- Абстрактні типи даних

Содержание
- 2. 3.1. Визначення абстрактного типу даних Література для самостійного читання: с. 23-27 [1], с. 310-311 [4], с.47-84
- 3. Тип даних Структура даних Абстрактний тип даних
- 4. Тип даних Структура даних Абстрактний тип даних Тип даних - у мовах програмування тип даних змінної
- 5. Тип даних Структура даних Абстрактний тип даних Абстрактний тип даних - це математична модель плюс різні
- 6. Тип даних Структура даних Абстрактний тип даних Абстрактний тип даних - це математична модель плюс різні
- 7. Базовим будівельним блоком структури даних є комірка, яка призначена для зберігання значення певного базового або складеного
- 8. Способи агрегації комірок для створення структур даних: одновимірний масив запис файл покажчик + запис курсор +
- 9. 3.2. АТД "Список" Література для самостійного читання: с. 45-57 [1], с. 310-311 [4]
- 10. Приклад. Здійснюється реєстрація автомобілів, які прибувають на автостоянку та залишають її. Потрібно зберігати і обробляти множину
- 11. Зв'язний лінійний список — це сукупність однотипних компонентів, які послідовно зв'язані між собою за допомогою покажчиків.
- 12. Різновиди однозв'язних списків: Стек — це однозв'язний лінійний список, в якому компоненти додаються та видаляються лише
- 13. Різновиди двозв'язних списків: Двозв'язний лінійний список — це список, в якому попередній компонент посилається на наступний,
- 14. Реалізація списків за допомогою масивів При реалізації списків за допомогою масивів елементи списку розташовуються в суміжних
- 15. З прикладом реалізації можна ознайомитись в (с.48-50 [1]).
- 16. Реалізація списків за допомогою покажчиків Кожний компонент зв'язного лінійного списку складається з кількох інформаційних полів та
- 17. Зображення однозв'язного лінійного списку
- 18. Приклад. Оголошення типу компонента однозв'язного лінійного списку в Pascal. Для роботи з таким списком потрібні покажчики
- 19. Приклад. Оголошення типу компонента однозв'язного лінійного списку в С. // Декларація типу компонента struct list {
- 20. Приклади, що ілюструють реалізації АТД “Список”: реалізація за допомогою покажчиків (с.50-53 [1]). реалізація за допомогою масивів
- 21. Порівняння реалізацій АТД “Список” Зрозуміло, нас не може не цікавити питання про те, в яких ситуаціях
- 22. 1. Реалізація списків за допомогою масивів вимагає вказівки максимального розміру списку до початку виконання програм. Якщо
- 23. 2. Виконання деяких операторів в одній реалізації вимагає більших обчислювальних витрат, ніж в іншій. Наприклад, процедури
- 24. 3. Якщо необхідно вставляти або видаляти елементи, положення яких вказане з допомогою якоїсь змінної-курсору, і значення
- 25. 4. Реалізація списків за допомогою масивів марнотратна відносно комп’ютерної пам'яті, оскільки резервується об'єм пам'яті, достатній для
- 26. 3.3. Стек Література для самостійного читання: с. 58-60 [1], с. 312-316 [4]
- 27. Стек — це один із різновидів однозв'язного лінійного списку, доступ до елементів якого можливий лише через
- 28. Для роботи зі стеком використовують зазвичай п’ять дій: перевірка, чи порожній стек додавання елемента у вершину
- 29. Реалізація стеків за допомогою покажчиків Стек працює за принципом «останнім прийшов — першим вийшов», що позначається
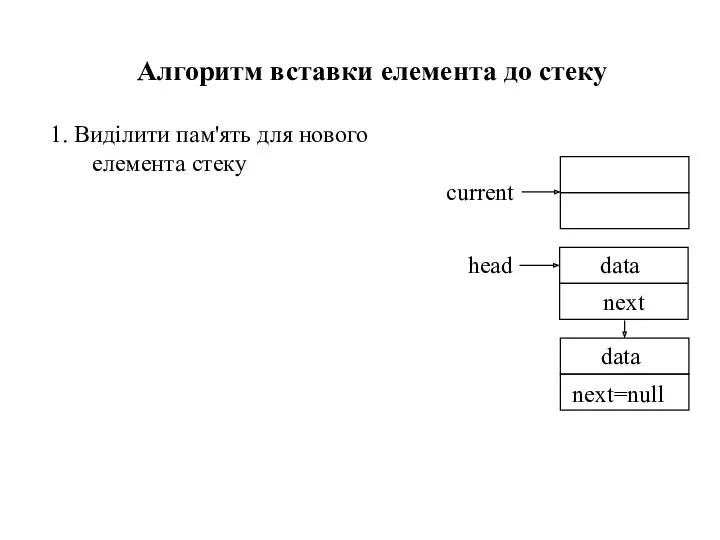
- 30. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до порожнього стеку current
- 31. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до порожнього стеку 2. Ввести дані
- 32. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до порожнього стеку 2. Ввести дані
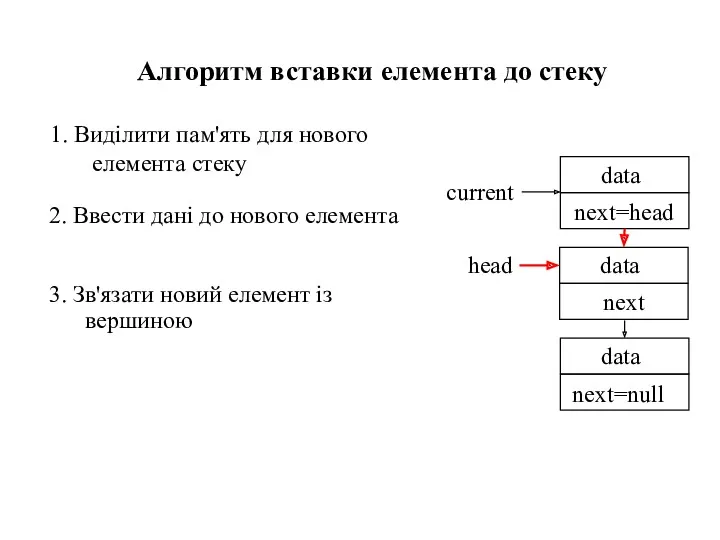
- 33. Алгоритм вставки елемента до стеку head
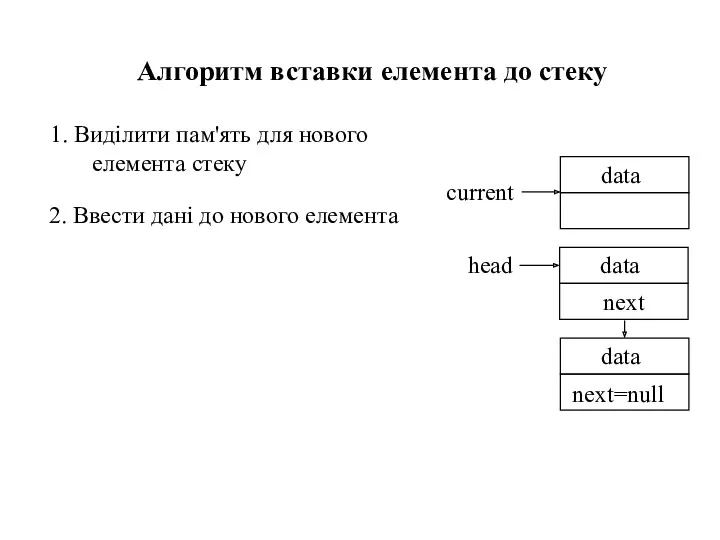
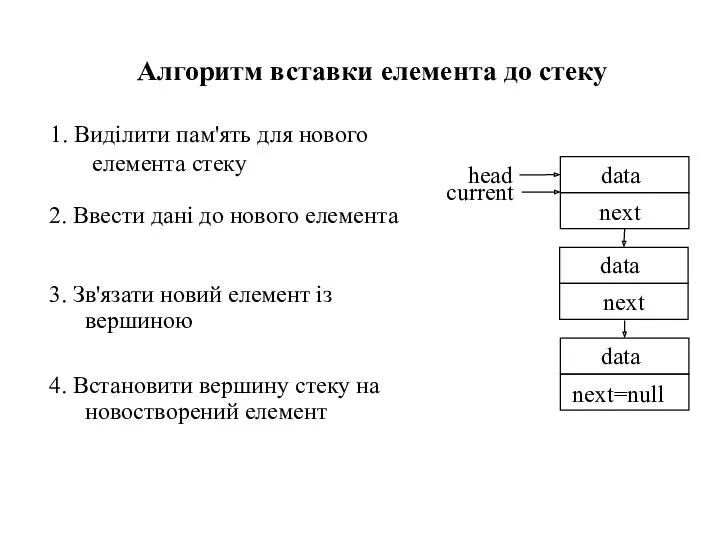
- 34. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до стеку
- 35. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до стеку 2. Ввести дані до
- 36. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до стеку 2. Ввести дані до
- 37. 1. Виділити пам'ять для нового елемента стеку Алгоритм вставки елемента до стеку 2. Ввести дані до
- 38. Опис структури даних Оголошення типу компонента однозв'язного лінійного списку. // Декларація типу компонента struct list {
- 39. Встановлення початковых значень 0) початкове значення змінних. Обидві змінні містять невизначене значення. current = head =
- 40. Створення першого елементу списку 1.1) здійснено виділення пам’яті current = new struct list;
- 41. Пам'ять містить «сміття». Виконаємо занулення виділеної пам’яті. 1.1.1. Занулення memset(current, 0,sizeof(struct list));
- 42. 1.2. Здійснюємо ввод даних із клавіатури: cout cin >> current->data;
- 43. 1.3. Зв'язати допоміжний елемент із вершиною: current->next_item = head; Оскільки мали порожнє значення в елементі HEAD,
- 44. 1.4. Встановити вершину стеку на новостворений елемент head = current;
- 45. В стек записано три елементи
- 46. Алгоритм видалення елемента зі стеку
- 47. 1. Створити копію покажчика на вершину стеку Алгоритм видалення елемента зі стеку current
- 48. 1. Створити копію покажчика на вершину стеку Алгоритм видалення елемента зі стеку 2. Перемістити покажчик на
- 49. 1. Створити копію покажчика на вершину стеку Алгоритм видалення елемента зі стеку 2. Перемістити покажчик на
- 50. Реалізація стеків за допомогою масивів Кожну реалізацію списків можна розглядати як реалізацію стеків, оскільки стеки з
- 51. Можна раціональніше пристосувати масиви для реалізації стеків, якщо взяти до уваги той факт, що вставка і
- 52. З прикладом реалізації можна ознайомитись в (с.60-61 [1]).
- 53. Приклади, що ілюструють реалізації АТД “Стек”: реалізація за допомогою покажчиків (с.310-315 [4]) ще одна реалізація за
- 54. 3.4. Черга Література для самостійного читання: с. 57-65 [1], с. 316-325 [4]
- 55. Черга, як і стек, — це один із різновидів однозв'язного лінійного списку. додавання видалення
- 56. Для роботи з чергою використовують такі дії: перевірка, чи порожня черга додавання елемента з кінець черги
- 57. Реалізація черг за допомогою покажчиків Черга працює за принципом «першим прийшов — першим вийшов», що позначається
- 58. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до порожньої черги
- 59. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до порожньої черги 2. Ввести дані
- 60. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до порожньої черги 2. Ввести дані
- 61. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до порожньої черги 2. Ввести дані
- 62. Опис структури даних Оголошення типу компонента однозв'язного лінійного списку. // Декларація типу компонента struct list {
- 63. struct list *add_to_list(struct list *p_head) { struct list *current = NULL; // поточний компоненти черги struct
- 64. //Якщо черга порожня, то ініціалізувати її вершину if (p_head == NULL) {p_head = current;} else {
- 65. 1) початкове значення змінних
- 66. 2) ввод даних із клавіатури cout cin >> current->data;
- 67. 3) Ініціалізувати початок списку head = current;
- 68. 4) Ініціалізувати кінець списку last = current;
- 69. 5) Записати ознаку того, що перший елемент є останнім head->next_item = NULL;
- 70. Алгоритм вставки елемента до черги
- 71. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до черги
- 72. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до черги 2. Ввести дані до
- 73. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до черги 2. Ввести дані до
- 74. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до черги 2. Ввести дані до
- 75. 1. Виділити пам'ять для нового елемента черги Алгоритм вставки елемента до черги 2. Ввести дані до
- 76. void print_list(struct list *p_head) { struct list *current; // поточний компонент списку int i = 0;
- 77. Реалізація черг за допомогою циклічних масивів Реалізацію списків за допомогою масивів, яка розглядалася раніше, можна застосувати
- 78. При такому представленні черги оператори додавання і видалення елемента виконуються за фіксований час, незалежний від довжини
- 79. Елементи черги розташовуються в "колі" записів в послідовних позиціях, кінець черги знаходиться за годинниковою стрілкою на
- 80. Приклади, що ілюструють реалізації АТД “Черга”: реалізація за допомогою покажчиків (с.316-319 [4]) ще одна реалізація за
- 81. 3.5. Однозв'язний лінійний список Література для самостійного читання: с. 60-66 [1], с. 319-325 [4]
- 82. Стек і черга є лінійними списками, множина допустимих операцій над якими обмежена операціями над першим або
- 83. Всі можливі варіанти застосування операцій вставки та видалення елементів у списку: створення списку, тобто внесення першого
- 84. У загальному випадку для роботи з однозв'язним лінійним списком потрібні такі покажчики: head на початок списку;
- 85. Додавання елемента в кінець списку виконується за алгоритмом додавання елемента до черги, а на початок списку
- 86. Алгоритм вставки елемента в середину списку Вважаємо, що новий елемент має бути вставлений між елементами previous
- 87. 1. Виділити пам'ять для нового елемента Алгоритм вставки елемента в середину списку Вважаємо, що новий елемент
- 88. 1. Виділити пам'ять для нового елемента Алгоритм вставки елемента до черги 2. Ввести дані до нового
- 89. 1. Виділити пам'ять для нового елемента Алгоритм вставки елемента в середину списку 2. Ввести дані до
- 90. 1. Виділити пам'ять для нового елемента Алгоритм вставки елемента в середину списку 2. Ввести дані до
- 91. Алгоритм видалення елемента з середини списку Вважаємо, що має бути видалений елемент current, розташований безпосередньо за
- 92. 1. Вважати, що за елементом previous буде розташований той елемент, що раніше знаходився за елементом current
- 93. 1. Вважати, що за елементом previous буде розташований той елемент, що раніше знаходився за елементом current
- 94. Алгоритм видалення елемента з кінця списку Вважаємо, що на передостанній елемент посилається покажчик previous. head last
- 95. 1. Записати до передостаннього елемента ознаку кінця списку Алгоритм видалення елемента з кінця списку Вважаємо, що
- 96. 1. Записати до передостаннього елемента ознаку кінця списку Алгоритм видалення елемента з кінця списку 2. Звільнити
- 97. 1. Записати до передостаннього елемента ознаку кінця списку Алгоритм видалення елемента з кінця списку 2. Звільнити
- 98. Приклад. Алгоритм роботи з алфавітним переліком слів. 1. Вважати список порожнім. 2. Вивести меню для роботи
- 99. 4. Якщо натиснута клавіша D, видалити елемент зі списку. 4.1. Ввести слово, що видаляється. 4.2. Якщо
- 100. Приклади, що ілюструють реалізації АТД “Однозв'язний лінійний список”: реалізація за допомогою покажчиків (с.319-325 [4]) ще одна
- 101. 3.6. Двозв'язний лінійний список Література для самостійного читання: с. 57-58 [1]
- 102. Часто виникає необхідність організувати ефективне пересування по списку як в прямому, так і в зворотному напрямах.
- 103. 3.7. Відображення Література для самостійного читання: с. 66-68 [1]
- 104. Відображення - це функція, визначена на множині елементів одного типу (області визначення), що приймає значення з
- 105. Перелік операторів, які можна виконати над відображенням М. перетворення відображення на порожнє; призначення M(d)=r незалежно від
- 106. Реалізація відображень за допомогою масивів У багатьох випадках тип елементів області визначення відображення є простим типом,
- 107. Реалізація відображень за допомогою списків Існує багато реалізацій відображень з кінцевою областю визначення. Наприклад, в багатьох
- 108. 3.8. АТД “Дерево” Література для самостійного читання: с. 77-89 [1], с. 326-330 [4]
- 109. Розглянуті раніше списки, стеки та черги належать до лінійних динамічних структур даних. Визначальною характеристикою лінійних структур
- 110. Представлення дерев за допомогою масивів Нехай Т - дерево з вузлами 1, 2 ..., n. Найпростішим
- 112. Використання покажчиків або курсорів на батьків не допомагає в реалізації операторів, що вимагають інформацію про синів.
- 113. Представлення дерев з використанням списків синів Важливий і корисний спосіб представлення дерев полягає у формуванні для
- 114. З прикладом реалізації можна ознайомитись в (с.87-88 [1]).
- 115. Серед недоліків такої структури даних можна назвати те, що вона не дозволяє створювати великі дерева з
- 116. 3.9. Бінарні дерева Література для самостійного читання: с. 91-99 [1], с. 328-336 [4]
- 117. Представлення бінарних дерев за допомогою масивів Якщо іменами вузлів бінарного дерева є їх номери 1,2, …
- 118. Представлення бінарних дерев за допомогою нелінійних динамічних структур Будь-який вузол бінарного дерева може бути зв'язаним не
- 119. Приклад бінарного дерева як динамічної структури даних
- 120. Алгоритми роботи з бінарними деревами Створення бінарного дерева Найпростіший спосіб побудови бінарного дерева полягає у створенні
- 121. Приклад. Створення бінарного дерева із заданою користувачем кількістю вузлів. Оскільки структура дерева визначена рекурсивно, то для
- 122. Функція створення дерева tree отримує один цілочисловий параметр AmountNode, що визначає кількість вузлів дерева та повертає
- 124. Дерево відображатиме рекурсивна процедура printtree. Піддерево рівня L виводитиметься так: спочатку буде відображене ліве піддерево, потім
- 126. Обхід дерева Алгоритм доступу до всіх вузлів дерева називається обходом дерева. Трьома основними способами обходу дерева
- 127. Результати обходу дерева.
- 128. Будь-який спосіб обходу дерева можна реалізувати рекурсивною процедурою. До цих процедур передається параметр-значення, що є покажчиком
- 131. Домашнє завдання Прочитати с.23-83 [1] , с.310-341 [4] Підготуватися до виконання практичної роботи №3.
- 133. Скачать презентацию

3.1. Визначення абстрактного типу даних
Література для самостійного читання:
с. 23-27 [1],
3.1. Визначення абстрактного типу даних
Література для самостійного читання:
с. 23-27 [1],

Тип даних
Структура даних
Абстрактний тип даних
Тип даних
Структура даних
Абстрактний тип даних

Тип даних
Структура даних
Абстрактний тип даних
Тип даних - у мовах програмування
Тип даних
Структура даних
Абстрактний тип даних
Тип даних - у мовах програмування

Тип даних
Структура даних
Абстрактний тип даних
Абстрактний тип даних - це математична
Тип даних
Структура даних
Абстрактний тип даних
Абстрактний тип даних - це математична

Тип даних
Структура даних
Абстрактний тип даних
Абстрактний тип даних - це математична
Тип даних
Структура даних
Абстрактний тип даних
Абстрактний тип даних - це математична

Базовим будівельним блоком структури даних є комірка, яка призначена для зберігання
Базовим будівельним блоком структури даних є комірка, яка призначена для зберігання

Способи агрегації комірок для створення структур даних:
одновимірний масив
запис
файл
покажчик + запис
Способи агрегації комірок для створення структур даних:
одновимірний масив
запис
файл
покажчик + запис
![3.2. АТД "Список" Література для самостійного читання: с. 45-57 [1], с. 310-311 [4]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-8.jpg)
3.2. АТД "Список"
Література для самостійного читання:
с. 45-57 [1], с. 310-311
3.2. АТД "Список"
Література для самостійного читання:
с. 45-57 [1], с. 310-311

Приклад. Здійснюється реєстрація автомобілів, які прибувають на автостоянку та залишають її.
Приклад. Здійснюється реєстрація автомобілів, які прибувають на автостоянку та залишають її.

Зв'язний лінійний список — це сукупність однотипних компонентів, які послідовно зв'язані
Зв'язний лінійний список — це сукупність однотипних компонентів, які послідовно зв'язані

Різновиди однозв'язних списків:
Стек — це однозв'язний лінійний список, в якому компоненти
Різновиди однозв'язних списків:
Стек — це однозв'язний лінійний список, в якому компоненти

Різновиди двозв'язних списків:
Двозв'язний лінійний список — це список, в якому попередній
Різновиди двозв'язних списків:
Двозв'язний лінійний список — це список, в якому попередній

Реалізація списків за допомогою масивів
При реалізації списків за допомогою масивів
Реалізація списків за допомогою масивів
При реалізації списків за допомогою масивів
![З прикладом реалізації можна ознайомитись в (с.48-50 [1]).](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-14.jpg)
З прикладом реалізації можна ознайомитись в (с.48-50 [1]).
З прикладом реалізації можна ознайомитись в (с.48-50 [1]).

Реалізація списків за допомогою покажчиків
Кожний компонент зв'язного лінійного списку складається
Реалізація списків за допомогою покажчиків
Кожний компонент зв'язного лінійного списку складається
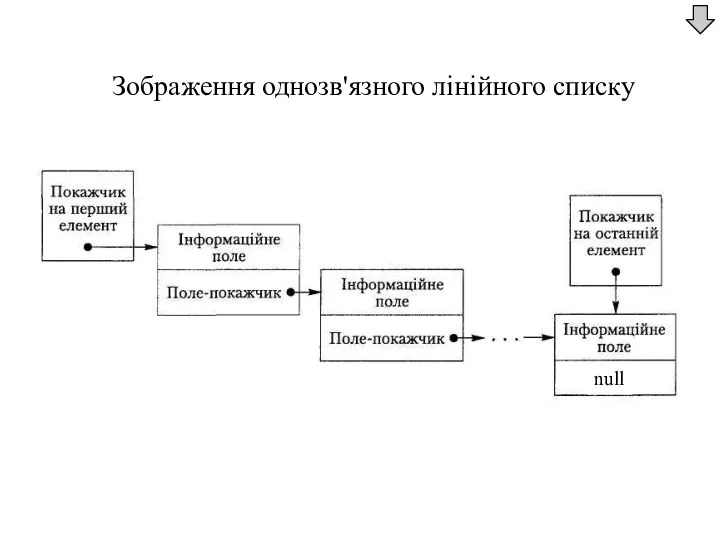
Зображення однозв'язного лінійного списку
Зображення однозв'язного лінійного списку

Приклад. Оголошення типу компонента однозв'язного лінійного списку в Pascal. Для роботи
Приклад. Оголошення типу компонента однозв'язного лінійного списку в Pascal. Для роботи

Приклад. Оголошення типу компонента однозв'язного лінійного списку в С.
// Декларація
Приклад. Оголошення типу компонента однозв'язного лінійного списку в С.
// Декларація

Приклади, що ілюструють реалізації АТД “Список”:
реалізація за допомогою покажчиків (с.50-53
Приклади, що ілюструють реалізації АТД “Список”:
реалізація за допомогою покажчиків (с.50-53

Порівняння реалізацій АТД “Список”
Зрозуміло, нас не може не цікавити питання
Порівняння реалізацій АТД “Список”
Зрозуміло, нас не може не цікавити питання

1. Реалізація списків за допомогою масивів вимагає вказівки максимального розміру списку
1. Реалізація списків за допомогою масивів вимагає вказівки максимального розміру списку

2. Виконання деяких операторів в одній реалізації вимагає більших обчислювальних витрат,
2. Виконання деяких операторів в одній реалізації вимагає більших обчислювальних витрат,

3. Якщо необхідно вставляти або видаляти елементи, положення яких вказане з
3. Якщо необхідно вставляти або видаляти елементи, положення яких вказане з

4. Реалізація списків за допомогою масивів марнотратна відносно комп’ютерної пам'яті, оскільки
4. Реалізація списків за допомогою масивів марнотратна відносно комп’ютерної пам'яті, оскільки
![3.3. Стек Література для самостійного читання: с. 58-60 [1], с. 312-316 [4]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-25.jpg)
3.3. Стек
Література для самостійного читання:
с. 58-60 [1], с. 312-316 [4]
3.3. Стек
Література для самостійного читання:
с. 58-60 [1], с. 312-316 [4]
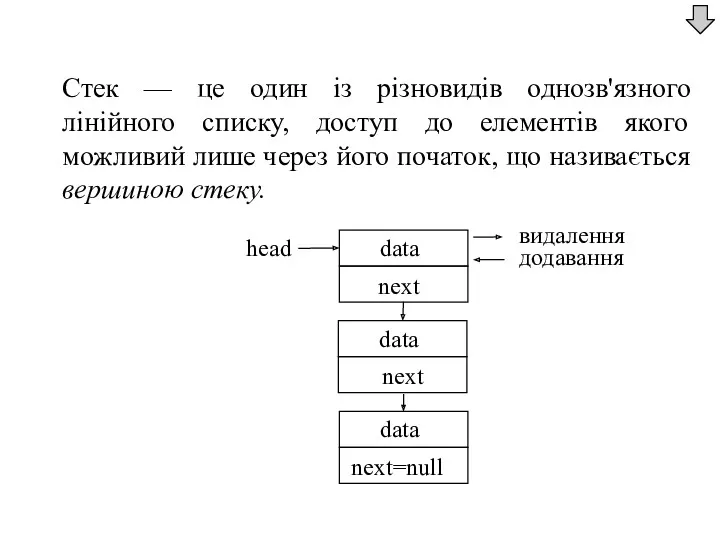
Стек — це один із різновидів однозв'язного лінійного списку, доступ до
Стек — це один із різновидів однозв'язного лінійного списку, доступ до

Для роботи зі стеком використовують зазвичай п’ять дій:
перевірка, чи порожній стек
додавання
Для роботи зі стеком використовують зазвичай п’ять дій:
перевірка, чи порожній стек
додавання

Реалізація стеків за допомогою покажчиків
Стек працює за принципом «останнім прийшов
Реалізація стеків за допомогою покажчиків
Стек працює за принципом «останнім прийшов
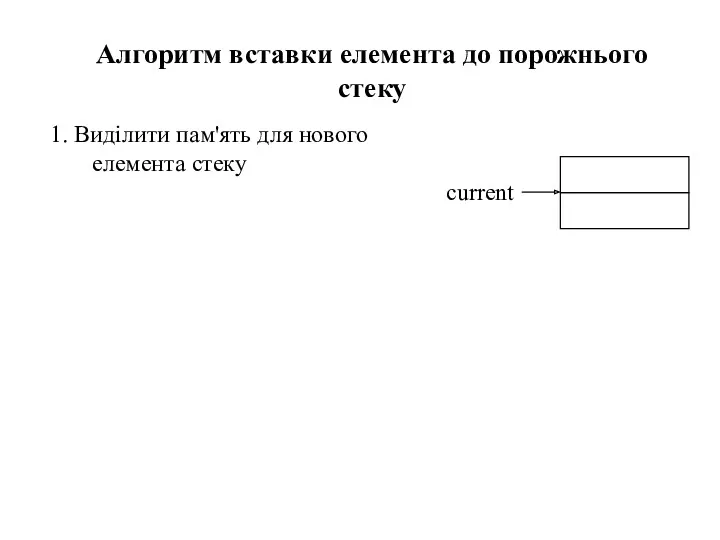
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до порожнього
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до порожнього

1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до порожнього
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до порожнього

1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до порожнього
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до порожнього
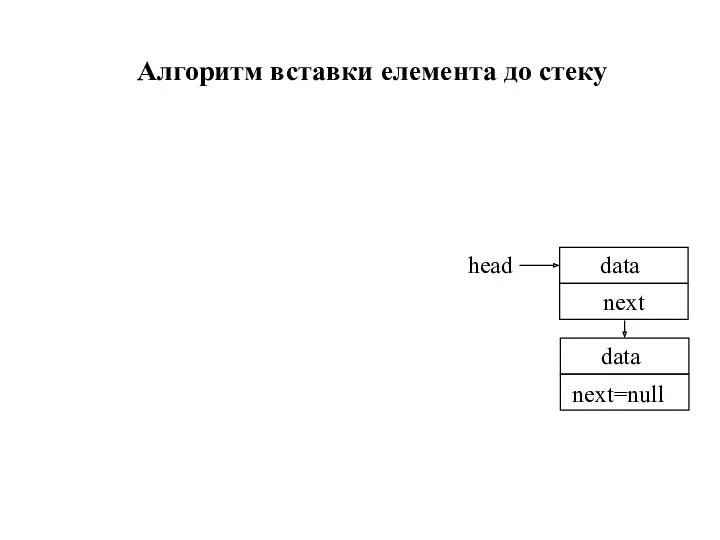
Алгоритм вставки елемента до стеку
head
Алгоритм вставки елемента до стеку
head
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
2.
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
2.
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
2.
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
2.
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
2.
1. Виділити пам'ять для нового елемента стеку
Алгоритм вставки елемента до стеку
2.

Опис структури даних
Оголошення типу компонента однозв'язного лінійного списку.
// Декларація типу
Опис структури даних
Оголошення типу компонента однозв'язного лінійного списку.
// Декларація типу

Встановлення початковых значень
0) початкове значення змінних.
Обидві змінні містять невизначене значення.
current
Встановлення початковых значень
0) початкове значення змінних.
Обидві змінні містять невизначене значення.
current
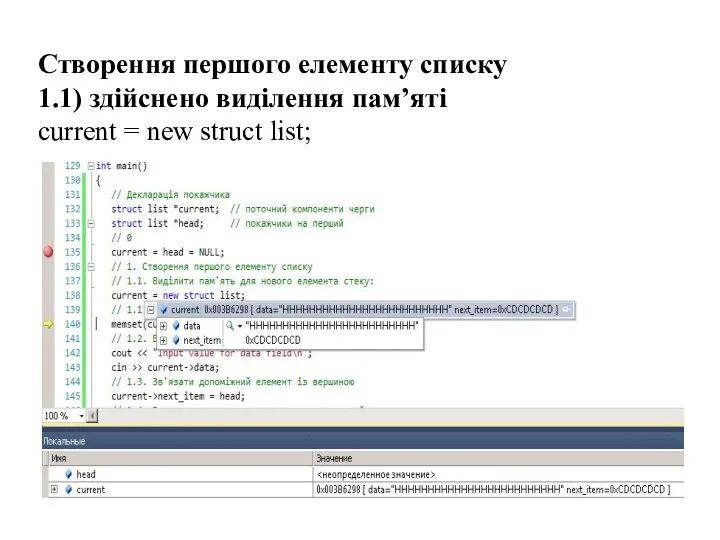
Створення першого елементу списку
1.1) здійснено виділення пам’яті
current = new struct list;
Створення першого елементу списку
1.1) здійснено виділення пам’яті
current = new struct list;
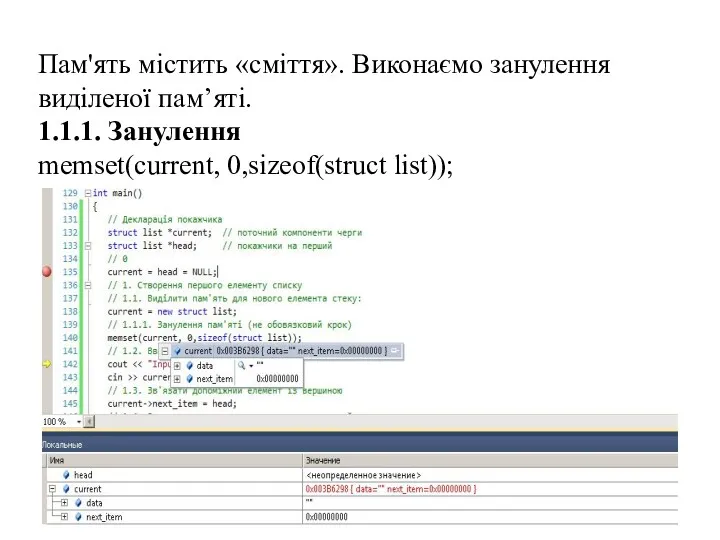
Пам'ять містить «сміття». Виконаємо занулення виділеної пам’яті.
1.1.1. Занулення
memset(current, 0,sizeof(struct list));
Пам'ять містить «сміття». Виконаємо занулення виділеної пам’яті.
1.1.1. Занулення
memset(current, 0,sizeof(struct list));
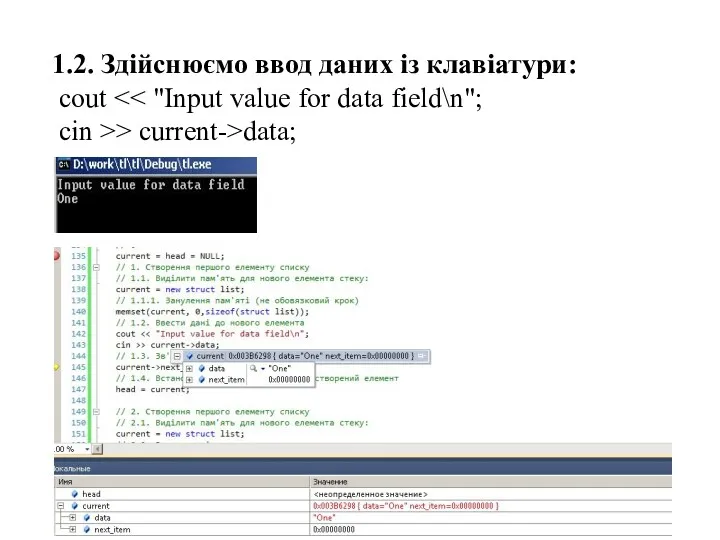
1.2. Здійснюємо ввод даних із клавіатури:
cout << "Input value
1.2. Здійснюємо ввод даних із клавіатури:
cout << "Input value
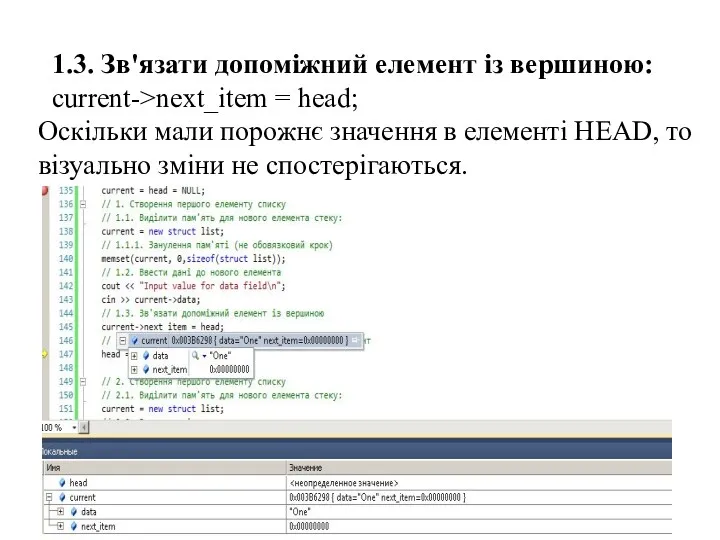
1.3. Зв'язати допоміжний елемент із вершиною:
current->next_item = head;
Оскільки мали
1.3. Зв'язати допоміжний елемент із вершиною:
current->next_item = head;
Оскільки мали
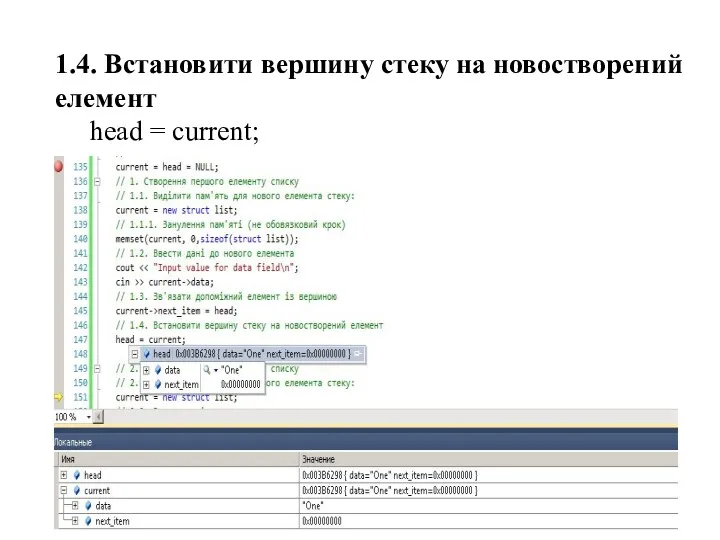
1.4. Встановити вершину стеку на новостворений елемент
head = current;
1.4. Встановити вершину стеку на новостворений елемент
head = current;

В стек записано три елементи
В стек записано три елементи
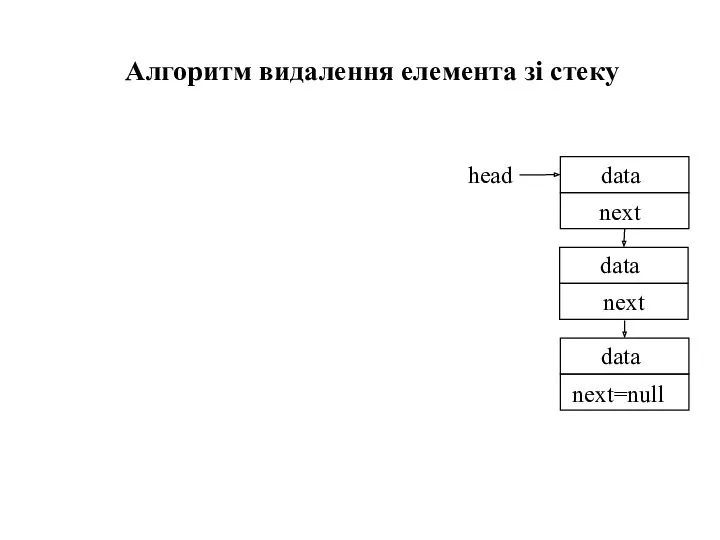
Алгоритм видалення елемента зі стеку
Алгоритм видалення елемента зі стеку
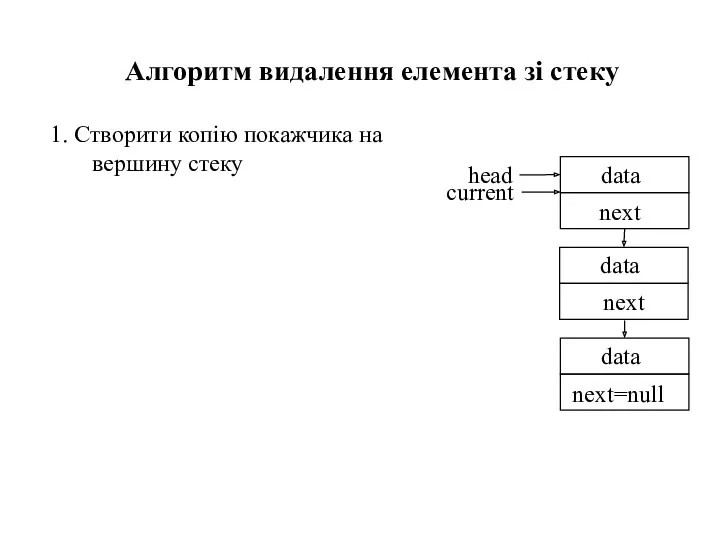
1. Створити копію покажчика на вершину стеку
Алгоритм видалення елемента зі стеку
current
1. Створити копію покажчика на вершину стеку
Алгоритм видалення елемента зі стеку
current
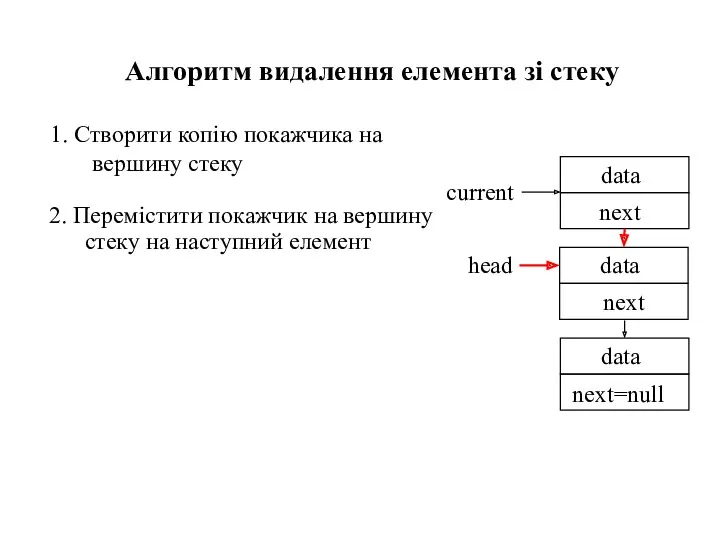
1. Створити копію покажчика на вершину стеку
Алгоритм видалення елемента зі стеку
2.
1. Створити копію покажчика на вершину стеку
Алгоритм видалення елемента зі стеку
2.
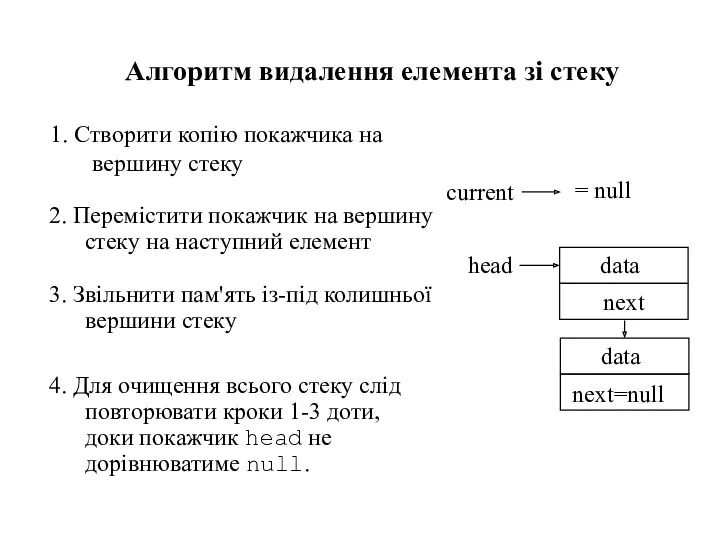
1. Створити копію покажчика на вершину стеку
Алгоритм видалення елемента зі стеку
2.
1. Створити копію покажчика на вершину стеку
Алгоритм видалення елемента зі стеку
2.

Реалізація стеків за допомогою масивів
Кожну реалізацію списків можна розглядати як реалізацію
Реалізація стеків за допомогою масивів
Кожну реалізацію списків можна розглядати як реалізацію

Можна раціональніше пристосувати масиви для реалізації стеків, якщо взяти до уваги
Можна раціональніше пристосувати масиви для реалізації стеків, якщо взяти до уваги
![З прикладом реалізації можна ознайомитись в (с.60-61 [1]).](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-51.jpg)
З прикладом реалізації можна ознайомитись в (с.60-61 [1]).
З прикладом реалізації можна ознайомитись в (с.60-61 [1]).

Приклади, що ілюструють реалізації АТД “Стек”:
реалізація за допомогою покажчиків (с.310-315
Приклади, що ілюструють реалізації АТД “Стек”:
реалізація за допомогою покажчиків (с.310-315
![3.4. Черга Література для самостійного читання: с. 57-65 [1], с. 316-325 [4]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-53.jpg)
3.4. Черга
Література для самостійного читання:
с. 57-65 [1], с. 316-325 [4]
3.4. Черга
Література для самостійного читання:
с. 57-65 [1], с. 316-325 [4]
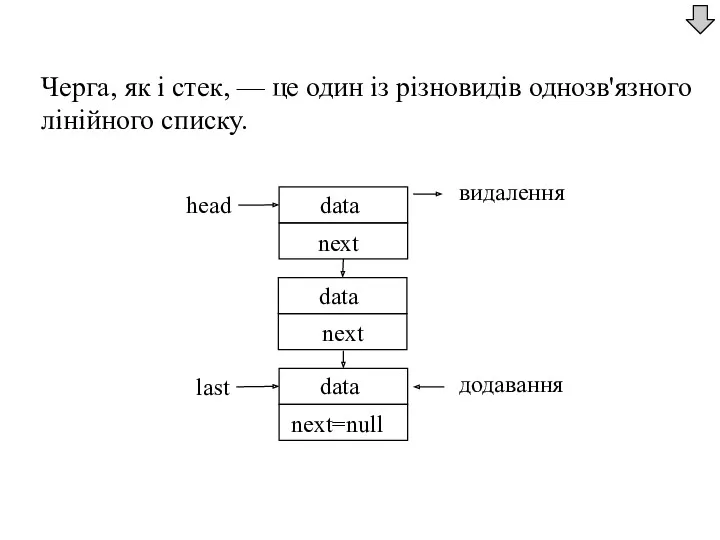
Черга, як і стек, — це один із різновидів однозв'язного лінійного
Черга, як і стек, — це один із різновидів однозв'язного лінійного

Для роботи з чергою використовують такі дії:
перевірка, чи порожня черга
додавання
Для роботи з чергою використовують такі дії:
перевірка, чи порожня черга
додавання

Реалізація черг за допомогою покажчиків
Черга працює за принципом «першим прийшов
Реалізація черг за допомогою покажчиків
Черга працює за принципом «першим прийшов
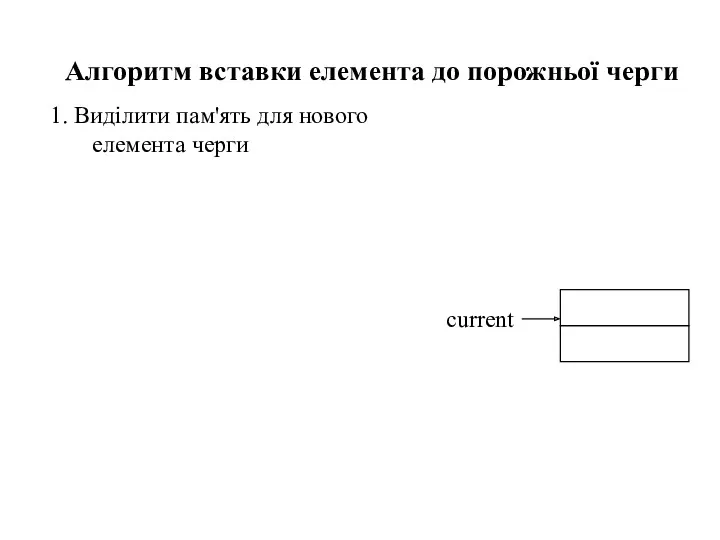
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої

1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої
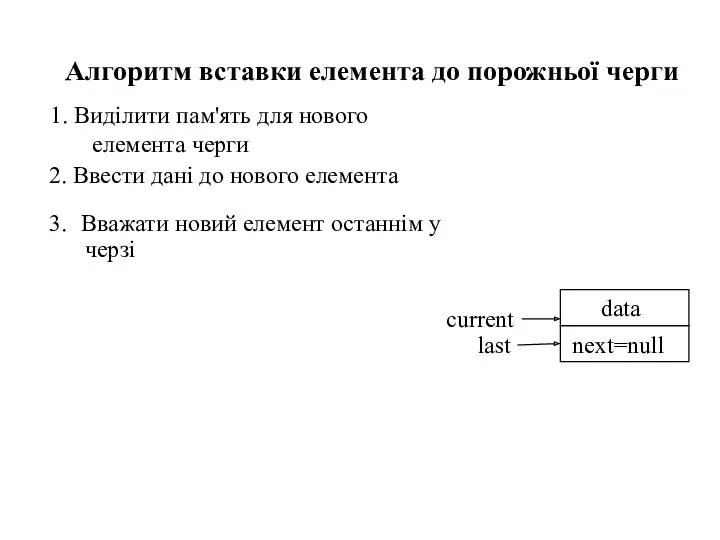
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої

1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до порожньої

Опис структури даних
Оголошення типу компонента однозв'язного лінійного списку.
// Декларація типу
Опис структури даних
Оголошення типу компонента однозв'язного лінійного списку.
// Декларація типу

struct list *add_to_list(struct list *p_head)
{ struct list *current = NULL; //
struct list *add_to_list(struct list *p_head)
{ struct list *current = NULL; //

//Якщо черга порожня, то ініціалізувати її вершину
if (p_head ==
//Якщо черга порожня, то ініціалізувати її вершину
if (p_head ==
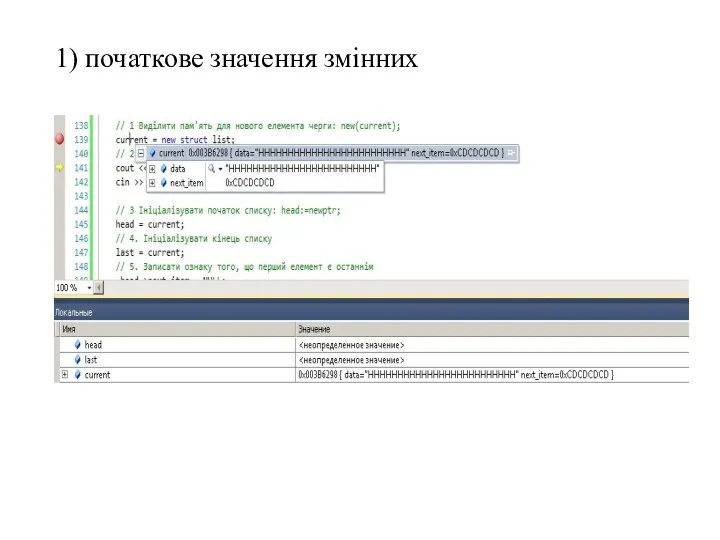
1) початкове значення змінних
1) початкове значення змінних
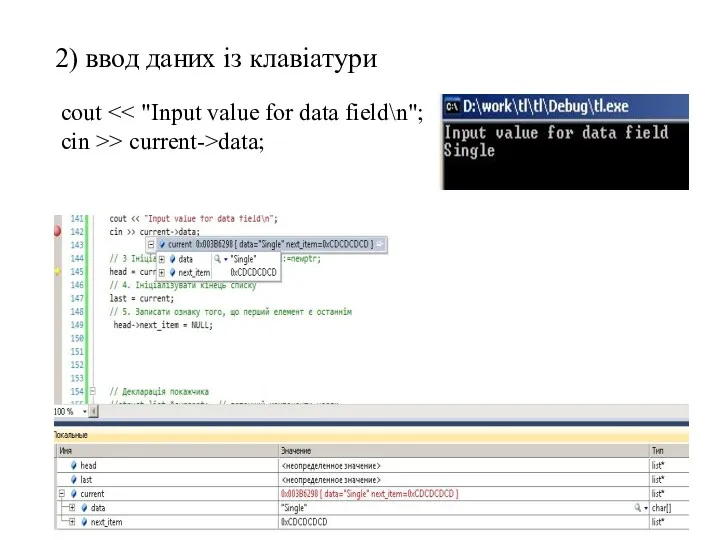
2) ввод даних із клавіатури
cout << "Input value for data field\n";
cin
2) ввод даних із клавіатури
cout << "Input value for data field\n";
cin

3) Ініціалізувати початок списку
head = current;
3) Ініціалізувати початок списку
head = current;
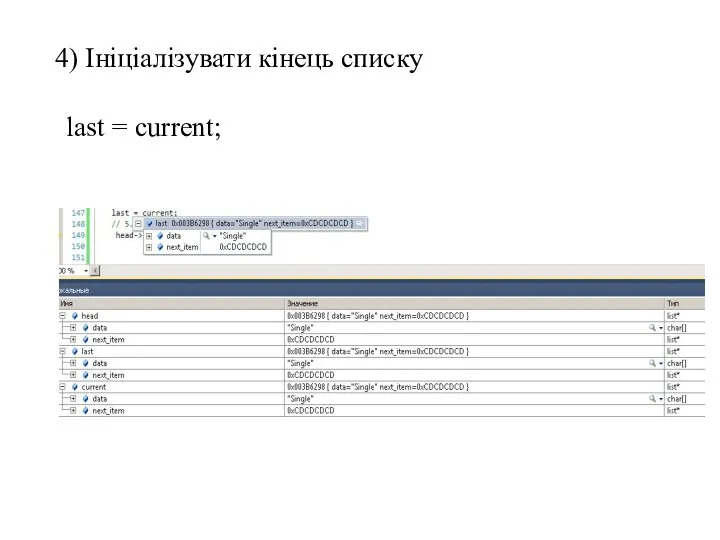
4) Ініціалізувати кінець списку
last = current;
4) Ініціалізувати кінець списку
last = current;
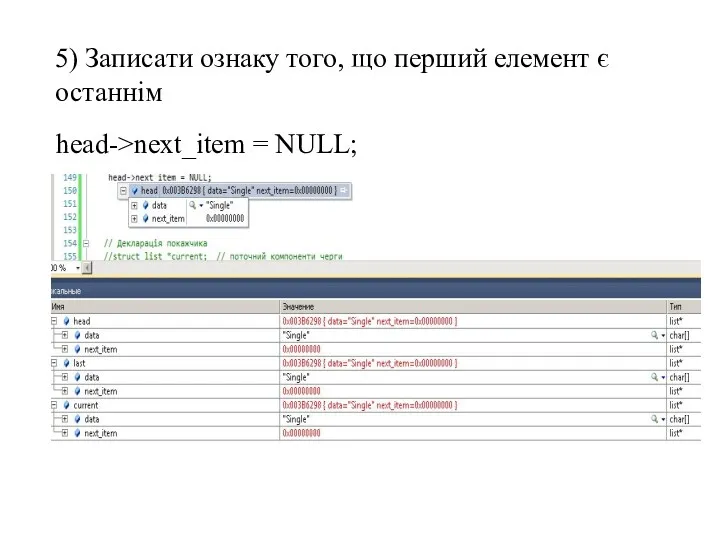
5) Записати ознаку того, що перший елемент є останнім
head->next_item = NULL;
5) Записати ознаку того, що перший елемент є останнім
head->next_item = NULL;
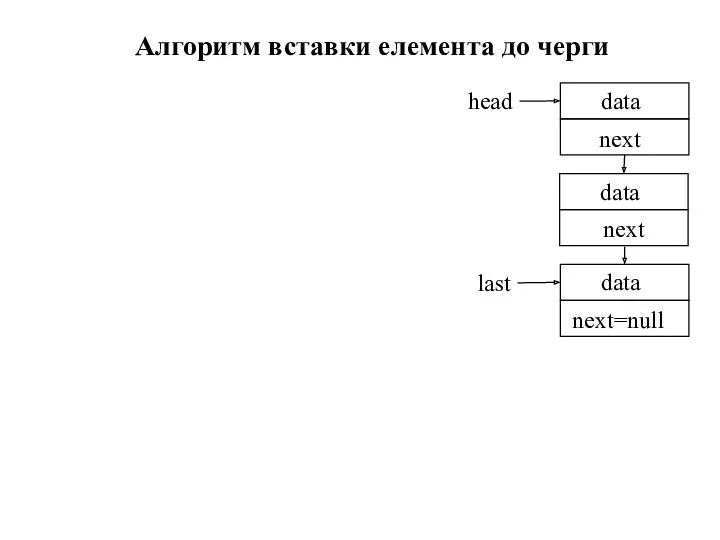
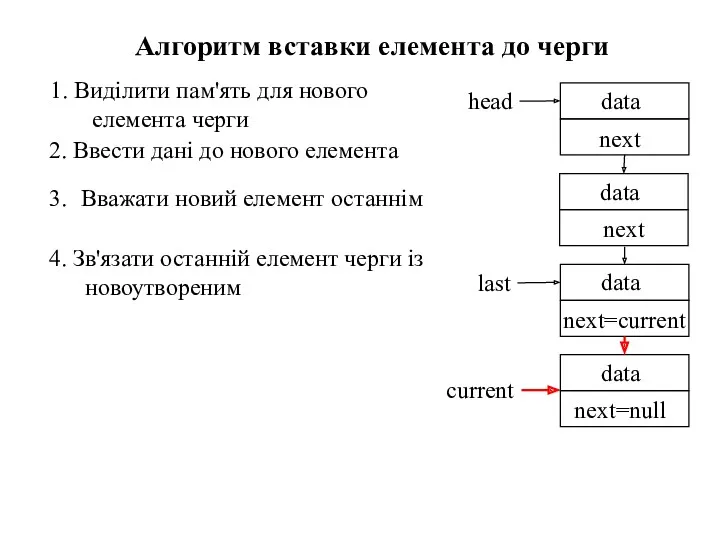
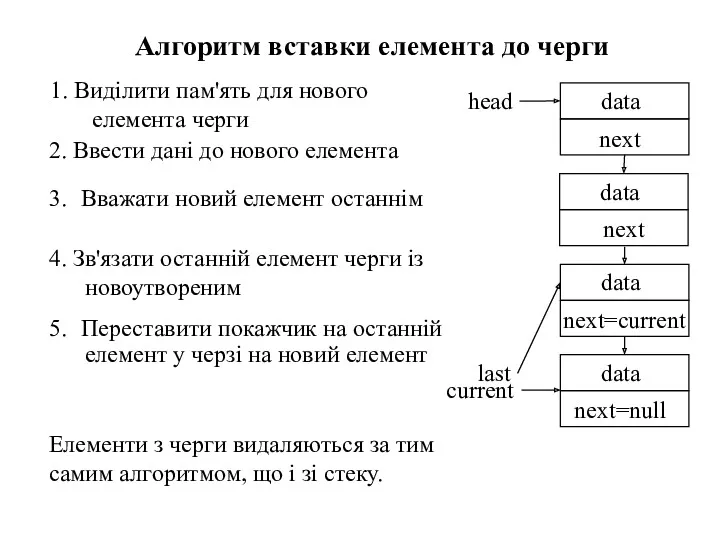
Алгоритм вставки елемента до черги
Алгоритм вставки елемента до черги
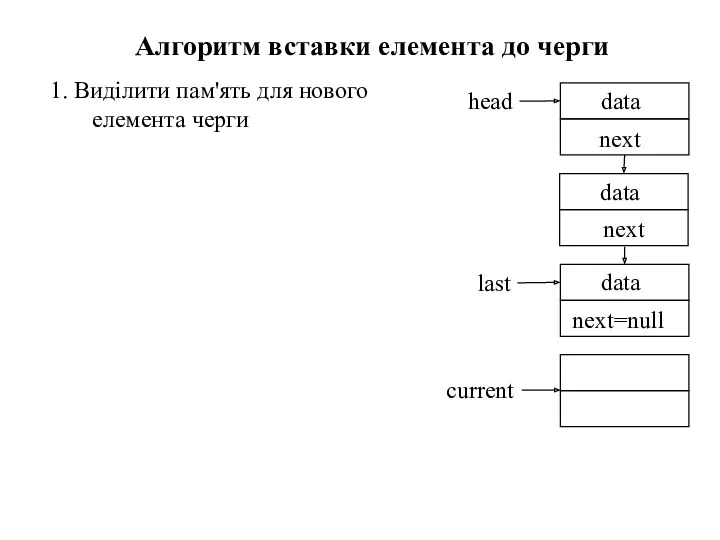
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
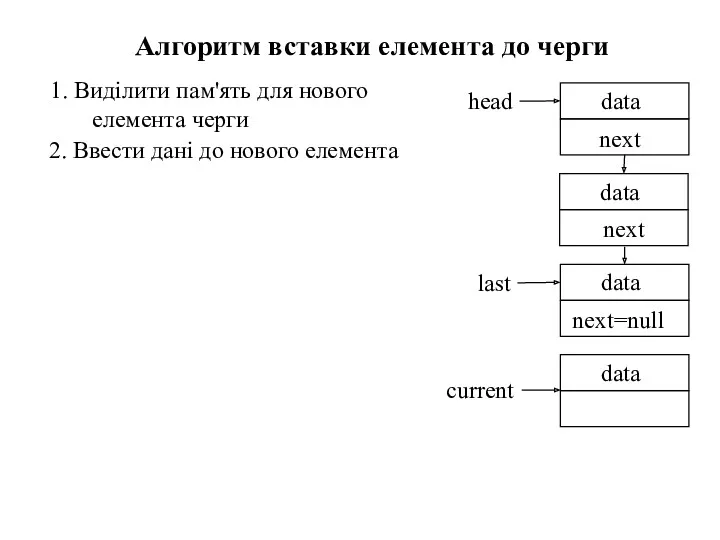
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
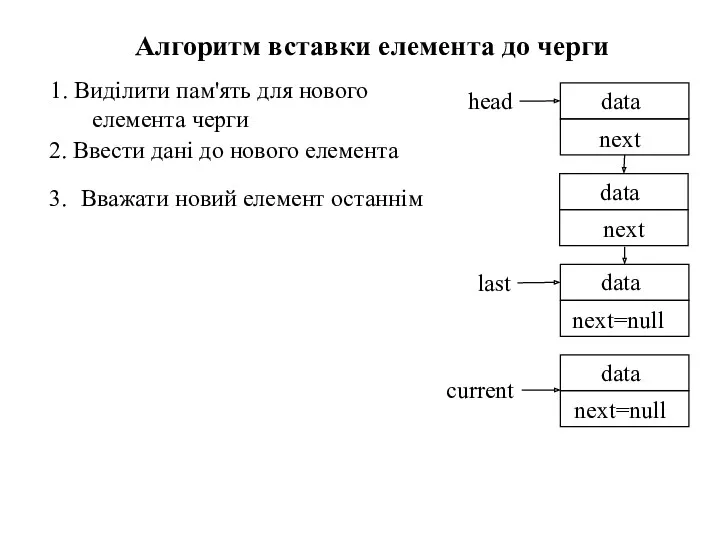
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.
1. Виділити пам'ять для нового елемента черги
Алгоритм вставки елемента до черги
2.

void print_list(struct list *p_head)
{ struct list *current; // поточний компонент списку
void print_list(struct list *p_head)
{ struct list *current; // поточний компонент списку

Реалізація черг за допомогою циклічних масивів
Реалізацію списків за допомогою масивів,
Реалізація черг за допомогою циклічних масивів
Реалізацію списків за допомогою масивів,
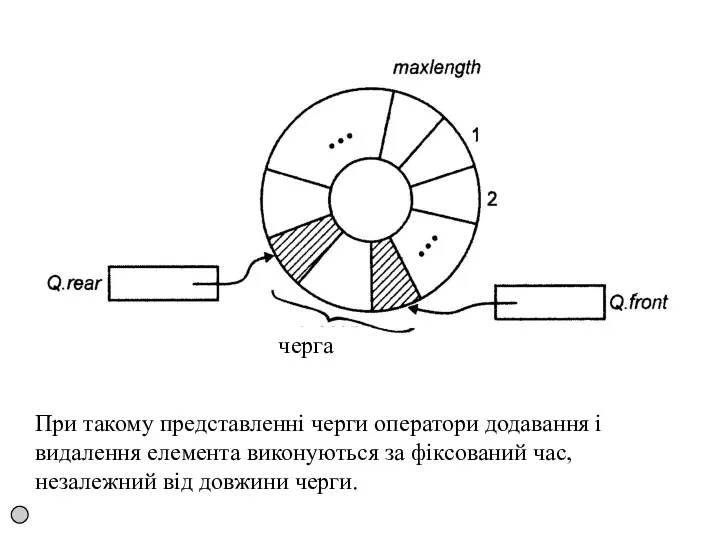
При такому представленні черги оператори додавання і видалення елемента виконуються за
При такому представленні черги оператори додавання і видалення елемента виконуються за

Елементи черги розташовуються в "колі" записів в послідовних позиціях, кінець черги
Елементи черги розташовуються в "колі" записів в послідовних позиціях, кінець черги

Приклади, що ілюструють реалізації АТД “Черга”:
реалізація за допомогою покажчиків (с.316-319
Приклади, що ілюструють реалізації АТД “Черга”:
реалізація за допомогою покажчиків (с.316-319
![3.5. Однозв'язний лінійний список Література для самостійного читання: с. 60-66 [1], с. 319-325 [4]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-80.jpg)
3.5. Однозв'язний лінійний список
Література для самостійного читання:
с. 60-66 [1], с.
3.5. Однозв'язний лінійний список
Література для самостійного читання:
с. 60-66 [1], с.

Стек і черга є лінійними списками, множина допустимих операцій над якими
Стек і черга є лінійними списками, множина допустимих операцій над якими

Всі можливі варіанти застосування операцій вставки та видалення елементів у списку:
Всі можливі варіанти застосування операцій вставки та видалення елементів у списку:

У загальному випадку для роботи з однозв'язним лінійним списком потрібні такі
У загальному випадку для роботи з однозв'язним лінійним списком потрібні такі

Додавання елемента в кінець списку виконується за алгоритмом додавання елемента до
Додавання елемента в кінець списку виконується за алгоритмом додавання елемента до
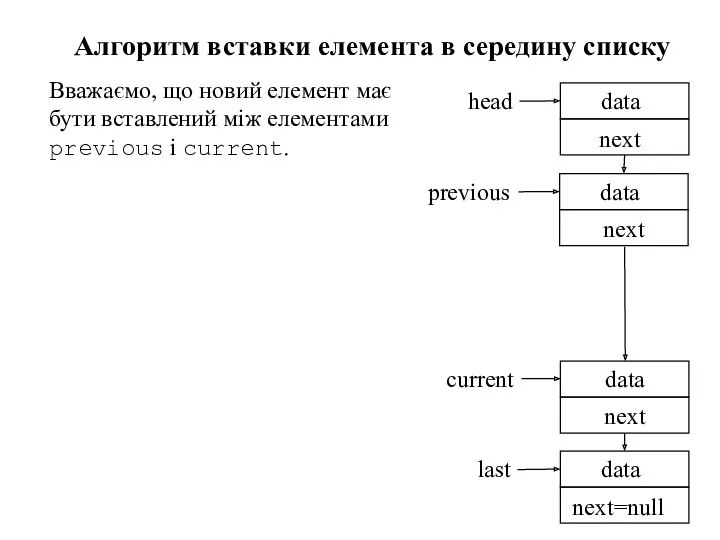
Алгоритм вставки елемента в середину списку
Вважаємо, що новий елемент має бути
Алгоритм вставки елемента в середину списку
Вважаємо, що новий елемент має бути
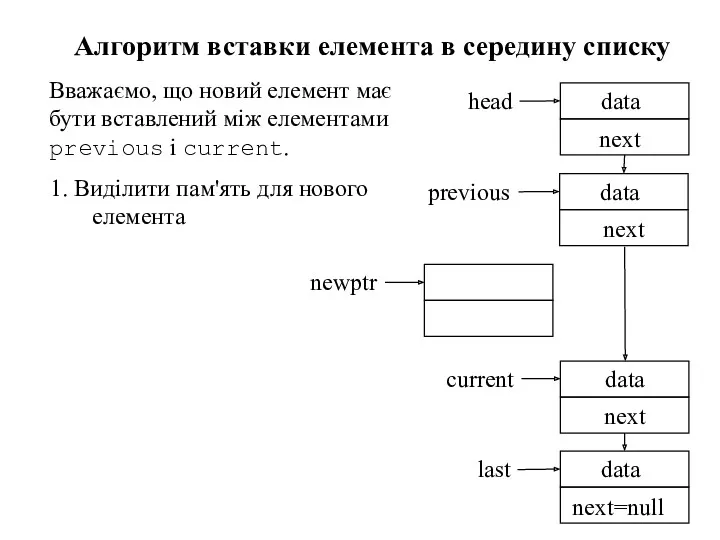
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента в середину списку
Вважаємо,
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента в середину списку
Вважаємо,
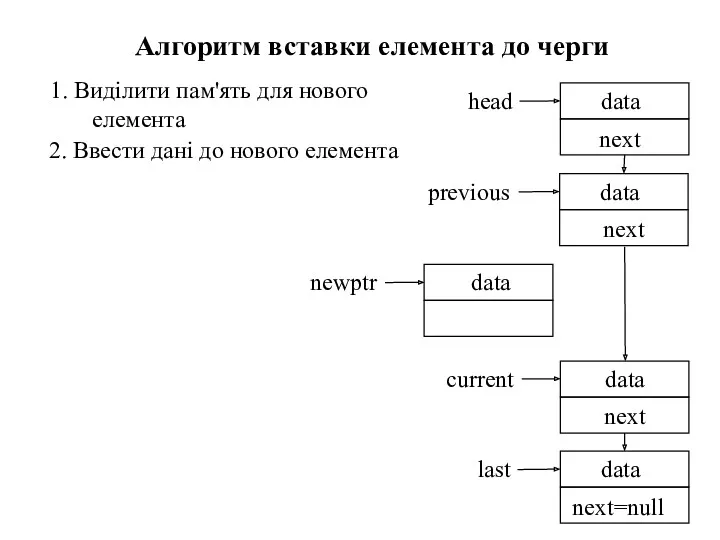
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента до черги
2. Ввести
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента до черги
2. Ввести
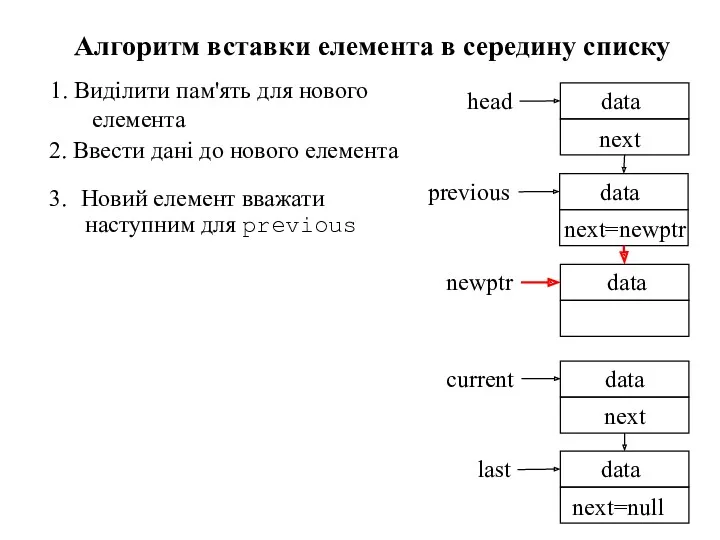
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента в середину списку
2.
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента в середину списку
2.
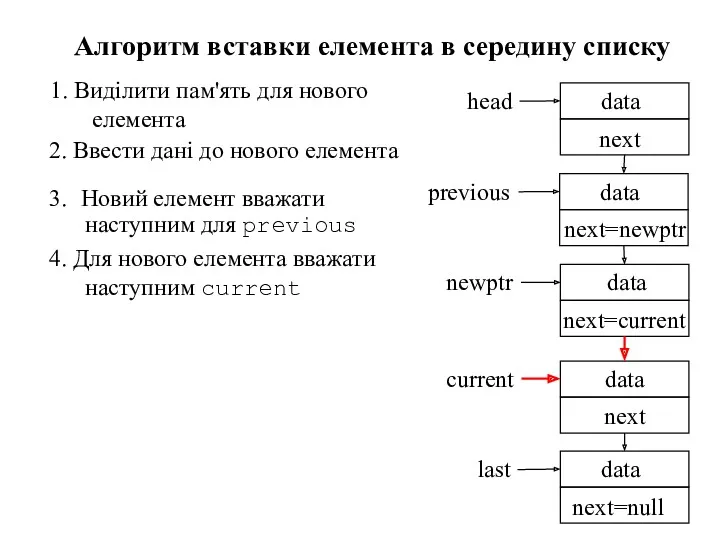
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента в середину списку
2.
1. Виділити пам'ять для нового елемента
Алгоритм вставки елемента в середину списку
2.
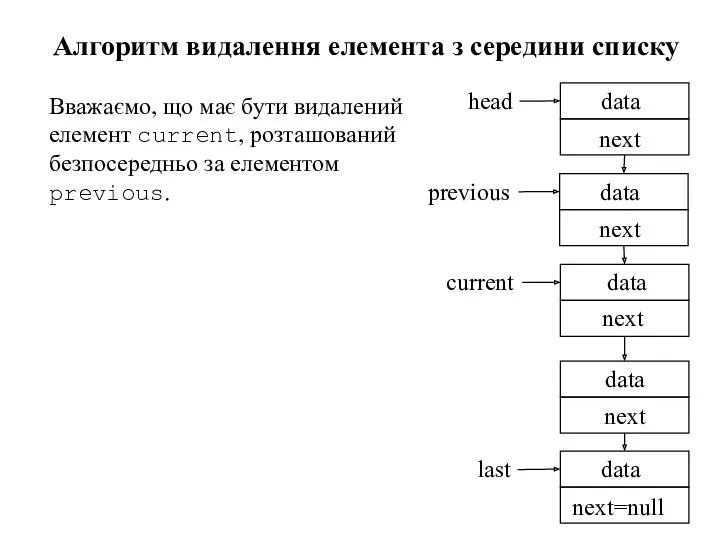
Алгоритм видалення елемента з середини списку
Вважаємо, що має бути видалений елемент
Алгоритм видалення елемента з середини списку
Вважаємо, що має бути видалений елемент
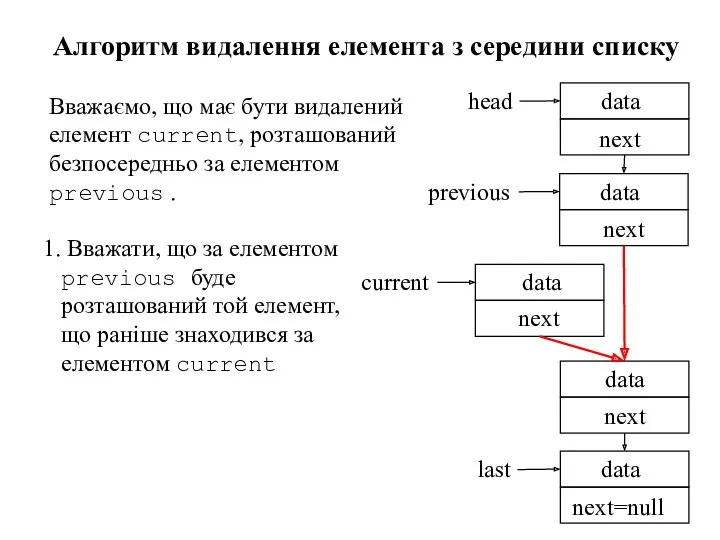
1. Вважати, що за елементом previous буде розташований той елемент,
1. Вважати, що за елементом previous буде розташований той елемент,
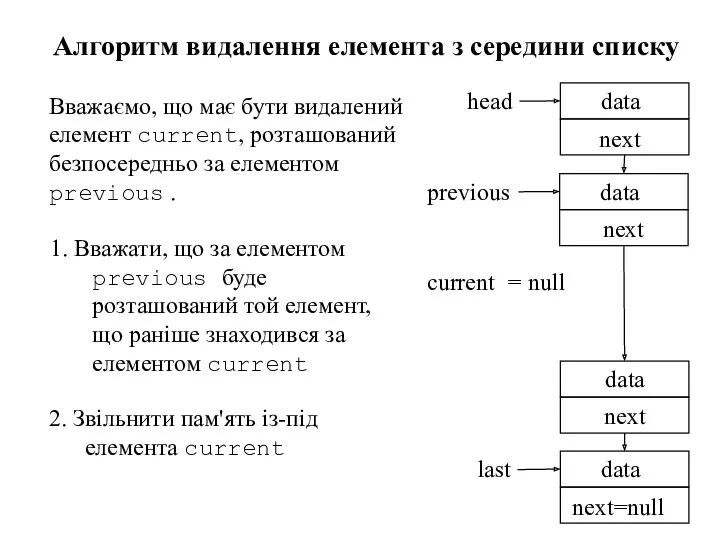
1. Вважати, що за елементом previous буде розташований той елемент, що
1. Вважати, що за елементом previous буде розташований той елемент, що
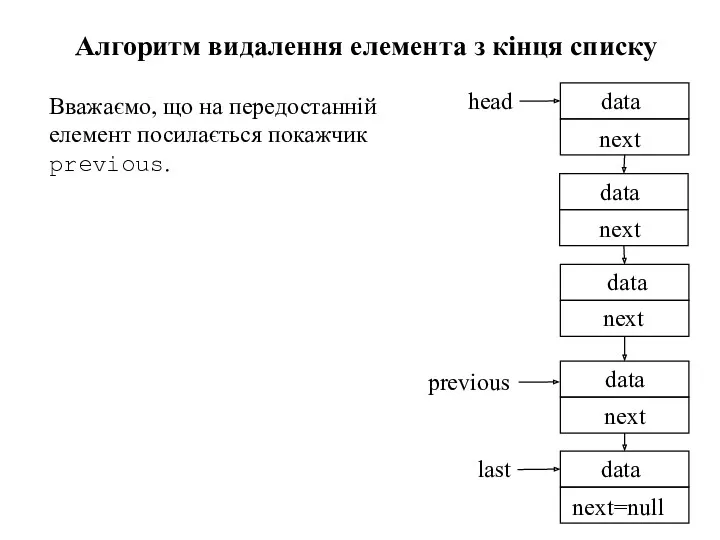
Алгоритм видалення елемента з кінця списку
Вважаємо, що на передостанній елемент посилається
Алгоритм видалення елемента з кінця списку
Вважаємо, що на передостанній елемент посилається
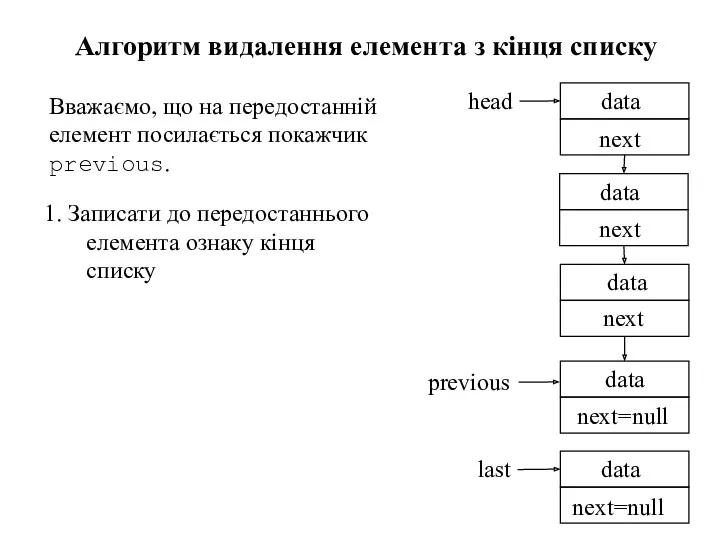
1. Записати до передостаннього елемента ознаку кінця списку
Алгоритм видалення елемента з
1. Записати до передостаннього елемента ознаку кінця списку
Алгоритм видалення елемента з
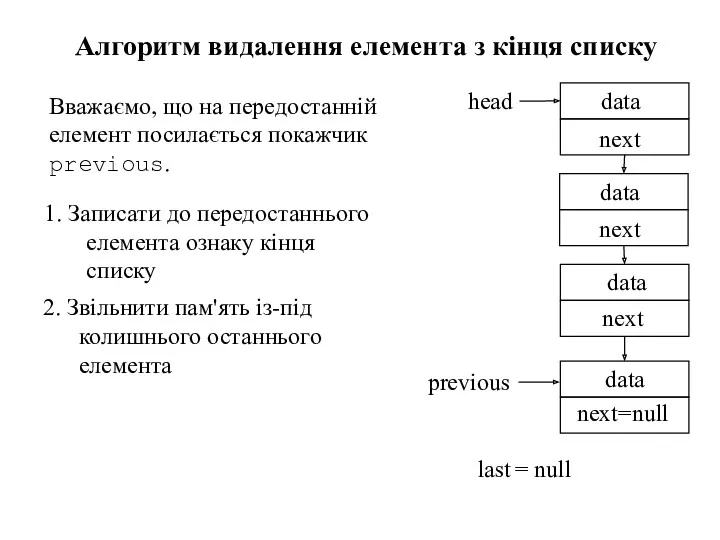
1. Записати до передостаннього елемента ознаку кінця списку
Алгоритм видалення елемента з
1. Записати до передостаннього елемента ознаку кінця списку
Алгоритм видалення елемента з
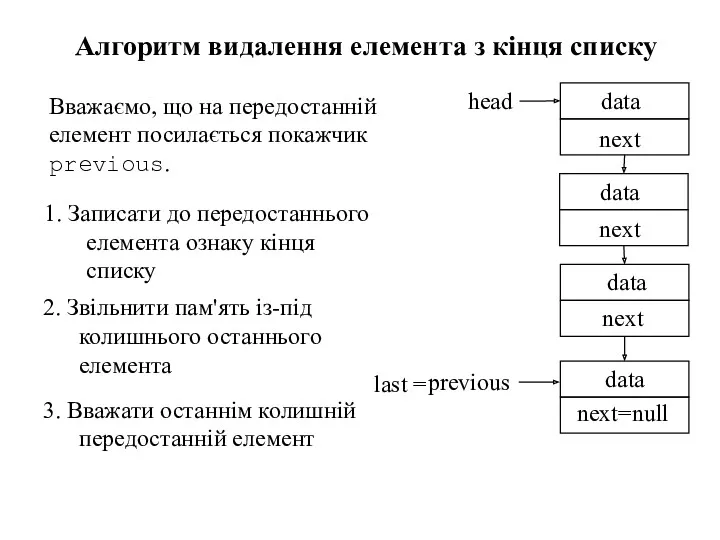
1. Записати до передостаннього елемента ознаку кінця списку
Алгоритм видалення елемента з
1. Записати до передостаннього елемента ознаку кінця списку
Алгоритм видалення елемента з

Приклад. Алгоритм роботи з алфавітним переліком слів.
1. Вважати список порожнім.
2. Вивести
Приклад. Алгоритм роботи з алфавітним переліком слів.
1. Вважати список порожнім.
2. Вивести

4. Якщо натиснута клавіша D, видалити елемент зі списку.
4.1. Ввести слово,
4. Якщо натиснута клавіша D, видалити елемент зі списку.
4.1. Ввести слово,

Приклади, що ілюструють реалізації АТД “Однозв'язний лінійний список”:
реалізація за допомогою
Приклади, що ілюструють реалізації АТД “Однозв'язний лінійний список”:
реалізація за допомогою
![3.6. Двозв'язний лінійний список Література для самостійного читання: с. 57-58 [1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-100.jpg)
3.6. Двозв'язний лінійний список
Література для самостійного читання:
с. 57-58 [1]
3.6. Двозв'язний лінійний список
Література для самостійного читання:
с. 57-58 [1]

Часто виникає необхідність організувати ефективне пересування по списку як в
Часто виникає необхідність організувати ефективне пересування по списку як в
![3.7. Відображення Література для самостійного читання: с. 66-68 [1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-102.jpg)
3.7. Відображення
Література для самостійного читання:
с. 66-68 [1]
3.7. Відображення
Література для самостійного читання:
с. 66-68 [1]

Відображення - це функція, визначена на множині елементів одного типу (області
Відображення - це функція, визначена на множині елементів одного типу (області

Перелік операторів, які можна виконати над відображенням М.
перетворення відображення на порожнє;
призначення
Перелік операторів, які можна виконати над відображенням М.
перетворення відображення на порожнє;
призначення

Реалізація відображень за допомогою масивів
У багатьох випадках тип елементів області
Реалізація відображень за допомогою масивів
У багатьох випадках тип елементів області

Реалізація відображень за допомогою списків
Існує багато реалізацій відображень з кінцевою областю
Реалізація відображень за допомогою списків
Існує багато реалізацій відображень з кінцевою областю
![3.8. АТД “Дерево” Література для самостійного читання: с. 77-89 [1], с. 326-330 [4]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-107.jpg)
3.8. АТД “Дерево”
Література для самостійного читання:
с. 77-89 [1], с. 326-330
3.8. АТД “Дерево”
Література для самостійного читання:
с. 77-89 [1], с. 326-330

Розглянуті раніше списки, стеки та черги належать до лінійних динамічних структур
Розглянуті раніше списки, стеки та черги належать до лінійних динамічних структур

Представлення дерев за допомогою масивів
Нехай Т - дерево з вузлами 1,
Представлення дерев за допомогою масивів
Нехай Т - дерево з вузлами 1,
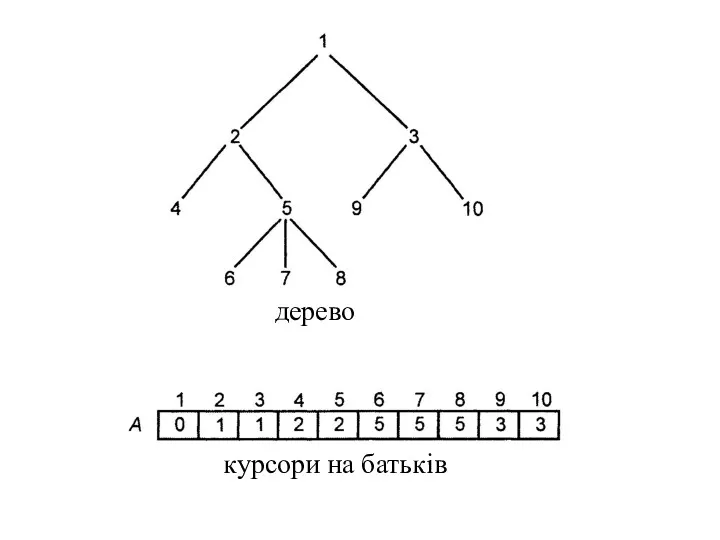

Використання покажчиків або курсорів на батьків не допомагає в реалізації операторів,
Використання покажчиків або курсорів на батьків не допомагає в реалізації операторів,

Представлення дерев з використанням списків синів
Важливий і корисний спосіб представлення
Представлення дерев з використанням списків синів
Важливий і корисний спосіб представлення
![З прикладом реалізації можна ознайомитись в (с.87-88 [1]).](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-113.jpg)
З прикладом реалізації можна ознайомитись в (с.87-88 [1]).
З прикладом реалізації можна ознайомитись в (с.87-88 [1]).
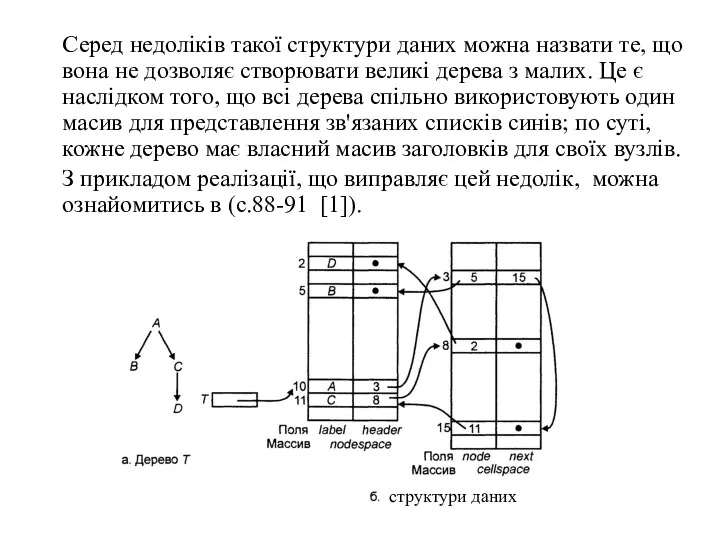
Серед недоліків такої структури даних можна назвати те, що вона не
Серед недоліків такої структури даних можна назвати те, що вона не
![3.9. Бінарні дерева Література для самостійного читання: с. 91-99 [1], с. 328-336 [4]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-115.jpg)
3.9. Бінарні дерева
Література для самостійного читання:
с. 91-99 [1], с. 328-336
3.9. Бінарні дерева
Література для самостійного читання:
с. 91-99 [1], с. 328-336
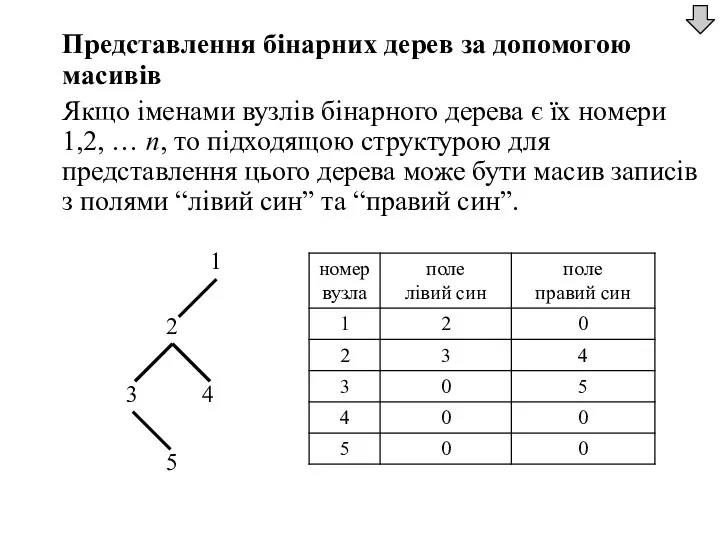
Представлення бінарних дерев за допомогою масивів
Якщо іменами вузлів бінарного дерева є
Представлення бінарних дерев за допомогою масивів
Якщо іменами вузлів бінарного дерева є

Представлення бінарних дерев за допомогою нелінійних динамічних структур
Будь-який вузол бінарного дерева
Представлення бінарних дерев за допомогою нелінійних динамічних структур
Будь-який вузол бінарного дерева
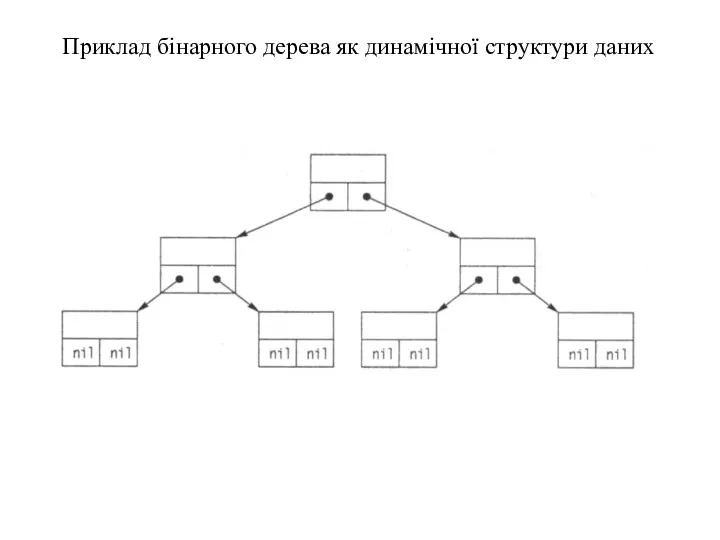
Приклад бінарного дерева як динамічної структури даних
Приклад бінарного дерева як динамічної структури даних

Алгоритми роботи з бінарними деревами
Створення бінарного дерева
Найпростіший спосіб побудови бінарного дерева
Алгоритми роботи з бінарними деревами
Створення бінарного дерева
Найпростіший спосіб побудови бінарного дерева

Приклад. Створення бінарного дерева із заданою користувачем кількістю вузлів.
Оскільки
Приклад. Створення бінарного дерева із заданою користувачем кількістю вузлів.
Оскільки

Функція створення дерева tree отримує один цілочисловий параметр AmountNode, що визначає
Функція створення дерева tree отримує один цілочисловий параметр AmountNode, що визначає


Дерево відображатиме рекурсивна процедура printtree. Піддерево рівня L виводитиметься так: спочатку
Дерево відображатиме рекурсивна процедура printtree. Піддерево рівня L виводитиметься так: спочатку

Обхід дерева
Алгоритм доступу до всіх вузлів дерева називається обходом дерева. Трьома
Обхід дерева
Алгоритм доступу до всіх вузлів дерева називається обходом дерева. Трьома
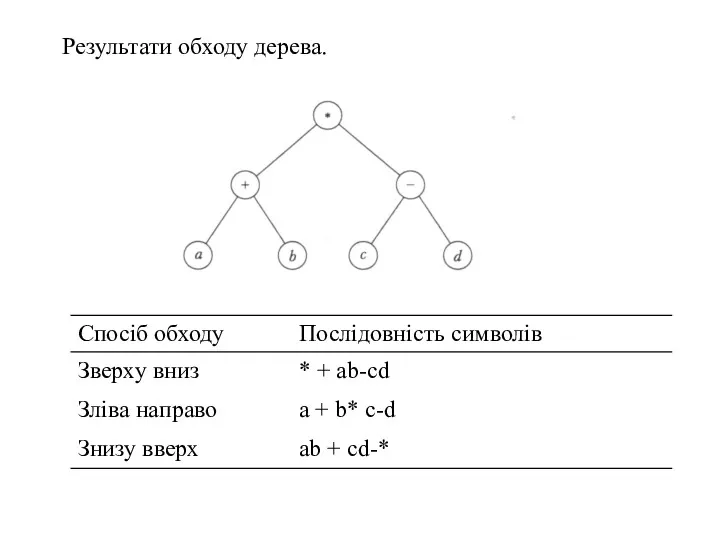
Результати обходу дерева.
Результати обходу дерева.

Будь-який спосіб обходу дерева можна реалізувати рекурсивною процедурою.
До цих процедур передається
Будь-який спосіб обходу дерева можна реалізувати рекурсивною процедурою.
До цих процедур передається


![Домашнє завдання Прочитати с.23-83 [1] , с.310-341 [4] Підготуватися до виконання практичної роботи №3.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/297068/slide-130.jpg)
Домашнє завдання
Прочитати с.23-83 [1] , с.310-341 [4]
Підготуватися до виконання практичної роботи
Домашнє завдання
Прочитати с.23-83 [1] , с.310-341 [4]
Підготуватися до виконання практичної роботи
 Системы счисления. 10 класс
Системы счисления. 10 класс Ai2 APP Inventor. Переводчик
Ai2 APP Inventor. Переводчик Разработка приложений с использованием .NET Framework
Разработка приложений с использованием .NET Framework Подготовка кандидатов к собеседованию по техническим вопросам
Подготовка кандидатов к собеседованию по техническим вопросам Основні види графічних зображень статистичних показників та їх використання в статистичному аналізі
Основні види графічних зображень статистичних показників та їх використання в статистичному аналізі Инструкция пользования роботом
Инструкция пользования роботом Domains with nothing on
Domains with nothing on Система управления базами данных Microsoft Access и хранение служебной информации МЧС. Архитектура СУБД Access. (Тема 1.1)
Система управления базами данных Microsoft Access и хранение служебной информации МЧС. Архитектура СУБД Access. (Тема 1.1) СЕТИ (ПРОТОКОЛЫ СЕТЕВОГО ВЗАИМОДЕЙСТВИЯ) SOFTWARE
СЕТИ (ПРОТОКОЛЫ СЕТЕВОГО ВЗАИМОДЕЙСТВИЯ) SOFTWARE КРУЖОК ИНФОРМАТИКИ МИКРОША
КРУЖОК ИНФОРМАТИКИ МИКРОША Создание цветных узоров КОМПАС 3 D-LT
Создание цветных узоров КОМПАС 3 D-LT Понятие информации
Понятие информации Фантастический TI и где он обитает
Фантастический TI и где он обитает Конструирование алгоритмов
Конструирование алгоритмов Синтаксис языка VBA. Лекция 4
Синтаксис языка VBA. Лекция 4 Интеграция информационной системы DPD
Интеграция информационной системы DPD Электронные таблицы. Встроенные функции. Графическое представление данных
Электронные таблицы. Встроенные функции. Графическое представление данных Работа с личным кабинетом
Работа с личным кабинетом Кодирование текстовой информации. Представление информации в компьютере
Кодирование текстовой информации. Представление информации в компьютере История развития операционной системы Windows
История развития операционной системы Windows Основные задачи управления организацией как предмет автоматизации в современных информационных системах
Основные задачи управления организацией как предмет автоматизации в современных информационных системах Історія створення інтернету
Історія створення інтернету Parts of the Computer
Parts of the Computer Система контроля версий Git
Система контроля версий Git Компьютерная графка. (6 класс)
Компьютерная графка. (6 класс) Новые формы подачи информации
Новые формы подачи информации Java бағдарламалау тілі
Java бағдарламалау тілі Исследование уязвимостей в беспроводных сетях поколения 4G при администрировании и эксплуатации таких сетей
Исследование уязвимостей в беспроводных сетях поколения 4G при администрировании и эксплуатации таких сетей