительных признака нелинейной структуры:
1) Любой элемент структуры
Можно выделить три отличительных признака нелинейной структуры:
1) Любой элемент структуры
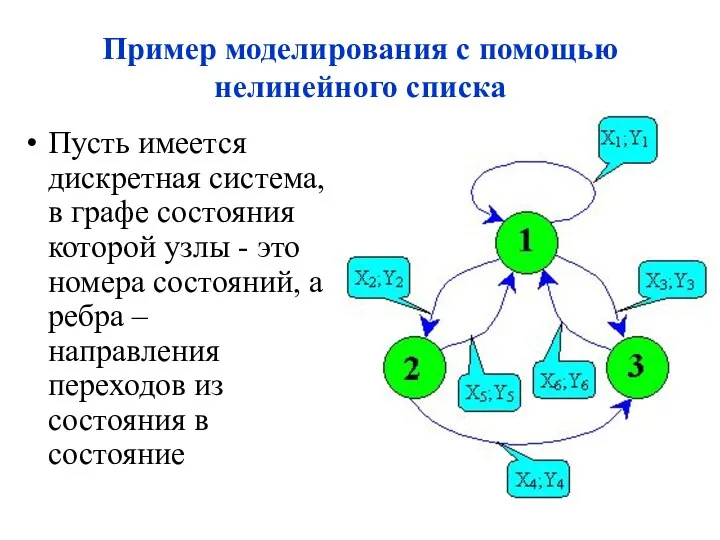
Пример моделирования с помощью нелинейного списка
Пусть имеется дискретная система, в графе
Пример моделирования с помощью нелинейного списка
Пусть имеется дискретная система, в графе

Входной сигнал в систему это X.
Реакцией на входной сигнал является
Входной сигнал в систему это X.
Реакцией на входной сигнал является
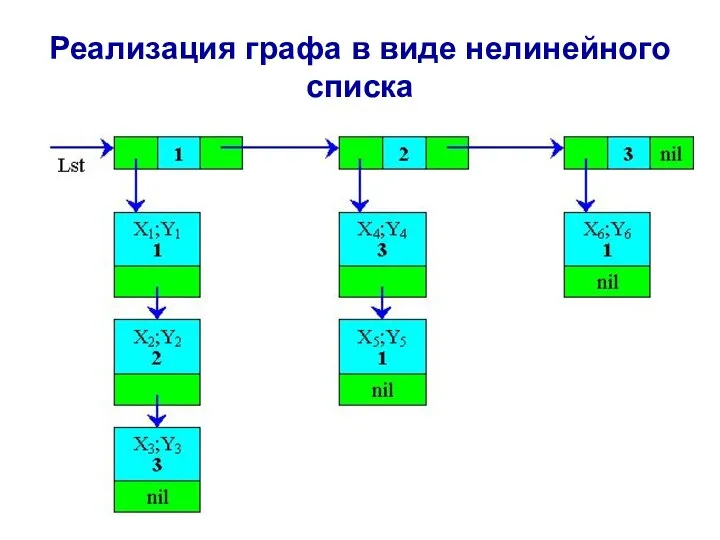
Реализация графа в виде нелинейного списка
Реализация графа в виде нелинейного списка
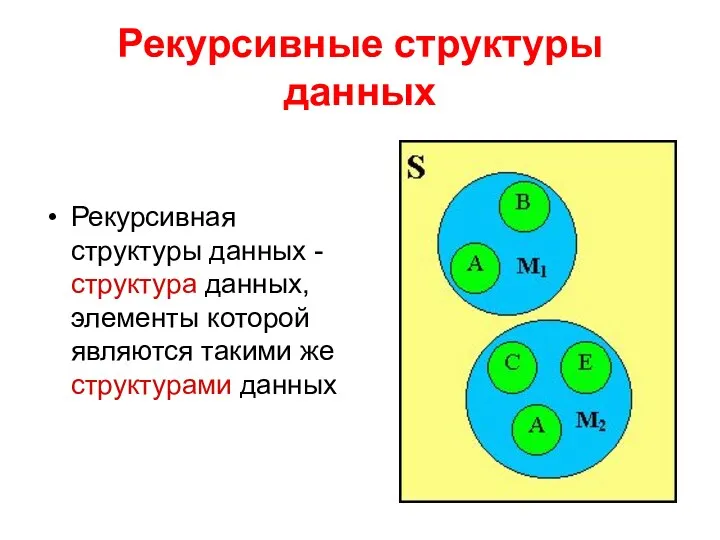
Рекурсивные структуры данных
Рекурсивная структуры данных - структура данных, элементы которой
Рекурсивные структуры данных
Рекурсивная структуры данных - структура данных, элементы которой
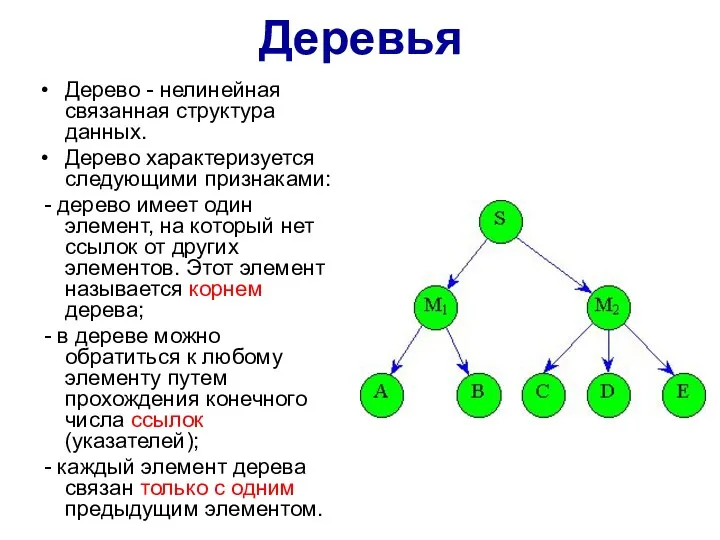
Деревья
Дерево - нелинейная связанная структура данных.
Дерево характеризуется следующими признаками:
-
Деревья
Дерево - нелинейная связанная структура данных.
Дерево характеризуется следующими признаками:
-
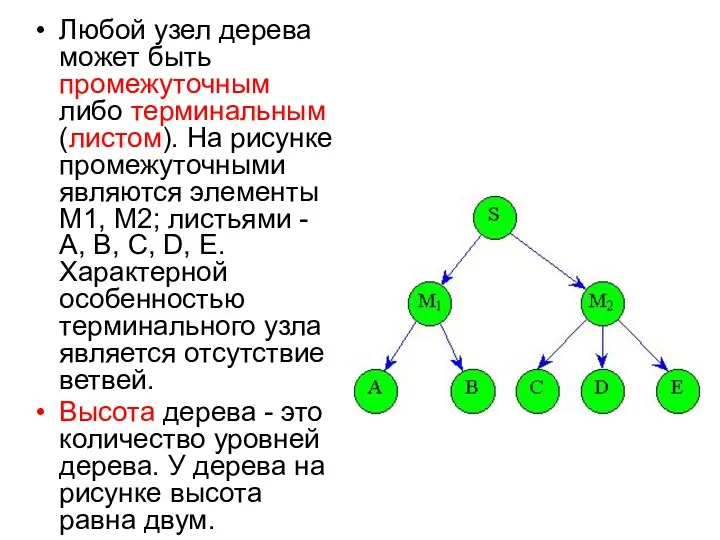
Любой узел дерева может быть промежуточным либо терминальным (листом). На рисунке
Любой узел дерева может быть промежуточным либо терминальным (листом). На рисунке
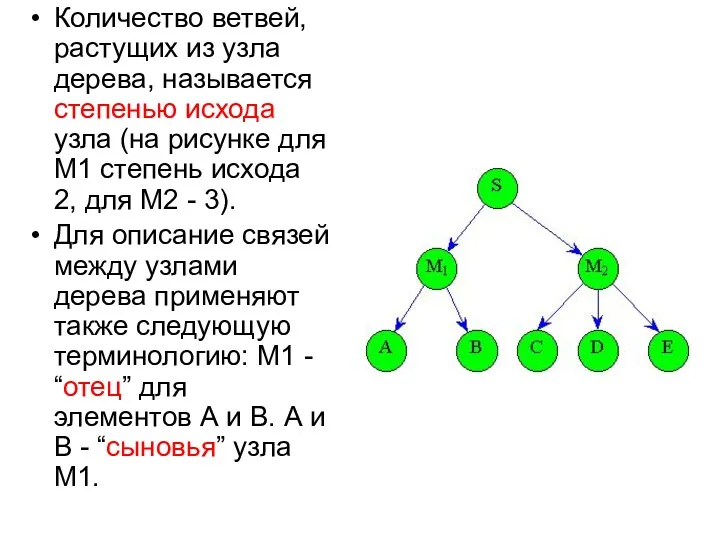
Количество ветвей, растущих из узла дерева, называется степенью исхода узла (на
Количество ветвей, растущих из узла дерева, называется степенью исхода узла (на

Деревья могут классифицироваться по степени исхода :
1) если максимальная степень исхода
Деревья могут классифицироваться по степени исхода :
1) если максимальная степень исхода

Представление деревьев
Наиболее удобно деревья представлять в памяти ЭВМ в виде
Представление деревьев
Наиболее удобно деревья представлять в памяти ЭВМ в виде
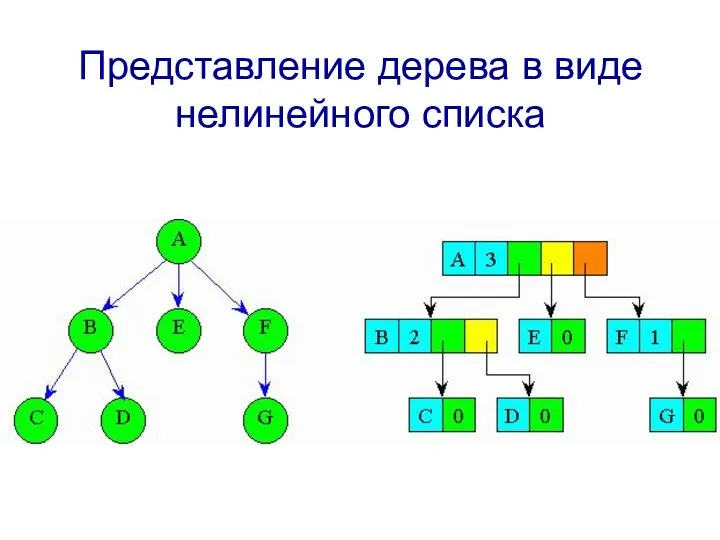
Представление дерева в виде нелинейного списка
Представление дерева в виде нелинейного списка

Бинарные деревья
Согласно представлению деревьев в памяти ЭВМ каждый элемент бинарного
Бинарные деревья
Согласно представлению деревьев в памяти ЭВМ каждый элемент бинарного
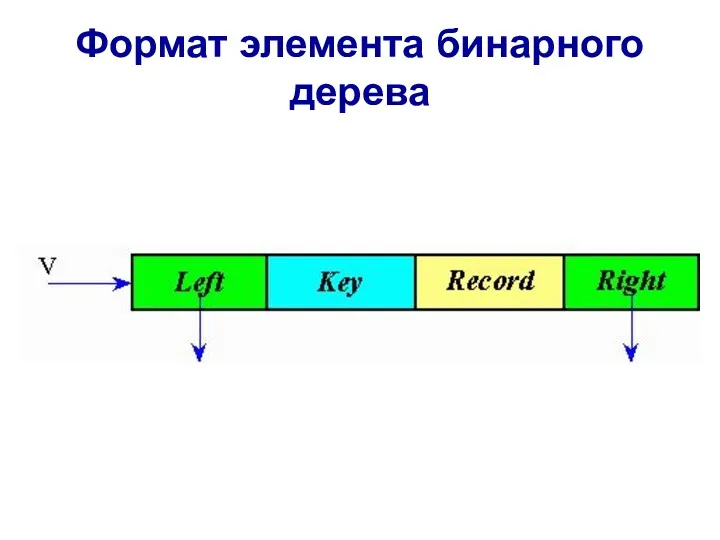
Формат элемента бинарного дерева
Формат элемента бинарного дерева

Упорядоченное бинарное дерево
В упорядоченном бинарном дереве левый сын имеет ключ меньший,
Упорядоченное бинарное дерево
В упорядоченном бинарном дереве левый сын имеет ключ меньший,
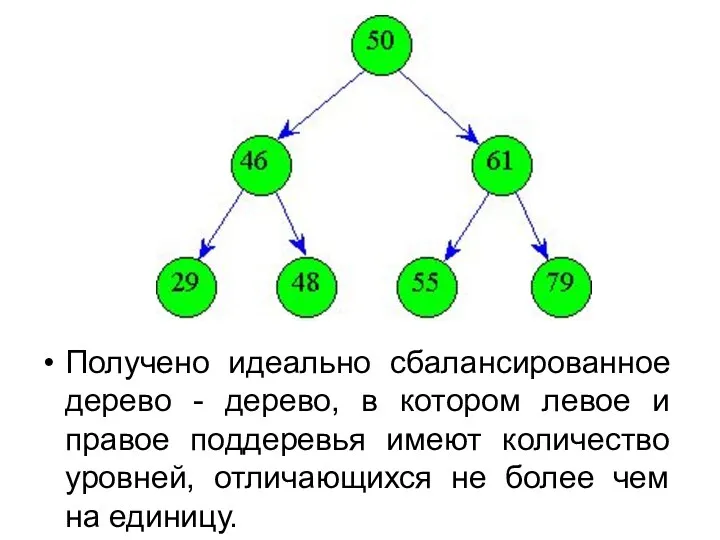
Получено идеально сбалансированное дерево - дерево, в котором левое и правое
Получено идеально сбалансированное дерево - дерево, в котором левое и правое

Сведение m-арного дерева к бинарному
Неформальный алгоритм:
1.В любом узле дерева отсекаются
Сведение m-арного дерева к бинарному
Неформальный алгоритм:
1.В любом узле дерева отсекаются
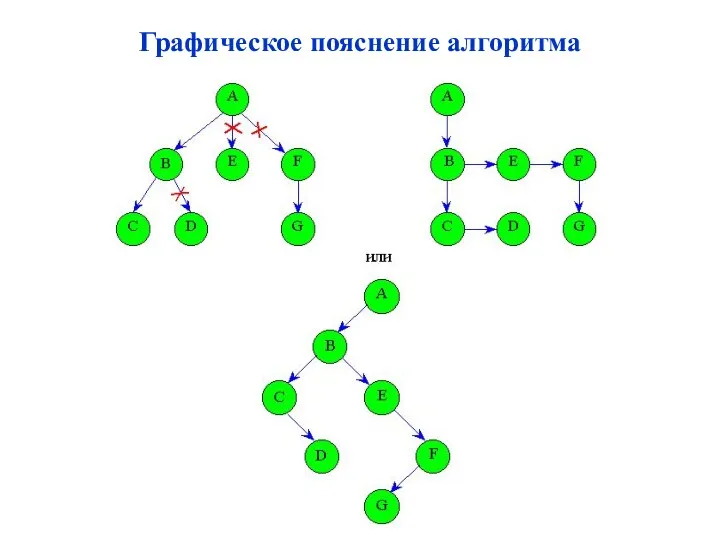
Графическое пояснение алгоритма
Графическое пояснение алгоритма
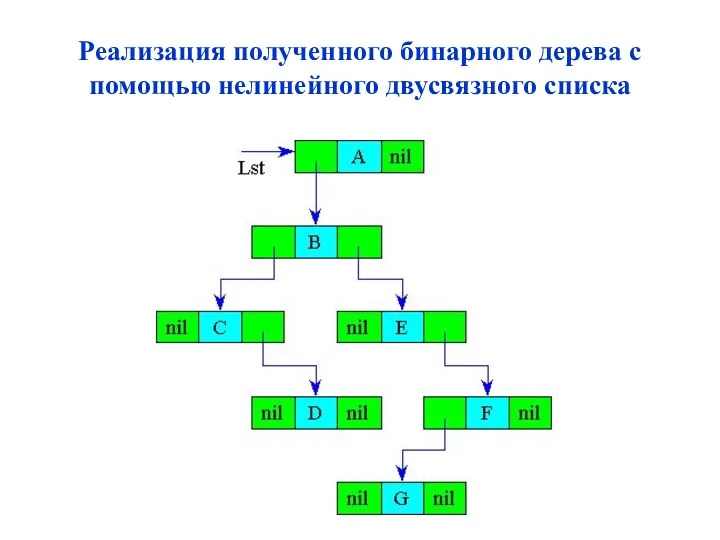
Реализация полученного бинарного дерева с помощью нелинейного двусвязного списка
Реализация полученного бинарного дерева с помощью нелинейного двусвязного списка

Основные операции с деревьями
1. Обход дерева.
2. Удаление поддерева.
3.
Основные операции с деревьями
1. Обход дерева.
2. Удаление поддерева.
3.

В зависимости от того, в какой последовательности выполняются эти три процедуры,
В зависимости от того, в какой последовательности выполняются эти три процедуры,
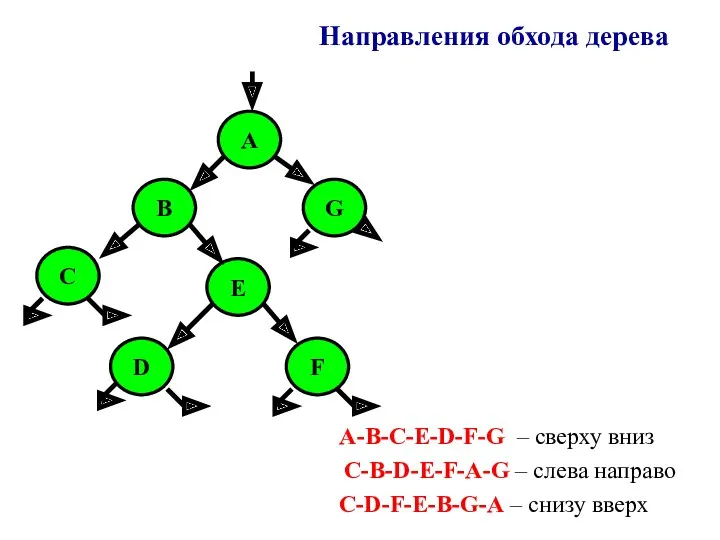
A
B
C
D
E
F
G
A-B-C-E-D-F-G – сверху вниз
C-B-D-E-F-A-G – слева направо
C-D-F-E-B-G-A – снизу вверх
Направления обхода
A
B
C
D
E
F
G
A-B-C-E-D-F-G – сверху вниз
C-B-D-E-F-A-G – слева направо
C-D-F-E-B-G-A – снизу вверх
Направления обхода

В зависимости от того, после какого по счету захода в узел
В зависимости от того, после какого по счету захода в узел

Операция удаления поддерева
Необходимо указать узел, к которому подсоединяется удаляемое поддерево
Операция удаления поддерева
Необходимо указать узел, к которому подсоединяется удаляемое поддерево

Операция вставки поддерева
Необходимо знать адрес корня вставляемого поддерева и узел,
Операция вставки поддерева
Необходимо знать адрес корня вставляемого поддерева и узел,

Создание дерева бинарного поиска
Пусть заданы элементы с ключами: 14, 18, 6,
Создание дерева бинарного поиска
Пусть заданы элементы с ключами: 14, 18, 6,
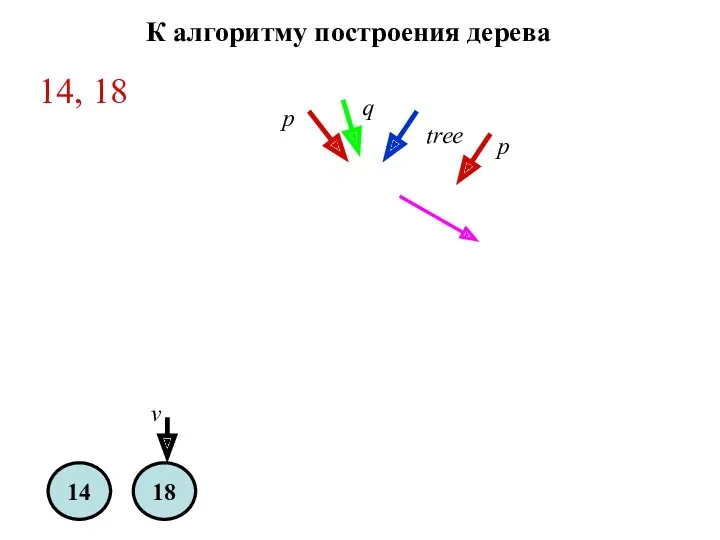
14
18
tree
q
p
v
p
14, 18
К алгоритму построения дерева
14
18
tree
q
p
v
p
14, 18
К алгоритму построения дерева
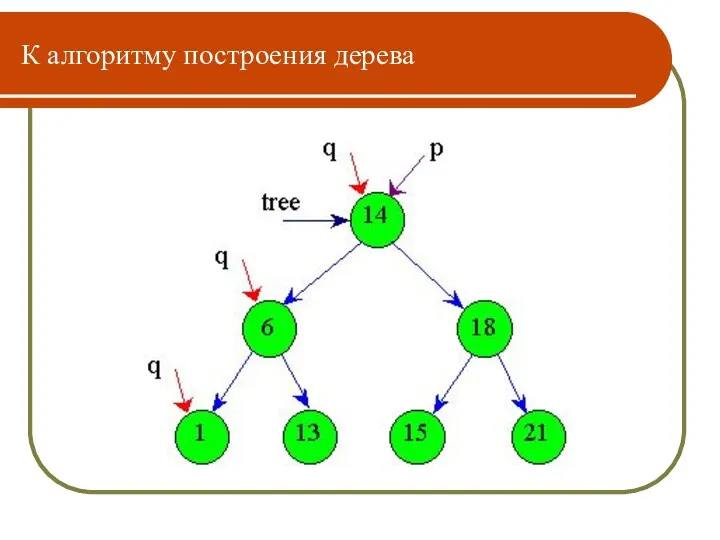
К алгоритму построения дерева
К алгоритму построения дерева
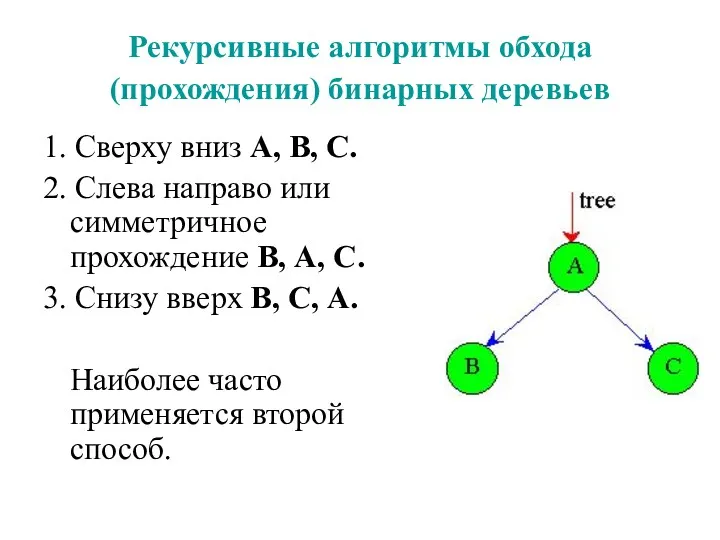
Рекурсивные алгоритмы обхода (прохождения) бинарных деревьев
1. Сверху вниз А, В,
Рекурсивные алгоритмы обхода (прохождения) бинарных деревьев
1. Сверху вниз А, В,
 Інструктування з безпеки життєдіяльності та правил поведінки під час роботи в комп’ютерному класі
Інструктування з безпеки життєдіяльності та правил поведінки під час роботи в комп’ютерному класі Построение дерева папок
Построение дерева папок Засоби перегляду й перетворення графічної інформації
Засоби перегляду й перетворення графічної інформації Подходы к изучению сложных систем защиты информации
Подходы к изучению сложных систем защиты информации Язык C# и платформа .NET. Лекция 1
Язык C# и платформа .NET. Лекция 1 Применение проектных и информационно-коммуникативных технологий для повышения уровня учебной мотивации учащихся старших классов
Применение проектных и информационно-коммуникативных технологий для повышения уровня учебной мотивации учащихся старших классов Электронная почта. Сетевое коллективное взаимодействие. Сетевой этикет
Электронная почта. Сетевое коллективное взаимодействие. Сетевой этикет Урок-игра по информатике в 9 классе
Урок-игра по информатике в 9 классе Сети с коммутацией каналов (СКК)
Сети с коммутацией каналов (СКК) Устройства ввода информации
Устройства ввода информации Разветвляющиеся алгоритмы. (9 класс)
Разветвляющиеся алгоритмы. (9 класс) Условный оператор, оператор выбора. Логические операции в Паскале
Условный оператор, оператор выбора. Логические операции в Паскале Система формирования режима информационной безопасности. Задачи информационной безопасности общества
Система формирования режима информационной безопасности. Задачи информационной безопасности общества Стилистика. Официально-деловой стиль
Стилистика. Официально-деловой стиль Програмне забезпечення комп’ютера за новою програмою
Програмне забезпечення комп’ютера за новою програмою Виртуальные машины и их операционные системы
Виртуальные машины и их операционные системы Windows. Версии Windows
Windows. Версии Windows DS Программирование Python. Генерация списков и словарей
DS Программирование Python. Генерация списков и словарей Арифметические и логические основы работы компьютера
Арифметические и логические основы работы компьютера Адресация компьютеров в сети
Адресация компьютеров в сети Programming in haskell. Рекурсия и функции высших порядков
Programming in haskell. Рекурсия и функции высших порядков 10 дурацких СМС, из-за которых я обломался с кучей девушек
10 дурацких СМС, из-за которых я обломался с кучей девушек ТБ в кабинете информатики
ТБ в кабинете информатики Тестирование ПО
Тестирование ПО Представление и кодирование информации
Представление и кодирование информации Презентация по теме База данных
Презентация по теме База данных Логические элементы ПК
Логические элементы ПК 30_WPF_технология_проектирования_приложений (2)
30_WPF_технология_проектирования_приложений (2)