- Теория формальных языков и трансляций. LR(k )-грамматики и трансляции

Содержание
- 2. § 3.1. Синтаксический анализ типа “снизу—вверх” В предыдущей части был рассмотрен класс LL(k)-грамматик, наибольший под-класс КС-грамматик,
- 3. Один шаг этого процесса состоит в определении того правила, правая часть которого должна использоваться для замены
- 5. k-предсказывающий алгоритм анализа, воспроизводит открытые части сентен-циальных форм в своём магазине. Простая модификация такого анализатора, выстраивает
- 6. Рис. 3.1. Построение вывода “сверху-вниз”.
- 8. Индекс pi (i = 1, 2,…, n) над стрелкой означает, что на данном шаге нетерминал текущей
- 9. Задача анализатора типа “снизу-вверх”, называемого также восходящим анализа-тором, состоит в том, чтобы найти правосторонний анализ данной
- 10. Рассмотрим один шаг работы такого анализатора. Пусть αi = αAw — текущая сентенциаль-ная форма правостороннего вывода.
- 11. Восходящий анализатор располагает текущую сентенциальную форму αi в магазине и на входной ленте таким образом, что
- 12. Табл. 3.1 B → βAy
- 13. В строке 1 табл. 3.1 представлено рас-положение текущей сентенциальной формы αi, в строке 2 — то
- 14. В строке 3 представлено размещение сентенциальной формы после сдвига в магазин части входа — цепочки y.
- 15. В строке 4 приведен результат свертки цепочки βAy, располагавшейся на предыдущем шаге в верхней части магазина,
- 16. Итак, один шаг работы анализатора типа “снизу-вверх” состоит в последовательном сдвиге символов из входной цепочки в
- 17. Если задача правостороннего анализа решается описанным выше механизмом детерминированно, то свойства КС-грам-матики, в которой производится анализ,
- 19. Пример 3.1. Пусть G = (VN, VT, P, S) — контекстно-свободная грамматика, в кото-рой VN =
- 20. Табл. 3.2
- 21. “Дно” магазина отмечено маркером $. Исходная конфигурация характеризуется тем, что магазин пуст (маркер “дна” не считается),
- 22. Следующее действие по команде shift — сдвиг: текущий символ a перемещается со входа на вершину магазина.
- 23. Рис. 3.2. Построение дерева вывода “снизу-вверх”. (1) (1) (2) (2) (2) Правый анализ ‘aabb’: πR =
- 24. Номера правил при командах свертки (reduce) образуют правосторонний анализ входной цепочки aabb. Не все КС-грамматики поддаются
- 25. Именно: (1) производить сдвиг или свертку? (2) если делать свёртку, то по какому правилу? (3) когда
- 26. В этом параграфе мы дадим строгое определение LR(k)-грамматик и опишем характерные их свойства. Определение 3.1. Пусть
- 27. в которых, должно быть αAy = γBx. Другими словами, α = γ, A = B, y
- 28. Иначе говоря, если согласно выводу 1) β — основа сентенциальной формы αβw, сворачиваемая в нетерминал A
- 29. Из этого определения следует, что если имеется право-выводимая цепочка αi= αβw, где β — основа, полученная
- 33. Если игнорировать 0-е правило, то, не заглядывая в правый контекст основы Sa, можно сказать, что она
- 34. С учётом же 0-го правила имеем:
- 37. Рассмотрим несколько примеров, иллю-стрирующих свойства КС-грамматик, от которых зависят их принадлежность к классу LR.
- 38. Пример 3.3. Пусть грамматика G содержит следующие правила: 1) S → C | D; 2) C
- 41. Другими словами, любая сентенциаль-ная форма должна быть выводима един-ственным способом. Что это именно так, можно убедится
- 42. Пример 3.4. Рассмотрим грамматику G с правилами: 1) S → Ab | Bc; 2) A →
- 43. (aib) = (aic), но A ≠ B.
- 46. Пример 3.5. Рассмотрим грамматику, иллюстрирующую другую причину, по которой она не LR(1): невозможность однозначно определить, что
- 47. C → ab β = ab ACbb ≠ AaE !!!
- 48. § 3.3. LR(k)-Анализатор Аналогично тому, как для LL(k)-грамматик адекватным типом анализаторов является k-предсказывающий алгоритм ана-лиза, поведение
- 50. Подтаблица f по аванцепочке опреде-ляет одно из трёх действий над не-обработанной частью входной цепочки: сдвиг, свёрка,
- 51. 205 222
- 53. Начальная конфигурация есть (T0, x, ε). Далее алгоритм действует согласно следующему описанию в зависимости от того,
- 59. 4: Приём. Пусть текущая конфигурация есть (T0ST, ε, πR), T = ( f, g), f (ε)
- 60. Пример 3.6. Обратимся ещё раз к грамматике из примера 3.1. Как мы увидим далее (см. примеры
- 61. Табл. 3.3 171 189 239 242 215 275 2276 2279 303
- 62. Рассмотрим действия этого анализатора на входной цепочке aabb: (T0ST1aT2 ε, abb, 2) (T0ST1aT2ST3, abb, 22) (T0ST1aT2ST3aT4
- 63. Итак, цепочка aabb принимается, и πR = 22211 — её правосторонний анализ, а π = 11222
- 64. (β ― основа) 201
- 65. Определение 3.5. Пусть G = (VN, VT, P, S) — контекстно-свободная грамматика и A → β1β2∈P.
- 66. 888 137
- 68. Пример 3.7. Обратимся ещё раз к LR(0)-грамматике из примера 3.3, которая содержит следующие правила: 1) S
- 69. C → aC C → b Рассмотрим выводы, дающие активный префикс aaaa, и четыре LR(0)-ситуации, допустимые
- 70. Во всех случаях правый контекст основы (β) пуст (k = 0). D → aD D →
- 71. Лемма 3.2. Пусть G = (VN, VT, P, S) — не LR(k)-грамматика. Тогда существуют два правосторонних
- 73. Условие в) не столь очевидно. Простой обмен ролями этих двух выводов ничего не даёт, так как
- 75. Условие γδx = αβy можно переписать как γδzy = αβy, и потому γδz = αβ. (3.1)
- 76. Вывод 2) разметим по образцу первого с учётом равенства x = zy, а вывод 1) разметим
- 80. RetRet 8Ret 83 88 104
- 81. Иначе говоря, могут представиться следующие случаи: Ясно, что в силу данного определения 104
- 82. тем, что значение не Функция отличается от функции включает префиксы терминальных цепочек, выводимых из α, только
- 84. Любой вывод имеет единственное начало: В искомое множество нужно включить префиксы этих терминальных цепочек длиной 2
- 85. Далее возможны следующие продолжения: w — недопустимо (ε-правило).
- 86. S ⇒ AB ⇒ BaB ⇒ CaB ⇒ aB ⇒ aC ⇒ a S ⇒ AB
- 87. Теорема 3.1. Чтобы cfg G = (VN, VT, P, S) была LR(k)-грамматикой, необходимо и до-статочно, чтобы
- 88. Ret 90 92 91 94 95 96
- 90. Кроме того, выполняется условие 91 Рассмотрим три возможных варианта состава цепочки β2: (1) β2 = ε;
- 93. 96
- 94. При A ≠ A1 равенство (*) невозможно, а при A = A1 и β ≠ β1
- 96. Чтобы грамматика G была LR(k)-грам-матикой, должно быть α1A1x = αAy (*) или, что то же самое,
- 97. 4)
- 98. Последнее равенство возможно лишь при u1u2 = ε и β = ε, чего нет по варианту
- 99. Рассмотренные варианты состава цепочки β2 исчерпывающе доказывают необходи-мость сформулированного условия.
- 100. 101
- 101. Не ограничивая общности рассуждений, можно считать, что αβ — одна из самых коротких цепочек, удовлетворяющих описанным
- 102. Цепочка β1β2 — основа сентенциальной формы α1β1β2 y1, причём β1 — её префикс такой длины, что
- 103. Действительно, если, например, | α1A1 | > | αβ | + 1, т. е. | α1
- 104. 105
- 106. Из факта существования вывода 1) сле-дует, что LR(k)-ситуация [A → β., u], где допустима для активного
- 108. Действительно, если бы то только потому, что цепочка β2 начилась бы с нетерминала, который на последнем
- 113. Не забывая, что это другой вид того же самого вывода 2), заменим цепочку β на A,
- 114. 209
- 115. 139 144 Вход: G = (VN, VT, P, S) — КС-грамматика, γ = X1X2...Xm, Xi∈VN∪VT ,
- 116. 130 147 148 150 121 145 146 147 210 222 156 193
- 117. 120
- 118. 141 145 147 148 149 1135 143 14146 14142 Заметим, что именно это значение v наследуется
- 119. Замечание 3.2. Алгоритм 3.2 не требует использования пополненной грамматики. 1156
- 120. Определение 3.9. Пусть G = (VN, VT, P, S) — контекстно-свободная грамматика. На множестве LR(k)-ситуаций в
- 122. Ret 1Ret 162
- 123. = {[S′→ .S, ε], [S → .SaSb, ε], [S → ., ε], [S → .SaSb, a],
- 124. 2: построение множества а) {[S′→ S., ε], [S → S.aSb, ε | a]}. Так как точка
- 126. Теорема 3.2. Алгоритм 3.2 правильно вычисляет , где γ∈(VN ∪ VT)* — актив-ный префикс право-сентенциальной формы
- 127. 239
- 131. … [Am – 1 → Amαm, vm – 1]∈ для любой в частности для Наконец, поскольку
- 137. Рассмотрим подробнее этот вывод, чтобы показать, как впервые появляется символ X, завершающий цепочку α, и как
- 138. В общем случае он имеет следующий вид: (∃ A1 → α2’XA2δ2∈P,), … (∃ A2 → A3δ1∈P),
- 139. (∃ Am – 1 → Amδm∈P), (Am = A, wmwm – 1…w1 = w), (∃ A
- 141. Поскольку | γ’ | = n, то в соответствии с индукционной гипотезой можно утверж-дать, что а
- 145. База. Пусть l = 0, т. е. γ = ε. В этом случае αβ1 = γ
- 147. ...
- 152. Другими словами, [A → β1.β2, u] — LR(k)-ситуация, допустимая для активного префикса γ. Из того, что
- 156. Извлечём теперь полезные следствия из вышеизложенной истории. Из п.1 алгоритма 3.2 согласно индукционной гипотезе следует существо-вание
- 158. 179 173 174 176 210
- 159. 2. Пусть ∈ и — не помечено. Пометить и построить множество = GOTO ( , X)
- 162. 2298 57 1185 206
- 164. Переходы из : Поскольку за позиционной точкой в каждой ситуации не следует нетерминал, то замыкание не
- 165. Переходы из : Замыкание (1) Замыкание ситуации (2) ничего нового не даёт!
- 171. Таб. 3.4 206
- 179. Согласно алгоритму 3.3 включается в множество на первом же шаге.
- 183. Ret Ret 199
- 184. 185
- 192. = {[S′→ .S, ε], [S → .aS, ε], [S → .ε, ε]}. Пример II-3.11 (а) Дана
- 195. [S → .ε, ε]∈ . Не существует X∉(VT ∪ VN), и ничего делать не надо.
- 197. [S → .aS, ε | a], [S → ., ε | a]} Вычисление GOTO для даёт
- 198. [S → ., ε | a]∈ (1) [S → a.S, ε | a] ∈ Условие противоречия
- 199. Условие противоречия по (2): {ε | a} ∩ {a} = {a} ≠ ∅ ― противоречие! Проверка
- 201. Теорема 3.4. Алгоритм 3.4 дает правильный ответ, т. е. является правиль-ным алгоритмом тестирования. Доказательство. Утверждение теоремы
- 202. Определение 3.12. Пусть G = (VN, VT, P, S) — контекстно-свободная грамматика и — каноническое множество
- 203. 1 Напомним, что под нулевым номером числится правило S’ → S, пополняющее данную грамматику G. Функция
- 204. в) f (u) = accept, если [S ’→ S., ε]∈ и u = ε; г) f
- 207. Обычно LR(k)-анализатор представляется управляющей таблицей, каждая строка которой является LR(k)-таблицей. Определение 3.15. Описанный ранее алгоритм 3.1
- 208. Пример 3.12. Построим каноническую систему LR(k)-таблиц для грамматики из примера 3.10, содержащей следующие правила: 0) S’→
- 209. Табл. T0 Поскольку = {[S’ → .S, ε], [S → .SaSb, ε | a], [S →.,
- 210. Табл. T1
- 211. Табл. T2
- 212. Табл. T3
- 213. Табл. T4
- 214. Табл. T5
- 215. Табл. T6
- 216. Табл. T7
- 217. Все эти LR(k)-таблицы сведены в управляющую таблицу 3.1 канонического LR(k)-анализатора, которая была приведена в примере 3.6.
- 218. Канонический LR(k)-анализатор обладает следующими свойствами: 1. Простая индукция по числу шагов анали-затора показывает, что каждая LR(k)-табли-ца,
- 219. Поэтому, как только k символов необработанной части входной цепочки оказываются такими, что нет суффикса, который вместе
- 220. В каждый момент его работы цепочка символов грамматики, хранящаяся в мага-зине, должна быть активным префиксом грамматики.
- 222. 3. Если в конфигурации, указанной в п.2, fj (u) = reduce i и A → Y1Y2
- 223. 4. Если fj (u) = accept, то u = ε. Содержимое магазина в этот момент имеет
- 224. 5. Можно построить детерминированный магазинный преобразователь (dpdt), реали-зующий канонический LR(k)-алгоритм разбо-ра. Действительно, так как аванцепочку можно
- 225. § 3.7. Корректность LR(k)-анализаторов Теорема 3.5. Канонический LR(k)-алгоритм правильно находит правый разбор входной цепочки, если он
- 226. 215
- 235. Поскольку A → β = β’z ∈ P, то α’β’ — актив-ный префикс право-сентенциальной формы α’β’zw,
- 237. fm + p – 1(vp) = shift для
- 239. Последний переход обоснован индук-ционной гипотезой с учётом того, что
- 242. существует множество LR(k)-ситуаций = GOTO ( , a1) и таблица T1 = T( ), T1 =
- 245. Случай 1: shift-движение. Это движение происходит следующим образом: (T0X1T1X2 ... XmTm, x’, π’R) = = (T0X1T1X2
- 246. Так как x’ = Xm + 1x, то X1X2 ... Xm Xm + 1x = X1X2
- 247. Случай 2: reduce i -движение. Имеем конфигурацию, достигнутую за пер-вые n движений: (T0X1T1X2 ... XmTm, x’,
- 252. Теорема 3.6. Если G = (VN, VT, P, S) — LR(k)-грамматика, то грамматика G — синтаксически
- 253. Покажем, что тогда в этой грамматике нарушается LR(k)-условие (см. теор. 3.2.). Найдём наименьшее i, при котором
- 256. Последнее равенство имеет место, так как β2∈VT*. Существование этих двух LR(k)-ситуаций, допустимых для одного и того
- 257. Теорема 3.7. Пусть G = (VN, VT, P, S) — LR(k)-грамматика. Канонический LR(k)-анализатор, построенный по G,
- 259. Тогда вследствие теоремы 3.5 существовало бы как угодно много правосторонних выводов сколь угодно большой длины одной
- 261. Замечание 3.6. LR(k)-анализатор на ошибочных цепочках “зациклиться” не может. Цепочка — ошибочная, если для некоторого её
- 262. § 3.8. Простые постфиксные синтаксически управляемые LR-трансляции Мы знаем, что простые семантически однозначные схемы синтаксически управ-ляемых
- 263. Аналогичную ситуацию интересно рассмотреть в отношении схем с LR(k)-грамматиками в качестве входных. К сожалению, существуют такие
- 264. Ret 267
- 266. Этому множеству соответствует управля-ющая таблица LR(1)-анализатора (табл. 3.5). Табл. 3.5
- 269. То, что в начале и в конце выходной цепочки должна быть порождена буква a, определяется лишь
- 270. Естественный способ получить на выходе цепочку wR — запомнить w в магазине, а затем выдать цепочку
- 271. Где ещё, помимо магазина, могла бы быть информация для восстановления цепочки w? — Только в состояниях
- 272. Короче говоря, dpdt, который мог бы реализовать описанную трансляцию, не существует. Однако, если простая синтак-сически управляемая
- 274. Теорема 3.8. Пусть T = (N, Σ, Δ, R, S) — простая семантически однозначная пост-фиксная схема
- 275. Доказательство. По входной грамматике схемы T можно построить канонический LR(k)-анализатор, а затем моделировать его работу посредством
- 276. В момент принятия входной цепочки dpdt P переходит в конечное состояние. Именно: если правило с номером
- 277. Пример 3.14. Пусть имеется простая схема T с правилами 0) S’→ S, S; 1) S →
- 278. Эта же таблица может быть использована LR(1)-транслятором, который отличается от анализатора только тем, что вместо номера
- 280. Руководствуясь табл. 3.3, LR(1)-транс-лятор совершает следующие движения: (T0, aabb, ε) (T0ST1, aabb, ε)
- 281. Каждый раз, когда происходит свёртка по правилу 1 схемы, на выход посылается символ ‘c’. В таблице
- 282. § 3.9. Простые непостфиксные синтаксически управляемые LR-трансляции Предположим, что имеется простая, но не постфиксная sdts, входная
- 283. Пусть T = (N, Σ, Δ, R, S) — простая семантически однозначная sdts с входной LR(k)-грамматикой
- 284. Рис. 3.3. Четырёхуровневая схема перевода.
- 285. Первый уровень занимает dpdt P1. Его входом служит входная цепочка w$, а выходом πR — правосторонний
- 286. На втором уровне dpdt P2 обращает цепочку πR. Для этого ему достаточно поместить всю цепочку πR
- 287. На следующем 3-м этапе цепочка π используется для порождения соответству-ющей инвертированной выходной цепочки yR правосторонним выводом
- 288. где R′ содержит правило вида A → iBmBm–1 ... B1, ymBmym–1Bm–1 ... y1B1y0 тогда и только
- 289. Нетрудно доказать, что (π, yR) ∈ τ(T′) тогда и только тогда, когда Схема T′ — это
- 290. На четвертом уровне dpdt P4 просто обращает цепочку yR — выход P3, записы-вая его в магазин
- 291. Число основных операций, выполняемых на каждом уровне, пропорционально длине цепочки w. Таким образом, можно сформулировать следующий
- 292. Теорема 3.9. Трансляция, задаваемая простой семантически однозначной схемой синтаксически управляемой трансляции с входной LR(k)-грамматикой, может быть
- 293. § 3.10. LALR(k)-Грамматики На практике часто используются частные подклассы LR(k)-грамматик, анализаторы для которых имеют более компактные
- 295. Определение 3.18. Пусть G — контекстно-свободная грамматика, — каноническая система множеств LR(k)-ситуаций для грамматики G и
- 296. Другими словами, если слить все множества LR(k)-ситуаций с одинаковыми наборами ядер в одно множество и окажется,
- 297. Число множеств, полученных при таком слиянии, разве лишь уменьшится. Соответственно уменьшится и число LR(k)-таблиц. Последние строятся
- 299. = {[S’ → .S, ε], [S → .SaSb, ε | a], [S → ., ε |
- 301. Системе объединённых множеств LR(1)-ситуаций соответствует управляющая таблица: Табл. 3.6
- 302. Отметим, что анализатор, использующий LALR(k)-таблицы, может чуть запаздывать с обнаружением ошибки по отношению к анализатору, использующему
- 305. Скачать презентацию

§ 3.1. Синтаксический анализ
типа “снизу—вверх”
В предыдущей части был
§ 3.1. Синтаксический анализ
типа “снизу—вверх”
В предыдущей части был

Один шаг этого процесса состоит в определении того правила, правая
Один шаг этого процесса состоит в определении того правила, правая


k-предсказывающий алгоритм анализа, воспроизводит открытые части сентен-циальных форм в своём
k-предсказывающий алгоритм анализа, воспроизводит открытые части сентен-циальных форм в своём
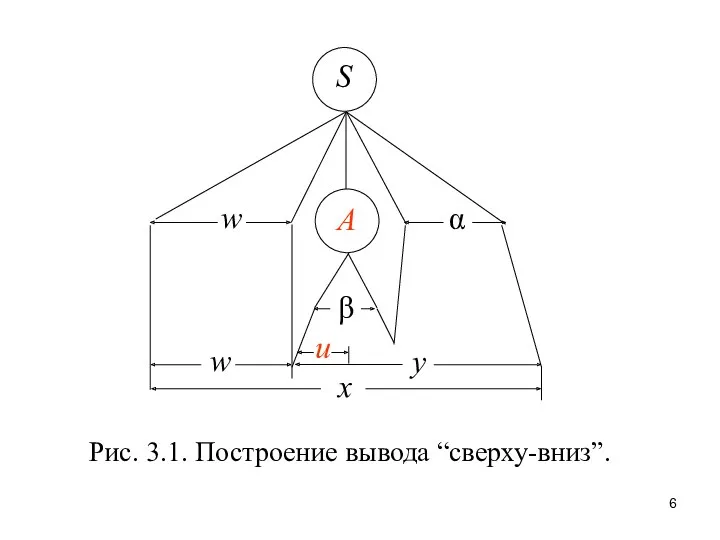
Рис. 3.1. Построение вывода “сверху-вниз”.
Рис. 3.1. Построение вывода “сверху-вниз”.


Индекс pi (i = 1, 2,…, n) над стрелкой означает,
Индекс pi (i = 1, 2,…, n) над стрелкой означает,

Задача анализатора типа “снизу-вверх”, называемого также восходящим анализа-тором, состоит в
Задача анализатора типа “снизу-вверх”, называемого также восходящим анализа-тором, состоит в

Рассмотрим один шаг работы такого
анализатора.
Пусть αi =
Рассмотрим один шаг работы такого
анализатора.
Пусть αi =

Восходящий анализатор располагает текущую сентенциальную форму αi в магазине и
Восходящий анализатор располагает текущую сентенциальную форму αi в магазине и
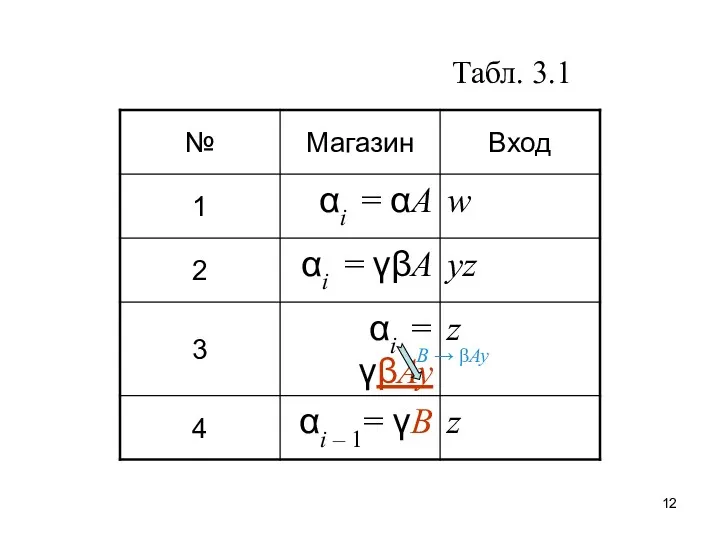
Табл. 3.1
B → βAy
Табл. 3.1
B → βAy

В строке 1 табл. 3.1 представлено рас-положение текущей сентенциальной формы
В строке 1 табл. 3.1 представлено рас-положение текущей сентенциальной формы

В строке 3 представлено размещение сентенциальной формы после сдвига в
В строке 3 представлено размещение сентенциальной формы после сдвига в

В строке 4 приведен результат свертки цепочки βAy, располагавшейся на
В строке 4 приведен результат свертки цепочки βAy, располагавшейся на

Итак, один шаг работы анализатора типа “снизу-вверх” состоит в последовательном
Итак, один шаг работы анализатора типа “снизу-вверх” состоит в последовательном

Если задача правостороннего анализа решается описанным выше механизмом детерминированно, то
Если задача правостороннего анализа решается описанным выше механизмом детерминированно, то


Пример 3.1. Пусть G = (VN, VT, P, S) —
Пример 3.1. Пусть G = (VN, VT, P, S) —
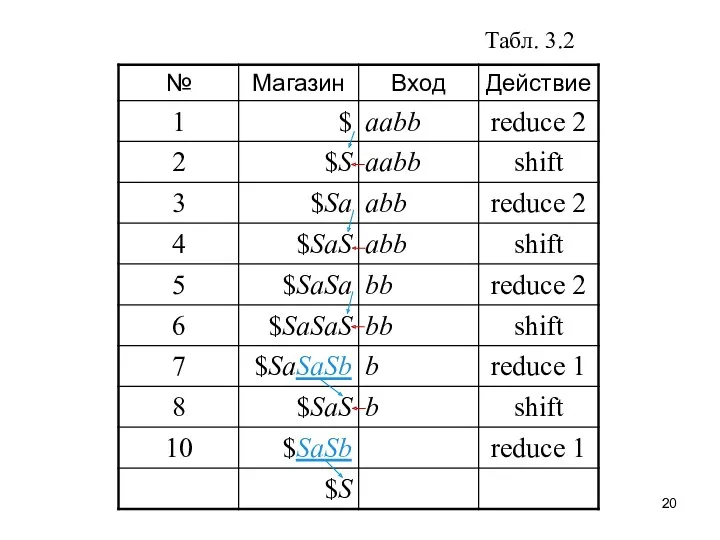
Табл. 3.2
Табл. 3.2

“Дно” магазина отмечено маркером $. Исходная конфигурация характеризуется тем, что
“Дно” магазина отмечено маркером $. Исходная конфигурация характеризуется тем, что

Следующее действие по команде shift — сдвиг: текущий символ a
Следующее действие по команде shift — сдвиг: текущий символ a
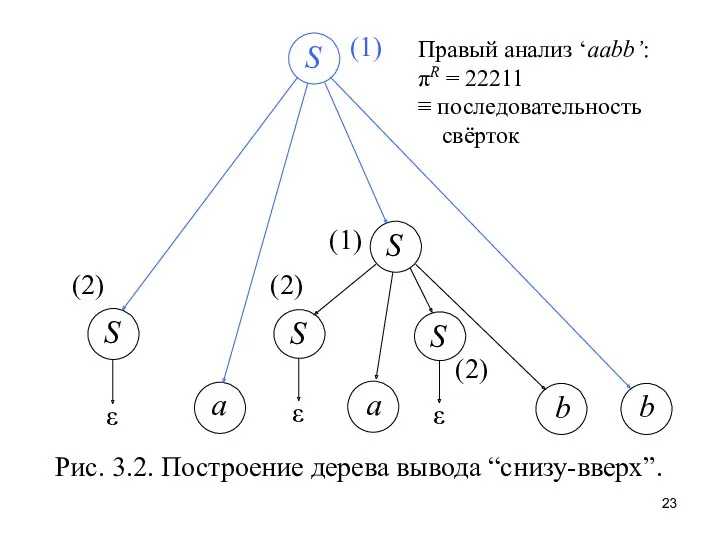
Рис. 3.2. Построение дерева вывода “снизу-вверх”.
(1)
(1)
(2)
(2)
(2)
Правый анализ ‘aabb’:
πR = 22211
≡ последовательность
Рис. 3.2. Построение дерева вывода “снизу-вверх”.
(1)
(1)
(2)
(2)
(2)
Правый анализ ‘aabb’:
πR = 22211
≡ последовательность

Номера правил при командах свертки (reduce) образуют правосторонний анализ входной
Номера правил при командах свертки (reduce) образуют правосторонний анализ входной

Именно:
(1) производить сдвиг или
свертку?
(2)
Именно:
(1) производить сдвиг или
свертку?
(2)

В этом параграфе мы дадим строгое определение LR(k)-грамматик и опишем
В этом параграфе мы дадим строгое определение LR(k)-грамматик и опишем

в которых,
должно быть αAy = γBx.
Другими словами,
в которых,
должно быть αAy = γBx.
Другими словами,

Иначе говоря, если согласно выводу 1) β — основа сентенциальной
Иначе говоря, если согласно выводу 1) β — основа сентенциальной

Из этого определения следует, что если имеется право-выводимая цепочка αi=
Из этого определения следует, что если имеется право-выводимая цепочка αi=




Если игнорировать 0-е правило, то, не заглядывая в правый контекст
Если игнорировать 0-е правило, то, не заглядывая в правый контекст

С учётом же 0-го правила имеем:
С учётом же 0-го правила имеем:



Рассмотрим несколько примеров, иллю-стрирующих свойства КС-грамматик, от которых зависят их
Рассмотрим несколько примеров, иллю-стрирующих свойства КС-грамматик, от которых зависят их

Пример 3.3. Пусть грамматика G содержит следующие правила:
1) S
Пример 3.3. Пусть грамматика G содержит следующие правила:
1) S



Другими словами, любая сентенциаль-ная форма должна быть выводима един-ственным способом.
Другими словами, любая сентенциаль-ная форма должна быть выводима един-ственным способом.

Пример 3.4. Рассмотрим грамматику G с правилами:
1) S →
Пример 3.4. Рассмотрим грамматику G с правилами:
1) S →

(aib) =
(aic), но A ≠ B.
(aib) =
(aic), но A ≠ B.



Пример 3.5. Рассмотрим грамматику, иллюстрирующую другую причину, по которой она
Пример 3.5. Рассмотрим грамматику, иллюстрирующую другую причину, по которой она

C → ab
β = ab
ACbb ≠ AaE !!!
C → ab
β = ab
ACbb ≠ AaE !!!

§ 3.3. LR(k)-Анализатор
Аналогично тому, как для LL(k)-грамматик адекватным типом
§ 3.3. LR(k)-Анализатор
Аналогично тому, как для LL(k)-грамматик адекватным типом


Подтаблица f по аванцепочке опреде-ляет одно из трёх действий над
Подтаблица f по аванцепочке опреде-ляет одно из трёх действий над

205
222
205
222


Начальная конфигурация есть (T0, x, ε).
Далее алгоритм действует согласно следующему
Начальная конфигурация есть (T0, x, ε).
Далее алгоритм действует согласно следующему






4: Приём.
Пусть текущая конфигурация есть
(T0ST, ε, πR),
4: Приём.
Пусть текущая конфигурация есть
(T0ST, ε, πR),

Пример 3.6. Обратимся ещё раз к грамматике из примера 3.1.
Пример 3.6. Обратимся ещё раз к грамматике из примера 3.1.
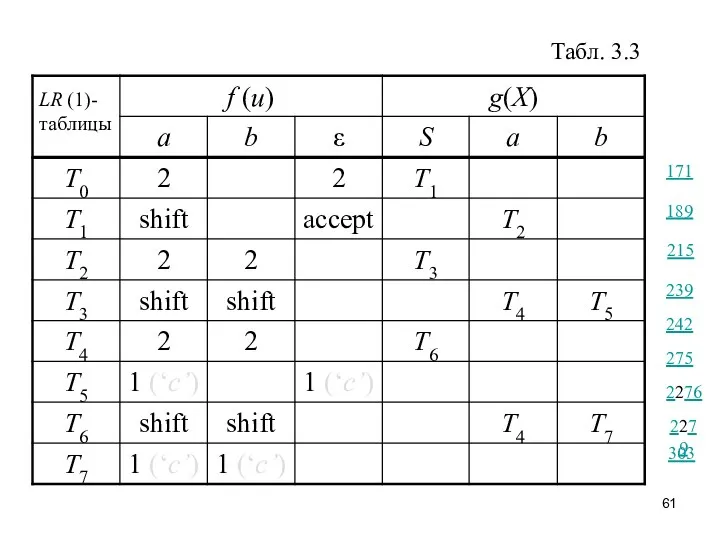
Табл. 3.3
171
189
239
242
215
275
2276
2279
303
Табл. 3.3
171
189
239
242
215
275
2276
2279
303

Рассмотрим действия этого анализатора на входной цепочке aabb:
(T0ST1aT2 ε,
Рассмотрим действия этого анализатора на входной цепочке aabb:
(T0ST1aT2 ε,

Итак, цепочка aabb принимается, и
πR = 22211 — её
Итак, цепочка aabb принимается, и
πR = 22211 — её

(β ― основа)
201
(β ― основа)
201

Определение 3.5. Пусть G = (VN, VT, P, S) —
Определение 3.5. Пусть G = (VN, VT, P, S) —

888
137
888
137


Пример 3.7. Обратимся ещё раз к LR(0)-грамматике из примера 3.3,
Пример 3.7. Обратимся ещё раз к LR(0)-грамматике из примера 3.3,

C → aC
C → b
Рассмотрим выводы, дающие активный префикс aaaa,
C → aC
C → b
Рассмотрим выводы, дающие активный префикс aaaa,

Во всех случаях правый контекст основы (β) пуст (k =
Во всех случаях правый контекст основы (β) пуст (k =

Лемма 3.2. Пусть G = (VN, VT, P, S) —
Лемма 3.2. Пусть G = (VN, VT, P, S) —


Условие в) не столь очевидно. Простой обмен ролями этих двух
Условие в) не столь очевидно. Простой обмен ролями этих двух


Условие γδx = αβy можно переписать как γδzy = αβy,
Условие γδx = αβy можно переписать как γδzy = αβy,

Вывод 2) разметим по образцу первого с учётом равенства x
Вывод 2) разметим по образцу первого с учётом равенства x




RetRet 8Ret 83
88
104
RetRet 8Ret 83
88
104

Иначе говоря, могут представиться следующие случаи:
Ясно, что в силу данного
Иначе говоря, могут представиться следующие случаи:
Ясно, что в силу данного

тем, что значение не
Функция отличается от функции
включает префиксы терминальных
тем, что значение не
Функция отличается от функции
включает префиксы терминальных


Любой вывод имеет единственное начало:
В искомое множество нужно
Любой вывод имеет единственное начало:
В искомое множество нужно

Далее возможны следующие продолжения:
w — недопустимо (ε-правило).
Далее возможны следующие продолжения:
w — недопустимо (ε-правило).

S ⇒ AB ⇒ BaB ⇒ CaB ⇒ aB ⇒ aC
S ⇒ AB ⇒ BaB ⇒ CaB ⇒ aB ⇒ aC

Теорема 3.1. Чтобы cfg G = (VN, VT, P, S)
Теорема 3.1. Чтобы cfg G = (VN, VT, P, S)

Ret 90
92
91
94
95
96
Ret 90
92
91
94
95
96


Кроме того, выполняется условие
91
Рассмотрим три возможных варианта состава
Кроме того, выполняется условие
91
Рассмотрим три возможных варианта состава



96
96

При A ≠ A1 равенство (*) невозможно, а при A
При A ≠ A1 равенство (*) невозможно, а при A


Чтобы грамматика G была LR(k)-грам-матикой, должно быть α1A1x = αAy
Чтобы грамматика G была LR(k)-грам-матикой, должно быть α1A1x = αAy

4)
4)

Последнее равенство возможно лишь при u1u2 = ε и β
Последнее равенство возможно лишь при u1u2 = ε и β

Рассмотренные варианты состава цепочки β2 исчерпывающе доказывают необходи-мость сформулированного условия.
Рассмотренные варианты состава цепочки β2 исчерпывающе доказывают необходи-мость сформулированного условия.

101
101

Не ограничивая общности рассуждений, можно считать, что αβ — одна
Не ограничивая общности рассуждений, можно считать, что αβ — одна

Цепочка β1β2 — основа сентенциальной формы α1β1β2 y1, причём β1
Цепочка β1β2 — основа сентенциальной формы α1β1β2 y1, причём β1

Действительно, если, например, | α1A1 | > | αβ |
Действительно, если, например, | α1A1 | > | αβ |

105
105


Из факта существования вывода 1) сле-дует, что LR(k)-ситуация [A →
Из факта существования вывода 1) сле-дует, что LR(k)-ситуация [A →


Действительно, если бы то только потому, что цепочка β2 начилась
Действительно, если бы то только потому, что цепочка β2 начилась





Не забывая, что это другой вид того же самого вывода
Не забывая, что это другой вид того же самого вывода

209
209

139
144
Вход: G = (VN, VT, P, S) — КС-грамматика,
γ
139
144
Вход: G = (VN, VT, P, S) — КС-грамматика,
γ

130
147
148
150
121
145
146
147
210
222
156
193
130
147
148
150
121
145
146
147
210
222
156
193

120
120

141
145
147
148
149
1135
143
14146
14142
Заметим, что именно это значение v наследуется ситуациями на базе
141
145
147
148
149
1135
143
14146
14142
Заметим, что именно это значение v наследуется ситуациями на базе

Замечание 3.2. Алгоритм 3.2 не требует использования пополненной грамматики.
1156
Замечание 3.2. Алгоритм 3.2 не требует использования пополненной грамматики.
1156

Определение 3.9. Пусть G = (VN, VT, P, S) — контекстно-свободная
Определение 3.9. Пусть G = (VN, VT, P, S) — контекстно-свободная


Ret 1Ret 162
Ret 1Ret 162
![= {[S′→ .S, ε], [S → .SaSb, ε], [S →](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-122.jpg)
= {[S′→ .S, ε], [S → .SaSb, ε], [S →
= {[S′→ .S, ε], [S → .SaSb, ε], [S →
![2: построение множества а) {[S′→ S., ε], [S → S.aSb,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-123.jpg)
2: построение множества
а) {[S′→ S., ε], [S → S.aSb, ε
2: построение множества
а) {[S′→ S., ε], [S → S.aSb, ε


Теорема 3.2. Алгоритм 3.2 правильно вычисляет , где γ∈(VN ∪
Теорема 3.2. Алгоритм 3.2 правильно вычисляет , где γ∈(VN ∪

239
239



![… [Am – 1 → Amαm, vm – 1]∈ для](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-130.jpg)
…
[Am – 1 → Amαm, vm – 1]∈
для любой
…
[Am – 1 → Amαm, vm – 1]∈
для любой






Рассмотрим подробнее этот вывод, чтобы показать, как впервые появляется символ X,
Рассмотрим подробнее этот вывод, чтобы показать, как впервые появляется символ X,

В общем случае он имеет следующий вид:
(∃ A1 → α2’XA2δ2∈P,),
…
(∃
В общем случае он имеет следующий вид:
(∃ A1 → α2’XA2δ2∈P,),
…
(∃
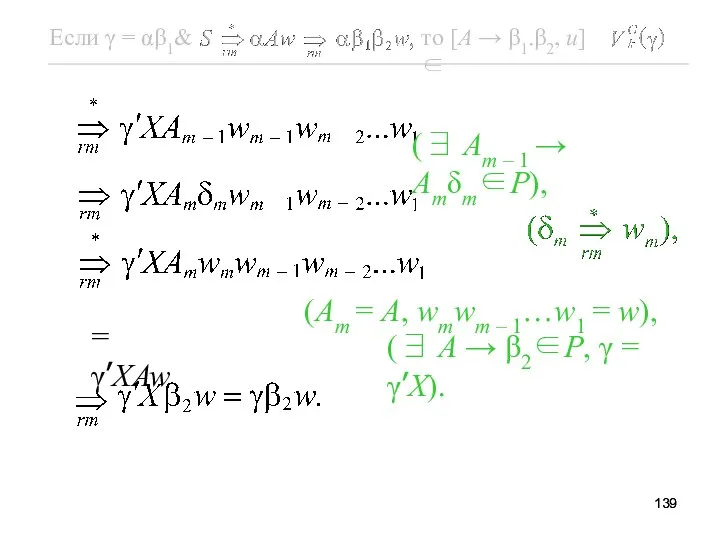
(∃ Am – 1 → Amδm∈P),
(Am = A, wmwm –
(∃ Am – 1 → Amδm∈P),
(Am = A, wmwm –


Поскольку | γ’ | = n, то в соответствии с
Поскольку | γ’ | = n, то в соответствии с




База. Пусть l = 0, т. е. γ = ε.
База. Пусть l = 0, т. е. γ = ε.


...
...




![Другими словами, [A → β1.β2, u] — LR(k)-ситуация, допустимая для](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-151.jpg)
Другими словами, [A → β1.β2, u] — LR(k)-ситуация, допустимая для
Другими словами, [A → β1.β2, u] — LR(k)-ситуация, допустимая для




Извлечём теперь полезные следствия из вышеизложенной истории.
Из п.1
Извлечём теперь полезные следствия из вышеизложенной истории.
Из п.1


179
173
174
176
210
179
173
174
176
210

2. Пусть ∈ и — не помечено.
Пометить и построить
2. Пусть ∈ и — не помечено.
Пометить и построить



2298
57
1185
206
2298
57
1185
206


Переходы из :
Поскольку за позиционной точкой в каждой ситуации не
Переходы из :
Поскольку за позиционной точкой в каждой ситуации не

Переходы из :
Замыкание (1)
Замыкание ситуации (2) ничего нового не даёт!
Переходы из :
Замыкание (1)
Замыкание ситуации (2) ничего нового не даёт!





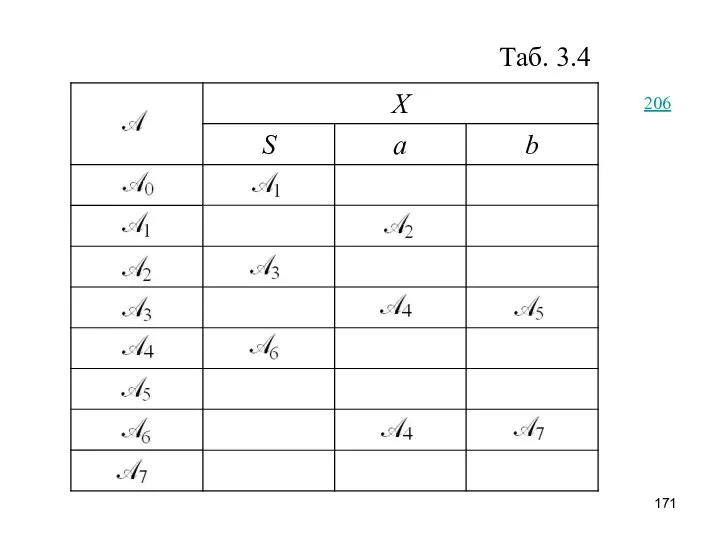
Таб. 3.4
206
Таб. 3.4
206








Согласно алгоритму 3.3 включается в множество на первом же шаге.
Согласно алгоритму 3.3 включается в множество на первом же шаге.




Ret Ret 199
Ret Ret 199

185
185







![= {[S′→ .S, ε], [S → .aS, ε], [S →](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-191.jpg)
= {[S′→ .S, ε],
[S → .aS, ε],
[S → .ε,
= {[S′→ .S, ε],
[S → .aS, ε],
[S → .ε,


![[S → .ε, ε]∈ . Не существует X∉(VT ∪ VN), и ничего делать не надо.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-194.jpg)
[S → .ε, ε]∈ . Не существует X∉(VT ∪ VN), и
[S → .ε, ε]∈ . Не существует X∉(VT ∪ VN), и

![[S → .aS, ε | a], [S → ., ε](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-196.jpg)
[S → .aS, ε | a], [S → ., ε
[S → .aS, ε | a], [S → ., ε
![[S → ., ε | a]∈ (1) [S → a.S,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-197.jpg)
[S → ., ε | a]∈
(1) [S → a.S, ε |
[S → ., ε | a]∈
(1) [S → a.S, ε |

Условие противоречия по (2):
{ε | a} ∩ {a} = {a} ≠
Условие противоречия по (2):
{ε | a} ∩ {a} = {a} ≠


Теорема 3.4. Алгоритм 3.4 дает правильный ответ, т. е. является
Теорема 3.4. Алгоритм 3.4 дает правильный ответ, т. е. является

Определение 3.12. Пусть G = (VN, VT, P, S) —
Определение 3.12. Пусть G = (VN, VT, P, S) —

1 Напомним, что под нулевым номером числится правило S’ → S,
1 Напомним, что под нулевым номером числится правило S’ → S,
![в) f (u) = accept, если [S ’→ S., ε]∈](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-203.jpg)
в) f (u) = accept, если [S ’→ S., ε]∈ и
в) f (u) = accept, если [S ’→ S., ε]∈ и



Обычно LR(k)-анализатор представляется управляющей таблицей, каждая строка которой является LR(k)-таблицей.
Обычно LR(k)-анализатор представляется управляющей таблицей, каждая строка которой является LR(k)-таблицей.

Пример 3.12. Построим каноническую систему LR(k)-таблиц для грамматики из примера
Пример 3.12. Построим каноническую систему LR(k)-таблиц для грамматики из примера
![Табл. T0 Поскольку = {[S’ → .S, ε], [S →](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-208.jpg)
Табл. T0
Поскольку
= {[S’ → .S, ε], [S →
Табл. T0
Поскольку
= {[S’ → .S, ε], [S →

Табл. T1
Табл. T1

Табл. T2
Табл. T2

Табл. T3
Табл. T3

Табл. T4
Табл. T4

Табл. T5
Табл. T5

Табл. T6
Табл. T6

Табл. T7
Табл. T7

Все эти LR(k)-таблицы сведены в управляющую таблицу 3.1 канонического LR(k)-анализатора,
Все эти LR(k)-таблицы сведены в управляющую таблицу 3.1 канонического LR(k)-анализатора,

Канонический LR(k)-анализатор обладает следующими свойствами:
1. Простая индукция по числу шагов
Канонический LR(k)-анализатор обладает следующими свойствами:
1. Простая индукция по числу шагов

Поэтому, как только k символов необработанной части входной цепочки оказываются
Поэтому, как только k символов необработанной части входной цепочки оказываются

В каждый момент его работы цепочка символов грамматики, хранящаяся в
В каждый момент его работы цепочка символов грамматики, хранящаяся в


3. Если в конфигурации, указанной в п.2, fj (u) = reduce
3. Если в конфигурации, указанной в п.2, fj (u) = reduce

4. Если fj (u) = accept, то u = ε. Содержимое
4. Если fj (u) = accept, то u = ε. Содержимое

5. Можно построить детерминированный магазинный преобразователь (dpdt), реали-зующий канонический LR(k)-алгоритм разбо-ра.
5. Можно построить детерминированный магазинный преобразователь (dpdt), реали-зующий канонический LR(k)-алгоритм разбо-ра.

§ 3.7. Корректность LR(k)-анализаторов
Теорема 3.5. Канонический LR(k)-алгоритм правильно находит
§ 3.7. Корректность LR(k)-анализаторов
Теорема 3.5. Канонический LR(k)-алгоритм правильно находит

215
215









Поскольку A → β = β’z ∈ P, то α’β’
Поскольку A → β = β’z ∈ P, то α’β’
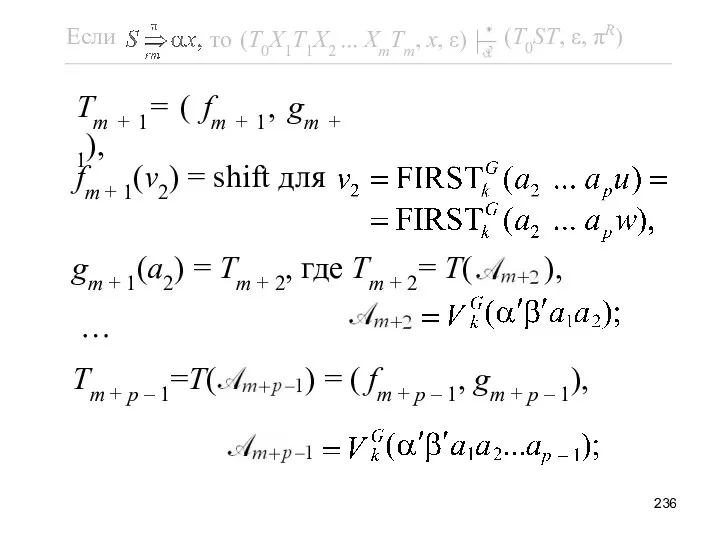

fm + p – 1(vp) = shift для
fm + p – 1(vp) = shift для
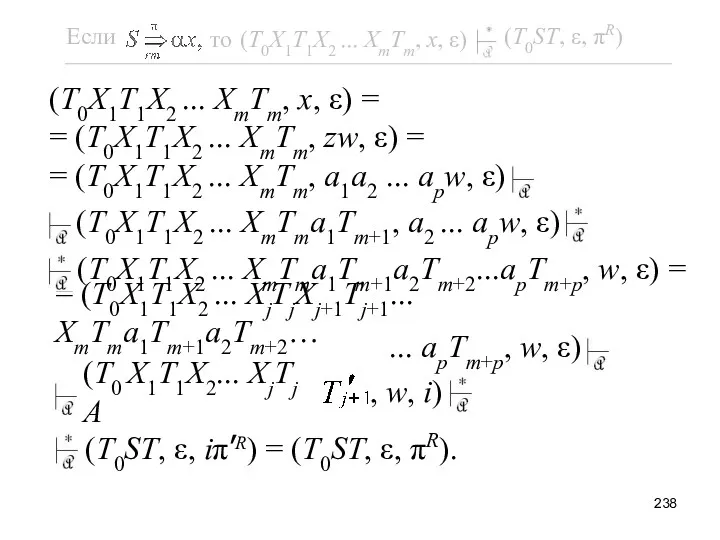

Последний переход обоснован индук-ционной гипотезой с учётом того, что
Последний переход обоснован индук-ционной гипотезой с учётом того, что



существует множество LR(k)-ситуаций
= GOTO ( , a1) и таблица T1
существует множество LR(k)-ситуаций
= GOTO ( , a1) и таблица T1



Случай 1: shift-движение.
Это движение происходит следующим образом:
(T0X1T1X2 ... XmTm, x’,
Случай 1: shift-движение.
Это движение происходит следующим образом:
(T0X1T1X2 ... XmTm, x’,

Так как x’ = Xm + 1x, то
X1X2 ...
Так как x’ = Xm + 1x, то
X1X2 ...

Случай 2: reduce i -движение.
Имеем конфигурацию, достигнутую за пер-вые n движений:
Случай 2: reduce i -движение.
Имеем конфигурацию, достигнутую за пер-вые n движений:





Теорема 3.6. Если G = (VN, VT, P, S) —
Теорема 3.6. Если G = (VN, VT, P, S) —

Покажем, что тогда в этой грамматике нарушается LR(k)-условие (см. теор.
Покажем, что тогда в этой грамматике нарушается LR(k)-условие (см. теор.



Последнее равенство имеет место, так как β2∈VT*. Существование этих двух
Последнее равенство имеет место, так как β2∈VT*. Существование этих двух

Теорема 3.7. Пусть G = (VN, VT, P, S) —
Теорема 3.7. Пусть G = (VN, VT, P, S) —


Тогда вследствие теоремы 3.5 существовало бы как угодно много правосторонних
Тогда вследствие теоремы 3.5 существовало бы как угодно много правосторонних


Замечание 3.6. LR(k)-анализатор на ошибочных цепочках “зациклиться” не может. Цепочка
Замечание 3.6. LR(k)-анализатор на ошибочных цепочках “зациклиться” не может. Цепочка

§ 3.8. Простые постфиксные
синтаксически управляемые
LR-трансляции
Мы
§ 3.8. Простые постфиксные
синтаксически управляемые
LR-трансляции
Мы

Аналогичную ситуацию интересно рассмотреть в отношении схем с LR(k)-грамматиками в
Аналогичную ситуацию интересно рассмотреть в отношении схем с LR(k)-грамматиками в

Ret 267
Ret 267

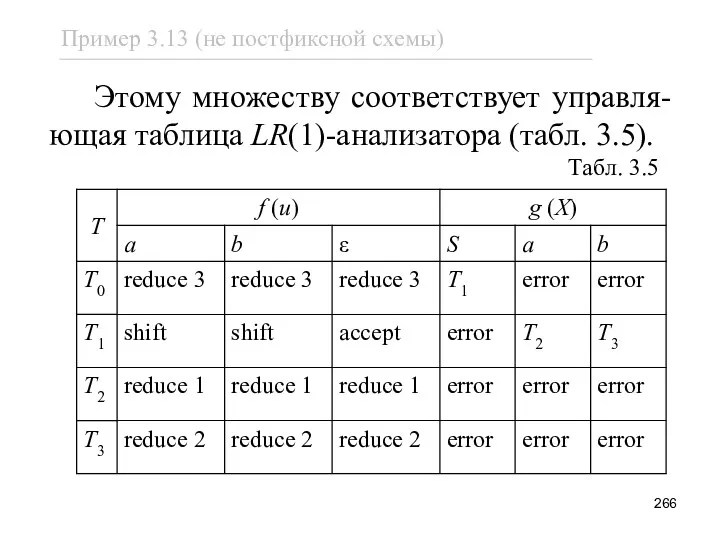
Этому множеству соответствует управля-ющая таблица LR(1)-анализатора (табл. 3.5).
Табл. 3.5
Этому множеству соответствует управля-ющая таблица LR(1)-анализатора (табл. 3.5).
Табл. 3.5



То, что в начале и в конце выходной цепочки должна
То, что в начале и в конце выходной цепочки должна

Естественный способ получить на выходе цепочку wR — запомнить w
Естественный способ получить на выходе цепочку wR — запомнить w

Где ещё, помимо магазина, могла бы быть информация для восстановления
Где ещё, помимо магазина, могла бы быть информация для восстановления

Короче говоря, dpdt, который мог бы реализовать описанную трансляцию, не
Короче говоря, dpdt, который мог бы реализовать описанную трансляцию, не


Теорема 3.8. Пусть T = (N, Σ, Δ, R, S)
Теорема 3.8. Пусть T = (N, Σ, Δ, R, S)

Доказательство. По входной грамматике схемы T можно построить канонический LR(k)-анализатор,
Доказательство. По входной грамматике схемы T можно построить канонический LR(k)-анализатор,

В момент принятия входной цепочки dpdt P переходит в конечное
В момент принятия входной цепочки dpdt P переходит в конечное

Пример 3.14. Пусть имеется простая схема T с правилами
0)
Пример 3.14. Пусть имеется простая схема T с правилами
0)

Эта же таблица может быть использована LR(1)-транслятором, который отличается от
Эта же таблица может быть использована LR(1)-транслятором, который отличается от


Руководствуясь табл. 3.3, LR(1)-транс-лятор совершает следующие движения:
(T0, aabb, ε)
Руководствуясь табл. 3.3, LR(1)-транс-лятор совершает следующие движения:
(T0, aabb, ε)

Каждый раз, когда происходит свёртка по правилу 1 схемы, на
Каждый раз, когда происходит свёртка по правилу 1 схемы, на

§ 3.9. Простые непостфиксные
синтаксически управляемые
LR-трансляции
Предположим,
§ 3.9. Простые непостфиксные
синтаксически управляемые
LR-трансляции
Предположим,

Пусть T = (N, Σ, Δ, R, S) — простая
Пусть T = (N, Σ, Δ, R, S) — простая
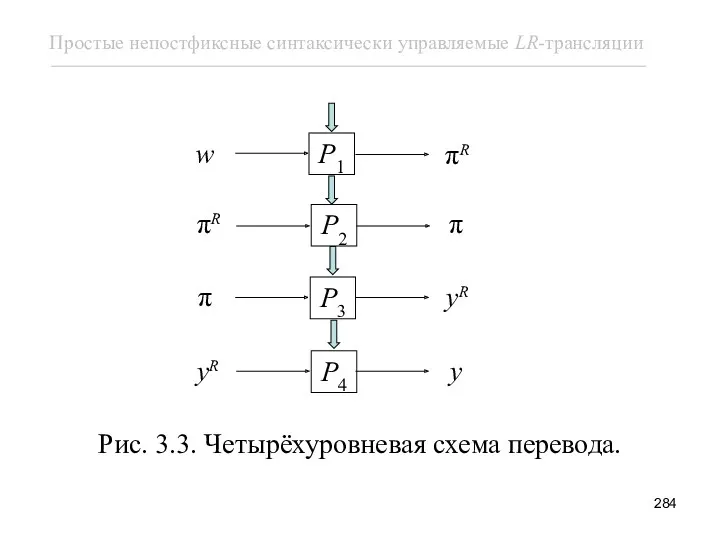
Рис. 3.3. Четырёхуровневая схема перевода.
Рис. 3.3. Четырёхуровневая схема перевода.

Первый уровень занимает dpdt P1. Его входом служит входная цепочка
Первый уровень занимает dpdt P1. Его входом служит входная цепочка

На втором уровне dpdt P2 обращает цепочку πR. Для этого
На втором уровне dpdt P2 обращает цепочку πR. Для этого

На следующем 3-м этапе цепочка π используется для порождения соответству-ющей
На следующем 3-м этапе цепочка π используется для порождения соответству-ющей

где R′ содержит правило вида
A → iBmBm–1 ... B1, ymBmym–1Bm–1 ...
где R′ содержит правило вида
A → iBmBm–1 ... B1, ymBmym–1Bm–1 ...

Нетрудно доказать, что (π, yR) ∈ τ(T′) тогда и только
Нетрудно доказать, что (π, yR) ∈ τ(T′) тогда и только

На четвертом уровне dpdt P4 просто обращает цепочку yR —
На четвертом уровне dpdt P4 просто обращает цепочку yR —

Число основных операций, выполняемых на каждом уровне, пропорционально длине цепочки
Число основных операций, выполняемых на каждом уровне, пропорционально длине цепочки

Теорема 3.9. Трансляция, задаваемая простой семантически однозначной схемой синтаксически управляемой трансляции
Теорема 3.9. Трансляция, задаваемая простой семантически однозначной схемой синтаксически управляемой трансляции

§ 3.10. LALR(k)-Грамматики
На практике часто используются частные подклассы LR(k)-грамматик,
§ 3.10. LALR(k)-Грамматики
На практике часто используются частные подклассы LR(k)-грамматик,


Определение 3.18. Пусть G — контекстно-свободная грамматика, — каноническая система
Определение 3.18. Пусть G — контекстно-свободная грамматика, — каноническая система

Другими словами, если слить все множества LR(k)-ситуаций с одинаковыми наборами
Другими словами, если слить все множества LR(k)-ситуаций с одинаковыми наборами

Число множеств, полученных при таком слиянии, разве лишь уменьшится. Соответственно
Число множеств, полученных при таком слиянии, разве лишь уменьшится. Соответственно

![= {[S’ → .S, ε], [S → .SaSb, ε |](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/350918/slide-298.jpg)
= {[S’ → .S, ε], [S → .SaSb, ε |
= {[S’ → .S, ε], [S → .SaSb, ε |


Системе объединённых множеств LR(1)-ситуаций соответствует управляющая таблица:
Табл. 3.6
Системе объединённых множеств LR(1)-ситуаций соответствует управляющая таблица:
Табл. 3.6

Отметим, что анализатор, использующий LALR(k)-таблицы, может чуть запаздывать с обнаружением
Отметим, что анализатор, использующий LALR(k)-таблицы, может чуть запаздывать с обнаружением

 Обработка и передача информации
Обработка и передача информации Ғылыми зерттеу жұмыстарының жіктемелері
Ғылыми зерттеу жұмыстарының жіктемелері Семейство червей “Code Red”
Семейство червей “Code Red” Учет поступивших в библиотеку документов в схемах и таблицах
Учет поступивших в библиотеку документов в схемах и таблицах Организация БД SQL Server 2008
Организация БД SQL Server 2008 Программное обеспечение персонального компьютера
Программное обеспечение персонального компьютера Представление информации в компьютере 6 класс
Представление информации в компьютере 6 класс Нечеткие множества в сиcтемах управления рисками информационной безопасностью
Нечеткие множества в сиcтемах управления рисками информационной безопасностью Правила набора, форматирования текста и верстки. Методическое пособие
Правила набора, форматирования текста и верстки. Методическое пособие Новогодняя открытка
Новогодняя открытка Візуалізація рядів і трендів даних. Інфографіка (10 клас)
Візуалізація рядів і трендів даних. Інфографіка (10 клас) Преобразование логических выражений
Преобразование логических выражений Теория цвета
Теория цвета Беспроводные каналы
Беспроводные каналы презентация к урокам по теме Кодирование графической информации
презентация к урокам по теме Кодирование графической информации Компьютерные презентации. Мультимедиа
Компьютерные презентации. Мультимедиа Віртуальна реальність
Віртуальна реальність Презентация Алфавитный подход
Презентация Алфавитный подход Теория и практика информационно-аналитической работы. Семинар 2
Теория и практика информационно-аналитической работы. Семинар 2 История и современные тенденции развития компьютеров. Персональный компьютер (ПК). 7 класс
История и современные тенденции развития компьютеров. Персональный компьютер (ПК). 7 класс Классификация СУБД. Лекция 3
Классификация СУБД. Лекция 3 Система автоматизации розничной торговли. Курс по работе с конфигурацией
Система автоматизации розничной торговли. Курс по работе с конфигурацией Системы счисления. Двоично-десятичные коды (часть 5.0)
Системы счисления. Двоично-десятичные коды (часть 5.0) The Basics of Object Lifetime. Disposing objects (Java)
The Basics of Object Lifetime. Disposing objects (Java) Цикл с параметром в языке Pascal
Цикл с параметром в языке Pascal Анализ данных в реляционных БД на примере СУБД MS Access. Создание запросов, изменяющих таблицы. Создание отчетов
Анализ данных в реляционных БД на примере СУБД MS Access. Создание запросов, изменяющих таблицы. Создание отчетов Математические пакеты
Математические пакеты Язык программирования С++
Язык программирования С++