- Подготовка собранных данных к анализу. Лекция 10

Содержание
- 2. Основные используемые понятия После окончания полевых работ собранные данные никогда не находятся в виде, приемлемом для
- 3. Редактирование данных Полевое редактирование – редактирование, выполненное в отношении части собранных работ (собранных одним интервьюером, на
- 4. Редактирование данных Невыполнение всех или части требований по методу и правилам сбора всех или части данных
- 5. Обработка неудовлетворительных ответов
- 6. Кодирование открытых вопросов Кодирование открытых вопросов – присвоение кода, чаще всего, численного, для представления ответа на
- 7. Кодирование открытых вопросов
- 8. Кодирование переменных Кодирование переменной с единственным возможным численным значением – создание одного поля одного из цифровых
- 9. Кодировочная книга (codebook) Кодировальная книга – таблица соответствий между собранными данными и переменными электронного массива данных.
- 10. Кодировочная книга (codebook)
- 11. Перенос данных в электронный массив CAPI/CAWI/CATI Ввод с клавиатуры Цифровое сканирование (сканеры специальных кодов) Оптическое сканирование
- 12. Перенос данных в электронный массив Ввод с клавиатуры При переносе данных из бумажного вида в электронный
- 13. Распределения данных как контроль ввода Получение и обзор первичных таблиц линейного (частотного) распределения значений измеряемых переменных
- 14. Перекрестные таблицы Перекрестный анализ первичных данных позволяет обнаружить наиболее заметные ошибки, возникшие при сборе данных
- 15. Проверка гипотез Нулевая (null) гипотеза – Hₒ - гипотеза о том, что полученные результаты не показывают
- 16. Проверка гипотез Варианты гипотез: Среднее количество кинотеатров, которые посещают жители города, составляет 3,0 Более 10% домохозяйств
- 17. Проверка гипотез Односторонний критерий (тест) – проверка нулевой гипотезы, когда альтернативная гипотеза выражена направленно. Например, мы
- 18. Проверка гипотез Предположим, что мы должны вывести на рынок новый бренд пива, в случае, если в
- 19. Перенос данных в электронный массив Сформулировать Hₒ и H‚ Выбрать подходящую статистику Выбрать уровень значимости Собрать
- 20. Проверка гипотез Выбор статистики – выбор способа измерения отклонения измеряемого значения от тестируемого уровня. Если тестируется
- 21. Проверка гипотез Выбор уровня значимости – это выбор при котором может произойти ошибка первого рода. Традиционно
- 23. Скачать презентацию

Основные используемые понятия
После окончания полевых работ собранные данные никогда не находятся
Основные используемые понятия
После окончания полевых работ собранные данные никогда не находятся

Редактирование данных
Полевое редактирование – редактирование, выполненное в отношении части собранных работ
Редактирование данных
Полевое редактирование – редактирование, выполненное в отношении части собранных работ

Редактирование данных
Невыполнение всех или части требований по методу и правилам сбора
Редактирование данных
Невыполнение всех или части требований по методу и правилам сбора
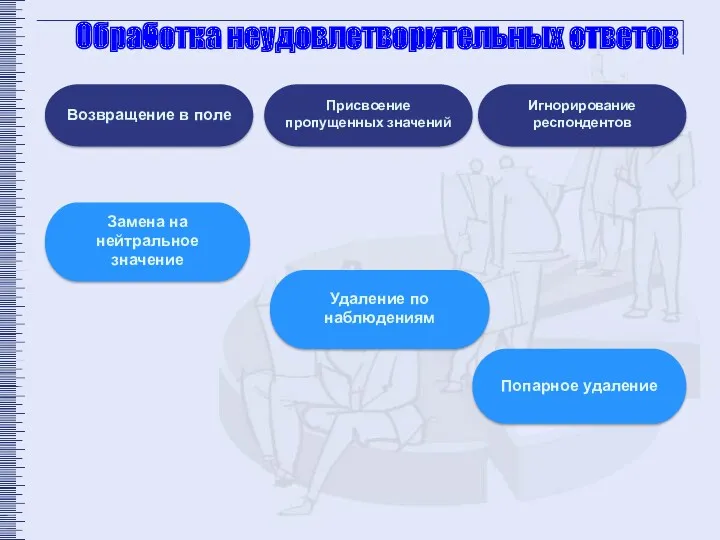
Обработка неудовлетворительных ответов
Обработка неудовлетворительных ответов

Кодирование открытых вопросов
Кодирование открытых вопросов – присвоение кода, чаще всего, численного,
Кодирование открытых вопросов
Кодирование открытых вопросов – присвоение кода, чаще всего, численного,

Кодирование открытых вопросов
Кодирование открытых вопросов

Кодирование переменных
Кодирование переменной с единственным возможным численным значением – создание одного
Кодирование переменных
Кодирование переменной с единственным возможным численным значением – создание одного

Кодировочная книга (codebook)
Кодировальная книга – таблица соответствий между собранными данными
Кодировочная книга (codebook)
Кодировальная книга – таблица соответствий между собранными данными

Кодировочная книга (codebook)
Кодировочная книга (codebook)
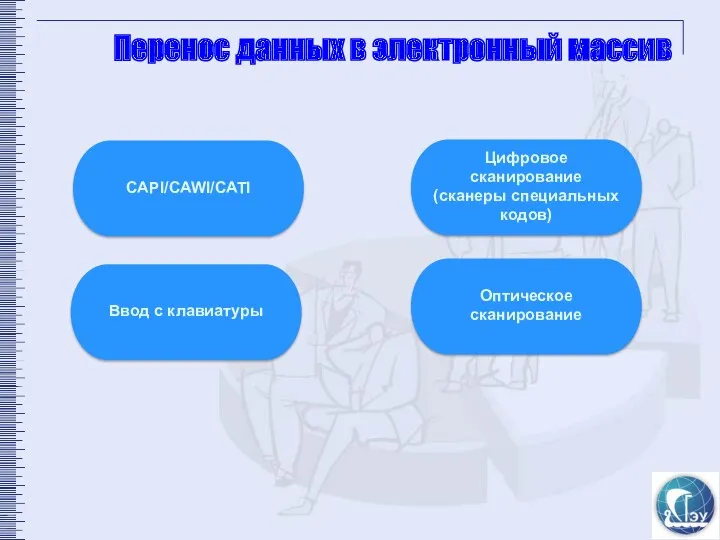
Перенос данных в электронный массив
CAPI/CAWI/CATI
Ввод с клавиатуры
Цифровое сканирование
(сканеры специальных кодов)
Оптическое сканирование
Перенос данных в электронный массив
CAPI/CAWI/CATI
Ввод с клавиатуры
Цифровое сканирование
(сканеры специальных кодов)
Оптическое сканирование

Перенос данных в электронный массив
Ввод с клавиатуры
При переносе данных из бумажного
Перенос данных в электронный массив
Ввод с клавиатуры
При переносе данных из бумажного

Распределения данных как контроль ввода
Получение и обзор первичных таблиц линейного (частотного)
Распределения данных как контроль ввода
Получение и обзор первичных таблиц линейного (частотного)
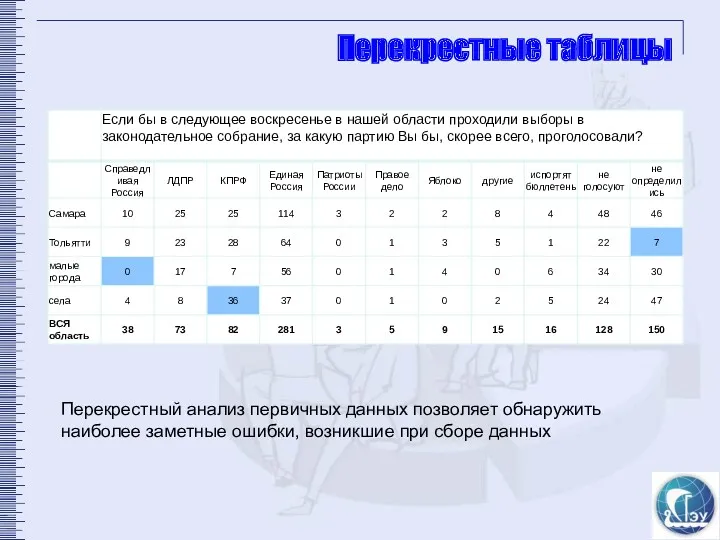
Перекрестные таблицы
Перекрестный анализ первичных данных позволяет обнаружить наиболее заметные ошибки, возникшие
Перекрестные таблицы
Перекрестный анализ первичных данных позволяет обнаружить наиболее заметные ошибки, возникшие

Проверка гипотез
Нулевая (null) гипотеза – Hₒ - гипотеза о том, что
Проверка гипотез
Нулевая (null) гипотеза – Hₒ - гипотеза о том, что

Проверка гипотез
Варианты гипотез:
Среднее количество кинотеатров, которые посещают жители города, составляет 3,0
Более
Проверка гипотез
Варианты гипотез:
Среднее количество кинотеатров, которые посещают жители города, составляет 3,0
Более

Проверка гипотез
Односторонний критерий (тест) – проверка нулевой гипотезы, когда альтернативная гипотеза
Проверка гипотез
Односторонний критерий (тест) – проверка нулевой гипотезы, когда альтернативная гипотеза

Проверка гипотез
Предположим, что мы должны вывести на рынок новый бренд пива,
Проверка гипотез
Предположим, что мы должны вывести на рынок новый бренд пива,
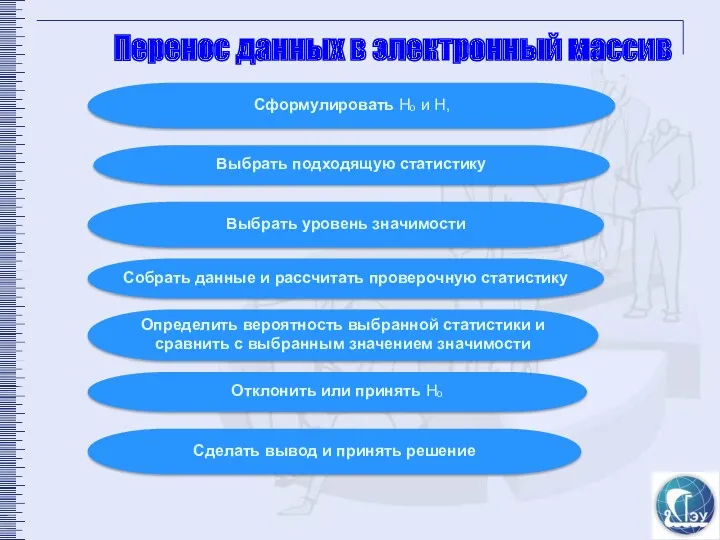
Перенос данных в электронный массив
Сформулировать Hₒ и H‚
Выбрать подходящую статистику
Выбрать
Перенос данных в электронный массив
Сформулировать Hₒ и H‚
Выбрать подходящую статистику
Выбрать

Проверка гипотез
Выбор статистики – выбор способа измерения отклонения измеряемого значения от
Проверка гипотез
Выбор статистики – выбор способа измерения отклонения измеряемого значения от

Проверка гипотез
Выбор уровня значимости – это выбор при котором может произойти
Проверка гипотез
Выбор уровня значимости – это выбор при котором может произойти
 Volunteers and Volunteering
Volunteers and Volunteering Поиск волонтеров
Поиск волонтеров Семья - социальный институт, базовая ячейка общества,
Семья - социальный институт, базовая ячейка общества,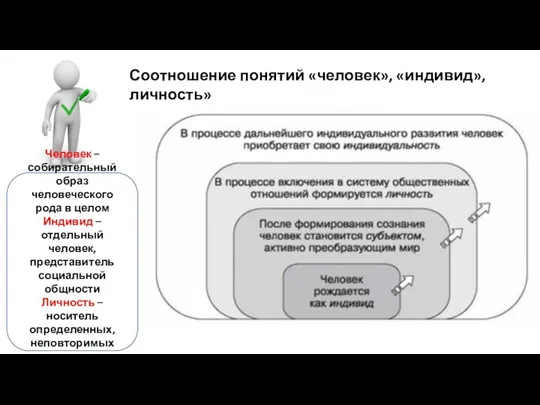 Соотношение понятий человек, индивид, личность
Соотношение понятий человек, индивид, личность Портфолио родительского комитета
Портфолио родительского комитета Молодежная субкультура готы
Молодежная субкультура готы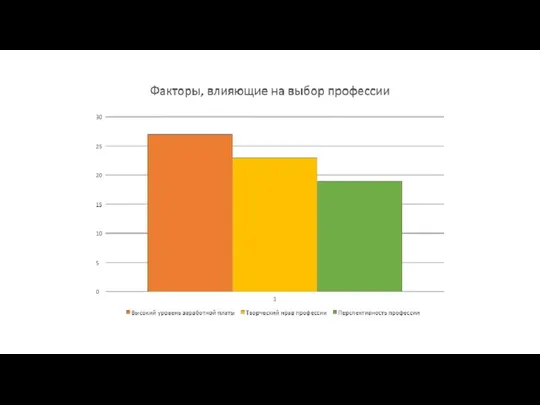 Факторы, влияющие на выбор профессии
Факторы, влияющие на выбор профессии 20 лет Конституции РФ
20 лет Конституции РФ Социальные ценности и нормы
Социальные ценности и нормы Человек в системе социальных связей
Человек в системе социальных связей Виновен - отвечай
Виновен - отвечай Студенческий художественный совет
Студенческий художественный совет Ана – өмірдің шуағы
Ана – өмірдің шуағы Летняя школа медиаторов школьных служб примирения Самарской области
Летняя школа медиаторов школьных служб примирения Самарской области Чебоксарский экономико-технологический колледж. Волонтерский центр
Чебоксарский экономико-технологический колледж. Волонтерский центр Командообразование
Командообразование Общество. Динамика общественного развития
Общество. Динамика общественного развития Регионы
Регионы Волонтерский центр САФУ на территории Архангельской области
Волонтерский центр САФУ на территории Архангельской области Манипулирование. Причины
Манипулирование. Причины Дуглас Норт. Институты, институциональные изменения и функционирование экономики
Дуглас Норт. Институты, институциональные изменения и функционирование экономики Әлеуметтану ғылымының қалыптасуы және даму тарихы
Әлеуметтану ғылымының қалыптасуы және даму тарихы Семья как социальный институт. Лекция 5
Семья как социальный институт. Лекция 5 Students organizations of MSU
Students organizations of MSU Цивилизационная концепция исторического развития
Цивилизационная концепция исторического развития Отбасы қоғамның кішігірім жүйесі ретінде
Отбасы қоғамның кішігірім жүйесі ретінде Публичный годовой отчет
Публичный годовой отчет Организация ученического самоуправления в классе под руководством школьной организации ЮСТ
Организация ученического самоуправления в классе под руководством школьной организации ЮСТ