- Deep generative models for raw audio synthesis

Содержание
- 2. Waveform Time Amplitude
- 4. VOICE CONVERSION IN A NUTSHELL Source speaker waveform Target speaker waveform Black magic Encoder Decoder some
- 5. Hello AIUkraine! Text-to-speech
- 6. Very high dimensionality Typical sample rate ranges from 16000 to 44000 samples per second One second
- 7. Samples are strongly correlated Periodicity + long-term dependencies We need to jointly model thousands of random
- 8. The is no single answer The same text
- 9. Issues with conventional methods Hard to control prosody (emotional content) Require a lot of labeled data
- 10. Idea: Reformulate the task as a joint probability function (or density) estimation: text Which waveforms are
- 11. Analogy to machine translation English German Multiple outcomes Joint distribution of words (language model)
- 12. Parameter estimation is typically performed via maximum likelihood estimation Text
- 13. Recap: the maximum likelihood Maximize the probability of observing the data
- 14. Autoregressive models Time series forecasting (ARIMA, SARIMA, FARIMA) Language models (typically with recurrent neural networks) Basic
- 15. WaveNet Source: DeepMind blog Waveform is modeled by a stack of dilated causal convolutions https://arxiv.org/abs/1609.03499 text
- 16. WaveNet Training: maximize the probability estimated by the model according to the maximum likelihood principle. Can
- 17. Data scientists when their model is training
- 18. Deep learning engineers when their WaveNet is generating
- 19. Autoencoders Encoder Decoder Bottleneck High-level abstract features Low-level features Goal: reconstruct the input
- 20. Variational autoencoder Latent space Learns an approximation to Condition (text)
- 21. Variational autoencoder: sampling Typically a normal distribution By tweaking the latent variables, we can control prosody,
- 22. Variational autoencoder: latent space Source: https://blog.fastforwardlabs.com/2016/08/12/introducing-variational-autoencoders-in-prose-and.html
- 23. Upgrade: VQ-VAE Now the latent space is discrete and represented by an autoregressive model https://arxiv.org/abs/1711.00937
- 24. Normalizing flows Take a random variable with distribution , apply some invertible mapping:
- 25. Normalizing flows Take a random variable with distribution , apply some invertible mapping: Recall the change
- 26. The change of variables rule For multidimensional random variables, replace the derivative with the Jacobian (a
- 27. General case (multiple transforms) Can be optimized directly, e.g. with a stochastic gradient ascent a flow
- 28. Waveform Text
- 29. Key idea: represent WaveNet with a normalizing flow This approach is called Inverse Autoregressive Flow
- 30. Waveform White noise Text https://deepmind.com/blog/article/high-fidelity-speech-synthesis-wavenet
- 31. Parallel WaveNet: the voice of Google Assistant https://arxiv.org/abs/1711.10433 fast training, slow generation slow training, fast generation
- 32. https://arxiv.org/abs/1609.03499 - WaveNet https://arxiv.org/abs/1312.6114 - Variational Autoencoder https://arxiv.org/abs/1711.00937 - VQ-VAE https://arxiv.org/abs/1711.10433 - Parallel WaveNet https://deepmind.com/blog/article/wavenet-generative-model-raw-audio -
- 34. Скачать презентацию

Waveform
Time
Amplitude
Waveform
Time
Amplitude

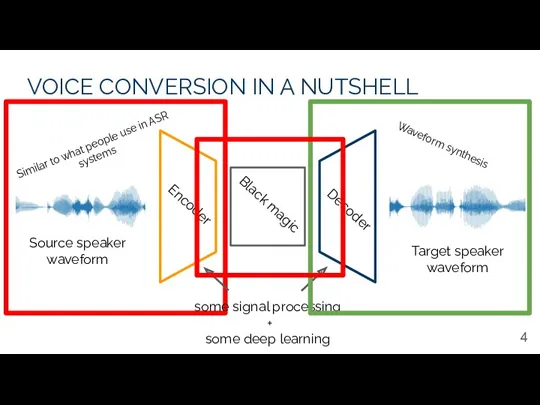
VOICE CONVERSION IN A NUTSHELL
Source speaker waveform
Target speaker waveform
Black magic
Encoder
Decoder
some signal
VOICE CONVERSION IN A NUTSHELL
Source speaker waveform
Target speaker waveform
Black magic
Encoder
Decoder
some signal

Hello AIUkraine!
Text-to-speech
Hello AIUkraine!
Text-to-speech
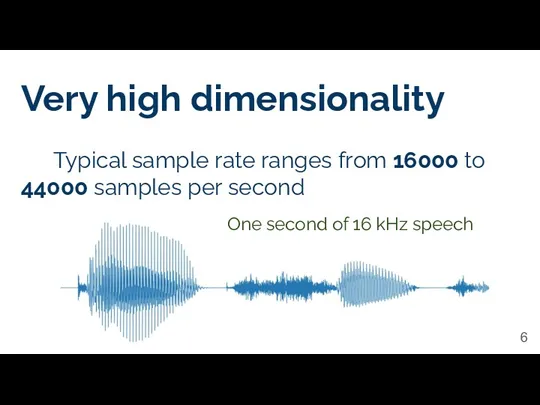
Very high dimensionality
Typical sample rate ranges from 16000 to 44000
Very high dimensionality
Typical sample rate ranges from 16000 to 44000
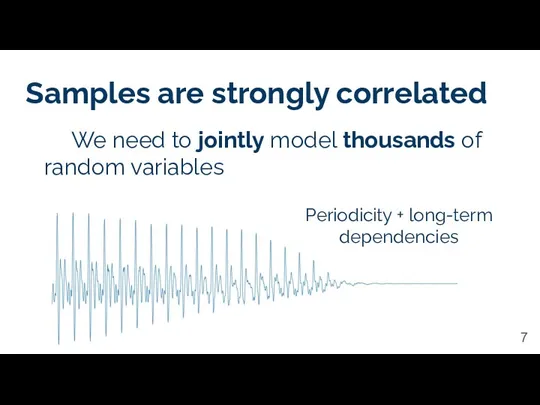
Samples are strongly correlated
Periodicity + long-term dependencies
We need to jointly model
Samples are strongly correlated
Periodicity + long-term dependencies
We need to jointly model

The is no single answer
The same text
The is no single answer
The same text

Issues with conventional methods
Hard to control prosody (emotional content)
Require a lot
Issues with conventional methods
Hard to control prosody (emotional content)
Require a lot

Idea:
Reformulate the task as a joint probability function (or density) estimation:
text
Which
Idea:
Reformulate the task as a joint probability function (or density) estimation:
text
Which
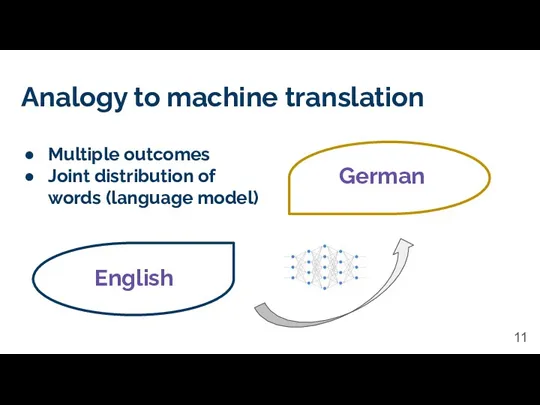
Analogy to machine translation
English
German
Multiple outcomes
Joint distribution of words (language model)
Analogy to machine translation
English
German
Multiple outcomes
Joint distribution of words (language model)

Parameter estimation is typically performed via maximum likelihood estimation
Text
Parameter estimation is typically performed via maximum likelihood estimation
Text

Recap: the maximum likelihood
Maximize the probability of observing the data
Recap: the maximum likelihood
Maximize the probability of observing the data

Autoregressive models
Time series forecasting (ARIMA, SARIMA, FARIMA)
Language models (typically with recurrent
Autoregressive models
Time series forecasting (ARIMA, SARIMA, FARIMA)
Language models (typically with recurrent

WaveNet
Source: DeepMind blog
Waveform is modeled by a stack of dilated causal
WaveNet
Source: DeepMind blog
Waveform is modeled by a stack of dilated causal

WaveNet
Training: maximize the probability estimated by the model according to the
WaveNet
Training: maximize the probability estimated by the model according to the

Data scientists when their model is training
Data scientists when their model is training

Deep learning engineers when their WaveNet is generating
Deep learning engineers when their WaveNet is generating
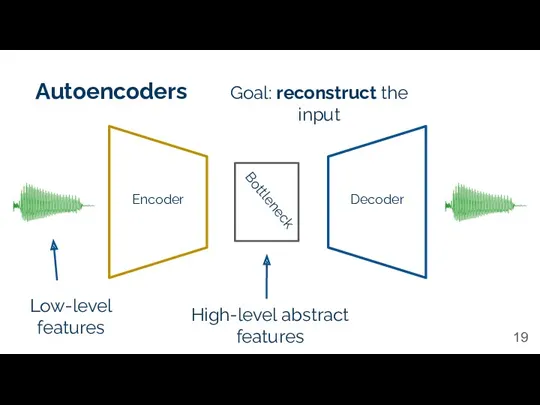
Autoencoders
Encoder
Decoder
Bottleneck
High-level abstract features
Low-level features
Goal: reconstruct the input
Autoencoders
Encoder
Decoder
Bottleneck
High-level abstract features
Low-level features
Goal: reconstruct the input
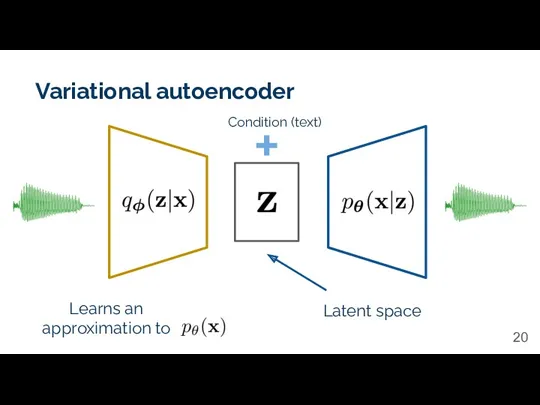
Variational autoencoder
Latent space
Learns an approximation to
Condition (text)
Variational autoencoder
Latent space
Learns an approximation to
Condition (text)
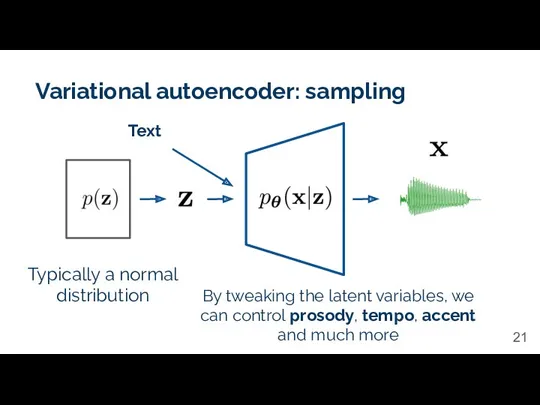
Variational autoencoder: sampling
Typically a normal distribution
By tweaking the latent variables, we
Variational autoencoder: sampling
Typically a normal distribution
By tweaking the latent variables, we
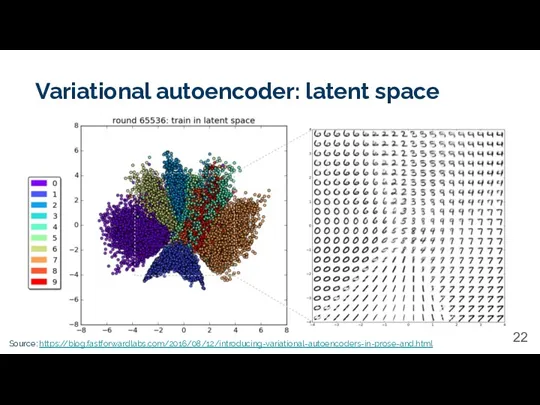
Variational autoencoder: latent space
Source: https://blog.fastforwardlabs.com/2016/08/12/introducing-variational-autoencoders-in-prose-and.html
Variational autoencoder: latent space
Source: https://blog.fastforwardlabs.com/2016/08/12/introducing-variational-autoencoders-in-prose-and.html
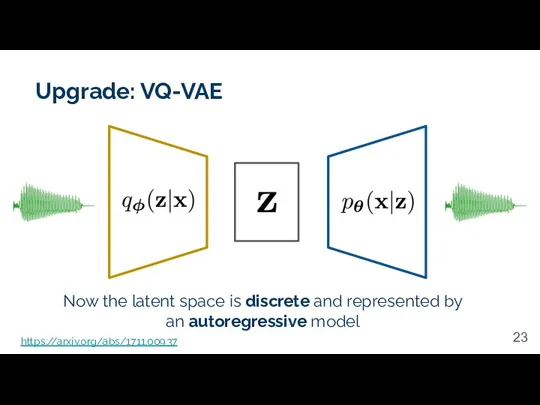
Upgrade: VQ-VAE
Now the latent space is discrete and represented by an
Upgrade: VQ-VAE
Now the latent space is discrete and represented by an

Normalizing flows
Take a random variable with distribution , apply some invertible
Normalizing flows
Take a random variable with distribution , apply some invertible

Normalizing flows
Take a random variable with distribution , apply some invertible
Normalizing flows
Take a random variable with distribution , apply some invertible

The change of variables rule
For multidimensional random variables, replace the derivative
The change of variables rule
For multidimensional random variables, replace the derivative

General case (multiple transforms)
Can be optimized directly, e.g. with a stochastic
General case (multiple transforms)
Can be optimized directly, e.g. with a stochastic

Waveform
Text
Waveform
Text

Key idea: represent WaveNet with a normalizing flow
This approach is called
Key idea: represent WaveNet with a normalizing flow
This approach is called
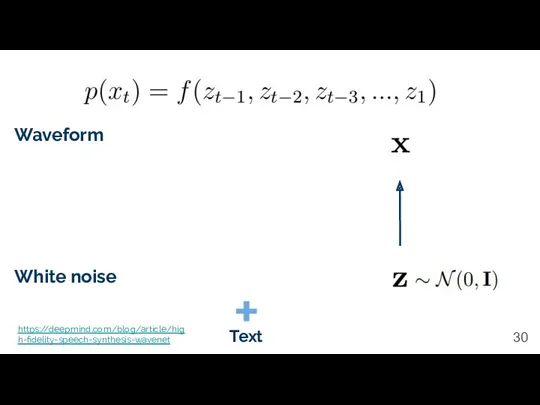
Waveform
White noise
Text
https://deepmind.com/blog/article/high-fidelity-speech-synthesis-wavenet
Waveform
White noise
Text
https://deepmind.com/blog/article/high-fidelity-speech-synthesis-wavenet
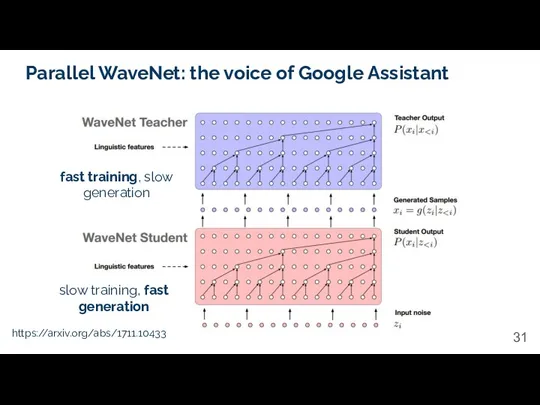
Parallel WaveNet: the voice of Google Assistant
https://arxiv.org/abs/1711.10433
fast training, slow generation
slow training,
Parallel WaveNet: the voice of Google Assistant
https://arxiv.org/abs/1711.10433
fast training, slow generation
slow training,

https://arxiv.org/abs/1609.03499 - WaveNet
https://arxiv.org/abs/1312.6114 - Variational Autoencoder
https://arxiv.org/abs/1711.00937 - VQ-VAE
https://arxiv.org/abs/1711.10433 - Parallel WaveNet
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
https://arxiv.org/abs/1609.03499 - WaveNet
https://arxiv.org/abs/1312.6114 - Variational Autoencoder
https://arxiv.org/abs/1711.00937 - VQ-VAE
https://arxiv.org/abs/1711.10433 - Parallel WaveNet
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
 Экономический ущерб, причиняемый инфекционными болезнями
Экономический ущерб, причиняемый инфекционными болезнями Рассмотрение полицией обращений граждан
Рассмотрение полицией обращений граждан Пословицы и поговорки
Пословицы и поговорки Устройство обработки информации. Процессор
Устройство обработки информации. Процессор Религия. Функции религии
Религия. Функции религии 9 государственных программ социальной сферы
9 государственных программ социальной сферы Анализ эффективности внедрения промышленной робототехники на обрабатывающем предприятии
Анализ эффективности внедрения промышленной робототехники на обрабатывающем предприятии Рабочее проектирование
Рабочее проектирование Значение дидактических игр в развитие детей раннего возраста
Значение дидактических игр в развитие детей раннего возраста Динамикалық буындар және структуралық схемаларды түрлендіру
Динамикалық буындар және структуралық схемаларды түрлендіру Травмы. Переломы. Кровотечения
Травмы. Переломы. Кровотечения Front-End Pro. Занятие №3
Front-End Pro. Занятие №3 Обмен веществ и энергии. Метаболизм
Обмен веществ и энергии. Метаболизм КВН: Арифметика повсюду. 6 класс
КВН: Арифметика повсюду. 6 класс презентация ученицы 3 класса Чтобы в наши дома не пришла беда, будем с огнём осторожны всегда!
презентация ученицы 3 класса Чтобы в наши дома не пришла беда, будем с огнём осторожны всегда! Расположение транспортных средств на проезжей части. Скорость движения
Расположение транспортных средств на проезжей части. Скорость движения Эксплуатация систем вентиляции зданий. Требования и мероприятия
Эксплуатация систем вентиляции зданий. Требования и мероприятия Окна и двери
Окна и двери Соединения элементов мебели
Соединения элементов мебели Зима. Основные модные тенденции
Зима. Основные модные тенденции Электр жетектердегі өтпелі процестер
Электр жетектердегі өтпелі процестер Возведение монолитных высотных зданий_СПм,моз_в форме презентации
Возведение монолитных высотных зданий_СПм,моз_в форме презентации Средства тепловой диагностики, обработка и представление результатов измерений
Средства тепловой диагностики, обработка и представление результатов измерений Этюдник В.В. Верещагина
Этюдник В.В. Верещагина Презентация Откуда появляется дождик?
Презентация Откуда появляется дождик? Основные физико-химические процессы при производстве алюминия
Основные физико-химические процессы при производстве алюминия Терроризм и факторы риска вовлечения подростка в террористическую деятельность. 7 класс
Терроризм и факторы риска вовлечения подростка в террористическую деятельность. 7 класс Наркомания
Наркомания