- Теория алгоритмов

Содержание
- 2. Первым дошедшим до нас алгоритмом считается предложенный Евклидом в III веке до нашей эры алгоритм нахождения
- 3. К 1960-70-ым годам оформились следующие направления в теории алгоритмов: Классическая теория алгоритмов Теория асимптотического анализа алгоритмов
- 4. Цели и задачи теории алгоритмов формализация понятия «алгоритм» и исследование формальных алгоритмических систем; формальное доказательство алгоритмической
- 5. Практическое применение результатов теории алгоритмов Теоретический аспект - является ли задача в принципе алгоритмически разрешимой Практический
- 6. Понятие алгоритма Определение 1.1: Алгоритм - это заданное на некотором языке конечное предписание, задающее конечную последовательность
- 7. Требования к алгоритму алгоритм должен содержать конечное количество элементарно выполнимых предписаний, т.е. удовлетворять требованию конечности записи;
- 8. Одной из фундаментальных статей, результаты которой лежат в основе современной теории алгоритмов является статья Эмиля Поста
- 9. Машина Поста
- 10. Одной из фундаментальных статей, результаты которой лежат в основе современной теории алгоритмов является статья Эмиля Поста
- 11. Основные понятия алгоритмического формализма Поста пространство символов (язык L) в котором задаётся конкретная проблема и получается
- 12. Постовское пространство символов – это бесконечная лента ячеек. Каждый ящик или ячейка могут быть помечены или
- 13. Набор инструкций (элементарных операций) Поста 1.пометить ящик, если он пуст; 2.стереть метку, если она есть; 3.переместиться
- 14. набор инструкций применим к общей проблеме, если для каждой конкретной проблемы не возникает коллизий в инструкциях
- 15. Способ задания проблемы и формулировка 1 Общая проблема называется по Посту 1-заданой, если существует такой финитный
- 16. Гипотеза Поста состоит в том, что любые более широкие формулировки в смысле алфавита символов ленты, набора
- 17. Машина Тьюринга
- 18. Машина Тьюринга является расширением модели конечного автомата, расширением, включающим потенциально бесконечную память с возможностью перехода (движения)
- 19. Формально машина Тьюринга может быть описана следующим образом
- 20. Пусть заданы: конечное множество состояний – Q, в которых может находиться машина Тьюринга; конечное множество символов
- 21. Решаемая проблема задается путем записи конечного количества символов из множества Σ є Г – Si є
- 22. Алгоритмически неразрешимые проблемы
- 23. Теорема Не существует алгоритма (машины Тьюринга), позволяющего по описанию произвольного алгоритма и его исходных данных (и
- 24. Проблема 1: Распределение девяток в записи числа π [10]; Проблема 2: Вычисление совершенных чисел; Проблема 3:
- 25. Введение в анализ алгоритмов
- 26. При использовании алгоритмов для решения практических задач мы сталкиваемся с проблемой рационального выбора алгоритма решения задачи.
- 27. Конкретная проблема задается N словами памяти, таким образом, на входе алгоритма – Nβ = N*β бит
- 28. Трудоёмкость алгоритма. Трудоёмкостью алгоритма для конкретного входа – Fa(N), является количество «элементарных» операций совершаемых алгоритмом для
- 29. Система обозначений в анализе алгоритмов
- 30. 1. Fa∧(N) – худший случай – наибольшее количество операций, совершаемых алгоритмом А для решения конкретных проблем
- 31. 2. Fa∨(N) – лучший случай – наименьшее количество операций, совершаемых алгоритмом А для решения конкретных проблем
- 32. 3. Fa(N) – средний случай – среднее количество операций, совершаемых алгоритмом А для решения конкретных проблем
- 33. Классификация алгоритмов по виду функции трудоёмкости
- 34. Количественно-зависимые по трудоемкости алгоритмы Алгоритмы, функция трудоемкости которых зависит только от размерности конкретного входа, и не
- 35. Параметрически-зависимые по трудоемкости алгоритмы Алгоритмы, трудоемкость которых определяется не размерностью входа, а конкретными значениями обрабатываемых слов
- 36. Количественно-параметрические по трудоемкости алгоритмы В большинстве практических случаев функция трудоемкости зависит как от количества данных на
- 37. Порядково-зависимые по трудоемкости алгоритмы Пусть множество D состоит из элементов (d1,…,dn), и ||D||=N, Определим Dp =
- 38. Асимптотический анализ функций
- 39. Оценка Θ (тетта) Пусть f(n) и g(n) – положительные функции положительного аргумента, n ≥ 1 (количество
- 40. Оценка О (О большое) В отличие от оценки Θ, оценка О требует только, что бы функция
- 41. Оценка Ω (Омега) В отличие от оценки О, оценка Ω является оценкой снизу – т.е. определяет
- 42. Временная оценка алгоритма
- 43. Проблемы построения временных оценок неадекватность формальной системы записи алгоритма и реальной системы команд процессора; наличие архитектурных
- 44. Методики перехода к временным оценкам
- 45. Пооперационный анализ Идея пооперационного анализа состоит в получении пооперационной функции трудоемкости для каждой из используемых алгоритмом
- 46. Метод Гиббсона Метод предполагает проведение совокупного анализа по трудоемкости и переход к временным оценкам на основе
- 47. Метод прямого определения среднего времени В этом методе так же проводится совокупный анализ по трудоемкости –
- 48. Классы сложности задач
- 49. Теоретический предел трудоемкости задачи
- 50. Рассматривая некоторую алгоритмически разрешимую задачу, и анализируя один из алгоритмов ее решения, мы можем получить оценку
- 51. Класс P (задачи с полиномиальной сложностью) Задача называется полиномиальной, т.е. относится к классу P, если существует
- 52. Класс NP (полиномиально проверяемые задачи) Дано N чисел – А = (a1,…an) и число V. Задача:
- 53. Проблема P = NP После введения в теорию алгоритмов понятий сложностных классов Эдмондсом была поставлена основная
- 54. Класс NPC (NP – полные задачи) NPC (NP-complete) или клас NP-полных задач требует выполнения следующих двух
- 55. Алгоритм полного перебора
- 56. Полный перебор — метод решения математических задач. Относится к классу методов поиска решения исчерпыванием всевозможных вариантов.
- 57. Полный перебор в большинстве прикладных задач на практике не применяется, есть ряд исключений. В частности, когда
- 58. Пример использования полного перебора
- 63. Таким образом, решение данной задачи может существенно сократить временные затраты на вычисление матричной цепочки. Это решение
- 64. Метод “разделяй и властвуй”
- 65. Описание метода Задача решается в три стадии: задача разбивается на несколько более простых подзадач (как правило,
- 66. Умножение чисел
- 68. Более эффективный алгоритм
- 69. Дерево работы алгоритма n n/2 n/2 n/2 n/4 n/4 n/4 n/4 n/4 n/4 n/4 n/4 n/4
- 71. Жадные алгоритмы
- 72. Общая идея На каждом шаге жадный алгоритм делает локально оптимальный выбор. Решение, найденное таким образом, не
- 73. Задача о выборе заявок Даны n пар чисел (si, fi), где si Говорим, что заявки (si,
- 74. Алгоритм Greedy-Activity-Selector(s, f ) 1 n ← length[s] 2 A ← {1} 3 j ← 1
- 75. Анализ Время работы есть Θ(n) (при условии, что заявки отсортированы!). Существует оптимальное решение, содержащее заявку 1:
- 76. Две отличительные особенности жадных алгоритмов Принцип жадного выбора: последовательность локально оптимальных (жадных) выборов дает глобально оптимальное
- 77. Жадный алгоритм или динамическое программирование? В непрерывной задаче о рюкзаке (fractional knapsack problem), в отличие от
- 78. Жадный алгоритм или динамическое программирование? Итак, в первом случае выполняется принцип жадного выбора, во втором —
- 79. Алгоритм перебора с возвратом
- 80. Обзор метода Решение задачи методом перебора с возвратом строится конструктивно последовательным расширением частичного решения. Если на
- 81. Вычислительная схема перебора с возвратом
- 82. Пусть, далее, существует конкретное правило P, в соответствии с которым некоторые из частичных решений могут объявляться
- 83. Задача о расстановке ферзей на шахматной доске. Составьте рекурсивную функцию, находящую возможную расстановку n ферзей на
- 84. Алгоритм "Все расстановки"
- 85. Проведем параметризацию задачи. Введем четыре вспомогательных вектора: pos, ho, dd и du c длинами n, n,
- 86. Рис.1
- 87. Использование этих соглашений позволяет получить такие утверждения: В позицию (i,j) можно поставить ферзь, если hoi+dui+j+ddn+i-j=0. Поставить
- 88. Алгоритм перебора с возвратом
- 89. Обзор метода Решение задачи методом перебора с возвратом строится конструктивно последовательным расширением частичного решения. Если на
- 90. Вычислительная схема перебора с возвратом
- 91. Пусть, далее, существует конкретное правило P, в соответствии с которым некоторые из частичных решений могут объявляться
- 92. Задача о расстановке ферзей на шахматной доске. Составьте рекурсивную функцию, находящую возможную расстановку n ферзей на
- 93. Алгоритм "Все расстановки"
- 94. Проведем параметризацию задачи. Введем четыре вспомогательных вектора: pos, ho, dd и du c длинами n, n,
- 95. Рис.1
- 96. Использование этих соглашений позволяет получить такие утверждения: В позицию (i,j) можно поставить ферзь, если hoi+dui+j+ddn+i-j=0. Поставить
- 97. Алгоритм пирамидальной сортировки
- 98. Метод пирамидальной сортировки, изобретенный Д. Уилльямсом, является улучшением традиционных сортировок с помощью дерева. Пирамидой (кучей) называется
- 99. Общая идея алгоритма Общая идея пирамидальной сортировки заключается в том, что сначала строится пирамида из элементов
- 100. 1 этап Построение пирамиды. Определяем правую часть дерева, начиная с n/2-1 (нижний уровень дерева). Берем элемент
- 101. Расположим элементы в виде исходной пирамиды; номер элемента правой части (6/2-1)=2 - это элемент 15.
- 102. Результат просеивания элемента 15 через пирамиду. Следующий просеиваемый элемент – 1, равный 31.
- 103. Затем – элемент 0, равный 24.
- 104. Разумеется, полученный массив еще не упорядочен. Однако процедура просеивания является основой для пирамидальной сортировки. В итоге
- 105. 2 этап Сортировка на построенной пирамиде. Берем последний элемент массива в качестве текущего. Меняем верхний (наименьший)
- 107. Продолжим процесс. В итоге массив будет отсортирован по убыванию.
- 116. Алгоритмы поиска кратчайших путей на графах
- 117. Алгоритм Дейкстры Алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути
- 118. Для примера возьмем такой ориентированный граф G:
- 119. Этот граф мы можем представить в виде матрицы С
- 120. Возьмем в качестве источника вершину 1. Это значит что мы будем искать кратчайшие маршруты из вершины
- 121. Присвоим 1-й вершине метку равную 0, потому как эта вершина — источник. Остальным вершинам присвоим метки
- 122. Далее выберем такую вершину W, которая имеет минимальную метку (сейчас это вершина 1) и рассмотрим все
- 123. После того как мы рассмотрели все вершины, в которые есть прямой путь из W, вершину W
- 124. Мы выберем вершину 2. Но из нее нет ни одного исходящего пути, поэтому мы сразу отмечаем
- 125. Исходя из картинки мы можем увидеть, что метки 3-ей и 4-ой вершин стали меньше, тоесть был
- 126. Также есть вектор Р, исходя из которого можно построить кратчайшие маршруты. По количеству элементов этот вектор
- 127. Далее на этапе пересчета значения метки для рассматриваемой вершины, в случае если метка рассматриваемой вершины меняется
- 128. Алгоритмы поиска кратчайших путей на графах
- 129. Алгоритм Флойда Алгоритм нахождения длин кратчайших путей между всеми парами вершин во взвешенном ориентированном графе. Работает
- 130. Алгоритм
- 133. Псевдокод
- 134. Сложность алгоритма
- 135. Пример работы i=0 i=1 i=2 i=3 i=4
- 136. Алгоритм Краскала
- 137. Алгоритм Краскала - алгоритм поиска минимального остовного дерева (англ. minimum spanning tree, MST) во взвешенном неориентированном
- 138. Идея
- 139. Реализация
- 140. Задача о максимальном ребре минимального веса Легко показать, что максимальное ребро в MST минимально. Обратное в
- 142. Пример
- 143. Первое ребро, которое будет рассмотрено — ae, так как его вес минимальный. Добавим его к ответу,
- 144. Рассмотрим следующие ребро — cd. Добавим его к ответу, так как его концы соединяют вершины из
- 145. Дальше рассмотрим ребро ab. Добавим его к ответу, так как его концы соединяют вершины из разных
- 146. Рассмотрим следующие ребро — be. Оно соединяет вершины из одного множества, поэтому перейдём к следующему ребру
- 147. Рёбра ec и ed соединяют вершины из одного множества, поэтому после их просмотра они не будут
- 148. Parallel Programming in OpenMP standard "Parallel and distributed programming" Total amount of intelligence on the planet
- 149. Content "Parallel and distributed programming" Programming model in shared memory Model "pulsating" parallelism FORK-JOIN OpenMP standard
- 150. Programming shared memory © М.Л. Цымблер "Parallel and distributed programming" A parallel application consists of multiple
- 151. FORK-JOIN model © М.Л. Цымблер "Parallel and distributed programming" Program - a full-weighted process. The process
- 152. Standard OpenMP © М.Л. Цымблер "Parallel and distributed programming" OpenMP (Open Multi-Processing) - a standard that
- 153. OpenMP-program © М.Л. Цымблер "Parallel and distributed programming" The main thread (the program) generates a family
- 154. Simple OpenMP-program © М.Л. Цымблер "Parallel and distributed programming" void main() { printf("Hello!\n"); } void main()
- 155. Simple OpenMP-program © М.Л. Цымблер "Parallel and distributed programming"
- 156. Advantages of OpenMP © М.Л. Цымблер "Parallel and distributed programming" Gradual (incremental) paralleling You can parallelize
- 157. OpenMP directives © М.Л. Цымблер "Parallel and distributed programming" Directives OpenMP - directive C / C
- 158. Functions of OpenMP library © М.Л. Цымблер "Parallel and distributed programming" The assignment of the library:
- 159. Environment variables OpenMP © М.Л. Цымблер "Parallel and distributed programming" Environment variables control the behavior of
- 160. Variable Scope © М.Л. Цымблер "Parallel and distributed programming" Common variable (shared) - global to the
- 161. Private and public variables © М.Л. Цымблер "Parallel and distributed programming" void main() { int a,
- 162. Private and public variables © М.Л. Цымблер "Parallel and distributed programming" void main() { int rank;
- 163. Private and public variables © М.Л. Цымблер "Parallel and distributed programming" void main() { int rank;
- 164. Distribution of computations © М.Л. Цымблер "Parallel and distributed programming" Directive computation distribution between threads in
- 165. Directive sections © М.Л. Цымблер "Parallel and distributed programming" Explicit definition of blocks of code that
- 166. Directive single © М.Л. Цымблер "Parallel and distributed programming" Specifies a code that is only one
- 167. Directive master © М.Л. Цымблер "Parallel and distributed programming" Specifies a code that is only one
- 168. Parallelization of loops © М.Л. Цымблер "Parallel and distributed programming" The loop counter is the default
- 169. Parallelization of loops © М.Л. Цымблер "Parallel and distributed programming" You can explicitly define the private
- 170. Parallelization of loops © М.Л. Цымблер "Parallel and distributed programming" Uncontrolled change thread shared data leads
- 171. Critical section in cycles © М.Л. Цымблер "Parallel and distributed programming" At any time, a critical
- 172. Reduction in a loop © М.Л. Цымблер "Parallel and distributed programming" Reduction involves identifying for each
- 173. Reduction in a loop © М.Л. Цымблер "Parallel and distributed programming" #include #include long long num_steps
- 174. Directive for © М.Л. Цымблер "Parallel and distributed programming" Format directives #pragma omp parallel for [clause
- 175. Parameter firstprivate © М.Л. Цымблер "Parallel and distributed programming" Defines private loop variables for, that early
- 176. Parameter lastprivate © М.Л. Цымблер "Parallel and distributed programming" Defines the private variables that the end
- 177. Parameter ordered © М.Л. Цымблер "Parallel and distributed programming" Defines the code in the loop for,
- 178. Parameter nowait © М.Л. Цымблер "Parallel and distributed programming" Avoids the implicit barrier at the end
- 179. Distribution of loop iterations © М.Л. Цымблер "Parallel and distributed programming" The iterations in the directive
- 180. Example © М.Л. Цымблер "Parallel and distributed programming" // The amount of work in iterations is
- 181. Example © М.Л. Цымблер "Parallel and distributed programming" // The threads are suitable for distribution point
- 182. Synchronization algorithms © М.Л. Цымблер "Parallel and distributed programming" Directive explicit synchronization Critical barrier atomic Directive
- 183. Directive critical © М.Л. Цымблер "Parallel and distributed programming" Defines the critical section - the section
- 184. Directive atomic © М.Л. Цымблер "Parallel and distributed programming" Defines the critical section for a statement
- 185. Directive barrier © М.Л. Цымблер "Parallel and distributed programming" Determines the barrier - the point in
- 186. Directive barrier © М.Л. Цымблер "Parallel and distributed programming" int main() { sub1(2); sub2(2); sub3(2); }
- 187. Directives and parameters © М.Л. Цымблер "Parallel and distributed programming"
- 188. Operation time © М.Л. Цымблер "Parallel and distributed programming" double start; double end; start = omp_get_wtime();
- 189. Threads count © М.Л. Цымблер "Parallel and distributed programming" // False np = omp_get_num_threads(); // It
- 190. © М.Л. Цымблер "Parallel and distributed programming" As castles using shared variables of omp_lock_t. These variables
- 191. © М.Л. Цымблер "Parallel and distributed programming" Causes the calling thread to wait for the release
- 192. Example © М.Л. Цымблер "Parallel and distributed programming" #include int main() { omp_lock_t lck; int id;
- 193. Conclusion © М.Л. Цымблер "Parallel and distributed programming" Programming model in shared memory Model "pulsating" parallelism
- 194. Information Resources © М.Л. Цымблер "Parallel and distributed programming" Introduction to OpenMP www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html Chandra R., Menon
- 195. Минимальный перебор в игровых деревьях. Альфа-бета отсечения. Построение игровых программ Удалова Татьяна 85М21
- 196. Деревья решений Узел дерева – один шаг решения задачи Ветвь – решение, которое ведёт к более
- 197. Игровые деревья Моделирование стратегических настольных игр (крестики нолики) Ветвь, выходящая из узла - ходы одного из
- 198. Минимаксный перебор Минимизировать максимальное значение, которое может иметь позиция для противника после следующего хода Т.Е Ищем
- 199. Крестики-нолики(1) 4 значения позиции поля: 4 –игрок выиграет 3 – ситуация не ясна 2 – ничья
- 200. Крестики-нолики(2) Дерево игры крестики-нолики в конце партии[1] Игрок X минимизирует свои потери Игрок 0 максимизирует свой
- 201. Альфа-бета отсечения(1) Оптимизация минимаксного перебора Сравнение наилучших оценок, полученных для полностью изученных ветвей, с наилучшими предполагаемыми
- 202. Альфа-бета отсечения(2) Предположим, что z
- 203. Альфа-бета отсечения(4) Правила вычисления альфа-бета: у MAX вершины значение a равно наибольшему в данный момент значению
- 204. Альфа-бета отсечения(5) Правила прекращения поиска: можно не проводить поиска на поддереве, растущем из всякой MIN вершины,
- 205. Альфа-бета отсечения(6) [2]
- 206. Программная реализация Игра крестики-нолики включающая в себя: Альфа-бета отсечения для расчёта следующего хода Возможность выбора глубины
- 207. Литература Rod Stephens. Ready-to-run Delphi© Algorithms. Wiley Computer Publishing. Интернет-Университет Информационных Технологий. Интеллектуальные робототехнические системы. Лекция:
- 209. Скачать презентацию

Первым дошедшим до нас алгоритмом считается предложенный Евклидом в III веке
Первым дошедшим до нас алгоритмом считается предложенный Евклидом в III веке

К 1960-70-ым годам оформились следующие направления в теории алгоритмов:
Классическая теория алгоритмов
Теория
К 1960-70-ым годам оформились следующие направления в теории алгоритмов:
Классическая теория алгоритмов
Теория

Цели и задачи теории алгоритмов
формализация понятия «алгоритм» и исследование формальных алгоритмических
Цели и задачи теории алгоритмов
формализация понятия «алгоритм» и исследование формальных алгоритмических

Практическое применение результатов теории алгоритмов
Теоретический аспект
- является ли задача в
Практическое применение результатов теории алгоритмов
Теоретический аспект
- является ли задача в

Понятие алгоритма
Определение 1.1: Алгоритм - это заданное на некотором языке конечное
Понятие алгоритма
Определение 1.1: Алгоритм - это заданное на некотором языке конечное

Требования к алгоритму
алгоритм должен содержать конечное количество элементарно выполнимых предписаний, т.е.
Требования к алгоритму
алгоритм должен содержать конечное количество элементарно выполнимых предписаний, т.е.

Одной из фундаментальных статей, результаты которой лежат в основе современной теории
Одной из фундаментальных статей, результаты которой лежат в основе современной теории

Машина Поста
Машина Поста

Одной из фундаментальных статей, результаты которой лежат в основе современной теории
Одной из фундаментальных статей, результаты которой лежат в основе современной теории

Основные понятия алгоритмического формализма Поста
пространство символов (язык L) в котором
Основные понятия алгоритмического формализма Поста
пространство символов (язык L) в котором

Постовское пространство символов – это бесконечная лента ячеек.
Каждый ящик или ячейка
Постовское пространство символов – это бесконечная лента ячеек.
Каждый ящик или ячейка

Набор инструкций (элементарных операций) Поста
1.пометить ящик, если он пуст;
2.стереть метку, если
Набор инструкций (элементарных операций) Поста
1.пометить ящик, если он пуст;
2.стереть метку, если

набор инструкций применим к общей проблеме, если для каждой конкретной проблемы
набор инструкций применим к общей проблеме, если для каждой конкретной проблемы

Способ задания проблемы и формулировка 1
Общая проблема называется по Посту 1-заданой,
Способ задания проблемы и формулировка 1
Общая проблема называется по Посту 1-заданой,

Гипотеза Поста состоит в том, что любые более широкие формулировки в
Гипотеза Поста состоит в том, что любые более широкие формулировки в

Машина Тьюринга
Машина Тьюринга

Машина Тьюринга является расширением модели конечного автомата, расширением, включающим потенциально бесконечную
Машина Тьюринга является расширением модели конечного автомата, расширением, включающим потенциально бесконечную

Формально машина Тьюринга может быть описана следующим образом
Формально машина Тьюринга может быть описана следующим образом

Пусть заданы:
конечное множество состояний – Q, в которых может находиться машина
Пусть заданы:
конечное множество состояний – Q, в которых может находиться машина

Решаемая проблема задается путем записи конечного количества символов из множества Σ
Решаемая проблема задается путем записи конечного количества символов из множества Σ

Алгоритмически неразрешимые проблемы
Алгоритмически неразрешимые проблемы

Теорема
Не существует алгоритма (машины Тьюринга), позволяющего по описанию произвольного алгоритма и
Теорема
Не существует алгоритма (машины Тьюринга), позволяющего по описанию произвольного алгоритма и
![Проблема 1: Распределение девяток в записи числа π [10]; Проблема](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/107585/slide-23.jpg)
Проблема 1: Распределение девяток в записи числа π [10];
Проблема 2: Вычисление
Проблема 1: Распределение девяток в записи числа π [10];
Проблема 2: Вычисление

Введение в анализ алгоритмов
Введение в анализ алгоритмов

При использовании алгоритмов для решения практических задач мы сталкиваемся с проблемой
При использовании алгоритмов для решения практических задач мы сталкиваемся с проблемой

Конкретная проблема задается N словами памяти, таким образом, на входе алгоритма
Конкретная проблема задается N словами памяти, таким образом, на входе алгоритма

Трудоёмкость алгоритма.
Трудоёмкостью алгоритма для конкретного входа – Fa(N), является количество «элементарных»
Трудоёмкость алгоритма.
Трудоёмкостью алгоритма для конкретного входа – Fa(N), является количество «элементарных»

Система обозначений в анализе алгоритмов
Система обозначений в анализе алгоритмов

1. Fa∧(N) – худший случай – наибольшее количество операций, совершаемых алгоритмом
1. Fa∧(N) – худший случай – наибольшее количество операций, совершаемых алгоритмом

2. Fa∨(N) – лучший случай – наименьшее количество операций, совершаемых алгоритмом
2. Fa∨(N) – лучший случай – наименьшее количество операций, совершаемых алгоритмом

3. Fa(N) – средний случай – среднее количество операций, совершаемых алгоритмом
3. Fa(N) – средний случай – среднее количество операций, совершаемых алгоритмом

Классификация алгоритмов по виду функции трудоёмкости
Классификация алгоритмов по виду функции трудоёмкости

Количественно-зависимые по трудоемкости алгоритмы
Алгоритмы, функция трудоемкости которых зависит только от размерности
Количественно-зависимые по трудоемкости алгоритмы
Алгоритмы, функция трудоемкости которых зависит только от размерности

Параметрически-зависимые по трудоемкости алгоритмы
Алгоритмы, трудоемкость которых определяется не размерностью входа, а
Параметрически-зависимые по трудоемкости алгоритмы
Алгоритмы, трудоемкость которых определяется не размерностью входа, а

Количественно-параметрические по трудоемкости алгоритмы
В большинстве практических случаев функция трудоемкости зависит как
Количественно-параметрические по трудоемкости алгоритмы
В большинстве практических случаев функция трудоемкости зависит как

Порядково-зависимые по трудоемкости алгоритмы
Пусть множество D состоит из элементов (d1,…,dn), и
Порядково-зависимые по трудоемкости алгоритмы
Пусть множество D состоит из элементов (d1,…,dn), и

Асимптотический анализ функций
Асимптотический анализ функций

Оценка Θ (тетта)
Пусть f(n) и g(n) – положительные функции положительного аргумента,
Оценка Θ (тетта)
Пусть f(n) и g(n) – положительные функции положительного аргумента,
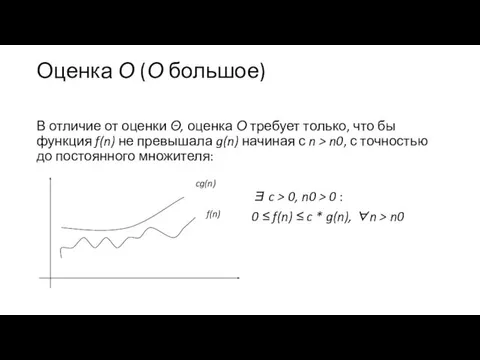
Оценка О (О большое)
В отличие от оценки Θ, оценка О требует
Оценка О (О большое)
В отличие от оценки Θ, оценка О требует
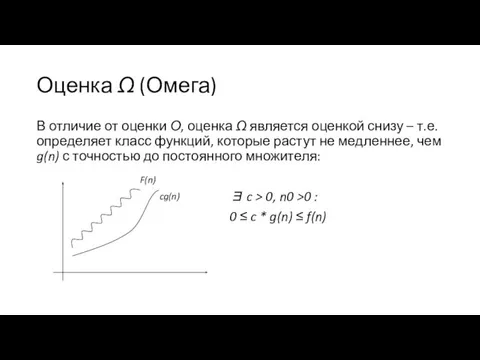
Оценка Ω (Омега)
В отличие от оценки О, оценка Ω является оценкой
Оценка Ω (Омега)
В отличие от оценки О, оценка Ω является оценкой

Временная оценка алгоритма
Временная оценка алгоритма

Проблемы построения временных оценок
неадекватность формальной системы записи алгоритма и реальной системы
Проблемы построения временных оценок
неадекватность формальной системы записи алгоритма и реальной системы

Методики перехода к временным оценкам
Методики перехода к временным оценкам

Пооперационный анализ
Идея пооперационного анализа состоит в получении пооперационной функции трудоемкости для
Пооперационный анализ
Идея пооперационного анализа состоит в получении пооперационной функции трудоемкости для

Метод Гиббсона
Метод предполагает проведение совокупного анализа по трудоемкости и переход к
Метод Гиббсона
Метод предполагает проведение совокупного анализа по трудоемкости и переход к

Метод прямого определения среднего времени
В этом методе так же проводится совокупный
Метод прямого определения среднего времени
В этом методе так же проводится совокупный

Классы сложности задач
Классы сложности задач

Теоретический предел трудоемкости задачи
Теоретический предел трудоемкости задачи

Рассматривая некоторую алгоритмически разрешимую задачу, и анализируя один из алгоритмов ее
Рассматривая некоторую алгоритмически разрешимую задачу, и анализируя один из алгоритмов ее

Класс P (задачи с полиномиальной сложностью)
Задача называется полиномиальной, т.е. относится к
Класс P (задачи с полиномиальной сложностью)
Задача называется полиномиальной, т.е. относится к

Класс NP (полиномиально проверяемые задачи)
Дано N чисел – А = (a1,…an)
Класс NP (полиномиально проверяемые задачи)
Дано N чисел – А = (a1,…an)

Проблема P = NP
После введения в теорию алгоритмов понятий сложностных классов
Проблема P = NP
После введения в теорию алгоритмов понятий сложностных классов

Класс NPC (NP – полные задачи)
NPC (NP-complete) или клас NP-полных задач
Класс NPC (NP – полные задачи)
NPC (NP-complete) или клас NP-полных задач

Алгоритм полного перебора
Алгоритм полного перебора

Полный перебор — метод решения математических задач. Относится к классу методов поиска
Полный перебор — метод решения математических задач. Относится к классу методов поиска

Полный перебор в большинстве прикладных задач на практике не применяется, есть
Полный перебор в большинстве прикладных задач на практике не применяется, есть

Пример использования полного перебора
Пример использования полного перебора





Таким образом, решение данной задачи может существенно сократить временные затраты на
Таким образом, решение данной задачи может существенно сократить временные затраты на

Метод “разделяй и властвуй”
Метод “разделяй и властвуй”

Описание метода
Задача решается в три стадии:
задача разбивается на несколько более простых
Описание метода
Задача решается в три стадии:
задача разбивается на несколько более простых

Умножение чисел
Умножение чисел


Более эффективный алгоритм
Более эффективный алгоритм
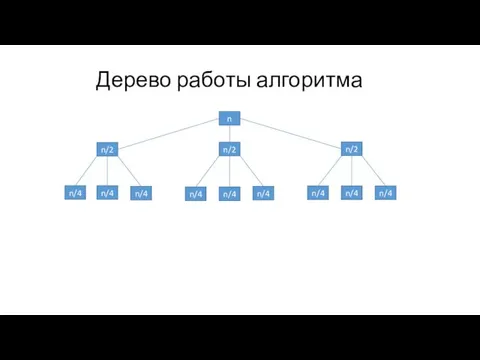
Дерево работы алгоритма
n
n/2
n/2
n/2
n/4
n/4
n/4
n/4
n/4
n/4
n/4
n/4
n/4
Дерево работы алгоритма
n
n/2
n/2
n/2
n/4
n/4
n/4
n/4
n/4
n/4
n/4
n/4
n/4


Жадные алгоритмы
Жадные алгоритмы

Общая идея
На каждом шаге жадный алгоритм делает локально оптимальный выбор.
Решение, найденное
Общая идея
На каждом шаге жадный алгоритм делает локально оптимальный выбор.
Решение, найденное

Задача о выборе заявок
Даны n пар чисел (si, fi), где si
Задача о выборе заявок
Даны n пар чисел (si, fi), где si
![Алгоритм Greedy-Activity-Selector(s, f ) 1 n ← length[s] 2 A](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/107585/slide-73.jpg)
Алгоритм
Greedy-Activity-Selector(s, f )
1 n ← length[s]
2 A ← {1}
Алгоритм
Greedy-Activity-Selector(s, f )
1 n ← length[s]
2 A ← {1}

Анализ
Время работы есть Θ(n) (при условии, что заявки отсортированы!).
Существует оптимальное решение,
Анализ
Время работы есть Θ(n) (при условии, что заявки отсортированы!).
Существует оптимальное решение,

Две отличительные особенности жадных алгоритмов
Принцип жадного выбора: последовательность локально оптимальных (жадных)
Две отличительные особенности жадных алгоритмов
Принцип жадного выбора: последовательность локально оптимальных (жадных)

Жадный алгоритм или динамическое программирование?
В непрерывной задаче о рюкзаке (fractional knapsack
Жадный алгоритм или динамическое программирование?
В непрерывной задаче о рюкзаке (fractional knapsack

Жадный алгоритм или динамическое программирование?
Итак, в первом случае выполняется принцип жадного
Жадный алгоритм или динамическое программирование?
Итак, в первом случае выполняется принцип жадного

Алгоритм перебора с возвратом
Алгоритм перебора с возвратом

Обзор метода
Решение задачи методом перебора с возвратом строится конструктивно последовательным расширением частичного решения.
Обзор метода
Решение задачи методом перебора с возвратом строится конструктивно последовательным расширением частичного решения.

Вычислительная схема перебора с возвратом
Вычислительная схема перебора с возвратом

Пусть, далее, существует конкретное правило P, в соответствии с которым некоторые из
Пусть, далее, существует конкретное правило P, в соответствии с которым некоторые из

Задача о расстановке ферзей на шахматной доске.
Составьте рекурсивную функцию, находящую возможную расстановку n ферзей
Задача о расстановке ферзей на шахматной доске.
Составьте рекурсивную функцию, находящую возможную расстановку n ферзей

Алгоритм "Все расстановки"
Алгоритм "Все расстановки"

Проведем параметризацию задачи. Введем четыре вспомогательных вектора: pos, ho, dd и du c длинами n, n, 2n-1 и 2n-1 соответственно.
Проведем параметризацию задачи. Введем четыре вспомогательных вектора: pos, ho, dd и du c длинами n, n, 2n-1 и 2n-1 соответственно.
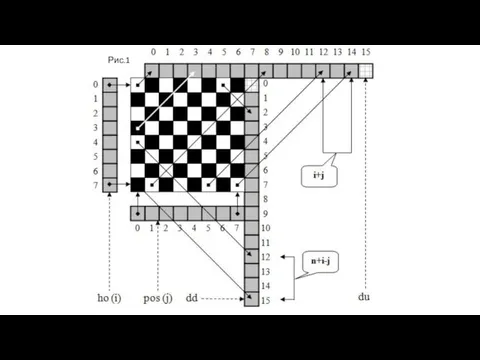
Рис.1
Рис.1

Использование этих соглашений позволяет получить такие утверждения:
В позицию (i,j) можно поставить ферзь, если hoi+dui+j+ddn+i-j=0.
Поставить
Использование этих соглашений позволяет получить такие утверждения:
В позицию (i,j) можно поставить ферзь, если hoi+dui+j+ddn+i-j=0.
Поставить

Алгоритм перебора с возвратом
Алгоритм перебора с возвратом

Обзор метода
Решение задачи методом перебора с возвратом строится конструктивно последовательным расширением частичного решения.
Обзор метода
Решение задачи методом перебора с возвратом строится конструктивно последовательным расширением частичного решения.

Вычислительная схема перебора с возвратом
Вычислительная схема перебора с возвратом

Пусть, далее, существует конкретное правило P, в соответствии с которым некоторые из
Пусть, далее, существует конкретное правило P, в соответствии с которым некоторые из

Задача о расстановке ферзей на шахматной доске.
Составьте рекурсивную функцию, находящую возможную расстановку n ферзей
Задача о расстановке ферзей на шахматной доске.
Составьте рекурсивную функцию, находящую возможную расстановку n ферзей

Алгоритм "Все расстановки"
Алгоритм "Все расстановки"

Проведем параметризацию задачи. Введем четыре вспомогательных вектора: pos, ho, dd и du c длинами n, n, 2n-1 и 2n-1 соответственно.
Проведем параметризацию задачи. Введем четыре вспомогательных вектора: pos, ho, dd и du c длинами n, n, 2n-1 и 2n-1 соответственно.
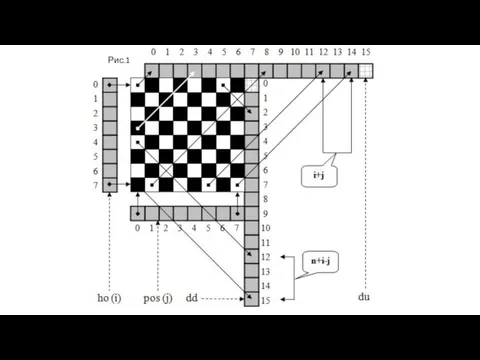
Рис.1
Рис.1

Использование этих соглашений позволяет получить такие утверждения:
В позицию (i,j) можно поставить ферзь, если hoi+dui+j+ddn+i-j=0.
Поставить
Использование этих соглашений позволяет получить такие утверждения:
В позицию (i,j) можно поставить ферзь, если hoi+dui+j+ddn+i-j=0.
Поставить

Алгоритм пирамидальной сортировки
Алгоритм пирамидальной сортировки
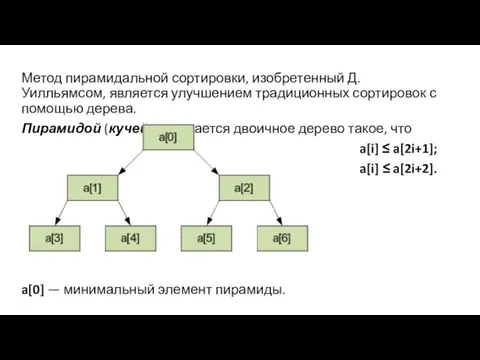
Метод пирамидальной сортировки, изобретенный Д. Уилльямсом, является улучшением традиционных сортировок с
Метод пирамидальной сортировки, изобретенный Д. Уилльямсом, является улучшением традиционных сортировок с

Общая идея алгоритма
Общая идея пирамидальной сортировки заключается в том, что сначала
Общая идея алгоритма
Общая идея пирамидальной сортировки заключается в том, что сначала

1 этап
Построение пирамиды. Определяем правую часть дерева, начиная с n/2-1 (нижний уровень дерева).
1 этап
Построение пирамиды. Определяем правую часть дерева, начиная с n/2-1 (нижний уровень дерева).
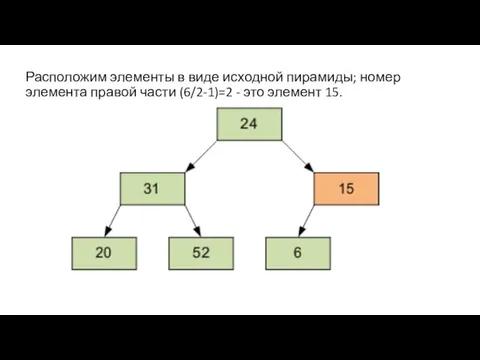
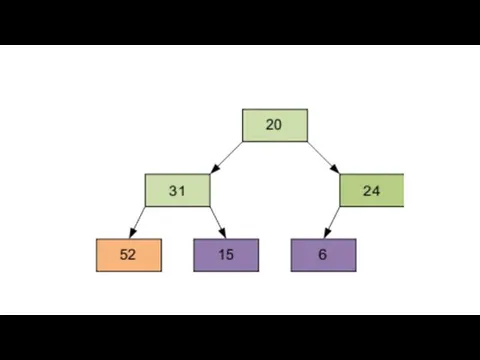
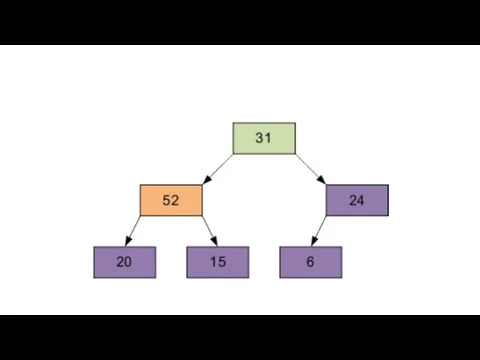
Расположим элементы в виде исходной пирамиды; номер элемента правой части (6/2-1)=2
Расположим элементы в виде исходной пирамиды; номер элемента правой части (6/2-1)=2

Результат просеивания элемента 15 через пирамиду.
Следующий просеиваемый элемент – 1, равный
Результат просеивания элемента 15 через пирамиду.
Следующий просеиваемый элемент – 1, равный
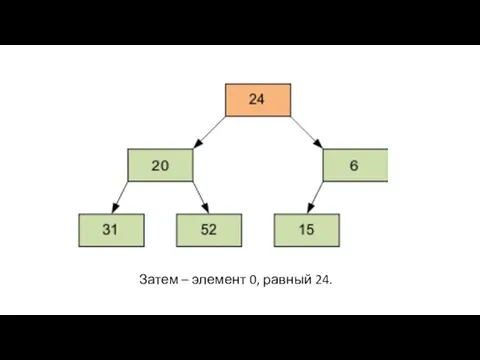
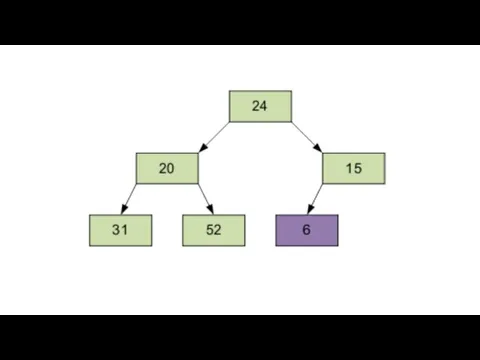
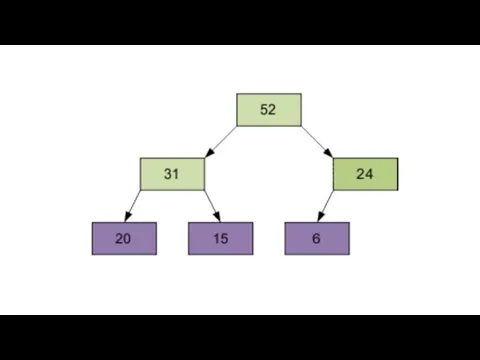
Затем – элемент 0, равный 24.
Затем – элемент 0, равный 24.
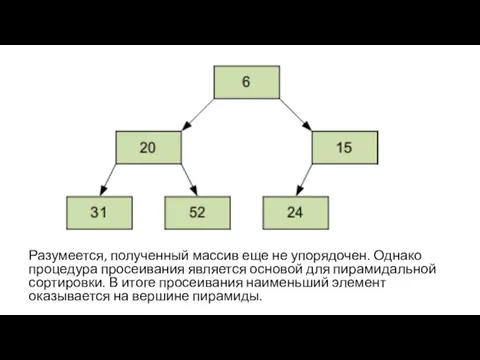
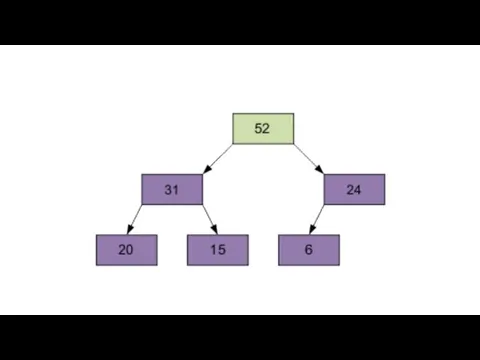
Разумеется, полученный массив еще не упорядочен. Однако процедура просеивания является основой
Разумеется, полученный массив еще не упорядочен. Однако процедура просеивания является основой

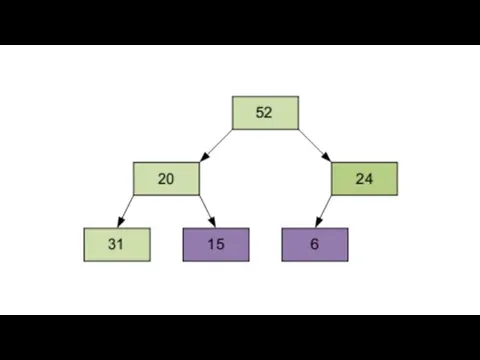
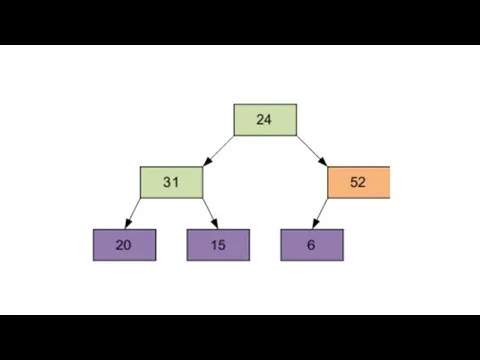
2 этап
Сортировка на построенной пирамиде. Берем последний элемент массива в качестве
2 этап
Сортировка на построенной пирамиде. Берем последний элемент массива в качестве
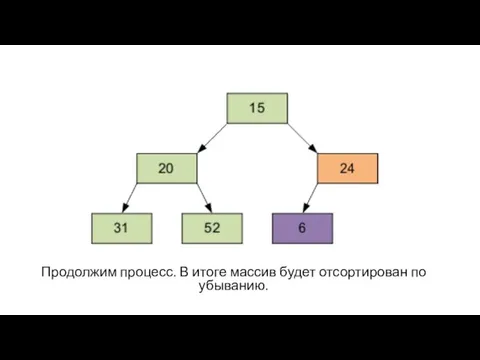
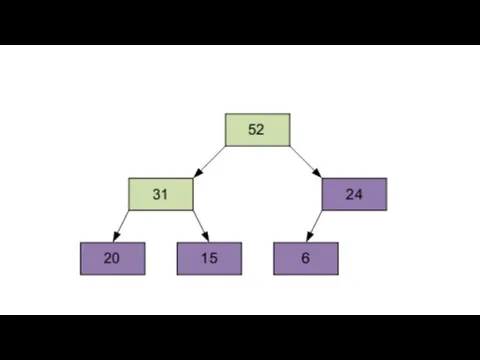
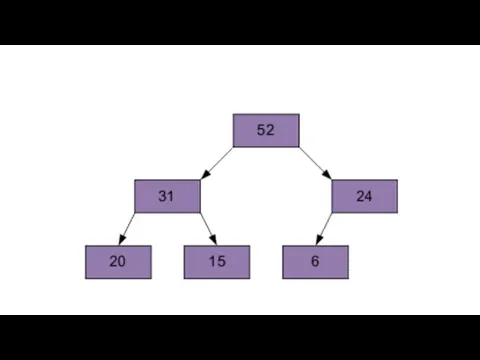
Продолжим процесс. В итоге массив будет отсортирован по убыванию.
Продолжим процесс. В итоге массив будет отсортирован по убыванию.

Алгоритмы поиска кратчайших путей на графах
Алгоритмы поиска кратчайших путей на графах

Алгоритм Дейкстры
Алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути от
Алгоритм Дейкстры
Алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути от
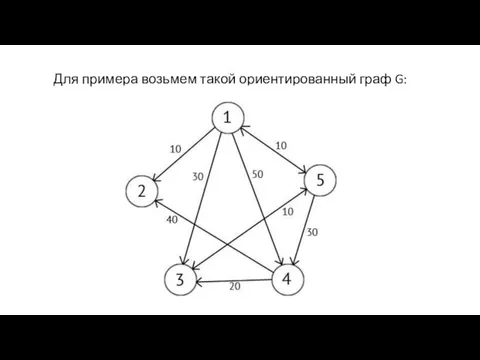
Для примера возьмем такой ориентированный граф G:
Для примера возьмем такой ориентированный граф G:

Этот граф мы можем представить в виде матрицы С
Этот граф мы можем представить в виде матрицы С

Возьмем в качестве источника вершину 1. Это значит что мы будем
Возьмем в качестве источника вершину 1. Это значит что мы будем
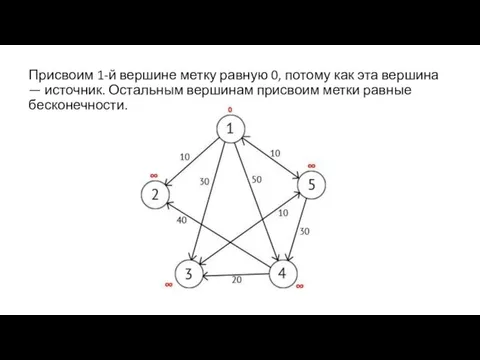
Присвоим 1-й вершине метку равную 0, потому как эта вершина —
Присвоим 1-й вершине метку равную 0, потому как эта вершина —

Далее выберем такую вершину W, которая имеет минимальную метку (сейчас это
Далее выберем такую вершину W, которая имеет минимальную метку (сейчас это
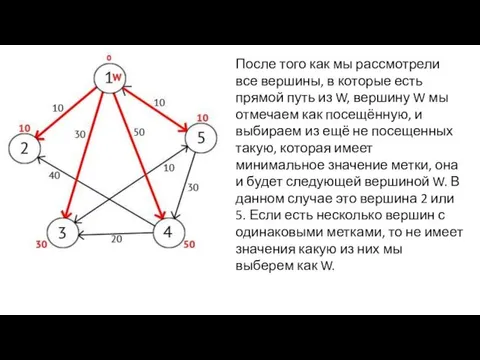
После того как мы рассмотрели все вершины, в которые есть прямой
После того как мы рассмотрели все вершины, в которые есть прямой
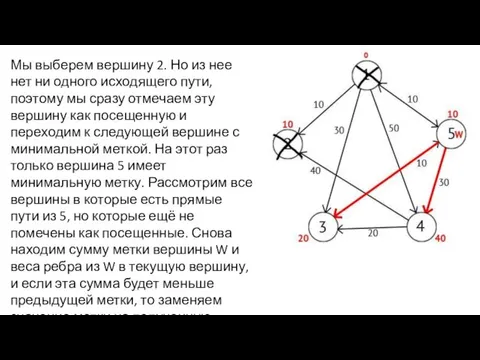
Мы выберем вершину 2. Но из нее нет ни одного исходящего
Мы выберем вершину 2. Но из нее нет ни одного исходящего

Исходя из картинки мы можем увидеть, что метки 3-ей и 4-ой
Исходя из картинки мы можем увидеть, что метки 3-ей и 4-ой

Также есть вектор Р, исходя из которого можно построить кратчайшие маршруты.
Также есть вектор Р, исходя из которого можно построить кратчайшие маршруты.

Далее на этапе пересчета значения метки для рассматриваемой вершины, в случае
Далее на этапе пересчета значения метки для рассматриваемой вершины, в случае

Алгоритмы поиска кратчайших путей на графах
Алгоритмы поиска кратчайших путей на графах

Алгоритм Флойда
Алгоритм нахождения длин кратчайших путей между всеми парами вершин во
Алгоритм Флойда
Алгоритм нахождения длин кратчайших путей между всеми парами вершин во

Алгоритм
Алгоритм



Псевдокод
Псевдокод

Сложность алгоритма
Сложность алгоритма

Пример работы
i=0
i=1
i=2
i=3
i=4
Пример работы
i=0
i=1
i=2
i=3
i=4

Алгоритм Краскала
Алгоритм Краскала

Алгоритм Краскала - алгоритм поиска минимального остовного дерева (англ. minimum spanning tree, MST) во взвешенном неориентированном
Алгоритм Краскала - алгоритм поиска минимального остовного дерева (англ. minimum spanning tree, MST) во взвешенном неориентированном

Идея
Идея

Реализация
Реализация

Задача о максимальном ребре минимального веса
Легко показать, что максимальное ребро в
Задача о максимальном ребре минимального веса
Легко показать, что максимальное ребро в


Пример
Пример

Первое ребро, которое будет рассмотрено — ae, так как его вес минимальный.
Добавим
Первое ребро, которое будет рассмотрено — ae, так как его вес минимальный. Добавим

Рассмотрим следующие ребро — cd.
Добавим его к ответу, так как его концы
Рассмотрим следующие ребро — cd. Добавим его к ответу, так как его концы

Дальше рассмотрим ребро ab.
Добавим его к ответу, так как его концы соединяют
Дальше рассмотрим ребро ab. Добавим его к ответу, так как его концы соединяют
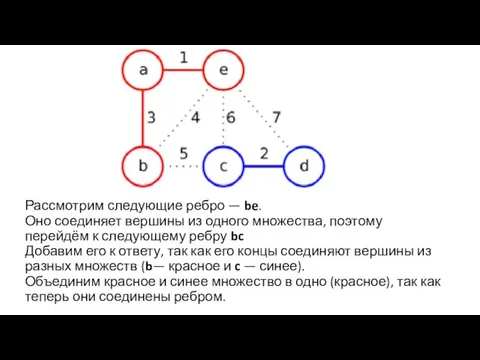
Рассмотрим следующие ребро — be.
Оно соединяет вершины из одного множества, поэтому перейдём
Рассмотрим следующие ребро — be. Оно соединяет вершины из одного множества, поэтому перейдём

Рёбра ec и ed соединяют вершины из одного множества,
поэтому после их просмотра они не будут
Рёбра ec и ed соединяют вершины из одного множества, поэтому после их просмотра они не будут

Parallel Programming in OpenMP standard
"Parallel and distributed programming"
Total amount of intelligence
Parallel Programming in OpenMP standard
"Parallel and distributed programming"
Total amount of intelligence

Content
"Parallel and distributed programming"
Programming model in shared memory
Model "pulsating" parallelism FORK-JOIN
OpenMP
Content
"Parallel and distributed programming"
Programming model in shared memory
Model "pulsating" parallelism FORK-JOIN
OpenMP
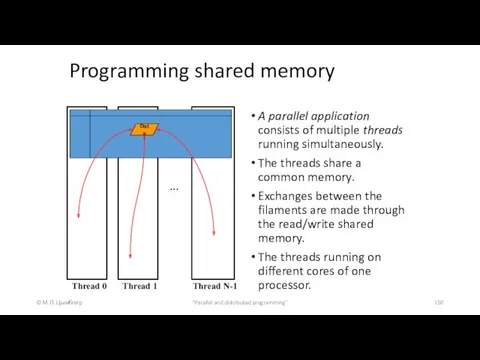
Programming shared memory
© М.Л. Цымблер
"Parallel and distributed programming"
A parallel application consists
Programming shared memory
© М.Л. Цымблер
"Parallel and distributed programming"
A parallel application consists
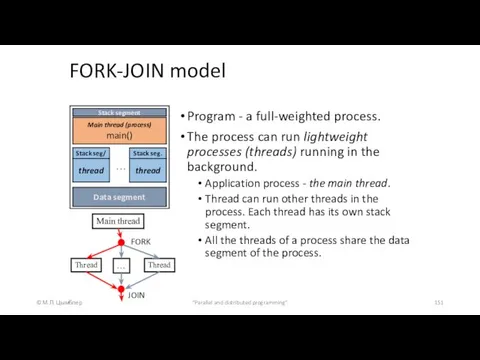
FORK-JOIN model
© М.Л. Цымблер
"Parallel and distributed programming"
Program - a full-weighted process.
The
FORK-JOIN model
© М.Л. Цымблер
"Parallel and distributed programming"
Program - a full-weighted process.
The

Standard OpenMP
© М.Л. Цымблер
"Parallel and distributed programming"
OpenMP (Open Multi-Processing) - a
Standard OpenMP
© М.Л. Цымблер
"Parallel and distributed programming"
OpenMP (Open Multi-Processing) - a
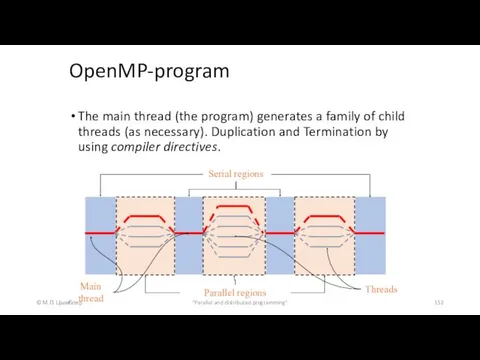
OpenMP-program
© М.Л. Цымблер
"Parallel and distributed programming"
The main thread (the program) generates
OpenMP-program
© М.Л. Цымблер
"Parallel and distributed programming"
The main thread (the program) generates

Simple OpenMP-program
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
printf("Hello!\n");
}
void main()
{
#pragma omp
Simple OpenMP-program
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
printf("Hello!\n");
}
void main() { #pragma omp
Simple OpenMP-program
© М.Л. Цымблер
"Parallel and distributed programming"
Simple OpenMP-program
© М.Л. Цымблер
"Parallel and distributed programming"

Advantages of OpenMP
© М.Л. Цымблер
"Parallel and distributed programming"
Gradual (incremental) paralleling
You can
Advantages of OpenMP
© М.Л. Цымблер
"Parallel and distributed programming"
Gradual (incremental) paralleling
You can

OpenMP directives
© М.Л. Цымблер
"Parallel and distributed programming"
Directives OpenMP - directive C
OpenMP directives
© М.Л. Цымблер
"Parallel and distributed programming"
Directives OpenMP - directive C

Functions of OpenMP library
© М.Л. Цымблер
"Parallel and distributed programming"
The assignment
Functions of OpenMP library
© М.Л. Цымблер
"Parallel and distributed programming"
The assignment

Environment variables OpenMP
© М.Л. Цымблер
"Parallel and distributed programming"
Environment variables control the
Environment variables OpenMP
© М.Л. Цымблер
"Parallel and distributed programming"
Environment variables control the

Variable Scope
© М.Л. Цымблер
"Parallel and distributed programming"
Common variable (shared) - global
Variable Scope
© М.Л. Цымблер
"Parallel and distributed programming"
Common variable (shared) - global

Private and public variables
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
int
Private and public variables
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
int

Private and public variables
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
int
Private and public variables
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
int

Private and public variables
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
int
Private and public variables
© М.Л. Цымблер
"Parallel and distributed programming"
void main()
{
int

Distribution of computations
© М.Л. Цымблер
"Parallel and distributed programming"
Directive computation distribution between
Distribution of computations
© М.Л. Цымблер
"Parallel and distributed programming"
Directive computation distribution between

Directive sections
© М.Л. Цымблер
"Parallel and distributed programming"
Explicit definition of blocks of
Directive sections
© М.Л. Цымблер
"Parallel and distributed programming"
Explicit definition of blocks of

Directive single
© М.Л. Цымблер
"Parallel and distributed programming"
Specifies a code that is
Directive single
© М.Л. Цымблер
"Parallel and distributed programming"
Specifies a code that is

Directive master
© М.Л. Цымблер
"Parallel and distributed programming"
Specifies a code that is
Directive master
© М.Л. Цымблер
"Parallel and distributed programming"
Specifies a code that is
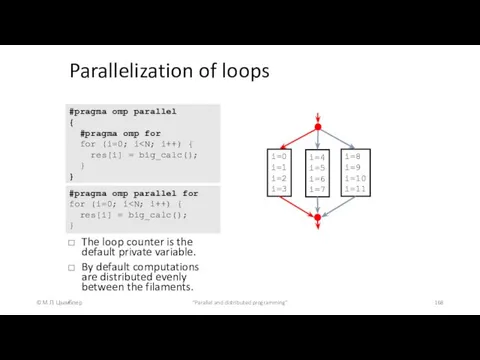
Parallelization of loops
© М.Л. Цымблер
"Parallel and distributed programming"
The loop counter is
Parallelization of loops
© М.Л. Цымблер
"Parallel and distributed programming"
The loop counter is

Parallelization of loops
© М.Л. Цымблер
"Parallel and distributed programming"
You can explicitly define
Parallelization of loops
© М.Л. Цымблер
"Parallel and distributed programming"
You can explicitly define

Parallelization of loops
© М.Л. Цымблер
"Parallel and distributed programming"
Uncontrolled change thread shared
Parallelization of loops
© М.Л. Цымблер
"Parallel and distributed programming"
Uncontrolled change thread shared

Critical section in cycles
© М.Л. Цымблер
"Parallel and distributed programming"
At any time,
Critical section in cycles
© М.Л. Цымблер
"Parallel and distributed programming"
At any time,

Reduction in a loop
© М.Л. Цымблер
"Parallel and distributed programming"
Reduction involves identifying
Reduction in a loop
© М.Л. Цымблер
"Parallel and distributed programming"
Reduction involves identifying
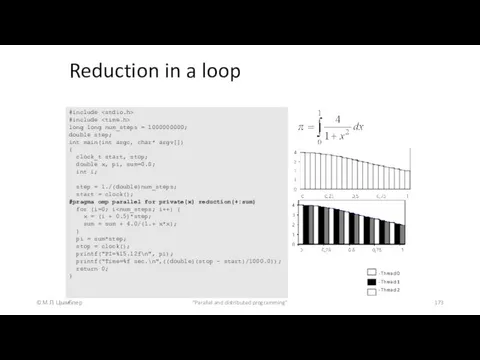
Reduction in a loop
© М.Л. Цымблер
"Parallel and distributed programming"
#include
#include
long
Reduction in a loop
© М.Л. Цымблер
"Parallel and distributed programming"
#include
#include
long

Directive for
© М.Л. Цымблер
"Parallel and distributed programming"
Format directives
#pragma omp parallel for
Directive for
© М.Л. Цымблер
"Parallel and distributed programming"
Format directives
#pragma omp parallel for

Parameter firstprivate
© М.Л. Цымблер
"Parallel and distributed programming"
Defines private loop variables for,
Parameter firstprivate
© М.Л. Цымблер
"Parallel and distributed programming"
Defines private loop variables for,

Parameter lastprivate
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the private variables that
Parameter lastprivate
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the private variables that

Parameter ordered
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the code in the
Parameter ordered
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the code in the

Parameter nowait
© М.Л. Цымблер
"Parallel and distributed programming"
Avoids the implicit barrier at
Parameter nowait
© М.Л. Цымблер
"Parallel and distributed programming"
Avoids the implicit barrier at

Distribution of loop iterations
© М.Л. Цымблер
"Parallel and distributed programming"
The iterations in
Distribution of loop iterations
© М.Л. Цымблер
"Parallel and distributed programming"
The iterations in

Example
© М.Л. Цымблер
"Parallel and distributed programming"
// The amount of work in
Example
© М.Л. Цымблер
"Parallel and distributed programming"
// The amount of work in

Example
© М.Л. Цымблер
"Parallel and distributed programming"
// The threads are suitable for
Example
© М.Л. Цымблер
"Parallel and distributed programming"
// The threads are suitable for

Synchronization algorithms
© М.Л. Цымблер
"Parallel and distributed programming"
Directive explicit synchronization
Critical
barrier
atomic
Directive implicit synchronization
#pragma
Synchronization algorithms
© М.Л. Цымблер
"Parallel and distributed programming"
Directive explicit synchronization
Critical
barrier
atomic
Directive implicit synchronization
#pragma

Directive critical
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the critical section
Directive critical
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the critical section

Directive atomic
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the critical section for
Directive atomic
© М.Л. Цымблер
"Parallel and distributed programming"
Defines the critical section for

Directive barrier
© М.Л. Цымблер
"Parallel and distributed programming"
Determines the barrier - the
Directive barrier
© М.Л. Цымблер
"Parallel and distributed programming"
Determines the barrier - the

Directive barrier
© М.Л. Цымблер
"Parallel and distributed programming"
int main()
{
sub1(2);
sub2(2);
sub3(2);
}
void sub1(int n)
{
int i;
#pragma
Directive barrier
© М.Л. Цымблер
"Parallel and distributed programming"
int main()
{
sub1(2);
sub2(2);
sub3(2);
}
void sub1(int n)
{
int i;
#pragma
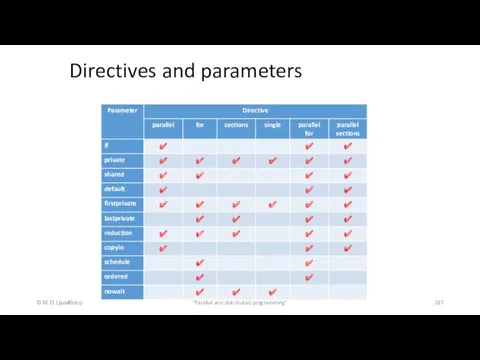
Directives and parameters
© М.Л. Цымблер
"Parallel and distributed programming"
Directives and parameters
© М.Л. Цымблер
"Parallel and distributed programming"

Operation time
© М.Л. Цымблер
"Parallel and distributed programming"
double start;
double end;
start = omp_get_wtime();
//
Operation time
© М.Л. Цымблер
"Parallel and distributed programming"
double start;
double end;
start = omp_get_wtime();
//

Threads count
© М.Л. Цымблер
"Parallel and distributed programming"
// False
np = omp_get_num_threads(); //
Threads count
© М.Л. Цымблер
"Parallel and distributed programming"
// False
np = omp_get_num_threads(); //

© М.Л. Цымблер
"Parallel and distributed programming"
As castles using shared variables of
© М.Л. Цымблер
"Parallel and distributed programming"
As castles using shared variables of

© М.Л. Цымблер
"Parallel and distributed programming"
Causes the calling thread to wait
© М.Л. Цымблер
"Parallel and distributed programming"
Causes the calling thread to wait

Example
© М.Л. Цымблер
"Parallel and distributed programming"
#include
int main()
{
omp_lock_t lck;
int
Example
© М.Л. Цымблер
"Parallel and distributed programming"
#include
int main()
{
omp_lock_t lck;
int

Conclusion
© М.Л. Цымблер
"Parallel and distributed programming"
Programming model in shared memory
Model "pulsating"
Conclusion
© М.Л. Цымблер
"Parallel and distributed programming"
Programming model in shared memory
Model "pulsating"

Information Resources
© М.Л. Цымблер
"Parallel and distributed programming"
Introduction to OpenMP www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
Chandra R.,
Information Resources
© М.Л. Цымблер
"Parallel and distributed programming"
Introduction to OpenMP www.llnl.gov/computing/tutorials/workshops/workshop/openMP/MAIN.html
Chandra R.,

Минимальный перебор в игровых деревьях. Альфа-бета отсечения. Построение игровых программ
Удалова Татьяна
85М21
Минимальный перебор в игровых деревьях. Альфа-бета отсечения. Построение игровых программ
Удалова Татьяна
85М21

Деревья решений
Узел дерева – один шаг решения задачи
Ветвь – решение, которое
Деревья решений
Узел дерева – один шаг решения задачи
Ветвь – решение, которое

Игровые деревья
Моделирование стратегических настольных игр (крестики нолики)
Ветвь, выходящая из узла -
Игровые деревья
Моделирование стратегических настольных игр (крестики нолики)
Ветвь, выходящая из узла -

Минимаксный перебор
Минимизировать максимальное значение, которое может иметь позиция для противника после
Минимаксный перебор
Минимизировать максимальное значение, которое может иметь позиция для противника после

Крестики-нолики(1)
4 значения позиции поля:
4 –игрок выиграет
3 – ситуация не
Крестики-нолики(1)
4 значения позиции поля:
4 –игрок выиграет
3 – ситуация не
![Крестики-нолики(2) Дерево игры крестики-нолики в конце партии[1] Игрок X минимизирует](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/107585/slide-199.jpg)
Крестики-нолики(2)
Дерево игры крестики-нолики в конце партии[1]
Игрок X минимизирует свои потери
Игрок 0
Крестики-нолики(2)
Дерево игры крестики-нолики в конце партии[1]
Игрок X минимизирует свои потери
Игрок 0

Альфа-бета отсечения(1)
Оптимизация минимаксного перебора
Сравнение наилучших оценок, полученных для полностью изученных ветвей,
Альфа-бета отсечения(1)
Оптимизация минимаксного перебора
Сравнение наилучших оценок, полученных для полностью изученных ветвей,

Альфа-бета отсечения(2)
Предположим, что z<=a. После анализа узла Z, когда справедливо соотношение
Альфа-бета отсечения(2)
Предположим, что z<=a. После анализа узла Z, когда справедливо соотношение

Альфа-бета отсечения(4)
Правила вычисления альфа-бета:
у MAX вершины значение a равно наибольшему в
Альфа-бета отсечения(4)
Правила вычисления альфа-бета:
у MAX вершины значение a равно наибольшему в

Альфа-бета отсечения(5)
Правила прекращения поиска:
можно не проводить поиска на поддереве, растущем из
Альфа-бета отсечения(5)
Правила прекращения поиска:
можно не проводить поиска на поддереве, растущем из
![Альфа-бета отсечения(6) [2]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/107585/slide-204.jpg)
Альфа-бета отсечения(6)
[2]
Альфа-бета отсечения(6)
[2]

Программная реализация
Игра крестики-нолики включающая в себя:
Альфа-бета отсечения для расчёта следующего хода
Возможность
Программная реализация
Игра крестики-нолики включающая в себя:
Альфа-бета отсечения для расчёта следующего хода
Возможность

Литература
Rod Stephens. Ready-to-run Delphi© Algorithms. Wiley Computer Publishing.
Интернет-Университет Информационных Технологий. Интеллектуальные
Литература
Rod Stephens. Ready-to-run Delphi© Algorithms. Wiley Computer Publishing.
Интернет-Университет Информационных Технологий. Интеллектуальные
 KNX Manufacturer Tool
KNX Manufacturer Tool Интернет тушунчаси
Интернет тушунчаси Есептеу жүйесі
Есептеу жүйесі Детектор лиц на основе метода Виолы-Джонса
Детектор лиц на основе метода Виолы-Джонса Презентация к первому уроку информатики по Босовой Л.Л. Информация-компьютер-информатика
Презентация к первому уроку информатики по Босовой Л.Л. Информация-компьютер-информатика Особливості уроку інформатики в початковій школі. Лекція 2
Особливості уроку інформатики в початковій школі. Лекція 2 Защита от вредоносных программ
Защита от вредоносных программ Анализ дерева решений
Анализ дерева решений Основы программирования (Python)
Основы программирования (Python) презентация для урока в 10 классе по учебнику Семакина Программирование линейных алгоритмов, Практическая работа №8
презентация для урока в 10 классе по учебнику Семакина Программирование линейных алгоритмов, Практическая работа №8 Атласные информационные системы
Атласные информационные системы Конференция Я - исследователь
Конференция Я - исследователь Информатика. Материалы к лекциям. Построение графиков функций в Excel. Математические функции рабочего листа
Информатика. Материалы к лекциям. Построение графиков функций в Excel. Математические функции рабочего листа Создание сайта на языке HTML и CSS Народные инструменты у кочевников
Создание сайта на языке HTML и CSS Народные инструменты у кочевников Antivirus dasturiy vositalar: kompyuter viruslarining xarakteristikalari, viruslarni aniqlash va ulardan himoya qilish
Antivirus dasturiy vositalar: kompyuter viruslarining xarakteristikalari, viruslarni aniqlash va ulardan himoya qilish CAD SmartSketch. Biesse icons defining machining technologies
CAD SmartSketch. Biesse icons defining machining technologies Математические пакеты для инженерных и научных расчетов. Отладка программ (m-файлов)
Математические пакеты для инженерных и научных расчетов. Отладка программ (m-файлов) Подключение к интернету
Подключение к интернету Градиентный спуск в нейронных сетях
Градиентный спуск в нейронных сетях Компьютер – инструмент подготовки текстов
Компьютер – инструмент подготовки текстов Нормативно-методические основы работы со служебными документами. Лекция №12
Нормативно-методические основы работы со служебными документами. Лекция №12 Python.Основы Циклы While. For. Лекция 3.2
Python.Основы Циклы While. For. Лекция 3.2 Компьютерная графика. Обработка графической информации. Информатика. 7 класс
Компьютерная графика. Обработка графической информации. Информатика. 7 класс Администрирование сетей Microsoft
Администрирование сетей Microsoft Информатика 10 класс Кодирование графической информации
Информатика 10 класс Кодирование графической информации Использование информационных технологий в обработке текстов
Использование информационных технологий в обработке текстов Интернет-зависимость
Интернет-зависимость Текстовые функции
Текстовые функции