- Распределенные базы данных

Содержание
- 2. Процессы децентрализации и информационной интеграции, происходящие в современном мире характеризуются следующими признаками. 1. Много организационно и
- 3. Понятие распределенной БД (DDB) Под распределенной (Distributed DataBase - DDB) обычно подразумевают базу данных, включающую фрагменты
- 4. Определение идеальной DDB Криса Дейта Локальная автономия (local autonomy) Независимость узлов (no reliance on central site)
- 5. 1. Локальная автономия Это качество означает, что управление данными на каждом из узлов распределенной системы выполняется
- 6. 2. Независимость от центрального узла В идеальной распределенной системе все узлы сети равноправны и независимы, а
- 7. 3. Непрерывные операции Это качество можно трактовать как возможность непрерывного доступа к данным (известное выражение "24
- 8. 4. Прозрачность расположения Это свойство означает полную прозрачность расположения данных. Пользователь, обращающийся к DDB, ничего не
- 9. 5. Прозрачная фрагментация Это свойство трактуется как возможность распределенного (то есть на различных узлах) размещения данных,
- 10. 6. Прозрачность тиражирования Тиражирование данных - это асинхронный (в общем случае) процесс переноса изменений объектов исходной
- 11. 7. Обработка распределенных запросов Это свойство DDB трактуется как возможность выполнения операций выборки над распределенной базой
- 12. 8. Обработка распределенных транзакций Это качество DDB можно трактовать как возможность выполнения операций обновления распределенной базы
- 13. 9. Независимость от оборудования Это свойство означает, что в качестве узлов распределенной системы могут выступать компьютеры
- 14. 10. Независимость от операционных систем Это качество вытекает из предыдущего и означает многообразие операционных систем, управляющих
- 15. 11. Прозрачность сети Доступ к любым базам данных может осуществляться по сети. Спектр поддерживаемых конкретной СУБД
- 16. 12. Независимость от баз данных Это качество означает, что в распределенной системе могут мирно сосуществовать СУБД
- 17. ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ DDB Возникающие проблемы: Проблемы техники представлений (Views) Проблема целостности данных Проблема обработка распределенных запросов
- 18. Определение представления Представлением называется сохраняемый в БД авторизованный глобальный запрос на выборку. Авторизованность означает возможность запуска
- 19. В результате таких глобальных авторизованных запросов для конкретного пользователя создается некая виртуальная БД, со своим перечнем
- 20. I. Размещение системного каталога БД: ядро СУБД должно узнавать, где в самом деле находятся данные. Требование
- 21. Проблема целостности данных В DDB поддержка целостности и согласованности данных, ввиду свойств 1-2, представляет собой сложную
- 22. Если в DDB предусмотрено тиражирование данных, то это сразу предъявляет дополнительные жесткие требования к поддержки целостности
- 23. Обработка распределенных запросов Обработка распределенных запросов (Distributed Query -DQ) - задача, более сложная, нежели обработка локальных
- 24. Межоперабельность Во-первых, - это качество, позволяющее обмениваться данными между БД различных поставщиков. Как, например, тиражировать данные
- 25. ОТСТУПЛЕНИЕ ОТ ПРИНЦИПОВ ИДЕАЛЬНОЙ DDB КРИСА ДЕЙТА Если в жертву приносится принцип 2 (независимость узлов ),
- 26. ТЕХНОЛОГИИ "КЛИЕНТ-СЕРВЕР" Основной принцип данной технологии заключается в разделении функций стандартного клиентского приложения на четыре группы:
- 27. Логические компоненты СУБД В соответствии с этим в любой СУБД выделяются следующие логические компоненты: компонент представления,
- 28. Модели технологии «клиент-сервер» Модель файлового сервера (File Server — FS); Модель доступа к удаленным данным (Remote
- 29. 7.6.3 Модель файлового сервера (FS) Сетевая ОС
- 30. FS-модель является базовой для локальных сетей ПЭВМ. Суть модели проста. Один из компьютеров в сети считается
- 31. FS-модель и персональные СУБД FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского
- 32. Недостатки модели FS К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению),
- 33. Модель доступа к удаленным данным (RDA) ЯДРО СУБД
- 34. Отличие RDA – модели от FS Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа
- 35. Достоинство RDA-модели Основное достоинство RDA-модели заключается в унификации интерфейса "клиент-сервер" в виде языка SQL. Действительно, взаимодействие
- 36. Пассивная роль ядра СУБД в RDA Клиент направляет запросы к информационным ресурсам (например, к базам данных)
- 37. Недостатки RDA-модели К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов
- 38. Модель сервера базы данных (DBS) ЯДРО СУБД
- 39. Достоинства DBS-модели В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен
- 40. Модель сервера базы данных реализована в реляционных СУБД. Ее основу составляет механизм хранимых процедур — средство
- 41. Недостатки DBS-модели К недостаткам можно отнести ограниченность средств, используемых для написания хранимых процедур (ХП), которые представляют
- 42. Модель сервера приложений (AS) Application Programming Interface (API) - стандарт прикладного программного интерфейса
- 43. Реализация AS-модели В AS-модели процесс, выполняющийся на компьютере-клиенте, отвечает за интерфейс с пользователем (то есть реализует
- 44. Двухзвенная схема разделения функций RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные
- 45. Трехзвенная схема разделения функций В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как
- 46. Программное обеспечение промежуточного слоя (Middleware) Трехзвенной AS – модель можно считать и потому, что в ней
- 47. Главная ошибка, которая может быть совершена при построении современных распределенных систем - это полное игнорирование ПО
- 48. В случае двухзвенной модели клиент явным образом запрашивает данные, зная структуру базы данных (имеет место так
- 49. В случае трехзвенной модели клиент явно запрашивает один из сервисов (предоставляемых прикладным компонентом), передавая ему некоторое
- 50. Вывод по моделям «Клиент-сервер» Таким образом, речь идет о двух принципиально разных подходах к построению распределенных
- 51. Технология тиражирования В отличие от распределенных баз DDB, тиражирование данных (Data Replication). предполагает отказ от их
- 52. Тиражирование данных Тиражирование данных — это асинхронный перенос изменений объектов исходной базы данных в БД, принадлежащие
- 53. Технология распределенных БД и технология тиражирования данных — в определенном смысле антиподы. Краеугольный камень первой (DDB)
- 54. Поскольку БД распределена по нескольким территориально удаленным узлам, объединенным медленными и ненадежными каналами связи, а число
- 55. Преимущества технологии тиражирования Технология тиражирования данных не требует синхронной фиксации изменений (и в этом ее сильная
- 56. Жизненность технологии тиражирования подтверждается опытом ее использования в области, предъявляющей повышенные требования к надежности — в
- 57. Недостатки технологии тиражирования Технология тиражирования данных не лишена некоторых недостатков, вытекающих из ее специфики. Например, невозможно
- 58. Следовательно, при проектировании распределенной информационной системы с использованием технологии тиражирования данных необходимо предусмотреть конфликтные ситуации (тупиковые
- 59. Технология объектного связывания Современные настольные СУБД обеспечивают возможность прямого доступа к объектам (таблицам, запросам, формам) внешних
- 60. В системный каталог текущей БД помещаются все необходимые сведения о связанных объектах — внутреннее имя и
- 61. Ядро СУБД при обращении к данным связанного объекта по системному каталогу текущей БД находит сведения о
- 62. Недостатки технологии объектного связывания 1. Данная технология построения распределенных систем при больших объемах данных в связанных
- 63. 2. Не менее существенной проблемой является отсутствие надежных механизмов безопасности данных и обеспечения ограничений целостности. Так
- 64. 3. Существенной проблемой технологий объектного связывания является появление «брешей» в системах защиты данных и разграничения доступа.
- 66. Скачать презентацию

Процессы децентрализации и информационной интеграции, происходящие в современном мире характеризуются
Процессы децентрализации и информационной интеграции, происходящие в современном мире характеризуются

Понятие распределенной БД (DDB)
Под распределенной (Distributed DataBase - DDB) обычно подразумевают
Понятие распределенной БД (DDB)
Под распределенной (Distributed DataBase - DDB) обычно подразумевают

Определение идеальной DDB Криса Дейта
Локальная автономия (local autonomy)
Независимость узлов (no
Определение идеальной DDB Криса Дейта
Локальная автономия (local autonomy)
Независимость узлов (no

1. Локальная автономия
Это качество означает, что управление данными на каждом из
1. Локальная автономия
Это качество означает, что управление данными на каждом из

2. Независимость от центрального узла
В идеальной распределенной системе все узлы сети
2. Независимость от центрального узла
В идеальной распределенной системе все узлы сети

3. Непрерывные операции
Это качество можно трактовать как возможность непрерывного доступа к
3. Непрерывные операции
Это качество можно трактовать как возможность непрерывного доступа к

4. Прозрачность расположения
Это свойство означает полную прозрачность расположения данных. Пользователь,
4. Прозрачность расположения
Это свойство означает полную прозрачность расположения данных. Пользователь,

5. Прозрачная фрагментация
Это свойство трактуется как возможность распределенного (то есть на
5. Прозрачная фрагментация
Это свойство трактуется как возможность распределенного (то есть на

6. Прозрачность тиражирования
Тиражирование данных - это асинхронный (в общем случае) процесс
6. Прозрачность тиражирования
Тиражирование данных - это асинхронный (в общем случае) процесс

7. Обработка распределенных запросов
Это свойство DDB трактуется как возможность выполнения операций
7. Обработка распределенных запросов
Это свойство DDB трактуется как возможность выполнения операций

8. Обработка распределенных транзакций
Это качество DDB можно трактовать как возможность выполнения
8. Обработка распределенных транзакций
Это качество DDB можно трактовать как возможность выполнения

9. Независимость от оборудования
Это свойство означает, что в качестве узлов распределенной
9. Независимость от оборудования
Это свойство означает, что в качестве узлов распределенной

10. Независимость от операционных систем
Это качество вытекает из предыдущего и означает
10. Независимость от операционных систем
Это качество вытекает из предыдущего и означает

11. Прозрачность сети
Доступ к любым базам данных может осуществляться по сети.
11. Прозрачность сети
Доступ к любым базам данных может осуществляться по сети.

12. Независимость от баз данных
Это качество означает, что в распределенной системе
12. Независимость от баз данных
Это качество означает, что в распределенной системе

ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ DDB
Возникающие проблемы:
Проблемы техники представлений (Views)
Проблема целостности данных
Проблема обработка
ПРАКТИЧЕСКАЯ РЕАЛИЗАЦИЯ DDB
Возникающие проблемы:
Проблемы техники представлений (Views)
Проблема целостности данных
Проблема обработка

Определение представления
Представлением называется сохраняемый в БД авторизованный глобальный запрос на
Определение представления
Представлением называется сохраняемый в БД авторизованный глобальный запрос на

В результате таких глобальных авторизованных запросов для конкретного пользователя создается некая
В результате таких глобальных авторизованных запросов для конкретного пользователя создается некая

I. Размещение системного каталога БД: ядро СУБД должно узнавать, где в
I. Размещение системного каталога БД: ядро СУБД должно узнавать, где в

Проблема целостности данных
В DDB поддержка целостности и согласованности данных, ввиду
Проблема целостности данных
В DDB поддержка целостности и согласованности данных, ввиду

Если в DDB предусмотрено тиражирование данных, то это сразу предъявляет дополнительные
Если в DDB предусмотрено тиражирование данных, то это сразу предъявляет дополнительные

Обработка распределенных запросов
Обработка распределенных запросов (Distributed Query -DQ) - задача,
Обработка распределенных запросов
Обработка распределенных запросов (Distributed Query -DQ) - задача,

Межоперабельность
Во-первых, - это качество, позволяющее обмениваться данными между БД различных
Межоперабельность
Во-первых, - это качество, позволяющее обмениваться данными между БД различных

ОТСТУПЛЕНИЕ ОТ ПРИНЦИПОВ ИДЕАЛЬНОЙ DDB КРИСА ДЕЙТА
Если в жертву приносится принцип
ОТСТУПЛЕНИЕ ОТ ПРИНЦИПОВ ИДЕАЛЬНОЙ DDB КРИСА ДЕЙТА
Если в жертву приносится принцип

ТЕХНОЛОГИИ "КЛИЕНТ-СЕРВЕР"
Основной принцип данной технологии заключается в разделении функций стандартного клиентского
ТЕХНОЛОГИИ "КЛИЕНТ-СЕРВЕР"
Основной принцип данной технологии заключается в разделении функций стандартного клиентского

Логические компоненты СУБД
В соответствии с этим в любой СУБД выделяются следующие
Логические компоненты СУБД
В соответствии с этим в любой СУБД выделяются следующие

Модели технологии «клиент-сервер»
Модель файлового сервера
(File Server — FS);
Модель доступа
Модели технологии «клиент-сервер»
Модель файлового сервера
(File Server — FS);
Модель доступа
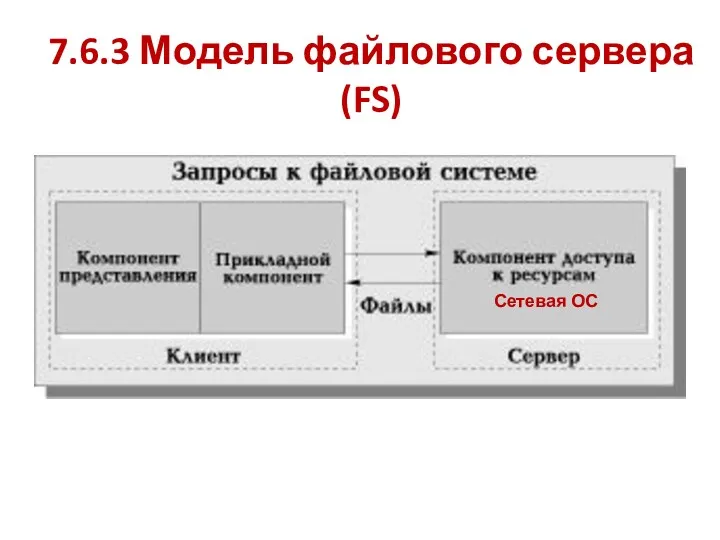
7.6.3 Модель файлового сервера (FS)
Сетевая ОС
7.6.3 Модель файлового сервера (FS)
Сетевая ОС

FS-модель является базовой для локальных сетей ПЭВМ. Суть модели проста. Один
FS-модель является базовой для локальных сетей ПЭВМ. Суть модели проста. Один

FS-модель и персональные СУБД
FS-модель послужила фундаментом для расширения возможностей персональных
FS-модель и персональные СУБД
FS-модель послужила фундаментом для расширения возможностей персональных

Недостатки модели FS
К технологическим недостаткам модели относят высокий сетевой трафик
Недостатки модели FS
К технологическим недостаткам модели относят высокий сетевой трафик
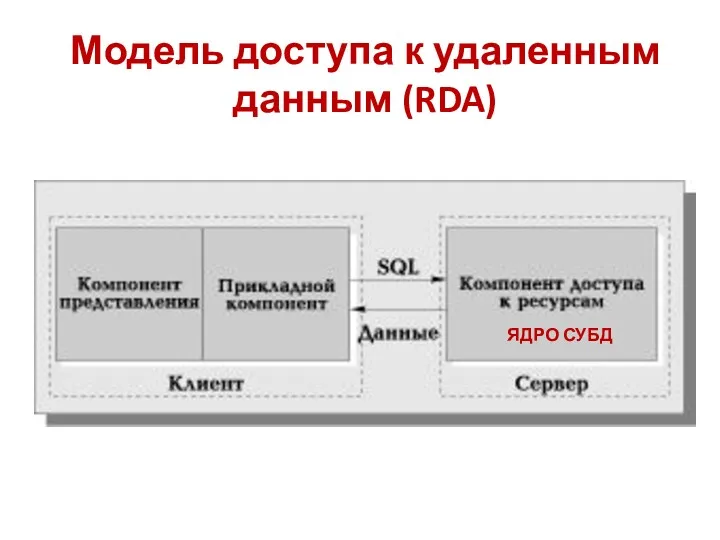
Модель доступа к удаленным данным (RDA)
ЯДРО СУБД
Модель доступа к удаленным данным (RDA)
ЯДРО СУБД

Отличие RDA – модели от FS
Более технологичная RDA-модель существенно отличается от
Отличие RDA – модели от FS
Более технологичная RDA-модель существенно отличается от

Достоинство RDA-модели
Основное достоинство RDA-модели заключается в унификации интерфейса "клиент-сервер" в
Достоинство RDA-модели
Основное достоинство RDA-модели заключается в унификации интерфейса "клиент-сервер" в

Пассивная роль ядра СУБД в RDA
Клиент направляет запросы к информационным
Пассивная роль ядра СУБД в RDA
Клиент направляет запросы к информационным

Недостатки RDA-модели
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие
Недостатки RDA-модели
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие
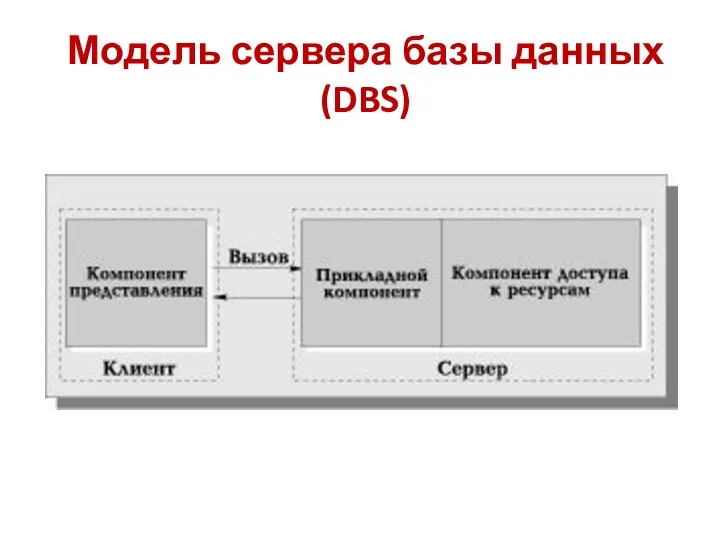
Модель сервера базы данных (DBS)
ЯДРО СУБД
Модель сервера базы данных (DBS)
ЯДРО СУБД

Достоинства DBS-модели
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то
Достоинства DBS-модели
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то

Модель сервера базы данных реализована в реляционных СУБД. Ее основу составляет
Модель сервера базы данных реализована в реляционных СУБД. Ее основу составляет

Недостатки DBS-модели
К недостаткам можно отнести ограниченность средств, используемых для написания
Недостатки DBS-модели
К недостаткам можно отнести ограниченность средств, используемых для написания
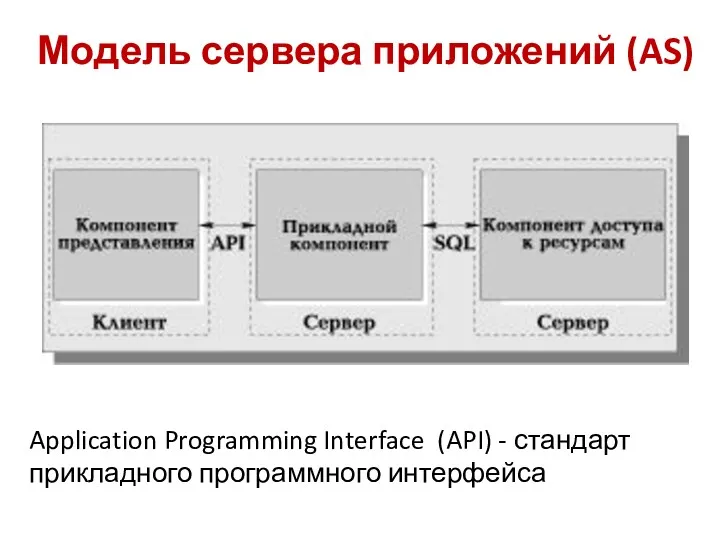
Модель сервера приложений (AS)
Application Programming Interface (API) - стандарт прикладного программного
Модель сервера приложений (AS)
Application Programming Interface (API) - стандарт прикладного программного

Реализация AS-модели
В AS-модели процесс, выполняющийся на компьютере-клиенте, отвечает за интерфейс
Реализация AS-модели
В AS-модели процесс, выполняющийся на компьютере-клиенте, отвечает за интерфейс

Двухзвенная схема разделения функций
RDA- и DBS-модели опираются на двухзвенную схему разделения
Двухзвенная схема разделения функций
RDA- и DBS-модели опираются на двухзвенную схему разделения

Трехзвенная схема разделения функций
В AS-модели реализована трехзвенная схема разделения функций, где
Трехзвенная схема разделения функций
В AS-модели реализована трехзвенная схема разделения функций, где

Программное обеспечение промежуточного слоя (Middleware)
Трехзвенной AS – модель можно считать и
Программное обеспечение промежуточного слоя (Middleware)
Трехзвенной AS – модель можно считать и

Главная ошибка, которая может быть совершена при построении современных распределенных систем
Главная ошибка, которая может быть совершена при построении современных распределенных систем

В случае двухзвенной модели клиент явным образом запрашивает данные, зная структуру
В случае двухзвенной модели клиент явным образом запрашивает данные, зная структуру

В случае трехзвенной модели клиент явно запрашивает один из сервисов (предоставляемых
В случае трехзвенной модели клиент явно запрашивает один из сервисов (предоставляемых

Вывод по моделям «Клиент-сервер»
Таким образом, речь идет о двух принципиально разных
Вывод по моделям «Клиент-сервер»
Таким образом, речь идет о двух принципиально разных

Технология тиражирования
В отличие от распределенных баз DDB, тиражирование данных (Data Replication).
Технология тиражирования
В отличие от распределенных баз DDB, тиражирование данных (Data Replication).

Тиражирование данных
Тиражирование данных — это асинхронный перенос изменений объектов исходной
Тиражирование данных
Тиражирование данных — это асинхронный перенос изменений объектов исходной

Технология распределенных БД и технология тиражирования данных — в определенном смысле
Технология распределенных БД и технология тиражирования данных — в определенном смысле

Поскольку БД распределена по нескольким территориально удаленным узлам, объединенным медленными и
Поскольку БД распределена по нескольким территориально удаленным узлам, объединенным медленными и

Преимущества технологии тиражирования
Технология тиражирования данных не требует синхронной фиксации изменений (и
Преимущества технологии тиражирования
Технология тиражирования данных не требует синхронной фиксации изменений (и

Жизненность технологии тиражирования
подтверждается опытом ее использования в области, предъявляющей повышенные
Жизненность технологии тиражирования
подтверждается опытом ее использования в области, предъявляющей повышенные

Недостатки технологии тиражирования
Технология тиражирования данных не лишена некоторых недостатков, вытекающих
Недостатки технологии тиражирования
Технология тиражирования данных не лишена некоторых недостатков, вытекающих

Следовательно, при проектировании распределенной информационной системы с использованием технологии тиражирования данных
Следовательно, при проектировании распределенной информационной системы с использованием технологии тиражирования данных

Технология объектного связывания
Современные настольные СУБД обеспечивают возможность прямого доступа к объектам
Технология объектного связывания
Современные настольные СУБД обеспечивают возможность прямого доступа к объектам

В системный каталог текущей БД помещаются все необходимые сведения о связанных
В системный каталог текущей БД помещаются все необходимые сведения о связанных

Ядро СУБД при обращении к данным связанного объекта по системному каталогу
Ядро СУБД при обращении к данным связанного объекта по системному каталогу

Недостатки технологии объектного связывания
1. Данная технология построения распределенных систем при больших
Недостатки технологии объектного связывания
1. Данная технология построения распределенных систем при больших

2. Не менее существенной проблемой является отсутствие надежных механизмов безопасности данных
2. Не менее существенной проблемой является отсутствие надежных механизмов безопасности данных

3. Существенной проблемой технологий объектного связывания является появление «брешей» в системах
3. Существенной проблемой технологий объектного связывания является появление «брешей» в системах
 Изготовление бахил
Изготовление бахил ЕГЭ по химии, решение заданий части 3
ЕГЭ по химии, решение заданий части 3 Растворы ВМС. Коллоидные растворы (фармацевтика)
Растворы ВМС. Коллоидные растворы (фармацевтика) Цифровая обработка сигналов и изображений
Цифровая обработка сигналов и изображений Правописание приставок ПРИ-, ПРЕ-.
Правописание приставок ПРИ-, ПРЕ-. Оздоровительная физическая культура и ее формы. Влияние оздоровительной физической культуры на организм человека
Оздоровительная физическая культура и ее формы. Влияние оздоровительной физической культуры на организм человека Картотека сюжетно-ролевых игр для дошкольников
Картотека сюжетно-ролевых игр для дошкольников Группы детей с комплексными нарушениями развития
Группы детей с комплексными нарушениями развития Обучение дошкольников рассказыванию
Обучение дошкольников рассказыванию Реализация научно-исторического подхода при изучении темы. Северный морской путь: с позиции ФГОС
Реализация научно-исторического подхода при изучении темы. Северный морской путь: с позиции ФГОС Ишемическая болезнь кишечника
Ишемическая болезнь кишечника Конспект занятия по обучению детей правилам дорожного движения на тему: Знакомство со светофором во второй младшей группе.
Конспект занятия по обучению детей правилам дорожного движения на тему: Знакомство со светофором во второй младшей группе. Каразін В.Н
Каразін В.Н Русско-ордынские отношения
Русско-ордынские отношения Жак Луи Давид
Жак Луи Давид Стратиграфия. Теоретическая основа стратиграфии
Стратиграфия. Теоретическая основа стратиграфии Кубанское - значит качественное.
Кубанское - значит качественное. Цифровая фотография и видео
Цифровая фотография и видео Основні положення ЗУ Про акредитацію органів з оцінки відповідності
Основні положення ЗУ Про акредитацію органів з оцінки відповідності Презентация Подарок маме от первоклассников
Презентация Подарок маме от первоклассников Решение задач по теме Четырехугольники
Решение задач по теме Четырехугольники The solution for Cement Grinding
The solution for Cement Grinding Осень, осень в гости просим. Онлайн-викторина
Осень, осень в гости просим. Онлайн-викторина Рабочая программа Здоровячок по внеурочной деятельности 1-4 класс в соответствии с ФГОС
Рабочая программа Здоровячок по внеурочной деятельности 1-4 класс в соответствии с ФГОС Знаменитые места Тульского края
Знаменитые места Тульского края Противодействие коррупции на государственном и муниципальном уровнях
Противодействие коррупции на государственном и муниципальном уровнях Дидактическая игра-паззл Узнай героя
Дидактическая игра-паззл Узнай героя Жизненный цикл ПО
Жизненный цикл ПО