- Нечеткие множества в сиcтемах управления рисками информационной безопасностью

Содержание
- 2. Содержание Основные понятия теории нечетких множеств. Логико-лингвистическое моделирование на основе нечетких множеств. Примеры моделей.
- 3. Некоторые примеры, относящиеся к невозможности точного определения параметров Оценка знаний Оценка присутствия Оценка угрозы Оценка уязвимостей
- 4. Откуда всё это взялось? Множества, для которых функция принадлежности представляет собой не жесткий порог (принадлежит/не принадлежит),
- 5. Автор теории нечетких множеств, нечетких множеств, теории возможностей и туманных вычислений Лютфи Рагим оглы Алескерзаде родился
- 6. Для чего нужна нечеткая логика и нечеткие множества? Нечеткая логика - надмножество булевой логики, расширенной с
- 7. Примеры использования нечеткой логики Создание управляющего микропроцессора на основе нечеткой логики, способного автоматически решать «задачу о
- 8. Лингвистическая переменная Опр2 (полное): Лингвистическая переменная - набор , где b – наименование лингвистической переменной; Т
- 9. Пример b = «температура в комнате» - имя лингвистической переменной; X = [5,35] – границы определения;
- 10. Нечёткая переменная Нечеткая переменная характеризуется тройкой , где a - наименование переменной, X - универсальное множество
- 11. Нечёткое множество (fuzzy set) Нечеткое множество – подмножество элементов А из области определения Е такое, что
- 12. Операции над нечеткими величинами
- 17. Основные операции над нечёткими отношениями 1) Объединение двух отношений R1 R2. Пример: xR1y - «действительные числа
- 18. Операции над нечёткими множествами Даны нечеткие множества А и В с функциями принадлежности: μА(u) и μB(u),
- 19. Лингвистические модели
- 20. Логико-лингвистическое описание систем, нечеткие модели L1 : Если и/или … и/или то и/или… и/или L2 :
- 21. Логико-лингвистическое описание систем, нечеткие модели Совокупность импликаций {L1, L2, ..., Lk} отражает функциональную взаимосвязь входных и
- 22. Этап непосредственного нечёткого вывода Нечёткий вывод Опр: Нечетким логическим выводом (fuzzy logic inference) называется аппроксимация зависимости
- 23. База знаний Если Лингвистическая Переменная 1 есть Терм Лингвистической Переменной 1 и Лингвистическая Переменная 2 есть
- 24. Нечёткий вывод Пусть есть система описывающая поведение некоторого реактора в виде следующих правил: Если Температура низкая
- 25. Температура. (множество возможных значений) – отрезок [0,150] . Начальное множество термов {Высокая, Средняя, Низкая}. Функции принадлежности
- 26. Этап фаззификации С помощью функций принадлежности всех термов входных лингвистических переменных и на основании задаваемых четких
- 27. 2) Этап непосредственного нечёткого вывода На основании набора правил – нечеткой базы знаний – вычисляется значение
- 28. Нечёткий вывод Правило 1 Правило 2 Правило 3 + 0,25 + 1 + 0,7
- 29. Нечёткий вывод Если ТЕМПЕРАТУРА низкая И РАСХОД малый, то ДАВЛЕНИЕ низкое 85 3,5 0,3 0,25 MIN
- 30. Нечёткий вывод 3) Этап композиции (аккумуляции) Все нечеткие множества, назначенные для каждого терма каждой выходной лингвистической
- 31. 4) Этап дефаззификации (необязательный) Используется когда необходимо от полученного нечёткого множества перейти к конкретному числовому значению.
- 32. ОПИСАНИЕ ПРИМЕРОВ
- 33. Пример 1 Рассмотрим модель, состоящую из трех параметров, где «А» и «В» - входные переменные, а
- 34. Этапы 1.Формирование базы правил системы нечеткого вывода. 2.Фаззификация входных параметров. 3.Агрегирование. 4.Активизация подусловий в нечетких правилах
- 35. 1.Создание базы правил Правило_1: Если «Условие_А1» или «Условие_В1» ТО «Следствие_С1» Правило_2: Если «Условие_ А2» или «Условие_В2»
- 36. 2.Фаззификация входных параметров Фаззификацией, или введением нечеткости, называется процесс нахождения функции принадлежности нечетких множеств на основе
- 37. Агрегирование Целью данного этапа является определение степени истинности каждого из подзаключений по каждому из правил систем
- 38. Активизация подусловий в нечетких правилах продукций Нечеткие подмножества, назначенные для каждой выходной переменной, объединяются вместе, чтобы
- 39. Дефазификация Дефаззификация Полученные результаты всех выходных переменных на предыдущих этапах нечеткого вывода преобразуются в обычные количественные
- 40. Этапы нечеткого вывода
- 41. Постановка задачи
- 42. Понятие «риск ИБ» Риск информационной безопасности (information security risk): Возможность того, что данная угроза сможет воспользоваться
- 43. Уточним понятие «риск ИБ» R = A∩T∩Y, где A≠∅, T≠∅, Y≠∅ ; ri=0, если (ai=o )∪
- 44. Следствия из этого определения Отсутствие любого параметра в этой модели рисков не имеет смысла. Где тут
- 45. Как измеряется риск ?
- 46. Проблема представления риска ? R = , где U – потери, Р – возможность реализации угрозы
- 47. Cтандарт NIST
- 48. Трехфакторные модели управления рисками
- 49. Вариант определения метрики риска
- 50. Методы оценки метрики риска Метрика (М)– это мера измерения R. Варианты метрик М =f (A,T, Y)
- 51. Какие задачи можно решать с использованием рисков ИБ ? Обоснование СМИБ на основе упорядочивании и классификация
- 52. Какие задачи можно решать с использованием рисков ИБ ? 2. Обоснование системы информационной безопасности (СМИБ) на
- 53. Постановка задачи Разработать модель оценки рисков с использованием нечетких множеств. Полученную модель проверить на логику полученных
- 54. Настройка функций принадлежности
- 56. Настройка блока правил
- 57. Результаты моделирования поля нечетких величин
- 58. Последовательность решения задачи Определить переменные по заданным условиям. Определить правила, задать уровень доверия от 30 до
- 59. Система “Набор баскетболистов” Рост баскетболиста Множество определения – [170,236] Очень высокий высокий средний низкий
- 60. Система “Набор баскетболистов” Техника игры баскетболиста Множество определения – [0,100] очень хорошая отличная средняя хорошая плохая
- 61. Система “Набор баскетболистов” Уверенность принятия в команду Множество определения – [0,100] полная средняя малая не берём
- 62. Система “Набор баскетболистов”- Правила
- 63. Система “Футбол” Лингвистические переменные Разница потерь ведущих игроков Множество определения – [-6,6] Множество термов - {большая
- 64. Система “Футбол” Лингвистические переменные Встречи команд Множество определения – [-20,20] Множество термов - {позорные встречи, равные
- 65. Система “Футбол” Разница потерь ведущих игроков Множество определения – [-6,6] большая скамейка одинаковая скамейка короткая скамейка
- 66. Система “Футбол” Разница игровых динамик Множество определения – [-15,15] разница очков, набранных командой хозяином поля и
- 67. Система “Футбол” Разница в классе команд Множество определения – [-13,13] разница мест, которые занимают команда-хозяин и
- 68. преимущество рассчитываться как HP/HG - GP/GG, где HP – общее количество очков, набранное командой хозяином поля
- 69. Система “Футбол” Встречи команд Множество определения – [-20,20] разница забитых и пропущенных мячей двух команд во
- 70. Система “Футбол” Результат матча Множество определения – [-3,3] разница голов забитых командой хозяином поля и гостевой
- 71. Система “Футбол” - Правила
- 73. Скачать презентацию

Содержание
Основные понятия теории нечетких множеств.
Логико-лингвистическое моделирование на основе нечетких множеств.
Примеры моделей.
Содержание
Основные понятия теории нечетких множеств.
Логико-лингвистическое моделирование на основе нечетких множеств.
Примеры моделей.

Некоторые примеры, относящиеся к невозможности точного определения параметров
Оценка знаний
Оценка присутствия
Оценка угрозы
Оценка
Некоторые примеры, относящиеся к невозможности точного определения параметров
Оценка знаний
Оценка присутствия
Оценка угрозы
Оценка

Откуда всё это взялось?
Множества, для которых функция принадлежности представляет собой
Откуда всё это взялось?
Множества, для которых функция принадлежности представляет собой

Автор теории нечетких множеств, нечетких множеств, теории возможностей и туманных вычислений
Лютфи
Автор теории нечетких множеств, нечетких множеств, теории возможностей и туманных вычислений
Лютфи

Для чего нужна нечеткая логика и нечеткие множества?
Нечеткая логика - надмножество
Для чего нужна нечеткая логика и нечеткие множества?
Нечеткая логика - надмножество

Примеры использования нечеткой логики
Создание управляющего микропроцессора на основе нечеткой логики,
способного
Примеры использования нечеткой логики
Создание управляющего микропроцессора на основе нечеткой логики,
способного

Лингвистическая переменная
Опр2 (полное):
Лингвистическая переменная - набор < b,T, Х,G,M >, где
Лингвистическая переменная
Опр2 (полное):
Лингвистическая переменная - набор < b,T, Х,G,M >, где
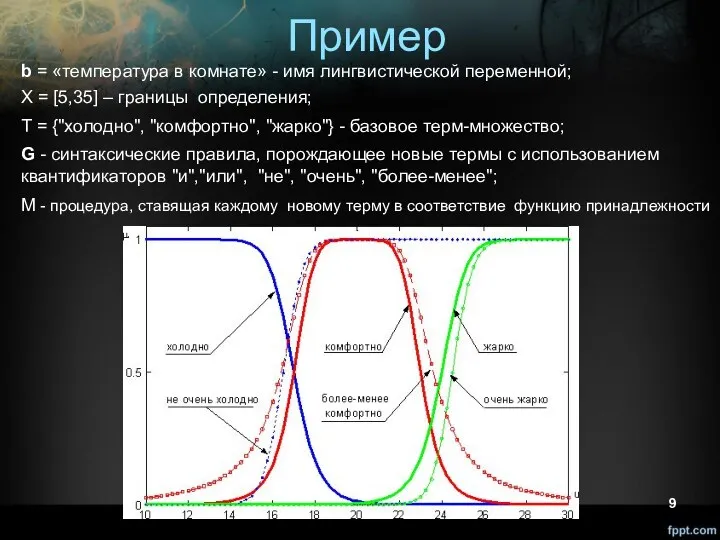
Пример
b = «температура в комнате» - имя лингвистической переменной;
X = [5,35]
Пример
b = «температура в комнате» - имя лингвистической переменной;
X = [5,35]

Нечёткая переменная
Нечеткая переменная характеризуется тройкой < a,X,A >, где
a -
Нечёткая переменная
Нечеткая переменная характеризуется тройкой < a,X,A >, где
a -
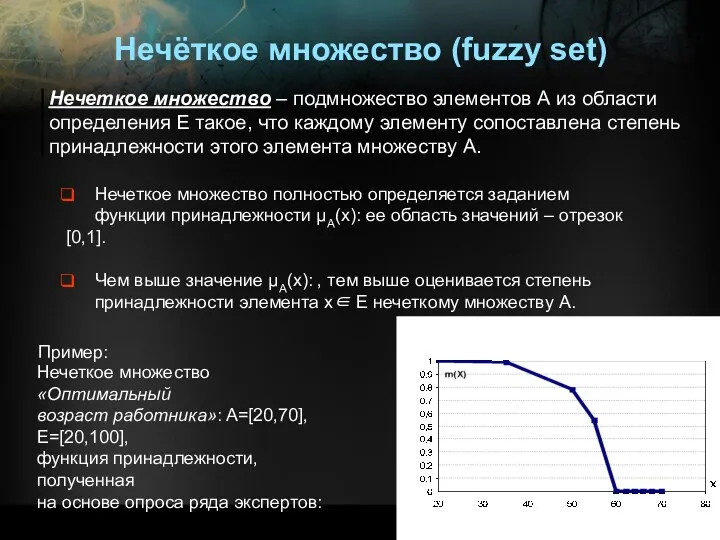
Нечёткое множество (fuzzy set)
Нечеткое множество – подмножество элементов А из
Нечёткое множество (fuzzy set)
Нечеткое множество – подмножество элементов А из

Операции над нечеткими величинами
Операции над нечеткими величинами





Основные операции над нечёткими отношениями
1) Объединение двух отношений R1 R2.
Пример:
Основные операции над нечёткими отношениями
1) Объединение двух отношений R1 R2.
Пример:
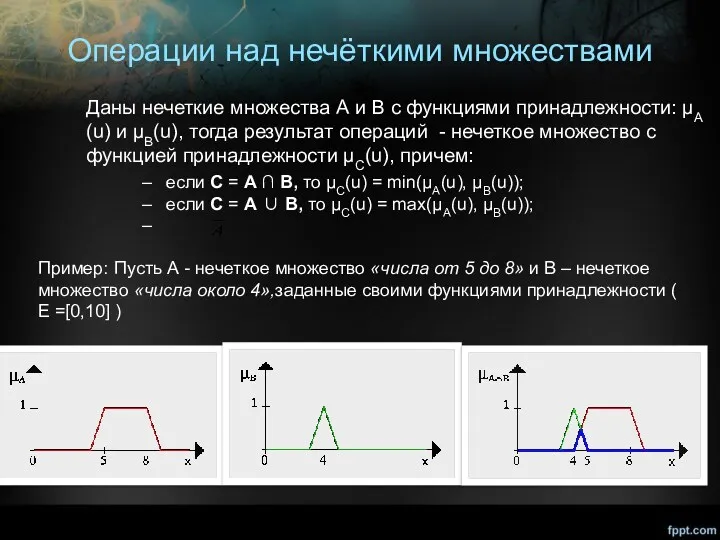
Операции над нечёткими множествами
Даны нечеткие множества А и В с функциями
Операции над нечёткими множествами
Даны нечеткие множества А и В с функциями
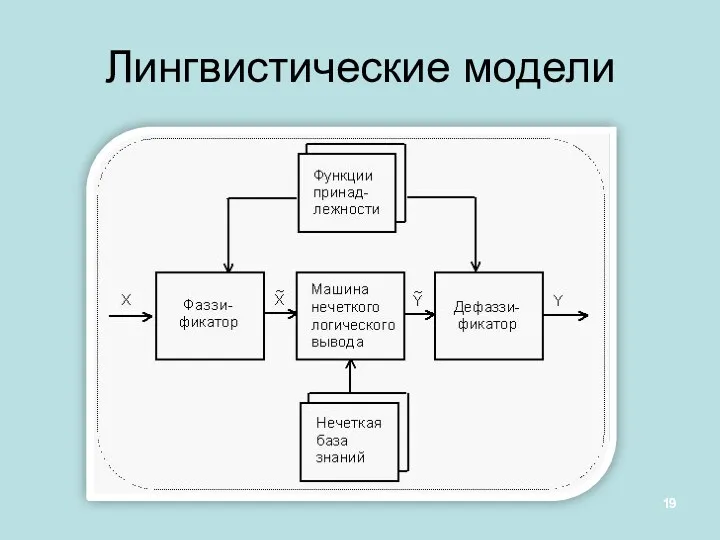
Лингвистические модели
Лингвистические модели
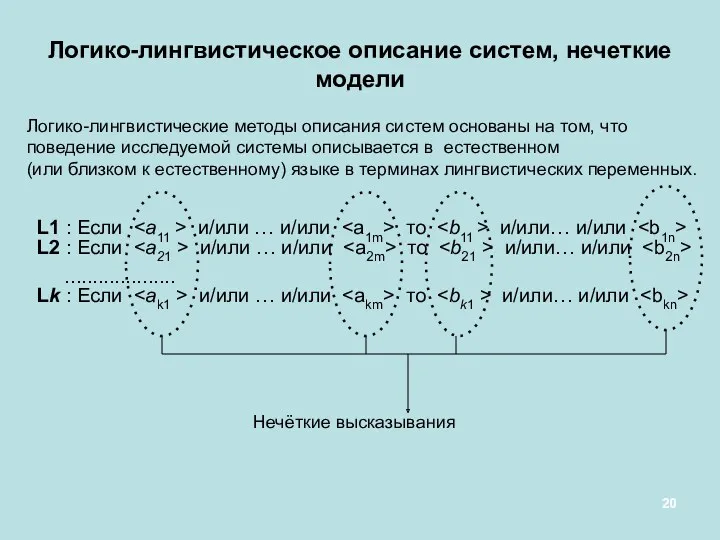
Логико-лингвистическое описание систем, нечеткие модели
L1 : Если и/или
Логико-лингвистическое описание систем, нечеткие модели
L1 : Если
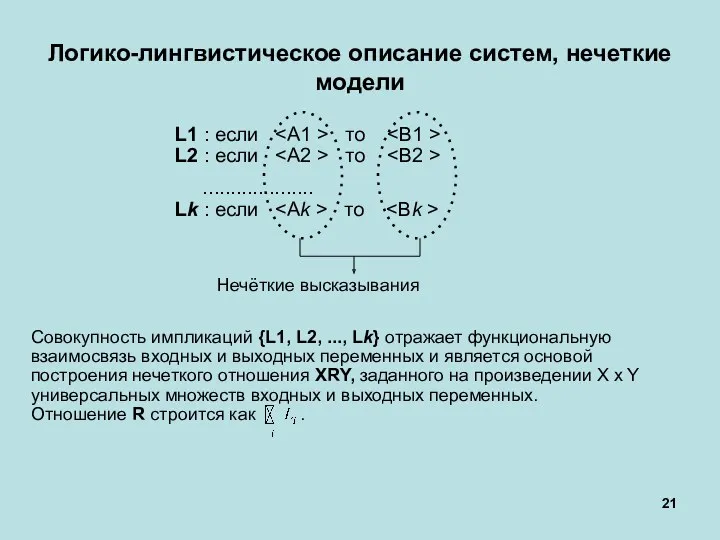
Логико-лингвистическое описание систем, нечеткие модели
Совокупность импликаций {L1, L2, ..., Lk}
Логико-лингвистическое описание систем, нечеткие модели
Совокупность импликаций {L1, L2, ..., Lk}
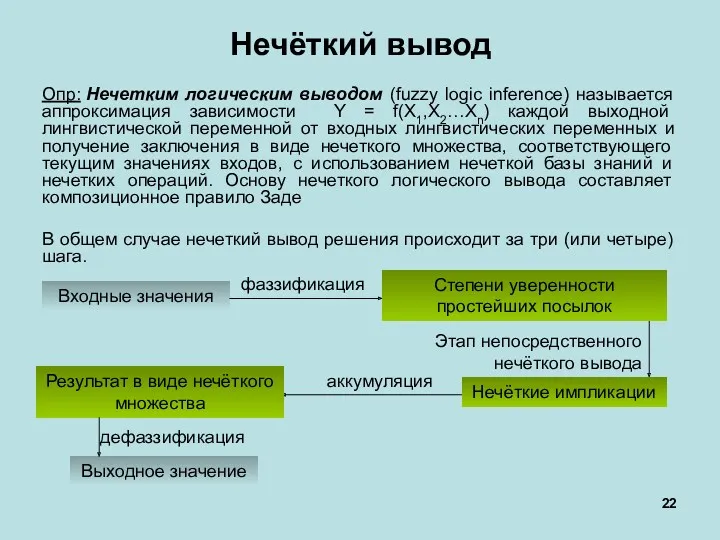
Этап непосредственного нечёткого вывода
Нечёткий вывод
Опр: Нечетким логическим выводом (fuzzy logic inference) называется
Этап непосредственного нечёткого вывода
Нечёткий вывод
Опр: Нечетким логическим выводом (fuzzy logic inference) называется
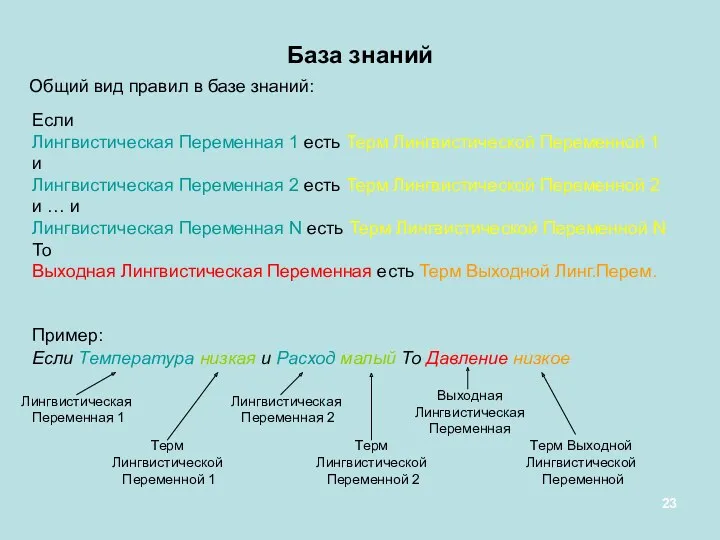
База знаний
Если
Лингвистическая Переменная 1 есть Терм Лингвистической Переменной 1
и
Лингвистическая Переменная
База знаний
Если Лингвистическая Переменная 1 есть Терм Лингвистической Переменной 1 и Лингвистическая Переменная

Нечёткий вывод
Пусть есть система описывающая поведение некоторого реактора в виде следующих
Нечёткий вывод
Пусть есть система описывающая поведение некоторого реактора в виде следующих
![Температура. (множество возможных значений) – отрезок [0,150] . Начальное множество](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-24.jpg)
Температура. (множество возможных значений) – отрезок [0,150] . Начальное множество термов
Температура. (множество возможных значений) – отрезок [0,150] . Начальное множество термов
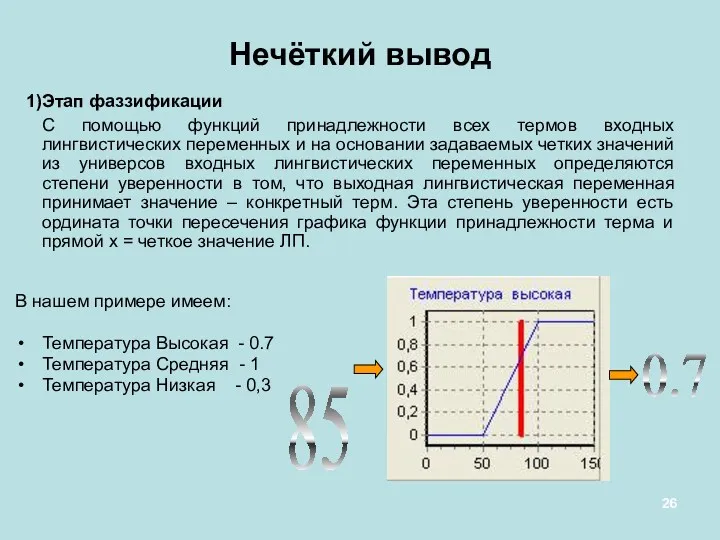
Этап фаззификации
С помощью функций принадлежности всех термов входных лингвистических
Этап фаззификации
С помощью функций принадлежности всех термов входных лингвистических

2) Этап непосредственного нечёткого вывода
На основании набора правил – нечеткой
2) Этап непосредственного нечёткого вывода
На основании набора правил – нечеткой
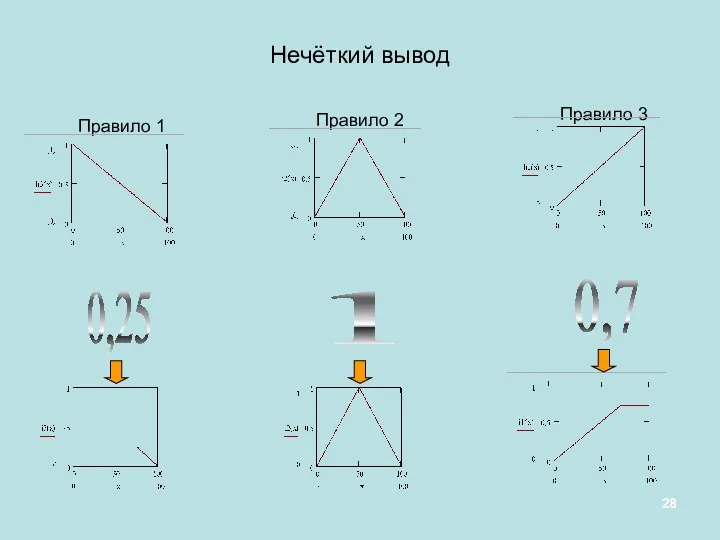
Нечёткий вывод
Правило 1
Правило 2
Правило 3
+
0,25
+
1
+
0,7
Нечёткий вывод
Правило 1
Правило 2
Правило 3
+
0,25
+
1
+
0,7
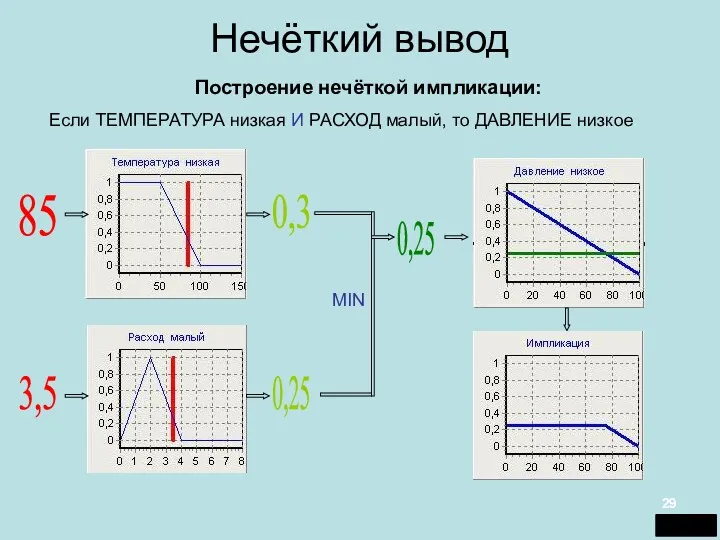
Нечёткий вывод
Если ТЕМПЕРАТУРА низкая И РАСХОД малый, то ДАВЛЕНИЕ низкое
85
3,5
0,3
0,25
MIN
0,25
Построение нечёткой
Нечёткий вывод
Если ТЕМПЕРАТУРА низкая И РАСХОД малый, то ДАВЛЕНИЕ низкое
85
3,5
0,3
0,25
MIN
0,25
Построение нечёткой
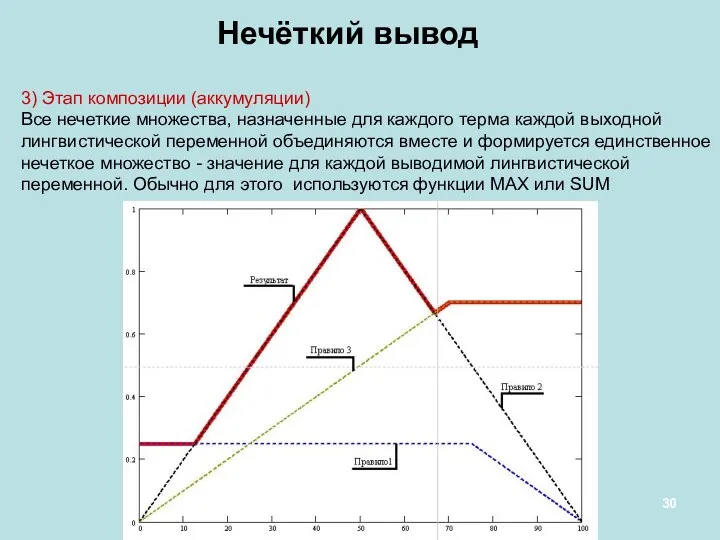
Нечёткий вывод
3) Этап композиции (аккумуляции)
Все нечеткие множества, назначенные для каждого
Нечёткий вывод
3) Этап композиции (аккумуляции)
Все нечеткие множества, назначенные для каждого
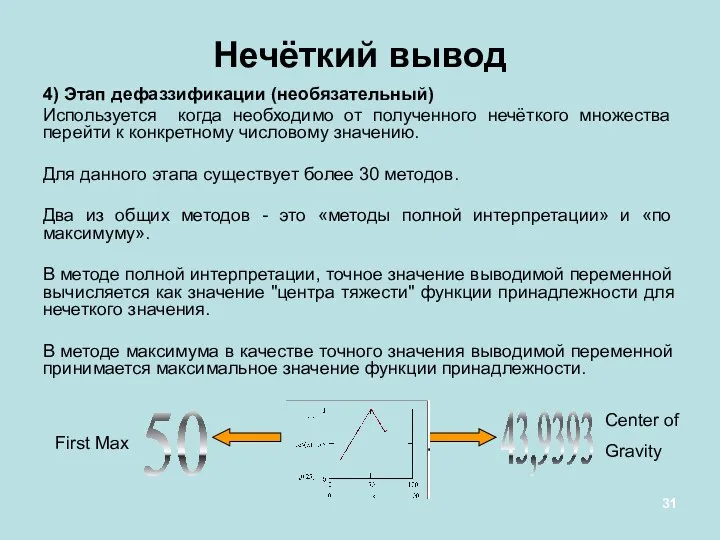
4) Этап дефаззификации (необязательный)
Используется когда необходимо от полученного нечёткого множества
4) Этап дефаззификации (необязательный)
Используется когда необходимо от полученного нечёткого множества

ОПИСАНИЕ ПРИМЕРОВ
ОПИСАНИЕ ПРИМЕРОВ

Пример 1
Рассмотрим модель, состоящую из трех параметров, где «А» и «В»
Пример 1
Рассмотрим модель, состоящую из трех параметров, где «А» и «В»

Этапы
1.Формирование базы правил системы нечеткого вывода.
2.Фаззификация входных параметров.
3.Агрегирование.
4.Активизация подусловий в нечетких
Этапы
1.Формирование базы правил системы нечеткого вывода.
2.Фаззификация входных параметров.
3.Агрегирование.
4.Активизация подусловий в нечетких

1.Создание базы правил
Правило_1: Если «Условие_А1» или «Условие_В1» ТО «Следствие_С1»
Правило_2: Если «Условие_
1.Создание базы правил
Правило_1: Если «Условие_А1» или «Условие_В1» ТО «Следствие_С1»
Правило_2: Если «Условие_

2.Фаззификация входных параметров
Фаззификацией, или введением нечеткости, называется процесс нахождения функции принадлежности
2.Фаззификация входных параметров
Фаззификацией, или введением нечеткости, называется процесс нахождения функции принадлежности

Агрегирование
Целью данного этапа является определение степени истинности каждого из подзаключений по
Агрегирование
Целью данного этапа является определение степени истинности каждого из подзаключений по

Активизация подусловий в нечетких правилах продукций
Нечеткие подмножества, назначенные для каждой выходной
Активизация подусловий в нечетких правилах продукций
Нечеткие подмножества, назначенные для каждой выходной

Дефазификация
Дефаззификация
Полученные результаты всех выходных переменных на предыдущих этапах нечеткого вывода преобразуются
Дефазификация
Дефаззификация
Полученные результаты всех выходных переменных на предыдущих этапах нечеткого вывода преобразуются
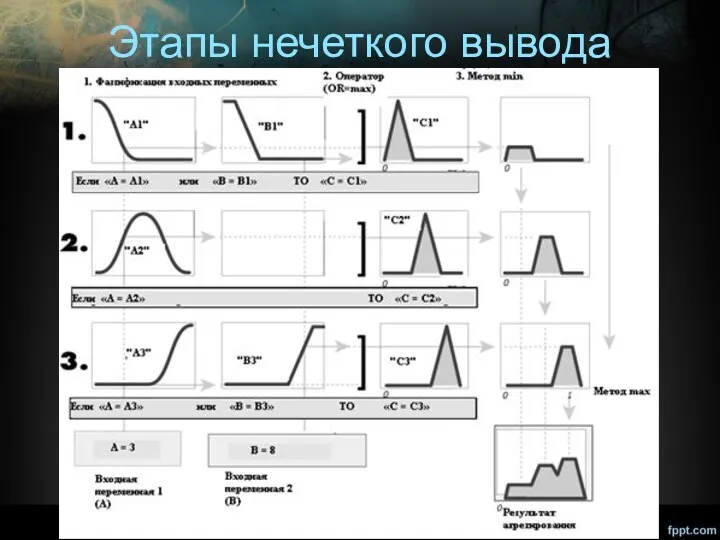
Этапы нечеткого вывода
Этапы нечеткого вывода

Постановка задачи
Постановка задачи

Понятие «риск ИБ»
Риск информационной безопасности (information security risk): Возможность того, что
Понятие «риск ИБ»
Риск информационной безопасности (information security risk): Возможность того, что

Уточним понятие «риск ИБ»
R = A∩T∩Y, где
A≠∅, T≠∅, Y≠∅
Уточним понятие «риск ИБ»
R = A∩T∩Y, где
A≠∅, T≠∅, Y≠∅

Следствия из этого определения
Отсутствие любого параметра в этой модели рисков не
Следствия из этого определения
Отсутствие любого параметра в этой модели рисков не

Как измеряется риск ?
Как измеряется риск ?

Проблема представления риска
?
R = ,
где U –
Проблема представления риска
?
R =
где U –
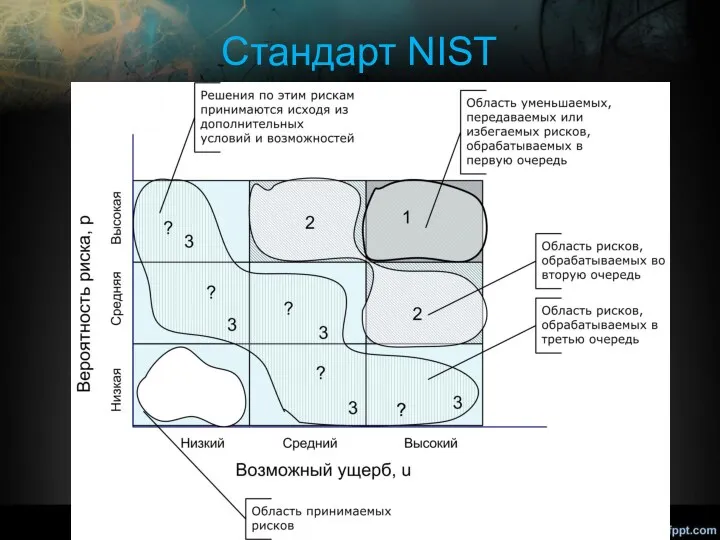
Cтандарт NIST
Cтандарт NIST
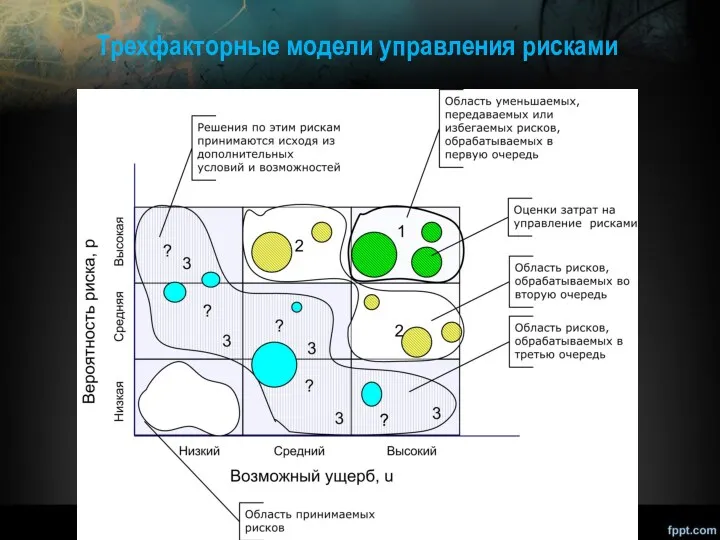
Трехфакторные модели управления рисками
Трехфакторные модели управления рисками
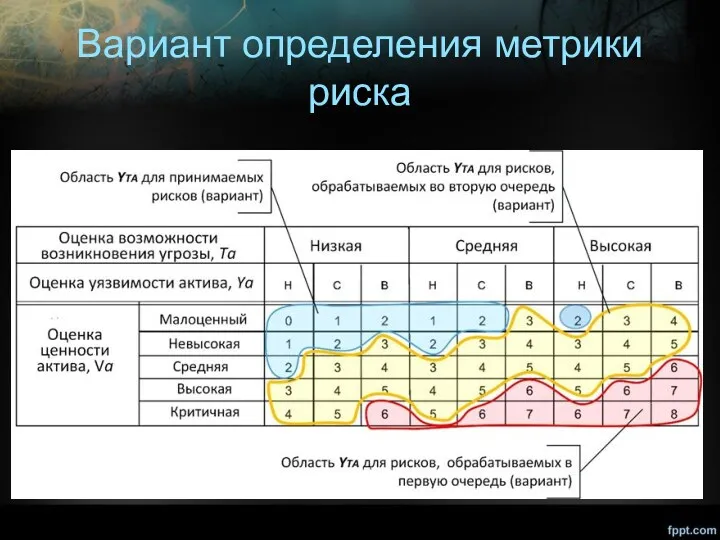
Вариант определения метрики
риска
Вариант определения метрики
риска

Методы оценки метрики риска
Метрика (М)– это мера измерения R.
Варианты метрик М
Методы оценки метрики риска
Метрика (М)– это мера измерения R.
Варианты метрик М

Какие задачи можно решать с использованием рисков ИБ ?
Обоснование СМИБ на
Какие задачи можно решать с использованием рисков ИБ ?
Обоснование СМИБ на

Какие задачи можно решать с использованием рисков ИБ ?
2. Обоснование системы
Какие задачи можно решать с использованием рисков ИБ ?
2. Обоснование системы
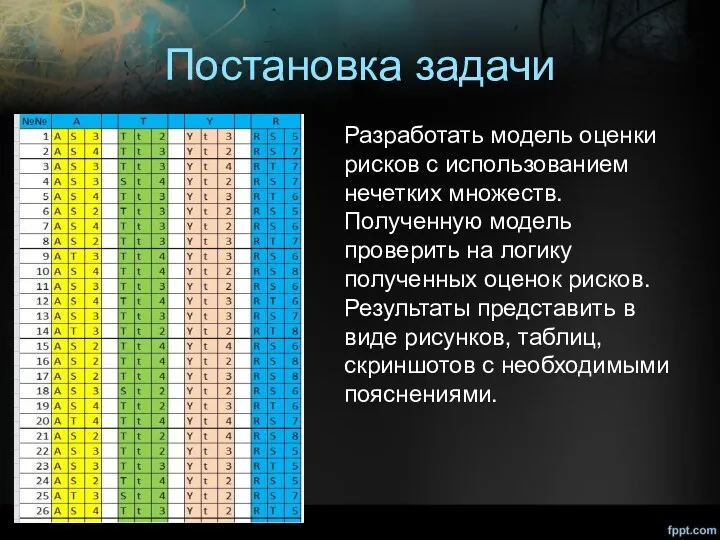
Постановка задачи
Разработать модель оценки рисков с использованием нечетких множеств. Полученную модель
Постановка задачи
Разработать модель оценки рисков с использованием нечетких множеств. Полученную модель
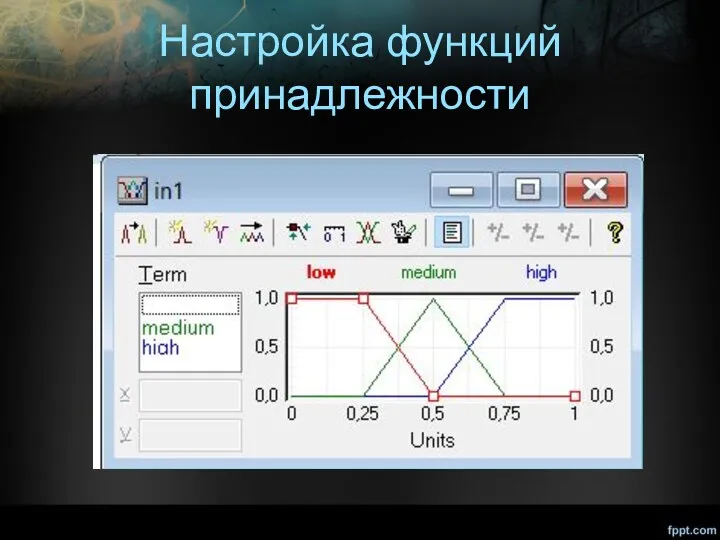
Настройка функций принадлежности
Настройка функций принадлежности
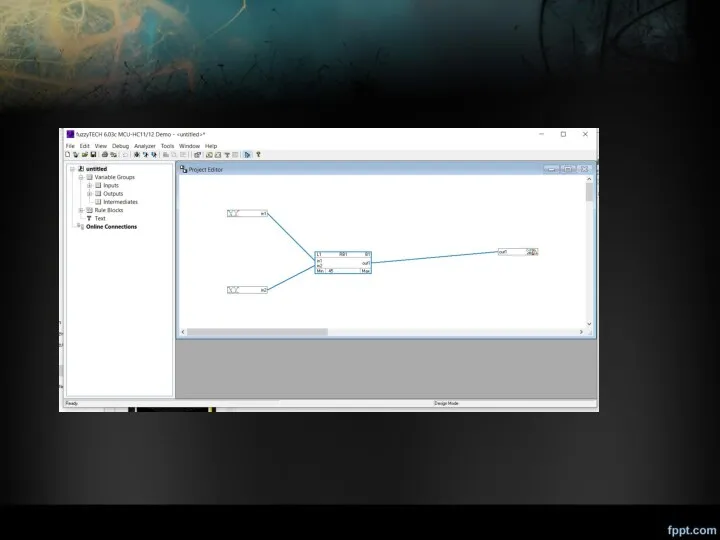
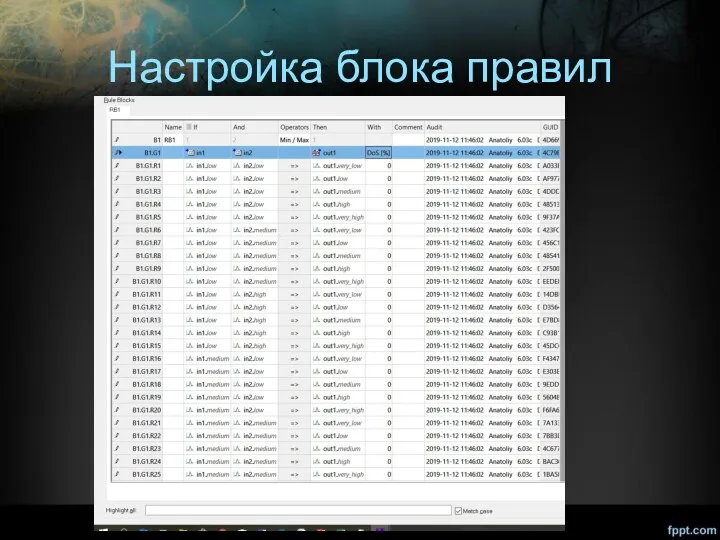
Настройка блока правил
Настройка блока правил
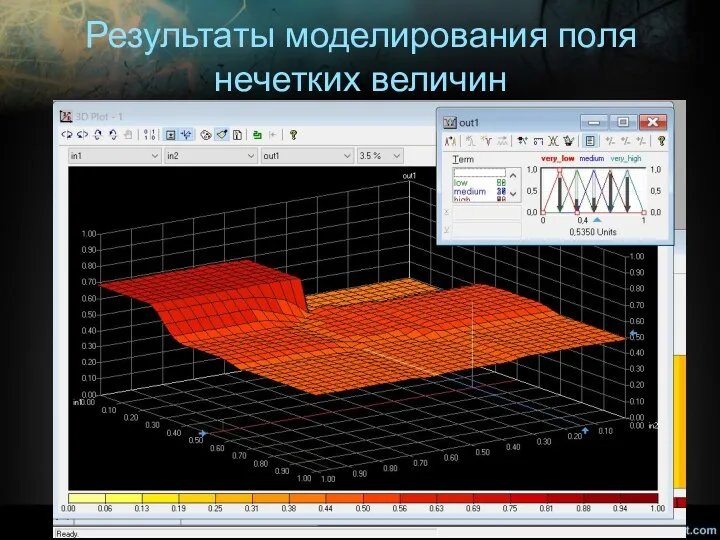
Результаты моделирования поля нечетких величин
Результаты моделирования поля нечетких величин

Последовательность решения задачи
Определить переменные по заданным условиям.
Определить правила, задать уровень доверия
Последовательность решения задачи
Определить переменные по заданным условиям.
Определить правила, задать уровень доверия
![Система “Набор баскетболистов” Рост баскетболиста Множество определения – [170,236] Очень высокий высокий средний низкий](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-58.jpg)
Система “Набор баскетболистов”
Рост баскетболиста
Множество определения – [170,236]
Очень высокий
высокий
средний
низкий
Система “Набор баскетболистов”
Рост баскетболиста
Множество определения – [170,236]
Очень высокий
высокий
средний
низкий
![Система “Набор баскетболистов” Техника игры баскетболиста Множество определения – [0,100] очень хорошая отличная средняя хорошая плохая](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-59.jpg)
Система “Набор баскетболистов”
Техника игры баскетболиста
Множество определения – [0,100]
очень хорошая
отличная
средняя
хорошая
плохая
Система “Набор баскетболистов”
Техника игры баскетболиста
Множество определения – [0,100]
очень хорошая
отличная
средняя
хорошая
плохая
![Система “Набор баскетболистов” Уверенность принятия в команду Множество определения – [0,100] полная средняя малая не берём](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-60.jpg)
Система “Набор баскетболистов”
Уверенность принятия в команду
Множество определения – [0,100]
полная
средняя
малая
не берём
Система “Набор баскетболистов”
Уверенность принятия в команду
Множество определения – [0,100]
полная
средняя
малая
не берём
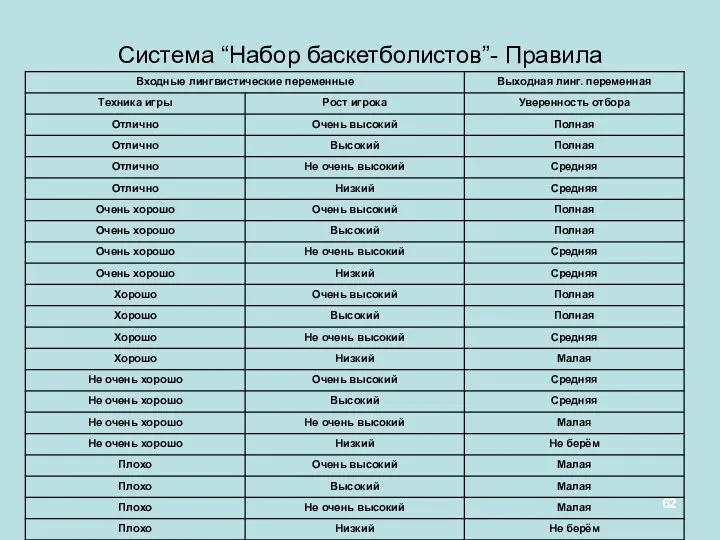
Система “Набор баскетболистов”- Правила
Система “Набор баскетболистов”- Правила

Система “Футбол”
Лингвистические переменные
Разница потерь ведущих игроков
Множество определения – [-6,6]
Множество термов
Система “Футбол”
Лингвистические переменные
Разница потерь ведущих игроков
Множество определения – [-6,6]
Множество термов
![Система “Футбол” Лингвистические переменные Встречи команд Множество определения – [-20,20]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-63.jpg)
Система “Футбол”
Лингвистические переменные
Встречи команд
Множество определения – [-20,20]
Множество термов - {позорные
Система “Футбол”
Лингвистические переменные
Встречи команд
Множество определения – [-20,20]
Множество термов - {позорные
![Система “Футбол” Разница потерь ведущих игроков Множество определения – [-6,6]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-64.jpg)
Система “Футбол”
Разница потерь ведущих игроков
Множество определения – [-6,6]
большая скамейка
одинаковая скамейка
короткая скамейка
разница
Система “Футбол”
Разница потерь ведущих игроков
Множество определения – [-6,6]
большая скамейка
одинаковая скамейка
короткая скамейка
разница
![Система “Футбол” Разница игровых динамик Множество определения – [-15,15] разница](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-65.jpg)
Система “Футбол”
Разница игровых динамик
Множество определения – [-15,15]
разница очков, набранных командой хозяином
Система “Футбол”
Разница игровых динамик
Множество определения – [-15,15]
разница очков, набранных командой хозяином
![Система “Футбол” Разница в классе команд Множество определения – [-13,13]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-66.jpg)
Система “Футбол”
Разница в классе команд
Множество определения – [-13,13]
разница мест, которые занимают
Система “Футбол”
Разница в классе команд
Множество определения – [-13,13]
разница мест, которые занимают
преимущество
рассчитываться как HP/HG - GP/GG, где HP – общее количество очков,
преимущество
рассчитываться как HP/HG - GP/GG, где HP – общее количество очков,
![Система “Футбол” Встречи команд Множество определения – [-20,20] разница забитых](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-68.jpg)
Система “Футбол”
Встречи команд
Множество определения – [-20,20]
разница забитых и пропущенных мячей двух
Система “Футбол”
Встречи команд
Множество определения – [-20,20]
разница забитых и пропущенных мячей двух
![Система “Футбол” Результат матча Множество определения – [-3,3] разница голов](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/583214/slide-69.jpg)
Система “Футбол”
Результат матча
Множество определения – [-3,3]
разница голов забитых командой хозяином поля
Система “Футбол”
Результат матча
Множество определения – [-3,3]
разница голов забитых командой хозяином поля
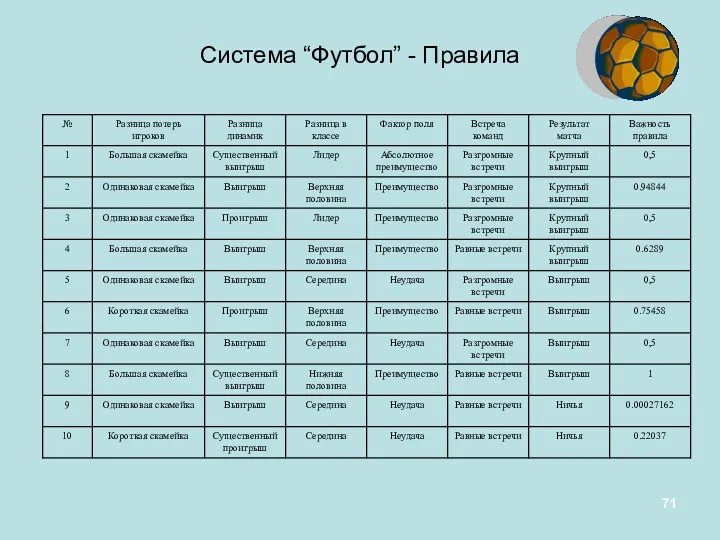
Система “Футбол” - Правила
Система “Футбол” - Правила
 Использование прикладных программ компьютера в работе с дошкольниками для формирования знаний по правилам дорожного движения
Использование прикладных программ компьютера в работе с дошкольниками для формирования знаний по правилам дорожного движения Информационное моделирование
Информационное моделирование Медиапланирование как основа деятельности пресс-службы
Медиапланирование как основа деятельности пресс-службы Растровая графика
Растровая графика Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих
Выполнение работ по одной или нескольким профессиям рабочих, должностям служащих Введение в Python
Введение в Python Методы на языке С#
Методы на языке С# Алгоритми. Лекция 1
Алгоритми. Лекция 1 Основные понятия языка гипертекстовой разметки документов HTML. Структура html-документа
Основные понятия языка гипертекстовой разметки документов HTML. Структура html-документа Антивирусные программы
Антивирусные программы Веб-разработка. Библиотека jQuery
Веб-разработка. Библиотека jQuery Алфавитный подход к определению количества информации
Алфавитный подход к определению количества информации Обработка исключений Python
Обработка исключений Python Тема 6
Тема 6 Журнал Esquire как СМИ
Журнал Esquire как СМИ История телеканала TV1000
История телеканала TV1000 Онтологический инжиниринг
Онтологический инжиниринг Swot-анализ мобильного приложения GrandApp
Swot-анализ мобильного приложения GrandApp Администрирование информационных систем
Администрирование информационных систем Программа Графический дизайнер старт карьеры
Программа Графический дизайнер старт карьеры Python nima?
Python nima? Двигатели на платформе arduino
Двигатели на платформе arduino Системы оптического распознавания документов
Системы оптического распознавания документов Концептуальное проектирование базы данных
Концептуальное проектирование базы данных Мир электронной почты, телеконференция. 9 класс
Мир электронной почты, телеконференция. 9 класс Основные направления развития искусственного интеллекта (лекция 2)
Основные направления развития искусственного интеллекта (лекция 2) Основы алгебры логики. Логические основы компьютера
Основы алгебры логики. Логические основы компьютера Виды 3D-моделирования
Виды 3D-моделирования