- Анализ данных. Статистические характеристики (Лекция 11)

Содержание
- 2. Статистические характеристики Далеко не всегда среднее арифметическое хорошо описывает переменную. Часто оно скорее затуманивает оценку, чем
- 3. Статистические характеристики Медиана - возможное значение признака, которое делит ранжированную совокупность на две равные части: 50
- 4. Статистические характеристики В случае использования среднего значения для оценки генерального среднего указывается величина дисперсии, стандартного отклонения
- 5. Стандартизация показателей Чаще всего значения доверительного интервала имеют различную размерность и для адекватного сравнения со средним
- 6. Интервальное оценивание Поскольку данные, полученные в результате измерения, носят статистический характер необходимо оценить интервал, в которые
- 7. Взаимосвязь переменных В задачи исследования часто входит не только измерение величин, но выявление и измерение взаимосвязи
- 8. Анализ взаимосвязи переменных Лекция 12 Звоновский, к.с.н.
- 9. Взаимосвязь переменных Основная задача анализа данных, собранных в результате количественного социологического или маркетингового исследования состоит в
- 10. Анализ сопряженности
- 11. Коэффициенты связи для номинальных переменных Зависимость – это отсутствие независимости. Два события считаются независимыми, если вероятность
- 12. Коэффициент Χ² χ² = ∑ (О – Е)² ∕ Е
- 13. Χ² - распределение Если значение Х равно 5, то вероятность, что наблюдаемые и ожидаемые частоты значимо
- 14. Ограничения X² Коэффициент Х² будет иметь распределение Х² лишь в случае, если ожидаемые частоты в таблице
- 15. Коэффициент X² по Пирсону Пирсон уточнил коэффициент Х² Достоинства коэффициент Пирсона: растет вместе с Х² меняется
- 16. Коэффициент Крамера Более удобным является коэффициент Крамера K – наименьшее из чисел (r,c), где r -
- 17. Коэффициент, основанные на прогнозе Эта группа коэффициентов основана на идее Гутмана: Насколько улучшится наш прогноз ответа
- 18. Коэффициент, основанные на прогнозе ошибка при первом прогнозе – ошибка при втором прогнозе ошибка при первом
- 19. Коэффициент, основанные на прогнозе ошибка при первом прогнозе – ошибка при втором прогнозе ошибка при первом
- 20. Коэффициенты для порядковых шкал Критерии наличия связи между порядковыми шкалами основаны на количестве нарушений порядка (инверсий).
- 21. Коэффициенты для порядковых шкал В случае, если между переменной А и В, коэффициент Гудмена-Краскала больше, чем
- 22. Коэффициенты для метрических шкал В случае, когда обе переменные измерены по метрическим шкалам, появляется возможность использовать
- 23. Сравнение средних Лекция 13 Звоновский, к.с.н.
- 24. Анализ средних Задача сравнения средних значений (means) возникает в случаях, когда необходимо убедиться в том, что
- 25. Анализ средних Для определения значимости различий средних значений в группах необходимо провести проверку t-тест, или тест
- 26. Анализ средних Случай двух независимых выборок. Одна выборка не зависит от другой в том случае, если
- 27. Анализ средних Случай одной выборки. Необходимо сравнить выборочное значение параметра с каким-то либо внешним параметром, чаще
- 28. Анализ средних Случай двух зависимых выборок. Зависимые выборки – выборки, где выпадение элементов одной выборки влияет
- 29. Анализ средних Сформулировать Hₒ и H‚ Выбрать подходящую статистику Выбрать уровень значимости Собрать данные и рассчитать
- 30. Непараметрические тесты Все рассмотренные выше случаи касались параметрических тестов. Параметрические тесты – тесты, основанные на допущении,
- 31. Непараметрические тесты
- 32. Непараметрические тесты Для определения, какому закону распределения подчиняется данная переменная, используется тест Колмогорова-Смирнова. Чаще всего, тест
- 33. Дисперсионный анализ Лекция 14 Звоновский, к.с.н.
- 34. Дисперсионный анализ (ANOVA) В случаях, когда необходимо сравнить не одну, а несколько средних, используют анализ вариаций,
- 35. Одномерный дисперсионный анализ В дисперсионном анализе важно различать зависимые и независимые переменные. Независимая – переменная, которая
- 36. Одномерный дисперсионный анализ Основная идея анализа состоит в разделении дисперсии на дисперсию, вносимую независимыми переменными (межгрупповую)
- 37. Одномерный дисперсионный анализ Дисперсионный анализ разделяет дисперсию на дисперсию, вносимую независимыми переменными (межгрупповую) и дисперсию (внутригрупповую),
- 38. Одномерный дисперсионный анализ хij - оценка i-ого респондента из j-ой группы μ - средняя оценка по
- 39. Одномерный дисперсионный анализ В результате теста на статистически значимые различия зависимой переменной мы получаем доказательство лишь
- 41. Скачать презентацию

Статистические характеристики
Далеко не всегда среднее арифметическое хорошо описывает переменную. Часто оно
Статистические характеристики
Далеко не всегда среднее арифметическое хорошо описывает переменную. Часто оно

Статистические характеристики
Медиана - возможное значение признака, которое делит ранжированную совокупность на
Статистические характеристики
Медиана - возможное значение признака, которое делит ранжированную совокупность на

Статистические характеристики
В случае использования среднего значения для оценки генерального среднего указывается
Статистические характеристики
В случае использования среднего значения для оценки генерального среднего указывается

Стандартизация показателей
Чаще всего значения доверительного интервала имеют различную размерность и для
Стандартизация показателей
Чаще всего значения доверительного интервала имеют различную размерность и для

Интервальное оценивание
Поскольку данные, полученные в результате измерения, носят статистический характер необходимо
Интервальное оценивание
Поскольку данные, полученные в результате измерения, носят статистический характер необходимо
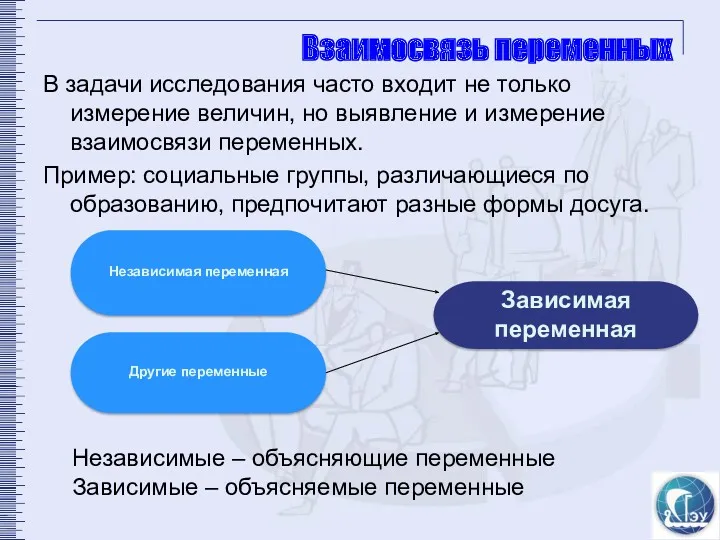
Взаимосвязь переменных
В задачи исследования часто входит не только измерение величин, но
Взаимосвязь переменных
В задачи исследования часто входит не только измерение величин, но

Анализ взаимосвязи переменных
Лекция 12
Звоновский, к.с.н.
Анализ взаимосвязи переменных
Лекция 12
Звоновский, к.с.н.

Взаимосвязь переменных
Основная задача анализа данных, собранных в результате количественного социологического или
Взаимосвязь переменных
Основная задача анализа данных, собранных в результате количественного социологического или
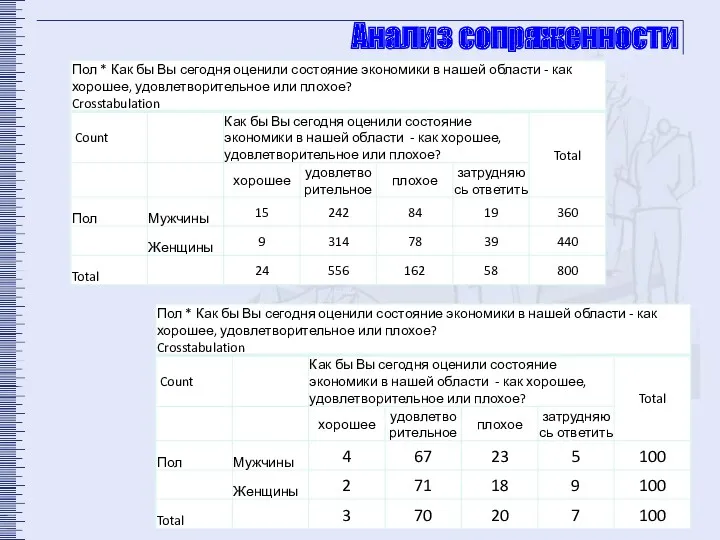
Анализ сопряженности
Анализ сопряженности

Коэффициенты связи для
номинальных переменных
Зависимость – это отсутствие независимости.
Два события считаются
Коэффициенты связи для
номинальных переменных
Зависимость – это отсутствие независимости.
Два события считаются
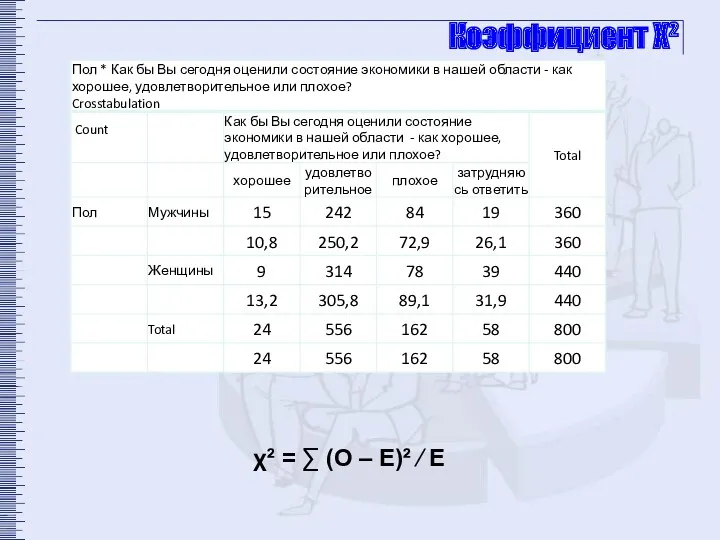
Коэффициент Χ²
χ² = ∑ (О – Е)² ∕ Е
Коэффициент Χ²
χ² = ∑ (О – Е)² ∕ Е
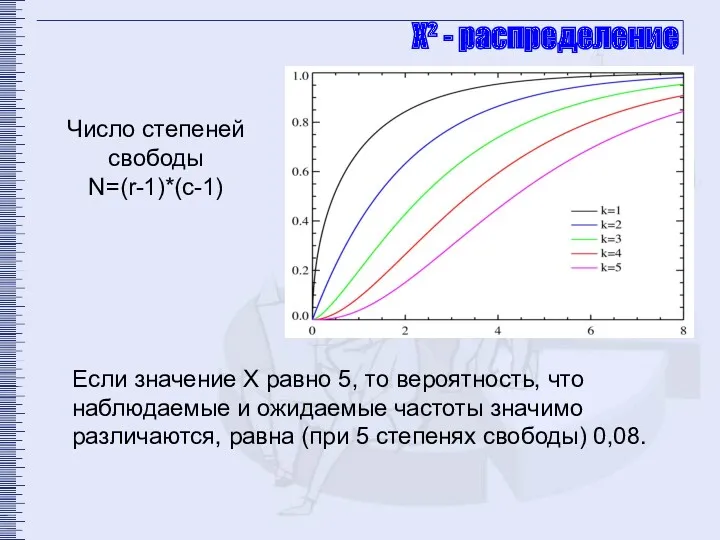
Χ² - распределение
Если значение Х равно 5, то вероятность, что наблюдаемые
Χ² - распределение
Если значение Х равно 5, то вероятность, что наблюдаемые

Ограничения X²
Коэффициент Х² будет иметь распределение Х² лишь в случае, если
Ограничения X²
Коэффициент Х² будет иметь распределение Х² лишь в случае, если

Коэффициент X² по Пирсону
Пирсон уточнил коэффициент Х²
Достоинства коэффициент Пирсона:
растет вместе
Коэффициент X² по Пирсону
Пирсон уточнил коэффициент Х²
Достоинства коэффициент Пирсона:
растет вместе

Коэффициент Крамера
Более удобным является коэффициент Крамера
K – наименьшее из чисел (r,c),
Коэффициент Крамера
Более удобным является коэффициент Крамера
K – наименьшее из чисел (r,c),

Коэффициент, основанные на прогнозе
Эта группа коэффициентов основана на идее Гутмана:
Насколько улучшится
Коэффициент, основанные на прогнозе
Эта группа коэффициентов основана на идее Гутмана:
Насколько улучшится

Коэффициент, основанные на прогнозе
ошибка при первом прогнозе – ошибка при втором
Коэффициент, основанные на прогнозе
ошибка при первом прогнозе – ошибка при втором

Коэффициент, основанные на прогнозе
ошибка при первом прогнозе – ошибка при втором
Коэффициент, основанные на прогнозе
ошибка при первом прогнозе – ошибка при втором

Коэффициенты для порядковых шкал
Критерии наличия связи между порядковыми шкалами основаны на
Коэффициенты для порядковых шкал
Критерии наличия связи между порядковыми шкалами основаны на

Коэффициенты для порядковых шкал
В случае, если между переменной А и В,
Коэффициенты для порядковых шкал
В случае, если между переменной А и В,
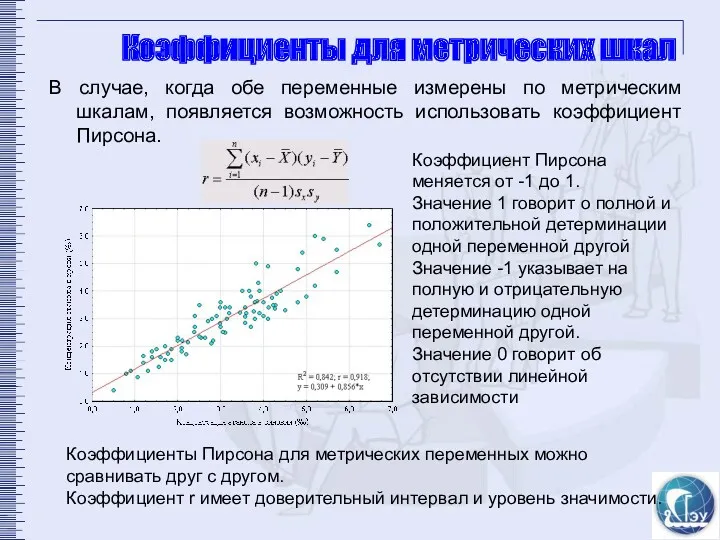
Коэффициенты для метрических шкал
В случае, когда обе переменные измерены по метрическим
Коэффициенты для метрических шкал
В случае, когда обе переменные измерены по метрическим

Сравнение средних
Лекция 13
Звоновский, к.с.н.
Сравнение средних
Лекция 13
Звоновский, к.с.н.

Анализ средних
Задача сравнения средних значений (means) возникает в случаях, когда необходимо
Анализ средних
Задача сравнения средних значений (means) возникает в случаях, когда необходимо
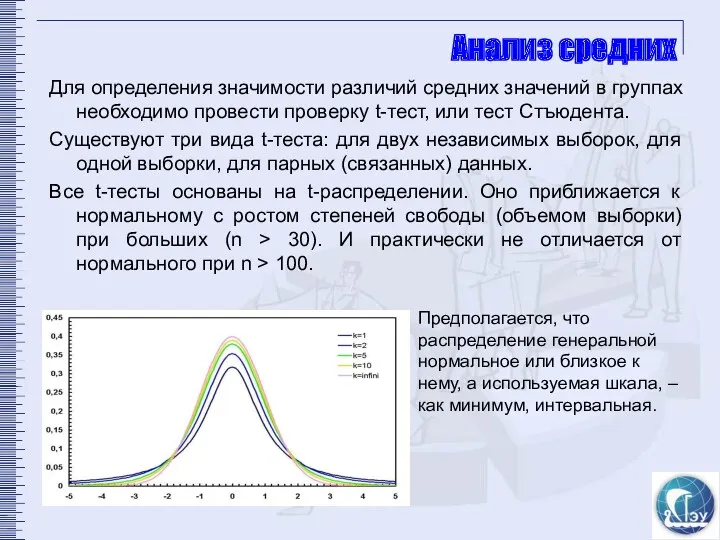
Анализ средних
Для определения значимости различий средних значений в группах необходимо провести
Анализ средних
Для определения значимости различий средних значений в группах необходимо провести

Анализ средних
Случай двух независимых выборок. Одна выборка не зависит от другой
Анализ средних
Случай двух независимых выборок. Одна выборка не зависит от другой

Анализ средних
Случай одной выборки. Необходимо сравнить выборочное значение параметра с каким-то
Анализ средних
Случай одной выборки. Необходимо сравнить выборочное значение параметра с каким-то

Анализ средних
Случай двух зависимых выборок. Зависимые выборки – выборки, где выпадение
Анализ средних
Случай двух зависимых выборок. Зависимые выборки – выборки, где выпадение
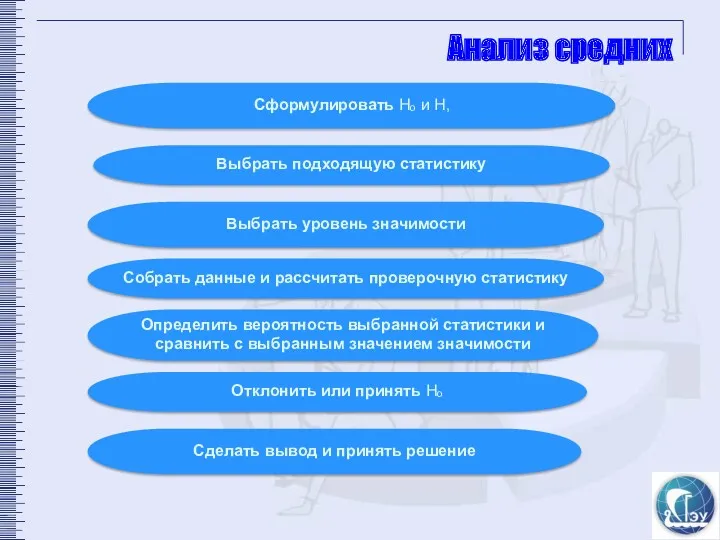
Анализ средних
Сформулировать Hₒ и H‚
Выбрать подходящую статистику
Выбрать уровень значимости
Собрать данные
Анализ средних
Сформулировать Hₒ и H‚
Выбрать подходящую статистику
Выбрать уровень значимости
Собрать данные

Непараметрические тесты
Все рассмотренные выше случаи касались параметрических тестов.
Параметрические тесты –
Непараметрические тесты
Все рассмотренные выше случаи касались параметрических тестов.
Параметрические тесты –

Непараметрические тесты
Непараметрические тесты

Непараметрические тесты
Для определения, какому закону распределения подчиняется данная переменная, используется тест
Непараметрические тесты
Для определения, какому закону распределения подчиняется данная переменная, используется тест

Дисперсионный анализ
Лекция 14
Звоновский, к.с.н.
Дисперсионный анализ
Лекция 14
Звоновский, к.с.н.

Дисперсионный анализ (ANOVA)
В случаях, когда необходимо сравнить не одну, а несколько
Дисперсионный анализ (ANOVA)
В случаях, когда необходимо сравнить не одну, а несколько

Одномерный дисперсионный анализ
В дисперсионном анализе важно различать зависимые и независимые переменные.
Независимая
Одномерный дисперсионный анализ
В дисперсионном анализе важно различать зависимые и независимые переменные.
Независимая

Одномерный дисперсионный анализ
Основная идея анализа состоит в разделении дисперсии на дисперсию,
Одномерный дисперсионный анализ
Основная идея анализа состоит в разделении дисперсии на дисперсию,

Одномерный дисперсионный анализ
Дисперсионный анализ разделяет дисперсию на дисперсию, вносимую независимыми переменными
Одномерный дисперсионный анализ
Дисперсионный анализ разделяет дисперсию на дисперсию, вносимую независимыми переменными
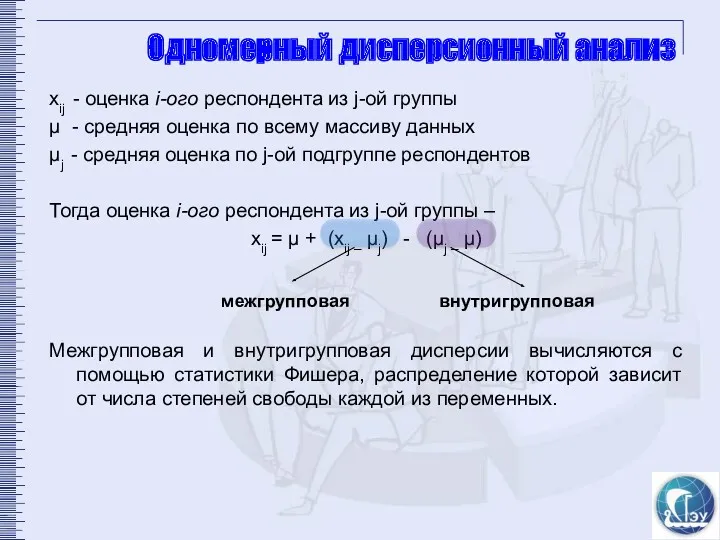
Одномерный дисперсионный анализ
хij - оценка i-ого респондента из j-ой группы
μ -
Одномерный дисперсионный анализ
хij - оценка i-ого респондента из j-ой группы
μ -

Одномерный дисперсионный анализ
В результате теста на статистически значимые различия зависимой переменной
Одномерный дисперсионный анализ
В результате теста на статистически значимые различия зависимой переменной
 Познание. Знание
Познание. Знание Весенняя неделя добра 2021 в республике Марий Эл
Весенняя неделя добра 2021 в республике Марий Эл Гражданская активность МОУ СШ с. Хмелевка, Ульяновской области. Участие в акциях РДШ
Гражданская активность МОУ СШ с. Хмелевка, Ульяновской области. Участие в акциях РДШ Брак и семья
Брак и семья Социоэкономический фактор в трансформации жизненного сценария человека
Социоэкономический фактор в трансформации жизненного сценария человека Презентация Законотворчество в РФ .
Презентация Законотворчество в РФ . ВКР: Разработка мероприятий по совершенствованию работы с обращениями граждан в думе города Костромы
ВКР: Разработка мероприятий по совершенствованию работы с обращениями граждан в думе города Костромы Организация и социальные группы как объект управления
Организация и социальные группы как объект управления Методика и техника социологических исследований
Методика и техника социологических исследований The average statistical portrait of a Belarusian pensioner
The average statistical portrait of a Belarusian pensioner Международный день пожилых людей. Помоги ближнему
Международный день пожилых людей. Помоги ближнему Семейная политика в Италии
Семейная политика в Италии АНО Время возможностей. Как вступить в организацию
АНО Время возможностей. Как вступить в организацию Доклад Интерактивные технологии
Доклад Интерактивные технологии Новые формы массовой работы в печати и на радио в 20-30 годы XX века. Листки РКИ
Новые формы массовой работы в печати и на радио в 20-30 годы XX века. Листки РКИ Окно Овертона - пример с дикими собаками
Окно Овертона - пример с дикими собаками Социальный проект Компьютер для всех поколений
Социальный проект Компьютер для всех поколений Молодежное движение
Молодежное движение Социальный проект Семья - будущее России
Социальный проект Семья - будущее России Управление целевыми программами в муниципальном образовании в решении проблем обеспечения жильем. г. Саров
Управление целевыми программами в муниципальном образовании в решении проблем обеспечения жильем. г. Саров Студенческий совет ИОН
Студенческий совет ИОН Гражданские активисты – лидеры Ульяновской области
Гражданские активисты – лидеры Ульяновской области Обществознание
Обществознание Презентация к уроку Роль права в жизни человека, общества и государства. 9 класс. Обществознание.
Презентация к уроку Роль права в жизни человека, общества и государства. 9 класс. Обществознание. Порядок предоставления Фондом социального страхования Российской Федерации государственных услуг
Порядок предоставления Фондом социального страхования Российской Федерации государственных услуг Урок обществознания в 8 классе по теме Образование
Урок обществознания в 8 классе по теме Образование Основные направления деятельности профсоюзной организации. Организация работы профкома
Основные направления деятельности профсоюзной организации. Организация работы профкома Громадська організація Спілка жінок Херсонщини
Громадська організація Спілка жінок Херсонщини