- Статистическая обработка результатов

Содержание
- 2. План 1. Общее понятие о статистике 2. Представление данных 3. Описательная статистика 4. Индуктивная статистика
- 3. Литература Руководство по проведению научных исследований в области биологии для студентов и аспирантов / сост. Л.А.Гайсина,
- 4. 1. Общее понятие о статистике Слово «статистика» часто ассоциируется со словом «математика», и это пугает студентов,
- 5. Общее понятие о статистике Все эти виды деятельности мало отличаются от тех операций, которые лежат в
- 6. Разделы статистики Рассмотрим в самых общих чертах три главных раздела статистики. 1. Описательная статистика, как следует
- 7. Разделы статистики 3. Наконец, измерение корреляции позволяет узнать, насколько связаны между собой две переменные, с тем,
- 8. 2. Представление данных Одна из задач статистики состоит в том, чтобы анализировать данные, полученные на части
- 9. Представление данных Данные в статистике – это основные элементы, подлежащие анализу. Данными могут быть какие-то количественные
- 10. Представление данных Существуют три типа данных: Количественные данные, получаемые при измерениях (например, данные о весе, размерах,
- 11. Составление таблиц Таблицы относятся к наиболее простому способу представления данных. Они состоят из колонок со значениями
- 12. Графическое представление данных График – это двухмерное изображение зависимости между двумя или более переменными. График самой
- 13. Пример графика График зависимости между средней высотой проростков овса и продолжительностью роста (Грин и др., 1996)
- 14. Распределение частот Существует множество отношений между переменными, при которых каждое значение зависимой переменной, соответствующее значению независимой
- 15. Распределение частот Кривая нормального распределения. В этом случае распределение частот симметрично относительно центрального значения, а рассматриваемые
- 16. Распределение частот Положительный уклон. Кривая распределения в этом случае несимметрична. Наибольшие частоты независимой переменной приходятся на
- 17. Распределение частот Отрицательный уклон. В этом случае наибольшие частоты независимой переменной приходятся на ее более высокие
- 18. Диаграмма Если независимая переменная принимает дискретные значения, например, целые числа 3 и 5 (как число лепестков
- 19. Диаграмма Диаграмма в виде вертикальных столбцов. Она показывает частоту, с которой определенные признаки встречаются внутри популяции.
- 20. Описательная статистика Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь
- 21. Характеристики расположения относительно центра. Среднее (среднее арифметическое) Среднее (среднее арифметическое) Это «средняя величина» группы значений, которую
- 22. Медиана
- 23. Мода Это значение переменной, встречающееся наиболее часто. Например, если число детей в десядесяти семьях соответственно равно
- 24. Соотношение средних величин Каждое из трех значений, описанных выше, имеет свои преимущества и недостатки и применяется
- 25. Оценки дисперсии Для того чтобы оценить, в какой мере значения признака отклоняются от среднего, вычисляют среднее
- 26. Стандартное отклонение
- 27. Стандартное отклонение
- 28. Стандартное отклонение В этой популяции имеющих общее происхождение блюдечек среднее максимальное значение диаметра раковины равно 38,3
- 29. Дисперсия
- 30. Дисперсия
- 31. Связь между переменными Данные всегда необходимо представлять таким образом, чтобы можно было выявить связи между двумя
- 32. Линия регрессии По внешнему виду графика видно, что эти две переменные связаны между собой некоторым образом,
- 33. Индуктивная статистика Задачи индуктивной статистики заключаются в том, чтобы определять, насколько вероятно, что две выборки принадлежат
- 34. Индуктивная статистика Видно, что в контрольной группе разница между средними обоих распределений невелика, и поэтому можно
- 35. Проверка гипотез Как уже говорилось, задача индуктивной статистики – определять, достаточно ли велика разность между средними
- 36. Проверка гипотез Основной принцип метода проверки гипотез состоит в том, что выдвигается нулевая гипотеза Н0, с
- 37. Проверка гипотез Для того чтобы судить о том, какова вероятность ошибиться, принимая или отвергая нулевую гипотезу,
- 38. Уровни достоверности (значимости) Уровни достоверности (значимости) Тот или иной вывод с некоторой вероятностью может оказаться ошибочным,
- 39. Уровни достоверности (значимости) Для каждого статистического метода этот уровень можно узнать из таблиц распределения критических значений
- 40. Параметрические методы. Метод Стьюдента (t-тест) Метод Стьюдента (t-тест) Это параметрический метод, используемый для проверки гипотез о
- 41. Метод Стьюдента
- 42. Метод Стьюдента Если наш результат больше, чем значение для уровня достоверности 0,05 (вероятность 5%), найденное в
- 43. Степени свободы Для того чтобы свести к минимуму ошибки, в таблицах критических значений статистических критериев в
- 45. Скачать презентацию

План
1. Общее понятие о статистике
2. Представление данных
3. Описательная статистика
4. Индуктивная статистика
План
1. Общее понятие о статистике
2. Представление данных
3. Описательная статистика
4. Индуктивная статистика

Литература
Руководство по проведению научных исследований в области биологии для студентов и
Литература
Руководство по проведению научных исследований в области биологии для студентов и

1. Общее понятие о статистике
Слово «статистика» часто ассоциируется со словом «математика»,
1. Общее понятие о статистике
Слово «статистика» часто ассоциируется со словом «математика»,

Общее понятие о статистике
Все эти виды деятельности мало отличаются от тех
Общее понятие о статистике
Все эти виды деятельности мало отличаются от тех

Разделы статистики
Рассмотрим в самых общих чертах три главных раздела статистики.
1. Описательная статистика,
Разделы статистики
Рассмотрим в самых общих чертах три главных раздела статистики.
1. Описательная статистика,

Разделы статистики
3. Наконец, измерение корреляции позволяет узнать, насколько связаны между собой две
Разделы статистики
3. Наконец, измерение корреляции позволяет узнать, насколько связаны между собой две

2. Представление данных
Одна из задач статистики состоит в том, чтобы анализировать
2. Представление данных
Одна из задач статистики состоит в том, чтобы анализировать

Представление данных
Данные в статистике – это основные элементы, подлежащие анализу. Данными
Представление данных
Данные в статистике – это основные элементы, подлежащие анализу. Данными

Представление данных
Существуют три типа данных:
Количественные данные, получаемые при измерениях (например, данные
Представление данных
Существуют три типа данных:
Количественные данные, получаемые при измерениях (например, данные

Составление таблиц
Таблицы относятся к наиболее простому способу представления данных. Они состоят
Составление таблиц
Таблицы относятся к наиболее простому способу представления данных. Они состоят

Графическое представление данных
График – это двухмерное изображение зависимости между двумя или
Графическое представление данных
График – это двухмерное изображение зависимости между двумя или
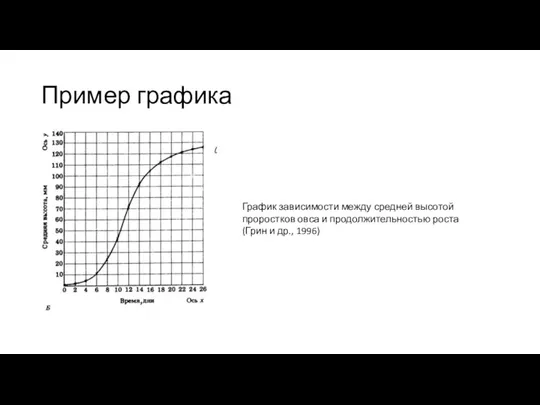
Пример графика
График зависимости между средней высотой проростков овса и продолжительностью роста
Пример графика
График зависимости между средней высотой проростков овса и продолжительностью роста

Распределение частот
Существует множество отношений между переменными, при которых каждое значение зависимой
Распределение частот
Существует множество отношений между переменными, при которых каждое значение зависимой
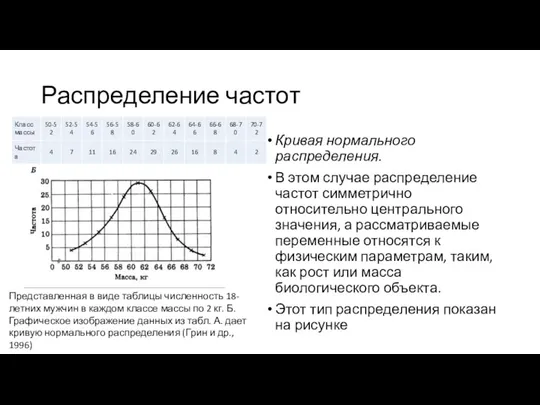
Распределение частот
Кривая нормального распределения.
В этом случае распределение частот симметрично относительно центрального
Распределение частот
Кривая нормального распределения.
В этом случае распределение частот симметрично относительно центрального

Распределение частот
Положительный уклон.
Кривая распределения в этом случае несимметрична. Наибольшие частоты независимой
Распределение частот
Положительный уклон.
Кривая распределения в этом случае несимметрична. Наибольшие частоты независимой

Распределение частот
Отрицательный уклон.
В этом случае наибольшие частоты независимой переменной приходятся на
Распределение частот
Отрицательный уклон.
В этом случае наибольшие частоты независимой переменной приходятся на

Диаграмма
Если независимая переменная принимает дискретные значения, например, целые числа 3 и
Диаграмма
Если независимая переменная принимает дискретные значения, например, целые числа 3 и

Диаграмма
Диаграмма в виде вертикальных столбцов. Она показывает частоту, с которой определенные
Диаграмма
Диаграмма в виде вертикальных столбцов. Она показывает частоту, с которой определенные

Описательная статистика
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или
Описательная статистика
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или

Характеристики расположения относительно центра. Среднее (среднее арифметическое)
Среднее (среднее арифметическое)
Это «средняя величина»
Характеристики расположения относительно центра. Среднее (среднее арифметическое)
Среднее (среднее арифметическое)
Это «средняя величина»

Медиана
Медиана

Мода
Это значение переменной, встречающееся наиболее часто. Например, если число детей в
Мода
Это значение переменной, встречающееся наиболее часто. Например, если число детей в
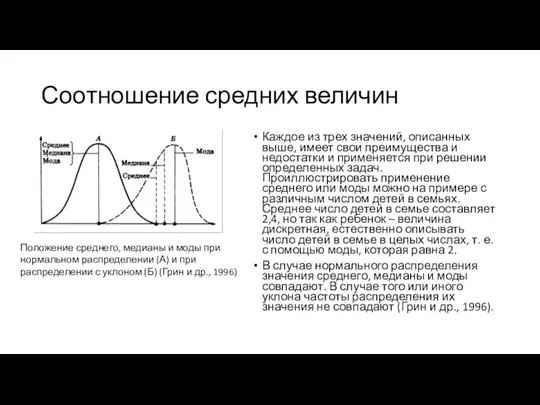
Соотношение средних величин
Каждое из трех значений, описанных выше, имеет свои преимущества
Соотношение средних величин
Каждое из трех значений, описанных выше, имеет свои преимущества

Оценки дисперсии
Для того чтобы оценить, в какой мере значения признака отклоняются
Оценки дисперсии
Для того чтобы оценить, в какой мере значения признака отклоняются

Стандартное отклонение
Стандартное отклонение

Стандартное отклонение
Стандартное отклонение

Стандартное отклонение
В этой популяции имеющих общее происхождение блюдечек среднее максимальное значение
Стандартное отклонение
В этой популяции имеющих общее происхождение блюдечек среднее максимальное значение

Дисперсия
Дисперсия

Дисперсия
Дисперсия

Связь между переменными
Данные всегда необходимо представлять таким образом, чтобы можно было
Связь между переменными
Данные всегда необходимо представлять таким образом, чтобы можно было

Линия регрессии
По внешнему виду графика видно, что эти две переменные связаны
Линия регрессии
По внешнему виду графика видно, что эти две переменные связаны

Индуктивная статистика
Задачи индуктивной статистики заключаются в том, чтобы определять, насколько вероятно,
Индуктивная статистика
Задачи индуктивной статистики заключаются в том, чтобы определять, насколько вероятно,

Индуктивная статистика
Видно, что в контрольной группе разница между средними обоих распределений
Индуктивная статистика
Видно, что в контрольной группе разница между средними обоих распределений

Проверка гипотез
Как уже говорилось, задача индуктивной статистики – определять, достаточно ли
Проверка гипотез
Как уже говорилось, задача индуктивной статистики – определять, достаточно ли

Проверка гипотез
Основной принцип метода проверки гипотез состоит в том, что выдвигается
Проверка гипотез
Основной принцип метода проверки гипотез состоит в том, что выдвигается

Проверка гипотез
Для того чтобы судить о том, какова вероятность ошибиться, принимая
Проверка гипотез
Для того чтобы судить о том, какова вероятность ошибиться, принимая

Уровни достоверности (значимости)
Уровни достоверности (значимости)
Тот или иной вывод с некоторой вероятностью
Уровни достоверности (значимости)
Уровни достоверности (значимости)
Тот или иной вывод с некоторой вероятностью

Уровни достоверности (значимости)
Для каждого статистического метода этот уровень можно узнать из
Уровни достоверности (значимости)
Для каждого статистического метода этот уровень можно узнать из

Параметрические методы. Метод Стьюдента (t-тест)
Метод Стьюдента (t-тест)
Это параметрический метод, используемый для
Параметрические методы. Метод Стьюдента (t-тест)
Метод Стьюдента (t-тест)
Это параметрический метод, используемый для

Метод Стьюдента
Метод Стьюдента

Метод Стьюдента
Если наш результат больше, чем значение для уровня достоверности 0,05
Метод Стьюдента
Если наш результат больше, чем значение для уровня достоверности 0,05

Степени свободы
Для того чтобы свести к минимуму ошибки, в таблицах критических
Степени свободы
Для того чтобы свести к минимуму ошибки, в таблицах критических
 Конспекты уроков по математике 1 класс ПНШ Диск
Конспекты уроков по математике 1 класс ПНШ Диск Числовые промежутки
Числовые промежутки Математическая смекалка
Математическая смекалка Математика дәресенә презентация
Математика дәресенә презентация Координатная плоскость 6 класс
Координатная плоскость 6 класс Интерактивная игра по математика Самый умный
Интерактивная игра по математика Самый умный Организация, планирование и управление железнодорожным строительством. Сетевое моделирование строительного производства
Организация, планирование и управление железнодорожным строительством. Сетевое моделирование строительного производства The discoveries of Pythagoras
The discoveries of Pythagoras Додавання і віднімання числа 5. Взаємозв'язок дій додавання і віднімання
Додавання і віднімання числа 5. Взаємозв'язок дій додавання і віднімання Асимптотические разложения. (Лекция 2)
Асимптотические разложения. (Лекция 2) Координатная плоскость
Координатная плоскость Різницеве порівняння чисел. Задачі. Урок №60
Різницеве порівняння чисел. Задачі. Урок №60 Решение задач на применение аксиом стереометрии и их следствий. Урок 3
Решение задач на применение аксиом стереометрии и их следствий. Урок 3 Построение сечений многогранников
Построение сечений многогранников Первые уроки школьной отметки
Первые уроки школьной отметки Приём вычитания вида 12 -
Приём вычитания вида 12 - Параллельный перенос. Поворот и симметрия. Самостоятельная работа. 9 класс
Параллельный перенос. Поворот и симметрия. Самостоятельная работа. 9 класс Игра Математик - бизнесмен. 10-11 классы
Игра Математик - бизнесмен. 10-11 классы Урок математики.Задачи на движение
Урок математики.Задачи на движение Использование технологии дифференцированного обучения на уроке математики в малокомплектной школе
Использование технологии дифференцированного обучения на уроке математики в малокомплектной школе Тренажер по таблице умножения и деления
Тренажер по таблице умножения и деления Неопределённый интеграл. Метод подстановки (замены переменной)
Неопределённый интеграл. Метод подстановки (замены переменной) Тренажер Сложение и вычитание с переходом через разряд 2 класс
Тренажер Сложение и вычитание с переходом через разряд 2 класс Геометрический смысл производной. Уравнение касательной. 11 класс
Геометрический смысл производной. Уравнение касательной. 11 класс Вивчаємо арифметичні дії множення і ділення; табличне множення та ділення
Вивчаємо арифметичні дії множення і ділення; табличне множення та ділення Открытый банк заданий ОГЭ на подобие треугольников
Открытый банк заданий ОГЭ на подобие треугольников Презентация к уроку математики по теме Обратные задачи
Презентация к уроку математики по теме Обратные задачи Combinatorics. Permutations. Combinations. The binomial theorem
Combinatorics. Permutations. Combinations. The binomial theorem