- Системы оптического распознавания документов

Содержание
- 2. Необходимость в системах распознавания символов С помощью сканера достаточно просто получить изображение страницы текста в графическом
- 3. Программы распознавания текста Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition
- 4. Получение электронного документа Отсканировать изображение (с помощью ПО сканера); Распознать структуру размещения текста на странице: выделить
- 5. Методы распознавания символов Если исходный документ имеет типографское качество то задача распознавания решается методом сравнения с
- 6. ABBYY FineReader FineReader - омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты,
- 7. Оптимальное разрешение при сканировании обычный текст - 300 dpi мелкий шрифт (9 и менее пунктов)- 400-600
- 8. Системы распознавания рукописного текста преобразуют текст, созданный на экране карманного компьютера специальной ручкой, в текстовый компьютерный
- 9. Системы оптического распознавания форм При заполнении документов большим количеством людей (например, при сдаче (ЕГЭ)) используются бланки
- 10. Вопросы: Зачем нужны программы распознавания текста? Как происходит распознавание текста? Какие программы распознания текста вы знаете?
- 12. Скачать презентацию

Необходимость в системах распознавания символов
С помощью сканера достаточно просто получить изображение
Необходимость в системах распознавания символов
С помощью сканера достаточно просто получить изображение

Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания
Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы распознавания

Получение электронного документа
Отсканировать изображение (с помощью ПО сканера);
Распознать структуру размещения текста
Получение электронного документа
Отсканировать изображение (с помощью ПО сканера);
Распознать структуру размещения текста

Методы распознавания символов
Если исходный документ имеет типографское качество то задача распознавания
Методы распознавания символов
Если исходный документ имеет типографское качество то задача распознавания

ABBYY FineReader
FineReader - омнифонтовая система оптического распознавания текстов. Это означает, что
ABBYY FineReader
FineReader - омнифонтовая система оптического распознавания текстов. Это означает, что
Оптимальное разрешение при сканировании
обычный текст - 300 dpi
мелкий шрифт (9
Оптимальное разрешение при сканировании
обычный текст - 300 dpi
мелкий шрифт (9

Системы распознавания рукописного текста
преобразуют текст, созданный на экране карманного компьютера
Системы распознавания рукописного текста
преобразуют текст, созданный на экране карманного компьютера
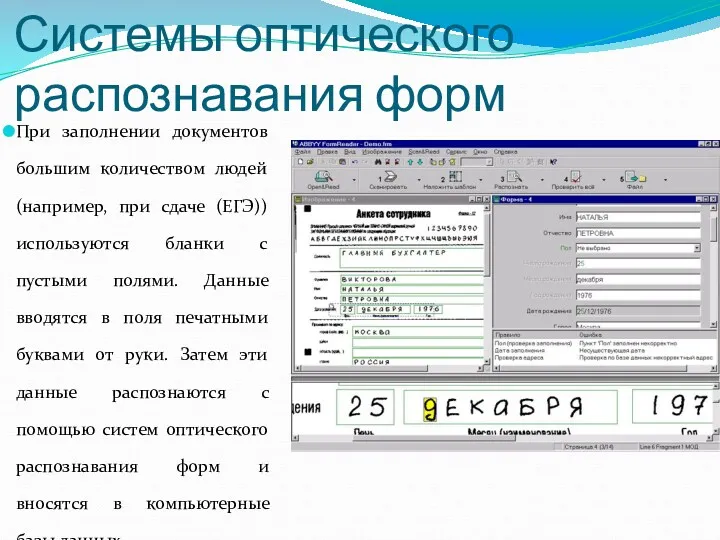
Системы оптического распознавания форм
При заполнении документов большим количеством людей (например, при
Системы оптического распознавания форм
При заполнении документов большим количеством людей (например, при

Вопросы:
Зачем нужны программы распознавания текста?
Как происходит распознавание текста?
Какие программы распознания текста
Вопросы:
Зачем нужны программы распознавания текста?
Как происходит распознавание текста?
Какие программы распознания текста
 Презентация-тест по теме Действия с информацией
Презентация-тест по теме Действия с информацией PriceBOX - мобильный маркет
PriceBOX - мобильный маркет Codzienna współpraca z DHL
Codzienna współpraca z DHL Моделирование в ARIS Express
Моделирование в ARIS Express Free PPT templates
Free PPT templates Структура языка Си. Основные функции ввода и вывода. Операторы языка. Обзор циклических операторов
Структура языка Си. Основные функции ввода и вывода. Операторы языка. Обзор циклических операторов Перемещение и копирование файлов и папок
Перемещение и копирование файлов и папок Защита информации в компьютерных сетях
Защита информации в компьютерных сетях Технология сетевого дизайна и ее программное обеспечение
Технология сетевого дизайна и ее программное обеспечение Сетевое сообщество учителей
Сетевое сообщество учителей Базы данных в информационных системах
Базы данных в информационных системах Методы визуального анализа и проектирования систем. Архитектурные стили. (Лекция 2)
Методы визуального анализа и проектирования систем. Архитектурные стили. (Лекция 2) Безопасный интернет
Безопасный интернет Эта презентация научит вас составлять презентации про то, как составлять презентации
Эта презентация научит вас составлять презентации про то, как составлять презентации Создание анимации в презентации
Создание анимации в презентации Информационные жанры журналистики. Лекция №2. Общая характеристика информационных жанров журналистики
Информационные жанры журналистики. Лекция №2. Общая характеристика информационных жанров журналистики Діловий стиль мовлення. Ділові папери
Діловий стиль мовлення. Ділові папери Визуализация данных. Правила оформления таблиц
Визуализация данных. Правила оформления таблиц Жанр компьютерных игр - шутер
Жанр компьютерных игр - шутер Фото, инфографика, анимация: понятие, специфика
Фото, инфографика, анимация: понятие, специфика Классические методы шифрования. Лекция 3 (ч.1)
Классические методы шифрования. Лекция 3 (ч.1) Компьютерные атаки
Компьютерные атаки Python. Числовые типы данных. Условный оператор. Логический тип
Python. Числовые типы данных. Условный оператор. Логический тип Системы обработки данных
Системы обработки данных Технологической цепочки решения задачи на ЭВМ
Технологической цепочки решения задачи на ЭВМ Информационная культура
Информационная культура Передача информации. Локальные компьютерные сети
Передача информации. Локальные компьютерные сети Компьютерная презентация к уроку по теме Общие правила безопасности для здоровья работы за компьютером
Компьютерная презентация к уроку по теме Общие правила безопасности для здоровья работы за компьютером