- Кластеризация

Содержание
- 2. Кластеризация – инструмент исследования данных: обнаружение классов образцов (например, новых подтипов болезни); проверка ожидаемого результата (например,
- 3. Разбиение объектов на кластеры, т.е. группы схожих элементов, причем объекты разных кластеров существенно отличаются; Кластеризация пациентов
- 4. ВЫЯВЛЕНИЕ АНОМАЛЬНЫХ ЗНАЧЕНИЙ Атрибут Возраст представлен следующими двадцатью значениями: {3, 56,23, 39, 156, 52, 41, 22,
- 5. В основе метода лежит оценка мер расстояния между всеми наблюдениями в n-мерном пространстве данных Значение Si
- 6. S3 и S5 - кандидаты в аномальные, для них значение p = 5 превышает заданный порог
- 7. В Data Mining распространенной мерой оценки близости между объектами является метрика или способ задания расстояния. Мера
- 8. Метрики в кластерном анализе Меры, основанные на расстоянии: Евклидово (Euclidian), Манхэттена и Канберра (Manhattan & Canberra),
- 9. Метрики в кластерном анализе
- 10. Метрики в кластерном анализе Расстояние Хэмминга (Hamming distance) — число позиций, в которых различаются соответствующие символы
- 11. Метрики в кластерном анализе Множество точек, равноудаленных от некоторого центра при использовании евклидовой метрики будет образовывать
- 12. Алгоритмы в кластерном анализе Наибольшее распространение в популярных статистических пакетах получили две группы алгоритмов кластерного анализа:
- 13. Дендрограмма описывает близость отдельных точек и кластеров друг к другу, представляет в графическом виде последовательность объединения
- 14. Алгоритмы в кластерном анализе Одним из наиболее простых и эффективных алгоритмов кластеризации является алгоритм K-means Он
- 15. k-means Центроиды становятся новыми центрами кластеров для следующей итерации алгоритма. Шаги 3 и 4 повторяются до
- 16. Пример работы алгоритма k-средних (k=2)
- 17. Пример Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество k=2. Шаг 2. Случайным
- 18. Пример
- 19. Вывод. При помощи метода к-среднего реализуется процедура построения усредненных профилей каждого класса, что дает возможность проводить
- 20. Пример
- 21. Пример
- 22. Высшая школа экономики, Москва, 2013 Результаты фото 24 k-means
- 23. ПЛАТФОРМА DEDUCTOR
- 24. ПЛАТФОРМА DEDUCTOR
- 25. ПЛАТФОРМА DEDUCTOR
- 26. ПЛАТФОРМА DEDUCTOR
- 27. ПЛАТФОРМА DEDUCTOR
- 28. ПЛАТФОРМА DEDUCTOR
- 29. ПЛАТФОРМА DEDUCTOR
- 30. ПЛАТФОРМА DEDUCTOR
- 31. ПЛАТФОРМА DEDUCTOR
- 32. Сети Кохонена Термин «сети Кохонена» (англ.: Kohonen network, KCN) был введен в 1982 финским ученым Тойв
- 34. Скачать презентацию

Кластеризация – инструмент исследования данных:
обнаружение классов образцов (например, новых подтипов болезни);
Кластеризация – инструмент исследования данных: обнаружение классов образцов (например, новых подтипов болезни);

Разбиение объектов на кластеры, т.е. группы схожих элементов, причем объекты разных
Разбиение объектов на кластеры, т.е. группы схожих элементов, причем объекты разных

ВЫЯВЛЕНИЕ АНОМАЛЬНЫХ ЗНАЧЕНИЙ
Атрибут Возраст представлен следующими двадцатью значениями:
{3, 56,23,
ВЫЯВЛЕНИЕ АНОМАЛЬНЫХ ЗНАЧЕНИЙ
Атрибут Возраст представлен следующими двадцатью значениями:
{3, 56,23,

В основе метода лежит оценка мер расстояния между всеми наблюдениями в
В основе метода лежит оценка мер расстояния между всеми наблюдениями в

S3 и S5 - кандидаты в аномальные, для них значение p
S3 и S5 - кандидаты в аномальные, для них значение p

В Data Mining распространенной мерой оценки близости между объектами является метрика
В Data Mining распространенной мерой оценки близости между объектами является метрика

Метрики в кластерном анализе
Меры, основанные на расстоянии: Евклидово (Euclidian), Манхэттена и
Метрики в кластерном анализе
Меры, основанные на расстоянии: Евклидово (Euclidian), Манхэттена и

Метрики в кластерном анализе
Метрики в кластерном анализе

Метрики в кластерном анализе
Расстояние Хэмминга (Hamming distance) — число позиций, в
Метрики в кластерном анализе
Расстояние Хэмминга (Hamming distance) — число позиций, в

Метрики в кластерном анализе
Множество точек, равноудаленных от некоторого центра при использовании
Метрики в кластерном анализе
Множество точек, равноудаленных от некоторого центра при использовании

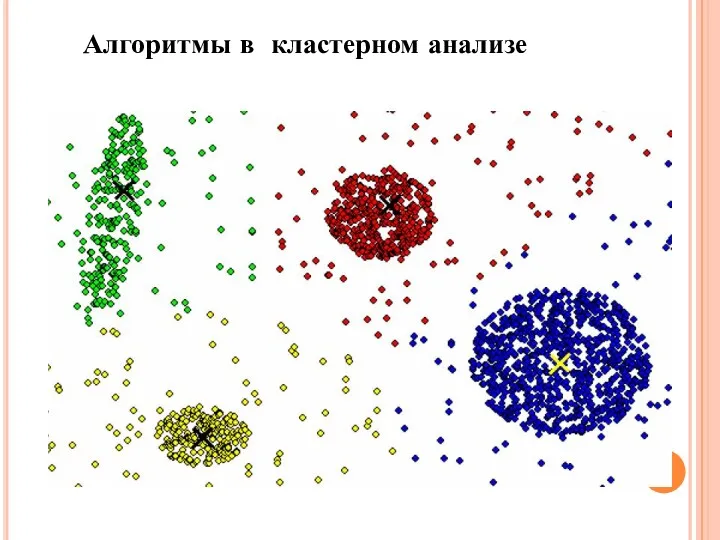
Алгоритмы в кластерном анализе
Наибольшее распространение в популярных статистических пакетах получили две
Алгоритмы в кластерном анализе
Наибольшее распространение в популярных статистических пакетах получили две
Дендрограмма описывает близость отдельных точек и кластеров друг к другу, представляет
Дендрограмма описывает близость отдельных точек и кластеров друг к другу, представляет

Алгоритмы в кластерном анализе
Одним из наиболее простых и эффективных алгоритмов кластеризации
Алгоритмы в кластерном анализе
Одним из наиболее простых и эффективных алгоритмов кластеризации

k-means
Центроиды становятся новыми центрами кластеров для следующей итерации алгоритма.
Шаги 3
k-means
Центроиды становятся новыми центрами кластеров для следующей итерации алгоритма.
Шаги 3
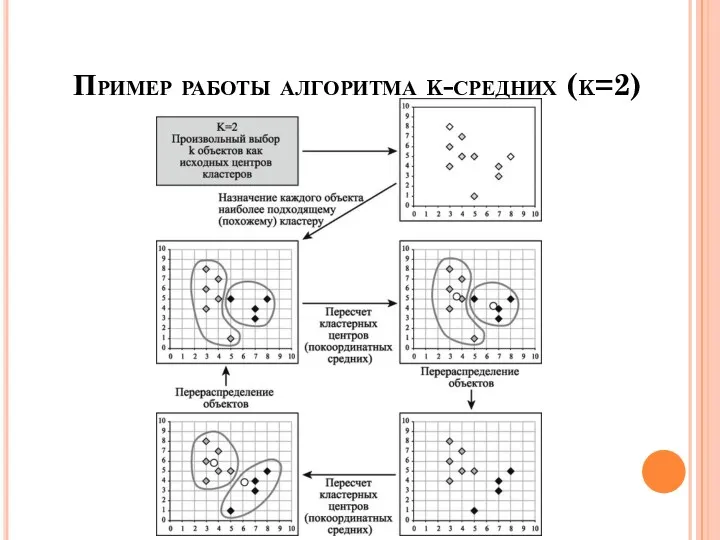
Пример работы алгоритма k-средних (k=2)
Пример работы алгоритма k-средних (k=2)
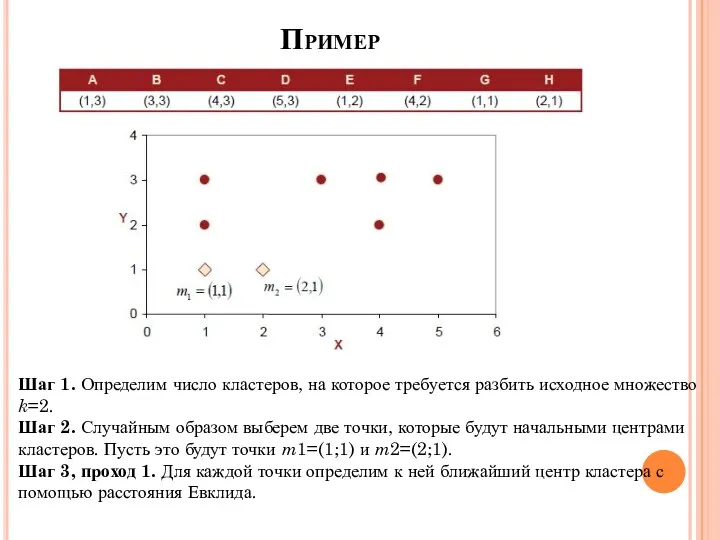
Пример
Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество
Пример
Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество

Пример
Пример

Вывод.
При помощи метода к-среднего реализуется процедура построения усредненных профилей каждого класса,
Вывод.
При помощи метода к-среднего реализуется процедура построения усредненных профилей каждого класса,

Пример
Пример

Пример
Пример
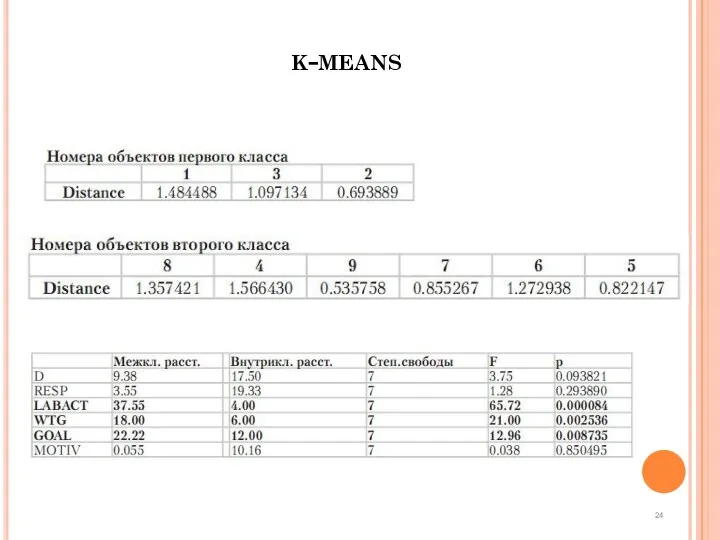
Высшая школа экономики, Москва, 2013
Результаты
фото
24
k-means
Высшая школа экономики, Москва, 2013
Результаты
фото
24
k-means
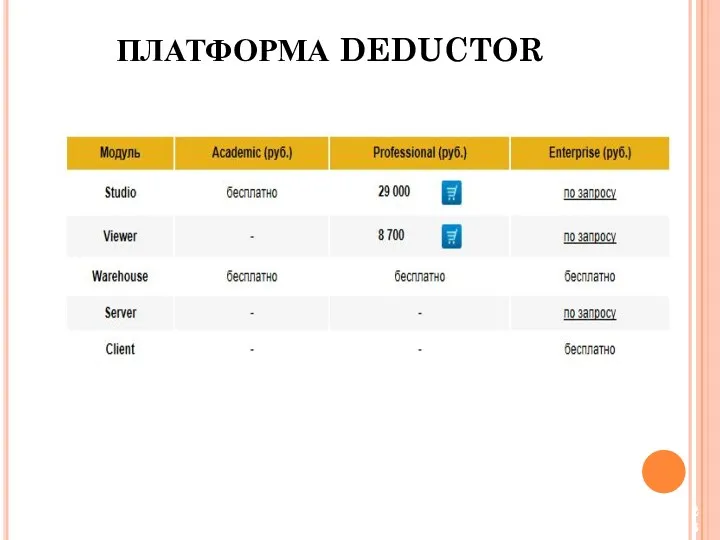
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
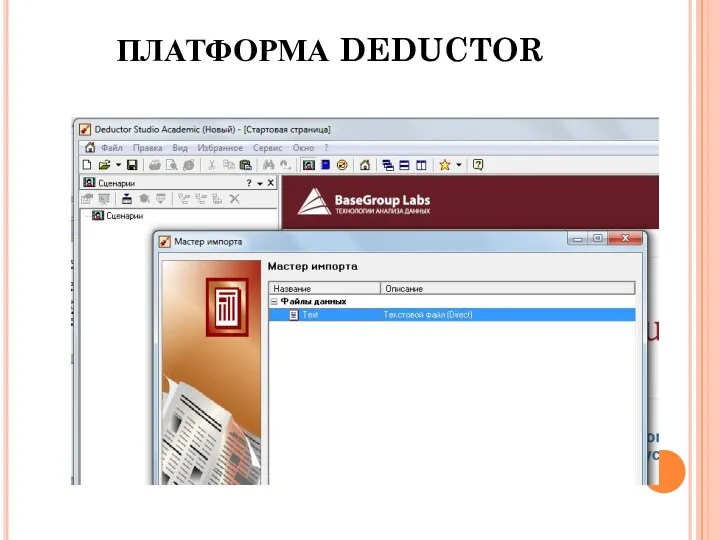
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
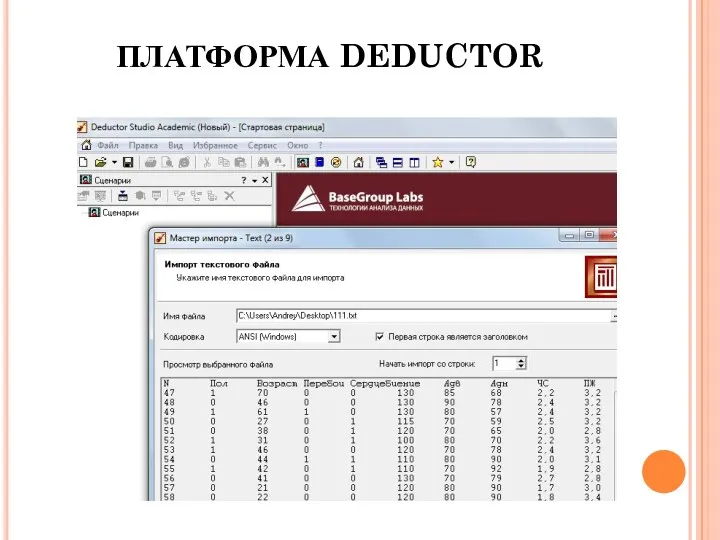
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
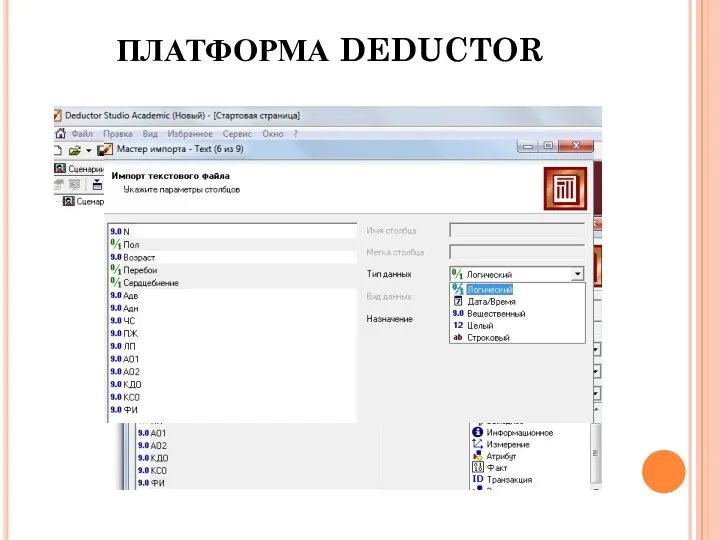
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
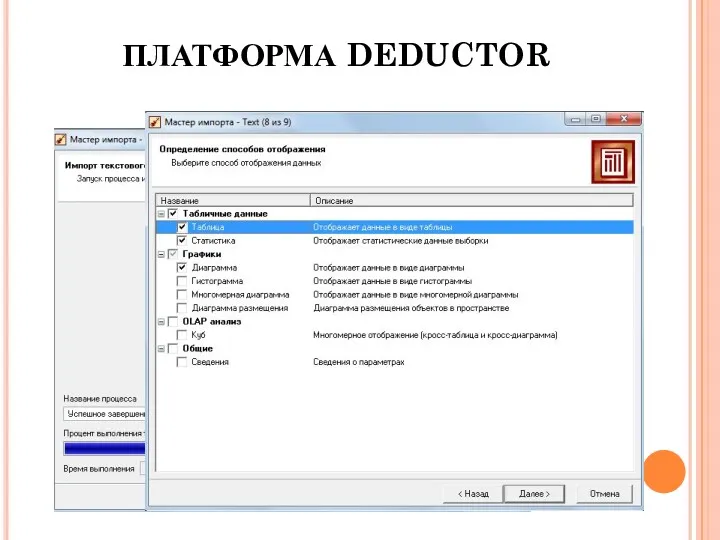
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
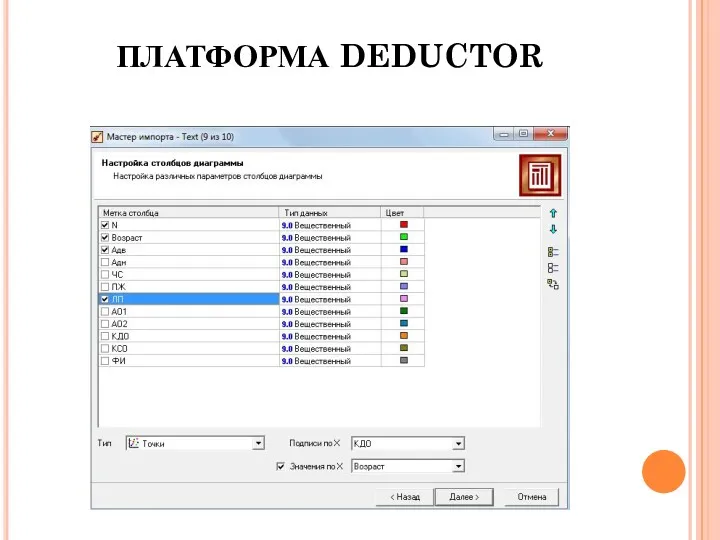
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
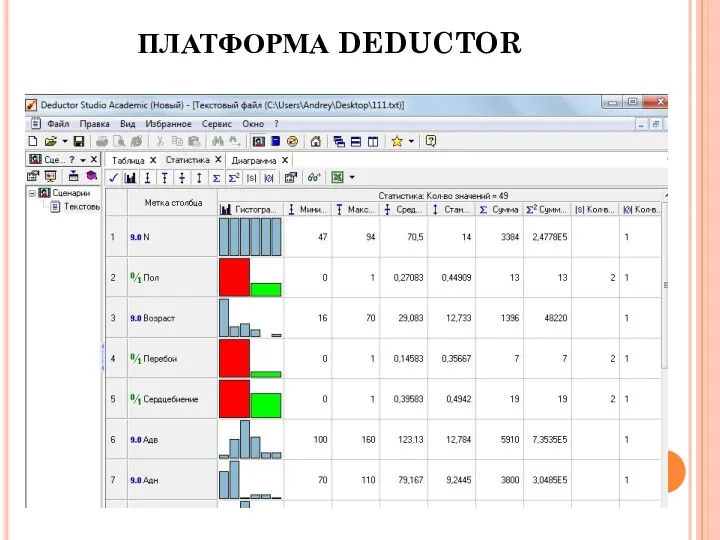
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
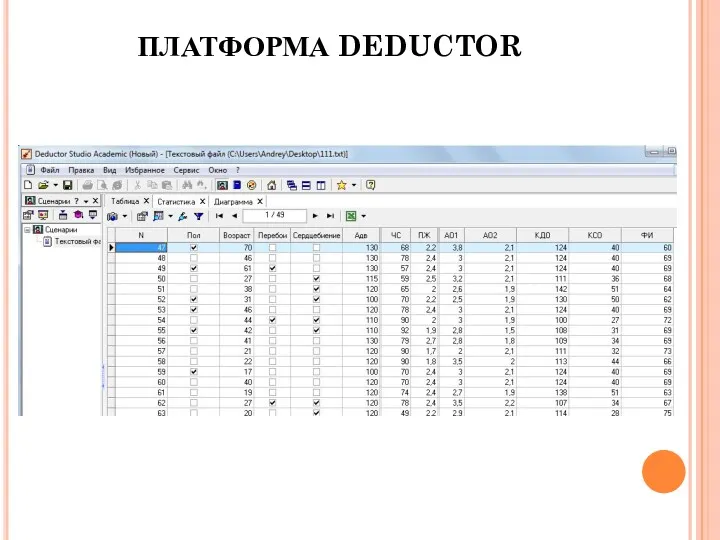
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR
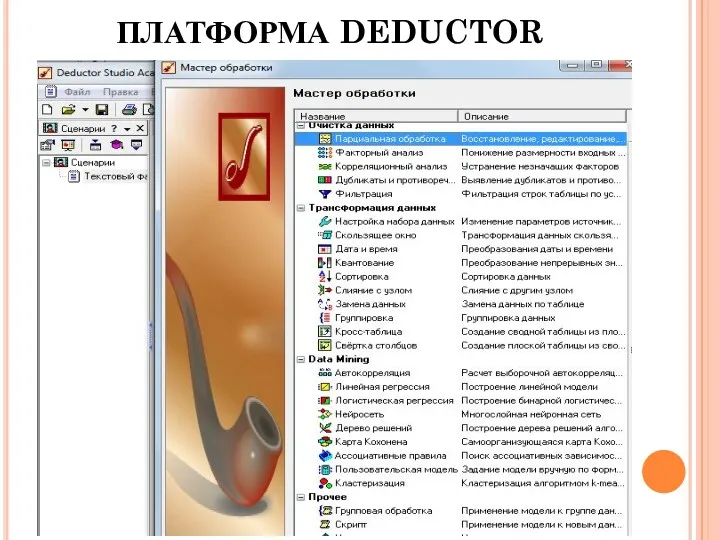
ПЛАТФОРМА DEDUCTOR
ПЛАТФОРМА DEDUCTOR

Сети Кохонена
Термин «сети Кохонена» (англ.: Kohonen network, KCN) был введен
Сети Кохонена
Термин «сети Кохонена» (англ.: Kohonen network, KCN) был введен
 Математика на железной дороге
Математика на железной дороге Асимптоты функции
Асимптоты функции Дидактическая игра по ФЭМП Помоги Буратино достать ключик (подготовительная группа).
Дидактическая игра по ФЭМП Помоги Буратино достать ключик (подготовительная группа). Презентация. Передача изображений
Презентация. Передача изображений Теория информационных процессов и систем. Лекция 1. Информационный процесс
Теория информационных процессов и систем. Лекция 1. Информационный процесс Противоположные числа
Противоположные числа Обучающая презентация Части суток
Обучающая презентация Части суток 2 продолжение презентации
2 продолжение презентации Приёмы умножения и деления на 10
Приёмы умножения и деления на 10 Из истории числительных. Мозговой штурм по русскому языку и математике
Из истории числительных. Мозговой штурм по русскому языку и математике Игры Воскобовича
Игры Воскобовича Неопределенный интеграл
Неопределенный интеграл Формирование представлений о времени детей старшего дошкольного возраста средствами дидактических игр и занимательных упражнений
Формирование представлений о времени детей старшего дошкольного возраста средствами дидактических игр и занимательных упражнений Понятие предела числовой последовательности. Предел функции в точке и на бесконечности. Теоремы о пределах функции
Понятие предела числовой последовательности. Предел функции в точке и на бесконечности. Теоремы о пределах функции Состав числа до 10
Состав числа до 10 Усеченная пирамида
Усеченная пирамида Відсотки. Математика. 6 клас
Відсотки. Математика. 6 клас Конспекты уроков по математике 1 класс ПНШ Диск
Конспекты уроков по математике 1 класс ПНШ Диск Презентация к уроку Прибавление чисел 7, 8. 9
Презентация к уроку Прибавление чисел 7, 8. 9 Осевая и центральная симметрия
Осевая и центральная симметрия Зеркальное отражение предметов
Зеркальное отражение предметов Прямоугольная система координат в пространстве
Прямоугольная система координат в пространстве Хронология. Счет времени
Хронология. Счет времени Площадь кругового сектора.площадь кругового сегмента. Геометрия. 9 класс
Площадь кругового сектора.площадь кругового сегмента. Геометрия. 9 класс Виды треугольников
Виды треугольников Симплекс-метод
Симплекс-метод Быстрый Поиск. Деревья поиска
Быстрый Поиск. Деревья поиска Тіла обертання. Циліндр
Тіла обертання. Циліндр