- The definition of a computer system pefmoRmance metrics

Содержание
- 2. Estimating the performance of computing systems The basis for comparing different types of computers with each
- 3. In some cases, the system time of the CPU is ignored because of the possible inaccuracy
- 4. Thus, the CPU time for some program can be expressed in two ways: the number of
- 5. In the process of searching, what would you not know, whatever it was. In fact, the
- 6. MIPS One of the alternative units for measuring the processor's performance (relative to the execution time)
- 7. The positive aspects of MIPS is that this characteristic is easy to understand, especially to the
- 8. At that time, the synthetic test Dhrystone was widespread, which allowed to evaluate the efficiency of
- 9. MFLOPS Measuring the performance of computers in solving scientific and technical problems, in which floating-point arithmetic
- 10. As a unit of measure, MFLOPS is designed to evaluate the performance of only floating point
- 11. The solution to both problems is to take the "canonical" or "normalized" number of floating point
- 12. On a parallel machine, performance essentially depends on the correspondence between the structure of the hardware
- 13. LINPACK is a package of fortran programs for solving systems of linear algebraic equations. The goal
- 14. The algorithms of the current version of LINPACK are based on the decomposition method. The initial
- 16. Скачать презентацию

Estimating the performance of computing systems
The basis for comparing different types
Estimating the performance of computing systems
The basis for comparing different types

In some cases, the system time of the CPU is ignored
In some cases, the system time of the CPU is ignored

Thus, the CPU time for some program can be expressed in
Thus, the CPU time for some program can be expressed in

In the process of searching, what would you not know, whatever
In the process of searching, what would you not know, whatever
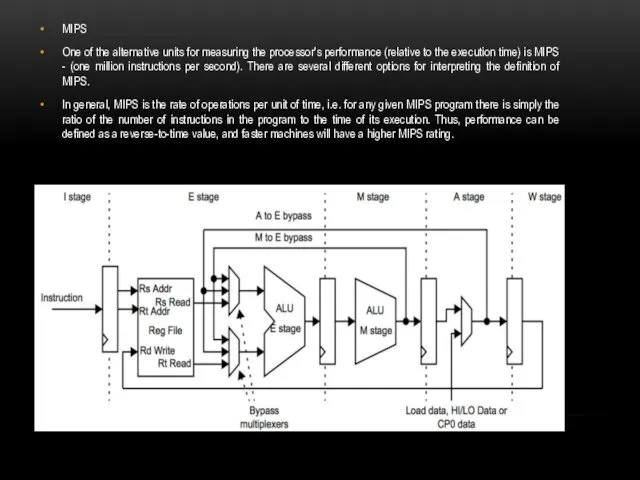
MIPS
One of the alternative units for measuring the processor's performance (relative
MIPS
One of the alternative units for measuring the processor's performance (relative

The positive aspects of MIPS is that this characteristic is easy
The positive aspects of MIPS is that this characteristic is easy

At that time, the synthetic test Dhrystone was widespread, which allowed
At that time, the synthetic test Dhrystone was widespread, which allowed

MFLOPS
Measuring the performance of computers in solving scientific and technical problems,
MFLOPS
Measuring the performance of computers in solving scientific and technical problems,

As a unit of measure, MFLOPS is designed to evaluate the
As a unit of measure, MFLOPS is designed to evaluate the

The solution to both problems is to take the "canonical" or
The solution to both problems is to take the "canonical" or
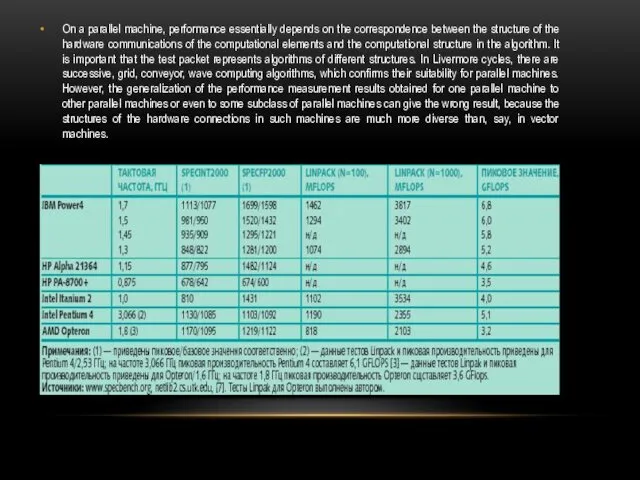
On a parallel machine, performance essentially depends on the correspondence between
On a parallel machine, performance essentially depends on the correspondence between
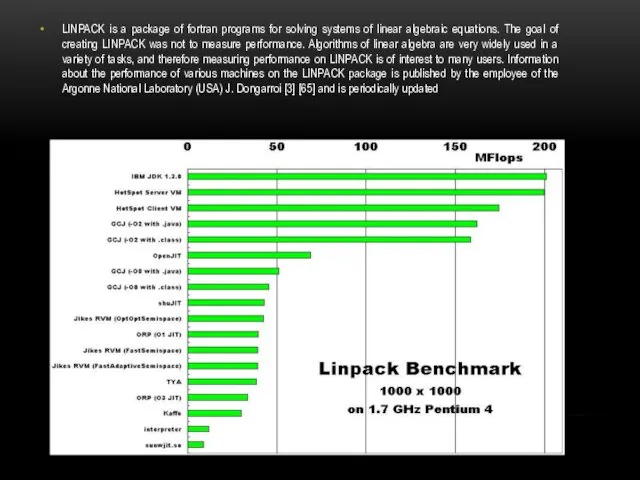
LINPACK is a package of fortran programs for solving systems of
LINPACK is a package of fortran programs for solving systems of

The algorithms of the current version of LINPACK are based on
The algorithms of the current version of LINPACK are based on
 Презентация к уроку Технология 1 класс. Оригами.
Презентация к уроку Технология 1 класс. Оригами. Tema_2_Ponyatie_Chast_II
Tema_2_Ponyatie_Chast_II Устройство судна
Устройство судна Организация труда секретаря-референта в современной организации
Организация труда секретаря-референта в современной организации Алексей Николаевич Толстой 1882-1945гг
Алексей Николаевич Толстой 1882-1945гг Lapbook Templates
Lapbook Templates Развитие творческого потенциала у младших школьников корррекционной школы VIII вида
Развитие творческого потенциала у младших школьников корррекционной школы VIII вида ТЫЖ Программист
ТЫЖ Программист Расстройства местного кровообращения
Расстройства местного кровообращения Классный час на тему: Всемирный день защиты животных
Классный час на тему: Всемирный день защиты животных История фотоаппарата
История фотоаппарата Дорожные знаки. Художественное творчество (рисование) в подготовительной группе Добрые сердца
Дорожные знаки. Художественное творчество (рисование) в подготовительной группе Добрые сердца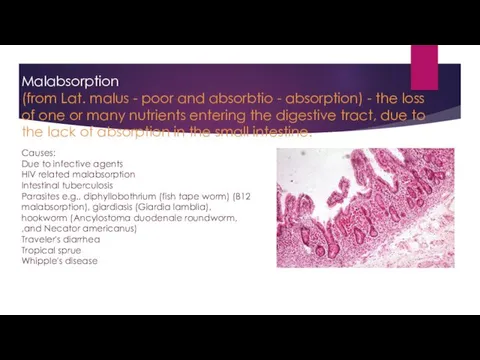 Malabsorption
Malabsorption Презентация Книжки-малышки
Презентация Книжки-малышки павлов
павлов день космонавтики
день космонавтики Все о возражениях и сомнениях клиента в настоящем периоде
Все о возражениях и сомнениях клиента в настоящем периоде Рахит. Этиология, патогенез, клиника, диагностика, лечение, профилактика
Рахит. Этиология, патогенез, клиника, диагностика, лечение, профилактика Writing an article
Writing an article Стоматологические индексы
Стоматологические индексы Излучение и спектры
Излучение и спектры Ориентирование подземных выработок
Ориентирование подземных выработок Урок географии по теме Воды суши. Реки.
Урок географии по теме Воды суши. Реки. консультация - презентация для родителей и педагогов Учимся произносить звук Р
консультация - презентация для родителей и педагогов Учимся произносить звук Р Последствия курения (кл.час)
Последствия курения (кл.час) Наполнение регионального репозитория образовательным контентом
Наполнение регионального репозитория образовательным контентом Викторина 8-б класс
Викторина 8-б класс Возрастные особенности третьеклассника
Возрастные особенности третьеклассника