- Алгоритм кластеризації k-means (1)

Содержание
- 2. Алгоритм кластеризації k-means (2) Крок 4, прохід 1. Обчислюємо центроїди, до яких переміщаються центр кластерів: Ц1=
- 3. Алгоритм кластеризації k-means (3) Крок 4, прохід 2. Обчислюємо нові центроїди для кожного кластеру: Ц1= [(1+1+1+2/4);(3+2+1+1/4)]=(1,25;1,75);
- 4. Наївний Байєсовький класифікатор (1) Для заданого набору даних, з використанням наївного байєсовського класифікатора визначте, який статус
- 5. ДЕРЕВА РІШЕНЬ (1) На основі навчальної вибірки побудуйте дерево рішень для визначення бажання різних категорій споживачів
- 6. ДЕРЕВА РІШЕНЬ (2) На основі навчальної вибірки побудуйте дерево рішень для визначення бажання різних категорій споживачів
- 7. ДЕРЕВА РІШЕНЬ (3) Ентропія блоку: I(SТАК, SНІ)= I(2,3)= -2/5 log(2/5) – 3/5 log(3/5)=0.97 Дохід: 3 значення:
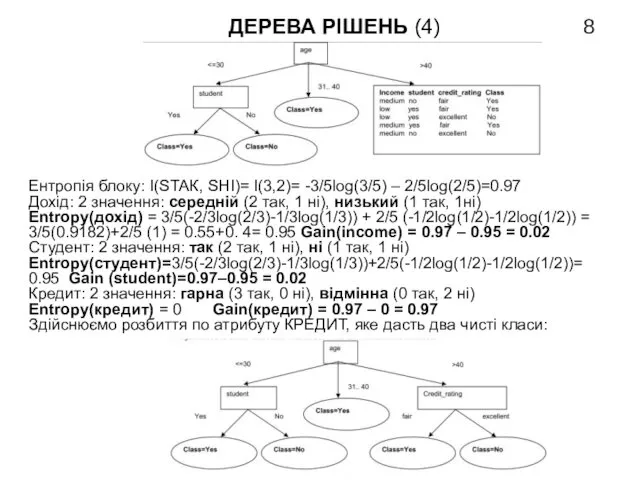
- 8. ДЕРЕВА РІШЕНЬ (4) Ентропія блоку: I(SТАК, SНІ)= I(3,2)= -3/5log(3/5) – 2/5log(2/5)=0.97 Дохід: 2 значення: середній (2
- 9. АСОЦІАТИВНІ ПРАВИЛА (1) T1{M,O,N,K,E,Y}; T2{D,O,N,K,E,Y}; T3{M,A,K,E}; T4{{M,U,C,K,Y}; T5{C,O,O,K,I,E};підтримка – 60%; довіра – 80%. ПРАВИЛА: A→B: P(B|A)=|B∩A|/|A|
- 10. МЕРЕЖА КОХОНЕНА (1) Розглянемо приклад роботи мережі Кохонена, що містить 2 х 2 нейрона у вихідному
- 11. МЕРЕЖА КОХОНЕНА (2) Випадковим чином виберемо початкові значення ваг нейронів: Сформуємо набір записів вхідної вибірки: Конкуренція.
- 12. МЕРЕЖА КОХОНЕНА (3) Початкові значення ваг нейронів: Hабір записів вхідної вибірки: Виконавши операції конкуренції та підстроювання
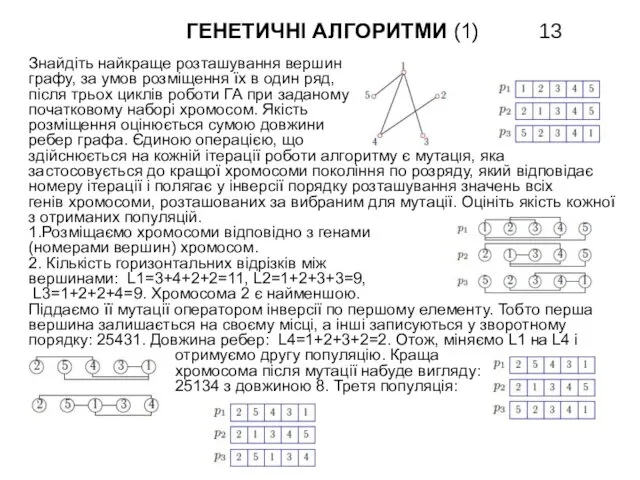
- 13. ГЕНЕТИЧНІ АЛГОРИТМИ (1) Знайдіть найкраще розташування вершин графу, за умов розміщення їх в один ряд, після
- 14. ГЕНЕТИЧНІ АЛГОРИТМИ (2) Задано початкову популяцію з 4 хромосом, кожна з яких має по 2 гени
- 15. ГЕНЕТИЧНІ АЛГОРИТМИ (2)
- 16. ГЕНЕТИЧНІ АЛГОРИТМИ (3)
- 18. Скачать презентацию

Алгоритм кластеризації k-means (2)
Крок 4, прохід 1. Обчислюємо центроїди,
Алгоритм кластеризації k-means (2)
Крок 4, прохід 1. Обчислюємо центроїди,

Алгоритм кластеризації k-means (3)
Крок 4, прохід 2. Обчислюємо нові
Алгоритм кластеризації k-means (3)
Крок 4, прохід 2. Обчислюємо нові

Наївний Байєсовький класифікатор (1)
Для заданого набору даних, з використанням
Наївний Байєсовький класифікатор (1)
Для заданого набору даних, з використанням

ДЕРЕВА РІШЕНЬ (1)
На основі навчальної вибірки побудуйте дерево рішень
ДЕРЕВА РІШЕНЬ (1)
На основі навчальної вибірки побудуйте дерево рішень

ДЕРЕВА РІШЕНЬ (2)
На основі навчальної вибірки побудуйте дерево рішень
ДЕРЕВА РІШЕНЬ (2)
На основі навчальної вибірки побудуйте дерево рішень

ДЕРЕВА РІШЕНЬ (3)
Ентропія блоку: I(SТАК, SНІ)= I(2,3)= -2/5 log(2/5)
ДЕРЕВА РІШЕНЬ (3)
Ентропія блоку: I(SТАК, SНІ)= I(2,3)= -2/5 log(2/5)
ДЕРЕВА РІШЕНЬ (4)
Ентропія блоку: I(SТАК, SНІ)= I(3,2)= -3/5log(3/5) –
ДЕРЕВА РІШЕНЬ (4)
Ентропія блоку: I(SТАК, SНІ)= I(3,2)= -3/5log(3/5) –

АСОЦІАТИВНІ ПРАВИЛА (1)
T1{M,O,N,K,E,Y}; T2{D,O,N,K,E,Y}; T3{M,A,K,E}; T4{{M,U,C,K,Y};
T5{C,O,O,K,I,E};підтримка – 60%;
АСОЦІАТИВНІ ПРАВИЛА (1)
T1{M,O,N,K,E,Y}; T2{D,O,N,K,E,Y}; T3{M,A,K,E}; T4{{M,U,C,K,Y};
T5{C,O,O,K,I,E};підтримка – 60%;

МЕРЕЖА КОХОНЕНА (1)
Розглянемо приклад роботи мережі Кохонена, що містить
МЕРЕЖА КОХОНЕНА (1)
Розглянемо приклад роботи мережі Кохонена, що містить

МЕРЕЖА КОХОНЕНА (2)
Випадковим чином виберемо початкові значення ваг нейронів:
Сформуємо
МЕРЕЖА КОХОНЕНА (2)
Випадковим чином виберемо початкові значення ваг нейронів:
Сформуємо

МЕРЕЖА КОХОНЕНА (3)
Початкові значення
ваг нейронів:
Hабір записів
вхідної вибірки:
Виконавши
МЕРЕЖА КОХОНЕНА (3)
Початкові значення
ваг нейронів:
Hабір записів
вхідної вибірки:
Виконавши
ГЕНЕТИЧНІ АЛГОРИТМИ (1)
Знайдіть найкраще розташування вершин
графу, за умов
ГЕНЕТИЧНІ АЛГОРИТМИ (1)
Знайдіть найкраще розташування вершин
графу, за умов

ГЕНЕТИЧНІ АЛГОРИТМИ (2)
Задано початкову популяцію з
4 хромосом, кожна
ГЕНЕТИЧНІ АЛГОРИТМИ (2)
Задано початкову популяцію з
4 хромосом, кожна

ГЕНЕТИЧНІ АЛГОРИТМИ (2)
ГЕНЕТИЧНІ АЛГОРИТМИ (2)

ГЕНЕТИЧНІ АЛГОРИТМИ (3)
ГЕНЕТИЧНІ АЛГОРИТМИ (3)
 Cerberus Mouse FW update SOP
Cerberus Mouse FW update SOP Объекты, которые можно использовать в качестве гипперссылок
Объекты, которые можно использовать в качестве гипперссылок Консольный кабель. Что записано в конфигурационном файле по умолчанию. (Лекция 2)
Консольный кабель. Что записано в конфигурационном файле по умолчанию. (Лекция 2) Технологии хранения информации и больших объемов данных. Лекция 1
Технологии хранения информации и больших объемов данных. Лекция 1 Системы счисления. Виды систем счисления
Системы счисления. Виды систем счисления Основы разработки требований к ПО. Лекция 1
Основы разработки требований к ПО. Лекция 1 Абстрактный тип данных. Стек
Абстрактный тип данных. Стек Законодательство в сфере информационной безопасности
Законодательство в сфере информационной безопасности Жизненный цикл программного обеспечения ИС
Жизненный цикл программного обеспечения ИС Языки программирования. Основные понятия
Языки программирования. Основные понятия Кибер-квиз. Безопасный интернет
Кибер-квиз. Безопасный интернет Поняття електронної таблиці
Поняття електронної таблиці Работа с электронными таблицами в программе Microsoft Excel
Работа с электронными таблицами в программе Microsoft Excel История развития вычислительной техники
История развития вычислительной техники Основы научных исследований. Реферирование научной статьи
Основы научных исследований. Реферирование научной статьи Инженеры будущего: 3D технологии в образовании
Инженеры будущего: 3D технологии в образовании Условная функция и логические выражения в табличном процессоре Excel
Условная функция и логические выражения в табличном процессоре Excel Моделирование на UML. Диаграммы. Лекция 2
Моделирование на UML. Диаграммы. Лекция 2 Опасности в интернете. Мошенники в интернете
Опасности в интернете. Мошенники в интернете Системы перевода и распознавания текстов
Системы перевода и распознавания текстов Разработка приложения Windows Forms на PascalABC для расчета стоимости товара и использование структуры алгоритма расчета
Разработка приложения Windows Forms на PascalABC для расчета стоимости товара и использование структуры алгоритма расчета Компьютерная этика
Компьютерная этика Атмосферные эффекты в 3d
Атмосферные эффекты в 3d Обработка текстовой информации. Текстовый редактор
Обработка текстовой информации. Текстовый редактор Опыт подсчета запасов золоторудного месторождения Узбекистана с использованием программного обеспечения Мicromine
Опыт подсчета запасов золоторудного месторождения Узбекистана с использованием программного обеспечения Мicromine Всероссийская акция Час кода
Всероссийская акция Час кода Перевод целых чисел из десятичной системы счисления в любую другую систему счисления А10→Ах
Перевод целых чисел из десятичной системы счисления в любую другую систему счисления А10→Ах Дистанционное обучение. Использование ресурса ЯКЛАСС
Дистанционное обучение. Использование ресурса ЯКЛАСС