- Анализ одномерных распределений

Содержание
- 2. Построение частотных распределений Анализ частотных распределений результатов количественного социологического исследования — это первый шаг при обработке
- 3. Методы одномерного описательного анализа построение частотных распределений; графическое представление поведения анализируемой переменной получение статистических характеристик распределения
- 4. Частотное распределение Частотное распределение – это упорядоченный подсчет количества признаков по каждому значению какой-либо переменной
- 5. Валидные проценты
- 6. Графическое представление поведения анализируемой переменной
- 7. Меры центральной тенденции и меры разброса Меры центральной тенденции – статистики, описывающие, где находятся наиболее типичные
- 8. Среднее арифметическое и дисперсия статистические расчеты должны соответствовать уровню измерений данных
- 9. Измерения для номинальных переменных Мода – это наиболее часто встречающееся значение признака в серии зарегистрированных наблюдений
- 10. Упражнение: определите моду и коэффициент вариации
- 11. Измерения для порядковых переменных Медиана - это такое значение признака, которое разделяет ранжированный ряд распределения на
- 12. Упражнение: определите медиану и межквартильный размах
- 14. Измерение для интервальных шкал Среднее арифметическое - величина, полученная путем сложения всех членов числового ряда и
- 15. Измерение для интервальных шкал
- 16. Упражнение: определите среднее арифметическое и стандартное отклонение
- 18. Ограничения критерия Объем выборки должен быть достаточно большим: n>30 Теоретическая частота для каждой ячейки таблицы не
- 19. Статистические гипотезы Статистические гипотезы делятся на нулевые и альтернативные Нулевая гипотеза - это гипотеза об отсутствии
- 20. Проверяемые статистические гипотезы H0 – эмпирическое распределение признака не отличается от теоретического равномерного распределения H1 –
- 23. Уровни статистической значимости Уровень значимости - это вероятность того, что мы сочли различия существенными, а они
- 24. Правило отклонения H0 и принятия H1 Если эмпирическое значение критерия равняется критическому значению, соответствующему р >
- 26. Скачать презентацию

Построение частотных распределений
Анализ частотных распределений результатов количественного социологического исследования — это
Построение частотных распределений
Анализ частотных распределений результатов количественного социологического исследования — это

Методы одномерного описательного анализа
построение частотных распределений;
графическое представление поведения анализируемой переменной
получение статистических
Методы одномерного описательного анализа
построение частотных распределений;
графическое представление поведения анализируемой переменной
получение статистических
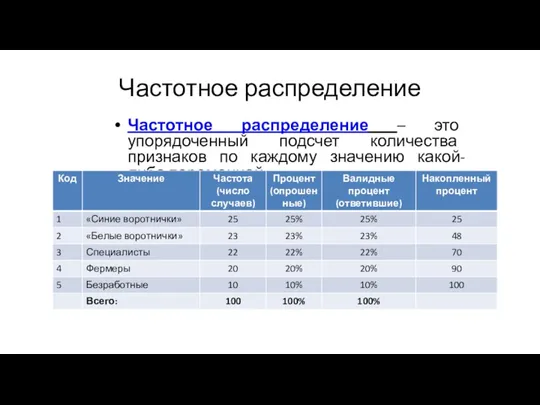
Частотное распределение
Частотное распределение – это упорядоченный подсчет количества признаков по каждому
Частотное распределение
Частотное распределение – это упорядоченный подсчет количества признаков по каждому
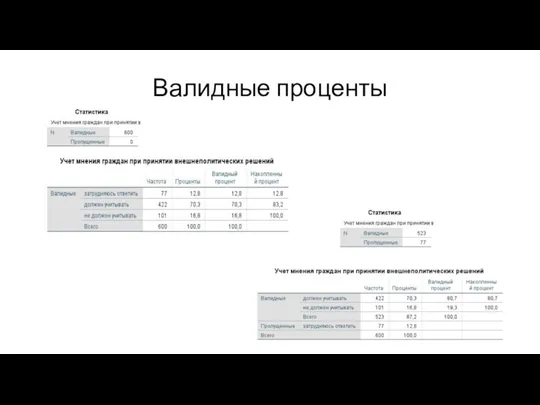
Валидные проценты
Валидные проценты
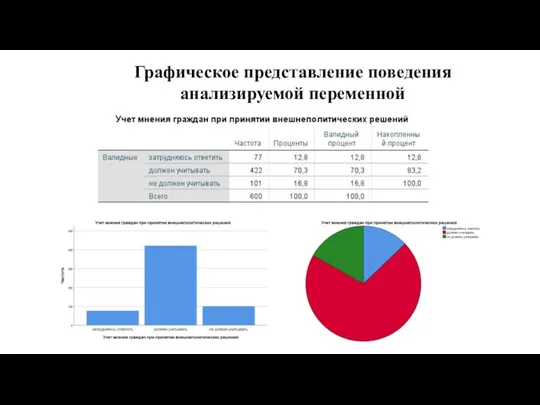
Графическое представление поведения анализируемой переменной
Графическое представление поведения анализируемой переменной

Меры центральной тенденции и меры разброса
Меры центральной тенденции – статистики, описывающие,
Меры центральной тенденции и меры разброса
Меры центральной тенденции – статистики, описывающие,

Среднее арифметическое и дисперсия
статистические расчеты должны соответствовать уровню измерений данных
Среднее арифметическое и дисперсия
статистические расчеты должны соответствовать уровню измерений данных

Измерения для номинальных переменных
Мода – это наиболее часто встречающееся значение признака
Измерения для номинальных переменных
Мода – это наиболее часто встречающееся значение признака
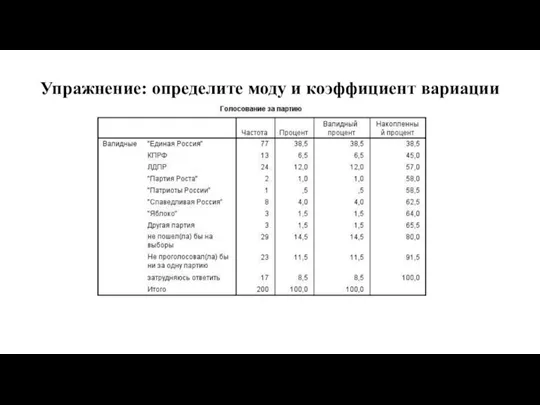
Упражнение: определите моду и коэффициент вариации
Упражнение: определите моду и коэффициент вариации

Измерения для порядковых переменных
Медиана - это такое значение признака, которое разделяет
Измерения для порядковых переменных
Медиана - это такое значение признака, которое разделяет

Упражнение: определите медиану и межквартильный размах
Упражнение: определите медиану и межквартильный размах
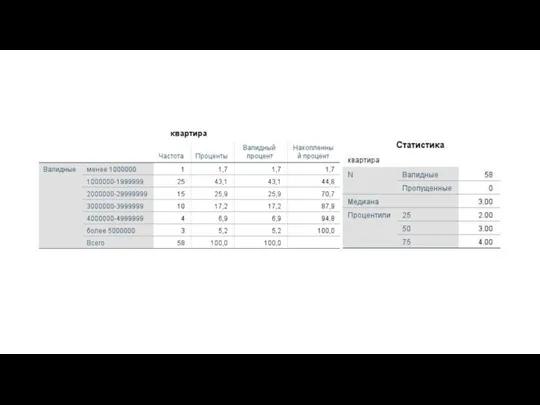

Измерение для интервальных шкал
Среднее арифметическое - величина, полученная путем сложения всех
Измерение для интервальных шкал
Среднее арифметическое - величина, полученная путем сложения всех

Измерение для интервальных шкал
Измерение для интервальных шкал

Упражнение: определите среднее арифметическое и стандартное отклонение
Упражнение: определите среднее арифметическое и стандартное отклонение


Ограничения критерия
Объем выборки должен быть достаточно большим: n>30
Теоретическая частота для каждой
Ограничения критерия
Объем выборки должен быть достаточно большим: n>30
Теоретическая частота для каждой

Статистические гипотезы
Статистические гипотезы делятся на нулевые и альтернативные
Нулевая гипотеза - это
Статистические гипотезы
Статистические гипотезы делятся на нулевые и альтернативные
Нулевая гипотеза - это

Проверяемые статистические гипотезы
H0 – эмпирическое распределение признака не отличается от теоретического
Проверяемые статистические гипотезы
H0 – эмпирическое распределение признака не отличается от теоретического

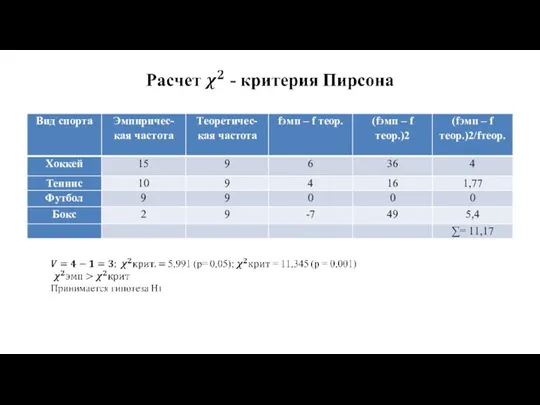

Уровни статистической значимости
Уровень значимости - это вероятность того, что мы сочли
Уровни статистической значимости
Уровень значимости - это вероятность того, что мы сочли

Правило отклонения H0 и принятия H1
Если эмпирическое значение критерия равняется критическому
Правило отклонения H0 и принятия H1
Если эмпирическое значение критерия равняется критическому
 20181112_logarifmy
20181112_logarifmy Презентация по математике
Презентация по математике Основные понятия и аксиомы стереометрии
Основные понятия и аксиомы стереометрии Функции y=tgx, y=ctgx, их свойства и графики
Функции y=tgx, y=ctgx, их свойства и графики Степень числа
Степень числа Доказательства теоремы Пифагора
Доказательства теоремы Пифагора Развитие геометрии
Развитие геометрии Обратная функция
Обратная функция Всемирный потоп. Возможен ли он с математической точки зрения
Всемирный потоп. Возможен ли он с математической точки зрения Формулы сокращенного умножения (7 класс)
Формулы сокращенного умножения (7 класс) D нуқтадан ABC текислигигача бўлган энг қисқа масофани аниқлаш
D нуқтадан ABC текислигигача бўлган энг қисқа масофани аниқлаш Криволінійні інтеграли
Криволінійні інтеграли Сложение и вычитание в пределах 10
Сложение и вычитание в пределах 10 Математическое сказочное путешествие
Математическое сказочное путешествие Занимательная математика
Занимательная математика Многоугольники. Внешняя область
Многоугольники. Внешняя область Мода и медиана
Мода и медиана Решение задач с помощью квадратных уравнений
Решение задач с помощью квадратных уравнений Регрессионный анализ. Основы
Регрессионный анализ. Основы Интегрированные уроки в начальной школе
Интегрированные уроки в начальной школе Умножение десятичных дробей
Умножение десятичных дробей Равнобедренный треугольник
Равнобедренный треугольник Неопределённый интеграл, его свойства . Непосредственное интегрирование. Метод замены переменной в неопределенном интеграле
Неопределённый интеграл, его свойства . Непосредственное интегрирование. Метод замены переменной в неопределенном интеграле Уравнения и неравенства, содержащие переменную под знаком модуля
Уравнения и неравенства, содержащие переменную под знаком модуля Презентация Учим таблицу умножения...
Презентация Учим таблицу умножения... презентация Математика (материалы для подготовки будущих первоклассников к школе)
презентация Математика (материалы для подготовки будущих первоклассников к школе) Метод проектов на уроках математики
Метод проектов на уроках математики Масштаб
Масштаб