- Лингвистика для математиков. Исправление опечаток 1

Содержание
- 2. Удивительно, но начнём мы сегодня с задачи В автоматической обработке естественного языка (например, при автоматической проверке
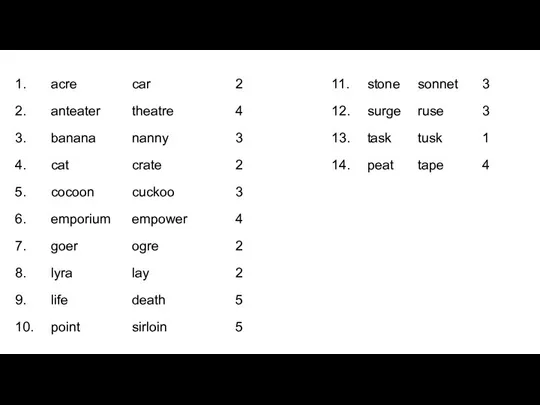
- 4. Задание 1. Заполните пропуски. Задание 2. Дайте определение расстоянию Дамерау–Левенштейна и предположите, какие классы опечаток выделил
- 5. Изначальная идея
- 6. Что такое spell checker Софт/программа, которая проверяет текст на наличие опечаток Задачи Поиск опечаток Исправление опечаток:
- 7. Применение
- 8. Just a really old meme
- 9. Виды опечаток Non-word errors Real world errors Когнитивные ошибки Ошибки при записи речи “на слух” Ошибки
- 10. Задание. 1913 год - не тот мир
- 11. Работа с real word опечатками Для каждого слова w генерируем список кандидатов: • Ищем кандидатов с
- 12. Работа с non-word опечатками Поиск non-word опечаток: Составляем словарь. Если слово не в словаре → это
- 13. Методом составления словаря
- 14. Работа с non-word опечатками Поиск non-word опечаток: Составляем словарь. Если слово не в словаре → это
- 15. Методом Bk-tress Преобразуем словарь в дерево Корень - случайное слово из словаря Слова из словаря связываются
- 16. Bk-tress
- 17. Что такое “близкие слова” Можно искать близкие слова в словаре Для этого нужно задать функцию расстояния
- 18. Функции расстояния между строками Hamming расстояние = количество необходимых замен в строке Арина Vs. Алина =
- 19. Функции расстояния между строками Hamming расстояние = количество необходимых замен в строке Арина Vs. Алина =
- 20. Функции расстояния между строками Hamming расстояние = количество необходимых замен в строке Арина Vs. Алина =
- 21. Модель близости слов Формальное определение: Расстояние Левенштейна p(u, v) между словами u и v -- минимальное
- 22. Модель близости слов d(montagne, mountain) = 3 Посчитали количество необходимых операций
- 23. Вычисление расстояния Левенштейна Введём обозначения: w = w[0] ... w[n-1] -- слово, где |w| = n
- 24. Вычисление расстояния Левенштейна Введём обозначения: w = w[0] ... w[n-1] -- слово, где |w| = n
- 25. Вычисление расстояние Левенштейна Разделяй и властвуй Какие есть подзадачи
- 26. Вычисление расстояние Левенштейна То же самое в виде таблицы yabxe → abcde
- 27. Формула расстояния Левенштейна
- 28. Вычисление расстояние Левенштейна Посчитайте расстояние между соль Vs. волос с помощью таблицы Какое расстояние будет между
- 29. Оптимальное выравнивание Это путь по таблице, который приводит к преобразованию одной строки в другую с минимальным
- 30. Взвешенное расстояние Левенштейна Какое расстояние между этими словами d(loup, lobo) из здравого смысла?
- 31. Взвешенное расстояние Левенштейна Какое расстояние между этими словами d(loup, lobo) из здравого смысла? Теперь попробуйте посчитать
- 32. Взвешенное расстояние Левенштейна Какое расстояние между этими словами d(loup, lobo) из здравого смысла? Теперь попробуйте посчитать
- 33. Взвешенное расстояние Левенштейна Какое расстояние между этими словами d(loup, lobo) из здравого смысла? Теперь попробуйте посчитать
- 34. Модель близости слов Еще раз как же выглядит модель по поиску ошибок и их исправлению этой
- 35. Модель близости слов Еще раз как же выглядит модель по поиску ошибок и их исправлению этой
- 36. Взвешенное расстояние Левенштейна Как же определять веса? Можем условно считать, что вес - это вероятность опечатки
- 37. Кстати, про фонетическую близость обычно в алгоритмах с метриками расстояния кандидатами в итоге считаются слова, которые
- 38. Soundex
- 39. Дан список фамилий и соответствующих им кодов Soundex в перепутанном порядке. Некоторые символы пропущены: Allaway, Anderson,
- 40. Soundex Задание 1. Опишите пошагово, как генерируется код Soundex. Задание 2. Установите соответствия между фамилиями и
- 41. Всем спасибо
- 43. Скачать презентацию

Удивительно, но начнём мы сегодня с задачи
В автоматической обработке естественного языка
Удивительно, но начнём мы сегодня с задачи
В автоматической обработке естественного языка

Задание 1. Заполните пропуски.
Задание 2. Дайте определение расстоянию Дамерау–Левенштейна и предположите,
Задание 1. Заполните пропуски.
Задание 2. Дайте определение расстоянию Дамерау–Левенштейна и предположите,

Изначальная идея
Изначальная идея

Что такое spell checker
Софт/программа, которая проверяет текст на наличие опечаток
Задачи
Поиск опечаток
Исправление
Что такое spell checker
Софт/программа, которая проверяет текст на наличие опечаток
Задачи
Поиск опечаток
Исправление
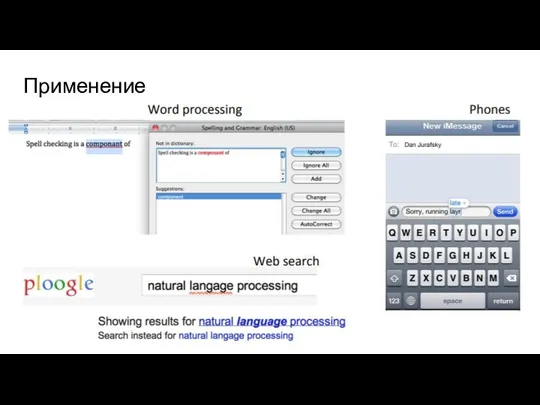
Применение
Применение
Just a really old meme
Just a really old meme

Виды опечаток
Non-word errors
Real world errors
Когнитивные ошибки
Ошибки при записи речи “на слух”
Ошибки
Виды опечаток
Non-word errors
Real world errors
Когнитивные ошибки
Ошибки при записи речи “на слух”
Ошибки

Задание. 1913 год - не тот мир
Задание. 1913 год - не тот мир

Работа с real word опечатками
Для каждого слова w генерируем список кандидатов:
Работа с real word опечатками
Для каждого слова w генерируем список кандидатов:

Работа с non-word опечатками
Поиск non-word опечаток:
Составляем словарь.
Если слово не в словаре
Работа с non-word опечатками
Поиск non-word опечаток:
Составляем словарь.
Если слово не в словаре
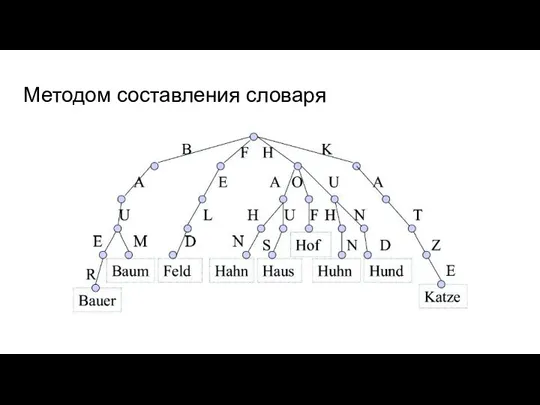
Методом составления словаря
Методом составления словаря

Работа с non-word опечатками
Поиск non-word опечаток:
Составляем словарь.
Если слово не в словаре
Работа с non-word опечатками
Поиск non-word опечаток:
Составляем словарь.
Если слово не в словаре

Методом Bk-tress
Преобразуем словарь в дерево
Корень - случайное слово из словаря
Слова из
Методом Bk-tress
Преобразуем словарь в дерево
Корень - случайное слово из словаря
Слова из
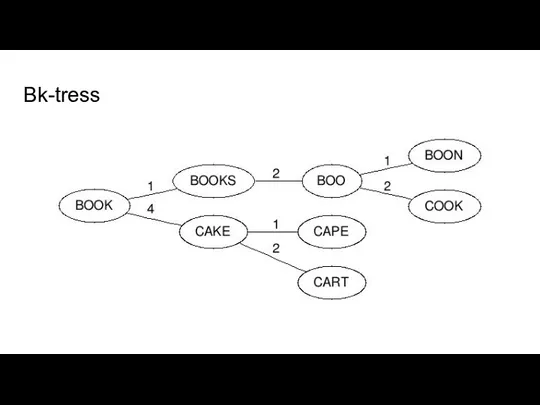
Bk-tress
Bk-tress

Что такое “близкие слова”
Можно искать близкие слова в словаре
Для этого нужно
Что такое “близкие слова”
Можно искать близкие слова в словаре
Для этого нужно

Функции расстояния между строками
Hamming расстояние = количество необходимых замен в строке
Арина
Функции расстояния между строками
Hamming расстояние = количество необходимых замен в строке
Арина

Функции расстояния между строками
Hamming расстояние = количество необходимых замен в строке
Арина
Функции расстояния между строками
Hamming расстояние = количество необходимых замен в строке
Арина

Функции расстояния между строками
Hamming расстояние = количество необходимых замен в строке
Арина
Функции расстояния между строками
Hamming расстояние = количество необходимых замен в строке
Арина

Модель близости слов
Формальное определение:
Расстояние Левенштейна p(u, v) между словами u и
Модель близости слов
Формальное определение:
Расстояние Левенштейна p(u, v) между словами u и

Модель близости слов
d(montagne, mountain) = 3
Посчитали количество необходимых операций
Модель близости слов
d(montagne, mountain) = 3
Посчитали количество необходимых операций
![Вычисление расстояния Левенштейна Введём обозначения: w = w[0] ... w[n-1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/399712/slide-22.jpg)
Вычисление расстояния Левенштейна
Введём обозначения:
w = w[0] ... w[n-1] -- слово, где
Вычисление расстояния Левенштейна
Введём обозначения:
w = w[0] ... w[n-1] -- слово, где
![Вычисление расстояния Левенштейна Введём обозначения: w = w[0] ... w[n-1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/399712/slide-23.jpg)
Вычисление расстояния Левенштейна
Введём обозначения:
w = w[0] ... w[n-1] -- слово, где
Вычисление расстояния Левенштейна
Введём обозначения:
w = w[0] ... w[n-1] -- слово, где

Вычисление расстояние Левенштейна
Разделяй и властвуй
Какие есть подзадачи
Вычисление расстояние Левенштейна
Разделяй и властвуй
Какие есть подзадачи

Вычисление расстояние Левенштейна
То же самое в виде таблицы
yabxe → abcde
Вычисление расстояние Левенштейна
То же самое в виде таблицы
yabxe → abcde

Формула расстояния Левенштейна
Формула расстояния Левенштейна

Вычисление расстояние Левенштейна
Посчитайте расстояние между соль Vs. волос с помощью таблицы
Какое
Вычисление расстояние Левенштейна
Посчитайте расстояние между соль Vs. волос с помощью таблицы
Какое

Оптимальное выравнивание
Это путь по таблице, который приводит к преобразованию одной строки
Оптимальное выравнивание
Это путь по таблице, который приводит к преобразованию одной строки

Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого
Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого

Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого
Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого

Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого
Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого

Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого
Взвешенное расстояние Левенштейна
Какое расстояние между этими словами d(loup, lobo) из здравого

Модель близости слов
Еще раз как же выглядит модель по поиску ошибок
Модель близости слов
Еще раз как же выглядит модель по поиску ошибок

Модель близости слов
Еще раз как же выглядит модель по поиску ошибок
Модель близости слов
Еще раз как же выглядит модель по поиску ошибок

Взвешенное расстояние Левенштейна
Как же определять веса? Можем условно считать, что вес
Взвешенное расстояние Левенштейна
Как же определять веса? Можем условно считать, что вес

Кстати, про фонетическую близость
обычно в алгоритмах с метриками расстояния кандидатами в
Кстати, про фонетическую близость
обычно в алгоритмах с метриками расстояния кандидатами в
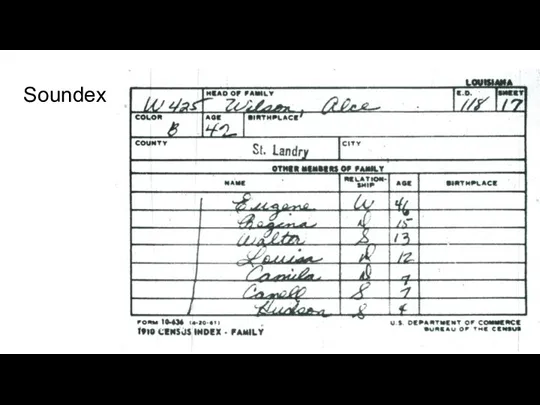
Soundex
Soundex

Дан список фамилий и соответствующих им кодов Soundex в перепутанном порядке.
Дан список фамилий и соответствующих им кодов Soundex в перепутанном порядке.

Soundex
Задание 1. Опишите пошагово, как генерируется код Soundex.
Задание 2. Установите соответствия
Soundex
Задание 1. Опишите пошагово, как генерируется код Soundex.
Задание 2. Установите соответствия

Всем спасибо
Всем спасибо
 第十五课. Урок по китайскому языку
第十五课. Урок по китайскому языку К уроку по теме She's got blue eyes
К уроку по теме She's got blue eyes Гамил Афзал шигырьләрен мәктәптә укыту тәҗрибәсе һәм аларның тәрбияви әһәмияте
Гамил Афзал шигырьләрен мәктәптә укыту тәҗрибәсе һәм аларның тәрбияви әһәмияте Презентация к внеклассному мероприятию Этот удивительный М. Твен
Презентация к внеклассному мероприятию Этот удивительный М. Твен Складні та багатокомпонентні речення. Особливості структури та семантики сполучникових і безсполучникових речень
Складні та багатокомпонентні речення. Особливості структури та семантики сполучникових і безсполучникових речень Звуки [т], [т'], позначення їх буквою т, Т (те). Читання складів і слів із буквою (урок № 083)
Звуки [т], [т'], позначення їх буквою т, Т (те). Читання складів і слів із буквою (урок № 083) Словари как отражение современных научных тенденций в лингвистике
Словари как отражение современных научных тенденций в лингвистике Презентация Модальный глагол CAN (Spotlight 2)
Презентация Модальный глагол CAN (Spotlight 2) Тайна имени Софья
Тайна имени Софья The emergence of sociolinguistics: where, when and why?
The emergence of sociolinguistics: where, when and why? Соответствия в переводе
Соответствия в переводе Ćwiczenia fonetyczne
Ćwiczenia fonetyczne возвратные местоимения в английском языке
возвратные местоимения в английском языке Онлайн переводчики. Словари
Онлайн переводчики. Словари Futuro imediato.No restaurante
Futuro imediato.No restaurante Відокремлені уточнювальні члени речення. 8 клас
Відокремлені уточнювальні члени речення. 8 клас презентация на тему Цифры (саннар)
презентация на тему Цифры (саннар) Звуковий аналіз слів. Голосні та приголосні звуки. Позначення їх умовними позначками
Звуковий аналіз слів. Голосні та приголосні звуки. Позначення їх умовними позначками Le club des amateurs de la langue française Croissant - 7
Le club des amateurs de la langue française Croissant - 7 Разработка урока по английскому языку 2-й класс Путешествие в Волшебный лес
Разработка урока по английскому языку 2-й класс Путешествие в Волшебный лес Презентация Еда к уроку английского языка в 4 классе
Презентация Еда к уроку английского языка в 4 классе Навчання грамоти. Написання малої букви щ, складів, слів і речень з вивченими буквами
Навчання грамоти. Написання малої букви щ, складів, слів і речень з вивченими буквами Lexical transformation
Lexical transformation Август Шлейхер. Натуралистическое направление
Август Шлейхер. Натуралистическое направление Quelle heure est-il? Leçon 19
Quelle heure est-il? Leçon 19 Los quehaceres
Los quehaceres Урок по китайскому языку. (Урок 18)
Урок по китайскому языку. (Урок 18) Презентация Простое прошедшее время
Презентация Простое прошедшее время