- Схема научно-исследовательской работы регионоведа, проводящего эксперименты

Содержание
- 2. Исследование обычно начинается с некоторого предположения, требующего проверки с привлечением фактов. Это предположение — гипотеза —
- 3. Генеральная совокупность — это все множество объектов, в отношении которого формулируется исследовательская гипотеза. генеральная совокупность —
- 4. Выборочная совокупность (Выборка) — это ограниченная по численности группа объектов (испытуемых, респондентов), специальным образом отбираемая из
- 5. 1. сформулирована гипотеза 2. определены соответствующие генеральные совокупности 3. организация выборки. Свойства выборки Выборка должна обосновывать
- 6. 1.Репрезентативность выборки — или её представительность — это способность выборки представлять изучаемые явления достаточно полно, с
- 7. приёмы, позволяющие получить достаточную для исследователя репрезентативность выборки. А.Первый (основной) приём — это простой случайный (рандомизированный)
- 8. В Второй прием — стратифицированный случайный отбор, (отбор по свойствам генеральной совокупности) 1. предварительное определение тех
- 9. 2 Статистическая достоверность, или (статистическая значимость) результатов исследования определяется при помощи методов статистического вывода, которые предъявляют
- 10. Зависимые и независимые выборки. Обычна ситуация исследования, когда интересующее исследователя свойство изучается на двух или более
- 11. выделим две парадигмы исследования. R-методология предполагает изучение изменчивости некоторого свойства (поведенческого) под влиянием некоторого воздействия, фактора
- 12. следует различать объекты исследования (в это чаще всего люди, испытуемые) их свойства (то, что интересует исследователя,
- 13. Процесс присвоения количественных (числовых) значений, имеющейся у исследователя информации, называется кодированием. кодирование это такая операция, с
- 14. Измерение в терминах производимых исследователем операций — это приписывание объекту числа по определённому правилу. Это правило
- 15. ИЗМЕРИТЕЛЬНЫЕ ШКАЛЫ номинативная, номинальная или шкала наименований порядковая, ординарная или ранговая шкала, интервальная или шкала равных
- 16. НОМИНАТИВНАЯ ШКАЛА (ШКАЛА НАИМЕНОВАНИЙ) процедура измерения сводится к классификации свойств, группировке объектов, к объединению их в
- 17. Номинативная шкала (не метрическая), или шкала наименований (номинальное измерение). В основе лежит процедура, обычно не ассоциируемая
- 18. Ранговая, или порядковая шкала (не метрическая) (как результат ранжирования). измерение в этой шкале предполагает приписывание объектам
- 19. Интервальная шкала (метрическая). измерение, при котором числа отражают насколько больше или меньше выражено свойство. Равным разностям
- 20. шкала отношений (метрическая, абсолютная шкала). Измерение в этой шкале отличается от интервального только тем, что в
- 21. шкалы полезно характеризовать по признаку их дифференцирующей способности (мощности). шкалы по мере возрастания мощности располагаются следующим
- 22. Измерения, осуществляемые с помощью двух первых шкал, считаются качественными, а осуществляемые с помощью двух последних шкал
- 23. ТАБЛИЦЫ И ГРАФИКИ ТАБЛИЦА ИСХОДНЫХ ДАННЫХ
- 24. Обычно в ходе исследования интересующий исследователя признак измеряется не у одного-двух, а у множества объектов (испытуемых).
- 25. Процесс присвоения количественных (числовых) значений, имеющейся у исследователя информации, называется кодированием Иными словами — кодирование это
- 26. ТАБЛИЦЫ И ГРАФИКИ РАСПРЕДЕЛЕНИЯ ЧАСТОТ Как правило, анализ данных начинается с изучения того, как часто встречаются
- 27. Ещё одной разновидностью таблиц распределения являются таблицы распределения накопленных частот. Они показывают, как накапливаются частоты по
- 28. Гистограмма распределения частот — это столбиковая диаграмма, каждый столбец которой опирается на конкретное значение признака или
- 29. Гистограмма накопленных частот отличается от гистограммы распределения тем, что высота каждого столбика пропорциональна частоте, накопленной к
- 30. Построение полигона распределения частот напоминает построение гистограммы. В гистограмме вершина каждого столбца, соответствующая частоте встречаемости данного
- 31. Вместо гистограммы или полигона часто изображают сглаженную кривую распределения частот сглаженная кривая распределения частот.
- 32. Таблицы и графики распределения частот дают важную предварительную информацию о форме распределения признака: о том, какие
- 33. Таблицы и графики распределения признака позволяют делать некоторые содержательные выводы при сравнении групп испытуемых между собой.
- 34. ТАБЛИЦЫ СОПРЯЖЕННОСТИ НОМИНАТИВНЫХ ПРИЗНАКОВ Таблицы сопряжённости, или кросстабуляции — это таблицы совместного распределения частот двух и
- 35. ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
- 36. К первичным описательным статистикам (Descriptive Statistics) обычно относят числовые характеристики распределения измеренного на выборке признака. Каждая
- 37. МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
- 38. Мера центральной тенденции (Central Tendency) — это число, характеризующее выборку по уровню выраженности измеренного признака. Существуют
- 39. Мода (Mode) — это значение из множества измерений, которое встречается наиболее часто. Моде, или модальному интервалу
- 40. Медиана (Median) — это значение признака, которое делит упорядоченное (ранжированное) множество данных пополам так, что одна
- 41. Далее медиана определяется следующим образом: - если данные содержат нечётное число значений (8, 9, 10, 13,
- 42. Среднее {Mean) (Мх— выборочное среднее, среднее арифметическое) —сумма всех значений измеренного признака, делённая на количество суммированных
- 43. Свойства среднего Если к каждому значению переменной прибавить одно и то же число с, то среднее
- 44. отклонение от среднего: (хi — Мх). Из первого, очевидного свойства среднего следует одно важное свойство: сумма
- 45. ВЫБОР МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ Каждая мера центральной тенденции обладает характеристиками, которые делают её ценной в определённых
- 46. Наиболее очевидной и часто используемой мерой центральной тенденции является среднее значение. Но его использование ограничивается тем,
- 47. На величину моды и медианы величина каждого отдельного значения не влияет. Например, если в группе из
- 48. Меры центральной тенденции чаще всего используются для сравнения групп по уровню выраженности признака. какую меру использовать?
- 49. Помимо мер центральной тенденции широко используются меры положения, которые называются квантилями распределения
- 50. Квантиль — это точка на числовой оси измеренного признака, которая делит всю совокупность упорядоченных измерений на
- 51. Процентили (Percentiles) — это 99 точек — значений признака (Р1, ..., Р99), которые делят упорядоченное (по
- 52. Квартили (Quartiles) — это 3 точки — значения признака (Р25, Р50, Р75), которые делят упорядоченное (по
- 53. МЕРЫ ИЗМЕНЧИВОСТИ Меры центральной тенденции отражают уровень выраженности измеренного признака. Однако не менее важной характеристикой является
- 54. Наиболее простой и очевидной мерой изменчивости является размах, указывающий на диапазон изменчивости значений. Размах (Range) —
- 55. Чем больше изменчивость в данных, тем больше отклонения значений от среднего, тем больше величина дисперсии. Величина
- 56. для метрических данных используется дисперсия — величина, название которой в науке является синонимом изменчивости. Дисперсия (Variance)
- 57. Стандартное отклонение (Std. deviation) (сигма, среднеква-дратическое отклонение) — положительное значение квадратного корня из дисперсии: (На практике
- 58. Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида относительно среднего значения. Если исходные
- 59. Эксцесс (Kurtosis) — мера плосковершинности или остроконечности графика распределения измеренного признака. Если исходные данные переведены в
- 60. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
- 61. Нормальный закон распределения играет важнейшую роль в применении численных методов в психологии. Он лежит в основе
- 63. График распределения вероятностей выпадения «орлов» в игре с 10 подбрасываниями монеты и кривая нормального распределения (*)
- 64. Семейство нормальных кривых, 1-е распределение отличается от 2-го стандартным отклонением (σ1 Каждому психологическому ( биологическому) свойству
- 65. Все многообразие нормальных распределений может быть сведено к одной кривой, если применить z-преобразование ко всем возможным
- 66. Рассмотрим важные свойства стандартного нормального распределения Единицей измерения единичного нормального распределения является стандартное отклонение. Кривая приближается
- 67. любое нормальное распределение может быть сведено к единичному нормальному распределению путем z-преобразования. Таким образом: если xi
- 68. РАЗРАБОТКА ТЕСТОВЫХ ШКАЛ Тестовые шкалы разрабатываются для того, чтобы оценить индивидуальный результат тестирования путём сопоставления его
- 69. Существует множество стандартных тестовых шкал, основное назначение которых — представление индивидуальных результатов тестирования в удобном для
- 70. ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
- 71. Для проверки нормальности используются различные процедуры, позволяющие выяснить, отличается ли от нормального выборочное распределение измеренной переменной.
- 72. Наиболее весомым аргументом в пользу того, что признак измерен в метрической шкале, является соответствие выборочного распределения
- 73. Графический способ (Q-Q Plots, Р-Р Plots). Строят либо квантильные графики, либо графики накопленных частот. Квантильные графики
- 74. Критерии асимметрии и эксцесса. Эти критерии определяют допустимую степень отклонения эмпирических значений асимметрии и эксцесса от
- 75. Статистический критерий нормальности Колмогорова-Смирнова считается наиболее состоятельным для определения степени соответствия эмпирического распределения нормальному. Он позволяет
- 76. Последствия отклонения от нормальности. Следует отметить, что задача получения эмпирического распределения, строго соответствующего нормальному закону, нечасто
- 77. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
- 78. основные одномерные описательные статистики — меры центральной тенденции и изменчивости, которые применяются для описания одной переменной.
- 79. ПРИМЕРЫ Приведем два примера исследования влияния демонстрации сцен насилия по ТВ на агрессивность подростков. 1. Изучается
- 80. ПОНЯТИЕ КОРРЕЛЯЦИИ Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически изображаются в виде
- 81. . Примеры графиков часто встречающихся функций Примеры диаграмм рассеивания и соответствующих коэффициентов корреляции
- 82. Коэффициент корреляции — это количественная мера силы и направления вероятностной взаимосвязи двух переменных; принимает значения в
- 83. КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ г-ПИРСОНА r-Пирсона (Pearson г) применяется для изучения взаимосвязи двух метрических переменных, измеренных на одной
- 84. ПРИМЕР В таблице приведен пример исходных данных измерения двух показателей интеллекта (вербального и невербального) у 20
- 96. Скачать презентацию

Исследование обычно начинается с некоторого предположения, требующего проверки с привлечением фактов.
Исследование обычно начинается с некоторого предположения, требующего проверки с привлечением фактов.

Генеральная совокупность — это все множество объектов, в отношении которого формулируется
Генеральная совокупность — это все множество объектов, в отношении которого формулируется

Выборочная совокупность (Выборка) — это ограниченная по численности группа объектов (испытуемых,
Выборочная совокупность (Выборка) — это ограниченная по численности группа объектов (испытуемых,

1. сформулирована гипотеза
2. определены соответствующие генеральные совокупности
3. организация выборки.
Свойства выборки
1. сформулирована гипотеза
2. определены соответствующие генеральные совокупности
3. организация выборки.
Свойства выборки

1.Репрезентативность выборки — или её представительность — это способность выборки представлять
1.Репрезентативность выборки — или её представительность — это способность выборки представлять

приёмы, позволяющие получить достаточную для исследователя репрезентативность выборки.
А.Первый (основной) приём —
приёмы, позволяющие получить достаточную для исследователя репрезентативность выборки.
А.Первый (основной) приём —

В Второй прием — стратифицированный случайный отбор, (отбор по свойствам генеральной
В Второй прием — стратифицированный случайный отбор, (отбор по свойствам генеральной

2 Статистическая достоверность, или (статистическая значимость) результатов исследования определяется при помощи
2 Статистическая достоверность, или (статистическая значимость) результатов исследования определяется при помощи

Зависимые и независимые выборки.
Обычна ситуация исследования, когда интересующее исследователя свойство
Зависимые и независимые выборки.
Обычна ситуация исследования, когда интересующее исследователя свойство

выделим две парадигмы исследования.
R-методология предполагает изучение изменчивости некоторого свойства (поведенческого)
выделим две парадигмы исследования.
R-методология предполагает изучение изменчивости некоторого свойства (поведенческого)

следует различать
объекты исследования (в это чаще всего люди, испытуемые)
их
следует различать
объекты исследования (в это чаще всего люди, испытуемые)
их

Процесс присвоения количественных (числовых) значений, имеющейся у исследователя информации, называется кодированием.
Процесс присвоения количественных (числовых) значений, имеющейся у исследователя информации, называется кодированием.

Измерение в терминах производимых исследователем операций — это приписывание объекту числа
Измерение в терминах производимых исследователем операций — это приписывание объекту числа

ИЗМЕРИТЕЛЬНЫЕ ШКАЛЫ
номинативная, номинальная или шкала наименований
порядковая, ординарная или ранговая шкала,
ИЗМЕРИТЕЛЬНЫЕ ШКАЛЫ
номинативная, номинальная или шкала наименований
порядковая, ординарная или ранговая шкала,

НОМИНАТИВНАЯ ШКАЛА (ШКАЛА НАИМЕНОВАНИЙ)
процедура измерения сводится к классификации свойств, группировке объектов,
НОМИНАТИВНАЯ ШКАЛА (ШКАЛА НАИМЕНОВАНИЙ)
процедура измерения сводится к классификации свойств, группировке объектов,

Номинативная шкала (не метрическая), или шкала наименований (номинальное измерение).
В основе
Номинативная шкала (не метрическая), или шкала наименований (номинальное измерение).
В основе

Ранговая, или порядковая шкала (не метрическая) (как результат ранжирования).
измерение
Ранговая, или порядковая шкала (не метрическая) (как результат ранжирования).
измерение

Интервальная шкала (метрическая).
измерение, при котором числа отражают насколько больше
Интервальная шкала (метрическая).
измерение, при котором числа отражают насколько больше

шкала отношений (метрическая, абсолютная шкала).
Измерение в этой шкале отличается от
шкала отношений (метрическая, абсолютная шкала).
Измерение в этой шкале отличается от

шкалы полезно характеризовать по признаку их дифференцирующей способности (мощности).
шкалы
шкалы полезно характеризовать по признаку их дифференцирующей способности (мощности).
шкалы

Измерения, осуществляемые с помощью двух первых шкал, считаются качественными, а осуществляемые
Измерения, осуществляемые с помощью двух первых шкал, считаются качественными, а осуществляемые

ТАБЛИЦЫ И ГРАФИКИ
ТАБЛИЦА ИСХОДНЫХ ДАННЫХ
ТАБЛИЦЫ И ГРАФИКИ
ТАБЛИЦА ИСХОДНЫХ ДАННЫХ

Обычно в ходе исследования интересующий исследователя признак измеряется не у одного-двух,
Обычно в ходе исследования интересующий исследователя признак измеряется не у одного-двух,

Процесс присвоения количественных (числовых) значений, имеющейся у исследователя информации, называется кодированием
Процесс присвоения количественных (числовых) значений, имеющейся у исследователя информации, называется кодированием

ТАБЛИЦЫ И ГРАФИКИ РАСПРЕДЕЛЕНИЯ ЧАСТОТ
Как правило, анализ данных начинается с изучения
ТАБЛИЦЫ И ГРАФИКИ РАСПРЕДЕЛЕНИЯ ЧАСТОТ
Как правило, анализ данных начинается с изучения

Ещё одной разновидностью таблиц распределения являются таблицы распределения накопленных частот.
Они
Ещё одной разновидностью таблиц распределения являются таблицы распределения накопленных частот.
Они
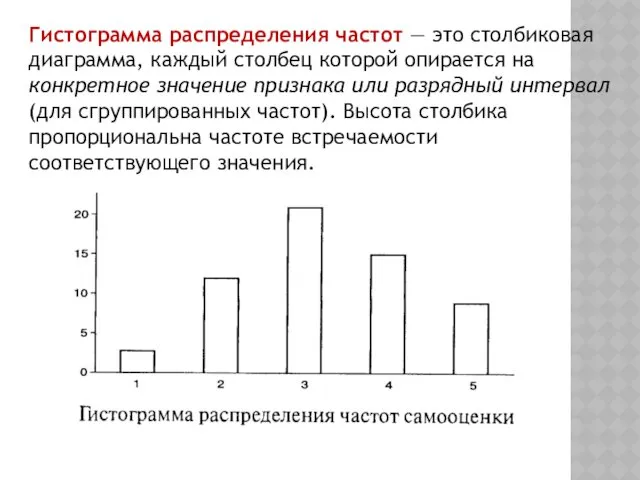
Гистограмма распределения частот — это столбиковая диаграмма, каждый столбец которой опирается
Гистограмма распределения частот — это столбиковая диаграмма, каждый столбец которой опирается
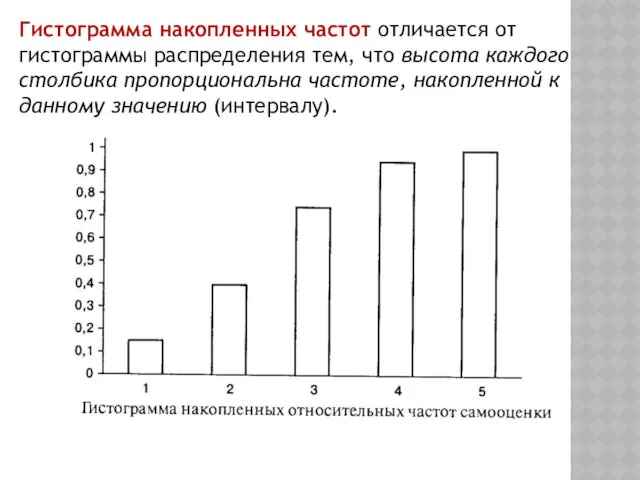
Гистограмма накопленных частот отличается от гистограммы распределения тем, что высота каждого
Гистограмма накопленных частот отличается от гистограммы распределения тем, что высота каждого
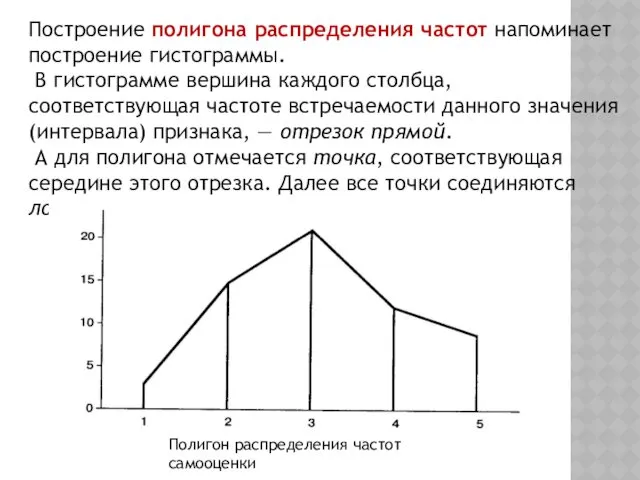
Построение полигона распределения частот напоминает построение гистограммы.
В гистограмме вершина каждого
Построение полигона распределения частот напоминает построение гистограммы.
В гистограмме вершина каждого
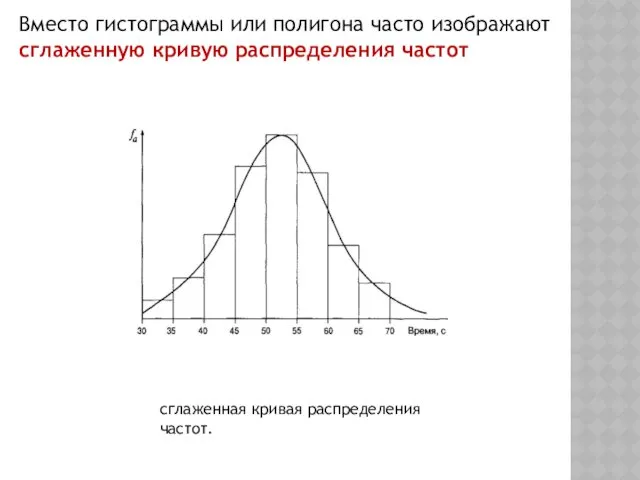
Вместо гистограммы или полигона часто изображают сглаженную кривую распределения частот
сглаженная кривая
Вместо гистограммы или полигона часто изображают сглаженную кривую распределения частот
сглаженная кривая

Таблицы и графики распределения частот дают важную предварительную информацию о форме
Таблицы и графики распределения частот дают важную предварительную информацию о форме

Таблицы и графики распределения признака позволяют делать некоторые содержательные выводы при
Таблицы и графики распределения признака позволяют делать некоторые содержательные выводы при

ТАБЛИЦЫ СОПРЯЖЕННОСТИ НОМИНАТИВНЫХ ПРИЗНАКОВ
Таблицы сопряжённости, или кросстабуляции — это таблицы совместного
ТАБЛИЦЫ СОПРЯЖЕННОСТИ НОМИНАТИВНЫХ ПРИЗНАКОВ
Таблицы сопряжённости, или кросстабуляции — это таблицы совместного

ПЕРВИЧНЫЕ
ОПИСАТЕЛЬНЫЕ
СТАТИСТИКИ
ПЕРВИЧНЫЕ
ОПИСАТЕЛЬНЫЕ
СТАТИСТИКИ

К первичным описательным статистикам (Descriptive Statistics) обычно относят числовые характеристики распределения
К первичным описательным статистикам (Descriptive Statistics) обычно относят числовые характеристики распределения

МЕРЫ
ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
МЕРЫ
ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ

Мера центральной тенденции (Central Tendency) —
это число, характеризующее выборку по
это число, характеризующее выборку по

Мода (Mode) — это значение из множества измерений, которое встречается наиболее
Мода (Mode) — это значение из множества измерений, которое встречается наиболее

Медиана (Median) — это значение признака, которое делит упорядоченное (ранжированное) множество
Медиана (Median) — это значение признака, которое делит упорядоченное (ранжированное) множество

Далее медиана определяется следующим образом:
- если данные содержат нечётное число значений
Далее медиана определяется следующим образом:
- если данные содержат нечётное число значений

Среднее {Mean) (Мх— выборочное среднее, среднее арифметическое) —сумма всех значений измеренного
Среднее {Mean) (Мх— выборочное среднее, среднее арифметическое) —сумма всех значений измеренного

Свойства среднего
Если к каждому значению переменной прибавить одно и то же
Свойства среднего
Если к каждому значению переменной прибавить одно и то же

отклонение от среднего: (хi — Мх).
Из первого, очевидного свойства среднего
отклонение от среднего: (хi — Мх).
Из первого, очевидного свойства среднего

ВЫБОР МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
Каждая мера центральной тенденции обладает характеристиками, которые делают
ВЫБОР МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
Каждая мера центральной тенденции обладает характеристиками, которые делают

Наиболее очевидной и часто используемой мерой центральной тенденции является среднее значение.
Наиболее очевидной и часто используемой мерой центральной тенденции является среднее значение.

На величину моды и медианы величина каждого отдельного значения не влияет.
На величину моды и медианы величина каждого отдельного значения не влияет.

Меры центральной тенденции чаще всего используются для сравнения групп по уровню
Меры центральной тенденции чаще всего используются для сравнения групп по уровню

Помимо мер центральной тенденции широко используются меры положения, которые называются
квантилями
Помимо мер центральной тенденции широко используются меры положения, которые называются
квантилями

Квантиль — это точка на числовой оси измеренного признака, которая делит

Процентили (Percentiles) — это 99 точек — значений признака (Р1, ...,
Процентили (Percentiles) — это 99 точек — значений признака (Р1, ...,

Квартили (Quartiles) — это 3 точки — значения признака (Р25, Р50,
Квартили (Quartiles) — это 3 точки — значения признака (Р25, Р50,

МЕРЫ ИЗМЕНЧИВОСТИ
Меры центральной тенденции отражают уровень выраженности измеренного признака.
Однако не
МЕРЫ ИЗМЕНЧИВОСТИ
Меры центральной тенденции отражают уровень выраженности измеренного признака.
Однако не

Наиболее простой и очевидной мерой изменчивости является размах, указывающий на диапазон
Наиболее простой и очевидной мерой изменчивости является размах, указывающий на диапазон

Чем больше изменчивость в данных, тем больше отклонения значений от
Чем больше изменчивость в данных, тем больше отклонения значений от

для метрических данных используется
дисперсия — величина, название которой
в науке
для метрических данных используется
дисперсия — величина, название которой
в науке

Стандартное отклонение (Std. deviation) (сигма, среднеква-дратическое отклонение) — положительное значение квадратного
Стандартное отклонение (Std. deviation) (сигма, среднеква-дратическое отклонение) — положительное значение квадратного
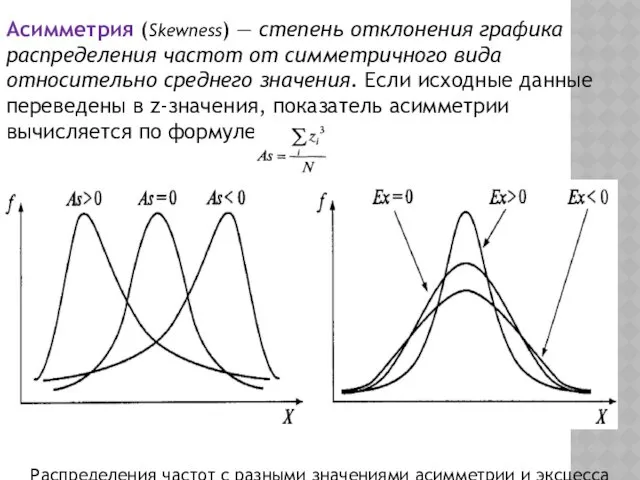
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида

Эксцесс (Kurtosis) — мера плосковершинности или остроконечности графика распределения измеренного признака.
Эксцесс (Kurtosis) — мера плосковершинности или остроконечности графика распределения измеренного признака.

НОРМАЛЬНЫЙ ЗАКОН
РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ

Нормальный закон распределения играет важнейшую роль в применении численных методов в
Нормальный закон распределения играет важнейшую роль в применении численных методов в
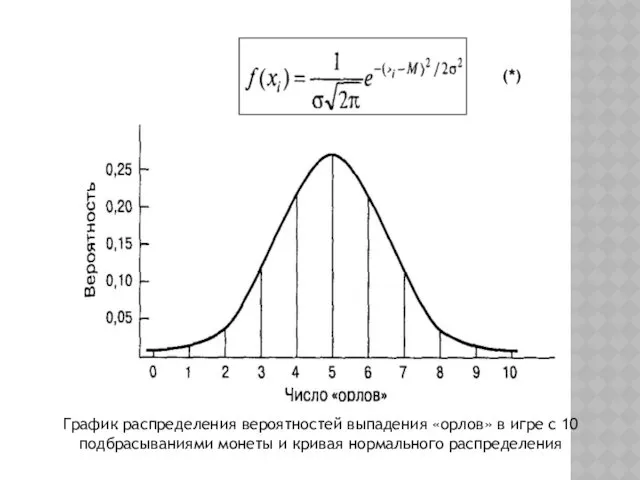
График распределения вероятностей выпадения «орлов» в игре с 10 подбрасываниями монеты
График распределения вероятностей выпадения «орлов» в игре с 10 подбрасываниями монеты

Семейство нормальных кривых, 1-е распределение отличается от 2-го стандартным отклонением
Семейство нормальных кривых, 1-е распределение отличается от 2-го стандартным отклонением
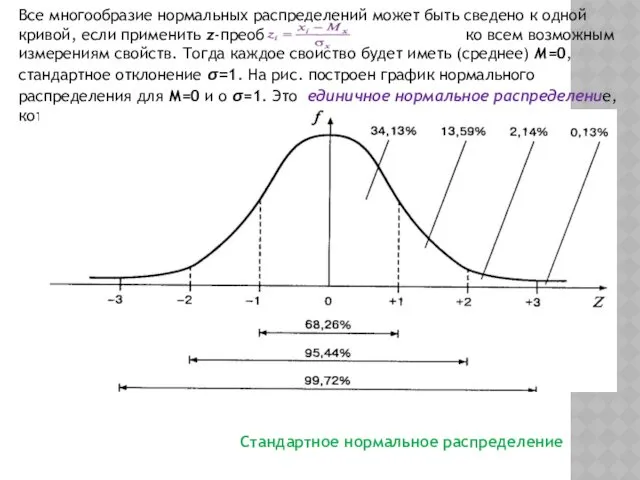
Все многообразие нормальных распределений может быть сведено к одной кривой, если
Все многообразие нормальных распределений может быть сведено к одной кривой, если

Рассмотрим важные свойства стандартного нормального распределения
Единицей измерения единичного нормального распределения является
Рассмотрим важные свойства стандартного нормального распределения
Единицей измерения единичного нормального распределения является

любое нормальное распределение может быть сведено к единичному нормальному распределению путем
любое нормальное распределение может быть сведено к единичному нормальному распределению путем

РАЗРАБОТКА ТЕСТОВЫХ ШКАЛ
Тестовые шкалы разрабатываются для того, чтобы оценить индивидуальный результат
РАЗРАБОТКА ТЕСТОВЫХ ШКАЛ
Тестовые шкалы разрабатываются для того, чтобы оценить индивидуальный результат
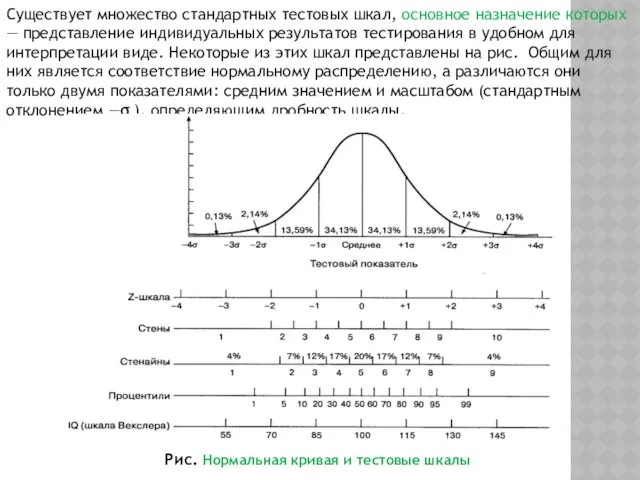
Существует множество стандартных тестовых шкал, основное назначение которых — представление индивидуальных
Существует множество стандартных тестовых шкал, основное назначение которых — представление индивидуальных

ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ

Для проверки нормальности используются различные процедуры, позволяющие выяснить, отличается ли от
Для проверки нормальности используются различные процедуры, позволяющие выяснить, отличается ли от

Наиболее весомым аргументом в пользу того, что признак измерен в метрической
Наиболее весомым аргументом в пользу того, что признак измерен в метрической

Графический способ (Q-Q Plots, Р-Р Plots).
Строят либо квантильные графики, либо графики
Графический способ (Q-Q Plots, Р-Р Plots).
Строят либо квантильные графики, либо графики

Критерии асимметрии и эксцесса.
Эти критерии определяют допустимую степень отклонения эмпирических
Критерии асимметрии и эксцесса.
Эти критерии определяют допустимую степень отклонения эмпирических

Статистический критерий нормальности
Колмогорова-Смирнова
считается наиболее состоятельным для определения степени соответствия
Статистический критерий нормальности
Колмогорова-Смирнова
считается наиболее состоятельным для определения степени соответствия

Последствия отклонения от нормальности.
Следует отметить, что задача получения эмпирического распределения,
Последствия отклонения от нормальности.
Следует отметить, что задача получения эмпирического распределения,

КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ

основные одномерные описательные статистики — меры центральной тенденции и изменчивости, которые
основные одномерные описательные статистики — меры центральной тенденции и изменчивости, которые

ПРИМЕРЫ
Приведем два примера исследования влияния демонстрации сцен насилия по ТВ на
ПРИМЕРЫ
Приведем два примера исследования влияния демонстрации сцен насилия по ТВ на

ПОНЯТИЕ КОРРЕЛЯЦИИ
Взаимосвязи на языке математики обычно описываются при помощи функций, которые
ПОНЯТИЕ КОРРЕЛЯЦИИ
Взаимосвязи на языке математики обычно описываются при помощи функций, которые
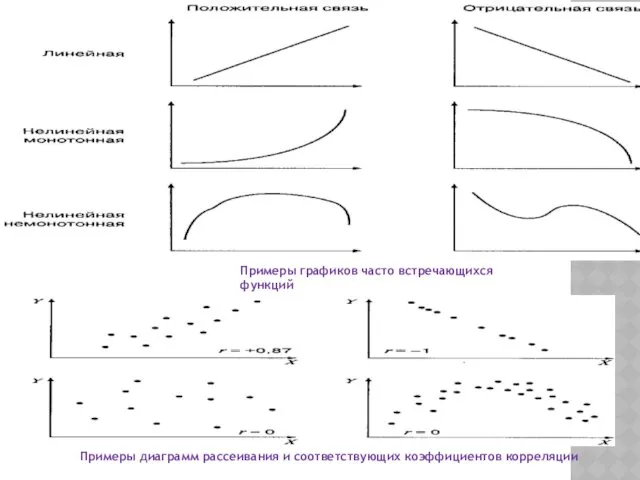
.
Примеры графиков часто встречающихся функций
Примеры диаграмм рассеивания и соответствующих коэффициентов корреляции
.
Примеры графиков часто встречающихся функций
Примеры диаграмм рассеивания и соответствующих коэффициентов корреляции

Коэффициент корреляции — это количественная мера силы и направления вероятностной взаимосвязи
Коэффициент корреляции — это количественная мера силы и направления вероятностной взаимосвязи

КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ г-ПИРСОНА
r-Пирсона (Pearson г) применяется для изучения взаимосвязи двух метрических
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ г-ПИРСОНА
r-Пирсона (Pearson г) применяется для изучения взаимосвязи двух метрических
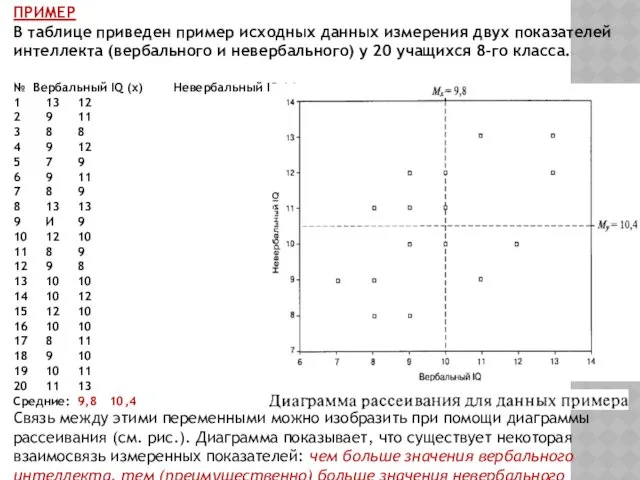
ПРИМЕР
В таблице приведен пример исходных данных измерения двух показателей интеллекта
ПРИМЕР
В таблице приведен пример исходных данных измерения двух показателей интеллекта










 презентация Потребности
презентация Потребности Социальная работа с родителями по социализации детей дошкольного возраста
Социальная работа с родителями по социализации детей дошкольного возраста Антисоциальные и криминальные молодежные группы
Антисоциальные и криминальные молодежные группы Центр Альтернатива насилию. О чем молчат женщины
Центр Альтернатива насилию. О чем молчат женщины Уровень жизни и динамика доходов населения РФ
Уровень жизни и динамика доходов населения РФ Социальная сфера жизни общества (тема 5.1 - 5.5)
Социальная сфера жизни общества (тема 5.1 - 5.5) Презентация по обществознанию Мораль как проявление культуры
Презентация по обществознанию Мораль как проявление культуры Цели, задачи и функции связей с общественностью в государственных органах и учреждениях
Цели, задачи и функции связей с общественностью в государственных органах и учреждениях Социальная структура и стратификация. Признаки и критерии стратификации
Социальная структура и стратификация. Признаки и критерии стратификации Региональный отборочный этап Национальных чемпионатов по профессиональному мастерству для людей с инвалидностью. (Модуль 4)
Региональный отборочный этап Национальных чемпионатов по профессиональному мастерству для людей с инвалидностью. (Модуль 4) Нұр отан партиясы Тұран филиалы Жас отан жастар қанатының 2017 жылдық есебі
Нұр отан партиясы Тұран филиалы Жас отан жастар қанатының 2017 жылдық есебі Молодежный сленг. Формирование, функционирование развитие
Молодежный сленг. Формирование, функционирование развитие Опросные методы как метод эмпирического исследования
Опросные методы как метод эмпирического исследования Теоретические основы корпоративной социальной ответственности. Лекция1
Теоретические основы корпоративной социальной ответственности. Лекция1 Comedy Radio
Comedy Radio План-конспект урока по теме: Подросток в группе
План-конспект урока по теме: Подросток в группе Проблемы познаваемости мира
Проблемы познаваемости мира Творите добрые дела. Волонтёрское движение
Творите добрые дела. Волонтёрское движение Профсоюзный комитет
Профсоюзный комитет Православная семья
Православная семья Migraţia forţei de muncă, cunoştinţe şi abilităţi
Migraţia forţei de muncă, cunoştinţe şi abilităţi Субкультура: аниме
Субкультура: аниме Мониторинг состояния действенности профильных организаций Ассоциации Военно-патриотических клубов ДОСААФ РФ
Мониторинг состояния действенности профильных организаций Ассоциации Военно-патриотических клубов ДОСААФ РФ Российское движение школьников, город Ростов-на-Дону
Российское движение школьников, город Ростов-на-Дону Гендерная дифференциация процесса общения
Гендерная дифференциация процесса общения Молодёжная субкультура Эмо
Молодёжная субкультура Эмо Разработка урока по обществознанию в 9 классе Правовые основы семьи и брака
Разработка урока по обществознанию в 9 классе Правовые основы семьи и брака Гендер в сучасному світі
Гендер в сучасному світі