- Научная школа по ЭММ

Содержание
- 2. Введение
- 3. Существует три основных класса эконометрических моделей: Модели временных рядов Регрессионные модели с одним уравнением Системы эконометрических
- 4. Регрессионные модели с одним уравнением, в которых зависимая переменная может быть представлена в виде функции факторных
- 5. Для решения эконометрической задачи необходимо последовательно выполнить несколько этапов экономико-математического моделирования Постановочный этап - определяются конечные
- 6. Этап параметризации – происходит выбор общего вида модели, а также определяется состав и формы формирующих ее
- 7. В рамках регрессионного анализа необходимо решить 4 задачи: Определение числовых значений параметров модели; Определение статистической достоверности
- 8. Математическое ожидание: это среднее ожидаемое значение, принимаемое случайной величиной в больших сериях испытаний. оно используется в
- 9. Дисперсия: Используется для оценки разброса значений случайной величины вокруг ее среднего значения (математического ожидания). Это показатель
- 10. Стандартное (среднеквадратичное) отклонение: Как и дисперсия используется в качестве меры абсолютного разброса случайной величины возле ее
- 12. Чтобы совокупность случайных величин можно было использовать для регрессионного анализа и строить точные прогнозы, необходимо, чтобы
- 13. График плотности вероятности нормального распределения имеет вид колокола: Максимум этой функции, а также центр симметрии находится
- 14. Такой график может быть получен только при бесконечно большом количестве измерений (при увеличении количества измерений приближается
- 15. Построение гистограммы с помощью программы Excel. Идем во вкладку «Анализ данных» и выбираем «Гистограмма». Выбираем входной
- 16. Теперь нужно сделать так, чтобы по вертикальной оси отображалась не абсолютная частота, а относительная. Под появившейся
- 17. Корреляция и ковариация Важнейшая задача эконометрики – исследование существующих связей между социально-экономическими явлениями и процессами. В
- 18. Принято различать следующие виды корреляции: Парная — связь между двумя признаками (результативным и факторным, или двумя
- 19. Ковариация выражает степень статистической зависимости между двумя множествами данных, измеряется в тех же единицах что и
- 20. Оценка связи по ковариации: Положительная ковариация наблюдается когда большим значениям случайной величины Х соответствуют большие значения
- 21. Коэффициент корреляции принимает значения от -1 до +1 : Если R Если R>0, то связь между
- 22. Парные регрессионные модели
- 23. Модели парной регрессии В регрессионной модели все переменные делятся на: зависимые, эндогенные (y) и независимые, экзогенные
- 24. Существует несколько причин появления в модели случайной составляющей: Не включение объясняющих переменных. Соотношение между yt и
- 25. Неправильная функциональная спецификация. соотношение между yt и хt математически может быть определено неверно. истинная зависимость может
- 26. Предположим, что у нас имеется n наблюдений для хt и yt, Имеющиеся переменные имеют линейную динамику,
- 27. Недостатки такого подхода: Построение линии регрессии без точных расчетов является достаточно субъективным. Более того, если переменная
- 28. Второй этап – Необходимо выбрать какой-то критерий подбора, который будет одновременно учитывать величину всех остатков. Один
- 29. Третий этап – Нахождение параметров уравнения регрессии методом наименьших квадратов: Минимизируется сумма квадратов отклонений фактических значений
- 30. Например:
- 31. Предположим наличие линейной зависимости между рассматриваемыми переменными. Отсюда получается: a0 = 211,296 a1 = 7,305 Y
- 32. Другой способ нахождения коэффициентов регрессии:
- 33. Экономико-математическая интерпретация построенной регрессионной модели После записи уравнения регрессии необходимо выполнить экономико-математическую интерпретацию полученной модели: y
- 34. Математически параметры а и b можно рассчитать для любого массива статистической информации, однако необходимо проверить, можно
- 35. Алгоритм проверки статистической гипотезы о достоверности параметра b: Выдвигается нулевая гипотеза Н0 (b): b = 0,
- 36. По таблице распределения Стьюдента определяется критическое значение t-статистики для оцениваемого коэффициента регрессии. t крит = (n-1;
- 37. В большинстве случаев определяется не только величина статистики Стьюдента, но и вероятность выполнения нулевой гипотезы. Вероятность
- 38. Например: По 25 наблюдениям получено уравнение регрессии: Необходимо проверить значимость коэффициента при переменной zi на уровне
- 39. Мы предположили, что показатели хt и yt связаны между собой линейной связью, нашли параметры а и
- 40. 2. Необходимо установить уровень подгонки модели к исходным данным (рассчитать коэффициент детерминации) Исходя из этого квадрат
- 41. Доля дисперсии, объясненная регрессией (RSS) – Коэффициент детерминации показывает: какая доля вариации зависимой переменной может быть
- 42. Для устранения эффекта, связанного с ростом коэффициента детерминации при увеличении количества факторов используется нормированный коэффициент детерминации.
- 43. 3. Необходимо проанализировать выбросы в модели Статистический выброс – это аномальное наблюдение, для которого реальное значение
- 44. Величина, с помощью которой проверяется нулевая гипотеза для коэффициента детерминации, называется статистикой Фишера. Для ее расчета
- 45. F крит = F(k-1; n-k)
- 46. По распределению Фишера определяют вероятность нулевой гипотезы для коэффициента детерминации: Сначала выдвигается нуль-гипотеза, согласно которой R2=0,
- 47. Например: По 25 наблюдениям получено уравнение: Необходимо проверить гипотезу о значимости регрессии на уровне значимости α=0.05.
- 48. Множественные регрессионные модели
- 49. Модели множественной линейной регрессии строятся когда величина исследуемого показателя складывается под влиянием не одного, а многих
- 50. В таких моделях зависимая переменная у рассматривается как функция не одной, а нескольких независимых переменных хt:
- 51. Оценка качества модели: Связь между изучаемыми факторами и зависимой переменной должна быть тесной: коэффициент корреляции (Множественный
- 52. Нелинейные регрессионные модели
- 53. Модели нелинейной регрессии Соотношения, существующие между социально-экономическими показателями и процессами не всегда описываются линейными функциями, Зачастую
- 54. Этап линеаризации – преобразования переменных к линейному виду. Этап линеаризации – это переход от нелинейной связи
- 55. Связь кубическая: Связь степенная: y = a * xb (b≥2 и целое) y = a +
- 56. Связь гиперболическая: y = a + b / x (x≠0, b≠0) Связь экспоненциальная: y = ebx
- 57. Связь логарифмическая (обратная экспоненциальной): у = а + b· ln x Связь тригонометрическая с функцией синуса:
- 58. Функция Кобба-Дугласа характеризует связь между совокупным выпуском (доходом) и объемами используемых ресурсов. применяются для описания технологических
- 59. По результатам модели: увеличение затрат труда на 1% повлечет за собой рост национального дохода на b
- 60. При построении модели: в качестве Входного интервала Y выбираются значения из столбца ln Y, а в
- 61. Пример нелинейного моделирования Используем функцию LN (каждой ячейки) Проводим регрессионный анализ и получаем прогнозные значения для
- 62. Используем функцию EXP (каждой ячейки) Увеличение затрат на производство приводит к постоянному возрастанию отдачи от масштаба
- 63. Регрессионные модели с фиктивными переменными
- 64. Использование фиктивных переменных в регрессионном анализе До сих пор в качестве факторов мы рассматривали экономические переменные,
- 65. Например: Имеется бинарная модель: Пробег = 41,98 – 1,5 * Возраст + 1,11 * Пол Фиктивная
- 66. Например: Используем формулу: ЕСЛИ (ячейка = «средний»; 1; 0) ЕСЛИ (ячейка = «есть»; 1; 0) Стоимость
- 67. Использование фиктивных переменных в анализе сезонных колебаний Иногда заметное влияние на регрессионную зависимость оказывает сезонный характер
- 68. Переходим к оценке уравнения у = a + b1 d1 + b2 d2 + b3 d3
- 69. Таким образом, среднее значение результативного показателя в каждый из сезонов достигает значения: Для осеннего периода =
- 70. Например: Предполагается проведение исследований сезонных колебаний цены на акции компании «Лукойл». Выделяются четыре сезона: зима, весна,
- 73. Last price = 23,51 – 3,93 * зима – 5,92 * весна + 2,26 * лето.
- 74. Аналогично можно получить средние значения цены закрытия в другие сезоны: Last price (весна) = 23,51 –
- 75. Устранение трендовых компонент с помощью регрессионных моделей
- 76. Пример освобождения динамических рядов от сезонных колебаний В задаче необходимо: Исследовать зависимость производства товаров двух заводов.
- 77. Этап №2 - Исключение трендовой составляющей и нахождение реальной регрессионной зависимости временных рядов. Удаление трендовой составляющей
- 78. Этап №3 – Освобождение исходных данных от трендовой компоненты. Освобождение от трендовой компоненты необходимо осуществлять по
- 80. Этап №4 – Нахождение регрессионной зависимости по данным, освобожденным от влияния трендовой компоненты. Связь между переменными
- 81. Метод последовательных разностей Связь между переменными отсутствует: Δy = 0,88 + 0,227 * Δx R-квадрат =
- 82. Предпосылки МНК
- 83. Предпосылки метода наименьших квадратов Для того чтобы регрессионный анализ давал наилучшие результаты должны выполняться условия Гаусса-Маркова,
- 84. Предпосылки МНК Математическое ожидание случайной составляющей (остатков) в любом наблюдении должно быть равно нулю. Иногда случайная
- 85. Отсутствие автокорреляции остатков. Любые случайные отклонения ut и uk должны быть независимыми друг от друга. Здесь
- 86. Мультиколлинеарность
- 87. Мультиколлинеарность это сильная коррелированность двух или нескольких объясняющих переменных. в этом случае переменные меняются синхронно оказывается
- 88. Признаки мультиколлинеарности: незначительное изменение исходных данных приводит к существенному изменению коэффициентов регрессионной модели. коэффициенты имеют большие
- 89. Для измерения мультиколлинеарности можно использовать коэффициент множественной детерминации: При отсутствии мультиколлинеарности факторов коэффициент множественной детерминации рассчитывается
- 90. Для устранения мультиколлинеарности используется метод исключения переменных: высоко коррелированные объясняющие переменные поэтапно удаляются из регрессионной модели,
- 91. Процедура отбора удаляемых факторов включает следующие этапы: Проводится анализ рассчитанных значений коэффициентов парной корреляции между объясняющими
- 92. Прежде, чем вынести решение об исключении факторов, проводят дополнительное исследование с помощью статистики Фишера F. Рассчитывают
- 93. Например: Этап 1 – Проведение регрессионного анализа и исследование его результатов.
- 94. Этап 2 - Построение матрицы попарных корреляций и ее анализ Из построенной матрицы мы видим: наиболее
- 95. Этап 3 – Расчет меры мультиколлинеарности (М) где R2 – коэф. детерминации регрессионного уравнения, полученного на
- 96. Этап 5 – Расчет коэффициента Бета (β). где bk – коэффициент регрессии при k-м факторе, Dxk
- 97. Этап 7 – Удаление из модели переменной и повтор всех проведенных процедур для поиска качественной модели.
- 98. Автокорреляция остатков
- 99. Автокорреляция остатков Статистическая значимость коэффициентов регрессии и близкое к 1 значение коэффициента детерминации R2 не всегда
- 100. Например. Исследуется зависимость объема потребления С от численности населения Р в США в 1931-1990 гг. Корреляционное
- 101. Если использовать линейную регрессию для прогнозирования дальнейшей динамики потребления, то результат будет неудовлетворительным. В нашем примере
- 102. Автокорреляция – статистическая зависимость между ошибками различных наблюдений изучаемых показателей, упорядоченных во времени или в пространстве.
- 103. Основные причины появления автокорреляции: Ошибки спецификации: не учет в модели какой-нибудь важной объясняющей переменной неправильный выбор
- 104. Последствия автокорреляции: Оценки коэффициентов регрессии, оставаясь линейными и несмещенными, перестают быть эффективными, Дисперсии оценок являются смещенными,
- 105. Способы выявления наличия автокорреляции. Графический метод. Строится последовательно-временной график. По оси абсцисс откладывается время получения статистических
- 106. Метод рядов: Последовательно определяются знаки отклонений et , t = 1,2,...,Т. Ряд определяется как непрерывная последовательность
- 107. Например: Имеется временная последовательность (– – – – – ) (+ + + + + +
- 108. Метод Дарбина-Уотсона. Это наиболее известный критерий обнаружения автокорреляции первого порядка является важнейшая характеристика качества регрессионной модели.
- 109. Расчет интервала коэффициента DW: Если et = et-1, то r (et, et-1) = 1, тогда DW=0.
- 110. Какие значения DW можно считать статистически близкими к 2? Для ответа на этот вопрос разработаны специальные
- 111. Не обращаясь к таблице критических точек Дарбина-Уотсона, можно пользоваться «грубым» правилом и считать, что автокорреляция отсутствует,
- 112. При использовании критерия Дарбина-Уотсона необходимо учитывать следующие ограничения: Критерий DW применяется лишь для тех моделей, которые
- 113. Методы устранения автокорреляции. Так как автокорреляция чаще всего вызывается неправильной спецификацией модели, то можно скорректировать саму
- 114. Рассмотрим модель парной линейной регрессии: Тогда наблюдениям t и (t-1) соответствуют формулы: Пусть случайные отклонения подвержены
- 115. Два подхода к оценке параметра ρ: На основе статистики Дарбина-Уотсона. Статистика Дарбина-Уотсона тесно связана с коэффициентом
- 116. Метод Хилдрета-Лу. Рассмотрим зависимость показателя у от значений k регрессоров: В данном случае для оценивания системы
- 117. Суть процедуры Хилдрета-Лу достаточно проста: Из интервала от –1 до +1 возможного изменения коэффициента ρ берутся
- 118. Например: Этап 1 – По выведенным значениям остатков находится статистика Дарбина-Уотсона и тестируется гипотеза о наличии
- 120. DW = 261,815 / 238,554 = 1,099 Поскольку статистика Дарбина-Уотсона DW меньше 1,5 значит наблюдается положительная
- 121. 1й месяц: = 13,7–( - 0,9*17,1) = 29,09 = 99,6–( - 0,9*75,6) = 167,7
- 122. Этап 3 – Строится линейная регрессионная зависимость По выведенным результатам определяется величина остаточной дисперсии ESS. Если
- 123. Этап 4 – Изменяем величину ρ Берем ρ = –0,8 преобразуем исходные данные с учетом нового
- 124. Этап 5 – Определение оптимального коэффициента ρ Наименьшее значение остаточной дисперсии соответствует значению ρ = 0,5
- 125. Этап 6 – Необходимо записать уравнение регрессии, скорректировав его параметры с учетом найденного значения коэффициента авторегрессии
- 126. Этап 7 – Определение величины статистики Дарбина-Уотсона DW = 2,0442 Проведенное преобразование увеличило значение статистики DW
- 128. Скачать презентацию

Введение
Введение

Существует три основных класса эконометрических моделей:
Модели временных рядов
Регрессионные модели с одним
Существует три основных класса эконометрических моделей:
Модели временных рядов
Регрессионные модели с одним

Регрессионные модели с одним уравнением, в которых зависимая переменная может быть
Регрессионные модели с одним уравнением, в которых зависимая переменная может быть

Для решения эконометрической задачи необходимо последовательно выполнить несколько этапов экономико-математического моделирования
Постановочный
Для решения эконометрической задачи необходимо последовательно выполнить несколько этапов экономико-математического моделирования
Постановочный

Этап параметризации – происходит выбор общего вида модели, а также определяется
Этап параметризации – происходит выбор общего вида модели, а также определяется

В рамках регрессионного анализа необходимо решить 4 задачи:
Определение числовых значений параметров
В рамках регрессионного анализа необходимо решить 4 задачи:
Определение числовых значений параметров
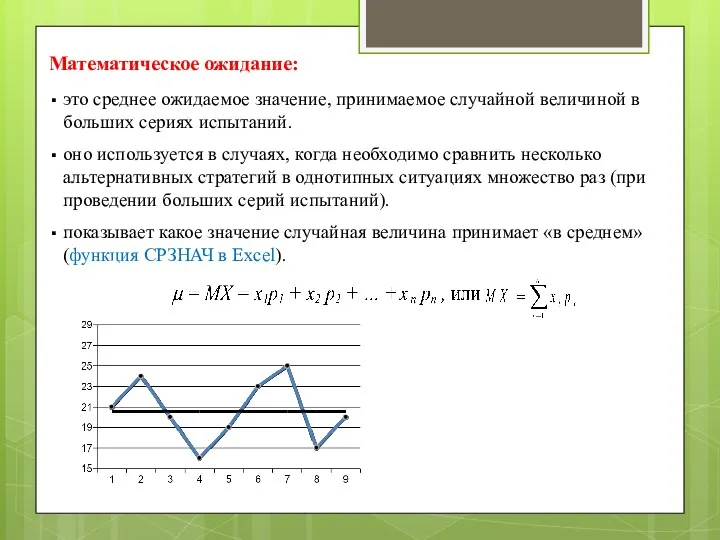
Математическое ожидание:
это среднее ожидаемое значение, принимаемое случайной величиной в больших сериях
Математическое ожидание:
это среднее ожидаемое значение, принимаемое случайной величиной в больших сериях

Дисперсия:
Используется для оценки разброса значений случайной величины вокруг ее среднего
Дисперсия:
Используется для оценки разброса значений случайной величины вокруг ее среднего

Стандартное (среднеквадратичное) отклонение:
Как и дисперсия используется в качестве меры абсолютного разброса
Стандартное (среднеквадратичное) отклонение:
Как и дисперсия используется в качестве меры абсолютного разброса


Чтобы совокупность случайных величин можно было использовать для регрессионного анализа и
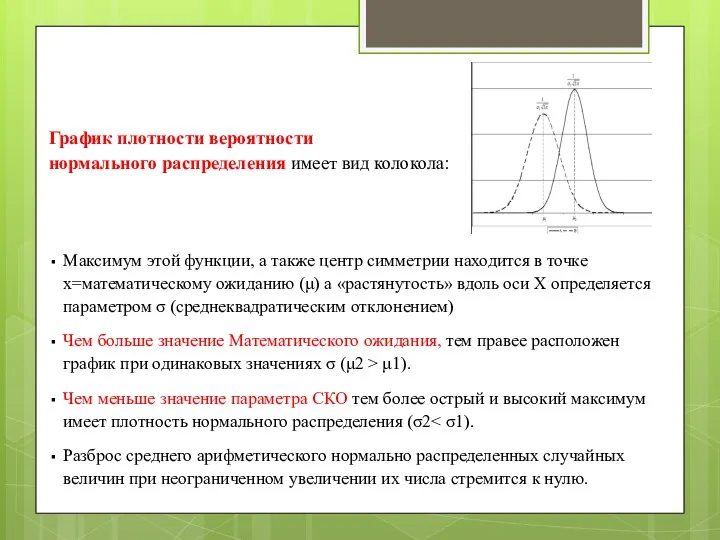
График плотности вероятности
нормального распределения имеет вид колокола:
Максимум этой функции,
График плотности вероятности
нормального распределения имеет вид колокола:
Максимум этой функции,

Такой график может быть получен только при бесконечно большом количестве измерений
Такой график может быть получен только при бесконечно большом количестве измерений

Построение гистограммы с помощью программы Excel.
Идем во вкладку «Анализ данных» и
Построение гистограммы с помощью программы Excel.
Идем во вкладку «Анализ данных» и

Теперь нужно сделать так, чтобы по вертикальной оси отображалась не абсолютная
Теперь нужно сделать так, чтобы по вертикальной оси отображалась не абсолютная

Корреляция и ковариация
Важнейшая задача эконометрики – исследование существующих связей между социально-экономическими
Корреляция и ковариация
Важнейшая задача эконометрики – исследование существующих связей между социально-экономическими

Принято различать следующие виды корреляции:
Парная — связь между двумя признаками (результативным
Принято различать следующие виды корреляции:
Парная — связь между двумя признаками (результативным

Ковариация выражает степень статистической зависимости между двумя множествами данных, измеряется в тех же
Ковариация выражает степень статистической зависимости между двумя множествами данных, измеряется в тех же

Оценка связи по ковариации:
Положительная ковариация наблюдается когда большим значениям случайной величины Х соответствуют
Оценка связи по ковариации:
Положительная ковариация наблюдается когда большим значениям случайной величины Х соответствуют

Коэффициент корреляции принимает значения от -1 до +1 :
Если R<0,
Коэффициент корреляции принимает значения от -1 до +1 :
Если R<0,

Парные регрессионные модели
Парные регрессионные модели

Модели парной регрессии
В регрессионной модели все переменные делятся на:
зависимые, эндогенные (y)
Модели парной регрессии
В регрессионной модели все переменные делятся на:
зависимые, эндогенные (y)

Существует несколько причин появления в модели случайной составляющей:
Не включение объясняющих переменных.
Соотношение
Существует несколько причин появления в модели случайной составляющей:
Не включение объясняющих переменных.
Соотношение

Неправильная функциональная спецификация.
соотношение между yt и хt математически может быть определено
Неправильная функциональная спецификация.
соотношение между yt и хt математически может быть определено

Предположим, что у нас имеется n наблюдений для хt и yt,

Недостатки такого подхода:
Построение линии регрессии без точных расчетов является достаточно субъективным.
Недостатки такого подхода:
Построение линии регрессии без точных расчетов является достаточно субъективным.

Второй этап – Необходимо выбрать какой-то критерий подбора, который будет одновременно
Второй этап – Необходимо выбрать какой-то критерий подбора, который будет одновременно

Третий этап – Нахождение параметров уравнения регрессии методом наименьших квадратов:
Минимизируется сумма
Третий этап – Нахождение параметров уравнения регрессии методом наименьших квадратов:
Минимизируется сумма
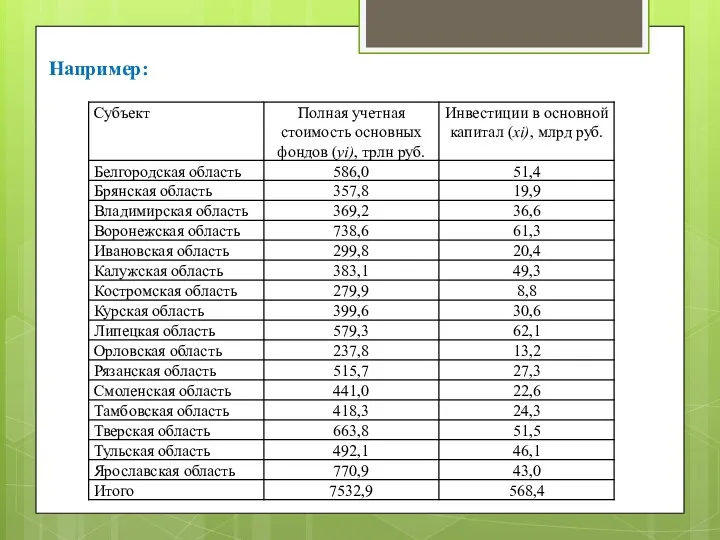
Например:
Например:

Предположим наличие линейной зависимости между рассматриваемыми переменными.
Отсюда получается:
a0 = 211,296
a1
Предположим наличие линейной зависимости между рассматриваемыми переменными.
Отсюда получается:
a0 = 211,296
a1

Другой способ нахождения коэффициентов регрессии:

Экономико-математическая интерпретация построенной регрессионной модели
После записи уравнения регрессии необходимо выполнить экономико-математическую
Экономико-математическая интерпретация построенной регрессионной модели
После записи уравнения регрессии необходимо выполнить экономико-математическую

Математически параметры а и b можно рассчитать для любого массива статистической

Алгоритм проверки статистической гипотезы о достоверности параметра b:
Выдвигается нулевая гипотеза Н0
Алгоритм проверки статистической гипотезы о достоверности параметра b:
Выдвигается нулевая гипотеза Н0

По таблице распределения Стьюдента определяется критическое значение t-статистики для оцениваемого коэффициента
По таблице распределения Стьюдента определяется критическое значение t-статистики для оцениваемого коэффициента

В большинстве случаев определяется не только величина статистики Стьюдента, но и
В большинстве случаев определяется не только величина статистики Стьюдента, но и

Например:
По 25 наблюдениям получено уравнение регрессии:
Необходимо проверить значимость коэффициента при
Например:
По 25 наблюдениям получено уравнение регрессии:
Необходимо проверить значимость коэффициента при

Мы предположили, что показатели хt и yt связаны между собой линейной

2. Необходимо установить уровень подгонки модели
к исходным данным (рассчитать коэффициент
к исходным данным (рассчитать коэффициент

Доля дисперсии, объясненная регрессией (RSS) – Коэффициент детерминации показывает:
какая доля вариации
Доля дисперсии, объясненная регрессией (RSS) – Коэффициент детерминации показывает:
какая доля вариации

Для устранения эффекта, связанного с ростом коэффициента детерминации при увеличении количества
Для устранения эффекта, связанного с ростом коэффициента детерминации при увеличении количества

3. Необходимо проанализировать выбросы в модели
Статистический выброс – это аномальное наблюдение,
3. Необходимо проанализировать выбросы в модели
Статистический выброс – это аномальное наблюдение,

Величина, с помощью которой проверяется нулевая гипотеза для коэффициента детерминации, называется
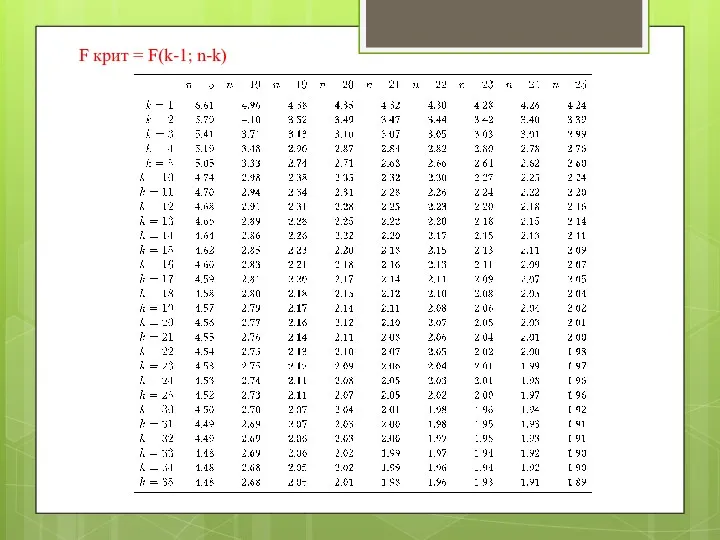
F крит = F(k-1; n-k)
F крит = F(k-1; n-k)

По распределению Фишера определяют вероятность нулевой гипотезы для коэффициента детерминации:
Сначала выдвигается
По распределению Фишера определяют вероятность нулевой гипотезы для коэффициента детерминации:
Сначала выдвигается

Например:
По 25 наблюдениям получено уравнение:
Необходимо проверить гипотезу о значимости регрессии
Например:
По 25 наблюдениям получено уравнение:
Необходимо проверить гипотезу о значимости регрессии

Множественные регрессионные модели
Множественные регрессионные модели

Модели множественной линейной регрессии
строятся когда величина исследуемого показателя складывается под влиянием
Модели множественной линейной регрессии
строятся когда величина исследуемого показателя складывается под влиянием

В таких моделях зависимая переменная у рассматривается как функция не одной,
В таких моделях зависимая переменная у рассматривается как функция не одной,

Оценка качества модели:
Связь между изучаемыми факторами и зависимой переменной должна
Оценка качества модели:
Связь между изучаемыми факторами и зависимой переменной должна

Нелинейные регрессионные модели
Нелинейные регрессионные модели

Модели нелинейной регрессии
Соотношения, существующие между социально-экономическими показателями и процессами не всегда
Модели нелинейной регрессии
Соотношения, существующие между социально-экономическими показателями и процессами не всегда
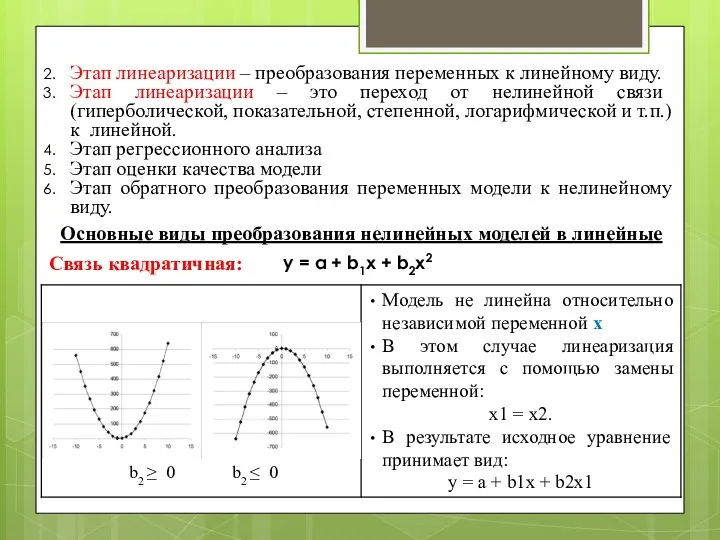
Этап линеаризации – преобразования переменных к линейному виду.
Этап линеаризации – это
Этап линеаризации – преобразования переменных к линейному виду.
Этап линеаризации – это
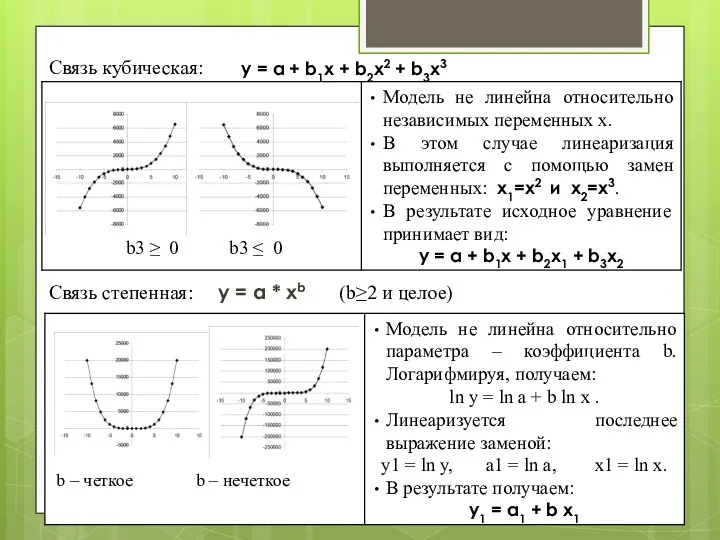
Связь кубическая:
Связь степенная: y = a * xb (b≥2 и целое)
y
Связь кубическая:
Связь степенная: y = a * xb (b≥2 и целое)
y
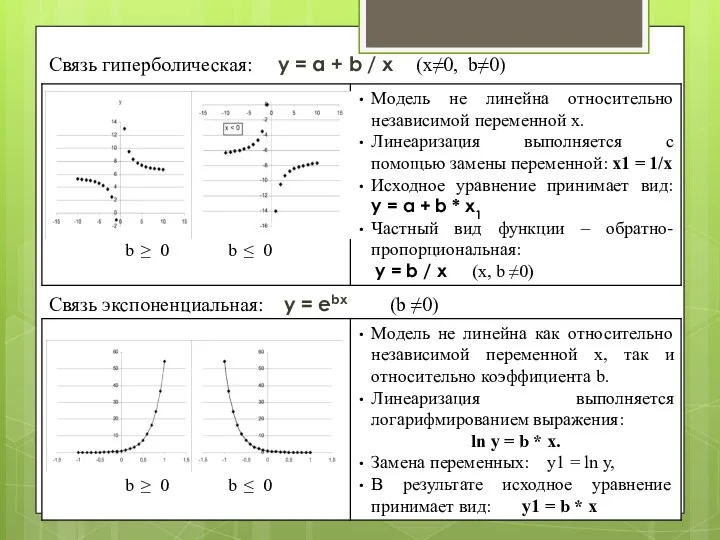
Связь гиперболическая: y = a + b / x (x≠0, b≠0)
Связь
Связь гиперболическая: y = a + b / x (x≠0, b≠0)
Связь

Связь логарифмическая (обратная экспоненциальной): у = а + b· ln x
Связь логарифмическая (обратная экспоненциальной): у = а + b· ln x

Функция Кобба-Дугласа
характеризует связь между совокупным выпуском (доходом) и объемами используемых ресурсов.
Функция Кобба-Дугласа
характеризует связь между совокупным выпуском (доходом) и объемами используемых ресурсов.

По результатам модели:
увеличение затрат труда на 1% повлечет за собой
По результатам модели:
увеличение затрат труда на 1% повлечет за собой

При построении модели:
в качестве Входного интервала Y выбираются значения из столбца
При построении модели:
в качестве Входного интервала Y выбираются значения из столбца

Пример нелинейного моделирования
Используем функцию LN (каждой ячейки)
Проводим регрессионный анализ и получаем
Пример нелинейного моделирования
Используем функцию LN (каждой ячейки)
Проводим регрессионный анализ и получаем
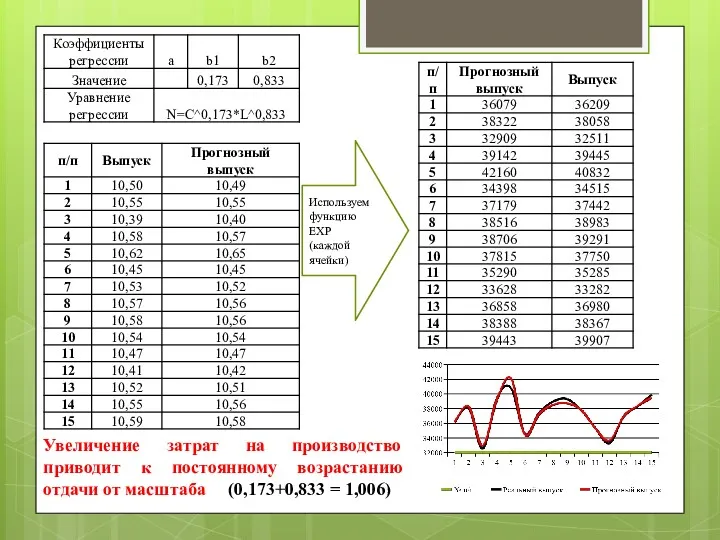
Используем функцию EXP (каждой ячейки)
Увеличение затрат на производство приводит к постоянному
Используем функцию EXP (каждой ячейки)
Увеличение затрат на производство приводит к постоянному

Регрессионные модели с фиктивными переменными
Регрессионные модели с фиктивными переменными

Использование фиктивных переменных в регрессионном анализе
До сих пор в качестве факторов
До сих пор в качестве факторов

Например:
Имеется бинарная модель:
Пробег = 41,98 – 1,5 * Возраст + 1,11
Например:
Имеется бинарная модель:
Пробег = 41,98 – 1,5 * Возраст + 1,11

Например:
Используем формулу:
ЕСЛИ (ячейка = «средний»; 1; 0)
ЕСЛИ (ячейка = «есть»; 1;
Например:
Используем формулу:
ЕСЛИ (ячейка = «средний»; 1; 0)
ЕСЛИ (ячейка = «есть»; 1;

Использование фиктивных переменных в анализе сезонных колебаний
Иногда заметное влияние на регрессионную
Использование фиктивных переменных в анализе сезонных колебаний
Иногда заметное влияние на регрессионную

Переходим к оценке уравнения
у = a + b1 d1 + b2
Переходим к оценке уравнения
у = a + b1 d1 + b2

Таким образом, среднее значение результативного показателя в каждый из сезонов достигает
Таким образом, среднее значение результативного показателя в каждый из сезонов достигает

Например:
Предполагается проведение исследований сезонных колебаний цены на акции компании «Лукойл».
Выделяются четыре
Например:
Предполагается проведение исследований сезонных колебаний цены на акции компании «Лукойл».
Выделяются четыре
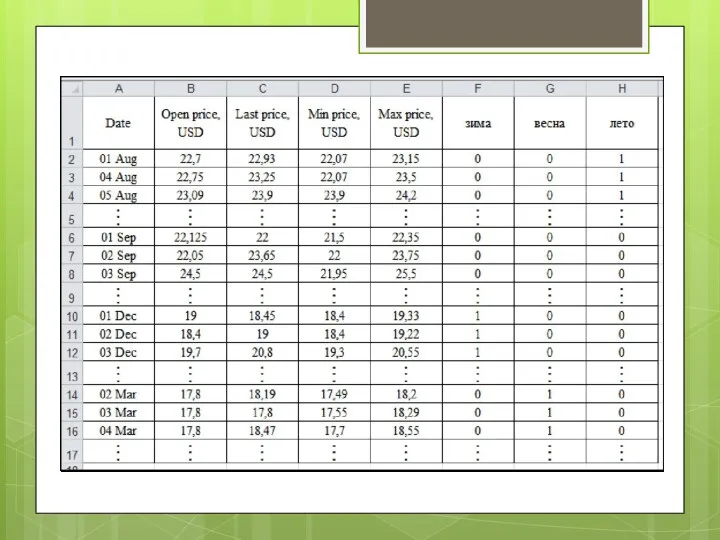
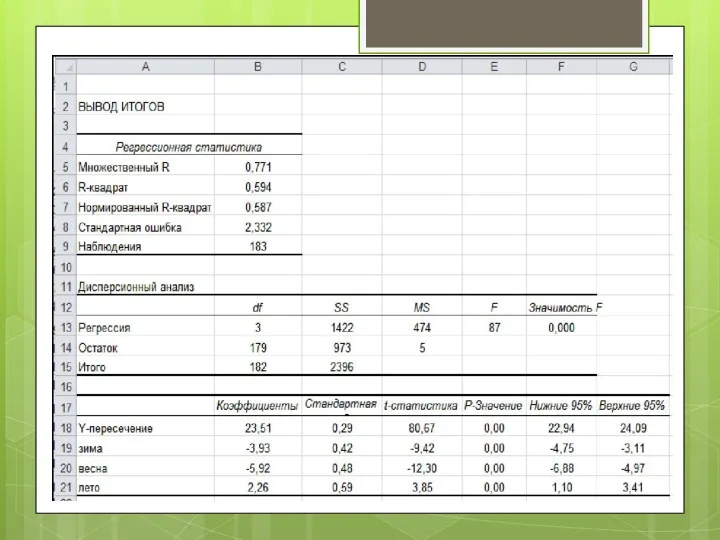

Last price = 23,51 – 3,93 * зима – 5,92 *

Аналогично можно получить средние значения цены закрытия в другие сезоны:
Last price
Аналогично можно получить средние значения цены закрытия в другие сезоны:
Last price

Устранение трендовых компонент с помощью регрессионных моделей
Устранение трендовых компонент с помощью регрессионных моделей
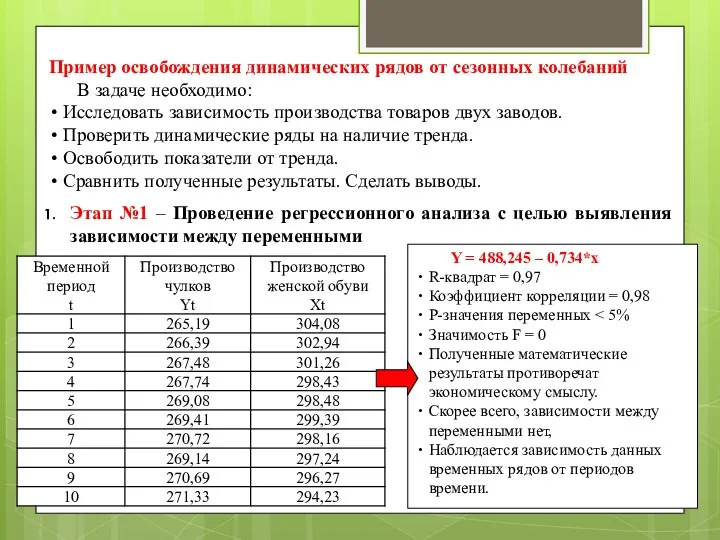
Пример освобождения динамических рядов от сезонных колебаний
В задаче необходимо:
Исследовать зависимость
Пример освобождения динамических рядов от сезонных колебаний
В задаче необходимо:
Исследовать зависимость
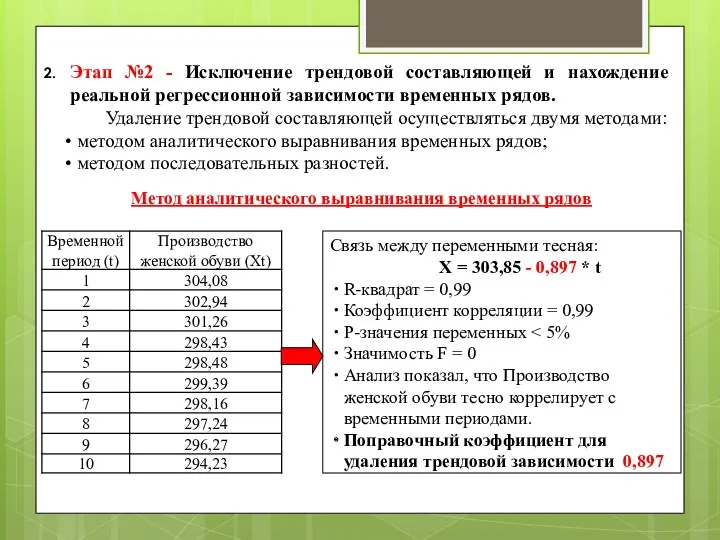
Этап №2 - Исключение трендовой составляющей и нахождение реальной регрессионной зависимости
Этап №2 - Исключение трендовой составляющей и нахождение реальной регрессионной зависимости
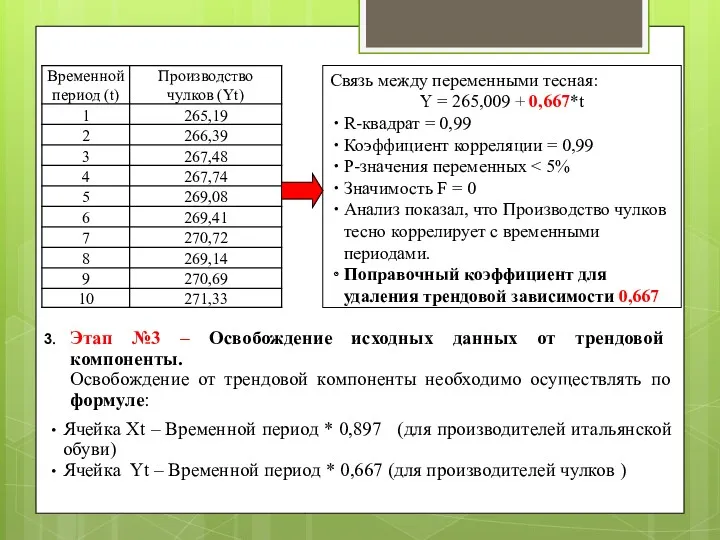
Этап №3 – Освобождение исходных данных от трендовой компоненты.
Освобождение от
Этап №3 – Освобождение исходных данных от трендовой компоненты.
Освобождение от

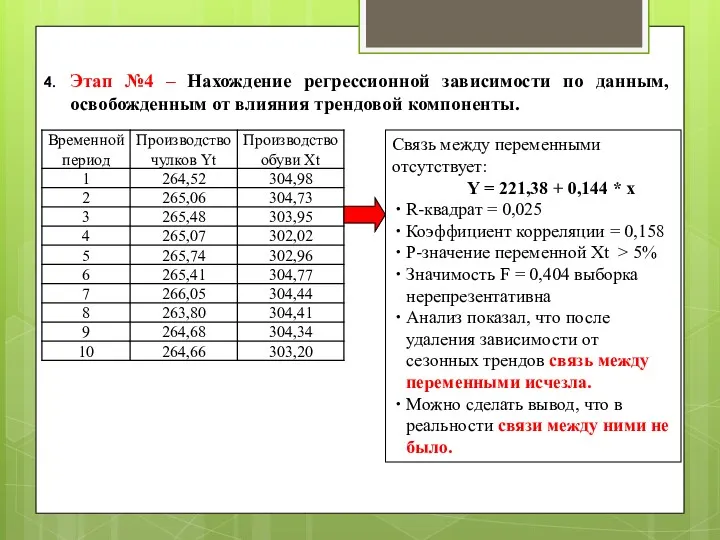
Этап №4 – Нахождение регрессионной зависимости по данным, освобожденным от влияния
Этап №4 – Нахождение регрессионной зависимости по данным, освобожденным от влияния
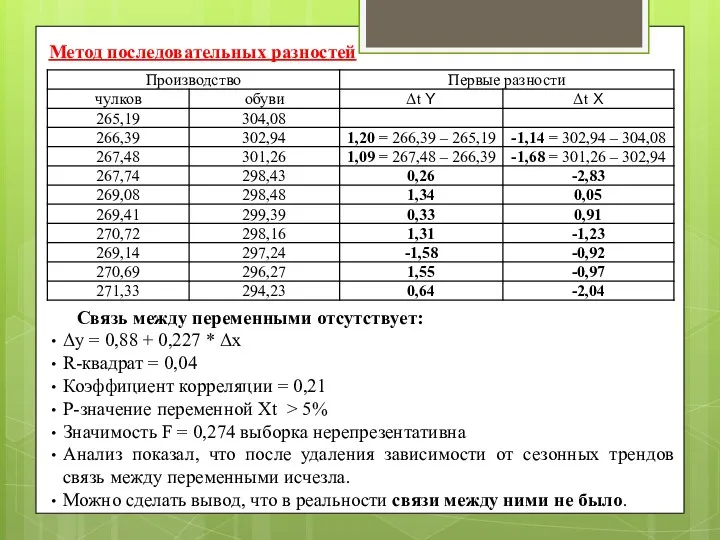
Метод последовательных разностей
Связь между переменными отсутствует:
Δy = 0,88 + 0,227
Метод последовательных разностей
Связь между переменными отсутствует:
Δy = 0,88 + 0,227

Предпосылки МНК
Предпосылки МНК

Предпосылки метода наименьших квадратов
Для того чтобы регрессионный анализ давал наилучшие результаты
Предпосылки метода наименьших квадратов
Для того чтобы регрессионный анализ давал наилучшие результаты

Предпосылки МНК
Математическое ожидание случайной составляющей (остатков) в любом наблюдении должно быть
Предпосылки МНК
Математическое ожидание случайной составляющей (остатков) в любом наблюдении должно быть

Отсутствие автокорреляции остатков. Любые случайные отклонения ut и uk должны быть
Отсутствие автокорреляции остатков. Любые случайные отклонения ut и uk должны быть

Мультиколлинеарность
Мультиколлинеарность

Мультиколлинеарность
это сильная коррелированность двух или нескольких объясняющих переменных.
в этом случае
Мультиколлинеарность
это сильная коррелированность двух или нескольких объясняющих переменных.
в этом случае

Признаки мультиколлинеарности:
незначительное изменение исходных данных приводит к существенному изменению коэффициентов
Признаки мультиколлинеарности:
незначительное изменение исходных данных приводит к существенному изменению коэффициентов

Для измерения мультиколлинеарности можно использовать коэффициент множественной детерминации:
При отсутствии мультиколлинеарности
Для измерения мультиколлинеарности можно использовать коэффициент множественной детерминации:
При отсутствии мультиколлинеарности

Для устранения мультиколлинеарности используется метод исключения переменных:
высоко коррелированные объясняющие переменные
Для устранения мультиколлинеарности используется метод исключения переменных:
высоко коррелированные объясняющие переменные

Процедура отбора удаляемых факторов включает следующие этапы:
Проводится анализ рассчитанных значений
Процедура отбора удаляемых факторов включает следующие этапы:
Проводится анализ рассчитанных значений

Прежде, чем вынести решение об исключении факторов, проводят дополнительное исследование с
Прежде, чем вынести решение об исключении факторов, проводят дополнительное исследование с
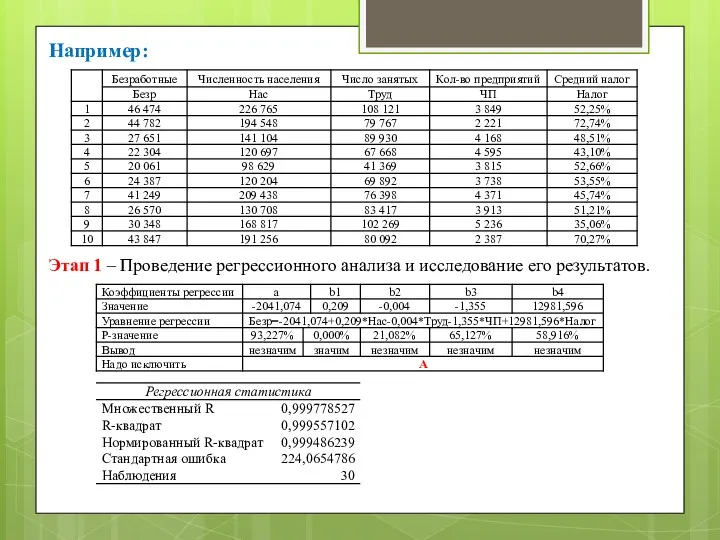
Например:
Этап 1 – Проведение регрессионного анализа и исследование его результатов.
Например:
Этап 1 – Проведение регрессионного анализа и исследование его результатов.

Этап 2 - Построение матрицы попарных корреляций и ее анализ
Из построенной
Этап 2 - Построение матрицы попарных корреляций и ее анализ
Из построенной

Этап 3 – Расчет меры мультиколлинеарности (М)
где R2 – коэф. детерминации
Этап 3 – Расчет меры мультиколлинеарности (М)
где R2 – коэф. детерминации
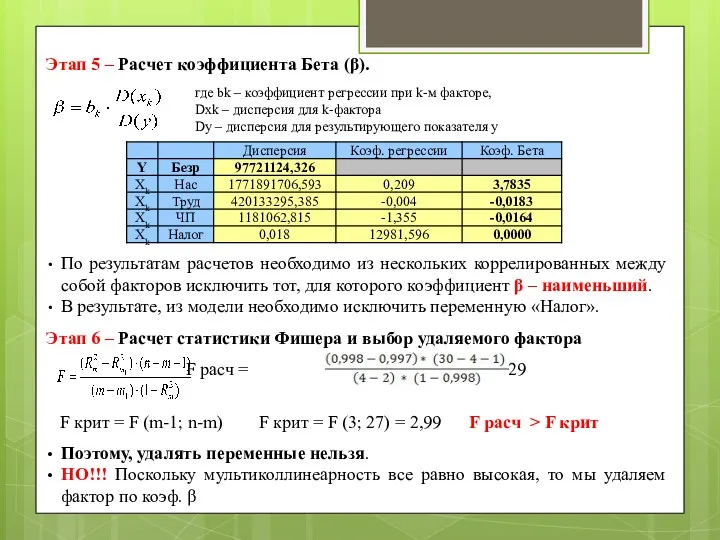
Этап 5 – Расчет коэффициента Бета (β).
где bk – коэффициент регрессии
Этап 5 – Расчет коэффициента Бета (β).
где bk – коэффициент регрессии
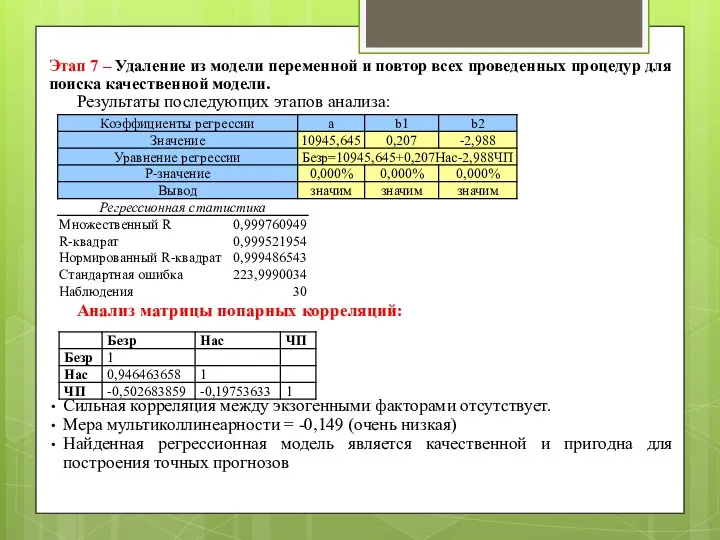
Этап 7 – Удаление из модели переменной и повтор всех проведенных
Этап 7 – Удаление из модели переменной и повтор всех проведенных

Автокорреляция остатков
Автокорреляция остатков

Автокорреляция остатков
Статистическая значимость коэффициентов регрессии и близкое к 1 значение коэффициента
Автокорреляция остатков
Статистическая значимость коэффициентов регрессии и близкое к 1 значение коэффициента

Например.
Исследуется зависимость объема потребления С от численности населения Р в
Например.
Исследуется зависимость объема потребления С от численности населения Р в

Если использовать линейную регрессию для прогнозирования дальнейшей динамики потребления, то результат
Если использовать линейную регрессию для прогнозирования дальнейшей динамики потребления, то результат

Автокорреляция – статистическая зависимость между ошибками различных наблюдений изучаемых показателей, упорядоченных
Автокорреляция – статистическая зависимость между ошибками различных наблюдений изучаемых показателей, упорядоченных

Основные причины появления автокорреляции:
Ошибки спецификации:
не учет в модели какой-нибудь важной
Основные причины появления автокорреляции:
Ошибки спецификации:
не учет в модели какой-нибудь важной

Последствия автокорреляции:
Оценки коэффициентов регрессии, оставаясь линейными и несмещенными, перестают быть эффективными,
Оценки коэффициентов регрессии, оставаясь линейными и несмещенными, перестают быть эффективными,

Способы выявления наличия автокорреляции.
Графический метод.
Строится последовательно-временной график.
По оси абсцисс откладывается
Способы выявления наличия автокорреляции.
Графический метод.
Строится последовательно-временной график.
По оси абсцисс откладывается

Метод рядов:
Последовательно определяются знаки отклонений et , t = 1,2,...,Т.
Ряд определяется
Метод рядов:
Последовательно определяются знаки отклонений et , t = 1,2,...,Т.
Ряд определяется

Например:
Имеется временная последовательность
(– – – – – ) (+ +
Например:
Имеется временная последовательность
(– – – – – ) (+ +

Метод Дарбина-Уотсона.
Это наиболее известный критерий обнаружения автокорреляции первого порядка является
важнейшая характеристика
Метод Дарбина-Уотсона.
Это наиболее известный критерий обнаружения автокорреляции первого порядка является
важнейшая характеристика

Расчет интервала коэффициента DW:
Если et = et-1, то r (et, et-1)
Расчет интервала коэффициента DW:
Если et = et-1, то r (et, et-1)

Какие значения DW можно считать статистически близкими к 2?
Для ответа
Какие значения DW можно считать статистически близкими к 2?
Для ответа

Не обращаясь к таблице критических точек Дарбина-Уотсона, можно пользоваться «грубым» правилом
Не обращаясь к таблице критических точек Дарбина-Уотсона, можно пользоваться «грубым» правилом

При использовании критерия Дарбина-Уотсона необходимо учитывать следующие ограничения:
Критерий DW применяется лишь
При использовании критерия Дарбина-Уотсона необходимо учитывать следующие ограничения:
Критерий DW применяется лишь

Методы устранения автокорреляции.
Так как автокорреляция чаще всего вызывается неправильной спецификацией модели,
Методы устранения автокорреляции.
Так как автокорреляция чаще всего вызывается неправильной спецификацией модели,

Рассмотрим модель парной линейной регрессии:
Тогда наблюдениям t и (t-1) соответствуют формулы:
Пусть
Рассмотрим модель парной линейной регрессии:
Тогда наблюдениям t и (t-1) соответствуют формулы:
Пусть

Два подхода к оценке параметра ρ:
На основе статистики Дарбина-Уотсона.
Статистика Дарбина-Уотсона тесно
Два подхода к оценке параметра ρ:
На основе статистики Дарбина-Уотсона.
Статистика Дарбина-Уотсона тесно

Метод Хилдрета-Лу.
Рассмотрим зависимость показателя у от значений k регрессоров:
В данном случае
Метод Хилдрета-Лу.
Рассмотрим зависимость показателя у от значений k регрессоров:
В данном случае

Суть процедуры Хилдрета-Лу достаточно проста:
Из интервала от –1 до +1
Суть процедуры Хилдрета-Лу достаточно проста:
Из интервала от –1 до +1
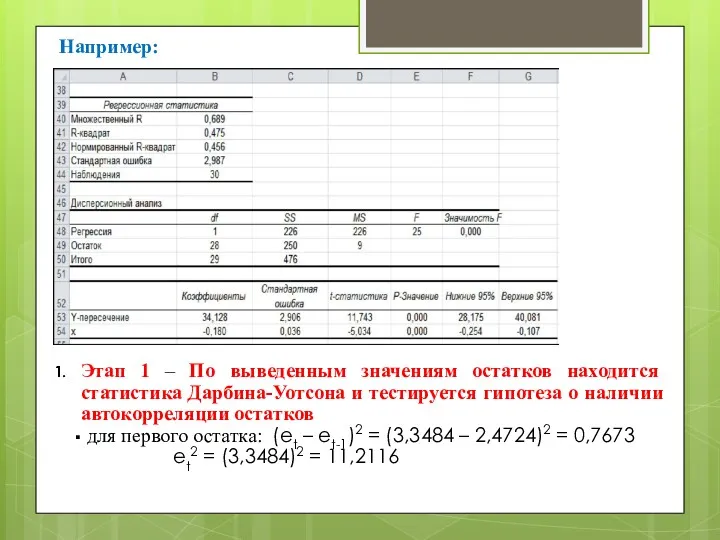
Например:
Этап 1 – По выведенным значениям остатков находится статистика Дарбина-Уотсона и
Например:
Этап 1 – По выведенным значениям остатков находится статистика Дарбина-Уотсона и
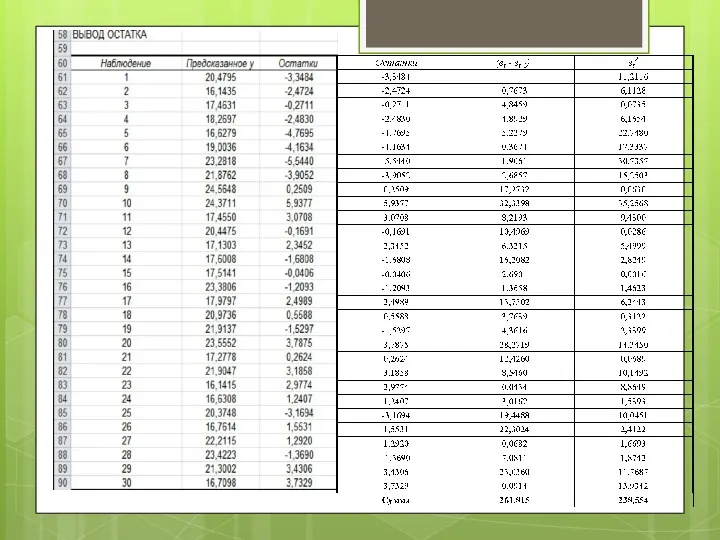

DW = 261,815 / 238,554 = 1,099
Поскольку статистика Дарбина-Уотсона DW
DW = 261,815 / 238,554 = 1,099
Поскольку статистика Дарбина-Уотсона DW
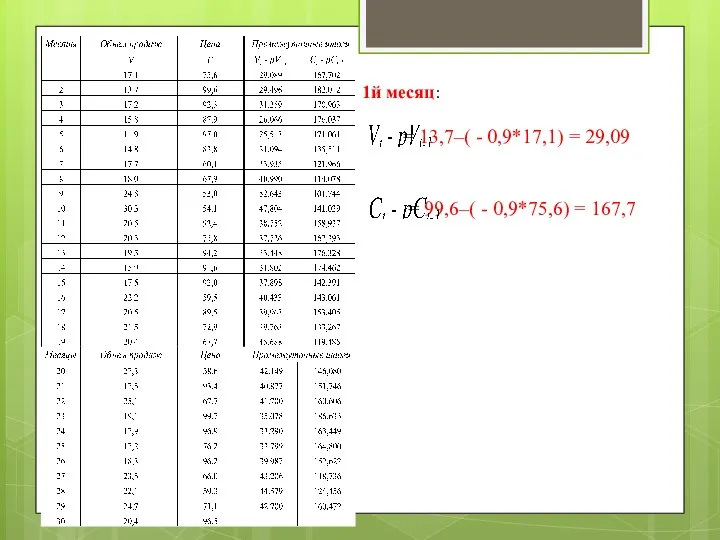
1й месяц:
= 13,7–( - 0,9*17,1) = 29,09
= 99,6–( - 0,9*75,6)
1й месяц:
= 13,7–( - 0,9*17,1) = 29,09
= 99,6–( - 0,9*75,6)
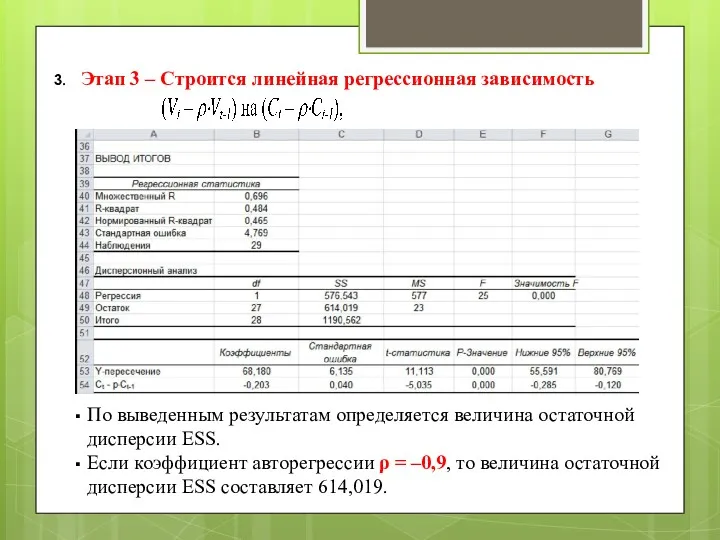
Этап 3 – Строится линейная регрессионная зависимость
По выведенным результатам определяется
Этап 3 – Строится линейная регрессионная зависимость
По выведенным результатам определяется
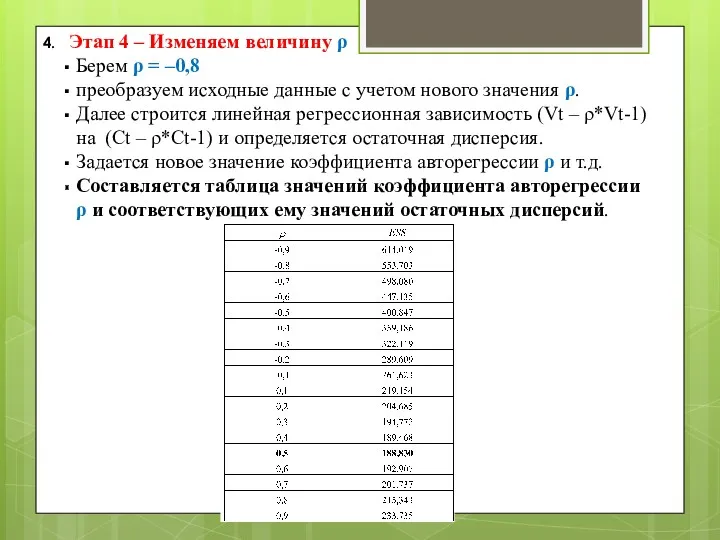
Этап 4 – Изменяем величину ρ
Берем ρ = –0,8
преобразуем
Этап 4 – Изменяем величину ρ
Берем ρ = –0,8
преобразуем
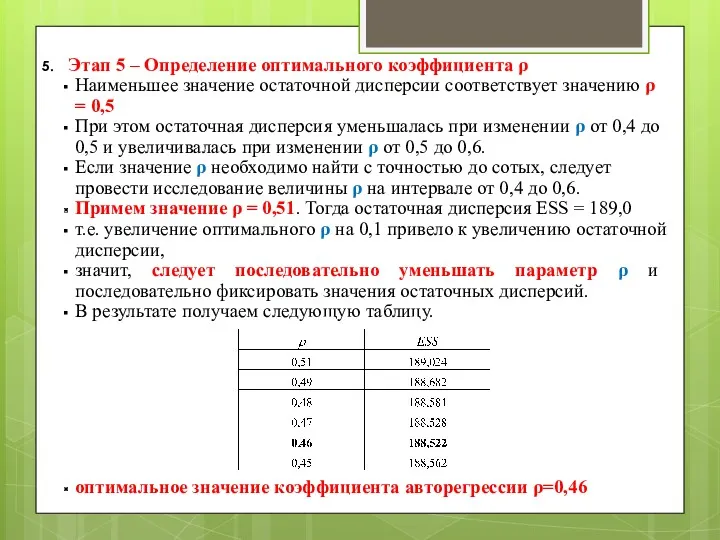
Этап 5 – Определение оптимального коэффициента ρ
Наименьшее значение остаточной дисперсии соответствует
Этап 5 – Определение оптимального коэффициента ρ
Наименьшее значение остаточной дисперсии соответствует
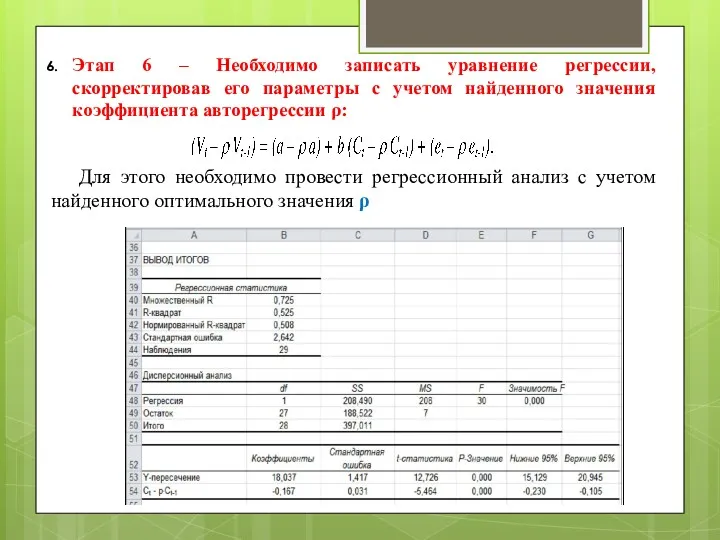
Этап 6 – Необходимо записать уравнение регрессии, скорректировав его параметры с
Этап 6 – Необходимо записать уравнение регрессии, скорректировав его параметры с

Этап 7 – Определение величины статистики Дарбина-Уотсона
DW = 2,0442
Проведенное преобразование увеличило
Этап 7 – Определение величины статистики Дарбина-Уотсона
DW = 2,0442
Проведенное преобразование увеличило
 Скалярное произведение в координатах
Скалярное произведение в координатах Применение векторов к решению задач. Геометрия (9 класс)
Применение векторов к решению задач. Геометрия (9 класс) Умножение и деление круглых чисел
Умножение и деление круглых чисел Лобачевский Николай Иванович и его творческий путь
Лобачевский Николай Иванович и его творческий путь Анализ записей решения уравнений, их сравнение. Математика Истомина Н.Б. 2-ая часть УМК Гармония
Анализ записей решения уравнений, их сравнение. Математика Истомина Н.Б. 2-ая часть УМК Гармония Развитие математики в России
Развитие математики в России Аксиомы стереометрии. (10 класс)
Аксиомы стереометрии. (10 класс) Математика 1 класс Длиннее и короче презентация Диск
Математика 1 класс Длиннее и короче презентация Диск Способы отбора выборки
Способы отбора выборки Russian mathematician. Sofia Kovalevskaya
Russian mathematician. Sofia Kovalevskaya Гамильтоновы графы
Гамильтоновы графы Умножение разности двух выражений на их сумму
Умножение разности двух выражений на их сумму Лінійні алгоритми
Лінійні алгоритми Математика. 1 класс. Урок 97. Сложение и вычитание в пределах 20 - Презентация
Математика. 1 класс. Урок 97. Сложение и вычитание в пределах 20 - Презентация Признаки подобия треугольников
Признаки подобия треугольников Математика Демонстрационный материал Весёлый счёт (1 класс)
Математика Демонстрационный материал Весёлый счёт (1 класс) Сравнение дробей
Сравнение дробей Методы статистического вывода: проверка гипотез
Методы статистического вывода: проверка гипотез Диагностическая работа. Готовимся к ГИА. 9 класс
Диагностическая работа. Готовимся к ГИА. 9 класс Математический диктант 4
Математический диктант 4 Веселый счет
Веселый счет Сравнение многозначных чисел
Сравнение многозначных чисел Көбейтудің ауыстырымдылық қасиеті
Көбейтудің ауыстырымдылық қасиеті Логарифмическая функция
Логарифмическая функция Математика. Устный счет 2 класс
Математика. Устный счет 2 класс группировка слагаемых
группировка слагаемых Дифференциальные уравнения с разделяющимися переменными
Дифференциальные уравнения с разделяющимися переменными Презентация Сложение и вычитание в картинках 1 класс УМК Перспективная начальная школа
Презентация Сложение и вычитание в картинках 1 класс УМК Перспективная начальная школа