- Анализ языковых данных в информационной системе семограф

Содержание
- 2. Общие сведения
- 3. Perm State University Информационная система Семограф Семограф является свободно распространяемой многопользовательской информационной системой с веб-интерфейсом, предназначенной
- 4. Perm State University Общие принципы Распределенный в режиме реального времени научный процесс Организация сетевого взаимодействия участников
- 5. Perm State University Цели информационной системы Семограф Основная цель – создание доступных и понятных широкому кругу
- 6. Регистрация в ИС "Семограф"
- 7. Perm State University Стартовая страница ИС «Семограф» Стартовая страница: http://semograph.org Для работы в ИС «Семограф» требуется
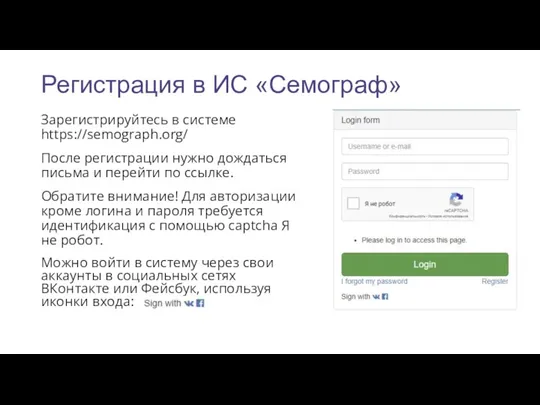
- 8. Регистрация в ИС «Семограф» Зарегистрируйтесь в системе https://semograph.org/ После регистрации нужно дождаться письма и перейти по
- 9. Создание проекта
- 10. Perm State University Создание таблицы с данными Данные в ИС «Семограф» можно вносить несколькими способами, из
- 11. Perm State University Создание таблицы с данными Остальные типы данных могут быть строковыми (string), целочисленными (int),
- 12. Perm State University Подготовка файла для загрузки Рисунок 1. Фрагмент файла для загрузки в ИС «Семограф»
- 13. Perm State University Создание загрузочного файла Загрузочный файл создается из гугл-таблицы: Файл – Скачать как –
- 14. Perm State University Импорт загрузочного csv-файла в ИС «Семограф» Для импорта подготовленного csv-файла необходимо: зарегистрироваться в
- 15. Рабочий стол системы Рабочий стол системы существует в двух вариантах: "Админ-панели" (Рис. 1) и "Рабочего стола"
- 16. Работа с меню системы В Админ-панели доступны следующие инструменты: Рабочий стол (переход к состоянию Рабочий стол)
- 17. Окно «Проекты» Работа с системой начинается в окне «Проекты». Создать проект* можно двумя способами: 1. С
- 18. Создание проекта с помощью импорта файла Создайте первый проект. Для этого захватите мышкой Ваш файл, сохраненный
- 19. Создание проекта с помощью импорта файла Если Ваш проект успешно импортировался, нужно обновить окно браузера и
- 20. Работа в Проекте
- 21. Работа в проекте После перехода в пространство Проекта становится доступным меню проекта (слева) и инструменты организации
- 22. Создание полей. Классификация компонентов В левой панели нужно перейти на вкладку Полевый анализ. Открывшееся окно –
- 23. Создание полей. Классификация компонентов В открывшемся меню фильтров выбрать тип
- 24. Создание полей. Классификация компонентов После чего в появившемся окне тип выбрать цифру 3. В отфильтрованном таким
- 25. Создание полей. Классификация компонентов Для того, чтобы создать поле в ИС “Семограф”, необходимо ввести его название
- 26. Создание полей. Классификация компонентов После создания поля необходимо внести в него все компоненты, имеющие семы этого
- 27. Создание полей. Классификация компонентов Перед полем, в котором уже есть “привязанные” компоненты, появляется знак папка. Тот
- 28. Создание полей. Классификация компонентов По итогам анализа будет сформирована система семантических полей, которую Вы будете упорядочивать
- 29. Семантические карты
- 30. Работа с Семантическими картами После завершения классификации можно генерировать результаты исследования для дальнейшей интерпретации. Нужно перейти
- 31. Работа с Семантическими картами Нижняя таблица - это показатели “веса” полей в выборке, т.е. количество их
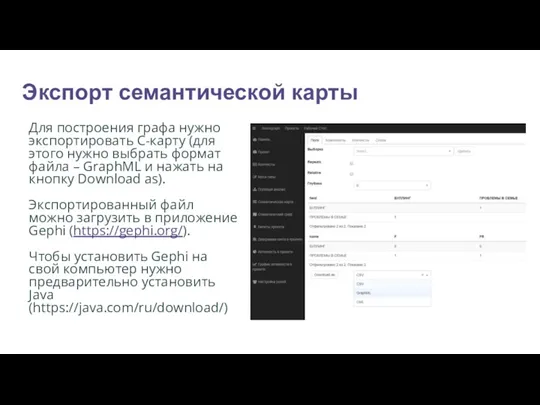
- 32. Экспорт семантической карты Для построения графа нужно экспортировать С-карту (для этого нужно выбрать формат файла –
- 33. Создание выборок
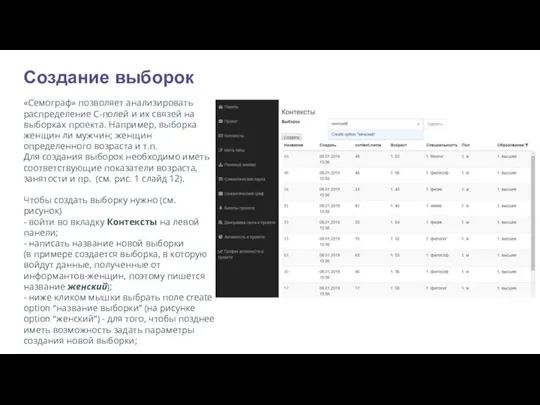
- 34. Создание выборок «Семограф» позволяет анализировать распределение С-полей и их связей на выборках проекта. Например, выборка женщин
- 35. Создание выборок - далее нужно выбрать знак фильтра (воронка) в правом верхнем углу таблицы, после чего
- 36. Создание выборок - после того, как нужный параметр выбран, рядом появляется окно, одноименное этому параметру (на
- 37. Создание С-карт на основе выборок Созданные выборки позволяют генерировать семантические карты на основе контекстов не всего
- 39. Скачать презентацию
Общие сведения
Общие сведения

Perm State University
Информационная система Семограф
Семограф является свободно распространяемой многопользовательской информационной системой
Perm State University
Информационная система Семограф
Семограф является свободно распространяемой многопользовательской информационной системой

Perm State University
Общие принципы
Распределенный в режиме реального времени научный процесс
Организация сетевого
Perm State University
Общие принципы
Распределенный в режиме реального времени научный процесс
Организация сетевого

Perm State University
Цели информационной системы Семограф
Основная цель – создание доступных и
Perm State University
Цели информационной системы Семограф
Основная цель – создание доступных и
Регистрация в ИС "Семограф"
Регистрация в ИС "Семограф"

Perm State University
Стартовая страница ИС «Семограф»
Стартовая страница: http://semograph.org
Для работы в ИС
Perm State University
Стартовая страница ИС «Семограф»
Стартовая страница: http://semograph.org
Для работы в ИС
Регистрация в ИС «Семограф»
Зарегистрируйтесь в системе https://semograph.org/
После регистрации нужно дождаться письма
Регистрация в ИС «Семограф»
Зарегистрируйтесь в системе https://semograph.org/
После регистрации нужно дождаться письма
Создание проекта
Создание проекта

Perm State University
Создание таблицы с данными
Данные в ИС «Семограф» можно вносить
Perm State University
Создание таблицы с данными
Данные в ИС «Семограф» можно вносить

Perm State University
Создание таблицы с данными
Остальные типы данных могут быть строковыми
Perm State University
Создание таблицы с данными
Остальные типы данных могут быть строковыми
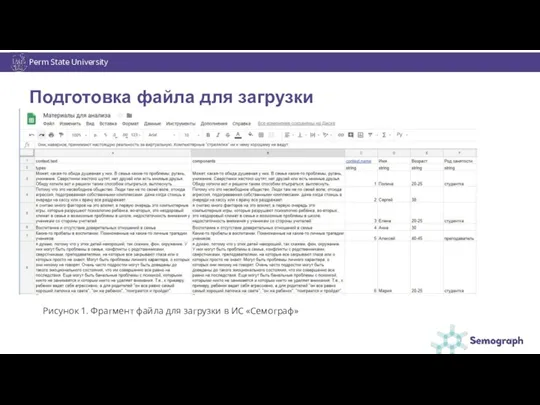
Perm State University
Подготовка файла для загрузки
Рисунок 1. Фрагмент файла для загрузки
Perm State University
Подготовка файла для загрузки
Рисунок 1. Фрагмент файла для загрузки
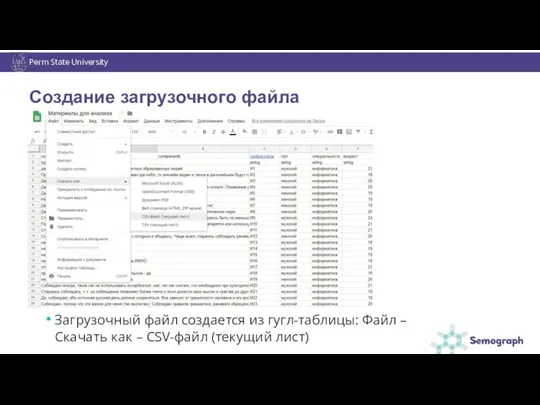
Perm State University
Создание загрузочного файла
Загрузочный файл создается из гугл-таблицы: Файл –
Perm State University
Создание загрузочного файла
Загрузочный файл создается из гугл-таблицы: Файл –

Perm State University
Импорт загрузочного csv-файла в ИС «Семограф»
Для импорта подготовленного csv-файла
Perm State University
Импорт загрузочного csv-файла в ИС «Семограф»
Для импорта подготовленного csv-файла
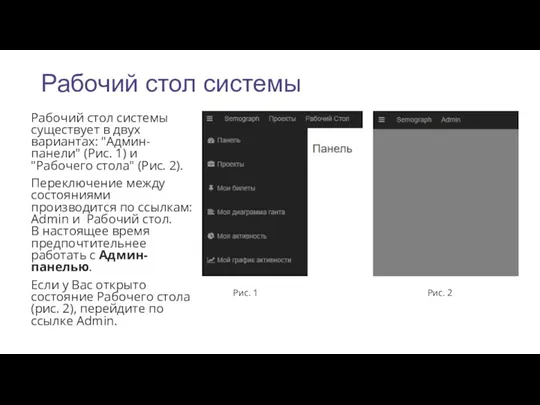
Рабочий стол системы
Рабочий стол системы существует в двух вариантах: "Админ-панели" (Рис.
Рабочий стол системы
Рабочий стол системы существует в двух вариантах: "Админ-панели" (Рис.
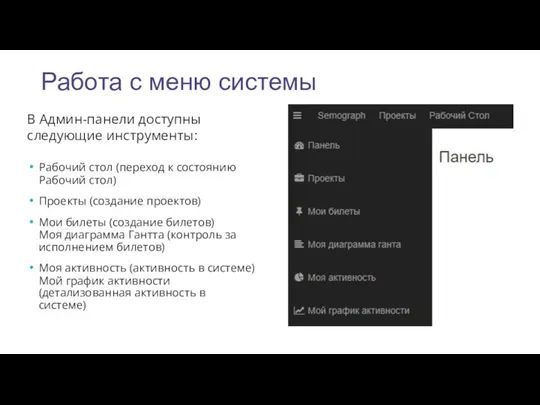
Работа с меню системы
В Админ-панели доступны следующие инструменты:
Рабочий стол (переход к
Работа с меню системы
В Админ-панели доступны следующие инструменты:
Рабочий стол (переход к
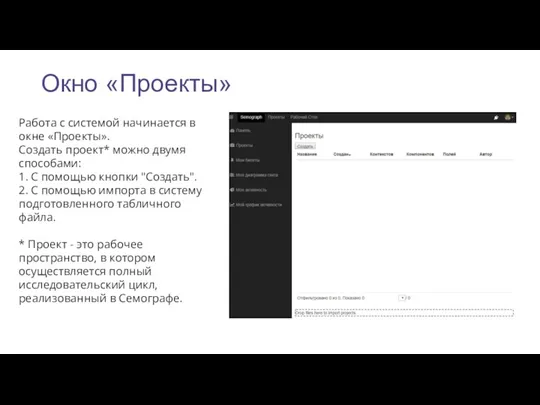
Окно «Проекты»
Работа с системой начинается в окне «Проекты».
Создать проект* можно двумя
Окно «Проекты»
Работа с системой начинается в окне «Проекты».
Создать проект* можно двумя
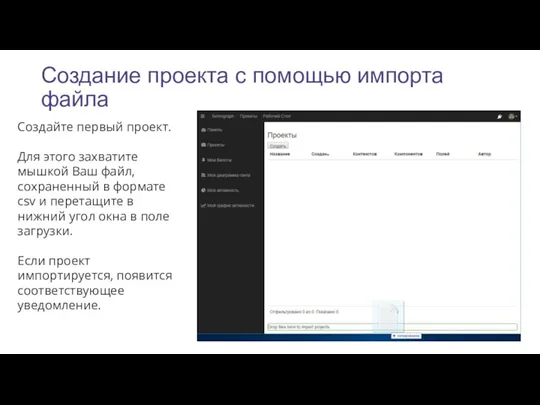
Создание проекта с помощью импорта файла
Создайте первый проект.
Для этого захватите
Создание проекта с помощью импорта файла
Создайте первый проект.
Для этого захватите
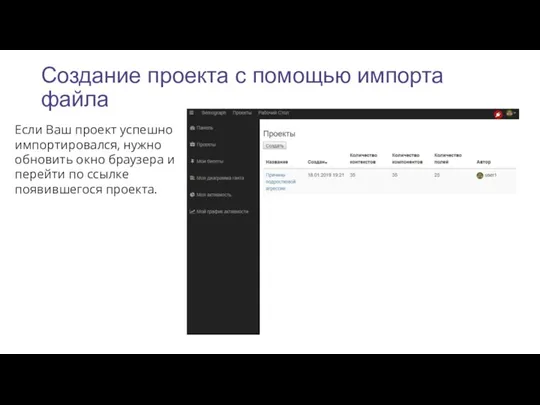
Создание проекта с помощью импорта файла
Если Ваш проект успешно импортировался, нужно
Создание проекта с помощью импорта файла
Если Ваш проект успешно импортировался, нужно

Работа в Проекте
Работа в Проекте
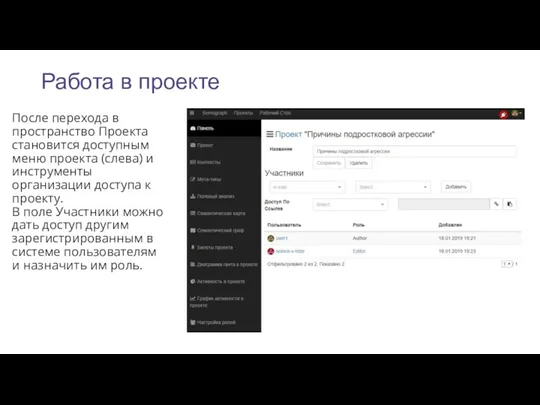
Работа в проекте
После перехода в пространство Проекта становится доступным меню проекта
Работа в проекте
После перехода в пространство Проекта становится доступным меню проекта
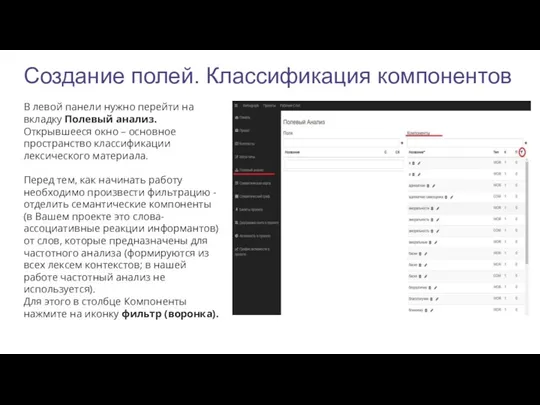
Создание полей. Классификация компонентов
В левой панели нужно перейти на вкладку Полевый
Создание полей. Классификация компонентов
В левой панели нужно перейти на вкладку Полевый
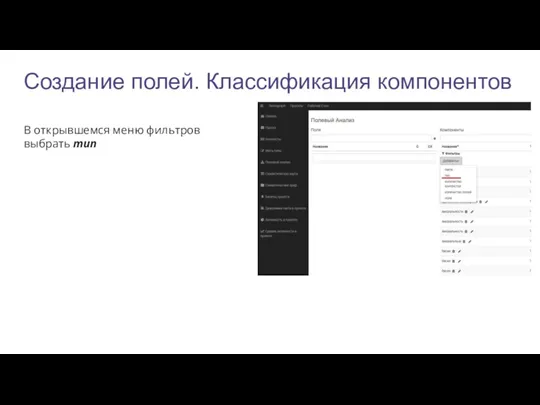
Создание полей. Классификация компонентов
В открывшемся меню фильтров выбрать тип
Создание полей. Классификация компонентов
В открывшемся меню фильтров выбрать тип

Создание полей. Классификация компонентов
После чего в появившемся окне тип выбрать цифру
Создание полей. Классификация компонентов
После чего в появившемся окне тип выбрать цифру
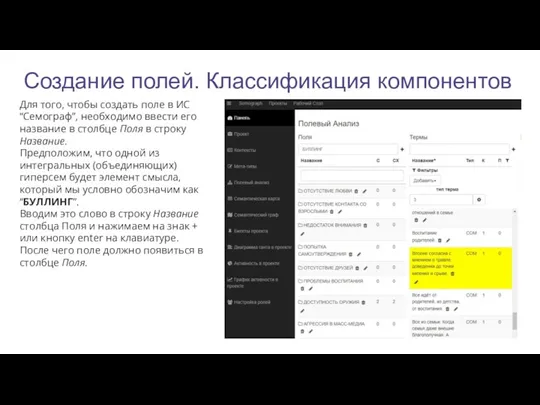
Создание полей. Классификация компонентов
Для того, чтобы создать поле в ИС “Семограф”,
Создание полей. Классификация компонентов
Для того, чтобы создать поле в ИС “Семограф”,

Создание полей. Классификация компонентов
После создания поля необходимо внести в него все
Создание полей. Классификация компонентов
После создания поля необходимо внести в него все

Создание полей. Классификация компонентов
Перед полем, в котором уже есть “привязанные” компоненты,
Создание полей. Классификация компонентов
Перед полем, в котором уже есть “привязанные” компоненты,

Создание полей. Классификация компонентов
По итогам анализа будет сформирована система семантических полей,
Создание полей. Классификация компонентов
По итогам анализа будет сформирована система семантических полей,
Семантические карты
Семантические карты

Работа с Семантическими картами
После завершения классификации можно генерировать результаты исследования для
Работа с Семантическими картами
После завершения классификации можно генерировать результаты исследования для

Работа с Семантическими картами
Нижняя таблица - это показатели “веса” полей в
Работа с Семантическими картами
Нижняя таблица - это показатели “веса” полей в
Экспорт семантической карты
Для построения графа нужно экспортировать С-карту (для этого нужно
Экспорт семантической карты
Для построения графа нужно экспортировать С-карту (для этого нужно

Создание выборок
Создание выборок
Создание выборок
«Семограф» позволяет анализировать распределение С-полей и их связей на выборках
Создание выборок
«Семограф» позволяет анализировать распределение С-полей и их связей на выборках

Создание выборок
- далее нужно выбрать знак фильтра (воронка) в правом верхнем
Создание выборок
- далее нужно выбрать знак фильтра (воронка) в правом верхнем
Создание выборок
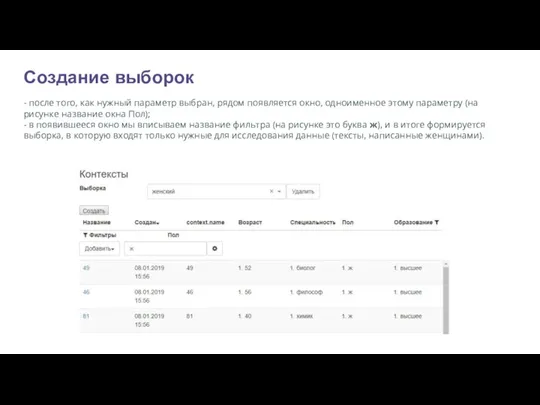
- после того, как нужный параметр выбран, рядом появляется окно,
Создание выборок
- после того, как нужный параметр выбран, рядом появляется окно,

Создание С-карт на основе выборок
Созданные выборки позволяют генерировать семантические карты на
Создание С-карт на основе выборок
Созданные выборки позволяют генерировать семантические карты на
 Инструкция для подачи обращения/заявления для получения муниципальной услуги Зачисление в образовательное учреждение
Инструкция для подачи обращения/заявления для получения муниципальной услуги Зачисление в образовательное учреждение Динамические структуры данных. Указатели
Динамические структуры данных. Указатели Centre Monitoring System PH-BC911 (Operation)
Centre Monitoring System PH-BC911 (Operation) LI-FI световая замена WI-FI
LI-FI световая замена WI-FI CoDeSys - общий обзор
CoDeSys - общий обзор Мастер-класс Получение услуг через Портал государственных и муниципальных услуг
Мастер-класс Получение услуг через Портал государственных и муниципальных услуг Плюсы и минусы информационного общества
Плюсы и минусы информационного общества Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма
Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма Огляд введення та виведення в С++
Огляд введення та виведення в С++ Филатов Андрей В-45
Филатов Андрей В-45 Безопасность детей в интернете
Безопасность детей в интернете Логические основы построения компьютера
Логические основы построения компьютера Cистемы электронного документооборота
Cистемы электронного документооборота Ведение базы данных в MS Access. Технологии баз данных. (Лекция 5)
Ведение базы данных в MS Access. Технологии баз данных. (Лекция 5) Компьютер как средство автоматизации информационных процессов.
Компьютер как средство автоматизации информационных процессов. Рабочий стол. Управление мышью
Рабочий стол. Управление мышью Верификация программного обеспечения. Дефекты
Верификация программного обеспечения. Дефекты Понятие юзабилити
Понятие юзабилити Файлы и файловые структуры. Компьютер как универсальное устройство для работы с информацией. Информатика. 7 класс
Файлы и файловые структуры. Компьютер как универсальное устройство для работы с информацией. Информатика. 7 класс Орта мектепте химия пәнінен типтік есептер шығаруда ақпараттық технологияны қолдану әдістері
Орта мектепте химия пәнінен типтік есептер шығаруда ақпараттық технологияны қолдану әдістері Современные информационные технологии в образовании
Современные информационные технологии в образовании Разработка web-сайта для ООО Лидер
Разработка web-сайта для ООО Лидер Искусственный интеллект, данные и знания. Экспертные системы. Лекция №1
Искусственный интеллект, данные и знания. Экспертные системы. Лекция №1 Информационные модели на графах
Информационные модели на графах Лекция 1. Системы обработки информации в таможенных органах Российской Федерации
Лекция 1. Системы обработки информации в таможенных органах Российской Федерации Кодирование информации
Кодирование информации MVC в Android. Создание простейшего приложения
MVC в Android. Создание простейшего приложения Разновидности объектов и их классификация
Разновидности объектов и их классификация