- БД_22_Лекция12

Содержание
- 2. Схема организации хешированного файла. Если число участков мало, то справочник участков может находиться в основной памяти.
- 3. Структура блока хешированного файла В каждом блоке предусмотрено место для размещения фиксированного числа записей. Если запись
- 4. Структура блока хешированного файла Иногда отводят ещё один бит (в заголовке или в записи) который показывает,
- 5. Организация поиска в хешированном файле Задача: найти запись с ключом v. (v– одно поле или список
- 6. Модификация в хешированном файле Задача: изменить одно или несколько полей записи с ключом v. Найти запись
- 7. Включение в хешированном файле Задача: добавить запись с ключом v. Найти запись с ключом v (вычисляется
- 8. Удаление в хешированном файле Задача: удаление записи с ключом v. Найти запись с ключом v. Если
- 9. Проблема реорганизации. Анализ временных характеристик хеширования Для каждой операции поиска, модификации, включения, удаления требуется: одно обращение
- 10. Проблема реорганизации. Анализ временных характеристик хеширования Для повышения скорости доступа, при росте числа блоков в участках,
- 11. Проблема реорганизации. Анализ временных характеристик хеширования Пусть по ключу v построим N=h(v) и N >>n– числа
- 12. Индексированные файлы Решается та же задача: поиск записи по ключу v. Допустим, что записи в файле
- 13. Индексированные файлы Аналогично организован доступ к файлу. Пусть мы имеем отсортированный файл с информацией, назовем его
- 14. Индексированные файлы Кроме того, необходима новая функция (вместо поиска): для данного ключа v1, найти такую запись
- 15. Индексированные файлы. Поиск в индексе. Требуется найти запись в основном файле с ключом v1. Задача (для
- 16. Индексированные файлы. Поиск в индексе. Лучшая стратегия поиска в файле индекса – использование двоичного поиска. При
- 17. Индексированные файлы. Поиск в индексе. Пример: Пусть в главном файле есть 106 записей. В блоке помещается
- 19. Скачать презентацию
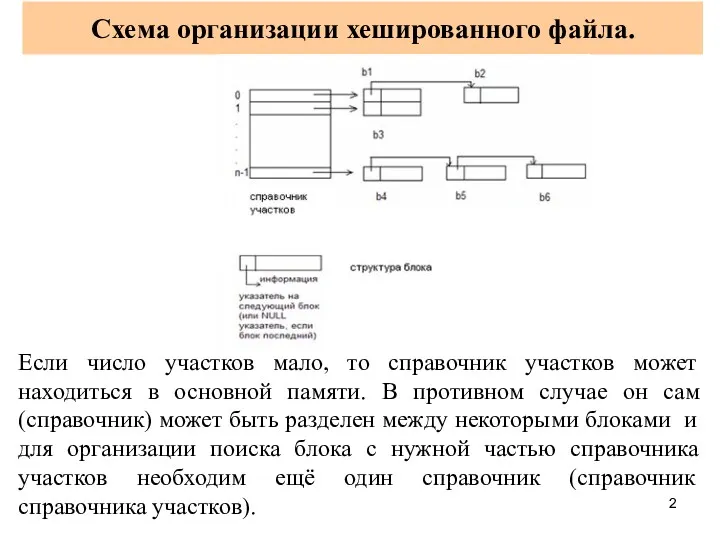
Схема организации хешированного файла.
Если число участков мало, то справочник участков может
Схема организации хешированного файла.
Если число участков мало, то справочник участков может

Структура блока хешированного файла
В каждом блоке предусмотрено место для размещения фиксированного
Структура блока хешированного файла
В каждом блоке предусмотрено место для размещения фиксированного

Структура блока хешированного файла
Иногда отводят ещё один бит (в заголовке или
Структура блока хешированного файла
Иногда отводят ещё один бит (в заголовке или

Организация поиска в хешированном файле
Задача: найти запись с ключом v. (v–
Организация поиска в хешированном файле
Задача: найти запись с ключом v. (v–

Модификация в хешированном файле
Задача: изменить одно или несколько полей записи с
Модификация в хешированном файле
Задача: изменить одно или несколько полей записи с

Включение в хешированном файле
Задача: добавить запись с ключом v.
Найти запись
Включение в хешированном файле
Задача: добавить запись с ключом v.
Найти запись

Удаление в хешированном файле
Задача: удаление записи с ключом v.
Найти запись с
Удаление в хешированном файле
Задача: удаление записи с ключом v.
Найти запись с

Проблема реорганизации. Анализ временных характеристик хеширования
Для каждой операции поиска, модификации, включения,
Проблема реорганизации. Анализ временных характеристик хеширования
Для каждой операции поиска, модификации, включения,

Проблема реорганизации. Анализ временных характеристик хеширования
Для повышения скорости доступа, при росте
Проблема реорганизации. Анализ временных характеристик хеширования
Для повышения скорости доступа, при росте

Проблема реорганизации. Анализ временных характеристик хеширования
Пусть по ключу v построим N=h(v)
Проблема реорганизации. Анализ временных характеристик хеширования
Пусть по ключу v построим N=h(v)

Индексированные файлы
Решается та же задача: поиск записи по ключу v.
Допустим, что
Индексированные файлы
Решается та же задача: поиск записи по ключу v.
Допустим, что

Индексированные файлы
Аналогично организован доступ к файлу. Пусть мы имеем отсортированный файл
Индексированные файлы
Аналогично организован доступ к файлу. Пусть мы имеем отсортированный файл

Индексированные файлы
Кроме того, необходима новая функция (вместо поиска): для данного ключа
Индексированные файлы
Кроме того, необходима новая функция (вместо поиска): для данного ключа

Индексированные файлы. Поиск в индексе.
Требуется найти запись в основном файле с
Индексированные файлы. Поиск в индексе.
Требуется найти запись в основном файле с

Индексированные файлы. Поиск в индексе.
Лучшая стратегия поиска в файле индекса –
Индексированные файлы. Поиск в индексе.
Лучшая стратегия поиска в файле индекса –

Индексированные файлы. Поиск в индексе.
Пример: Пусть в главном файле есть 106
Индексированные файлы. Поиск в индексе.
Пример: Пусть в главном файле есть 106
 действие моделирования
действие моделирования Металургія. Різновиди металургії
Металургія. Різновиди металургії Основные понятия и определения ОС. Классификация компьютерных систем
Основные понятия и определения ОС. Классификация компьютерных систем Зоряні системи - галактики
Зоряні системи - галактики ПОРТФОЛИО воспитателя 1 квалификационной категории Вахромеевой Г.В.
ПОРТФОЛИО воспитателя 1 квалификационной категории Вахромеевой Г.В. Использование логических устройств в вычислительной технике
Использование логических устройств в вычислительной технике Праздник - душа народа
Праздник - душа народа Презентация кружка по вокалу Солнечная капель
Презентация кружка по вокалу Солнечная капель Проект Свет моей Родины.
Проект Свет моей Родины. Памятники Челябинска
Памятники Челябинска Развитие речи детей в условиях семьи и детского сада
Развитие речи детей в условиях семьи и детского сада Аммиак, соли аммония
Аммиак, соли аммония Комплексные работы по оценке метапредметных достижений
Комплексные работы по оценке метапредметных достижений Culture of Kazakhstan
Culture of Kazakhstan Дискретное преобразование Фурье. Выделение дискретных гармоник сигнала
Дискретное преобразование Фурье. Выделение дискретных гармоник сигнала Книги посвященные проблемам выявления и развития личной одаренности
Книги посвященные проблемам выявления и развития личной одаренности Человек: информация и информационные процессы
Человек: информация и информационные процессы Золотая осень
Золотая осень Аффиксация как способ словообразования в языках мира
Аффиксация как способ словообразования в языках мира Смута. Хронологические рамки Смутного времени
Смута. Хронологические рамки Смутного времени Presentation Ti
Presentation Ti Теплоизоляционные материалы
Теплоизоляционные материалы Проект Семья Администрация Карагайского муниципального района МДОУ Савинский детский сад Проект: Семь Я
Проект Семья Администрация Карагайского муниципального района МДОУ Савинский детский сад Проект: Семь Я  Личность. Социализация
Личность. Социализация Город Владимир
Город Владимир Налоговая система РФ
Налоговая система РФ Использование ИКТ на уроках английского языка
Использование ИКТ на уроках английского языка Проект в младшей группе Я хочу играть!
Проект в младшей группе Я хочу играть!