- Вычисления на GPU с использованием NVIDIA CUDA

Содержание
- 2. Немного истории С самого появления GPU у разработчиков появилась идея перекладывать часть расчетов с CPU на
- 3. Краткое введение в технологию Технология CUDA — это программно-аппаратная вычислительная архитектура Nvidia, основанная на расширении языка
- 4. Основные возможности технологии Унифицированное программно-аппаратное решение для параллельных вычислений на видеочипах Nvidia; Стандартный язык программирования Си;
- 5. Основные сферы применения Симуляция поведения различных тел Обработка графики Расчет геометрии Вычисление различных хэшей Компьютерное зрение
- 6. Техническая реализация Для вызова функции на стороне GPU нужно: Выделить память под аргументы Скопировать данные с
- 7. Работа с памятью Работа с памятью организована при помощи функций cudaMalloc – выделение блока памяти cudaMalloc3D
- 8. Чуть подробнее про cudaMallocPitch Данная функция не только выделяет память под данные, но и гарантирует сохранение
- 9. Исполнение инструкций Вызов функции, на стороне GPU идет немного необычно Так же функция должна иметь модификатор
- 10. Плюсы технологии Быстрые вычисления Хорошая архитектура для многопоточности Удобный инструментарий и отсутствие лишних телодвижений при передаче
- 11. Минусы технологии Передача данных от CPU к GPU достаточно дорогая операция. Иногда это заставляет передавать лишние
- 12. Примеры Построение множества Мондельброта
- 13. Симуляция поверхности воды
- 15. Скачать презентацию

Немного истории
С самого появления GPU у разработчиков появилась идея перекладывать часть
Немного истории
С самого появления GPU у разработчиков появилась идея перекладывать часть

Краткое введение в технологию
Технология CUDA — это программно-аппаратная вычислительная архитектура Nvidia,
Краткое введение в технологию
Технология CUDA — это программно-аппаратная вычислительная архитектура Nvidia,

Основные возможности технологии
Унифицированное программно-аппаратное решение для параллельных вычислений на видеочипах Nvidia;
Стандартный
Основные возможности технологии
Унифицированное программно-аппаратное решение для параллельных вычислений на видеочипах Nvidia;
Стандартный

Основные сферы применения
Симуляция поведения различных тел
Обработка графики
Расчет геометрии
Вычисление различных хэшей
Компьютерное
Основные сферы применения
Симуляция поведения различных тел
Обработка графики
Расчет геометрии
Вычисление различных хэшей
Компьютерное

Техническая реализация
Для вызова функции на стороне GPU нужно:
Выделить память под аргументы
Скопировать
Техническая реализация
Для вызова функции на стороне GPU нужно:
Выделить память под аргументы
Скопировать

Работа с памятью
Работа с памятью организована при помощи функций
cudaMalloc – выделение
Работа с памятью
Работа с памятью организована при помощи функций
cudaMalloc – выделение

Чуть подробнее про cudaMallocPitch
Данная функция не только выделяет память под данные,
Чуть подробнее про cudaMallocPitch
Данная функция не только выделяет память под данные,

Исполнение инструкций
Вызов функции, на стороне GPU идет немного необычно
Так же функция
Исполнение инструкций
Вызов функции, на стороне GPU идет немного необычно
Так же функция

Плюсы технологии
Быстрые вычисления
Хорошая архитектура для многопоточности
Удобный инструментарий и отсутствие лишних телодвижений
Плюсы технологии
Быстрые вычисления
Хорошая архитектура для многопоточности
Удобный инструментарий и отсутствие лишних телодвижений

Минусы технологии
Передача данных от CPU к GPU достаточно дорогая операция. Иногда
Минусы технологии
Передача данных от CPU к GPU достаточно дорогая операция. Иногда

Примеры
Построение множества Мондельброта
Примеры
Построение множества Мондельброта

Симуляция поверхности воды
Симуляция поверхности воды
 Азбука журналистики
Азбука журналистики Методы и средства хранения информации
Методы и средства хранения информации Сел қауіптілігін карторграфиялауға арналған геоақпараттық жүйелер
Сел қауіптілігін карторграфиялауға арналған геоақпараттық жүйелер Защита информации в базах данных
Защита информации в базах данных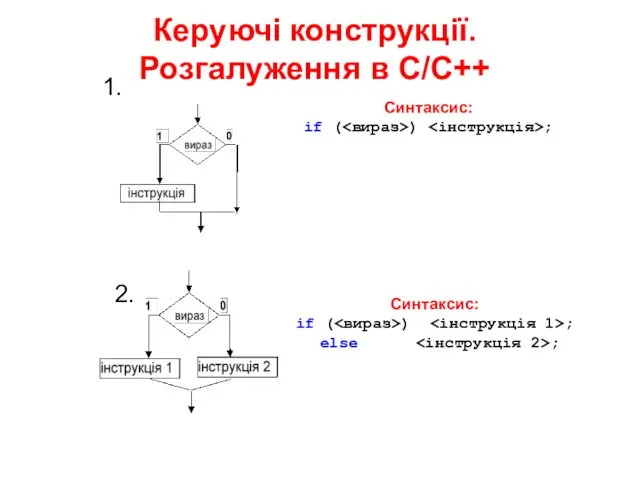 Керуючі конструкції. Розгалуження в С/C++
Керуючі конструкції. Розгалуження в С/C++ Вёрстка и дизайн газетной статьи
Вёрстка и дизайн газетной статьи Всемирная компьютерная сеть интернет. Опорный конспект
Всемирная компьютерная сеть интернет. Опорный конспект Составляющие информационной технологии
Составляющие информационной технологии Шесть видов подключения интернета
Шесть видов подключения интернета NAVY. Проблемы в создании рекламных роликов
NAVY. Проблемы в создании рекламных роликов Программирование в компьютерных системах
Программирование в компьютерных системах FaceByte UI Review
FaceByte UI Review Операционная система
Операционная система Минимальные маршруты и покрытия. Лекция 5
Минимальные маршруты и покрытия. Лекция 5 Измерение информации
Измерение информации Современная поэзия. Где смотреть
Современная поэзия. Где смотреть Презентация по теме Основы алгоритмизации
Презентация по теме Основы алгоритмизации Компьютерная лексикография (электронные словари в интернете)
Компьютерная лексикография (электронные словари в интернете) Проектная деятельность на уроках информатики
Проектная деятельность на уроках информатики Право и этика в Интернете
Право и этика в Интернете Графика в Quick Basic
Графика в Quick Basic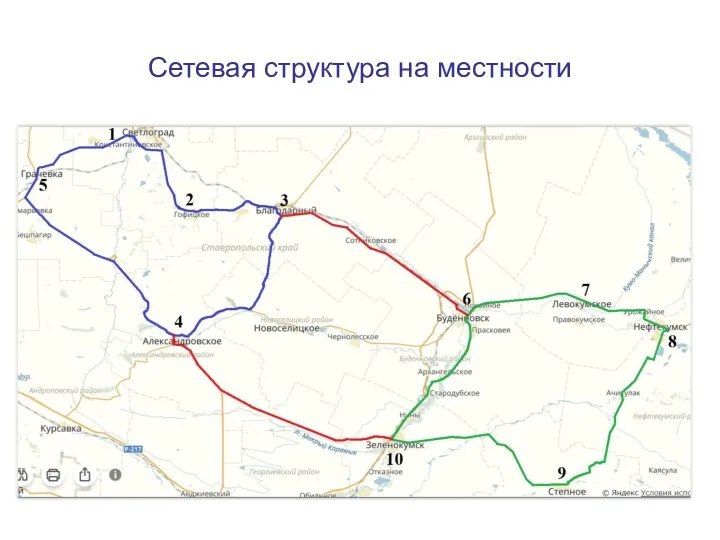 Сетевая структура на местности
Сетевая структура на местности Информация. Аппаратура компьютера
Информация. Аппаратура компьютера Правила создания презентаций.Урок родного (русского) языка.. 6 класс
Правила создания презентаций.Урок родного (русского) языка.. 6 класс Создание видеоклипа из цифровых фотографий
Создание видеоклипа из цифровых фотографий Сжатие, архивация и разархивация данных. Архиваторы. Работа с архивами
Сжатие, архивация и разархивация данных. Архиваторы. Работа с архивами Widgets. Custom Widgets Types
Widgets. Custom Widgets Types Презентация:Базы данных Урок 11 класс; Урок: Моделирование как метод познания.
Презентация:Базы данных Урок 11 класс; Урок: Моделирование как метод познания.