- Структуры и алгоритмы обработки данных

Содержание
- 2. 11. Хеширование.
- 3. Это преобразование (отображение) входного ключа – исходных данных (сообщения, массива) в выходную битовую строку определённой длины,
- 4. Пусть требуется создать БД персонала предприятия, численность сотрудников в котором 100 человек, хранить нужно анкетные данные
- 5. Отображение (в математике) – Это функция М, определенная на множестве элементов (в области определения) одного типа
- 6. Хеш-функция Хеширование (хеш-функция) создаёт отображение (соответствие) множества ключей в множество индексов массива (множество целых чисел) Алгоритм
- 7. Пример 2: поиск на основе хеш-таблицы Пусть хеш-таблица имеет размер L=100 (по количеству сотрудников) Тогда хеш-функция
- 8. Свойства хеш-функции Простой (быстрый) алгоритм вычисления хеш-значения Должна всегда возвращать одно и то же хеш-значение для
- 9. Алгоритмы хеширования Основанные на делении Основанные на умножении Универсальное хеширование – выбор функции из заданного универсального
- 10. Коллизия – Это ситуация, когда для разных ключей хеш-функция создаёт одинаковые значения (индексы) Так, в нашем
- 11. Подходы (технологии) устранения коллизий Два подхода: Цепное хеширование (формирование списков из элементов, хешированных с одним индексом)
- 12. 1. Цепное хеширование – Это способ разрешения коллизий, когда элементы, ключи которых получили один индекс, хранятся
- 13. Пример 3: Хеш – таблица с динамическими списками для устранения коллизий (1/2) Создадим хеш-таблицу для ключей
- 14. Пример 3: Хеш – таблица с динамическими списками для устранения коллизий (2/2)
- 15. Проблемы цепного хеширования Проблема однородного хеширования: Желательно, чтобы цепочки переполнения были примерно одной длины, иначе сложность
- 16. 2. Хеширование с открытой адресацией В хеш-таблице элементы могут содержать только пары ключ – значение (или
- 17. Алгоритм открытой адресации для поиска и вставки в общем виде: 1. Вычисляем адрес точки входа в
- 18. Последовательность проб Функции g(f(k), i), при 1 ≤ i ≤ N, определяют последовательность адресов для просмотра
- 19. Линейное пробирование Это простейшая схема адрес коллизии + смещение, при которой ai= g(f(k), i) = f(k)
- 20. Пример создания хеш-таблицы с линейной открытой адресацией
- 21. Открытая адресация с двойным хешированием По этой схеме аi = g(f(k), i) = f(k) + i*h(k),
- 22. 12. Поиск образца в тексте
- 23. Постановка задачи Дано: Некоторый текст Т (haystack) и образец или шаблон W (needle) – тоже текст
- 24. Линейный (последовательный, прямой) поиск Примитивный, наивный алгоритм (англ. brute force algorithm) Пример: Требуется найти все вхождения
- 25. Псевдокод алгоритма прямого поиска findstr (char *s, char *temp) do //i – индекс в строке s,
- 26. Сложность алгоритма прямого поиска подстроки Худший случай – обнаружение образца в конце текста: T→{AAA….AAAB}, длина │T│=n;
- 27. Улучшение эффективности поиска подстроки Цель улучшений – по возможности при поиске сдвинуть образец на >1 позицию
- 28. 1. Алгоритм Кнута-Морриса-Пратта (КМП) 1970-е, Д.Кнут и В.Пратт и, независимо от них, Д.Моррис При каждом несовпадении
- 29. Префикс и суффикс Префикс – начальные символы последовательности (с начального по максимум предпоследний) Суффикс – окончание
- 30. Идея расчёта сдвига (1/2) Организуется посимвольное сравнение текста и образца вплоть до первого несовпадения Суффикс образца
- 31. Идея расчёта сдвига (2/2) Индекс последнего совпавшего с текстом символа в образце должен стать ключом к
- 32. Префикс-функция Пусть дана строка (образец) а[1..m] Требуется вычислить для неё префикс-функцию, т.е. массив (вектор) чисел π[1..m],
- 33. 1 этап – Препроцессинг – формирование массива префиксов Пусть j = π[s, i-1]. Вычисление префикс-функции для
- 34. 2 этап – сам КМП-поиск (вариант реализации на С++)
- 35. Склеим образец ааbаа и основной текст ааbааbааааbааbаааb через символ-разделитель: ааbаа@ааbааbааааbааbаааb Вызовем для всей склейки префикс-функцию: Тогда
- 36. Особенности алгоритма КМП Движение по основному тексту – только вперёд (без возврата при нахождении несоответствия) –
- 38. Скачать презентацию

11. Хеширование.
11. Хеширование.
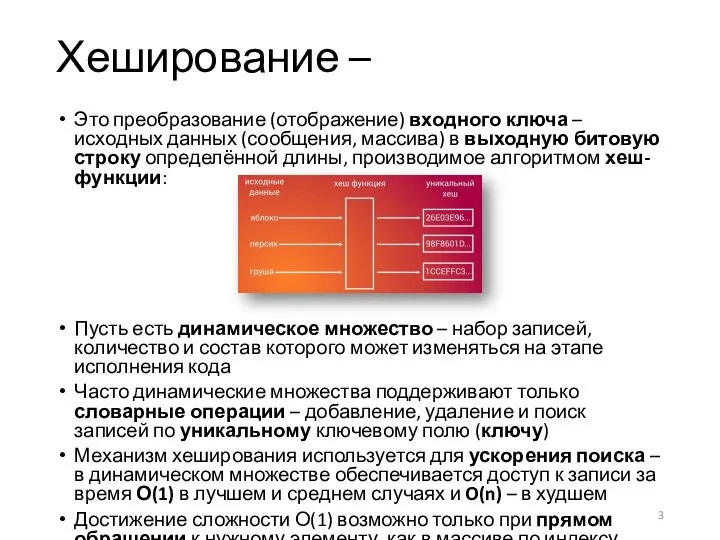
Это преобразование (отображение) входного ключа – исходных данных (сообщения, массива) в
Это преобразование (отображение) входного ключа – исходных данных (сообщения, массива) в

Пусть требуется создать БД персонала предприятия, численность сотрудников в котором 100
Пусть требуется создать БД персонала предприятия, численность сотрудников в котором 100

Отображение (в математике) –
Это функция М, определенная на множестве элементов (в
Отображение (в математике) –
Это функция М, определенная на множестве элементов (в

Хеш-функция
Хеширование (хеш-функция) создаёт отображение (соответствие) множества ключей в множество индексов массива
Хеш-функция
Хеширование (хеш-функция) создаёт отображение (соответствие) множества ключей в множество индексов массива

Пример 2:
поиск на основе хеш-таблицы
Пусть хеш-таблица имеет размер L=100 (по количеству
Пример 2:
поиск на основе хеш-таблицы
Пусть хеш-таблица имеет размер L=100 (по количеству

Свойства хеш-функции
Простой (быстрый) алгоритм вычисления хеш-значения
Должна всегда возвращать одно и то
Свойства хеш-функции
Простой (быстрый) алгоритм вычисления хеш-значения
Должна всегда возвращать одно и то

Алгоритмы хеширования
Основанные на делении
Основанные на умножении
Универсальное хеширование – выбор функции из
Алгоритмы хеширования
Основанные на делении
Основанные на умножении
Универсальное хеширование – выбор функции из

Коллизия –
Это ситуация, когда для разных ключей хеш-функция создаёт одинаковые значения
Коллизия –
Это ситуация, когда для разных ключей хеш-функция создаёт одинаковые значения
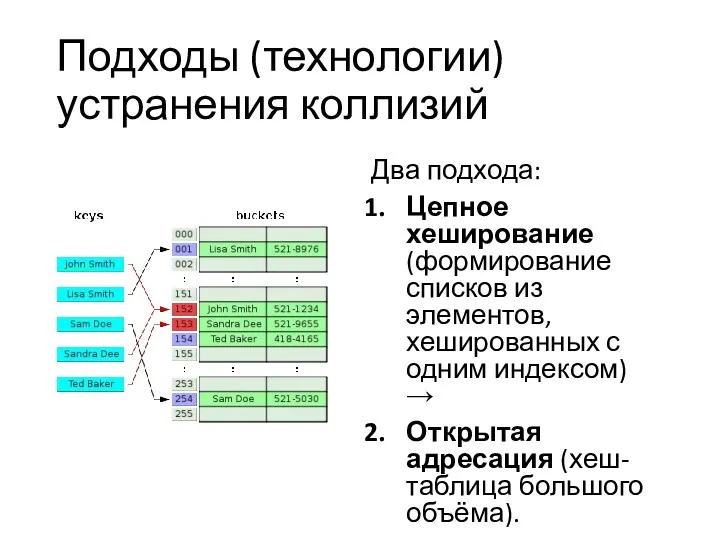
Подходы (технологии) устранения коллизий
Два подхода:
Цепное хеширование (формирование списков из элементов, хешированных
Подходы (технологии) устранения коллизий
Два подхода:
Цепное хеширование (формирование списков из элементов, хешированных
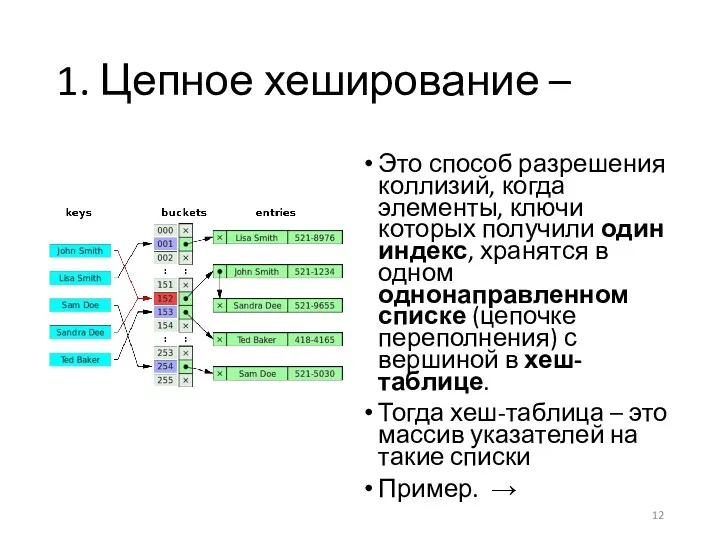
1. Цепное хеширование –
Это способ разрешения коллизий, когда элементы, ключи
1. Цепное хеширование –
Это способ разрешения коллизий, когда элементы, ключи

Пример 3: Хеш – таблица с динамическими списками для устранения коллизий
Пример 3: Хеш – таблица с динамическими списками для устранения коллизий
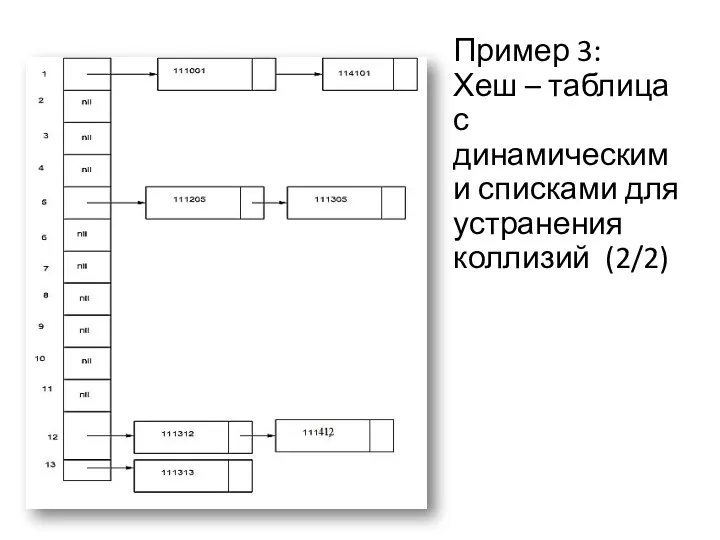
Пример 3:
Хеш – таблица с динамическими списками для устранения коллизий
Пример 3: Хеш – таблица с динамическими списками для устранения коллизий

Проблемы цепного хеширования
Проблема однородного хеширования:
Желательно, чтобы цепочки переполнения были примерно одной
Проблемы цепного хеширования
Проблема однородного хеширования:
Желательно, чтобы цепочки переполнения были примерно одной
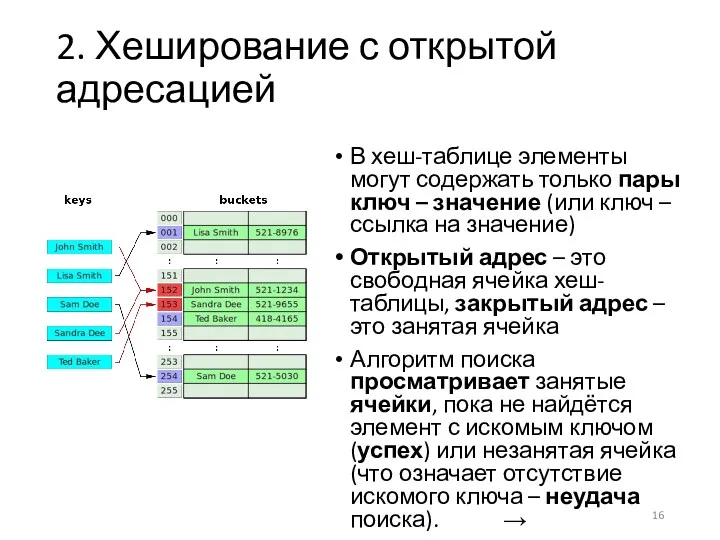
2. Хеширование с открытой адресацией
В хеш-таблице элементы могут содержать только пары
2. Хеширование с открытой адресацией
В хеш-таблице элементы могут содержать только пары

Алгоритм открытой адресации для поиска и вставки в общем виде:
1. Вычисляем
Алгоритм открытой адресации для поиска и вставки в общем виде:
1. Вычисляем

Последовательность проб
Функции g(f(k), i), при 1 ≤ i ≤ N, определяют
Последовательность проб
Функции g(f(k), i), при 1 ≤ i ≤ N, определяют

Линейное пробирование
Это простейшая схема адрес коллизии + смещение, при которой ai=
Линейное пробирование
Это простейшая схема адрес коллизии + смещение, при которой ai=
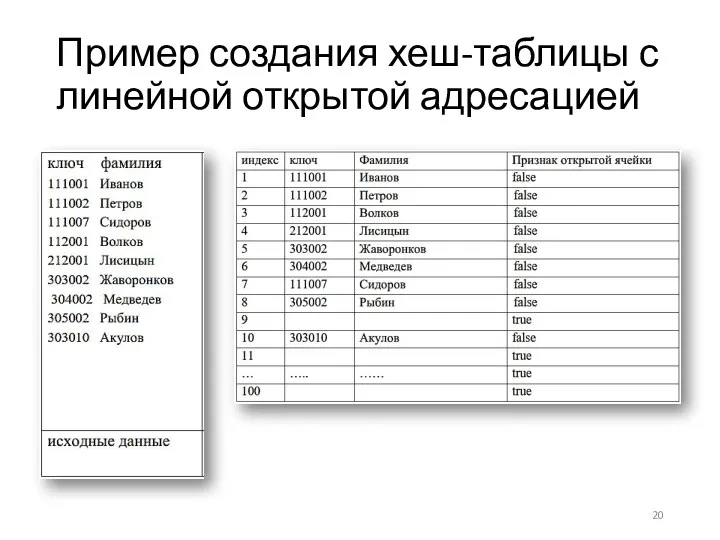
Пример создания хеш-таблицы с линейной открытой адресацией
Пример создания хеш-таблицы с линейной открытой адресацией

Открытая адресация
с двойным хешированием
По этой схеме аi = g(f(k), i)
Открытая адресация
с двойным хешированием
По этой схеме аi = g(f(k), i)

12. Поиск образца в тексте
12. Поиск образца в тексте

Постановка задачи
Дано:
Некоторый текст Т (haystack) и образец или шаблон W (needle)
Постановка задачи
Дано:
Некоторый текст Т (haystack) и образец или шаблон W (needle)

Линейный (последовательный, прямой) поиск
Примитивный, наивный алгоритм
(англ. brute force algorithm)
Пример:
Требуется найти
Линейный (последовательный, прямой) поиск
Примитивный, наивный алгоритм
(англ. brute force algorithm)
Пример:
Требуется найти

Псевдокод алгоритма прямого поиска
findstr (char *s, char *temp) do
//i –
Псевдокод алгоритма прямого поиска
findstr (char *s, char *temp) do
//i –

Сложность алгоритма прямого поиска подстроки
Худший случай – обнаружение образца в конце
Сложность алгоритма прямого поиска подстроки
Худший случай – обнаружение образца в конце

Улучшение эффективности поиска подстроки
Цель улучшений – по возможности при поиске сдвинуть
Улучшение эффективности поиска подстроки
Цель улучшений – по возможности при поиске сдвинуть

1. Алгоритм
Кнута-Морриса-Пратта (КМП)
1970-е, Д.Кнут и В.Пратт и, независимо от них,
1. Алгоритм
Кнута-Морриса-Пратта (КМП)
1970-е, Д.Кнут и В.Пратт и, независимо от них,
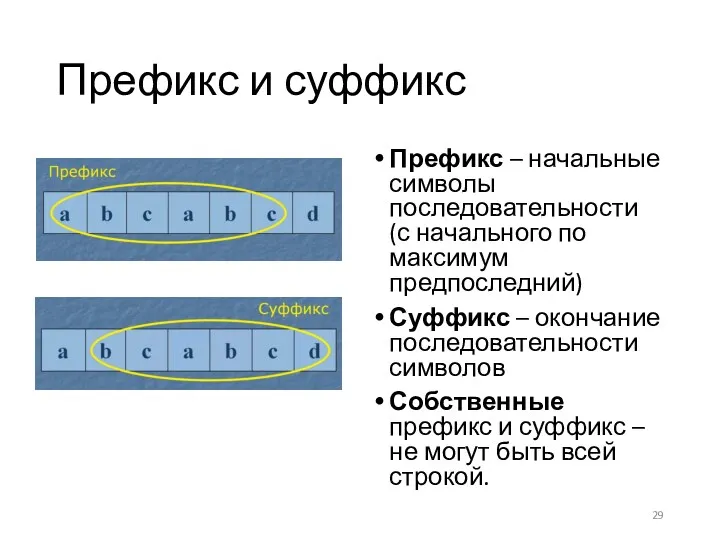
Префикс и суффикс
Префикс – начальные символы последовательности (с начального по максимум
Префикс и суффикс
Префикс – начальные символы последовательности (с начального по максимум

Идея расчёта сдвига (1/2)
Организуется посимвольное сравнение текста и образца вплоть до
Идея расчёта сдвига (1/2)
Организуется посимвольное сравнение текста и образца вплоть до
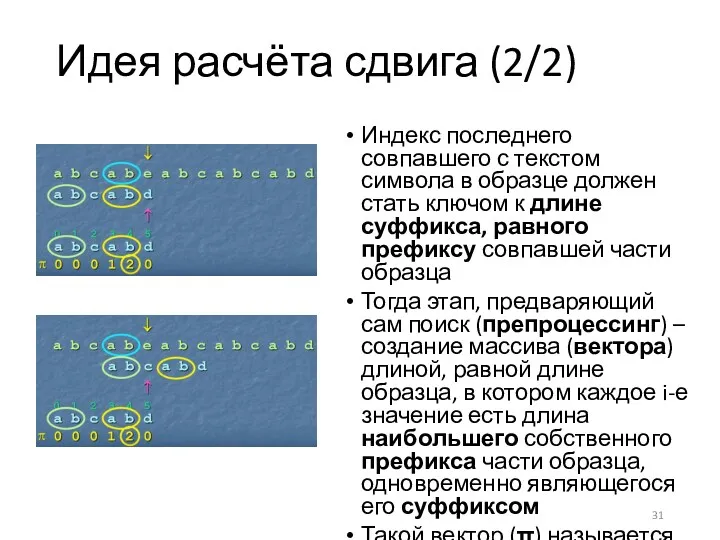
Идея расчёта сдвига (2/2)
Индекс последнего совпавшего с текстом символа в образце
Идея расчёта сдвига (2/2)
Индекс последнего совпавшего с текстом символа в образце
![Префикс-функция Пусть дана строка (образец) а[1..m] Требуется вычислить для неё](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/400297/slide-31.jpg)
Префикс-функция
Пусть дана строка (образец) а[1..m]
Требуется вычислить для неё префикс-функцию, т.е.
Префикс-функция
Пусть дана строка (образец) а[1..m]
Требуется вычислить для неё префикс-функцию, т.е.

1 этап – Препроцессинг – формирование массива префиксов
Пусть j = π[s,
1 этап – Препроцессинг – формирование массива префиксов
Пусть j = π[s,

2 этап – сам КМП-поиск
(вариант реализации на С++)
2 этап – сам КМП-поиск
(вариант реализации на С++)

Склеим образец ааbаа и основной текст ааbааbааааbааbаааb через символ-разделитель:
ааbаа@ааbааbааааbааbаааb
Вызовем для всей
Склеим образец ааbаа и основной текст ааbааbааааbааbаааb через символ-разделитель:
ааbаа@ааbааbааааbааbаааb
Вызовем для всей

Особенности алгоритма КМП
Движение по основному тексту – только вперёд (без возврата
Особенности алгоритма КМП
Движение по основному тексту – только вперёд (без возврата
 Microsoft Office Word
Microsoft Office Word Подходы к измерению информации. Информация и информационные процессы. Информатика. 10 класс
Подходы к измерению информации. Информация и информационные процессы. Информатика. 10 класс Overview of apps and web sites for language learning
Overview of apps and web sites for language learning SEO Журналистика. Практическое руководство по написанию статей
SEO Журналистика. Практическое руководство по написанию статей IT advancements in Finance Chat bot banking
IT advancements in Finance Chat bot banking Списки в документе Microsoft Word. Урок 8
Списки в документе Microsoft Word. Урок 8 1С:Лекторий - регулярные встречи пользователей c методистами 1С в центре Москвы
1С:Лекторий - регулярные встречи пользователей c методистами 1С в центре Москвы Сущность и значение комплектования государственных архивов. Технотронные документы
Сущность и значение комплектования государственных архивов. Технотронные документы Профессиография
Профессиография Виды профессиональной информационной деятельности человека с использованием технических средств и информационных ресурсов
Виды профессиональной информационной деятельности человека с использованием технических средств и информационных ресурсов Мультимедиа: Microsoft, PowerPoint
Мультимедиа: Microsoft, PowerPoint Ақпараттың құрылымдық өлшемдері. Энтропия – ақпараттық анықталмағандық өлшемі ретінде
Ақпараттың құрылымдық өлшемдері. Энтропия – ақпараттық анықталмағандық өлшемі ретінде Software metrics using constructive cost model
Software metrics using constructive cost model Минимальные необходимые требования к оформляемым ЭВСД в ГИС Меркурий
Минимальные необходимые требования к оформляемым ЭВСД в ГИС Меркурий Понятие информации. 10 класс
Понятие информации. 10 класс Представление информации в различных системах счисления
Представление информации в различных системах счисления Инструкция по выполнению домашних заданий учащимися при дистанционном обучении
Инструкция по выполнению домашних заданий учащимися при дистанционном обучении Умный Дом
Умный Дом Нормальные формы баз данных
Нормальные формы баз данных Практикум по основам языка разметки гипертекстов HTML
Практикум по основам языка разметки гипертекстов HTML Теоретические основы проектирования информационных систем
Теоретические основы проектирования информационных систем Вероятностная обработка лингвистической информации
Вероятностная обработка лингвистической информации Трёхмерная графика. (11 класс. § 66-§ 74)
Трёхмерная графика. (11 класс. § 66-§ 74) Функциональные возможности ГИС и элементы ГИС-технологий
Функциональные возможности ГИС и элементы ГИС-технологий Сценарий урока по теме Отношение входит в состав.
Сценарий урока по теме Отношение входит в состав. Среда программирования Кумир. Чертежник
Среда программирования Кумир. Чертежник Все на поиск терминов. Компьютерный турнир
Все на поиск терминов. Компьютерный турнир Этапы проектирования БД
Этапы проектирования БД