- Matrix optimization

Содержание
- 2. Особенности современных архитектур CISC и RISC Время на решение задачи t = C*T*I C – число
- 3. CISC и RISC Что мы можем сделать? Использовать оптимизированные библиотеки и компиляторы Минимизировать количество “дорогих” инструкций
- 4. Конвейеризация Генри Форд был прав … Разбиваем операцию на стадии Например – исполнение инструкции состоит из
- 5. Конвейеризация
- 6. Конвейеризация В идеале n-стадийный конвейер дает прирост производительности в n раз На практике: переходы, исключения, прерывания,
- 7. Конвейеризация Что мы можем сделать? А) Положиться на компилятор Б) Развернуть циклы В) Выполнить потактовую ассемблерную
- 8. Развертка циклов (loop unroll) Cкалярное произведение векторов double dot_prod(int n, double *a, double * b); Стандартная
- 9. Развертка цикла в 8 раз double s1=0.0, s2=0.0, s3=0.0, s4=0.0; int n8 = (n/8) * 8;
- 10. Кэш-память Cache != Cash ;) Факт: пропускной способности памяти не хватает процессору (докажите!) Выход: кэш память
- 11. Кэш-память Единый vs. разделяемый (гарвардский) кэш Уровни: TLB, L1D, L1I, L2, L3 … Кэш с прямой
- 12. Кэш-память Как можно оптимизировать? Правильное размещение данных Локализация Аппаратная или программная предвыборка (prefetch)
- 13. Базовый пример: матричное умножение В дальнейшем считаем матрицы квадратными размерности n По определению из линейной алгебры:
- 14. Рассмотрим систему с двумя уровнями памяти: быстрой и медленной Алгоритм 1. По определению = + *
- 15. for i = 1 to n {считываем строку i матрицы A в быструю память} for j
- 16. Модификация 1: транспонирование B Доступ по строке соответствует алгоритму работы кэш-памяти Возможность использования оптимизированной функции скалярного
- 17. Будем вычислять значения c[i][j] не построчно, а в пределах блоков размерности mxm Модификация 2: переупорядочивание вычислений
- 18. Модификация 3: Блочный алгоритм Разобьем матрицы A,B,C на блоки размерности m на m. m=n / N
- 20. Скачать презентацию

Особенности современных архитектур
CISC и RISC
Время на решение задачи t = C*T*I
C
Особенности современных архитектур
CISC и RISC
Время на решение задачи t = C*T*I
C

CISC и RISC
Что мы можем сделать?
Использовать оптимизированные библиотеки и компиляторы
Минимизировать количество
CISC и RISC
Что мы можем сделать?
Использовать оптимизированные библиотеки и компиляторы
Минимизировать количество

Конвейеризация
Генри Форд был прав …
Разбиваем операцию на стадии
Например – исполнение инструкции
Конвейеризация
Генри Форд был прав …
Разбиваем операцию на стадии
Например – исполнение инструкции
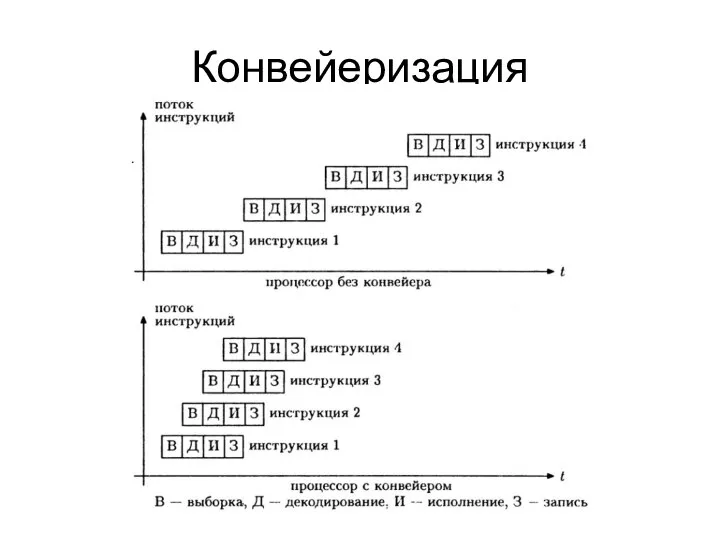
Конвейеризация
Конвейеризация

Конвейеризация
В идеале n-стадийный конвейер дает прирост производительности в n раз
На практике:
Конвейеризация
В идеале n-стадийный конвейер дает прирост производительности в n раз
На практике:

Конвейеризация
Что мы можем сделать?
А) Положиться на компилятор
Б) Развернуть циклы
В) Выполнить потактовую
Конвейеризация
Что мы можем сделать?
А) Положиться на компилятор
Б) Развернуть циклы
В) Выполнить потактовую

Развертка циклов (loop unroll)
Cкалярное произведение векторов
double dot_prod(int n, double *a, double
Развертка циклов (loop unroll)
Cкалярное произведение векторов
double dot_prod(int n, double *a, double

Развертка цикла в 8 раз
double s1=0.0, s2=0.0, s3=0.0, s4=0.0;
int n8 =
Развертка цикла в 8 раз
double s1=0.0, s2=0.0, s3=0.0, s4=0.0;
int n8 =

Кэш-память
Cache != Cash ;)
Факт: пропускной способности памяти не хватает процессору (докажите!)
Выход:
Кэш-память
Cache != Cash ;)
Факт: пропускной способности памяти не хватает процессору (докажите!)
Выход:

Кэш-память
Единый vs. разделяемый (гарвардский) кэш
Уровни: TLB, L1D, L1I, L2, L3 …
Кэш
Кэш-память
Единый vs. разделяемый (гарвардский) кэш
Уровни: TLB, L1D, L1I, L2, L3 …
Кэш

Кэш-память
Как можно оптимизировать?
Правильное размещение данных
Локализация
Аппаратная или программная предвыборка (prefetch)
Кэш-память
Как можно оптимизировать?
Правильное размещение данных
Локализация
Аппаратная или программная предвыборка (prefetch)

Базовый пример: матричное умножение
В дальнейшем считаем матрицы квадратными размерности n
По
Базовый пример: матричное умножение
В дальнейшем считаем матрицы квадратными размерности n
По

Рассмотрим систему с двумя уровнями памяти: быстрой и медленной
Алгоритм 1. По
Рассмотрим систему с двумя уровнями памяти: быстрой и медленной Алгоритм 1. По

for i = 1 to n
{считываем строку i матрицы A в
for i = 1 to n
{считываем строку i матрицы A в
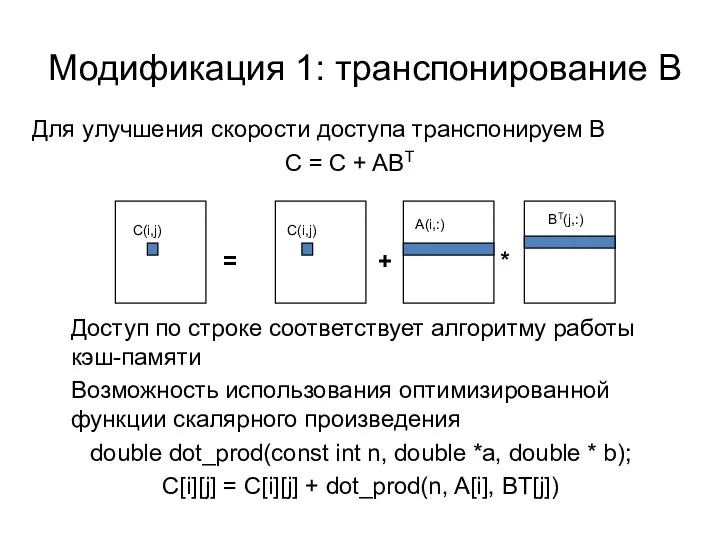
Модификация 1: транспонирование B
Доступ по строке соответствует алгоритму работы кэш-памяти
Возможность использования
Модификация 1: транспонирование B
Доступ по строке соответствует алгоритму работы кэш-памяти
Возможность использования
![Будем вычислять значения c[i][j] не построчно, а в пределах блоков](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/363213/slide-16.jpg)
Будем вычислять значения c[i][j] не построчно, а в пределах блоков размерности
Будем вычислять значения c[i][j] не построчно, а в пределах блоков размерности
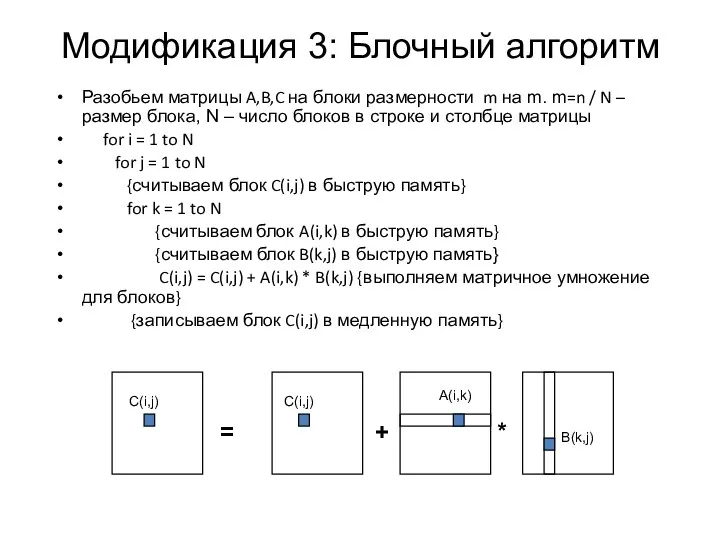
Модификация 3: Блочный алгоритм
Разобьем матрицы A,B,C на блоки размерности m на
Модификация 3: Блочный алгоритм
Разобьем матрицы A,B,C на блоки размерности m на
 Конспект урока и презентация Почитай родителей
Конспект урока и презентация Почитай родителей Заболевания печени
Заболевания печени Тревожные дети тревожных родителей
Тревожные дети тревожных родителей Ароматерапія – медицина майбутнього
Ароматерапія – медицина майбутнього Становление христианства и развитие больничного дела
Становление христианства и развитие больничного дела Логопедическая работа с учащимися 1 классов.
Логопедическая работа с учащимися 1 классов. Работа ученицы Первая железная дорога
Работа ученицы Первая железная дорога Элементы дизайна
Элементы дизайна Методы обеспечения финансовой безопасности предприятий отрасли дорожного строительства
Методы обеспечения финансовой безопасности предприятий отрасли дорожного строительства заявка на семинар
заявка на семинар Будь осторожен с огнём!
Будь осторожен с огнём! Culture and International Public Relations
Culture and International Public Relations Комплексные методы управления качеством
Комплексные методы управления качеством Бюджет МО Южно-Приморский на 2019 год и плановый период 2020 и 2021 годов
Бюджет МО Южно-Приморский на 2019 год и плановый период 2020 и 2021 годов Ряд Фурье и интеграл Фурье
Ряд Фурье и интеграл Фурье Шаблон. Руководство по использованию фирменного стиля администрации города Ноябрьска
Шаблон. Руководство по использованию фирменного стиля администрации города Ноябрьска Телефон доверия для детей и подростков, и их родителей
Телефон доверия для детей и подростков, и их родителей Робототехника в нашей жизни
Робототехника в нашей жизни sohrani_moyu_i_svoyu_zhizn
sohrani_moyu_i_svoyu_zhizn Выводы логики высказываний (2)
Выводы логики высказываний (2) Составляющие и функции операционной системы Linux
Составляющие и функции операционной системы Linux золотая хохлома
золотая хохлома Перекрытия и полы малоэтажных зданий
Перекрытия и полы малоэтажных зданий Поздравление с Днем рождения
Поздравление с Днем рождения Единицы времени 2. Календарь. 2 класс
Единицы времени 2. Календарь. 2 класс Круглый стол на тему Наркомания и СПИД: сущность и проблема (методика проведения вебинара)
Круглый стол на тему Наркомания и СПИД: сущность и проблема (методика проведения вебинара) Термообработка деревянного реквизита
Термообработка деревянного реквизита Характеристики позиционных систем счисления
Характеристики позиционных систем счисления