- Анализ эмпирических данных. (Тема 9)

Содержание
- 2. Виды анализа данных Эмпирические данные могут быть представлены в виде: совокупности чисел, характеризующих те или иные
- 3. Группировка, табулирование и представление данных До начала анализа данные необходимо сгруппировать, упорядочить по одному признаку. Когда
- 4. Графическое представление данных Круговая диаграмма Гистограмма
- 5. Графики связи двух и более переменных Динамика набора студентов НШФ ЮФУ Корреляция роста численности и влияния
- 6. Группировка В примере с двумя вариантами значений переменной (пол: либо мужской, либо женский) производить вычисления и
- 7. Статистики Наибольшее значение имеют две группы статистик: меры центральной тенденции и меры изменчивости (разброса). Меры центральной
- 8. Меры центральной тенденции 1. Мода (Мо) - значение наблюдений, которое встречается наиболее часто. Например, группа респондентов
- 9. Меры изменчивости, разброса 1. Размах - описывает диапазон изменчивости значений. Так, в примере с возрастом размах
- 10. Практическое задание Рассчитать статистики для данных о возрасте: 20,20,21,22,22,23,25,26,27,28,28,29,30,32,33,34,34,35,35,35,36,37,38,39,40,40,40,41,42,43,44,44,45,47,48,49: Мода Медиана Среднее арифметическое Отклонение от среднего
- 11. Проверка результатов 20,20,21,22,22,23,25,26,27,28,28,29,30,32,33,34,34,35,35,35,36,37,38,39,40,40,40,41,42,43,44,44,45,47,48,49: Мода – 35 и 40 Медиана - 35 Среднее арифметическое – 33,86 (39)
- 12. Рассчитать статистики, в том числе дисперсию и стандартное отклонение За 2011 год Ира посетила драматический театр
- 13. Анализ связи между двумя переменными При всей важности одномерного анализа в исследованиях основное внимание обычно уделяется
- 15. Скачать презентацию

Виды анализа данных
Эмпирические данные могут быть представлены в виде:
совокупности чисел, характеризующих
Виды анализа данных
Эмпирические данные могут быть представлены в виде:
совокупности чисел, характеризующих

Группировка, табулирование и представление данных
До начала анализа данные необходимо сгруппировать, упорядочить
Группировка, табулирование и представление данных
До начала анализа данные необходимо сгруппировать, упорядочить
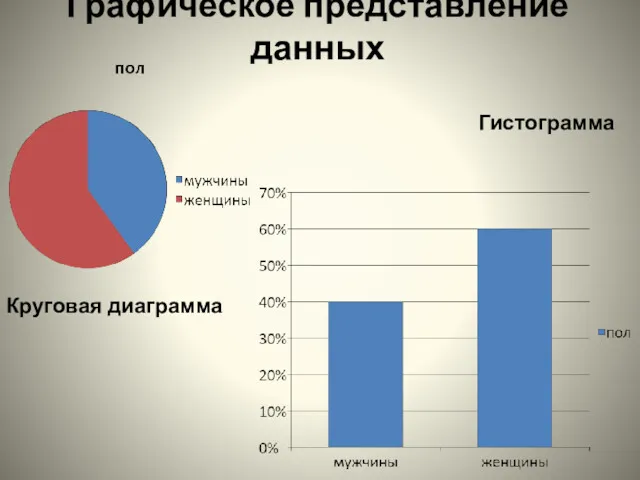
Графическое представление данных
Круговая диаграмма
Гистограмма
Графическое представление данных
Круговая диаграмма
Гистограмма
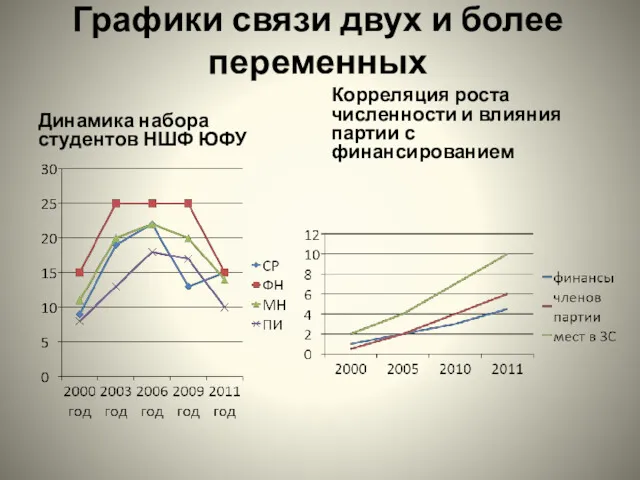
Графики связи двух и более переменных
Динамика набора студентов НШФ ЮФУ
Корреляция роста
Графики связи двух и более переменных
Динамика набора студентов НШФ ЮФУ
Корреляция роста

Группировка
В примере с двумя вариантами значений переменной (пол: либо мужской, либо
Группировка
В примере с двумя вариантами значений переменной (пол: либо мужской, либо

Статистики
Наибольшее значение имеют две группы статистик: меры центральной тенденции и
Статистики Наибольшее значение имеют две группы статистик: меры центральной тенденции и

Меры центральной тенденции
1. Мода (Мо) - значение наблюдений, которое встречается наиболее
Меры центральной тенденции
1. Мода (Мо) - значение наблюдений, которое встречается наиболее

Меры изменчивости, разброса
1. Размах - описывает диапазон изменчивости значений. Так, в
Меры изменчивости, разброса
1. Размах - описывает диапазон изменчивости значений. Так, в

Практическое задание
Рассчитать статистики для данных о возрасте:
20,20,21,22,22,23,25,26,27,28,28,29,30,32,33,34,34,35,35,35,36,37,38,39,40,40,40,41,42,43,44,44,45,47,48,49:
Мода
Медиана
Среднее арифметическое
Отклонение от среднего
Практическое задание
Рассчитать статистики для данных о возрасте:
20,20,21,22,22,23,25,26,27,28,28,29,30,32,33,34,34,35,35,35,36,37,38,39,40,40,40,41,42,43,44,44,45,47,48,49:
Мода
Медиана
Среднее арифметическое
Отклонение от среднего

Проверка результатов
20,20,21,22,22,23,25,26,27,28,28,29,30,32,33,34,34,35,35,35,36,37,38,39,40,40,40,41,42,43,44,44,45,47,48,49:
Мода – 35 и 40
Медиана - 35
Среднее арифметическое
Проверка результатов
20,20,21,22,22,23,25,26,27,28,28,29,30,32,33,34,34,35,35,35,36,37,38,39,40,40,40,41,42,43,44,44,45,47,48,49:
Мода – 35 и 40
Медиана - 35
Среднее арифметическое

Рассчитать статистики, в том числе дисперсию и стандартное отклонение
За 2011 год
Рассчитать статистики, в том числе дисперсию и стандартное отклонение
За 2011 год

Анализ связи между двумя переменными
При всей важности одномерного анализа в исследованиях
Анализ связи между двумя переменными
При всей важности одномерного анализа в исследованиях
 Прямоугольная система координат на плоскости
Прямоугольная система координат на плоскости Случаи сложения вида +6
Случаи сложения вида +6 Показательная функция
Показательная функция Подготовка к ЕГЭ по геометрии
Подготовка к ЕГЭ по геометрии Окружность и круг
Окружность и круг презентация к уроку по математике во 2 классе. Тема: Уравнение. Решение уравнений методом подбора
презентация к уроку по математике во 2 классе. Тема: Уравнение. Решение уравнений методом подбора Как писать цифры
Как писать цифры Презентация по математике Секунда. УМК Перспектива, 4 класс
Презентация по математике Секунда. УМК Перспектива, 4 класс Решение уравнений и координатный луч
Решение уравнений и координатный луч Геометрические головоломки
Геометрические головоломки Построение сечений. (10 класс)
Построение сечений. (10 класс) Презентация к уроку в 3 классе УМК Начальная школа 21 века
Презентация к уроку в 3 классе УМК Начальная школа 21 века Сумма углов треугольника
Сумма углов треугольника Определение вероятности
Определение вероятности Алгебраические уравнения. Системы нелинейных уравнений
Алгебраические уравнения. Системы нелинейных уравнений Тайны чисел. Творческая работа
Тайны чисел. Творческая работа Тела вращения
Тела вращения Задачи в стихах
Задачи в стихах Поможем Зайчику
Поможем Зайчику Связь между суммой и слагаемыми
Связь между суммой и слагаемыми Урок математики во 2 кл по теме Сложение и вычитание двузначных чисел без перехода через десяток.
Урок математики во 2 кл по теме Сложение и вычитание двузначных чисел без перехода через десяток. Обыкновенные дроби
Обыкновенные дроби Обобщающий урок по теме параллелограмм 8 класс
Обобщающий урок по теме параллелограмм 8 класс Многогранники. Призма
Многогранники. Призма Сумма углов треугольника
Сумма углов треугольника Призма
Призма Логарифмик тигезләмәләр
Логарифмик тигезләмәләр Методы описания детерминированных и случайных процессов в информационных системах (тема № 4)
Методы описания детерминированных и случайных процессов в информационных системах (тема № 4)