- Введение в искусственный интеллект. Тема 1

Содержание
- 2. Определения терминов Определение 1980 г: это область информатики, которая занимается разработкой интеллектуальных компьютерных систем, то есть
- 3. Классификация ИИ SAI ВА NAI WAI AGI ВА – BASIC ALGORITHMS Это простые интеллектуальные системы с
- 4. Выводы по классификации Данная классификация позволяет точнее определить значения термина ИИ в каждом контексте его употребления,
- 5. Почему мы можем говорить об ИИ как о глобальном тренде? Искусственный интеллект как глобальный тренд Наличие
- 6. Технологические направления ИИ. Данные Deloitte
- 7. Смежные области исследований Искусственный интеллект Машинное обучение Глубокое обучение Большие данные Data Science Data Mininig Технологии,
- 8. Машинное обучение Алгоритмы - специальные программы, "подсказывающие" компьютеру, каким источником данных необходимо воспользоваться Для каждой задачи
- 9. 1 Будущее Регрессия - составление прогнозов на основе выборки данных с отличающимися признаками 2 Классификация -
- 10. 1 Будущее Обучение с учителем – оно предполагает использование полного набора снабженных признаками данных (размеченного дата
- 11. Августовский рейтинг языков программирования на основе индекса TIOBE
- 12. Среды разработки В качестве среды разработки используются платформы и среды Visual Studio 22, R-Studio, R-Brain, Eclipse,
- 13. Глубокое обучение (Deep learning) Глубокое обучение не только может дать результат там, где другие методы не
- 14. Data Science Большие данные — это огромные объёмы неструктурированной информации: например, метеоданные за какой-то период, статистика
- 15. Data Mining Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро – один из основателей этого направления:
- 16. 1 Будущее Большие данные – Это набор подходов и методов, разработанных для анализа данных огромных размеров
- 17. Источники больших данных Источники сбора больших данных делятся на три типа: ➢ социальные ➢ машинные ➢
- 18. Концептуально мы рассмотрели составляющие или технологии искусственного интеллекта: Искусственный интеллект Машинное обучение Глубокое обучение Большие данные
- 20. Скачать презентацию
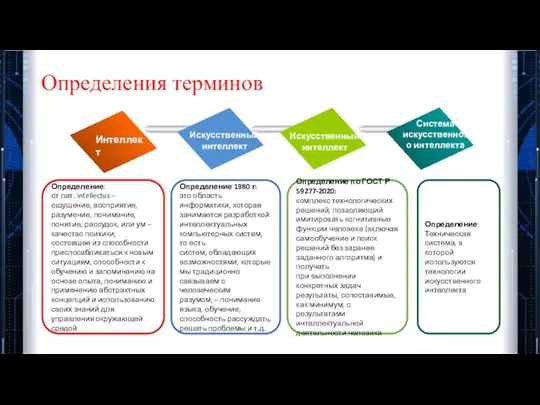
Определения терминов
Определение 1980 г:
это область информатики, которая занимается разработкой
интеллектуальных компьютерных систем,
Определения терминов
Определение 1980 г:
это область информатики, которая занимается разработкой
интеллектуальных компьютерных систем,
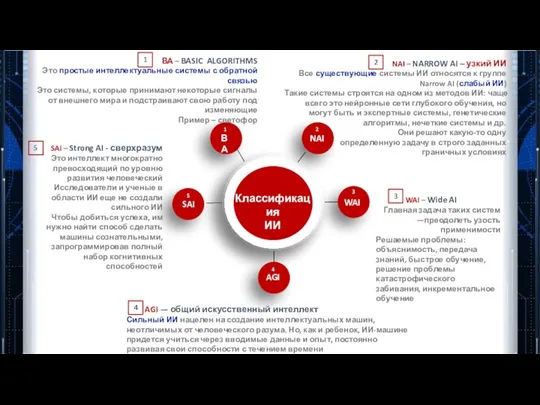
Классификация
ИИ
SAI
ВА
NAI
WAI
AGI
ВА – BASIC ALGORITHMS
Это простые интеллектуальные системы с обратной связью
Это
Классификация
ИИ
SAI
ВА
NAI
WAI
AGI
ВА – BASIC ALGORITHMS
Это простые интеллектуальные системы с обратной связью
Это

Выводы по классификации
Данная классификация позволяет точнее определить значения термина ИИ в
Выводы по классификации
Данная классификация позволяет точнее определить значения термина ИИ в

Почему мы можем говорить об ИИ как о глобальном тренде?
Искусственный интеллект
Почему мы можем говорить об ИИ как о глобальном тренде?
Искусственный интеллект

Технологические направления ИИ. Данные Deloitte
Технологические направления ИИ. Данные Deloitte
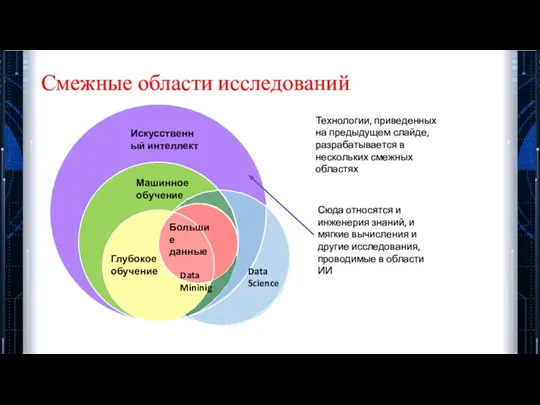
Смежные области исследований
Искусственный интеллект
Машинное обучение
Глубокое обучение
Большие данные
Data Science
Data Mininig
Технологии, приведенных на
Смежные области исследований
Искусственный интеллект
Машинное обучение
Глубокое обучение
Большие данные
Data Science
Data Mininig
Технологии, приведенных на

Машинное обучение
Алгоритмы - специальные программы, "подсказывающие" компьютеру, каким источником данных необходимо
Машинное обучение
Алгоритмы - специальные программы, "подсказывающие" компьютеру, каким источником данных необходимо

1
Будущее
Регрессия - составление прогнозов на основе выборки данных с отличающимися признаками
2
Классификация
1
Будущее
Регрессия - составление прогнозов на основе выборки данных с отличающимися признаками
2
Классификация

1
Будущее
Обучение с учителем – оно предполагает использование
полного набора снабженных признаками данных
1
Будущее
Обучение с учителем – оно предполагает использование
полного набора снабженных признаками данных
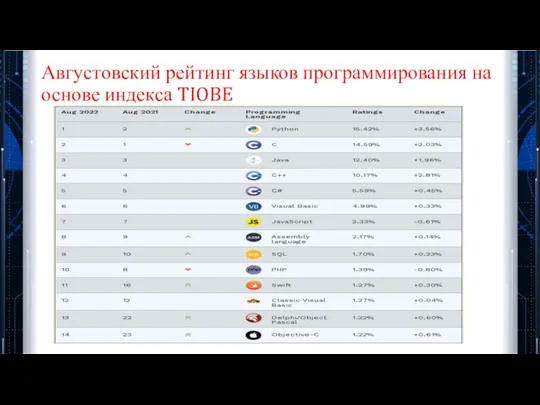
Августовский рейтинг языков программирования на основе индекса TIOBE
Августовский рейтинг языков программирования на основе индекса TIOBE

Среды разработки
В качестве среды разработки используются платформы и среды Visual Studio
Среды разработки
В качестве среды разработки используются платформы и среды Visual Studio

Глубокое обучение (Deep learning)
Глубокое обучение не только может дать результат там,
Глубокое обучение (Deep learning)
Глубокое обучение не только может дать результат там,

Data Science
Большие данные — это огромные объёмы неструктурированной информации: например, метеоданные
Data Science
Большие данные — это огромные объёмы неструктурированной информации: например, метеоданные

Data Mining
Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро – один
Data Mining
Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро – один

1
Будущее
Большие данные – Это набор подходов и методов, разработанных для анализа
1
Будущее
Большие данные – Это набор подходов и методов, разработанных для анализа

Источники больших данных
Источники сбора больших данных делятся на три типа:
➢
Источники больших данных
Источники сбора больших данных делятся на три типа:
➢

Концептуально мы рассмотрели составляющие или технологии искусственного интеллекта:
Искусственный интеллект
Машинное обучение
Глубокое обучение
Большие
Концептуально мы рассмотрели составляющие или технологии искусственного интеллекта:
Искусственный интеллект
Машинное обучение
Глубокое обучение
Большие
 Хмарні технології
Хмарні технології Алгоритм и его свойства. Составление линейных алгоритмов
Алгоритм и его свойства. Составление линейных алгоритмов Требования к современным операционным системам
Требования к современным операционным системам DCT – Wavelet – Filter Bank
DCT – Wavelet – Filter Bank Кодирование звука
Кодирование звука Облачные технологии в образовании
Облачные технологии в образовании Услуги: 1С БухОбслуживание
Услуги: 1С БухОбслуживание Әлеуметтік желінің зияны мен пайдасы
Әлеуметтік желінің зияны мен пайдасы час звена Психоактивные вещества
час звена Психоактивные вещества Как выполнить работу в Power Point
Как выполнить работу в Power Point презентация, сопровождающая объяснение нового материала
презентация, сопровождающая объяснение нового материала 3DMask. Разработка приложения для мобильных устройств
3DMask. Разработка приложения для мобильных устройств Системы счисления
Системы счисления Искусственный интеллект в играх
Искусственный интеллект в играх Доменная система имён. Протоколы передачи данных
Доменная система имён. Протоколы передачи данных Сбор и анализ требований к программному обеспечению. Технология разработки программного обеспечения
Сбор и анализ требований к программному обеспечению. Технология разработки программного обеспечения Модели данных
Модели данных Модели и моделирование
Модели и моделирование Даркнет. Как войти в Даркнет
Даркнет. Как войти в Даркнет Хмарні обчислення
Хмарні обчислення Методичка по созданию сайта на Google платформе
Методичка по созданию сайта на Google платформе Статистичні методи і обробка інформації у суспільній географії. (Лекція 1)
Статистичні методи і обробка інформації у суспільній географії. (Лекція 1) Опыт и перспективы работы педагогов дополнительного образования в дистанционном формате
Опыт и перспективы работы педагогов дополнительного образования в дистанционном формате Створення програмного забезпечення
Створення програмного забезпечення Система безопасности серверов БД
Система безопасности серверов БД Технология оцифровки архивных документов. Теория и практика
Технология оцифровки архивных документов. Теория и практика Разработка АИС Клиенті и планирование
Разработка АИС Клиенті и планирование Презентация Клавиатуры
Презентация Клавиатуры