- Биостатистика. Обзор данных

Содержание
- 2. Чем мы занимались на предыдущем занятии? Фактически теорией вероятностей! Мы вычисляли вероятность наблюдаемого расклада (комбинации событий)
- 3. Несколько обязательных общих понятий Статистика - это экспериментальный анализ случайных величин. Мы пытаемся судить о неизвестных
- 4. Обычно по результатам биологического эксперимента появляется некий Excel-файл Вносите все данные в одну электронную таблицу. Не
- 5. Познакомьтесь: наша учебная «база данных». Она будет использована для иллюстраций
- 6. Обзор данных: описательные статистики Среднее – основная характеристика «положения» случайной величины Дисперсия – основная характеристика разброса
- 7. Упражняемся… Чему равны средние оценки по физике и физкультуре? Для какого предмета дисперсия оценок выше? Средняя
- 8. Обзор данных: описательные статистики с помощью Excel В Excel есть встроенные функции описательных статистик: Кроме того
- 9. Обзор данных: описательные статистики с помощью WinStat Выбор одной или нескольких переменных
- 10. Обзор данных: смотрим характер распределений Всегда необходимо просматривать: … и частоты встречаемости для качественных признаков, например,
- 11. Обзор данных: смотрим характер распределений Всегда необходимо просматривать: С группировкой по номинальному признаку Упражняемся…
- 12. Ошибки средних и доверительные интервалы Выборочное среднее является величиной случайной! Стандартное отклонение этой случайной величины называется
- 13. Упражняемся… Чему равны стандартные отклонения и ошибки самих оценок (SD и SE)? Средняя оценка по физике
- 14. Упражняемся… Конечно вручную это никто не считает!
- 15. Боксы с усами (Box & Whisker) - еще один способ представления данных Медиана В боксе 50%
- 16. Оценки частот тоже имеют ошибки и доверительные интервалы Еще лучше WhatIs/CI/Proportion
- 17. Поговорим о нормальном распределении Это плотность распределения (кривая, огибающая гистограмму). Площадь под кривой равна вероятности попадания
- 18. Почему нормальное распределение встречается на каждом шагу? Например, биномиальный закон – это вероятность суммарного числа независимых
- 19. Гипотезы и статистики Статистический критерий – это правило, согласно которому принимается или отвергается гипотеза. Гипотеза –
- 20. α = 0.031 – вероятность ошибки I рода Гипотезы и статистики В данном случае мы умеем
- 21. Нулевая гипотеза – обычно предположение об отсутствии различий, например, 2 выборки взяты из одной генеральной совокупности
- 22. Н0 – беременности нет Вероятность упустить и вероятность обознаться Отвергнута правильная нулевая гипотеза. Сделано фальш-положительное открытие
- 23. От чего зависят ошибки статистических тестов? От объемов выборок Вероятность упустить и вероятность обознаться От размаха
- 24. Вероятность упустить и вероятность обознаться Караваджо (1573-1610). Фома Неверующий «Критерий» св. Фомы Неверующего (0033): всегда принимаем
- 25. Уменьшая ошибку I рода, увеличиваем ошибку II рода, т.е. теряем мощность теста (et converso) α vs.
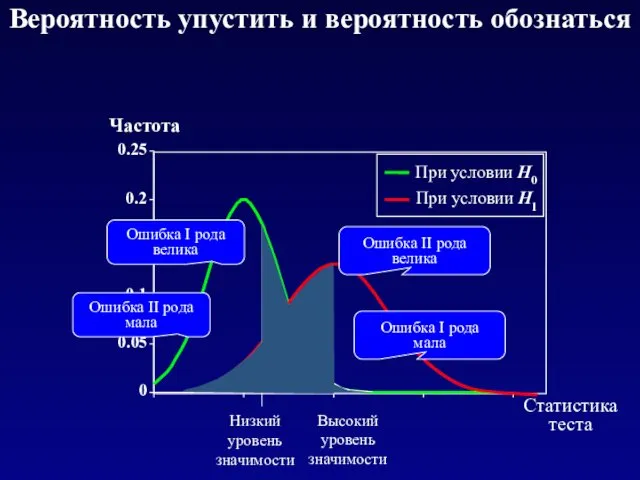
- 26. 0 0.05 0.1 0.15 0.2 0.25 Статистика теста Частота Высокий уровень значимости Низкий уровень значимости Вероятность
- 27. Мощность 80% считается приемлемой Вероятность упустить и вероятность обознаться Мощность теста = 1- β т.е. вероятность
- 29. Скачать презентацию

Чем мы занимались на предыдущем занятии?
Фактически теорией вероятностей!
Мы вычисляли
Чем мы занимались на предыдущем занятии?
Фактически теорией вероятностей!
Мы вычисляли

Несколько обязательных общих понятий
Статистика - это экспериментальный анализ случайных величин.
Несколько обязательных общих понятий
Статистика - это экспериментальный анализ случайных величин.

Обычно по результатам биологического эксперимента появляется некий Excel-файл
Вносите все данные
Обычно по результатам биологического эксперимента появляется некий Excel-файл
Вносите все данные
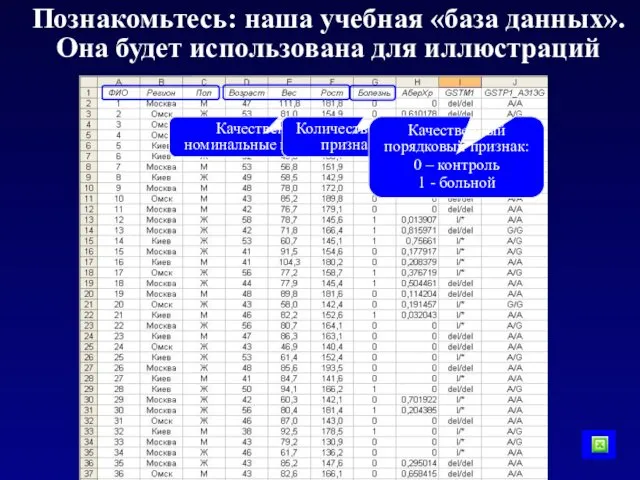
Познакомьтесь: наша учебная «база данных».
Она будет использована для иллюстраций
Познакомьтесь: наша учебная «база данных».
Она будет использована для иллюстраций

Обзор данных: описательные статистики
Среднее – основная характеристика «положения» случайной
Обзор данных: описательные статистики
Среднее – основная характеристика «положения» случайной

Упражняемся…
Чему равны средние оценки по физике и физкультуре?
Для
Упражняемся…
Чему равны средние оценки по физике и физкультуре?
Для
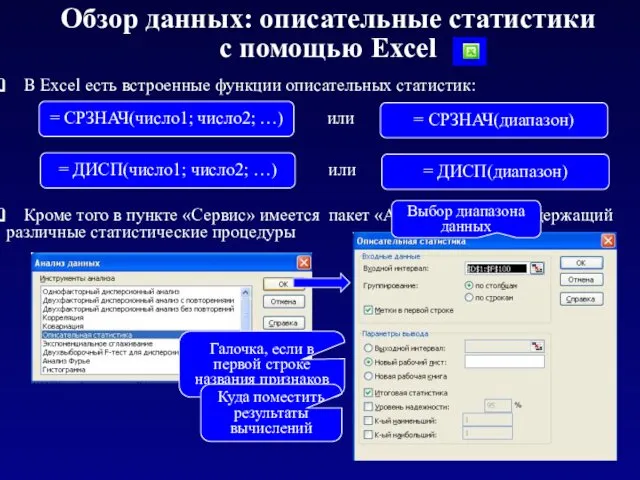
Обзор данных: описательные статистики
с помощью Excel
В Excel есть встроенные
Обзор данных: описательные статистики
с помощью Excel
В Excel есть встроенные
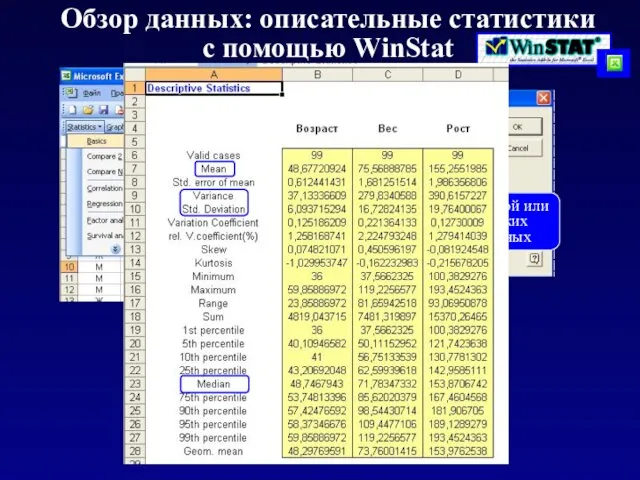
Обзор данных: описательные статистики
с помощью WinStat
Выбор одной или нескольких переменных
Обзор данных: описательные статистики
с помощью WinStat
Выбор одной или нескольких переменных

Обзор данных: смотрим характер распределений
Всегда необходимо просматривать:
… и
Обзор данных: смотрим характер распределений
Всегда необходимо просматривать:
… и
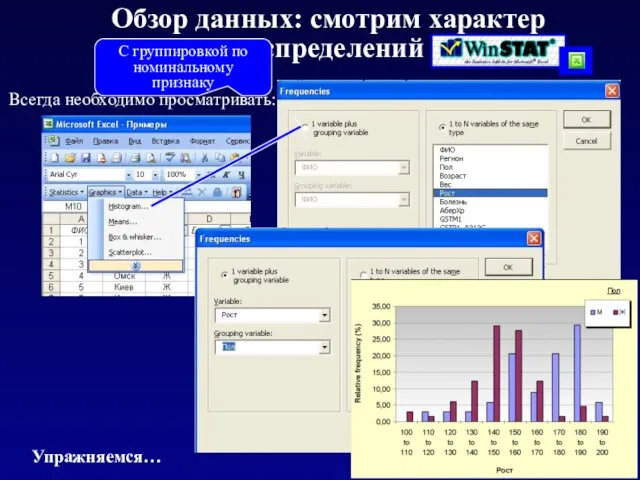
Обзор данных: смотрим характер распределений
Всегда необходимо просматривать:
С группировкой по
Обзор данных: смотрим характер распределений
Всегда необходимо просматривать:
С группировкой по

Ошибки средних и доверительные интервалы
Выборочное среднее является величиной случайной!
Стандартное отклонение
Ошибки средних и доверительные интервалы
Выборочное среднее является величиной случайной!
Стандартное отклонение

Упражняемся…
Чему равны стандартные отклонения и ошибки самих оценок (SD
Упражняемся…
Чему равны стандартные отклонения и ошибки самих оценок (SD
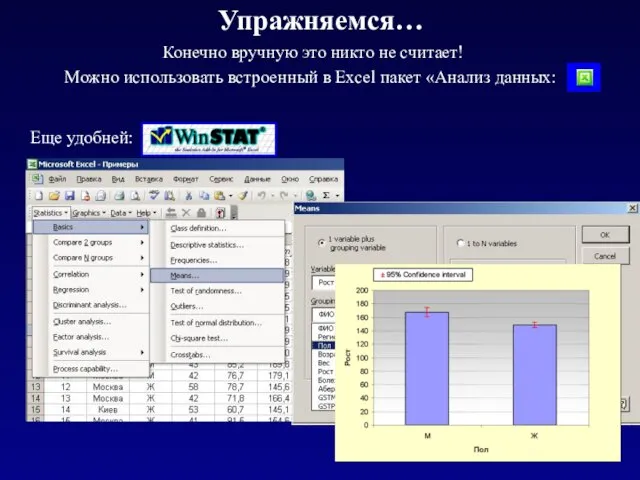
Упражняемся…
Конечно вручную это никто не считает!
Упражняемся…
Конечно вручную это никто не считает!
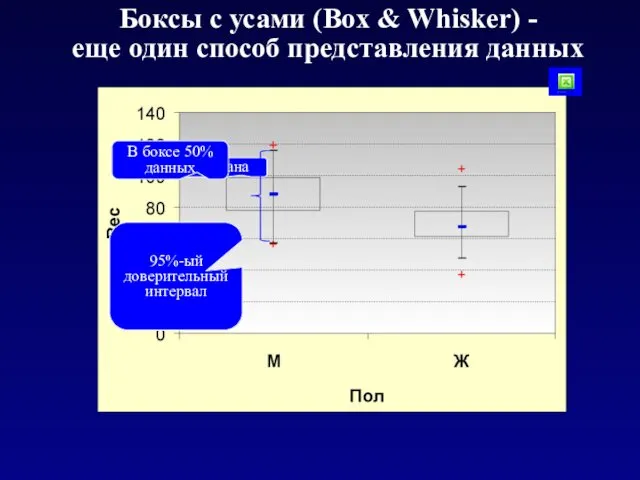
Боксы с усами (Box & Whisker) -
еще один способ представления
Боксы с усами (Box & Whisker) -
еще один способ представления

Оценки частот тоже имеют ошибки и доверительные интервалы
Еще лучше
WhatIs/CI/Proportion
Оценки частот тоже имеют ошибки и доверительные интервалы
Еще лучше
WhatIs/CI/Proportion
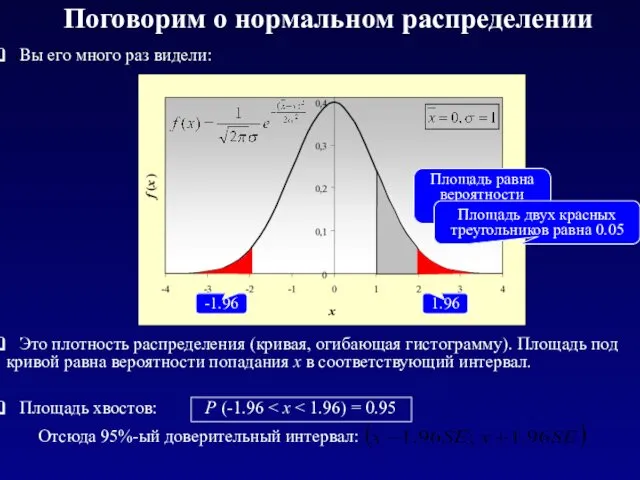
Поговорим о нормальном распределении
Это плотность распределения (кривая, огибающая гистограмму). Площадь
Поговорим о нормальном распределении
Это плотность распределения (кривая, огибающая гистограмму). Площадь

Почему нормальное распределение встречается на каждом шагу?
Например, биномиальный закон –
Почему нормальное распределение встречается на каждом шагу?
Например, биномиальный закон –

Гипотезы и статистики
Статистический критерий – это правило, согласно которому принимается
Гипотезы и статистики
Статистический критерий – это правило, согласно которому принимается
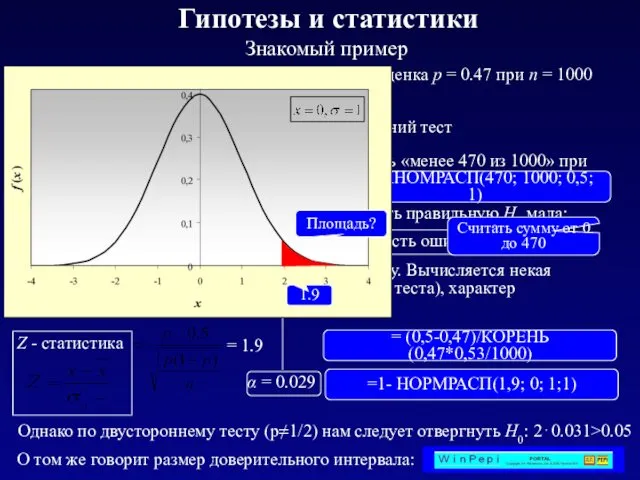
α = 0.031 – вероятность ошибки I рода
Гипотезы и статистики
В данном
α = 0.031 – вероятность ошибки I рода
Гипотезы и статистики
В данном

Нулевая гипотеза – обычно предположение об отсутствии различий, например, 2 выборки
Нулевая гипотеза – обычно предположение об отсутствии различий, например, 2 выборки

Н0 – беременности нет
Вероятность упустить и вероятность обознаться
Отвергнута правильная
Н0 – беременности нет
Вероятность упустить и вероятность обознаться
Отвергнута правильная

От чего зависят ошибки статистических тестов?
От объемов выборок
Вероятность упустить и
От чего зависят ошибки статистических тестов?
От объемов выборок
Вероятность упустить и

Вероятность упустить и вероятность обознаться
Караваджо (1573-1610). Фома Неверующий
«Критерий» св. Фомы
Вероятность упустить и вероятность обознаться
Караваджо (1573-1610). Фома Неверующий
«Критерий» св. Фомы

Уменьшая ошибку I рода, увеличиваем ошибку II рода,
т.е. теряем мощность теста
Уменьшая ошибку I рода, увеличиваем ошибку II рода,
т.е. теряем мощность теста
0
0.05
0.1
0.15
0.2
0.25
Статистика теста
Частота
Высокий уровень значимости
Низкий уровень значимости
Вероятность упустить и вероятность обознаться
0
0.05
0.1
0.15
0.2
0.25
Статистика теста
Частота
Высокий уровень значимости
Низкий уровень значимости
Вероятность упустить и вероятность обознаться

Мощность 80% считается приемлемой
Вероятность упустить и вероятность обознаться
Мощность теста
Мощность 80% считается приемлемой
Вероятность упустить и вероятность обознаться
Мощность теста
 Boeing 747
Boeing 747 Текстовые задачи ОГЭ 9 класс
Текстовые задачи ОГЭ 9 класс правила поведения на воде
правила поведения на воде Школьная газета ноябрь - декабрь 2020 года, школа №8 г. Туймазы
Школьная газета ноябрь - декабрь 2020 года, школа №8 г. Туймазы 20231011_shkolnyy_proekt
20231011_shkolnyy_proekt Соединение брусков
Соединение брусков Смысловые частицы
Смысловые частицы Скит преподобного Саввы. Храм преподобного Саввы Сторожевского
Скит преподобного Саввы. Храм преподобного Саввы Сторожевского Изготовление открытки в технике холодного батика. Призентация.
Изготовление открытки в технике холодного батика. Призентация. Презентация Как зовут тебя, дружок?
Презентация Как зовут тебя, дружок? С новым годом
С новым годом Введение в неврологию. Классификация нервной системы, ее значение в деятельности организма. Нейрон, нейроглия
Введение в неврологию. Классификация нервной системы, ее значение в деятельности организма. Нейрон, нейроглия Christmas in Great Britain
Christmas in Great Britain презентация к уроку природоведения 5 класс тема : Что нужно знать, чтобы вырастить различные виды растений.
презентация к уроку природоведения 5 класс тема : Что нужно знать, чтобы вырастить различные виды растений. Молочный цех для переработки молока в условиях ТОО Отес- Акдала
Молочный цех для переработки молока в условиях ТОО Отес- Акдала Перу
Перу MINI ECU LPG Injection system (4cyl. Only) – H2001
MINI ECU LPG Injection system (4cyl. Only) – H2001 Биомеханическая характеристика силовых качеств
Биомеханическая характеристика силовых качеств Halloween flashcards fun
Halloween flashcards fun Клеточная инженерия в селекции садовых культур. Методы генной инженерии растений. Генетическая трансформация растений
Клеточная инженерия в селекции садовых культур. Методы генной инженерии растений. Генетическая трансформация растений Снежинки и схемы вырезания. Диск
Снежинки и схемы вырезания. Диск Степень влияния телевидения и литературы (чтения книг) на развитие личности подростка
Степень влияния телевидения и литературы (чтения книг) на развитие личности подростка Захист нафтогазопромислового обладнання від корозії з використанням інгібіторів. Оцінка ефективності дії інгібіторів
Захист нафтогазопромислового обладнання від корозії з використанням інгібіторів. Оцінка ефективності дії інгібіторів Классный час. Тема Дружба
Классный час. Тема Дружба Прогноз ветра и связанных с ним явлений погоды
Прогноз ветра и связанных с ним явлений погоды Доклад директора ГБУ Жилищник района Котловка
Доклад директора ГБУ Жилищник района Котловка Технология дистанционного обучения
Технология дистанционного обучения в Лекция 6
в Лекция 6