- Системи розпізнавання текстової інформації. Тема 10

Содержание
- 2. Технологічні можливості та перспективи використання оптичних читаючих автоматів та систем розпізнавання знаку Оптичне розпізнавання тексту (англ.:
- 3. 1. Системи оптичного розпізнавання символів При введенні текстової інформації у КВС, при створенні електронних бібліотек і
- 4. Растровий метод розпізнавання Якщо початковий документ має поліграфічну якість (достатньо великий шрифт, відсутність погано надрукованих символів
- 5. 2. Основні принципи роботи ABBYY FineReader Класична система оптичного розпізнавання працює по наступному принципу: на підставі
- 6. Принцип цілісності (integrity), відповідно до якого об'єкт, що спостерігається, розглядається як ціле, що складається зі зв'язаних
- 7. Принцип цілеспрямованості (purposefulness) формулюється просто будь-яка інтерпретація даних переслідує певну мету. Відповідно до цього принципу, розпізнавання
- 8. Принцип адаптивності (adaptability) має на увазі здатність системи до самонавчання. Отримана при розпізнаванні інформація упорядковується, зберігається
- 9. 3. Багаторівневий аналіз документа (MDA) сучасні OCR-програми починають розпізнавання саме з аналізу структури. Як правило, при
- 10. Приклад ієрархічної структури документа
- 11. Зрозуміло, що будь-який високорівневий об'єкт може бути представлений як набір об'єктів більш низького рівня: букви утворять
- 12. Алгоритм MDA важлива особливість використовуваного в системі ABBYY FineReader алгоритму MDA: на всіх етапах багаторівневого аналізу
- 13. Висновок Ми коротко розглянули основні принципи роботи системи оптичного розпізнавання символів ABBYY FineReader. Як згадувалося, розпізнавання
- 14. Всі програми розпізнавання мови діляться на дві категорії програми з невеликим словниковим запасом, призначені для більшості
- 15. Сприйняття мови і її запис Для того щоб мова з’явилася на екрані або була сприйнята як
- 17. Скачать презентацию

Технологічні можливості та перспективи використання оптичних читаючих автоматів та систем розпізнавання
Технологічні можливості та перспективи використання оптичних читаючих автоматів та систем розпізнавання

1. Системи оптичного розпізнавання символів
При введенні текстової інформації у КВС, при
1. Системи оптичного розпізнавання символів
При введенні текстової інформації у КВС, при

Растровий метод розпізнавання
Якщо початковий документ має поліграфічну якість (достатньо великий шрифт,
Растровий метод розпізнавання
Якщо початковий документ має поліграфічну якість (достатньо великий шрифт,

2. Основні принципи роботи ABBYY FineReader
Класична система оптичного розпізнавання працює по
2. Основні принципи роботи ABBYY FineReader
Класична система оптичного розпізнавання працює по

Принцип цілісності (integrity), відповідно до якого об'єкт, що спостерігається, розглядається як
Принцип цілісності (integrity), відповідно до якого об'єкт, що спостерігається, розглядається як

Принцип цілеспрямованості (purposefulness) формулюється просто будь-яка інтерпретація даних переслідує певну мету.
Принцип цілеспрямованості (purposefulness) формулюється просто будь-яка інтерпретація даних переслідує певну мету.

Принцип адаптивності (adaptability) має на увазі здатність системи до самонавчання.
Отримана при
Принцип адаптивності (adaptability) має на увазі здатність системи до самонавчання.
Отримана при

3. Багаторівневий аналіз документа (MDA)
сучасні OCR-програми починають розпізнавання саме з аналізу
3. Багаторівневий аналіз документа (MDA)
сучасні OCR-програми починають розпізнавання саме з аналізу
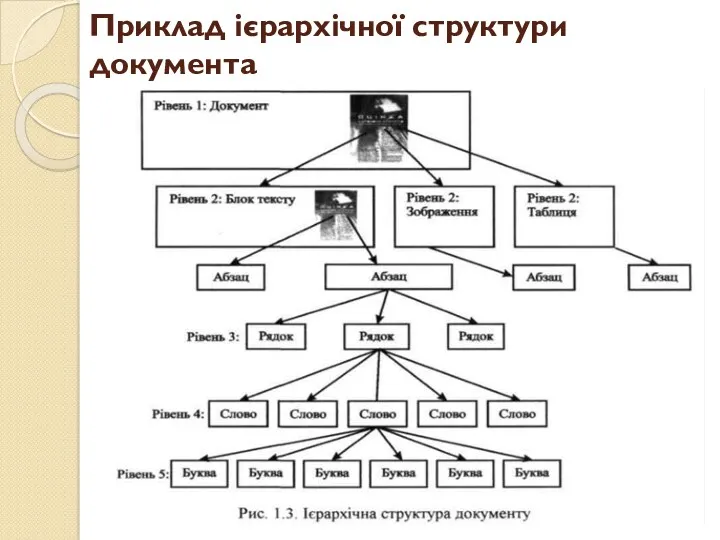
Приклад ієрархічної структури документа
Приклад ієрархічної структури документа

Зрозуміло, що будь-який високорівневий об'єкт може бути представлений як набір об'єктів
Зрозуміло, що будь-який високорівневий об'єкт може бути представлений як набір об'єктів

Алгоритм MDA
важлива особливість використовуваного в системі ABBYY FineReader алгоритму MDA: на
Алгоритм MDA
важлива особливість використовуваного в системі ABBYY FineReader алгоритму MDA: на

Висновок
Ми коротко розглянули основні принципи роботи системи оптичного розпізнавання символів ABBYY
Висновок
Ми коротко розглянули основні принципи роботи системи оптичного розпізнавання символів ABBYY

Всі програми розпізнавання мови діляться на дві категорії
програми з невеликим словниковим
Всі програми розпізнавання мови діляться на дві категорії
програми з невеликим словниковим

Сприйняття мови і її запис
Для того щоб мова з’явилася на екрані
Сприйняття мови і її запис
Для того щоб мова з’явилася на екрані
 Проводники и диэлектрики в электрическом поле
Проводники и диэлектрики в электрическом поле Организация праздника День логопеда
Организация праздника День логопеда Кулагина - (Ех) - лиц.102 - презентация
Кулагина - (Ех) - лиц.102 - презентация LEGO Mindstorms EV3
LEGO Mindstorms EV3 Безопасное колесо. Знатоки правил дорожного движения. Тренинг 1
Безопасное колесо. Знатоки правил дорожного движения. Тренинг 1 Зоны подготовки автомобилей к покраске на СТО
Зоны подготовки автомобилей к покраске на СТО High Sensitivity Camera. NEC Corporation
High Sensitivity Camera. NEC Corporation Окна. Оконные проёмы. Варианты оформления
Окна. Оконные проёмы. Варианты оформления Необслуживаемые аккумуляторные батареи
Необслуживаемые аккумуляторные батареи Удлинение геймплея в видеоиграх
Удлинение геймплея в видеоиграх Жевательная резинка польза или вред
Жевательная резинка польза или вред Исследовательская работа Опалённые войной
Исследовательская работа Опалённые войной Заболевания сердечно-сосудистой системы
Заболевания сердечно-сосудистой системы Разновидности планирования ГПД
Разновидности планирования ГПД Машины взбивальные
Машины взбивальные Презентация к уроку географии в 8 классе на темуКавказ.
Презентация к уроку географии в 8 классе на темуКавказ. Балаганная игрушка Петрушка из папье-маше (3 класс)
Балаганная игрушка Петрушка из папье-маше (3 класс) Операторы Insert, Update, Delete
Операторы Insert, Update, Delete ВКР: Организация ремонта электрооборудования в условиях ЗАО Белый Ручей
ВКР: Организация ремонта электрооборудования в условиях ЗАО Белый Ручей Проблемы психического здоровья детей
Проблемы психического здоровья детей Презентация. Игровая деятельность дошкольников в логике ФГОС
Презентация. Игровая деятельность дошкольников в логике ФГОС Ислам. Основные идеи ислама
Ислам. Основные идеи ислама Системы отопления
Системы отопления Геометрия в архитектуре
Геометрия в архитектуре Государство и экономика
Государство и экономика Практическая работа как форма учебной деятельности
Практическая работа как форма учебной деятельности Композиция с цветами и птицами
Композиция с цветами и птицами Семейство Псовые, или Собачьи
Семейство Псовые, или Собачьи