Identifying dialectal features of the Udmurt language with the help of an internet corpus презентация
- Identifying dialectal features of the Udmurt language with the help of an internet corpus

Содержание
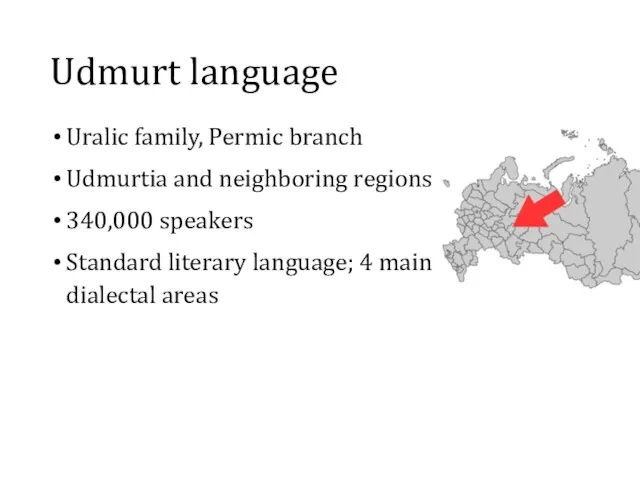
- 2. Udmurt language Uralic family, Permic branch Udmurtia and neighboring regions 340,000 speakers Standard literary language; 4
- 3. Corpus Collection of texts Linguistic annotation: metadata lemmatization, morphological annotation any other kind of annotation (e.g.
- 4. Udmurt vk-corpus Posts and comments of Udmurt-language Vkontakte groups and users 2.5 million tokens in Udmurt
- 5. Udmurt vk-corpus Мон бы пукысал али и кылзӥськысал Лариса Васильевнаез, сое можно кылзыны вечность. Интерес не
- 6. Udmurt vk-corpus Мон бы пукысал али и кылзӥськысал Лариса Васильевнаез, сое можно кылзыны вечность. Интерес не
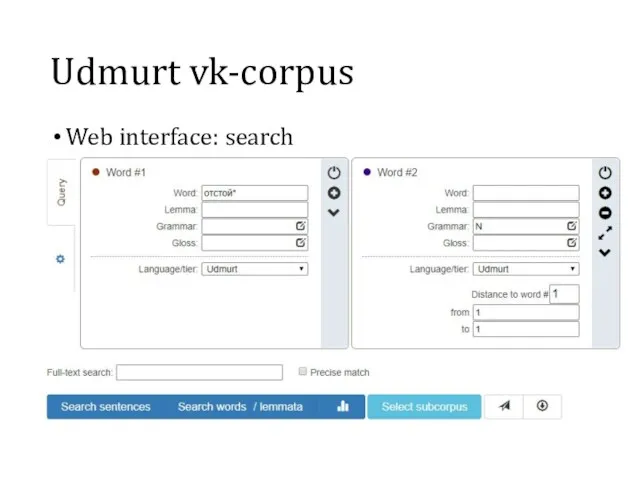
- 7. Udmurt vk-corpus Web interface: search
- 8. Udmurt vk-corpus Web interface: search results
- 9. Dialectology Phonetics Lexicon Morphology Syntax traditional dialectology
- 10. vk-corpus: phonetics People try not to deviate from the standard variety; orthography cannot reflect all dialectal
- 11. vk-corpus: lexicon Many people try to use the standard vocabulary Nevertheless, dialectal words show up quite
- 12. Particle бон/ бен
- 13. ‘Forest’ (Maksimov 2007)
- 14. Подорожник (Maksimov 2013)
- 15. Borrowed Russian verbs The standard way of borrowing a Russian verb is to use the construction
- 16. Borrowed Russian verbs There is a detransitivising suffix -ськ-/-ск- in Udmurt, which semantically is very close
- 17. Borrowed Russian verbs If a reflexive Russian verb is borrowed: either the light verb карыны has
- 18. Borrowed Russian verbs Possible hypotheses regarding the distribution of the two variants: lexical (depends on the
- 19. Borrowed Russian verbs Possible hypotheses regarding the distribution of the two variants: lexical: same verbs often
- 20. Russian verbs: кариськыны / карыны (vk + blogs)
- 21. Borrowed Russian verbs The choice is clearly geographically conditioned The detransitive-less strategy prevails on the territory
- 22. Conclusion An internet corpus can provide the data for identifying dialectal features The phonetic differences are
- 24. Скачать презентацию
Udmurt language
Uralic family, Permic branch
Udmurtia and neighboring regions
340,000 speakers
Standard literary language;
Udmurt language
Uralic family, Permic branch
Udmurtia and neighboring regions
340,000 speakers
Standard literary language;

Corpus
Collection of texts
Linguistic annotation:
metadata
lemmatization, morphological annotation
any other kind of annotation (e.g.
Corpus
Collection of texts
Linguistic annotation:
metadata
lemmatization, morphological annotation
any other kind of annotation (e.g.

Udmurt vk-corpus
Posts and comments of Udmurt-language Vkontakte groups and users
2.5 million
Udmurt vk-corpus
Posts and comments of Udmurt-language Vkontakte groups and users
2.5 million

Udmurt vk-corpus
Мон бы пукысал али и кылзӥськысал Лариса Васильевнаез, сое можно кылзыны вечность. Интерес не пропадёт. Тау та смена
Udmurt vk-corpus
Мон бы пукысал али и кылзӥськысал Лариса Васильевнаез, сое можно кылзыны вечность. Интерес не пропадёт. Тау та смена

Udmurt vk-corpus
Мон бы пукысал али и кылзӥськысал Лариса Васильевнаез, сое можно кылзыны вечность. Интерес не пропадёт. Тау та смена
Udmurt vk-corpus
Мон бы пукысал али и кылзӥськысал Лариса Васильевнаез, сое можно кылзыны вечность. Интерес не пропадёт. Тау та смена
Udmurt vk-corpus
Web interface: search
Udmurt vk-corpus
Web interface: search

Udmurt vk-corpus
Web interface: search results
Udmurt vk-corpus
Web interface: search results

Dialectology
Phonetics
Lexicon
Morphology
Syntax
traditional dialectology
Dialectology
Phonetics
Lexicon
Morphology
Syntax
traditional dialectology

vk-corpus: phonetics
People try not to deviate from the standard variety; orthography
vk-corpus: phonetics
People try not to deviate from the standard variety; orthography

vk-corpus: lexicon
Many people try to use the standard vocabulary
Nevertheless, dialectal words
vk-corpus: lexicon
Many people try to use the standard vocabulary
Nevertheless, dialectal words
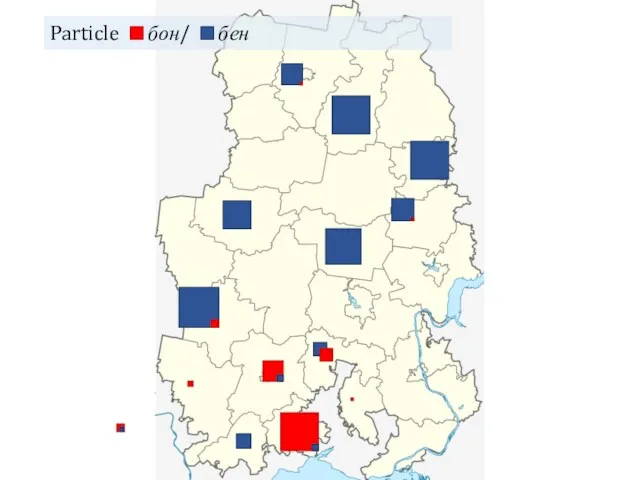
Particle бон/ бен
Particle бон/ бен
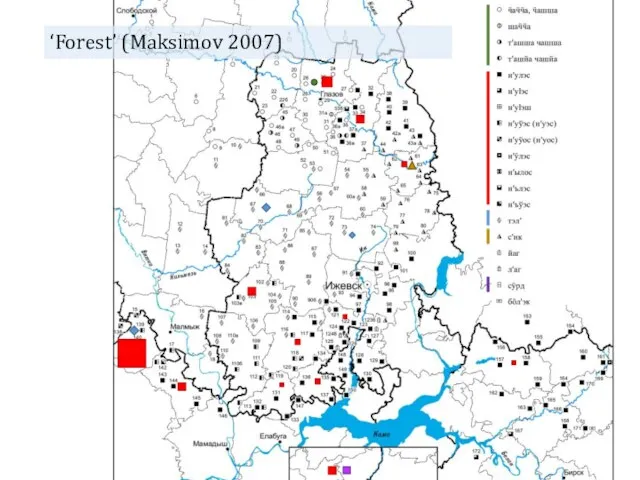
‘Forest’ (Maksimov 2007)
‘Forest’ (Maksimov 2007)
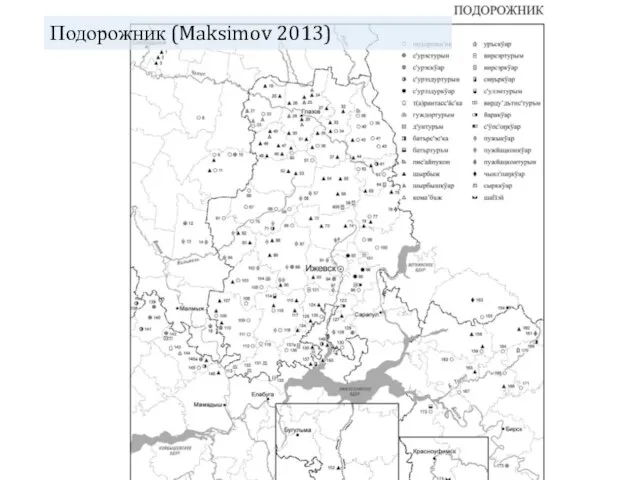
Подорожник (Maksimov 2013)
Подорожник (Maksimov 2013)

Borrowed Russian verbs
The standard way of borrowing a Russian verb is
Borrowed Russian verbs
The standard way of borrowing a Russian verb is

Borrowed Russian verbs
There is a detransitivising suffix -ськ-/-ск- in Udmurt, which
Borrowed Russian verbs
There is a detransitivising suffix -ськ-/-ск- in Udmurt, which

Borrowed Russian verbs
If a reflexive Russian verb is borrowed:
either the light
Borrowed Russian verbs
If a reflexive Russian verb is borrowed:
either the light

Borrowed Russian verbs
Possible hypotheses regarding the distribution of the two variants:
lexical
Borrowed Russian verbs
Possible hypotheses regarding the distribution of the two variants:
lexical

Borrowed Russian verbs
Possible hypotheses regarding the distribution of the two variants:
lexical:
Borrowed Russian verbs
Possible hypotheses regarding the distribution of the two variants:
lexical:
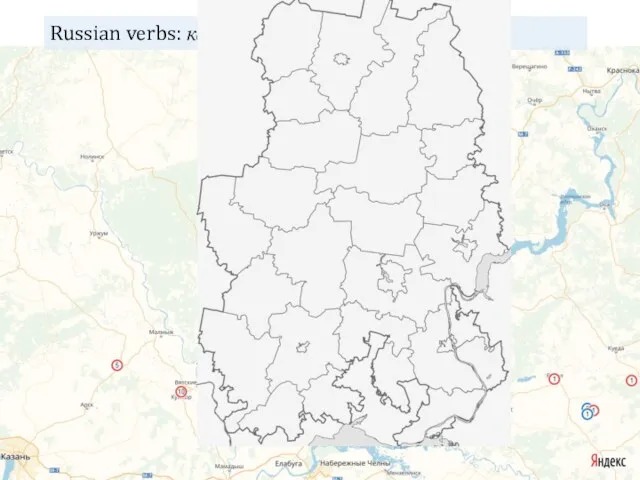
Russian verbs: кариськыны / карыны (vk + blogs)
Russian verbs: кариськыны / карыны (vk + blogs)

Borrowed Russian verbs
The choice is clearly geographically conditioned
The detransitive-less strategy prevails
Borrowed Russian verbs
The choice is clearly geographically conditioned
The detransitive-less strategy prevails

Conclusion
An internet corpus can provide the data for identifying dialectal features
The
Conclusion
An internet corpus can provide the data for identifying dialectal features
The
 Презентация к уроку английского языка School is fun 4 класс
Презентация к уроку английского языка School is fun 4 класс Жаңа сөздер – Новые слова. 6 класс
Жаңа сөздер – Новые слова. 6 класс урок - презентация
урок - презентация Презентация к уроку Времена года
Презентация к уроку Времена года Ж дыбысы
Ж дыбысы Введение в грамматику по японскому языку
Введение в грамматику по японскому языку Обучение письму и письменной речи на иностранном языке
Обучение письму и письменной речи на иностранном языке Конспект по французскому языку 2 класс Портрет
Конспект по французскому языку 2 класс Портрет Технологія редагування і техніка правки
Технологія редагування і техніка правки Достопримечательности Лондона,4 класс
Достопримечательности Лондона,4 класс Етістік сөзжасамы
Етістік сөзжасамы Презентация по английскому языку для 6 класса по теме Охрана окружающей среды
Презентация по английскому языку для 6 класса по теме Охрана окружающей среды Үткән заман сыйфат фигыль
Үткән заман сыйфат фигыль Презентация по теме Животные
Презентация по теме Животные Welcome to the capital of Great Britain
Welcome to the capital of Great Britain Презентация по английскому языку Jonathan Swift
Презентация по английскому языку Jonathan Swift Загальне поняття про прикметник
Загальне поняття про прикметник Частини мови і принципи їх класифікації. Граматичні категорії іменних частин мови
Частини мови і принципи їх класифікації. Граматичні категорії іменних частин мови Этапы создания текста перевода
Этапы создания текста перевода Презентация к уроку по теме About myself
Презентация к уроку по теме About myself Презентация к уроку немецкого языка: Das Turngymnastik und die Phönetische Übungen (2 класс)
Презентация к уроку немецкого языка: Das Turngymnastik und die Phönetische Übungen (2 класс) Интерактивный тест по теме The ABC для 2 класса
Интерактивный тест по теме The ABC для 2 класса Билингвизм. Типы билингвизма
Билингвизм. Типы билингвизма Катлаулы кушма җөмлә
Катлаулы кушма җөмлә Славянские языки в преподавании русского
Славянские языки в преподавании русского Introduction to CLIL (Content and Language Integrated Learning). Lecture 1
Introduction to CLIL (Content and Language Integrated Learning). Lecture 1 Внеклассное мероприятие в начальной школе Играем по-английски
Внеклассное мероприятие в начальной школе Играем по-английски Роль игры в изучении новой лексики по теме: Профессии
Роль игры в изучении новой лексики по теме: Профессии