Алгоритмы и структуры данных. Лекция 1. Общие представления о алгоритмах и структурах данных презентация
- Алгоритмы и структуры данных. Лекция 1. Общие представления о алгоритмах и структурах данных

Содержание
- 2. Лекция 1. Общие представления о алгоритмах и структурах данных
- 3. Что такое алгоритм Вычислительный алгоритм - это строго детерминированная последовательность операций, преобразующих исходные данные в искомый
- 4. Формы записи вычислительных алгоритмов Символьная форма записи представляет собой набор математических выражений и текстовых пояснений, где
- 5. Формы записи вычислительных алгоритмов Графическая форма записи - подразумевает представление алгоритма в виде блок-схемы - совокупности
- 6. Структурная классификация алгоритмов Алгоритмы с линейной структурой (или просто - линейные алгоритмы). Характерной особенностью алгоритмов этого
- 7. Структурная классификация алгоритмов 2 Алгоритмы разветвляющейся структуры. Алгоритмическая структура называется разветвляющейся, если она содержит несколько ветвей
- 8. Структурная классификация алгоритмов 3 Алгоритмы циклической структуры. Характерной особенностью циклических алгоритмов является наличие в них фрагмента
- 9. Структурная классификация алгоритмов 4 Многие из реально существующих алгоритмов имеют смешанный характер, т.е. могут содержать линейные
- 10. Общая классификация алгоритмов 5 Существуют фундаментальные алгоритмы (сортировка, алгоритмы на графах, шифрование). Это алгоритмы дискретной математики.
- 11. Свойства алгоритмов Конечность Алгоритм должен всегда заканчиваться после выполнения конечного числа шагов Число шагов может очень
- 12. Свойства алгоритмов 2 Вывод У алгоритма есть одно или несколько выходных данных, т. е. величин, имеющих
- 13. Анализ алгоритмов 1 Мера эффективности - определение затрат времени, действительное время, затраченное на выполнение алгоритма в
- 14. Анализ алгоритмов 2
- 15. Анализ алгоритмов 3 Три основных ограничения в экспериментальных исследованиях: • эксперименты могут проводиться лишь с использованием
- 16. Анализ алгоритмов 4 Общая методология анализа времени выполнения алгоритмов • учитывает различные типы входных данных; •
- 17. Псевдокод Непрерывный объект – это объект теоретический. Можно доказать, что существует, но нельзя провести вычисления, так
- 18. Лекция 2. Алгоритм и способ его описания
- 19. Этапы решения задачи Постановка (формулировка) задачи; • построение модели, выбор метода решения задачи; • разработка алгоритма;
- 20. Что такое алгоритм Алгоритм – строгая и четкая система правил, определяющая последовательность действий над некоторыми объектами
- 21. Свойства алгоритма Определенность (детерминированность) алгоритма предполагает такое составление предписания, которое не оставляет места для различных толкований
- 22. Свойства алгоритма 2 Массовость определяет возможность использования любых исходных данных из некоторого допустимого множества. Правило, сформулированное
- 23. Свойства алгоритма 3 Результативность (конечность) алгоритма означает, что при любом допустимом исходном наборе данных алгоритм закончит
- 24. Классификация алгоритмов Линейные алгоритмы описывают линейный вычислительный процесс, этапы которого выполняются однократно и последовательно один за
- 25. Классификация алгоритмов Линейные алгоритмы описывают линейный вычислительный процесс, этапы которого выполняются однократно и последовательно один за
- 26. Классификация алгоритмов Разветвляющийся алгоритм описывает вычислительный процесс, реализация которого происходит по одному из нескольких заранее предусмотренных
- 27. Классификация алгоритмов Циклический алгоритм описывает вычислительный процесс, этапы которого повторяются многократно. Различают простые циклы, не содержащие
- 28. Способы описания алгоритмов Существуют следующие способы описания алгоритмов: 1) запись на естественном языке (словесное описание); 2)
- 29. Графическое описание алгоритма
- 30. Блок-схема алгоритма нахождения максимального из трех заданных чисел
- 31. Блок-схема алгоритма вычисления графика функции в заданном интервале
- 32. Вычисление значения функции с переменным количеством шагов Y = sin x = x – x3 /
- 33. Основные понятия Абстрактный тип данных АТД (формально введен в 1974 г. Б.Лисков.) Но фактически использовалось Кнутом
- 34. Основные понятия Линейно связанный список (linked list) – набор элементов, последовательно связанных друг с другом так,
- 35. Операции со списком 1) Доступ к элементам: n = first(L) n = last(L) n = next(L,n)
- 36. Операции со списком Что нового по сравнению с массивами? У массива есть размер и произвольный доступ.
- 37. Операции со списком Пример [ ann, tennis, tom, skiing ] [ ] Элемент ann – голова
- 38. Операции со списком Пример [ ann, tennis, tom, skiing ] [ ] Элемент ann – голова
- 39. Реализация списка На С typedef struct list_tag { int data; // здесь может быть, что угодно
- 40. Реализация списка 1) Операции first и next list * first(list*L) { return L; } list *
- 41. Алгоритмы и структуры 3) Операция вставка n после p void insert_after(list*L,list*p,list*n) { n->next = p->next; p->next
- 42. Реализация списка 5) Операция remove list* remove(list*L, list*n) { list * r = n->next; // меняем
- 43. Реализация списка. Важные выводы Все рассмотренные выше операции имеют сложность О(1). Кроме особых случаев. При этом
- 44. Реализация списка. Продолжение 6 6) Операция search list* search(list*L, int key) { do { if( L->data
- 45. Реализация списка. Продолжение 7 и 8 Вспомогательные операции – создание и уничтожение списков Конструкторы и деструкторы
- 46. Реализация двусвязного списка
- 47. Реализация двусвязного списка Определение списка typedef struct list_tag { int data; // здесь может быть, что
- 48. Реализация двусвязного списка 1) Операции first и next int isempty(list*L) { return L->next == L ?
- 49. Реализация двусвязного списка 3) Операция вставка n после p void insert_after(list*L,list*p,list*n) { n->next = p->next; n->prev
- 50. Реализация двусвязного списка 5) Операция remove void remove(list*L, list*n) { n->prev->next = n->next; n->next->prev = n->prev;
- 51. Реализация двусвязного списка Вспомогательные операции – создание и уничтожение списков Конструкторы и деструкторы 7) Операция создания
- 52. Реализация двусвязного списка Пример int main(void) { list *head = list_create(0),*n; int i,N = 6; for(i=0;i
- 53. Стеки Определение стека Стек – это специальный вид списка, для которого все операции выполняются исключительно с
- 54. Стек подобен железнодорожному депо
- 55. Операции со стеком Операции со стеком Доступ к элементам и изменение стека: n = pop(S) --
- 56. Реализация стека Реализация стека Можно просто использовать односвязный список. Сделаем через свою реализацию. typedef struct stack_tag
- 57. Реализация стека 2 Реализация стека void PUSH(stack_t*S,void*data,int size) { stack_t*n=malloc(sizeof(stack_t)+size); n->data = n + sizeof(stack_t); memcpy(n->data,
- 58. Реализация стека 3 Реализация стека 1) Память под данные должна распределяться так n->data = n +
- 59. Реализация стека 4 Реализация стека Используем макросы #define PUSH(S,d,size) do{ \ STACK*n=malloc(sizeof(STACK)+size); \ n->data = n
- 60. Очереди Определение очереди Очередь – это специальный вид списка, для которого добавление элемента осуществляется в конец
- 61. Реализация очереди Реализация очереди Можно просто использовать односвязный список. Но операция добавления в конец будет О(N).
- 62. Реализация очереди 2 Реализация очереди Сделаем через свою реализацию. typedef struct queue_link_tag queue_link; struct queue_link {
- 63. Реализация очереди 3 Реализация очереди void ADD(queue_t*q,void*data) { queue_link*n=malloc(sizeof(queue_link)+q->size); n->data = n + 1; memcpy(n->data, data,
- 64. Деки Определение дека Дек (deque - double ended queue) – это специальный вид списка, для которого
- 65. Задание. Деки 1) Реализовать все операции для списка и двусвзяного списка в данных выше реализациях 2)
- 66. Метод пузырька #include int main() { int n, i, j; scanf_s("%d", &n); int a[n]; // считываем
- 67. Метод вставки #include int main() { int n, i, j; scanf_s("%d", &n); int a[n]; // считываем
- 68. Метод Шелла #include int main() { int n, i, j; scanf_s("%d", &n); int a[n]; // считываем
- 69. Усовершенствованные методы #include int main() { int n, i, j; scanf_s("%d", &n); int a[n]; // считываем
- 71. Скачать презентацию

Лекция 1.
Общие представления о алгоритмах и структурах данных
Лекция 1.
Общие представления о алгоритмах и структурах данных

Что такое алгоритм
Вычислительный алгоритм - это строго детерминированная последовательность операций,
Что такое алгоритм
Вычислительный алгоритм - это строго детерминированная последовательность операций,

Формы записи вычислительных алгоритмов
Символьная форма записи представляет собой набор математических выражений
Формы записи вычислительных алгоритмов
Символьная форма записи представляет собой набор математических выражений

Формы записи вычислительных алгоритмов
Графическая форма записи - подразумевает представление алгоритма в
Формы записи вычислительных алгоритмов
Графическая форма записи - подразумевает представление алгоритма в

Структурная классификация алгоритмов
Алгоритмы с линейной структурой (или просто - линейные алгоритмы).
Характерной
Структурная классификация алгоритмов
Алгоритмы с линейной структурой (или просто - линейные алгоритмы).
Характерной

Структурная классификация алгоритмов 2
Алгоритмы разветвляющейся структуры.
Алгоритмическая структура называется разветвляющейся, если она
Структурная классификация алгоритмов 2
Алгоритмы разветвляющейся структуры.
Алгоритмическая структура называется разветвляющейся, если она

Структурная классификация алгоритмов 3
Алгоритмы циклической структуры.
Характерной особенностью циклических алгоритмов является наличие
Структурная классификация алгоритмов 3
Алгоритмы циклической структуры.
Характерной особенностью циклических алгоритмов является наличие

Структурная классификация алгоритмов 4
Многие из реально существующих алгоритмов имеют смешанный характер,
Структурная классификация алгоритмов 4
Многие из реально существующих алгоритмов имеют смешанный характер,

Общая классификация алгоритмов 5
Существуют фундаментальные алгоритмы (сортировка, алгоритмы на графах, шифрование).
Общая классификация алгоритмов 5
Существуют фундаментальные алгоритмы (сортировка, алгоритмы на графах, шифрование).

Свойства алгоритмов
Конечность
Алгоритм должен всегда заканчиваться после выполнения конечного числа шагов
Число
Свойства алгоритмов
Конечность
Алгоритм должен всегда заканчиваться после выполнения конечного числа шагов
Число

Свойства алгоритмов 2
Вывод
У алгоритма есть одно или несколько выходных данных,
т.
Свойства алгоритмов 2
Вывод
У алгоритма есть одно или несколько выходных данных,
т.

Анализ алгоритмов 1
Мера эффективности - определение затрат времени, действительное время,
Анализ алгоритмов 1
Мера эффективности - определение затрат времени, действительное время,
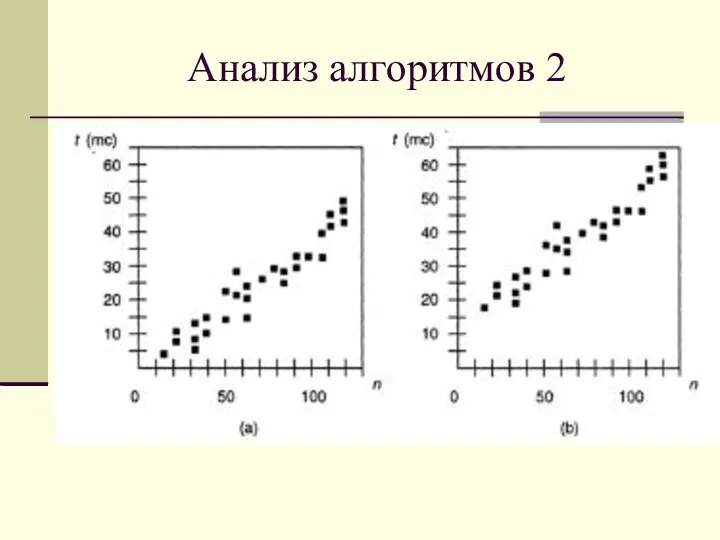
Анализ алгоритмов 2
Анализ алгоритмов 2

Анализ алгоритмов 3
Три основных ограничения в экспериментальных исследованиях:
• эксперименты могут
Анализ алгоритмов 3
Три основных ограничения в экспериментальных исследованиях:
• эксперименты могут

Анализ алгоритмов 4
Общая методология анализа времени выполнения алгоритмов
• учитывает
Анализ алгоритмов 4
Общая методология анализа времени выполнения алгоритмов
• учитывает

Псевдокод
Непрерывный объект – это объект теоретический. Можно доказать, что существует,
Псевдокод
Непрерывный объект – это объект теоретический. Можно доказать, что существует,

Лекция 2.
Алгоритм и способ его описания
Лекция 2.
Алгоритм и способ его описания

Этапы решения задачи
Постановка (формулировка) задачи;
• построение модели, выбор метода решения задачи;
•
Этапы решения задачи
Постановка (формулировка) задачи;
• построение модели, выбор метода решения задачи;
•

Что такое алгоритм
Алгоритм – строгая и четкая система правил, определяющая последовательность
Что такое алгоритм
Алгоритм – строгая и четкая система правил, определяющая последовательность

Свойства алгоритма
Определенность (детерминированность) алгоритма предполагает такое составление предписания, которое не оставляет
Свойства алгоритма
Определенность (детерминированность) алгоритма предполагает такое составление предписания, которое не оставляет

Свойства алгоритма 2
Массовость определяет возможность использования любых исходных данных из некоторого
Свойства алгоритма 2
Массовость определяет возможность использования любых исходных данных из некоторого

Свойства алгоритма 3
Результативность (конечность)
алгоритма означает, что при любом допустимом исходном
Свойства алгоритма 3
Результативность (конечность) алгоритма означает, что при любом допустимом исходном

Классификация алгоритмов
Линейные алгоритмы описывают линейный вычислительный процесс, этапы которого выполняются однократно
Классификация алгоритмов
Линейные алгоритмы описывают линейный вычислительный процесс, этапы которого выполняются однократно

Классификация алгоритмов
Линейные алгоритмы описывают линейный вычислительный процесс, этапы которого выполняются однократно
Классификация алгоритмов
Линейные алгоритмы описывают линейный вычислительный процесс, этапы которого выполняются однократно

Классификация алгоритмов
Разветвляющийся алгоритм описывает вычислительный процесс, реализация которого происходит по одному
Классификация алгоритмов
Разветвляющийся алгоритм описывает вычислительный процесс, реализация которого происходит по одному

Классификация алгоритмов
Циклический алгоритм описывает вычислительный процесс, этапы которого повторяются многократно. Различают
Классификация алгоритмов
Циклический алгоритм описывает вычислительный процесс, этапы которого повторяются многократно. Различают

Способы описания алгоритмов
Существуют следующие способы описания алгоритмов:
1) запись на естественном языке
Способы описания алгоритмов
Существуют следующие способы описания алгоритмов:
1) запись на естественном языке
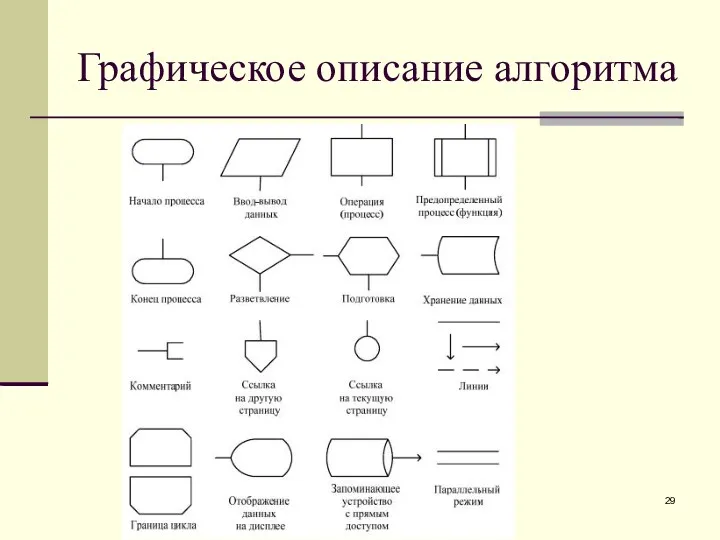
Графическое описание алгоритма
Графическое описание алгоритма
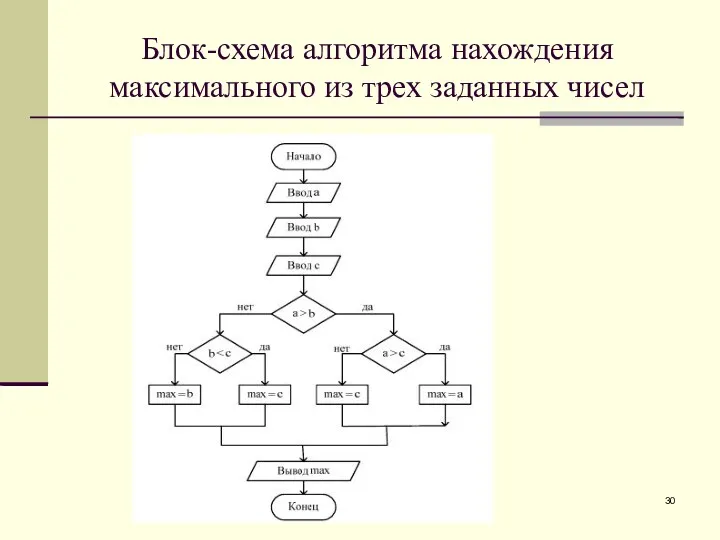
Блок-схема алгоритма нахождения максимального из трех заданных чисел
Блок-схема алгоритма нахождения максимального из трех заданных чисел
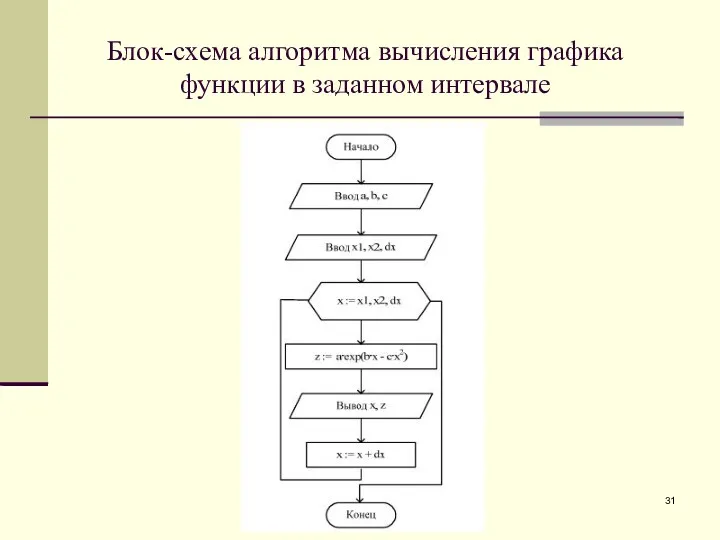
Блок-схема алгоритма вычисления графика
функции в заданном интервале
Блок-схема алгоритма вычисления графика
функции в заданном интервале
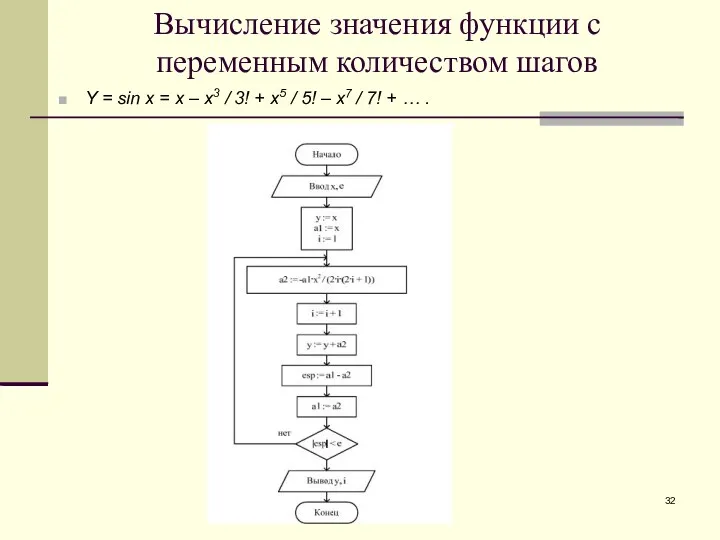
Вычисление значения функции с переменным количеством шагов
Y = sin x =
Вычисление значения функции с переменным количеством шагов
Y = sin x =

Основные понятия
Абстрактный тип данных АТД (формально введен в
1974 г. Б.Лисков.)
Основные понятия
Абстрактный тип данных АТД (формально введен в 1974 г. Б.Лисков.)

Основные понятия
Линейно связанный список (linked list) – набор элементов, последовательно связанных
Основные понятия
Линейно связанный список (linked list) – набор элементов, последовательно связанных

Операции со списком
1) Доступ к элементам:
n = first(L)
n = last(L)
n =
Операции со списком
1) Доступ к элементам:
n = first(L)
n = last(L)
n =

Операции со списком
Что нового по сравнению с массивами?
У массива есть
Операции со списком
Что нового по сравнению с массивами?
У массива есть
![Операции со списком Пример [ ann, tennis, tom, skiing ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582900/slide-36.jpg)
Операции со списком
Пример
[ ann, tennis, tom, skiing ]
[ ]
Элемент ann –
Операции со списком
Пример
[ ann, tennis, tom, skiing ]
[ ]
Элемент ann –
![Операции со списком Пример [ ann, tennis, tom, skiing ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/582900/slide-37.jpg)
Операции со списком
Пример
[ ann, tennis, tom, skiing ]
[ ]
Элемент ann –
Операции со списком
Пример
[ ann, tennis, tom, skiing ]
[ ]
Элемент ann –
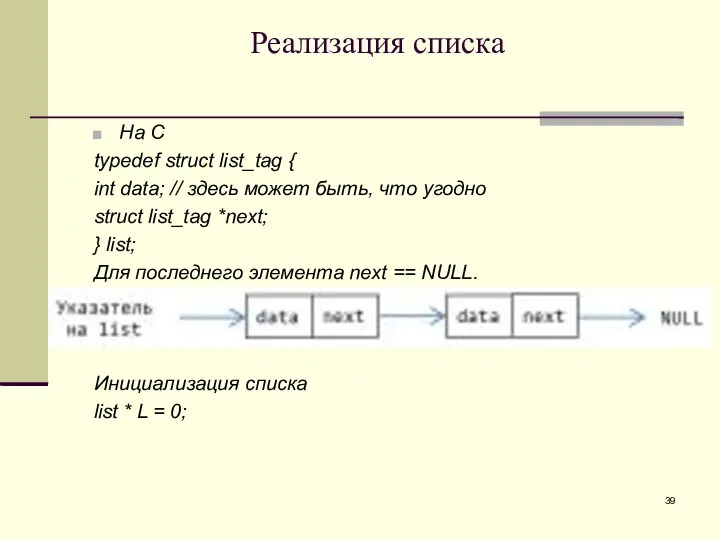
Реализация списка
На С
typedef struct list_tag {
int data; // здесь может быть,
Реализация списка
На С
typedef struct list_tag {
int data; // здесь может быть,
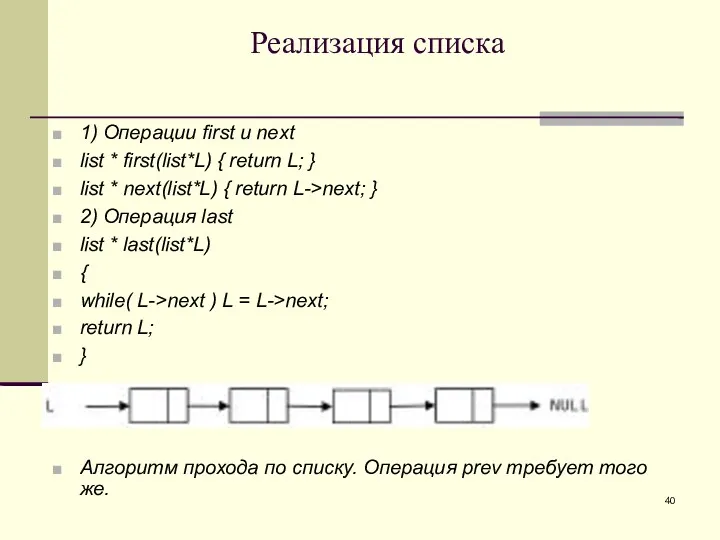
Реализация списка
1) Операции first и next
list * first(list*L) { return L;
Реализация списка
1) Операции first и next
list * first(list*L) { return L;

Алгоритмы и структуры
3) Операция вставка n после p
void insert_after(list*L,list*p,list*n)
{
n->next = p->next;
p->next
Алгоритмы и структуры
3) Операция вставка n после p
void insert_after(list*L,list*p,list*n)
{
n->next = p->next;
p->next
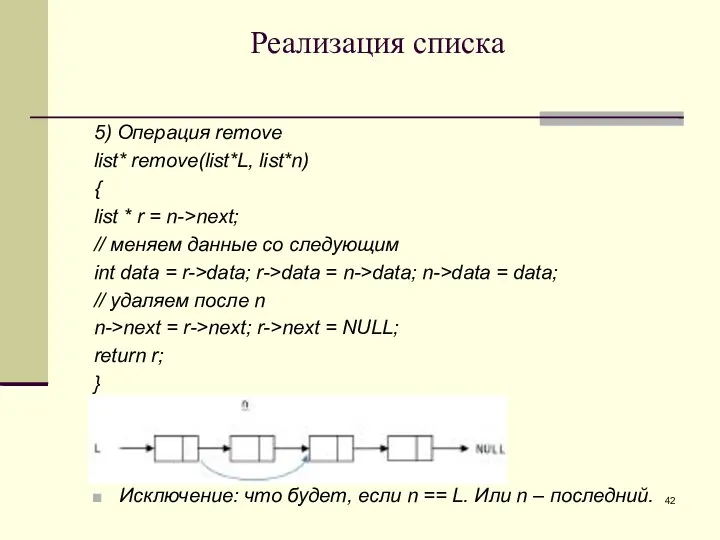
Реализация списка
5) Операция remove
list* remove(list*L, list*n)
{
list * r = n->next;
// меняем
Реализация списка
5) Операция remove
list* remove(list*L, list*n)
{
list * r = n->next;
// меняем

Реализация списка. Важные выводы
Все рассмотренные выше операции имеют сложность
О(1). Кроме
Реализация списка. Важные выводы
Все рассмотренные выше операции имеют сложность О(1). Кроме

Реализация списка. Продолжение 6
6) Операция search
list* search(list*L, int key)
{
do {
if( L->data
Реализация списка. Продолжение 6
6) Операция search
list* search(list*L, int key)
{
do {
if( L->data

Реализация списка. Продолжение 7 и 8
Вспомогательные операции – создание и уничтожение
Реализация списка. Продолжение 7 и 8
Вспомогательные операции – создание и уничтожение

Реализация двусвязного списка
Реализация двусвязного списка

Реализация двусвязного списка
Определение списка
typedef struct list_tag {
int data; // здесь может
Реализация двусвязного списка
Определение списка
typedef struct list_tag {
int data; // здесь может

Реализация двусвязного списка
1) Операции first и next
int isempty(list*L)
{
return L->next == L
Реализация двусвязного списка
1) Операции first и next
int isempty(list*L)
{
return L->next == L

Реализация двусвязного списка
3) Операция вставка n после p
void insert_after(list*L,list*p,list*n)
{
n->next = p->next;
Реализация двусвязного списка
3) Операция вставка n после p
void insert_after(list*L,list*p,list*n)
{
n->next = p->next;

Реализация двусвязного списка
5) Операция remove
void remove(list*L, list*n)
{
n->prev->next = n->next;
n->next->prev = n->prev;
n->prev
Реализация двусвязного списка
5) Операция remove
void remove(list*L, list*n)
{
n->prev->next = n->next;
n->next->prev = n->prev;
n->prev

Реализация двусвязного списка
Вспомогательные операции – создание и уничтожение списков
Конструкторы и деструкторы
7)
Реализация двусвязного списка
Вспомогательные операции – создание и уничтожение списков
Конструкторы и деструкторы
7)

Реализация двусвязного списка
Пример
int main(void)
{
list *head = list_create(0),*n;
int i,N = 6;
for(i=0;in
Реализация двусвязного списка
Пример
int main(void)
{
list *head = list_create(0),*n;
int i,N = 6;
for(i=0;i

Стеки
Определение стека
Стек – это специальный вид списка, для которого все операции
выполняются
Стеки
Определение стека
Стек – это специальный вид списка, для которого все операции
выполняются
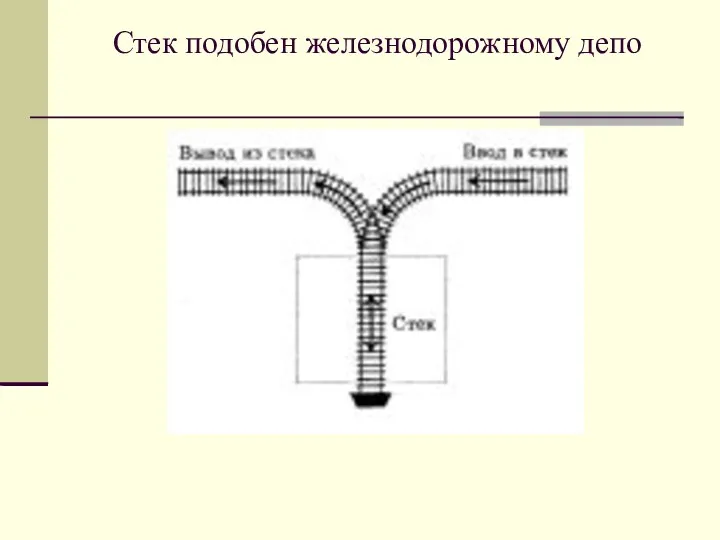
Стек подобен железнодорожному депо
Стек подобен железнодорожному депо

Операции со стеком
Операции со стеком
Доступ к элементам и изменение стека:
n =
Операции со стеком
Операции со стеком
Доступ к элементам и изменение стека:
n =

Реализация стека
Реализация стека
Можно просто использовать односвязный список. Сделаем через
свою реализацию.
typedef struct
Реализация стека
Реализация стека
Можно просто использовать односвязный список. Сделаем через
свою реализацию.
typedef struct

Реализация стека 2
Реализация стека
void PUSH(stack_t*S,void*data,int size)
{
stack_t*n=malloc(sizeof(stack_t)+size);
n->data = n + sizeof(stack_t);
memcpy(n->data, data,
Реализация стека 2
Реализация стека
void PUSH(stack_t*S,void*data,int size)
{
stack_t*n=malloc(sizeof(stack_t)+size);
n->data = n + sizeof(stack_t);
memcpy(n->data, data,

Реализация стека 3
Реализация стека
1) Память под данные должна распределяться так
n->data =
Реализация стека 3
Реализация стека
1) Память под данные должна распределяться так
n->data =

Реализация стека 4
Реализация стека
Используем макросы
#define PUSH(S,d,size) do{ \
STACK*n=malloc(sizeof(STACK)+size); \
n->data = n
Реализация стека 4
Реализация стека
Используем макросы
#define PUSH(S,d,size) do{ \
STACK*n=malloc(sizeof(STACK)+size); \
n->data = n

Очереди
Определение очереди
Очередь – это специальный вид списка, для которого добавление
элемента осуществляется
Очереди
Определение очереди
Очередь – это специальный вид списка, для которого добавление
элемента осуществляется

Реализация очереди
Реализация очереди
Можно просто использовать односвязный список. Но операция
добавления в конец
Реализация очереди
Реализация очереди
Можно просто использовать односвязный список. Но операция
добавления в конец

Реализация очереди 2
Реализация очереди
Сделаем через свою реализацию.
typedef struct queue_link_tag queue_link;
struct queue_link
Реализация очереди 2
Реализация очереди
Сделаем через свою реализацию.
typedef struct queue_link_tag queue_link;
struct queue_link

Реализация очереди 3
Реализация очереди
void ADD(queue_t*q,void*data)
{
queue_link*n=malloc(sizeof(queue_link)+q->size);
n->data = n + 1;
memcpy(n->data, data, q->size);
q->tail->next
Реализация очереди 3
Реализация очереди
void ADD(queue_t*q,void*data)
{
queue_link*n=malloc(sizeof(queue_link)+q->size);
n->data = n + 1;
memcpy(n->data, data, q->size);
q->tail->next

Деки
Определение дека
Дек (deque - double ended queue) – это специальный вид
Деки
Определение дека
Дек (deque - double ended queue) – это специальный вид

Задание. Деки
1) Реализовать все операции для списка и двусвзяного списка в
данных
Задание. Деки
1) Реализовать все операции для списка и двусвзяного списка в
данных

Метод пузырька
#include
int main() {
int n, i, j;
Метод пузырька
#include
int main() {
int n, i, j;

Метод вставки
#include
int main() {
int n, i, j;
Метод вставки
#include
int main() {
int n, i, j;

Метод Шелла
#include
int main() {
int n, i, j;
Метод Шелла
#include
int main() {
int n, i, j;

Усовершенствованные методы
#include
int main() {
int n, i, j;
Усовершенствованные методы
#include
int main() {
int n, i, j;
 Корпоративные информационные системы
Корпоративные информационные системы Основы программирования на Python
Основы программирования на Python This is CS50
This is CS50 Жанр компьютерных игр - Шутер
Жанр компьютерных игр - Шутер СМИ, которые я предпочитаю
СМИ, которые я предпочитаю Adobe Premier Pro CC. Создание интерфейса
Adobe Premier Pro CC. Создание интерфейса Группы клавиш компьютерной клавиатуры
Группы клавиш компьютерной клавиатуры Методы визуализации
Методы визуализации Принципы разработки параллельных алгоритмов
Принципы разработки параллельных алгоритмов Презентация к уроку информатики в 5 классе по теме Табличная форма представления информации
Презентация к уроку информатики в 5 классе по теме Табличная форма представления информации Нейронные сети
Нейронные сети троянские программы и защита от них
троянские программы и защита от них Управление процессами
Управление процессами Развитие вычислительной техники
Развитие вычислительной техники Черчение геометрических примитивов в системе компьютерного черчения КОМПАС
Черчение геометрических примитивов в системе компьютерного черчения КОМПАС условия выбора и простые логические выражения
условия выбора и простые логические выражения Тема урока: Алфавитный подход к определению количества информации. Единицы измерения информации. 8 класс
Тема урока: Алфавитный подход к определению количества информации. Единицы измерения информации. 8 класс Интегрированная среда программирования
Интегрированная среда программирования ESCOM.BPM. Система автоматизации бизнеспроцессов, документооборота и контроля исполнения
ESCOM.BPM. Система автоматизации бизнеспроцессов, документооборота и контроля исполнения Презентация по теме Технологии самостоятельной работы обучающихся
Презентация по теме Технологии самостоятельной работы обучающихся Области применения цифровых технологий
Области применения цифровых технологий Написание постов в инстаграм
Написание постов в инстаграм Формирование УУД при изучении графических и текстовых редакторов на уроках информатики и ИКТ
Формирование УУД при изучении графических и текстовых редакторов на уроках информатики и ИКТ Интервью (событийное) как жанр журналистики (лекция № 6)
Интервью (событийное) как жанр журналистики (лекция № 6) Интернет-портал администрации Масальского сельсовета, Алтайского края
Интернет-портал администрации Масальского сельсовета, Алтайского края Презентация по математике
Презентация по математике Отношения между объектами, 3 класс
Отношения между объектами, 3 класс Первые БЦВМ
Первые БЦВМ