- Лекция 2 Биомедстатистика. Гармонизация статистических доказательств и предсказаний

Содержание
- 2. Эпиграфы Один из самых обычных и ведущих к самым большим бедствиям соблазнов есть соблазн словами: «Все
- 3. В науку нет царского пути Однажды египетский царь Птолемей I выразил желание изучать геометрию. Призвал он
- 4. Итоги ХХ века Статистическая теория и анализ данных, несомненно, являются одними из главнейших научных технологий, развитых
- 5. Myron Tribus (Letter to Science) If experimentation is the queen of the sciences, surely statistical methods
- 6. Лекция 2. Гармонизация статистических доказательств и предсказаний
- 7. Эпидемиологи смотрят на мир сквозь решетку таблицы 2×2. При этом надо помнить, что результат обследования является
- 8. Интерфероны и диагностика ЗВУР - задержки внутриутробного развития Королева Л.И.
- 9. ЗВУР Термин задержка внутриутробного развития плода (ЗВУР) используется для описания плода, масса которого гораздо меньше ожидаемой
- 10. ЗВУР Сразу после рождения ему угрожает аспирация мекония, гипогликемия, гипотермия, респираторный дистресс-синдром (РДС)и множество других состояний.
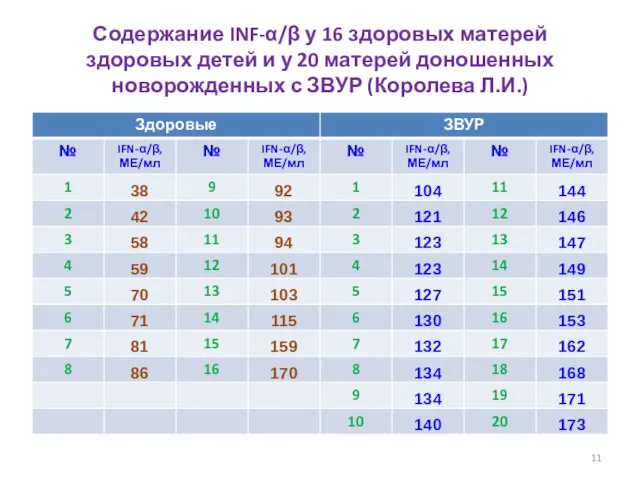
- 11. Содержание INF-α/β у 16 здоровых матерей здоровых детей и у 20 матерей доношенных новорожденных с ЗВУР
- 12. Гистограмма Гистограмма (от др.-греч. ἱστός — столб + γράμμα — черта, буква, написание) — столбиковая диаграмма
- 13. Сопоставление гистограмм содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных с ЗВУР
- 14. ROC-анализ: удобный инструмент для оценки качества диагностических исследований на основе мерных признаков
- 15. Распределения мерного диагностического признака у субъектов с болезнью и без нее Значения мерного диагностического признака Субъекты
- 16. Значения мерного диагностического признака Пороговое отсекающее значение
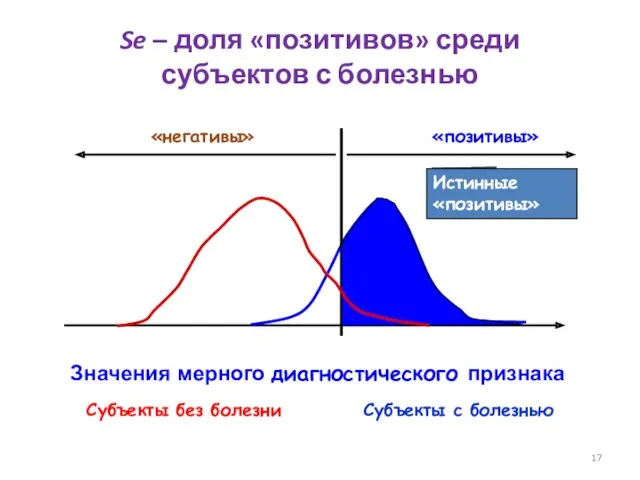
- 17. Значения мерного диагностического признака Субъекты без болезни Субъекты с болезнью Истинные «позитивы» Se – доля «позитивов»
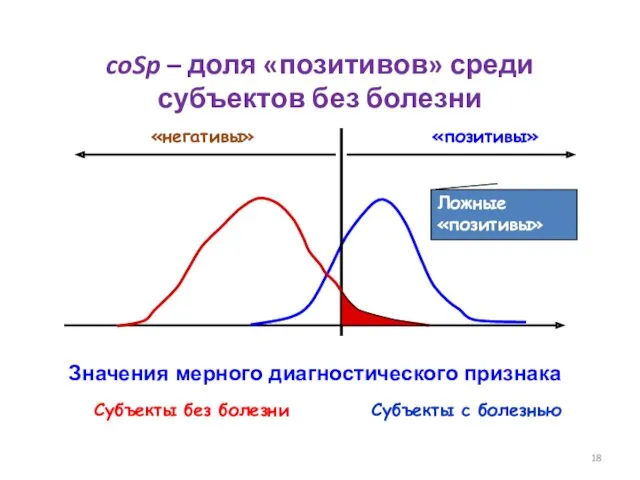
- 18. Значения мерного диагностического признака Субъекты без болезни Субъекты с болезнью Ложные «позитивы» coSp – доля «позитивов»
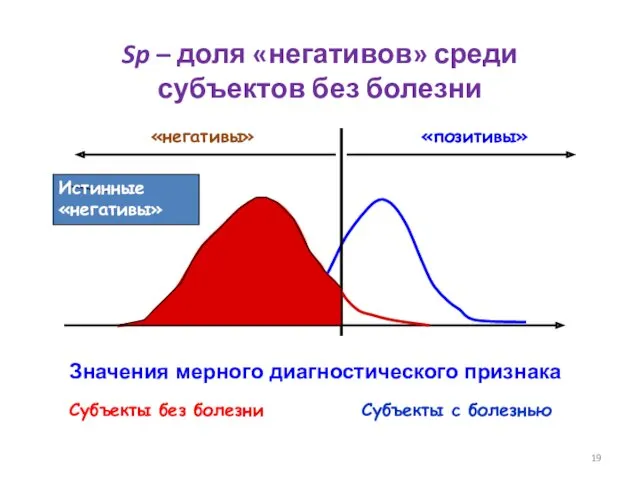
- 19. Значения мерного диагностического признака Субъекты без болезни Субъекты с болезнью Истинные «негативы» Sp – доля «негативов»
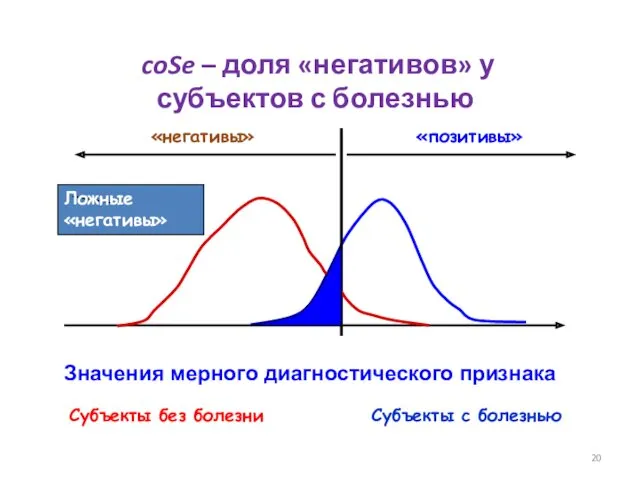
- 20. Значения мерного диагностического признака Субъекты без болезни Субъекты с болезнью Ложные «негативы» coSe – доля «негативов»
- 21. Наилучший тест: распределения значений мерного диагностического признака в двух группах не перекрываются
- 22. Наихудший тест: распределения значений мерного диагностического признака в двух группах полностью перекрываются
- 23. Операционная характеристика приёмника Термин операционная характеристика приёмника (Receiver Operating Characteristic, ROC) пришёл из теории обработки сигналов,
- 25. ROC-кривая – графическая характеристика качества диагностического теста, зависимость чувствительности, т.е. доли позитивов среди субъектов с болезнью:
- 26. Нахождение оптимального порога отсечения, Tr = 121 или 115
- 27. ROC-кривая, программа MedCalc
- 28. Графическая интерпретация порога отсечения на ROC-кривой для данных о содержании INF-α/β у матерей здоровых детей и
- 29. Наилучший тест: Наихудший тест: Распределения значений мерного признака не пересекаются вовсе Распределения значений мерного признака полностью
- 30. AUC (area under curve) – площадь под ROC-кривой Общее число ячеек в матрице сравнений: 20 ×
- 31. Программа GENERALISEDMW1.xls
- 32. Идеальный и бесполезный тесты в терминах AUC Если тест идеальный, то AUC = 1. Если AUC
- 33. AUC = 50% AUC = 90% AUC = 65% AUC = 100% Сравнение ROC-кривых
- 34. Словесные интерпретации для градаций AUC
- 35. Результаты ROC-анализа Оптимальный порог отсечения: Tr = 115 AUC = 0,750,891,00 Указаны границы параметрического 99%-го ДИ
- 36. Обсуждение результатов 99,9%-й ДИ для AUC = 0,570,890,98 не накрывает неинформативное значение AUC = 0,50. Следовательно,
- 37. Решающее правило: Значения признака, превышающие порог Tr = 115, принимаются за положительный результат диагностического теста. Значения
- 38. Графическое представление оптимального порога отсечения, программа MedCalc
- 39. Результирующая таблица 2 × 2 на основе ROC-анализа
- 41. Обсуждение результатов Se = 0,610,911,00 Sp = 0,470,830,99 99,9%-ые ДИ и для Se и для Sp
- 43. Обсуждение результатов LR[+] = 1,65,597,5 LR[-] = 1,99,2134,9 99,9%-ые ДИ и для LR[+] и для LR[-]
- 44. Номограмма Фейгена
- 45. Распространенность Prev = 0,16, при которой PPV = 0,5
- 46. График прогностичностей 99%-й ДИ 99,9%-й ДИ
- 47. Предостережение Подобные исследования следует рассматривать как сугубо предварительные (пилотные, разведочные, обучающие). Об этом свидетельствуют в частности
- 48. Одно распределение «вложено» в другое: ROC-анализ неприменим Гистограмма
- 49. Еще пример, когда ROC-анализ неприменим Гистограмма
- 50. Гистограммы содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных с ЗВУР. Программа PAST
- 51. Нормальные вероятностные графики Здоровые ЗВУР
- 52. Проверка нормальности (гауссовости) распределения у матерей здоровых детей и детей с ЗВУР Все Р-значения превышают пороговое
- 53. Диаграммы «короб с усами» для данных об уровне индуцированной продукции IFN‑α/β у здоровых матерей здоровых детей
- 54. Исключение резко выделяющихся наблюдений С рекомендаций по отбрасыванию выскакивающих (экстремальных) наблюдений («выбросов», «засорений») начинаются многие руководства
- 55. Отбрасывание выскакивающих значений основано на очень серьезных изначальных предположениях. Обычно подразумевается, что наблюдаемые выборочные значения принадлежат
- 56. Резко выделяющиеся значения – «выбросы» Выскакивающие значения можно и нужно выявлять. Но отбрасывать их следует на
- 57. Если же в малой выборке содержатся «выскакивающие» значения, то это может означать, что исходное распределение не
- 58. Сжатие (свертка, редукция) статистических данных Статистика – любая функция от случайных величин, порождающих получаемые статистические данные.
- 59. Основная логика статистического оценивания: интервальные оценки Понятно, что если мы многократно повторим эксперимент, то вычисленные средние
- 60. Статистические гипотезы В обычном языке слово «гипотеза» означает предположение. В том же смысле оно употребляется и
- 61. Проверяемая гипотеза В подавляющем большинстве реальных ситуаций проверяемая статистическая гипотеза является гипотезой об отсутствии того или
- 62. Использование доверительных интервалов (ДИ) для проверки нулевых гипотез Например, для проверки нулевой гипотезы о равенстве двух
- 63. Визуализация результатов проверки статистических гипотез с помощью доверительных интервалов для размера эффекта
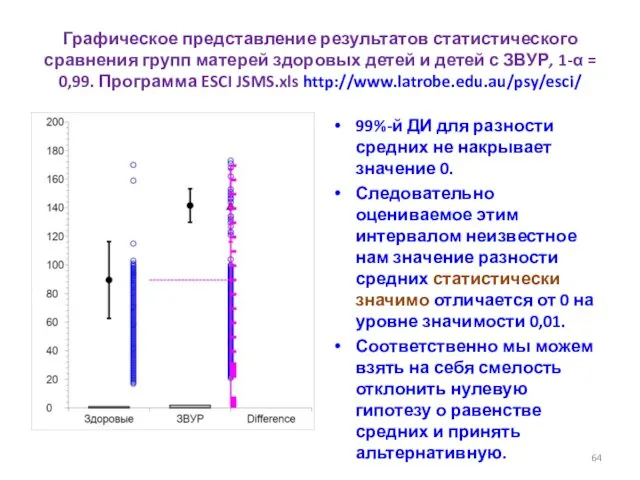
- 64. Графическое представление результатов статистического сравнения групп матерей здоровых детей и детей с ЗВУР, 1-α = 0,99.
- 65. Статистики критериев (тестовые статистики) Тестовая статистика – статистика, используемая для проверки конкретной статистической гипотезы. Пример: статистика
- 66. Проблема Беренса-Фишера Если дисперсии сравниваемых двух независимых случайных величин не равны, то, то следует использовать модификацию
- 67. Статистика Уэлча приближенно имеет t-распределение Стьюдента, но с параметром νW, который задается выражением: где
- 68. Р-значение Для проверки нулевых гипотез с помощью статистических критериев основным приемом является вычисление значения вероятности, которое
- 69. Р-значение P-значение есть условная вероятность, а именно: Вероятность получить наблюдаемое значение tнабл. статистики некоего критерия T
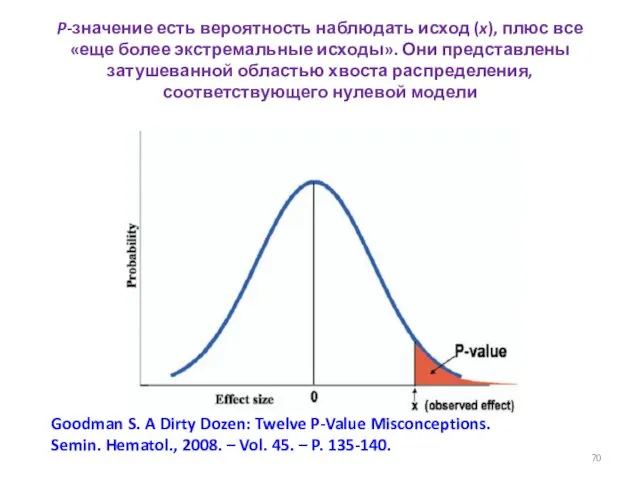
- 70. P-значение есть вероятность наблюдать исход (x), плюс все «еще более экстремальные исходы». Они представлены затушеванной областью
- 71. Односторонние Р-значения
- 72. Двухстороннее Р-значение
- 73. Основная логика использования наблюдаемого значения величины P состоит в том, что если оно малó, то считается,
- 74. Выбор порога для значения P, и можно ли его обосновать? Когда наблюдаемое значение P мало, то
- 75. Традиционная интерпретация значений P (шкала Michelin)
- 76. Глотов Н.В., Животовский Л.А., Хованов Н.В., Хромов-Борисов Н.Н. Биометрия, Л.: Изд-во ЛГУ, 1982. – 264 с.
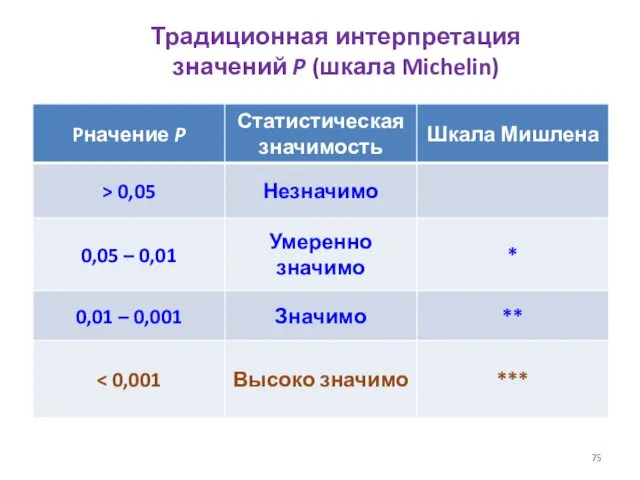
- 77. [0,05; 0,01] – «серая зона»
- 78. «Фильтруйте базар»: Sterne J.A.C., Davey Smith G. Sifting the evidence – what’s wrong with significance tests?
- 79. В модных ныне изысканиях различного рода генетических предрасположенностей, когда проверяются миллионы аллелей различных генов, исследователи ориентируются
- 80. Sir Ronald Aylmer Fisher 17.02.1890 – 29.07.1962
- 81. Пожелание: «гибкие» P-значения «В действительности ни один исследователь не пользуется фиксированным уровнем значимости с которым из
- 82. Результаты статистического сравнение групп матерей здоровых детей и детей с ЗВУР, 1-α = 0,99. Программа ESCI
- 83. Акт интеллектуальной смелости Когда значение P очень мало, мы берем на себя смелость отклонить нулевую гипотезу
- 84. Распространенный соблазн Квинтэссенцию традиционных (частотнических) заключений при проверке статистических гипотез принято интерпретировать так: чем меньше значение
- 85. Распространенное заблуждение Значение P не есть вероятность нулевой гипотезы ! Поскольку P-значение вычисляется при условии, что
- 86. P-значение не есть вероятность нулевой гипотезы! К сожалению, даже в известной книге С.Гланца можно встретить утверждение:
- 87. Р-значение потому столь привлекательно для ученых, что с ним очень легко получить «значимый» («достоверный») результат, даже
- 88. Калибровка значения P Sellke T., Bayarri M.J., Berger J.O. Calibration of p values for testing precise
- 89. Калибровка значений P Held L. A nomogram for P values. BMC Medical Research Methodology 2010, 10:21
- 93. «Цена» значения P Для наглядности значения в таблице округлены до первой значащей цифры. Более точно значения
- 94. Бейзовская интерпретация значения P Обычно принято интерпретировать значения P как меру доказательства, предоставляемого имеющимися данными, против
- 95. Привычка свыше нам дана Это прекрасно понимал Р.А. Фишер: «Критерий значимости не позволяет нам делать какие-либо
- 96. Статистическая значимость и размер эффекта Эффект (различие, связь, риск, польза, ассоциация и т. п.) может быть
- 97. Размер эффекта Вопрос о клинической (практической) ценности (важности) наблюдаемого Размера Эффекта является ключевым при интерпретации результатов
- 98. Стандартизированный размер эффекта по Коуэну (Cohen) dC
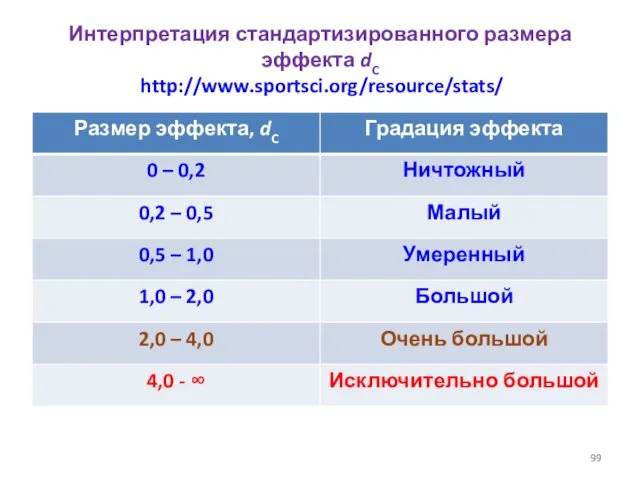
- 99. Интерпретация стандартизированного размера эффекта dC http://www.sportsci.org/resource/stats/
- 100. Результаты статистического сравнения групп матерей здоровых детей и детей с ЗВУР, (1 - α) = 0,99.
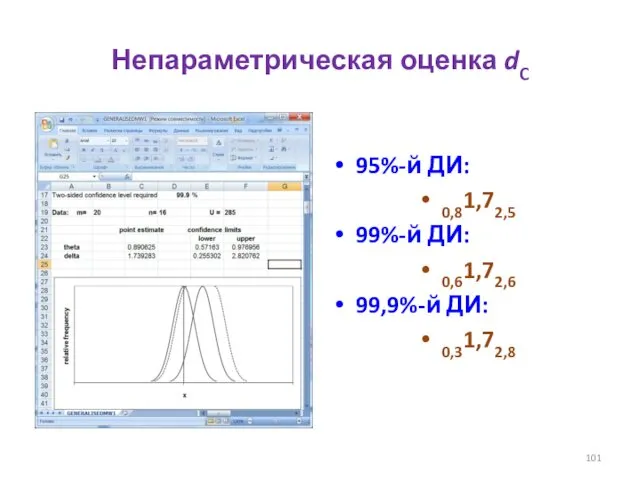
- 101. Непараметрическая оценка dC 95%-й ДИ: 0,81,72,5 99%-й ДИ: 0,61,72,6 99,9%-й ДИ: 0,31,72,8
- 102. Бейзов фактор, BF Бейзов фактор BF принципиально отличается от значения P. Бейзов фактор не является вероятностью
- 103. Интерпретация убедительности Бейзовых факторов, BF10 и BF01
- 104. Бейзов фактор, программа Bayes Factor Calculators http://pcl.missouri.edu/bayesfactor
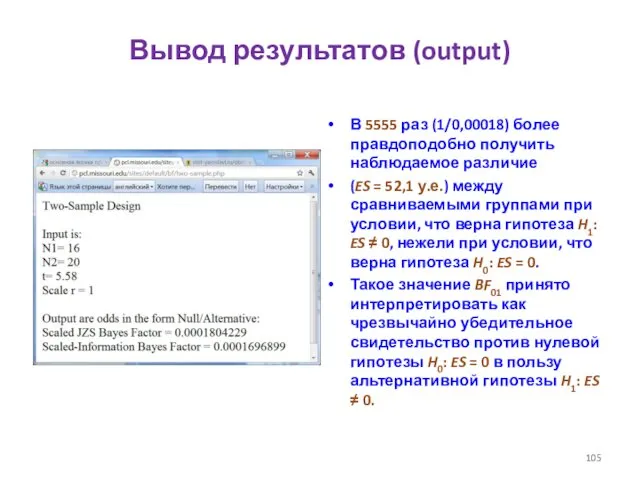
- 105. Вывод результатов (output) В 5555 раз (1/0,00018) более правдоподобно получить наблюдаемое различие (ES = 52,1 у.е.)
- 106. Достаточно малое значение P заставляет думать, что произошло нечто неожиданное. И обычно это интерпретируется как неверность
- 107. Статистические предсказания и воспроизводимость
- 108. Значение вероятностной P-величины Значение P есть наблюдаемое значение (реализация) соответствующей случайной величины Всякий раз мы наблюдаем
- 109. Отсюда следует, что, строго говоря, на основе всего лишь одного изолированного исследования нельзя делать определенные выводы.
- 110. Доверяя, повторяй Часто считается, что если получен «статистически значимый» результат, то это исключает необходимость повторить исследование.
- 111. Повторение – мать познания Повторение составляет суть науки: ученый должен всегда задумываться о том, что произойдет,
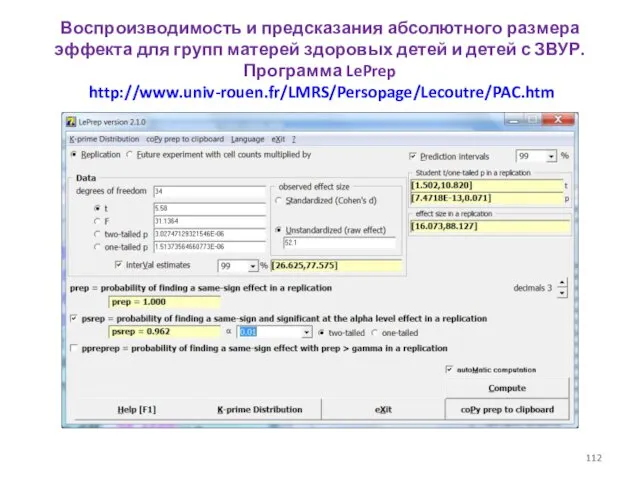
- 112. Воспроизводимость и предсказания абсолютного размера эффекта для групп матерей здоровых детей и детей с ЗВУР. Программа
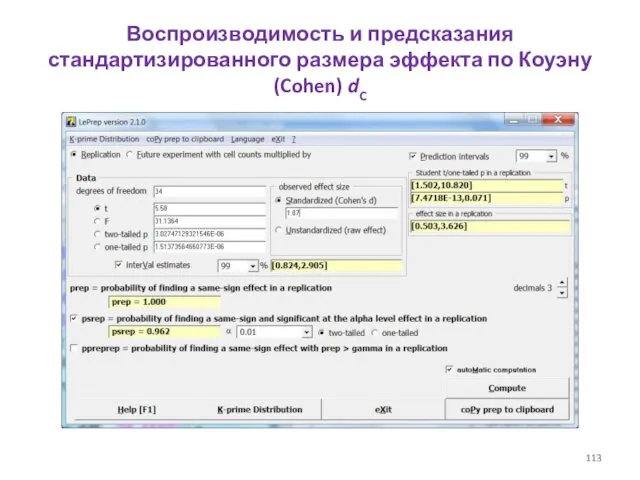
- 113. Воспроизводимость и предсказания стандартизированного размера эффекта по Коуэну (Cohen) dC
- 114. Воспроизводимость и предсказания размеров эффекта ES и dC для групп матерей здоровых детей и детей с
- 115. Ошибки I и II рода и мощность статистического критерия
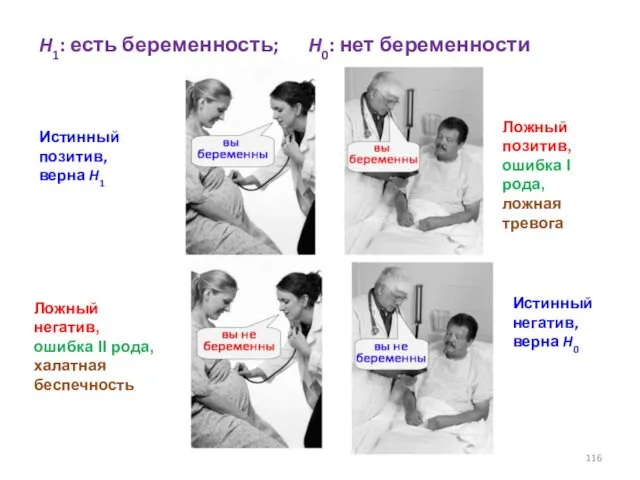
- 116. Истинный позитив, верна H1 Истинный негатив, верна H0 Ложный позитив, ошибка I рода, ложная тревога Ложный
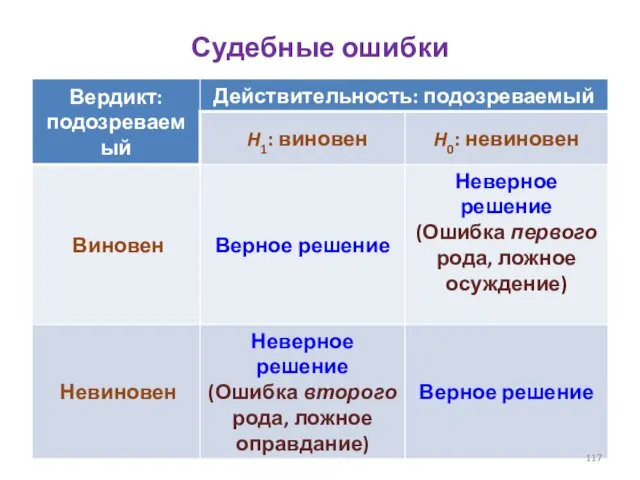
- 117. Судебные ошибки
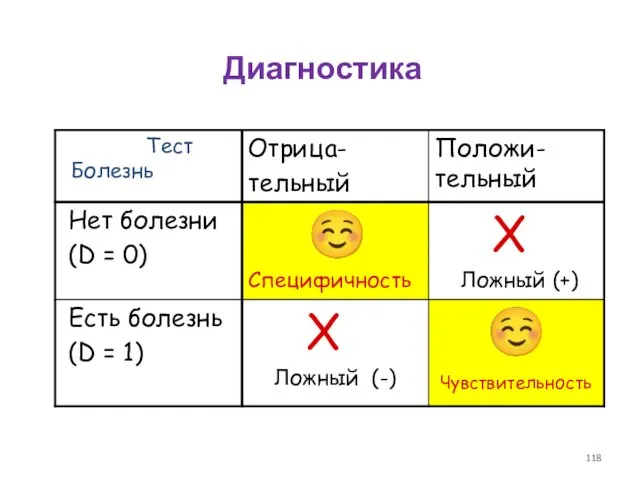
- 118. Диагностика Болезнь Тест
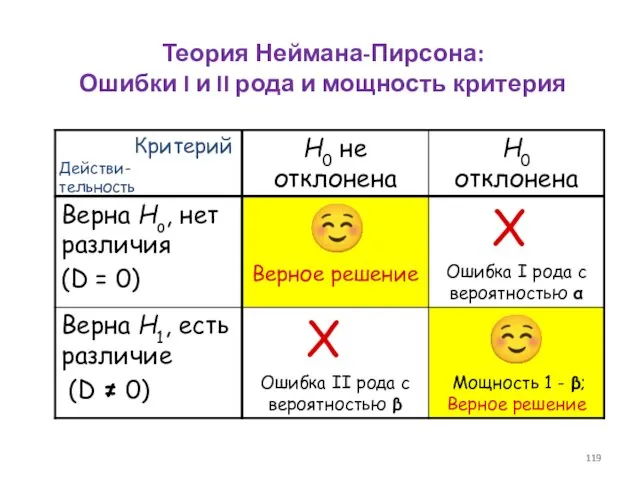
- 119. Теория Неймана-Пирсона: Ошибки I и II рода и мощность критерия Действи-тельность Критерий
- 120. Ошибки I и II рода Ошибка I рода: отклонение верной нулевой гипотезы; Аналитик решает (берет на
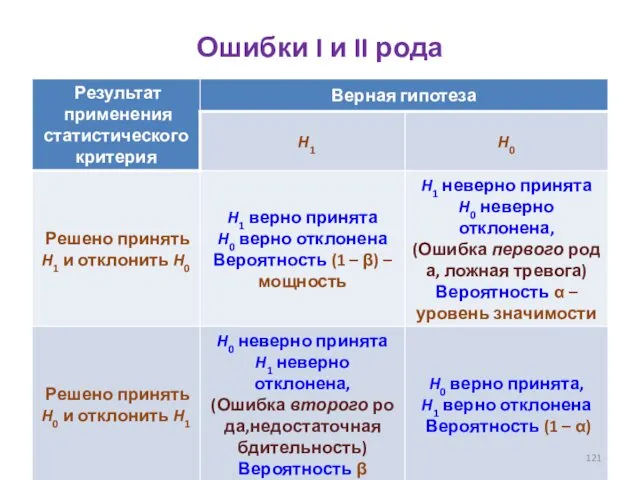
- 121. Ошибки I и II рода
- 122. Компромисс Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная
- 123. Мощность статистического критерия Мощность статистического критерия есть вероятность того, что критерий правильно отклонит ложную нулевую гипотезу
- 124. Мощность статистического критерия Мощность статистического критерия измеряет способность критерия выявлять истинные различия (эффекты). Ее можно интерпретировать
- 125. Мощность отвечает на вопрос: Если эффект (определенного размера) действительно существует, то какова вероятность того, что эксперимент
- 126. Анализ мощности a priori или post-hoc Анализ мощности можно проводить либо a priori, т.е. до получения
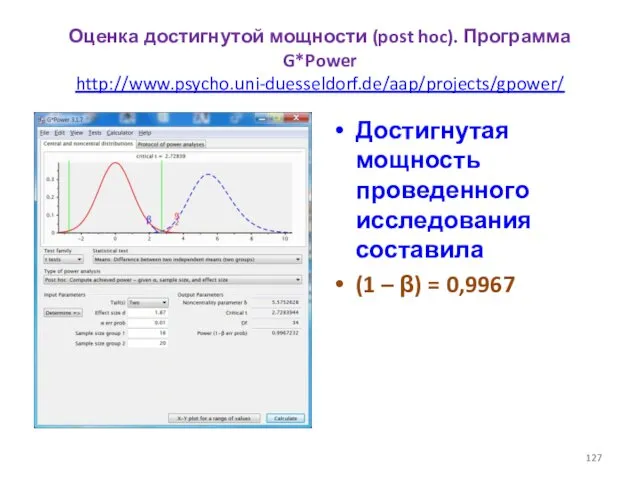
- 127. Оценка достигнутой мощности (post hoc). Программа G*Power http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/ Достигнутая мощность проведенного исследования составила (1 – β)
- 128. Элементы планирования эксперимента
- 129. Программа G*Power http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3 Оценка a priori минимально необходимого объема выборки N для достижения статистически значимого отличия
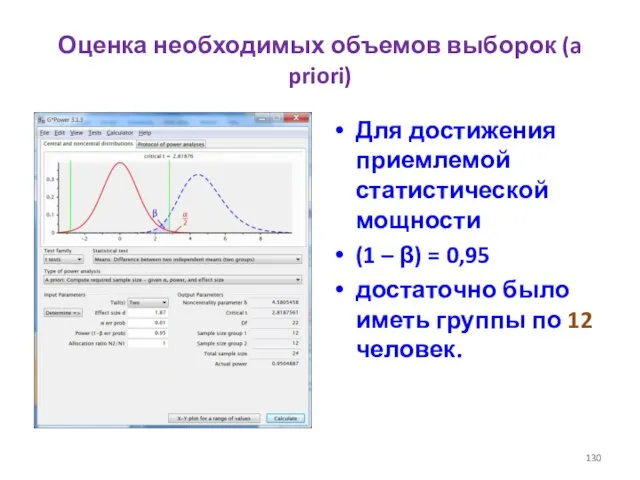
- 130. Оценка необходимых объемов выборок (a priori) Для достижения приемлемой статистической мощности (1 – β) = 0,95
- 131. Научный метод Ни один уважающий себя ученый не ограничится в своих исследованиях одним-единственным экспериментом, хотя бы
- 132. Культ одиночного изолированного исследования Чрезмерное «увлечение» анализом одиночных наборов данных пронизывает почти всю статистическую литературу и
- 133. Джон Уайлдер Тьюки (John Wilder Tukey, 16.04.1915 — 26.07.2000) Исследования должны быть как минимум двухэтапными. Первый
- 135. Скачать презентацию
Эпиграфы
Один из самых обычных и ведущих к самым большим бедствиям соблазнов есть
Эпиграфы
Один из самых обычных и ведущих к самым большим бедствиям соблазнов есть

В науку нет царского пути
Однажды египетский царь Птолемей I выразил желание изучать геометрию.
В науку нет царского пути
Однажды египетский царь Птолемей I выразил желание изучать геометрию.

Итоги ХХ века
Статистическая теория и анализ данных, несомненно, являются одними из главнейших научных
Итоги ХХ века
Статистическая теория и анализ данных, несомненно, являются одними из главнейших научных

Myron Tribus
(Letter to Science)
If experimentation is the queen of the sciences, surely
Myron Tribus
(Letter to Science)
If experimentation is the queen of the sciences, surely

Лекция 2.
Гармонизация статистических доказательств и предсказаний
Лекция 2.
Гармонизация статистических доказательств и предсказаний

Эпидемиологи смотрят на мир сквозь решетку таблицы 2×2.
При этом надо помнить, что результат
Эпидемиологи смотрят на мир сквозь решетку таблицы 2×2.
При этом надо помнить, что результат

Интерфероны и диагностика ЗВУР - задержки внутриутробного развития
Королева Л.И.
Интерфероны и диагностика ЗВУР - задержки внутриутробного развития
Королева Л.И.

ЗВУР
Термин задержка внутриутробного развития плода (ЗВУР) используется для описания плода, масса которого гораздо меньше ожидаемой
ЗВУР
Термин задержка внутриутробного развития плода (ЗВУР) используется для описания плода, масса которого гораздо меньше ожидаемой

ЗВУР
Сразу после рождения ему угрожает аспирация мекония, гипогликемия, гипотермия, респираторный дистресс-синдром (РДС)и множество
ЗВУР
Сразу после рождения ему угрожает аспирация мекония, гипогликемия, гипотермия, респираторный дистресс-синдром (РДС)и множество

Содержание INF-α/β у 16 здоровых матерей здоровых детей и у 20 матерей доношенных
Содержание INF-α/β у 16 здоровых матерей здоровых детей и у 20 матерей доношенных
Гистограмма
Гистограмма
(от др.-греч. ἱστός — столб + γράμμα — черта, буква, написание)
— столбиковая диаграмма
— способ графического представления табличных
Гистограмма
Гистограмма
(от др.-греч. ἱστός — столб + γράμμα — черта, буква, написание)
— столбиковая диаграмма
— способ графического представления табличных

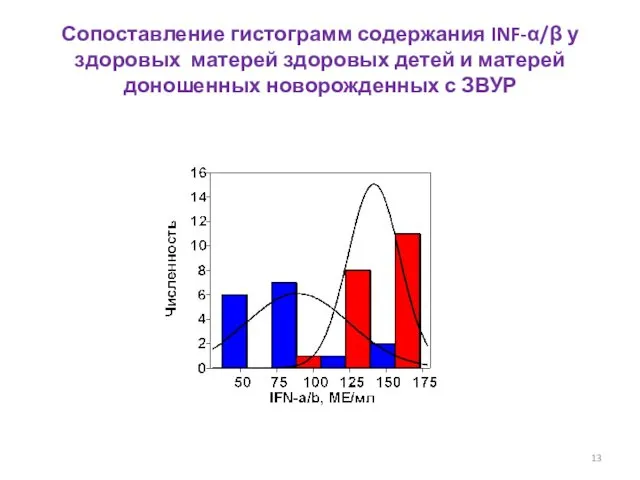
Сопоставление гистограмм содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных
Сопоставление гистограмм содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных
ROC-анализ:
удобный инструмент для оценки качества диагностических исследований на основе мерных признаков
ROC-анализ:
удобный инструмент для оценки качества диагностических исследований на основе мерных признаков

Распределения мерного диагностического признака у субъектов с болезнью и без нее
Значения мерного диагностического
Распределения мерного диагностического признака у субъектов с болезнью и без нее
Значения мерного диагностического
Значения мерного диагностического признака
Пороговое отсекающее значение
Значения мерного диагностического признака
Пороговое отсекающее значение
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Истинные «позитивы»
Se – доля «позитивов» среди
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Истинные «позитивы»
Se – доля «позитивов» среди
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Ложные «позитивы»
coSp – доля «позитивов» среди
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Ложные «позитивы»
coSp – доля «позитивов» среди
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Истинные «негативы»
Sp – доля «негативов» среди
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Истинные «негативы»
Sp – доля «негативов» среди
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Ложные «негативы»
coSe – доля «негативов»
Значения мерного диагностического признака
Субъекты без болезни
Субъекты с болезнью
Ложные «негативы»
coSe – доля «негативов»
Наилучший тест: распределения значений мерного диагностического признака в двух группах не перекрываются
Наилучший тест: распределения значений мерного диагностического признака в двух группах не перекрываются

Наихудший тест: распределения значений мерного диагностического признака в двух группах полностью перекрываются
Наихудший тест: распределения значений мерного диагностического признака в двух группах полностью перекрываются

Операционная характеристика приёмника
Термин операционная характеристика приёмника (Receiver Operating Characteristic, ROC) пришёл из теории обработки сигналов,
Операционная характеристика приёмника
Термин операционная характеристика приёмника (Receiver Operating Characteristic, ROC) пришёл из теории обработки сигналов,


ROC-кривая
– графическая характеристика качества диагностического теста,
зависимость чувствительности, т.е. доли позитивов среди
ROC-кривая
– графическая характеристика качества диагностического теста,
зависимость чувствительности, т.е. доли позитивов среди

Нахождение оптимального порога отсечения, Tr = 121 или 115
Нахождение оптимального порога отсечения, Tr = 121 или 115
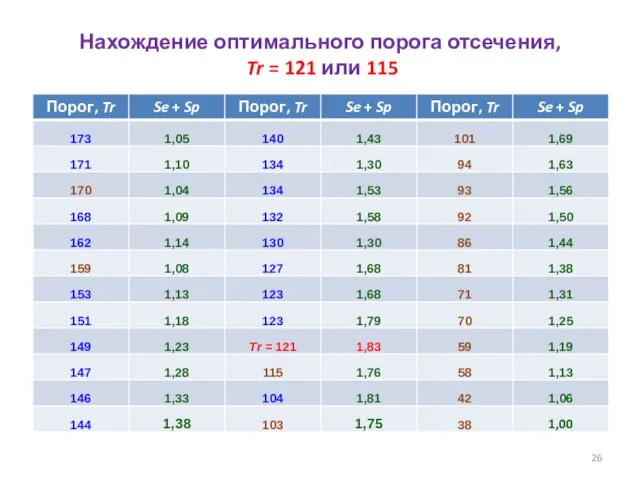
ROC-кривая, программа MedCalc
ROC-кривая, программа MedCalc
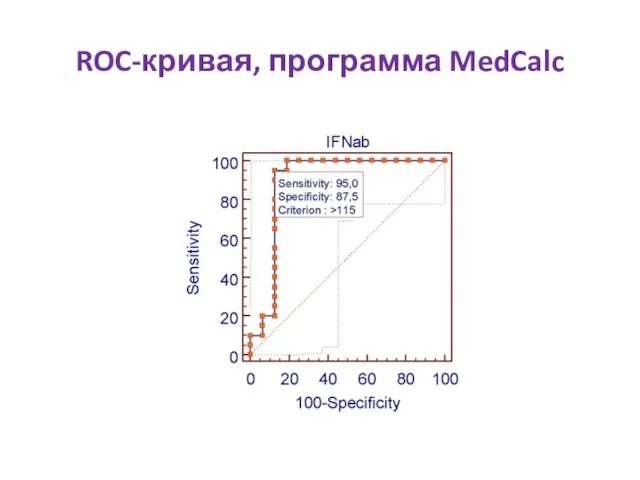
Графическая интерпретация порога отсечения на ROC-кривой для данных о содержании INF-α/β у матерей
Графическая интерпретация порога отсечения на ROC-кривой для данных о содержании INF-α/β у матерей
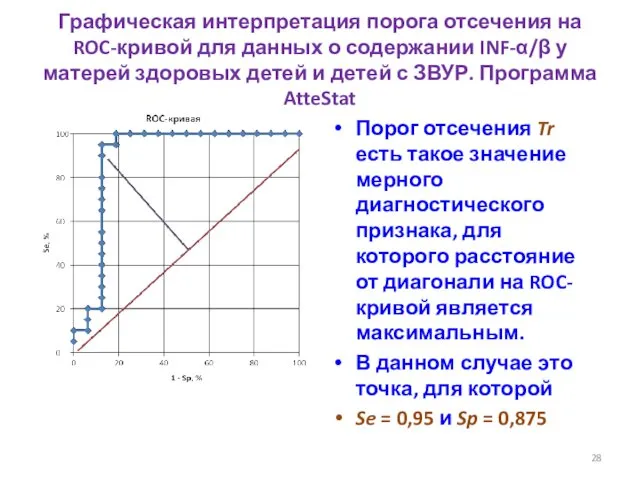
Наилучший тест:
Наихудший тест:
Распределения значений мерного признака не пересекаются вовсе
Распределения значений мерного признака полностью
Наилучший тест:
Наихудший тест:
Распределения значений мерного признака не пересекаются вовсе
Распределения значений мерного признака полностью
AUC (area under curve) –
площадь под ROC-кривой
Общее число ячеек в матрице сравнений:
20
AUC (area under curve) –
площадь под ROC-кривой
Общее число ячеек в матрице сравнений:
20

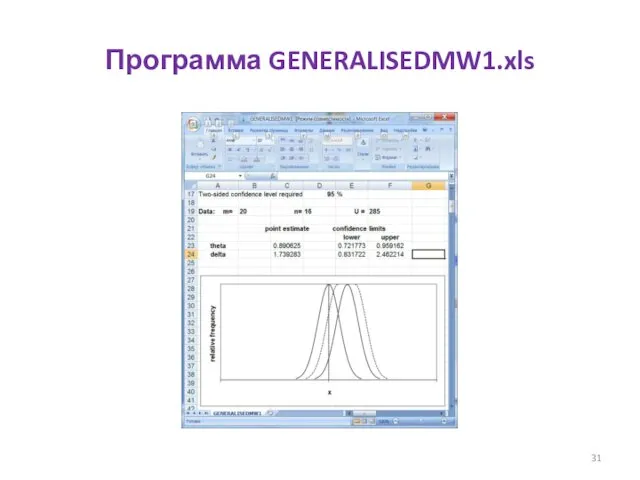
Программа GENERALISEDMW1.xls
Программа GENERALISEDMW1.xls
Идеальный и бесполезный тесты в терминах AUC
Если тест идеальный, то
AUC = 1.
Если
AUC
Идеальный и бесполезный тесты в терминах AUC
Если тест идеальный, то
AUC = 1.
Если
AUC

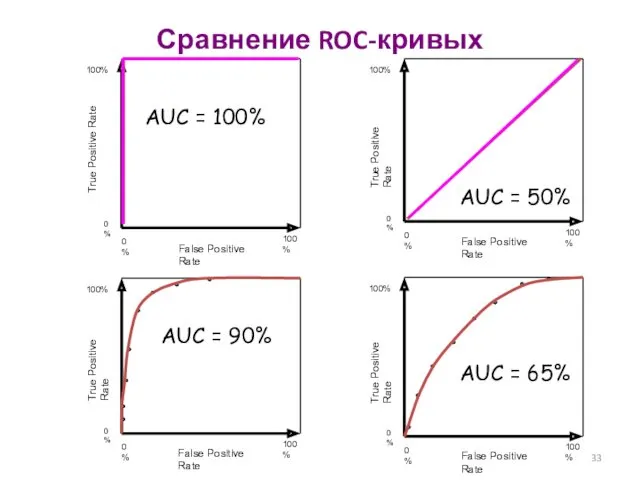
AUC = 50%
AUC = 90%
AUC = 65%
AUC = 100%
Сравнение ROC-кривых
AUC = 50%
AUC = 90%
AUC = 65%
AUC = 100%
Сравнение ROC-кривых
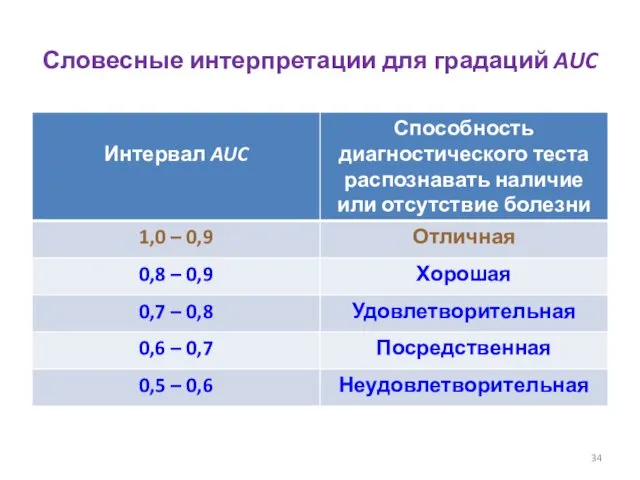
Словесные интерпретации для градаций AUC
Словесные интерпретации для градаций AUC
Результаты ROC-анализа
Оптимальный порог отсечения: Tr = 115
AUC = 0,750,891,00
Указаны границы параметрического 99%-го
Результаты ROC-анализа
Оптимальный порог отсечения: Tr = 115
AUC = 0,750,891,00
Указаны границы параметрического 99%-го

Обсуждение результатов
99,9%-й ДИ для AUC = 0,570,890,98 не накрывает неинформативное значение AUC =
Обсуждение результатов
99,9%-й ДИ для AUC = 0,570,890,98 не накрывает неинформативное значение AUC =

Решающее правило:
Значения признака, превышающие порог Tr = 115, принимаются за положительный результат диагностического
Решающее правило:
Значения признака, превышающие порог Tr = 115, принимаются за положительный результат диагностического

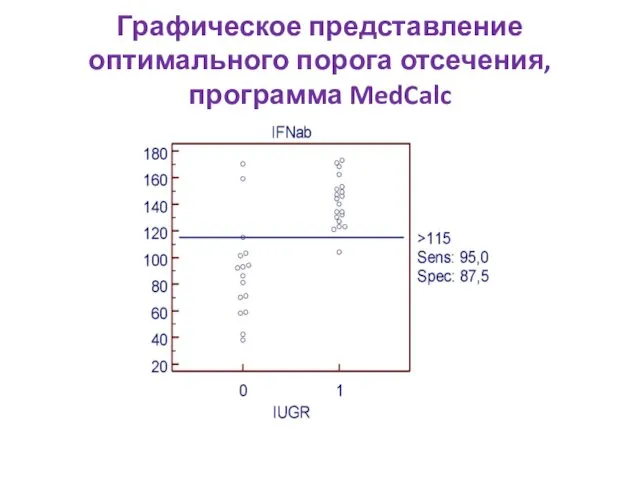
Графическое представление оптимального порога отсечения, программа MedCalc
Графическое представление оптимального порога отсечения, программа MedCalc
Результирующая таблица 2 × 2 на основе ROC-анализа
Результирующая таблица 2 × 2 на основе ROC-анализа
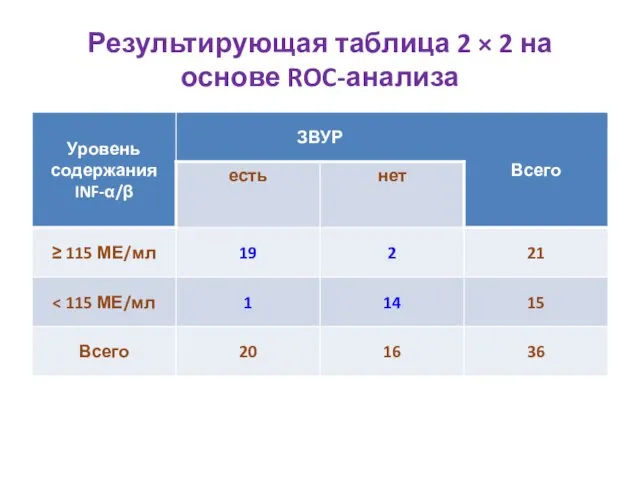

Обсуждение результатов
Se = 0,610,911,00
Sp = 0,470,830,99
99,9%-ые ДИ и для Se и для Sp
Обсуждение результатов
Se = 0,610,911,00
Sp = 0,470,830,99
99,9%-ые ДИ и для Se и для Sp


Обсуждение результатов
LR[+] = 1,65,597,5
LR[-] = 1,99,2134,9
99,9%-ые ДИ и для LR[+] и для LR[-]
Обсуждение результатов
LR[+] = 1,65,597,5
LR[-] = 1,99,2134,9
99,9%-ые ДИ и для LR[+] и для LR[-]
![Обсуждение результатов LR[+] = 1,65,597,5 LR[-] = 1,99,2134,9 99,9%-ые ДИ и для LR[+]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/55507/slide-42.jpg)
Номограмма Фейгена
Номограмма Фейгена

Распространенность Prev = 0,16, при которой PPV = 0,5
Распространенность Prev = 0,16, при которой PPV = 0,5

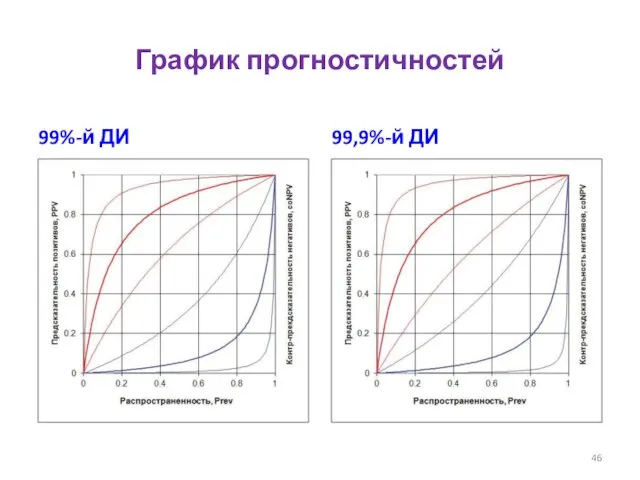
График прогностичностей
99%-й ДИ
99,9%-й ДИ
График прогностичностей
99%-й ДИ
99,9%-й ДИ
Предостережение
Подобные исследования следует рассматривать как сугубо предварительные
(пилотные, разведочные, обучающие).
Об этом свидетельствуют в
Предостережение
Подобные исследования следует рассматривать как сугубо предварительные
(пилотные, разведочные, обучающие).
Об этом свидетельствуют в

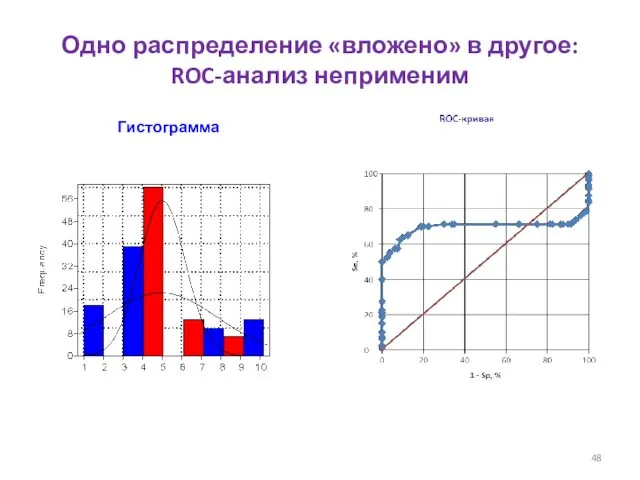
Одно распределение «вложено» в другое: ROC-анализ неприменим
Гистограмма
Одно распределение «вложено» в другое: ROC-анализ неприменим
Гистограмма
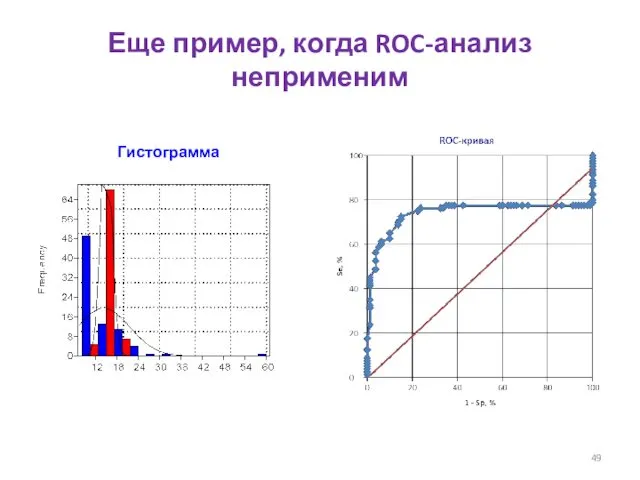
Еще пример, когда ROC-анализ неприменим
Гистограмма
Еще пример, когда ROC-анализ неприменим
Гистограмма
Гистограммы содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных с
Гистограммы содержания INF-α/β у здоровых матерей здоровых детей и матерей доношенных новорожденных с
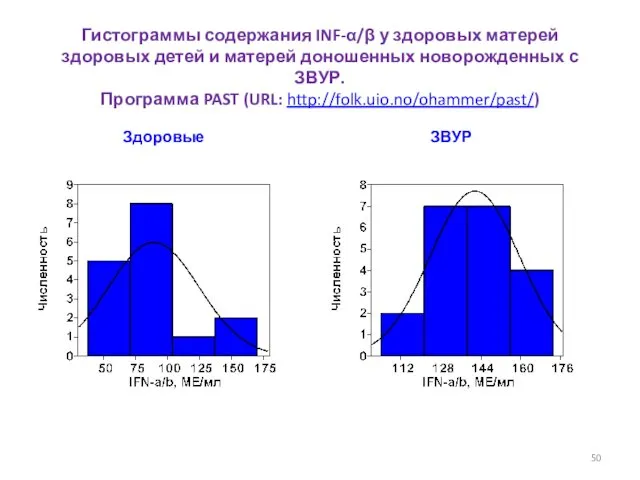
Нормальные вероятностные графики
Здоровые
ЗВУР
Нормальные вероятностные графики
Здоровые
ЗВУР
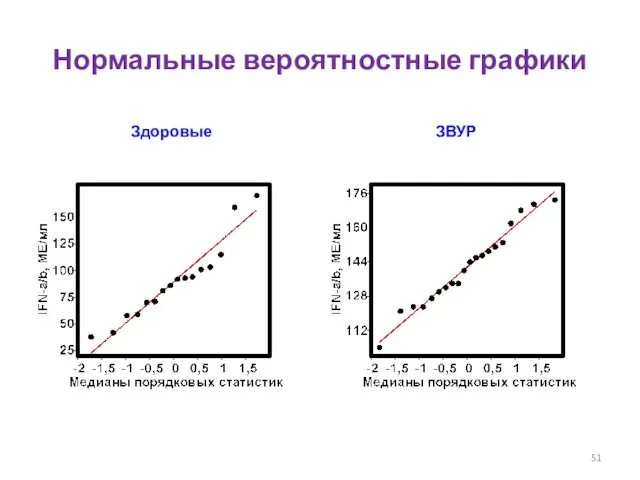
Проверка нормальности (гауссовости) распределения у матерей здоровых детей и детей с ЗВУР
Все Р-значения
Проверка нормальности (гауссовости) распределения у матерей здоровых детей и детей с ЗВУР
Все Р-значения
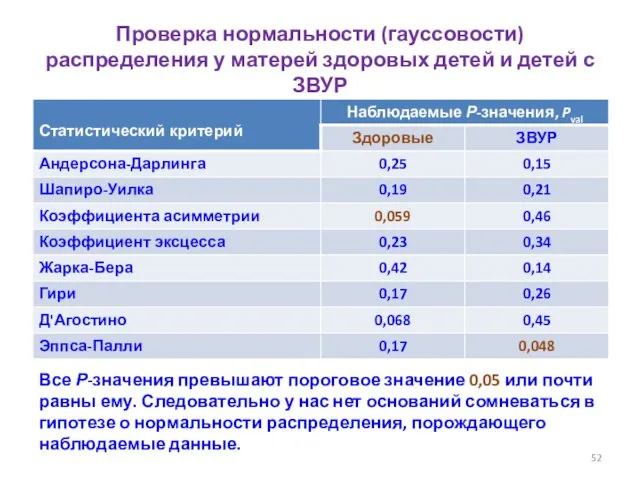
Диаграммы «короб с усами» для данных об уровне индуцированной продукции IFN‑α/β у здоровых
Диаграммы «короб с усами» для данных об уровне индуцированной продукции IFN‑α/β у здоровых
Исключение резко выделяющихся наблюдений
С рекомендаций по отбрасыванию выскакивающих (экстремальных) наблюдений («выбросов», «засорений») начинаются
Исключение резко выделяющихся наблюдений
С рекомендаций по отбрасыванию выскакивающих (экстремальных) наблюдений («выбросов», «засорений») начинаются

Отбрасывание выскакивающих значений основано на очень серьезных изначальных предположениях.
Обычно подразумевается, что наблюдаемые
Отбрасывание выскакивающих значений основано на очень серьезных изначальных предположениях.
Обычно подразумевается, что наблюдаемые

Резко выделяющиеся значения – «выбросы»
Выскакивающие значения можно и нужно выявлять.
Но отбрасывать их
Резко выделяющиеся значения – «выбросы»
Выскакивающие значения можно и нужно выявлять.
Но отбрасывать их

Если же в малой выборке содержатся «выскакивающие» значения, то это может означать, что
Если же в малой выборке содержатся «выскакивающие» значения, то это может означать, что

Сжатие (свертка, редукция) статистических данных
Статистика – любая функция от случайных величин, порождающих получаемые
Сжатие (свертка, редукция) статистических данных
Статистика – любая функция от случайных величин, порождающих получаемые

Основная логика статистического оценивания: интервальные оценки
Понятно, что если мы многократно повторим эксперимент, то
Основная логика статистического оценивания: интервальные оценки
Понятно, что если мы многократно повторим эксперимент, то

Статистические гипотезы
В обычном языке слово «гипотеза» означает предположение.
В том же смысле оно
Статистические гипотезы
В обычном языке слово «гипотеза» означает предположение.
В том же смысле оно

Проверяемая гипотеза
В подавляющем большинстве реальных ситуаций проверяемая статистическая гипотеза является гипотезой об отсутствии
Проверяемая гипотеза
В подавляющем большинстве реальных ситуаций проверяемая статистическая гипотеза является гипотезой об отсутствии

Использование доверительных интервалов (ДИ) для проверки нулевых гипотез
Например, для проверки нулевой гипотезы о
Использование доверительных интервалов (ДИ) для проверки нулевых гипотез
Например, для проверки нулевой гипотезы о

Визуализация результатов проверки статистических гипотез с помощью доверительных интервалов для размера эффекта
Визуализация результатов проверки статистических гипотез с помощью доверительных интервалов для размера эффекта

Графическое представление результатов статистического сравнения групп матерей здоровых детей и детей с ЗВУР,
Графическое представление результатов статистического сравнения групп матерей здоровых детей и детей с ЗВУР,
Статистики критериев (тестовые статистики)
Тестовая статистика – статистика, используемая для проверки конкретной статистической гипотезы.
Пример:
Статистики критериев (тестовые статистики)
Тестовая статистика – статистика, используемая для проверки конкретной статистической гипотезы.
Пример:

Проблема Беренса-Фишера
Если дисперсии сравниваемых двух независимых случайных величин не равны, то, то следует
Проблема Беренса-Фишера
Если дисперсии сравниваемых двух независимых случайных величин не равны, то, то следует

Статистика Уэлча приближенно имеет t-распределение Стьюдента, но с параметром νW, который задается выражением:
где
Статистика Уэлча приближенно имеет t-распределение Стьюдента, но с параметром νW, который задается выражением:
где

Р-значение
Для проверки нулевых гипотез с помощью статистических критериев основным приемом является вычисление
Р-значение
Для проверки нулевых гипотез с помощью статистических критериев основным приемом является вычисление

Р-значение
P-значение есть условная вероятность, а именно:
Вероятность получить наблюдаемое значение tнабл. статистики некоего
Р-значение
P-значение есть условная вероятность, а именно:
Вероятность получить наблюдаемое значение tнабл. статистики некоего

P-значение есть вероятность наблюдать исход (x), плюс все «еще более экстремальные исходы». Они
P-значение есть вероятность наблюдать исход (x), плюс все «еще более экстремальные исходы». Они
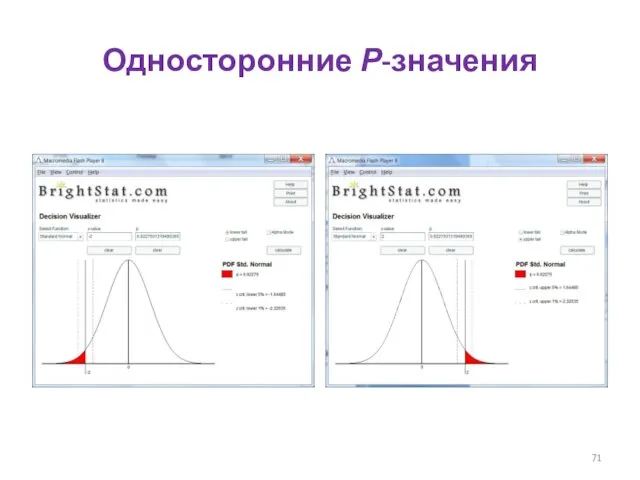
Односторонние Р-значения
Односторонние Р-значения
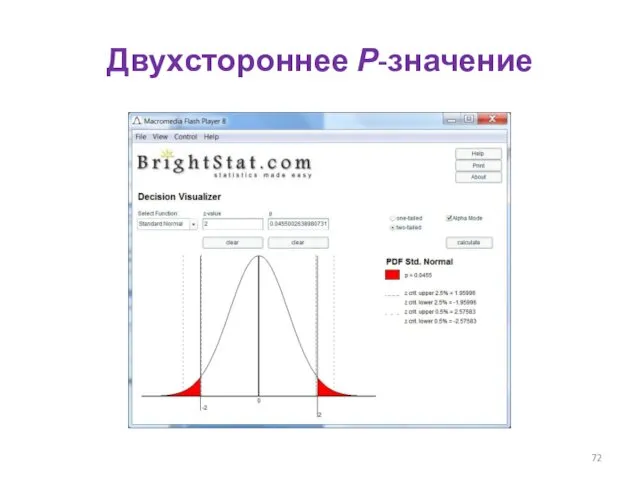
Двухстороннее Р-значение
Двухстороннее Р-значение
Основная логика использования наблюдаемого значения величины P состоит в том, что если оно
Основная логика использования наблюдаемого значения величины P состоит в том, что если оно

Выбор порога для значения P, и можно ли его обосновать?
Когда наблюдаемое значение P
Выбор порога для значения P, и можно ли его обосновать?
Когда наблюдаемое значение P

Традиционная интерпретация
значений P (шкала Michelin)
Традиционная интерпретация
значений P (шкала Michelin)
Глотов Н.В., Животовский Л.А., Хованов Н.В., Хромов-Борисов Н.Н. Биометрия, Л.: Изд-во ЛГУ, 1982.
Глотов Н.В., Животовский Л.А., Хованов Н.В., Хромов-Борисов Н.Н. Биометрия, Л.: Изд-во ЛГУ, 1982.

[0,05; 0,01] – «серая зона»
[0,05; 0,01] – «серая зона»
![[0,05; 0,01] – «серая зона»](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/55507/slide-76.jpg)
«Фильтруйте базар»: Sterne J.A.C., Davey Smith G.
Sifting the evidence – what’s wrong
«Фильтруйте базар»: Sterne J.A.C., Davey Smith G. Sifting the evidence – what’s wrong

В модных ныне изысканиях различного рода генетических предрасположенностей, когда проверяются миллионы аллелей различных
В модных ныне изысканиях различного рода генетических предрасположенностей, когда проверяются миллионы аллелей различных

Sir Ronald Aylmer Fisher
17.02.1890 – 29.07.1962
Sir Ronald Aylmer Fisher
17.02.1890 – 29.07.1962

Пожелание: «гибкие» P-значения
«В действительности ни один исследователь не пользуется фиксированным уровнем значимости с
Пожелание: «гибкие» P-значения
«В действительности ни один исследователь не пользуется фиксированным уровнем значимости с

Результаты статистического сравнение групп матерей здоровых детей и детей с ЗВУР, 1-α =
Результаты статистического сравнение групп матерей здоровых детей и детей с ЗВУР, 1-α =

Акт интеллектуальной смелости
Когда значение P очень мало, мы берем на себя смелость отклонить
Акт интеллектуальной смелости
Когда значение P очень мало, мы берем на себя смелость отклонить

Распространенный соблазн
Квинтэссенцию традиционных (частотнических) заключений при проверке статистических гипотез принято интерпретировать так:
чем
Распространенный соблазн
Квинтэссенцию традиционных (частотнических) заключений при проверке статистических гипотез принято интерпретировать так:
чем

Распространенное заблуждение
Значение P не есть вероятность нулевой гипотезы !
Поскольку P-значение вычисляется
при условии,
что справедлива
Распространенное заблуждение
Значение P не есть вероятность нулевой гипотезы !
Поскольку P-значение вычисляется
при условии,
что справедлива

P-значение не есть вероятность нулевой гипотезы!
К сожалению, даже в известной книге С.Гланца
P-значение не есть вероятность нулевой гипотезы!
К сожалению, даже в известной книге С.Гланца

Р-значение потому столь привлекательно для ученых, что с ним очень легко получить «значимый»
Р-значение потому столь привлекательно для ученых, что с ним очень легко получить «значимый»

Калибровка значения P
Sellke T., Bayarri M.J., Berger J.O.
Calibration of p values for
Калибровка значения P
Sellke T., Bayarri M.J., Berger J.O.
Calibration of p values for

Калибровка значений P
Held L. A nomogram for P values.
BMC Medical Research Methodology 2010,
Калибровка значений P
Held L. A nomogram for P values.
BMC Medical Research Methodology 2010,




«Цена» значения P
Для наглядности значения в таблице округлены до первой значащей цифры.
«Цена» значения P
Для наглядности значения в таблице округлены до первой значащей цифры.

Бейзовская интерпретация значения P
Обычно принято интерпретировать значения P как меру доказательства, предоставляемого
Бейзовская интерпретация значения P
Обычно принято интерпретировать значения P как меру доказательства, предоставляемого

Привычка свыше нам дана
Это прекрасно понимал Р.А. Фишер:
«Критерий значимости не позволяет нам
Привычка свыше нам дана
Это прекрасно понимал Р.А. Фишер:
«Критерий значимости не позволяет нам

Статистическая значимость и
размер эффекта
Эффект (различие, связь, риск, польза, ассоциация и т. п.)
Статистическая значимость и
размер эффекта
Эффект (различие, связь, риск, польза, ассоциация и т. п.)

Размер эффекта
Вопрос о клинической (практической) ценности (важности) наблюдаемого
Размера Эффекта
является ключевым при интерпретации
Размер эффекта
Вопрос о клинической (практической) ценности (важности) наблюдаемого
Размера Эффекта
является ключевым при интерпретации

Стандартизированный размер эффекта по Коуэну (Cohen) dC
Стандартизированный размер эффекта по Коуэну (Cohen) dC

Интерпретация стандартизированного размера эффекта dC http://www.sportsci.org/resource/stats/
Интерпретация стандартизированного размера эффекта dC http://www.sportsci.org/resource/stats/
Результаты статистического сравнения групп матерей здоровых детей и детей с ЗВУР, (1 -
Результаты статистического сравнения групп матерей здоровых детей и детей с ЗВУР, (1 -

Непараметрическая оценка dC
95%-й ДИ:
0,81,72,5
99%-й ДИ:
0,61,72,6
99,9%-й ДИ:
0,31,72,8
Непараметрическая оценка dC
95%-й ДИ:
0,81,72,5
99%-й ДИ:
0,61,72,6
99,9%-й ДИ:
0,31,72,8
Бейзов фактор, BF
Бейзов фактор BF принципиально отличается от значения P.
Бейзов фактор не
Бейзов фактор, BF
Бейзов фактор BF принципиально отличается от значения P.
Бейзов фактор не

Интерпретация убедительности
Бейзовых факторов, BF10 и BF01
Интерпретация убедительности
Бейзовых факторов, BF10 и BF01

Бейзов фактор, программа Bayes Factor Calculators
http://pcl.missouri.edu/bayesfactor
Бейзов фактор, программа Bayes Factor Calculators
http://pcl.missouri.edu/bayesfactor

Вывод результатов (output)
В 5555 раз (1/0,00018) более правдоподобно получить наблюдаемое различие
(ES =
Вывод результатов (output)
В 5555 раз (1/0,00018) более правдоподобно получить наблюдаемое различие
(ES =
Достаточно малое значение P заставляет думать, что произошло нечто неожиданное.
И обычно это интерпретируется
Достаточно малое значение P заставляет думать, что произошло нечто неожиданное.
И обычно это интерпретируется

Статистические предсказания и воспроизводимость
Статистические предсказания и воспроизводимость

Значение вероятностной P-величины
Значение P есть наблюдаемое значение (реализация) соответствующей случайной величины
Всякий раз мы
Значение вероятностной P-величины
Значение P есть наблюдаемое значение (реализация) соответствующей случайной величины
Всякий раз мы

Отсюда следует, что, строго говоря, на основе всего лишь одного изолированного исследования нельзя
Отсюда следует, что, строго говоря, на основе всего лишь одного изолированного исследования нельзя

Доверяя, повторяй
Часто считается, что если получен «статистически значимый» результат, то это исключает необходимость
Доверяя, повторяй
Часто считается, что если получен «статистически значимый» результат, то это исключает необходимость

Повторение – мать познания
Повторение составляет суть науки:
ученый должен всегда задумываться о том,
Повторение – мать познания
Повторение составляет суть науки:
ученый должен всегда задумываться о том,

Воспроизводимость и предсказания абсолютного размера эффекта для групп матерей здоровых детей и детей
Воспроизводимость и предсказания абсолютного размера эффекта для групп матерей здоровых детей и детей
Воспроизводимость и предсказания стандартизированного размера эффекта по Коуэну (Cohen) dC
Воспроизводимость и предсказания стандартизированного размера эффекта по Коуэну (Cohen) dC
Воспроизводимость и предсказания размеров эффекта ES и dC для групп матерей здоровых детей
Воспроизводимость и предсказания размеров эффекта ES и dC для групп матерей здоровых детей

Ошибки I и II рода
и мощность статистического критерия
Ошибки I и II рода
и мощность статистического критерия

Истинный позитив, верна H1
Истинный негатив, верна H0
Ложный позитив, ошибка I рода,
Истинный позитив, верна H1
Истинный негатив, верна H0
Ложный позитив, ошибка I рода,
Судебные ошибки
Судебные ошибки
Диагностика
Болезнь
Тест
Диагностика
Болезнь
Тест
Теория Неймана-Пирсона:
Ошибки I и II рода и мощность критерия
Действи-тельность
Критерий
Теория Неймана-Пирсона:
Ошибки I и II рода и мощность критерия
Действи-тельность
Критерий
Ошибки I и II рода
Ошибка I рода: отклонение верной нулевой гипотезы;
Аналитик решает
Ошибки I и II рода
Ошибка I рода: отклонение верной нулевой гипотезы;
Аналитик решает

Ошибки I и II рода
Ошибки I и II рода
Компромисс
Например, в случае металлодетектора
повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная
Компромисс
Например, в случае металлодетектора
повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная

Мощность статистического критерия
Мощность статистического критерия есть вероятность того, что критерий правильно отклонит ложную
Мощность статистического критерия
Мощность статистического критерия есть вероятность того, что критерий правильно отклонит ложную

Мощность статистического критерия
Мощность статистического критерия измеряет способность критерия выявлять истинные различия (эффекты).
Ее можно
Мощность статистического критерия
Мощность статистического критерия измеряет способность критерия выявлять истинные различия (эффекты).
Ее можно

Мощность отвечает на вопрос:
Если эффект (определенного размера) действительно существует, то какова вероятность того,
Мощность отвечает на вопрос:
Если эффект (определенного размера) действительно существует, то какова вероятность того,

Анализ мощности a priori или post-hoc
Анализ мощности можно проводить либо a priori, т.е.
Анализ мощности a priori или post-hoc
Анализ мощности можно проводить либо a priori, т.е.

Оценка достигнутой мощности (post hoc). Программа G*Power
http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/
Достигнутая мощность проведенного исследования составила
(1 – β)
Оценка достигнутой мощности (post hoc). Программа G*Power
http://www.psycho.uni-duesseldorf.de/aap/projects/gpower/
Достигнутая мощность проведенного исследования составила
(1 – β)
Элементы планирования эксперимента
Элементы планирования эксперимента

Программа G*Power
http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3
Оценка a priori минимально необходимого объема выборки N для достижения статистически
Программа G*Power
http://www.psycho.uni-duesseldorf.de/abteilungen/aap/gpower3
Оценка a priori минимально необходимого объема выборки N для достижения статистически

Оценка необходимых объемов выборок (a priori)
Для достижения приемлемой статистической мощности
(1 – β)
Оценка необходимых объемов выборок (a priori)
Для достижения приемлемой статистической мощности
(1 – β)
Научный метод
Ни один уважающий себя ученый не ограничится в своих исследованиях одним-единственным
Научный метод
Ни один уважающий себя ученый не ограничится в своих исследованиях одним-единственным

Культ одиночного изолированного исследования
Чрезмерное «увлечение» анализом одиночных наборов данных пронизывает почти всю статистическую
Культ одиночного изолированного исследования
Чрезмерное «увлечение» анализом одиночных наборов данных пронизывает почти всю статистическую

Джон Уайлдер Тьюки (John Wilder Tukey, 16.04.1915 — 26.07.2000)
Исследования должны быть как минимум двухэтапными.
Первый этап
Джон Уайлдер Тьюки (John Wilder Tukey, 16.04.1915 — 26.07.2000)
Исследования должны быть как минимум двухэтапными.
Первый этап

 Расширение возможностей ЦОД с помощью Microsoft Azure
Расширение возможностей ЦОД с помощью Microsoft Azure День смеха. Первое апреля в разных странах
День смеха. Первое апреля в разных странах Статистическая проверка статистических гипотез
Статистическая проверка статистических гипотез Управление успехом проекта
Управление успехом проекта Индивидуализация и дифференциация обучения
Индивидуализация и дифференциация обучения Презинтация
Презинтация Арматура систем водоснабжения зданий. Материал труб
Арматура систем водоснабжения зданий. Материал труб Квартирная электропроводка. 8 класс
Квартирная электропроводка. 8 класс Шахта лифта в панельных зданиях. Опирание перекрытий на шахту лифта. (Тест 3.1)
Шахта лифта в панельных зданиях. Опирание перекрытий на шахту лифта. (Тест 3.1) Материаловедение. Неметаллические материалы
Материаловедение. Неметаллические материалы Чтобы жить, нужно солнце, свобода и маленький цветок. 3 класс
Чтобы жить, нужно солнце, свобода и маленький цветок. 3 класс Древнеегипетская цивилизация: эпоха Древнего царства ( 2800 – 2250 г.г. до н. э.)
Древнеегипетская цивилизация: эпоха Древнего царства ( 2800 – 2250 г.г. до н. э.) Комплексная SEO оптимизация сайта учебного центра
Комплексная SEO оптимизация сайта учебного центра Правописание буквосочетаний ЦЫ-ЦИ
Правописание буквосочетаний ЦЫ-ЦИ Феномены восприятия
Феномены восприятия Презентация Величина тормозного пути транспортного средства
Презентация Величина тормозного пути транспортного средства Грыжи. Классификация грыж
Грыжи. Классификация грыж Методы экономического анализа и стратегическое управление промышленным производством
Методы экономического анализа и стратегическое управление промышленным производством Valooto Investor Deck - Apr23
Valooto Investor Deck - Apr23 Традиционные и инновационные технологии восстановления озерных экосистем
Традиционные и инновационные технологии восстановления озерных экосистем Виды транспорта. Взаимодействие, преимущества, недостатки
Виды транспорта. Взаимодействие, преимущества, недостатки Великое Княжество Тверское. 15 - 16 век
Великое Княжество Тверское. 15 - 16 век Викторина по произведениям А.П.Чехова
Викторина по произведениям А.П.Чехова Оборудование используемое для искривления ствола скважин
Оборудование используемое для искривления ствола скважин Шизофрения. Клинические формы и течение
Шизофрения. Клинические формы и течение График реализации SOFT SKILLS
График реализации SOFT SKILLS Қызылиек
Қызылиек Создание адаптивной культурно-развивающей школьной среды
Создание адаптивной культурно-развивающей школьной среды