- 4_Assotsiativnye_pravila

Содержание
- 2. Модели и задачи Data Mining Data Mining – совокупность большого числа различных методов обнаружения знаний. В
- 3. Модели и задачи Data Mining Описательная аналитика позволяет выполнить описание множества объектов в виде кластеров, правил,
- 4. Data Mining — это не один метод, а совокупность большого числа различных методов обнаружения знаний. Существует
- 5. Ассоциация Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из
- 6. Предметный набор — это непустое множество объектов, появившихся в одной транзакции. Транзакция — некоторое множество событий,
- 7. Формальная запись ассоциативных правил
- 8. Методы поиска ассоциативных правил Алгоритм AIS. Первый алгоритм, предложенный Agrawal, Imielinski and Swami сотрудниками IBM Almaden
- 9. Алгоритм Apriori Выявление частых наборов объектов — операция, требующая большого количества вычислений, а следовательно, и времени.
- 10. Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов. На i -м этапе определяются все часто
- 11. Разновидности алгоритма Apriori, являющиеся его оптимизацией, предложены для сокращения количества сканирований базы данных, количества наборов-кандидатов или
- 15. Ассоциативное правило состоит из двух наборов предметов, называемых условие и следствие, записываемых в виде X →
- 16. Поддержка ассоциативного правила S— это отношение числа транзакций, которые содержат как условие, так и следствие к
- 17. Достоверность ассоциативного правила A → B — это мера точности правила. Определяется как отношение количества транзакций,
- 18. При поиске ассоциативных правил используются дополнительные показатели, позволяющие оценить значимость правила. Можно выделить объективные и субъективные
- 19. Лифт (оригинальное название — интерес) вычисляется следующим образом: Лифт > 1 указывает, что условие и следствие
- 20. Другой мерой значимости правила, является левередж: Левередж — это разность между наблюдаемой частотой, с которой условие
- 21. Рассмотрим еще одну характеристику ассоциативного правила, которую можно считать мерой полезности. Она называется улучшением (improvement) и
- 22. Некоторые популярные меры: Полное доверие (англ. All-confidence) Коллективная мощь (англ. Collective strength) Убедительность (англ. Conviction) В
- 23. Выводы Задачей поиска ассоциативных правил является определение часто встречающихся наборов объектов в большом множестве наборов. Результаты
- 24. Задача поиска ассоциативных правил решается в два этапа: На первом выполняется поиск всех частых наборов объектов.
- 25. Интерпретация ассоциативных правил Все множество ассоциативных правил можно разделить на три вида: 1. Полезные правила –
- 27. Скачать презентацию

Модели и задачи Data Mining
Data Mining – совокупность большого числа различных
Модели и задачи Data Mining
Data Mining – совокупность большого числа различных

Модели и задачи Data Mining
Описательная аналитика позволяет выполнить описание множества объектов
Модели и задачи Data Mining
Описательная аналитика позволяет выполнить описание множества объектов

Data Mining — это не один метод, а совокупность большого числа
Data Mining — это не один метод, а совокупность большого числа

Ассоциация
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит
Ассоциация
Ассоциация – выявление закономерностей между связанными событиями. Примером такой закономерности служит

Предметный набор — это непустое множество объектов, появившихся в одной транзакции.
Транзакция
Предметный набор — это непустое множество объектов, появившихся в одной транзакции.
Транзакция

Формальная запись ассоциативных правил
Формальная запись ассоциативных правил

Методы поиска ассоциативных правил
Алгоритм AIS. Первый алгоритм, предложенный Agrawal, Imielinski and
Методы поиска ассоциативных правил
Алгоритм AIS. Первый алгоритм, предложенный Agrawal, Imielinski and

Алгоритм Apriori
Выявление частых наборов объектов — операция, требующая большого количества
Алгоритм Apriori
Выявление частых наборов объектов — операция, требующая большого количества

Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов. На i
Алгоритм Apriori определяет часто встречающиеся наборы за несколько этапов. На i

Разновидности алгоритма Apriori, являющиеся его оптимизацией, предложены для сокращения количества сканирований
Разновидности алгоритма Apriori, являющиеся его оптимизацией, предложены для сокращения количества сканирований

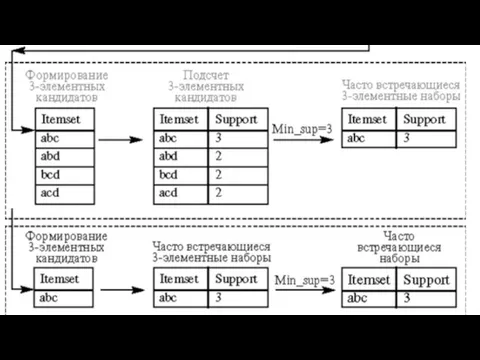


Ассоциативное правило состоит из двух наборов предметов, называемых условие и следствие,
Ассоциативное правило состоит из двух наборов предметов, называемых условие и следствие,

Поддержка ассоциативного правила S—
это отношение числа транзакций, которые содержат как
Поддержка ассоциативного правила S— это отношение числа транзакций, которые содержат как

Достоверность ассоциативного правила A → B — это мера точности правила.
Достоверность ассоциативного правила A → B — это мера точности правила.

При поиске ассоциативных правил используются дополнительные показатели, позволяющие оценить значимость правила.
При поиске ассоциативных правил используются дополнительные показатели, позволяющие оценить значимость правила.

Лифт (оригинальное название — интерес) вычисляется следующим образом:
Лифт > 1 указывает,
Лифт (оригинальное название — интерес) вычисляется следующим образом:
Лифт > 1 указывает,

Другой мерой значимости правила, является левередж:
Левередж — это разность между наблюдаемой
Другой мерой значимости правила, является левередж:
Левередж — это разность между наблюдаемой

Рассмотрим еще одну характеристику ассоциативного правила, которую можно считать мерой полезности.
Рассмотрим еще одну характеристику ассоциативного правила, которую можно считать мерой полезности.

Некоторые популярные меры:
Полное доверие (англ. All-confidence)
Коллективная мощь (англ. Collective strength)
Убедительность (англ.
Некоторые популярные меры:
Полное доверие (англ. All-confidence)
Коллективная мощь (англ. Collective strength)
Убедительность (англ.

Выводы
Задачей поиска ассоциативных правил является определение часто встречающихся наборов объектов в
Выводы
Задачей поиска ассоциативных правил является определение часто встречающихся наборов объектов в

Задача поиска ассоциативных правил решается в два этапа:
На первом выполняется
Задача поиска ассоциативных правил решается в два этапа:
На первом выполняется

Интерпретация ассоциативных правил
Все множество ассоциативных правил можно разделить на три вида:
1. Полезные
Интерпретация ассоциативных правил
Все множество ассоциативных правил можно разделить на три вида:
1. Полезные
 Разработка требований к зданиям и помещениям общеобразовательных организаций, с учетом перспектив развития системы образования
Разработка требований к зданиям и помещениям общеобразовательных организаций, с учетом перспектив развития системы образования Устройства внутренней памяти компьютера
Устройства внутренней памяти компьютера Экономический рост и развитие
Экономический рост и развитие Реконструкция и реставрация зданий и сооружений. (Тема 9)
Реконструкция и реставрация зданий и сооружений. (Тема 9) Профилактика табакокурения у подростков
Профилактика табакокурения у подростков Классный час Помним о Беслане
Классный час Помним о Беслане Проблемная группа Взаимодействие с семьей
Проблемная группа Взаимодействие с семьей Коррозия металлов
Коррозия металлов Книга Амоса. Суд и День Яхве
Книга Амоса. Суд и День Яхве Планирование работы библиотек на 2020 год
Планирование работы библиотек на 2020 год Отчёт об экспериментальной работе
Отчёт об экспериментальной работе исправлено
исправлено Подснежник
Подснежник Французская нефтегазовая компания Тоталь
Французская нефтегазовая компания Тоталь Group The Beatles
Group The Beatles Introduction to Mendeley
Introduction to Mendeley Снижение затрат при шлифовании изделий из массива древесины, шпонированных и лакокрасочных покрытий
Снижение затрат при шлифовании изделий из массива древесины, шпонированных и лакокрасочных покрытий Производственны зоны, размещение
Производственны зоны, размещение Молодой инженер
Молодой инженер Система учета переменных и полных затрат. (Лекция 7)
Система учета переменных и полных затрат. (Лекция 7) Теории происхождения искусства (ХIХ – ХХI вв.)
Теории происхождения искусства (ХIХ – ХХI вв.) Презентация Религия
Презентация Религия презентация ЮЖНАЯ ЕВРОПА
презентация ЮЖНАЯ ЕВРОПА Картотека сюжетно ролевых игр.
Картотека сюжетно ролевых игр. Клиническая физиология кислотно-щелочного равновесия
Клиническая физиология кислотно-щелочного равновесия Презентация :Обучение заучиванию стихотворений с помощью мнемотехники детей 4-5
Презентация :Обучение заучиванию стихотворений с помощью мнемотехники детей 4-5 Родной край - Кыштым
Родной край - Кыштым Движение поездов на дирекции. Схемы и графики. Подход поезда к станции
Движение поездов на дирекции. Схемы и графики. Подход поезда к станции