- Алгоритм индуцирования знаний из БД

Содержание
- 2. Исходная база данных, из которой извлекаются знания Окончание на следующем слайде…
- 3. (окончание)
- 4. Искомый атрибут «Прибыль» будем называть атрибутом класса. Для построения дерева решений нужно взять один из атрибутов
- 6. Из таблицы видно, что при значении атрибута «Возраст», равном «новый», прибыль всегда растёт, а при значении
- 7. Получим другую таблицу:
- 8. Поскольку теперь для атрибута класса наше дерево решений выво-дит однозначный ответ, то дерево решений построено. Порождаем
- 9. 3. ЕСЛИ Возраст = средний И Конкуренция = нет ТО Прибыль = растёт. 4. ЕСЛИ Возраст
- 10. Алгоритм C4.5 Улучшает базовый алгоритм индуцирования знаний. Основнoе отличие: следующий условный атрибут, по которому проводится разбиение,
- 11. Общее описание алгоритма C4.5 Алгоритм работает для таких таблиц данных, в которых атрибут класса (целевой атрибут)
- 12. |T | — мощность множества примеров (количество строк в таблице или подтаблице данных); C1 , C2
- 13. A1 , A2 , …, An — значения, принимаемые текущим условным атрибутом;
- 14. Выбор условного атрибута для разбиения Пусть рассматриваем условный атрибут X, принимающий n значений A1, A2 ...
- 15. Тогда вероятность того, что случайно выбранная строка из таблицы T будет принадлежать классу Cj, равна Например,
- 16. Согласно теории информации, количество содержащейся в сообщении информации зависит от её вероятности log2(1/P) = - log2(P).
- 17. Энтропия таблицы T, то есть среднее количество информации, необходимое для определения класса, к которому относится строка
- 18. Энтропия таблицы T после её разбиения по атрибуту X на n подтаблиц:
- 19. Критерий для выбора атрибута X – следующего атрибута для разбиения:
- 20. Шаги алгоритма C4.5 Шаг 1. Для всех условных атрибутов X1, … Xm таблицы T вычисляем критерий
- 21. Пример работы алгоритма C4.5 В качестве примера возьмём уже известную нам задачу о построении базы знаний
- 22. Расчёт критерия разбиения для атрибута «ВОЗРАСТ» Info(T1) = -(3/3 · log2(3/3)) = 0. Info(T2) = -(3/3
- 23. Расчёт критерия разбиения для атрибута «КОНКУРЕЦИЯ» Info(T1) = -(1/4 · log2(1/4) + 3/4 · log2(3/4))= =
- 25. Скачать презентацию
 Презентация Технологии создания и обработки графической информации, работа с фрагментами изображений. Графический редактор Paint.
Презентация Технологии создания и обработки графической информации, работа с фрагментами изображений. Графический редактор Paint. Интернет-журналистика
Интернет-журналистика Transaction Processing, Functional Applications, CRM, and Integration
Transaction Processing, Functional Applications, CRM, and Integration Разработка кода информационных систем
Разработка кода информационных систем Объектно-ориентированное программирование. Язык Python (§46-50). 11 класс
Объектно-ориентированное программирование. Язык Python (§46-50). 11 класс Детская деревня-SOS. Программа укрепления семьи
Детская деревня-SOS. Программа укрепления семьи Создание структуры базы данных. Семинар 3. Введение в базы данных
Создание структуры базы данных. Семинар 3. Введение в базы данных Компьютерные вирусы, признаки заражения
Компьютерные вирусы, признаки заражения Установка и деинсталляция программ в ОС Linux
Установка и деинсталляция программ в ОС Linux Библиотека в соцсети - практические рекомендации
Библиотека в соцсети - практические рекомендации Настольные и серверные СУБД. Доступ к данным БД
Настольные и серверные СУБД. Доступ к данным БД Логические выражения. Построение таблиц истинности логических выражений
Логические выражения. Построение таблиц истинности логических выражений Векторная графика. Графические возможности MS Word
Векторная графика. Графические возможности MS Word Технические средства реализации информационных процессов
Технические средства реализации информационных процессов Global Diagnostic System. Описание GDS
Global Diagnostic System. Описание GDS How the Web is changing the world
How the Web is changing the world Презентация СAD-CAM-CAE-системы-назначение, виды, история
Презентация СAD-CAM-CAE-системы-назначение, виды, история Проект Компьютер друг?
Проект Компьютер друг? Решение задач линейного программирования графическим методом
Решение задач линейного программирования графическим методом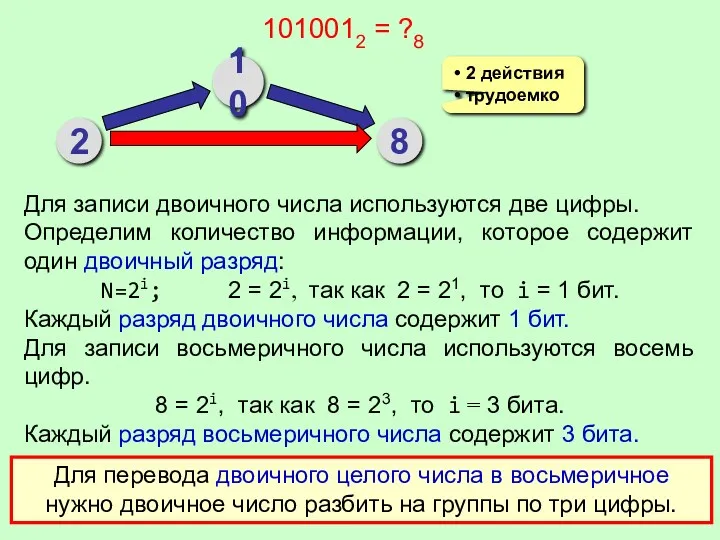 Перевод из двоичной системы в восьмеричную, шестнадцатеричную и обратно
Перевод из двоичной системы в восьмеричную, шестнадцатеричную и обратно PR on the Internet
PR on the Internet Прокси сервер
Прокси сервер Создание проектов на Уроках информатики 4-9 класс
Создание проектов на Уроках информатики 4-9 класс Створення реляційної бази даних. Лекція № 6
Створення реляційної бази даних. Лекція № 6 Условный оператор if. Введение в программирование на языке Python
Условный оператор if. Введение в программирование на языке Python Проект по розробці універсального додатку АнтиМат
Проект по розробці універсального додатку АнтиМат Основы HTML и CSS. Ссылки и иллюстрации
Основы HTML и CSS. Ссылки и иллюстрации Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы