- Моделирование. Распознавание образов

Содержание
- 2. Построение модели
- 3. Объекты моделирования в системах статические сущности (свойства, элементы, образы), динамические сущности (процессы, тенденции, поведение, сигналы), сущности,
- 4. Два основных этапа моделирования Построение модели объекта Применение и анализ модели объекта Две цели моделирования объектов
- 5. Цели моделирования Модели анализа. Получить новое знание о свойствах моделируемой системы: О природе ее входов и
- 6. Этапы построения модели анализа 1. Уяснение природы исследуемой системы, входов и выходов. Содержательное описание системы и
- 7. Способ описания объектов - евклидово пространство; - объекты представляются точками в евклидовом пространстве их вычисленных параметров,
- 8. Количественные модели входов и выходов Детерминированные: В виде одного значения в виде векторов значений одного типа
- 9. Количественные модели входов и выходов Нечеткие, допускающие лингвистическую неопределенность В виде множества функций (лингвистической переменной) для
- 10. Распознавание образов – задача анализа Теория распознавания образов — раздел информатики и смежных дисциплин, развивающий основы
- 11. Понятие образа
- 12. Распознавание Это способность живых организмов обнаруживать в потоке информации, поступающей от органов чувств, определённые объекты, закономерности,
- 13. Распознавание образов – задача анализа Проблема распознавания образов приобрела значение в условиях информационных перегрузок, когда человек
- 14. Формальная постановка задачи Распознавание образов — это задача отнесения исходного экземпляра объекта s* к некоторому классу
- 15. Формальная постановка задачи Классическая постановка задачи распознавания образов определяется в виде задачи классификации: Дано множество объектов
- 16. 9 вариантов моделей распознавания образов
- 17. Постройте черный ящик системы моделирования решения задачи распознавания как задачи поиска
- 18. Вариант 1.Модель распознавания образов как «черный ящик» S s* m dist
- 19. Изобразите архитектуру этой системы
- 20. Добавьте критерий эффективности распознавания
- 21. критерий эффективности распознавания
- 22. Варианты моделей распознавания образов
- 23. Постройте черный ящик
- 24. Постройте архитектуру
- 25. Варианты моделей распознавания образов
- 26. Этапы построения модели распознавания образов. Эти этапы, что напоминают?
- 27. Эти этапы, что напоминают? Стандартный процесс Data Mining: CRISP-DM
- 28. Пример распознавания образов Распознавание лица — последний тренд в авторизации пользователя. Apple использует Face ID, OnePlus
- 29. Модель объекта: статическое изображение Наиболее часто в задачах распознавания образов рассматривается задача поиска изображения. Образ –
- 30. FaceNet FaceNet — нейронная сеть, которая учится преобразовывать изображения лица в компактное евклидово пространство, где эвклидово
- 31. FaceNet FaceNet (на python) — сиамская сеть. Сиамская сеть — тип архитектуры нейросети, который обучается на
- 32. Алгоритм распознавания лиц
- 37. 3 D распознавание Обнаружение: получение снимка при помощи цифрового сканирования существующей фотографии (2D) или видео для
- 38. Российский банк «Открытие» представил собственное уникальное решение, разработанное под технологическим брендом Open Garage: перевод денег по
- 39. В задаче распознавания объектов существует несколько серьезных проблем: сильная зависимость от начальных параметров (необходимо знать достаточно
- 40. Направления в распознавании образов Развитие методов обучения для распознавания в условиях неполноты информации; Изучение способностей к
- 41. Обработка цифровых сигналов
- 42. Анализ сигналов[править | править код] Анализ сигналов — извлечение информации из сигнала, например, выявление и обособление
- 43. Для аналоговых сигналов обработка может включать усиление и фильтрацию, модуляцию и демодуляцию. Для цифровых сигналов также
- 44. Обнаружение сигнала — задача обнаружения сигнала на фоне шумов и помех. Различение сигнала — задача распознавания
- 45. Распознавание речи — одна из самых интересных и сложных задач искусственного интеллекта. Здесь задействованы достижения весьма
- 47. цифровые голосовые помощники
- 48. https://www.stonetemple.com/digital-personal-assistants-study/ Alexa Cortana Invoke Google Assistant on Google Home Google Assistant on a Smartphone Siri
- 49. Knowledge Graph – когда люди ищут информацию, они ищут не только сайты на которых может быть
- 50. Структура теста Мы собрали набор из 4 952 вопросов, чтобы спросить каждого личного помощника. Мы задали
- 51. https://roem.ru/31-07-2018/272581/google-assistant-rus/ 2018 г. Голосовой помощник Google Assistant, появившийся в 2016 году, стал доступен на русском языке,
- 52. В октябре 2017 года «Яндекс» запустил голосового помощника «Алису» в мобильном приложении, который в разговоре также
- 53. «Алиса» разговаривает голосом российской актрисы дубляжа Татьяны Шитовой, дублировавшей на русский язык большинство ролей актрисы Скарлетт
- 54. Мы, наверное, первые в мире пытаемся сделать вот что: мы тоже используем редакторские ответы на вопросы,
- 55. Корта́на — виртуальная голосовая помощница с элементами искусственного интеллекта от Microsoft для Windows Phone 8.1[1], Microsoft
- 56. Персональная помощница Кортана призвана предугадывать потребности пользователя. При желании ей можно дать доступ к вашим личным
- 57. Голосовая помощница Кортана интегрирована в Windows 10, но не доступна на русском. Она не выступает в
- 58. цифровые голосовые помощники Алекса, известная просто как Алекса, является виртуальным помощником, разработанным Amazon, впервые используемым в
- 59. Алекса, известная просто как Алекса, является виртуальным помощником, разработанным Amazon, впервые используемым в Amazon Echo и
- 60. Amazon Echo Dot Благодаря семи микрофонам, технологии шумоподавлению, Echo слышит вас в любом направлении - даже
- 61. Переводы с помощью голосовых команд пока доступны только для владельцев iOS-устройств. «Бинбанк» реализовал опцию на основе
- 62. «Умные» голосовые помощники базируются на архитектуре нейронных сетей и технологии машинного обучения. При этом надо понимать,
- 63. Все вышесказанное не значит, что современные голосовые помощники на базе ИИ бесперспективны и бесполезны. Уже сейчас
- 64. Речевые технологии распознают, анализируют и синтезируют голос человека. Имитация речи, восприятие смысла фраз, конвертация речи в
- 65. Речевые технологии демонстрируют впечатляющие результаты в разных сферах. Так, в области трансформации речи в текст тон
- 66. Используемые технологии и методы Распознавание речи – это процесс преобразования речевого сигнала в цифровую информацию. Именно
- 67. Голосовой поиск (или голосовая команда) – функция поиска информации без использования клавиатуры. Пользователь произносит фразу, а
- 68. Интеллектуальные голосовые помощники (или голосовые ассистенты) – это веб-сервисы, которые объединяют технологию распознавания речи и текста
- 69. Звучащая речь для нас — это, прежде всего, цифровой сигнал. И если мы посмотрим на запись
- 70. Еще один важный аспект акустики — вероятность перехода между различными фонемами. Из опыта мы знаем, что
- 71. Более формально HMM можно представить следующим образом. Во-первых, введем понятие эмиссии. Как мы помним из предыдущего
- 72. Пусть в нашем словаре распознавания всего два слова: «Да» ([д][а]) и «Нет» ([н'][е][т]). Таким образом, у
- 73. Однако акустическая модель — это всего лишь одна из составляющих системы. Что делать, если словарь распознавания
- 74. В последние годы основной тренд исследований в области распознавания речи смещается в сторону отказа от использования
- 75. Google опубликовала данные о создании инновационного алгоритма диаризации — разделения входящего аудиопотока на однородные сегменты в
- 76. Разработчики из Университета Цинхуа разработали голосовой помощник для смартфонов, который распознаёт команды по движениям губ пользователя.
- 77. Стохастические модели процессов Стохастические процессы, задающие зависимость между четким временем и случайной величиной с известным законом
- 78. Модель временного ряда yt = ft + ψt + ξt yt – заданный временной ряд, ft
- 79. Анализ поведения путем декомпозиции ВР Динамические свойства выхода Y (верхний график): Наличие восходящего тренда Наличие сезонности
- 80. Нечеткие модели входов и выходов Л. Заде предложил по аналогии с теорией вероятности использовать функцию в
- 81. В том случае, если значения функции принадлежности нечеткого множества представлены точными числовыми значениями, такие нечеткие множества
- 82. Нечеткий временной ряд как модель процесса Предположим, что задан процесс, состояния которого описываются n значениями одной
- 83. Нечеткие процессы
- 84. Нечеткие процессы
- 85. Методологические основы нечеткого моделирования ВР Теорема нечеткой аппроксимации (Kosko, 1992) Теорема аппроксимации любой непрерывной функции с
- 87. Пример. Определите цель моделирования
- 88. Обобщенная регрессионно-нечеткая модель сервера
- 90. Введены три лингвистические переменные
- 91. Результаты фаззификации значений выходных характеристик сервера
- 92. Правила нечеткой модели
- 93. Нечеткое моделирование Для всех технических параметров построены правила нечеткого вывода: Сформированы правила нечеткого вывода для прогноза
- 96. Скачать презентацию

Построение модели
Построение модели

Объекты моделирования в системах
статические сущности (свойства, элементы, образы),
динамические сущности (процессы,
Объекты моделирования в системах
статические сущности (свойства, элементы, образы),
динамические сущности (процессы,

Два основных этапа моделирования
Построение модели объекта
Применение и анализ модели объекта
Две
Два основных этапа моделирования
Построение модели объекта
Применение и анализ модели объекта
Две

Цели моделирования
Модели анализа. Получить новое знание о свойствах моделируемой системы:
О природе
Цели моделирования
Модели анализа. Получить новое знание о свойствах моделируемой системы:
О природе

Этапы построения модели анализа
1. Уяснение природы исследуемой системы, входов и выходов.
Этапы построения модели анализа
1. Уяснение природы исследуемой системы, входов и выходов.

Способ описания объектов
- евклидово пространство;
- объекты представляются точками в евклидовом
Способ описания объектов
- евклидово пространство;
- объекты представляются точками в евклидовом

Количественные модели входов и выходов
Детерминированные:
В виде одного значения
в виде векторов
Количественные модели входов и выходов
Детерминированные:
В виде одного значения
в виде векторов

Количественные модели входов и выходов
Нечеткие, допускающие лингвистическую неопределенность
В виде множества
Количественные модели входов и выходов
Нечеткие, допускающие лингвистическую неопределенность
В виде множества

Распознавание образов – задача анализа
Теория распознавания образов — раздел информатики и смежных дисциплин, развивающий
Распознавание образов – задача анализа
Теория распознавания образов — раздел информатики и смежных дисциплин, развивающий
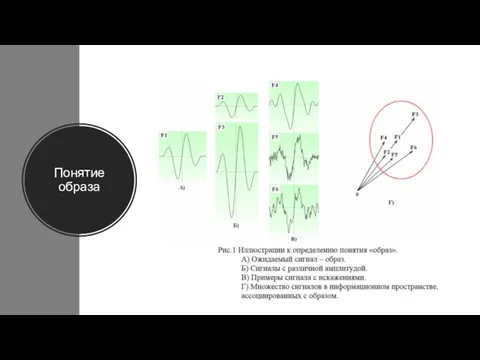
Понятие образа
Понятие образа

Распознавание
Это способность живых организмов обнаруживать в потоке информации, поступающей от органов
Распознавание
Это способность живых организмов обнаруживать в потоке информации, поступающей от органов

Распознавание образов – задача анализа
Проблема распознавания образов приобрела значение в условиях
Распознавание образов – задача анализа
Проблема распознавания образов приобрела значение в условиях

Формальная постановка задачи
Распознавание образов — это задача отнесения исходного экземпляра объекта
Формальная постановка задачи
Распознавание образов — это задача отнесения исходного экземпляра объекта

Формальная постановка задачи
Классическая постановка задачи распознавания образов определяется в виде задачи
Формальная постановка задачи
Классическая постановка задачи распознавания образов определяется в виде задачи

9 вариантов моделей распознавания образов
9 вариантов моделей распознавания образов

Постройте черный ящик системы моделирования решения задачи распознавания как задачи поиска
Постройте черный ящик системы моделирования решения задачи распознавания как задачи поиска
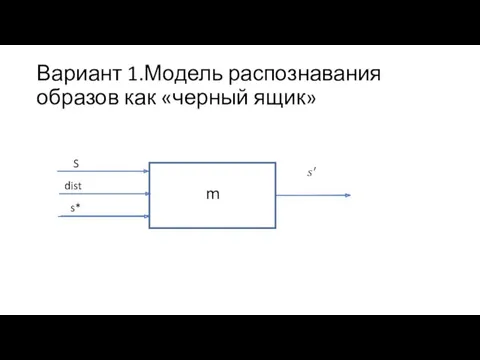
Вариант 1.Модель распознавания образов как «черный ящик»
S
s*
m
dist
Вариант 1.Модель распознавания образов как «черный ящик»
S
s*
m
dist

Изобразите архитектуру этой системы
Изобразите архитектуру этой системы

Добавьте критерий эффективности распознавания
Добавьте критерий эффективности распознавания

критерий эффективности распознавания
критерий эффективности распознавания

Варианты моделей распознавания образов
Варианты моделей распознавания образов

Постройте черный ящик
Постройте черный ящик

Постройте архитектуру
Постройте архитектуру

Варианты моделей распознавания образов
Варианты моделей распознавания образов

Этапы построения модели распознавания образов. Эти этапы, что напоминают?
Этапы построения модели распознавания образов. Эти этапы, что напоминают?

Эти этапы, что напоминают? Стандартный процесс Data Mining: CRISP-DM
Эти этапы, что напоминают? Стандартный процесс Data Mining: CRISP-DM

Пример распознавания образов
Распознавание лица — последний тренд в авторизации пользователя. Apple использует
Пример распознавания образов
Распознавание лица — последний тренд в авторизации пользователя. Apple использует

Модель объекта: статическое изображение
Наиболее часто в задачах распознавания образов рассматривается задача
Модель объекта: статическое изображение
Наиболее часто в задачах распознавания образов рассматривается задача

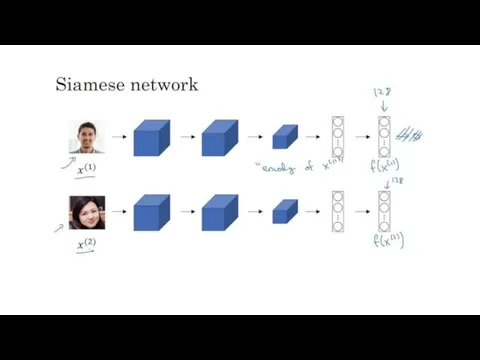
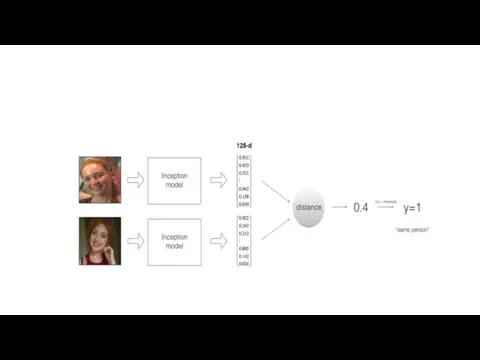
FaceNet
FaceNet — нейронная сеть, которая учится преобразовывать изображения лица в компактное евклидово пространство,
FaceNet
FaceNet — нейронная сеть, которая учится преобразовывать изображения лица в компактное евклидово пространство,

FaceNet
FaceNet (на python) — сиамская сеть. Сиамская сеть — тип архитектуры
FaceNet
FaceNet (на python) — сиамская сеть. Сиамская сеть — тип архитектуры

Алгоритм распознавания лиц
Алгоритм распознавания лиц



3 D распознавание
Обнаружение: получение снимка при помощи цифрового сканирования существующей фотографии
3 D распознавание
Обнаружение: получение снимка при помощи цифрового сканирования существующей фотографии

Российский банк «Открытие» представил собственное уникальное решение, разработанное под технологическим брендом
Российский банк «Открытие» представил собственное уникальное решение, разработанное под технологическим брендом

В задаче распознавания объектов существует несколько серьезных проблем:
сильная зависимость от начальных
В задаче распознавания объектов существует несколько серьезных проблем:
сильная зависимость от начальных

Направления в распознавании образов
Развитие методов обучения для распознавания в условиях неполноты
Направления в распознавании образов
Развитие методов обучения для распознавания в условиях неполноты

Обработка цифровых сигналов
Обработка цифровых сигналов
![Анализ сигналов[править | править код] Анализ сигналов — извлечение информации](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/66349/slide-41.jpg)
Анализ сигналов[править | править код]
Анализ сигналов — извлечение информации из сигнала, например, выявление и обособление
Анализ сигналов[править | править код]
Анализ сигналов — извлечение информации из сигнала, например, выявление и обособление

Для аналоговых сигналов обработка может включать усиление и фильтрацию, модуляцию и демодуляцию.
Для аналоговых сигналов обработка может включать усиление и фильтрацию, модуляцию и демодуляцию.

Обнаружение сигнала — задача обнаружения сигнала на фоне шумов и помех.
Различение
Обнаружение сигнала — задача обнаружения сигнала на фоне шумов и помех.
Различение

Распознавание речи — одна из самых интересных и сложных задач искусственного
Распознавание речи — одна из самых интересных и сложных задач искусственного


цифровые голосовые помощники
цифровые голосовые помощники
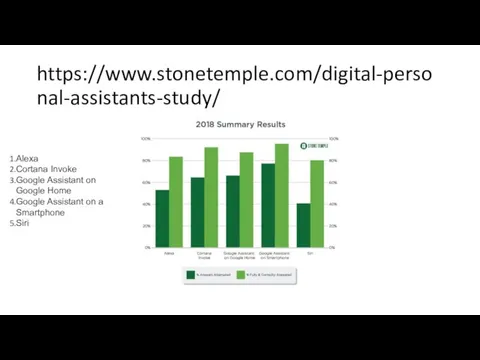
https://www.stonetemple.com/digital-personal-assistants-study/
Alexa
Cortana Invoke
Google Assistant on Google Home
Google Assistant on a Smartphone
Siri
https://www.stonetemple.com/digital-personal-assistants-study/
Alexa
Cortana Invoke
Google Assistant on Google Home
Google Assistant on a Smartphone
Siri

Knowledge Graph – когда люди ищут информацию, они ищут не только сайты
Knowledge Graph – когда люди ищут информацию, они ищут не только сайты

Структура теста
Мы собрали набор из 4 952 вопросов, чтобы спросить каждого
Структура теста
Мы собрали набор из 4 952 вопросов, чтобы спросить каждого

https://roem.ru/31-07-2018/272581/google-assistant-rus/
2018 г. Голосовой помощник Google Assistant, появившийся в 2016 году, стал доступен на русском языке, рассказали представители
https://roem.ru/31-07-2018/272581/google-assistant-rus/
2018 г. Голосовой помощник Google Assistant, появившийся в 2016 году, стал доступен на русском языке, рассказали представители

В октябре 2017 года «Яндекс» запустил голосового помощника «Алису» в мобильном приложении, который в разговоре также не ограничивается шаблонными ответами.
В октябре 2017 года «Яндекс» запустил голосового помощника «Алису» в мобильном приложении, который в разговоре также не ограничивается шаблонными ответами.

«Алиса» разговаривает голосом российской актрисы дубляжа Татьяны Шитовой, дублировавшей на русский язык
«Алиса» разговаривает голосом российской актрисы дубляжа Татьяны Шитовой, дублировавшей на русский язык

Мы, наверное, первые в мире пытаемся сделать вот что: мы тоже используем редакторские ответы на вопросы, но добавляем
Мы, наверное, первые в мире пытаемся сделать вот что: мы тоже используем редакторские ответы на вопросы, но добавляем

Корта́на — виртуальная голосовая помощница с элементами искусственного интеллекта от Microsoft для Windows Phone 8.1[1], Microsoft Band[2][3], Windows 10, Android, Xbox
Корта́на — виртуальная голосовая помощница с элементами искусственного интеллекта от Microsoft для Windows Phone 8.1[1], Microsoft Band[2][3], Windows 10, Android, Xbox

Персональная помощница Кортана призвана предугадывать потребности пользователя. При желании ей можно
Персональная помощница Кортана призвана предугадывать потребности пользователя. При желании ей можно

Голосовая помощница Кортана интегрирована в Windows 10, но не доступна на русском.
Голосовая помощница Кортана интегрирована в Windows 10, но не доступна на русском.

цифровые голосовые помощники
Алекса, известная просто как Алекса, является виртуальным помощником, разработанным
цифровые голосовые помощники
Алекса, известная просто как Алекса, является виртуальным помощником, разработанным

Алекса, известная просто как Алекса, является виртуальным помощником, разработанным Amazon, впервые
Алекса, известная просто как Алекса, является виртуальным помощником, разработанным Amazon, впервые

Amazon Echo Dot
Благодаря семи микрофонам, технологии шумоподавлению, Echo слышит вас в
Amazon Echo Dot
Благодаря семи микрофонам, технологии шумоподавлению, Echo слышит вас в

Переводы с помощью голосовых команд пока доступны только для владельцев iOS-устройств.
Переводы с помощью голосовых команд пока доступны только для владельцев iOS-устройств.

«Умные» голосовые помощники базируются на архитектуре нейронных сетей и технологии машинного
«Умные» голосовые помощники базируются на архитектуре нейронных сетей и технологии машинного

Все вышесказанное не значит, что современные голосовые помощники на базе ИИ
Все вышесказанное не значит, что современные голосовые помощники на базе ИИ

Речевые технологии распознают, анализируют и синтезируют голос человека. Имитация речи, восприятие
Речевые технологии распознают, анализируют и синтезируют голос человека. Имитация речи, восприятие

Речевые технологии демонстрируют впечатляющие результаты в разных сферах. Так, в области
Речевые технологии демонстрируют впечатляющие результаты в разных сферах. Так, в области

Используемые технологии и методы
Распознавание речи – это процесс преобразования речевого сигнала в цифровую информацию.
Используемые технологии и методы
Распознавание речи – это процесс преобразования речевого сигнала в цифровую информацию.

Голосовой поиск (или голосовая команда) – функция поиска информации без использования клавиатуры. Пользователь произносит фразу, а приложение
Голосовой поиск (или голосовая команда) – функция поиска информации без использования клавиатуры. Пользователь произносит фразу, а приложение

Интеллектуальные голосовые помощники (или голосовые ассистенты) – это веб-сервисы, которые объединяют технологию распознавания речи
Интеллектуальные голосовые помощники (или голосовые ассистенты) – это веб-сервисы, которые объединяют технологию распознавания речи

Звучащая речь для нас — это, прежде всего, цифровой сигнал. И
Звучащая речь для нас — это, прежде всего, цифровой сигнал. И

Еще один важный аспект акустики — вероятность перехода между различными фонемами.
Еще один важный аспект акустики — вероятность перехода между различными фонемами.

Более формально HMM можно представить следующим образом. Во-первых, введем понятие эмиссии.
Более формально HMM можно представить следующим образом. Во-первых, введем понятие эмиссии.
![Пусть в нашем словаре распознавания всего два слова: «Да» ([д][а])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/66349/slide-71.jpg)
Пусть в нашем словаре распознавания всего два слова: «Да» ([д][а]) и
Пусть в нашем словаре распознавания всего два слова: «Да» ([д][а]) и

Однако акустическая модель — это всего лишь одна из составляющих системы.
Однако акустическая модель — это всего лишь одна из составляющих системы.

В последние годы основной тренд исследований в области распознавания речи смещается
В последние годы основной тренд исследований в области распознавания речи смещается

Google опубликовала данные о создании инновационного алгоритма диаризации — разделения входящего аудиопотока на
Google опубликовала данные о создании инновационного алгоритма диаризации — разделения входящего аудиопотока на

Разработчики из Университета Цинхуа разработали голосовой помощник для смартфонов, который распознаёт команды по движениям губ пользователя. Эта
Разработчики из Университета Цинхуа разработали голосовой помощник для смартфонов, который распознаёт команды по движениям губ пользователя. Эта

Стохастические модели процессов
Стохастические процессы, задающие зависимость между четким временем и случайной
Стохастические модели процессов
Стохастические процессы, задающие зависимость между четким временем и случайной

Модель временного ряда
yt = ft + ψt + ξt
yt –
Модель временного ряда
yt = ft + ψt + ξt
yt –
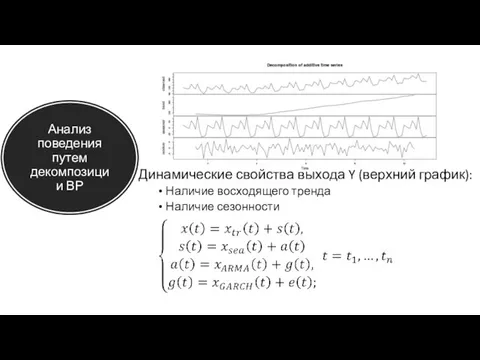
Анализ поведения путем декомпозиции ВР
Динамические свойства выхода Y (верхний график):
Наличие восходящего
Анализ поведения путем декомпозиции ВР
Динамические свойства выхода Y (верхний график):
Наличие восходящего

Нечеткие модели входов и выходов
Л. Заде предложил по аналогии с теорией
Нечеткие модели входов и выходов
Л. Заде предложил по аналогии с теорией
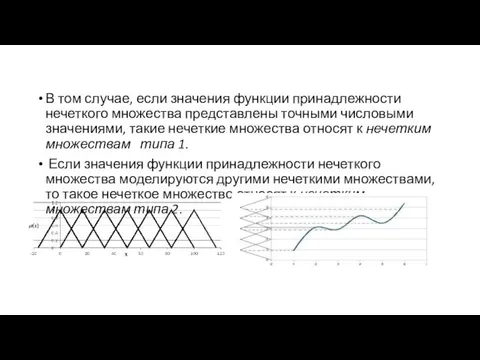
В том случае, если значения функции принадлежности нечеткого множества представлены точными
В том случае, если значения функции принадлежности нечеткого множества представлены точными
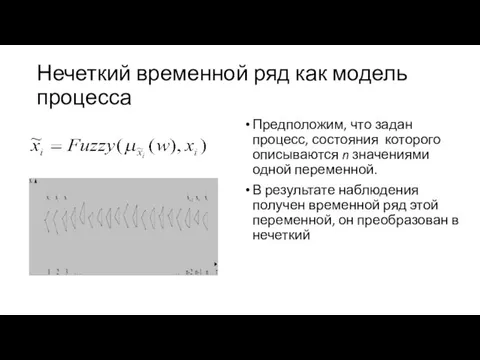
Нечеткий временной ряд как модель процесса
Предположим, что задан процесс, состояния которого
Нечеткий временной ряд как модель процесса
Предположим, что задан процесс, состояния которого

Нечеткие процессы
Нечеткие процессы

Нечеткие процессы
Нечеткие процессы

Методологические основы нечеткого моделирования ВР
Теорема нечеткой аппроксимации (Kosko, 1992)
Теорема аппроксимации любой
Методологические основы нечеткого моделирования ВР
Теорема нечеткой аппроксимации (Kosko, 1992)
Теорема аппроксимации любой


Пример. Определите цель моделирования
Пример. Определите цель моделирования

Обобщенная регрессионно-нечеткая модель сервера
Обобщенная регрессионно-нечеткая модель сервера


Введены три лингвистические переменные
Введены три лингвистические переменные
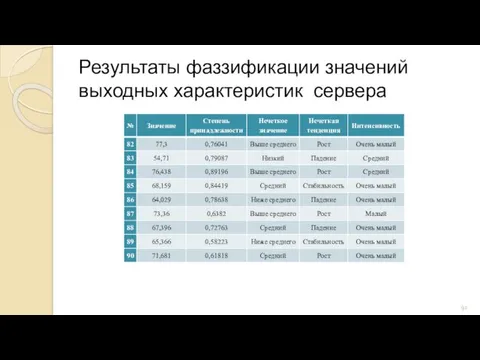
Результаты фаззификации значений выходных характеристик сервера
Результаты фаззификации значений выходных характеристик сервера

Правила нечеткой модели
Правила нечеткой модели
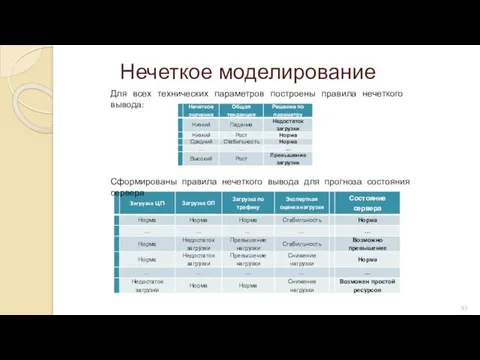
Нечеткое моделирование
Для всех технических параметров построены правила нечеткого вывода:
Сформированы правила нечеткого
Нечеткое моделирование
Для всех технических параметров построены правила нечеткого вывода:
Сформированы правила нечеткого
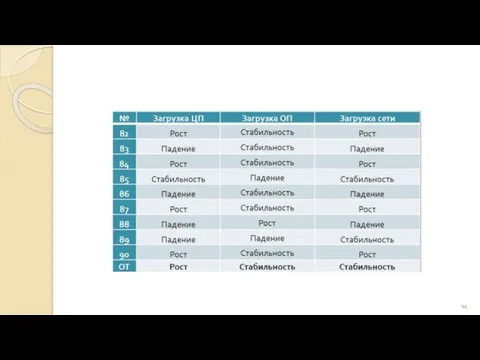
 Синодальный перевод Библии
Синодальный перевод Библии Языковые паттерны (предикаты)
Языковые паттерны (предикаты) My family traditions connected with holidays
My family traditions connected with holidays Классический преобразователь напряжения
Классический преобразователь напряжения Маркировка зарубежных полупроводниковых компонентов
Маркировка зарубежных полупроводниковых компонентов Движение вдоль линии с одним датчиком
Движение вдоль линии с одним датчиком Стратегия научно-технологического развития Российской Федерации
Стратегия научно-технологического развития Российской Федерации Учитель года 2015-2016
Учитель года 2015-2016 Презентация к занятию по внеурочной деятельности Многоцветные кружева родного края Алексеевский район
Презентация к занятию по внеурочной деятельности Многоцветные кружева родного края Алексеевский район Роль логистики в организации
Роль логистики в организации Четвериков Андрей
Четвериков Андрей Презентация Искусственные острова мира
Презентация Искусственные острова мира Масса. Плотность. Объем
Масса. Плотность. Объем Основы работы с Единой Информационной системой в сфере закупок
Основы работы с Единой Информационной системой в сфере закупок Основные урологические синдромы
Основные урологические синдромы Приложение №1 к уроку Природные зоны Русской равнины
Приложение №1 к уроку Природные зоны Русской равнины Суффикс как часть слова. Урок русского языка во 2 классе
Суффикс как часть слова. Урок русского языка во 2 классе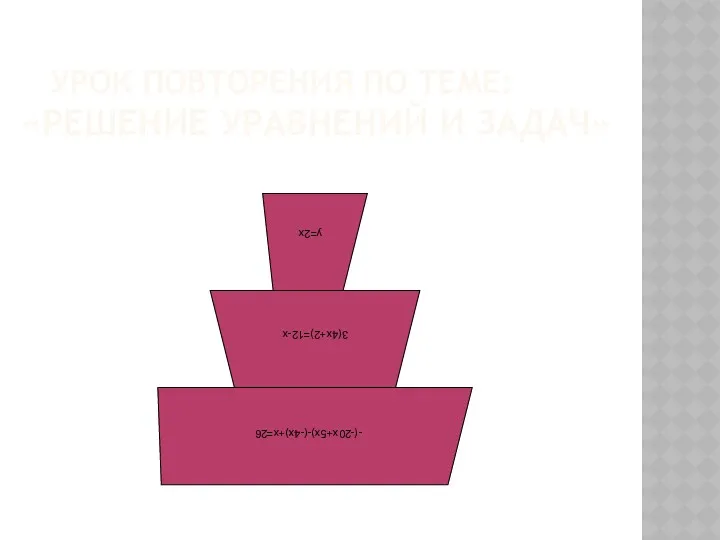 Презентация к открытому уроку по математике в 6 классе Тема Решение уравнений и задач
Презентация к открытому уроку по математике в 6 классе Тема Решение уравнений и задач Логосказка для малышей
Логосказка для малышей Патология. Общая и частная
Патология. Общая и частная Central Nervous System
Central Nervous System Необычное путешествие
Необычное путешествие Электрическая емкость. Конденсаторы
Электрическая емкость. Конденсаторы Конструкция скважины
Конструкция скважины Особенности производства сыров из козьего молока
Особенности производства сыров из козьего молока Попереднє очищення води методом вапнування
Попереднє очищення води методом вапнування Подготовка к экзаменам по русскому языку (8 класс)
Подготовка к экзаменам по русскому языку (8 класс) Русь в середине XI - начале XII века
Русь в середине XI - начале XII века