- Analyst Documentation

Содержание
- 2. Table of Contents
- 3. Data Discovery Meeting
- 4. Data Discovery Meeting (1/7) Purpose: To establish a global picture of all data required for modelling
- 5. Data Discovery Meeting (2/7) Step by Step: Prior to the meeting, send a high level survey
- 6. Data Discovery Meeting (3/7) Typical Media Activities and Breaks: Television: Daypart, Duration, Network vs Cable, Local
- 7. Data Discovery Meeting (4/7) Typical Trade/Promotional Activities: Coupons Temporary Price Reductions (TPRs) Feature, Display, Feature and
- 8. (5/7) Pic 1
- 9. (6/7) Pic 2
- 10. (7/7) Pic 3
- 11. Creating a New Project Instance
- 12. Creating a New Project Instance (1/4) Purpose: A project instance holds a particular implementation of the
- 13. Creating a New Project Instance (2/4) Step by Step: Open the relevant marketplace On the home
- 14. Pic 1 Pic 2 (3/4)
- 15. Settings Field: Sales Units: Typically set to “Millions”. Thousands or billions can be substituted if the
- 16. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items
- 17. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (1/7) Purpose: The purpose of
- 18. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (2/7) Step by Step -
- 19. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (3/7) Step by Step -
- 20. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (3/7) Step by Step –
- 21. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (4/8) The explanation should help
- 22. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (4/7) Step by Step -
- 23. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (5/7) Step by Step -
- 24. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (6/7) Step by Step –
- 25. Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items) (7/7) Watch-outs: Be mindful about
- 26. Configuring the Marketplace (sales, price, distribution)
- 27. Configuring the Marketplace (sales, price, distribution (1/4) Purpose: Finalizing the marketplace so it is accurately capturing
- 28. Configuring the Marketplace (sales, price, distribution) (2/4) Sales: Inputting sales into the model is fairly straightforward.
- 29. Configuring the Marketplace (sales, price, distribution) (3/4) Price: Price can be input as either an index
- 30. Configuring the Marketplace (sales, price, distribution) (4/4) Often, traditional “distribution” is not appropriate for the category
- 31. Defining Seasonality
- 32. Defining Seasonality Purpose: Defining seasonality to determine when agents are most likely to experience a category
- 33. Defining Seasonality Step by Step: Seasonality is used to determine when agents are most likely to
- 34. Defining Seasonality Step by Step: For each year of the calibration, divide each week by the
- 35. Sampling Variables to get to 100%
- 36. Sampling Variables to get to 100% (1/3) Certain variables are required to sum to 1 for
- 37. Sampling Variables to get to 100% (2/3) How do you deal with three channels? Sample each
- 38. Sampling Variables to get to 100% (3/3) Use solver, change the green cells with red arrow,
- 39. Agent Generation - Demographics
- 40. Agent Generation (1/7) Purpose: Agent characteristics typically include demographics, placement on a brand awareness continuum, category
- 41. Agent Generation (2/7) Step by Step: Open the relevant marketplace On the Agents tab, select Agents
- 42. (3/7) Pic 1
- 43. Agent Generation (4/7) Step by Step: In the example provided, Income is being sampled from a
- 44. Agent Generation (5/7) Probability Density Functions: Beta(z, S) Sampled values are between 0 and 1. z
- 45. Agent Generation (6/7) Demographics: Many different distributions used: Income (gamma), Race (discrete), etc. Census should dictate
- 46. Agent Generation (7/7) Watch outs: If sampled values of media awareness are close to 1, media
- 47. Weekly Data Collection Meetings
- 48. Weekly Data Collection Meetings (1/4) Purpose: To facilitate frequent and regular communication between ThinkVine, the customer,
- 49. Weekly Data Collection Meetings (2/4) Step by Step: Prior to the meeting, the updated Data Collection
- 50. (3/4) Pic 1
- 51. (4/4) Pic 2
- 52. Agent Generation – Media Activities
- 53. Agent Generation – Media Activities Purpose: In order to simulate media consumption behaviors in the agents,
- 54. Step by Step: Open the relevant marketplace From the dashboard, click on AGENTS on the top
- 55. Step by Step (cont.): A graph will appear on the right hand side after all the
- 56. Pic 2 Pic 1 Pic 3 Agent Generation – Media Activities
- 57. Pic 4 Agent Generation – Media Activities Any tactic from the marketing plan has to have
- 58. Noteworthy Include as many media activities as available, even those that the customers currently do not
- 59. Agent Generation (Targets, Needs, Influences, Weights)
- 60. Agent Generation (Targets, Needs, Influences, Weights) Purpose: This step is important because the targets, influences, needs
- 61. Agent Generation (Needs) Step by Step: Needs - for every need defined during marketplace configuration, there
- 62. Agent Generation (Targets) Targets After establishing which targets you want to define (see Prerequisites), navigate to
- 63. Agent Generation (Targets) Targets (continued) Note that if you used a Beta distribution to enforce lower
- 64. Agent Generation (Influences) If you decide that you need to use the functionality of influences within
- 65. Agent Generation (Weights) Again, each agent in the model represents an arbitrary number of real-world consumers,
- 66. Agent Generation (Weights) Watch-outs Nearly every project will make use of Targets and Needs. Most projects
- 67. Correlating agent characteristics
- 68. Correlating agent characteristics (1/8) Purpose: In order to make the agent population more realistic, the analyst
- 69. Correlating agent characteristics (2/8) Step by Step: Open the relevant marketplace On the Agents tab, select
- 70. Correlating agent characteristics (3/8) Viewing habits of younger people Viewing habits of older people Viewing habits
- 71. (4/8) Gender value of 1 = Female Less than/greater than agent value Direction of the correlation
- 72. Correlating agent characteristics (5/8) Step by Step: In the example provided, the sampled value for Television
- 73. Correlating agent characteristics (6/8) How is this handled: If I want higher sampled values of TV
- 74. Correlating agent characteristics (7/8) Export Agents: The analyst can export data [Export Agents] to a Microsoft
- 75. Correlating agent characteristics (7/8) Pic 2 TV Minutes Income Age TV Minutes
- 76. Agent Generation: All Variables, Final Variables
- 77. Agent Generation: All Variables, Final Variables Purpose: The purpose of the All Variables screen is to
- 78. Agent Generation: All Variables, Final Variables Step by Step – All Variables: Navigate to the All
- 79. Agent Generation: All Variables, Final Variables Step by Step – Final Variables: Navigate to the Final
- 80. Agent Generation: All Variables, Final Variables Watch-outs: All Variables screen Use this screen only to re-arrange
- 81. Agent Generation: All Variables, Final Variables Watch-outs: Final Variables screen When initializing Ever Bought = 1
- 82. Importing/Exporting Agents
- 83. Exporting Agents Purpose: Exporting agents allows the analyst to document and store all of the agent
- 84. Exporting Agents Step by Step: To export agents, navigate to the Agents tab and click the
- 85. Exporting Agents
- 86. Agent Generation Calibration/Tweaking
- 87. Agent Generation Calibration/Tweaking Purpose: Calibrating the agent population to ensure it is a close representation of
- 88. Agent Generation Calibration/Tweaking Step by Step: This step of the process is to try to ensure
- 89. Agent Generation Calibration/Tweaking Step by Step: To that point, unless the modeled population differs from the
- 90. Agent Generation Calibration/Tweaking Step by Step: As a first step, the agent population must be downloaded
- 91. Agent Generation Calibration/Tweaking Step by Step: This makes for easy comparisons to see where the agent
- 92. Agent Generation Calibration/Tweaking Correlations are the most frequently used lever in agent calibration and should be
- 93. Agent Generation Calibration/Tweaking That said, it likely impossible to “hit” every single agent characteristic perfectly. It
- 94. Reach Curve Generation
- 95. Reach Curve Generation – Calculate the Reach Conversion Rate Purpose: Help the marketplace estimate the reach
- 96. The marketplace calculates reach as follows: Reach = (1-EXP(Conversion Rate*Execution Data))*Reach Constant Therefore, the conversion rate
- 97. Step by Step (Calculate the Reach) Below are some equations that may help generate data points
- 98. Step by Step (Calculate Conversion Rate) Once you have calculated the reach, you can input it
- 99. Pic 2 Pic 1 Reach Curve Generation – Calculate the Reach Conversion Rate Step by Step
- 100. Noteworthy For customers within an industry, their reach conversion rates should be very similar. Instead of
- 101. Put Marketing Activities into Model
- 102. Put Marketing Activities into Model (1/5) Purpose: This step in implementation populates the model with the
- 103. Put Marketing Activities into Model (2/5) Step by Step: Open the relevant marketplace and project instance
- 104. Step by Step (cont.): Marketing Plan Grouping is where you have the opportunity to group the
- 105. Picture 1 (4/5)
- 106. Picture 2 (5/5)
- 107. Create Patterns for Marketing Objects
- 108. Create Patterns for Marketing Objects (1/5) Purpose: Some marketing tactics, such as coupon and direct mail,
- 109. Step by Step: Open the relevant marketplace From the dashboard, click on MARKETING on the top
- 110. Step by Step (cont.): Each box represents one week, therefore, enter the percentage of impact that
- 111. Pic 2 Pic 1 Pic 3 Create Patterns for Marketing Objects (4/5)
- 112. Noteworthy Coupons, direct mail, and email are the most common marketing objects that require patterns. Patterns
- 113. Set Up Base Marketing Plan
- 114. Set Up Base Marketing Plan Purpose of this step This step is required to proceed with
- 115. Set Up Base Marketing Plan Prerequisites (continued) The summaries must include, at a minimum, spend and
- 116. Set Up Base Marketing Plan Step-by-step instructions: Collect the files containing the weekly summaries of each
- 117. Set Up Base Marketing Plan Click on the plan you just created, return to the Plan
- 118. Set Up Base Marketing Plan On the Import Plans screen, click “+ Add Files” Select your
- 119. Set Up Base Marketing Plan Watch-Outs If you have data on marketing activities that were executed
- 120. Set Up Base Marketing Plan How long should this step take? Summary of the data depends
- 121. Set Up Calibrate/Scenarios Screen
- 122. Setting up Calibrate/Scenarios Screen Purpose of this step: This step is the beginning of your calibration.
- 123. Pic 3 Setting up Calibrate/Scenarios Screen
- 124. Setting up Calibrate/Scenarios Screen Recommendations for starting values of Saturation Constant of 1.0 (no saturation) to
- 125. Run Regression
- 126. Running a Regression Purpose: Running a simple regression on your dependent variable and some of your
- 127. Running a Regression Step by Step: Open up a blank workbook in Excel. Put the dates
- 128. Running a Regression
- 129. Running a Regression For the next step you will need to have the Data Analysis toolkit
- 130. Running a Regression If you don’t see it, try going to File->Options->Add-ins. Make sure Analysis ToolPak
- 131. Running a Regression So now you have the Data Analysis button on your Data tab. Click
- 132. Running a Regression Make the Y range equal to the range of your dependent variable in
- 133. Running a Regression Output should look something like this. I’ve highlighted the parts we’ll be interested
- 134. Running a Regression You can use the coefficients to build a simple algebra equation that, once
- 135. Running a Regression To figure out how much volume the regression predicts will be driven each
- 136. Running a Regression A few more points to consider. T-stat is a measure of the significance
- 137. Bug Check (Calibration)
- 138. Bug Check Purpose: The model will not run if agents and/or marketing activities are not properly
- 139. Bug Check (General)
- 140. Bug Check Purpose: By bug checking, you’re ensuring the validity and accuracy of the results. In
- 141. Step by Step (continued): An email should be sent to support@thinkvine.com In this email, you should
- 142. Example Bug Check Email: SUBJECT: [Insert Name of Bug] TO: support@thinkvine.com FROM: marvin@thinkvine.com CC: Anyone who
- 143. AutoCalibrate
- 144. Autocalibration Purpose: Once the initial plan is run, use auto-calibration to save time in the calibration
- 145. Autocalibration Rough steps mimic what you do manually Rotating rounds loop through your goal types Several
- 146. Autocalibration You can set the initial value for any parameter If that parameter is not optimized,
- 147. Autocalibration Recommendations for best outcomes: Use a narrow media forgetting range, like 0.1 or even 0.05
- 148. Autocalibration Autocalibration will help with parameter choices of Exo Variables Use the “Minimum” and “Maximum” input
- 149. Autocalibration In the Software: Calibrate / Choose scenario “Work on Scenario” Autocalibration / Setting Parameter Boundaries
- 150. Autocalibration / Impacts and Results Awareness goals: don’t need these, but can tell algorithm to minimize
- 151. Autocalibration / Impacts and Results Sales Goals: You must enter at least one of these If
- 152. Autocalibration Outputs: A scenario, with the name you specified, seen on the “Scenarios” tab of “Calibrate.”
- 153. Autocalibration watch-out: noise in weekly sales Because of the low number of agents (necessary for repeated
- 154. Set up MAPE Workbook
- 155. Set up MAPE Workbook Purpose: The purpose of setting up a MAPE Workbook is to allow
- 156. Set up MAPE Workbook Step by Step (1/2): To create your MAPE Workbook, you can either
- 157. Set up MAPE Workbook Step by Step (2/2): In addition to the Weekly MAPE that you
- 158. Set up MAPE Workbook Watch-outs: Most analysts already have templates, including the one attached in this
- 159. Set up the MAPE Calculator
- 160. Set up MAPE Calculator Purpose: The MAPE calculator is a tool that allows the analyst to
- 161. Set up MAPE Calculator Step by Step: (1/4) Obtain a copy of the MAPE Calculator template
- 162. Set up MAPE Calculator Step by Step: (2/4) Click “Locate File…” and select the downloaded results
- 163. Set up MAPE Calculator Step by Step: (3/4) The calculator will output a chart for each
- 164. Set up MAPE Calculator Step by Step: (4/4) If there is a negative correlation, it suggests
- 165. Flatten Awareness
- 166. Flatten Awareness (1/4) Purpose: The probability that an agent purchases an item is related to its
- 167. Flatten Awareness (2/4) Step by Step: Open the relevant marketplace On the Calibrate tab, select Scenario
- 168. Flatten Awareness (3/4) Step by Step: An Excel file with weekly awareness is downloaded. On the
- 169. Flatten awareness (4/4) How to adjust awareness If awareness is trending up or down beyond what
- 170. Improve Impacts
- 171. Improve Impacts Purpose: Highlight some common adjustments to improve the impacts of the marketing activities. Specifics:
- 172. Step by Step: What to think about when adjusting impacts: Are tactics that have a lower
- 173. Step by Step: Adjust the impact of individual marketing objects: This process is the same as
- 174. Step by Step: Adjust the impact of all marketing objects: This macro level adjustment process is
- 175. Step by Step: Adjust the impact of all marketing objects (cont.): The modeler can also adjust
- 176. Pic 2 Pic 1 Improve Impacts
- 177. Pic 3 Improve Impacts
- 178. Pic 5 Pic 6 Pic 7 Pic 4
- 179. Noteworthy A tool such as Parameter Solver, image below, can translate the parameters into more meaning
- 180. Improve Fit
- 181. Improve Fit Purpose: Illustrate some common ways to improve your model fit. Methods: 1. Increase Number
- 182. Improve Fit: Increase Number of Agents Increasing the number of agents is one of the easiest
- 183. Improve Fit: Increase Number of Agents Navigate to the correct marketplace, and on the Home screen,
- 184. Improve Fit: Increase Number of Agents Next, change the number of Agents to your desired value,
- 185. Improve Fit: Increase Number of Agents Some things to watch out for: Increasing the number of
- 186. Improve Fit: Adjust based on number of over/under predictions. Check your MAPE workbook. In any given
- 187. Improve Fit: Adjust based on number of over/under predictions. First, let’s adjust the number of consumers.
- 188. Improve Fit: Adjust based on number of over/under predictions. The number of consumers is usually in
- 189. Improve Fit: Adjust based on number of over/under predictions. You can also do this with Units
- 190. Improve Fit: Adjust based on number of over/under predictions. Frequency can be found under Agents->Definitions->Needs. Units
- 191. Improve Fit: Adjust based on number of over/under predictions. Frequency is a Gamma distribution with parameters
- 192. Target Your “Problem” Weeks Some weeks will have more errors than others. Focus on the weeks
- 193. Target Your “Problem” Weeks Open the plan once you’ve downloaded it and click on the Plan
- 194. Diagnose common problems with the fit chart (green bar is actuals, red is predicted) What this
- 195. Diagnose common problems with the fit chart (green bar is actuals, red is predicted) What this
- 196. Fine Tuning
- 197. Fine Tuning Purpose of this step: This step is designed to simultaneously improve the fit of
- 198. Fine Tuning Step-by-step instructions: Increase the number of agents in the simulation to at least 20,000,
- 199. Fine Tuning Seasonality may be worth revisiting – once you’ve teased out some of the marketing
- 200. Fine Tuning Watch-outs: Because the scenarios will take longer to run, it’s usually advisable to run
- 201. Future Prediction Awareness Impacts
- 202. Future Prediction Awareness Impacts Purpose: To ensure that the model behaves as expected in future simulations.
- 203. Future Prediction Awareness Impacts Step by Step: The goal of this step of the calibration is
- 204. Future Prediction Awareness Impacts Step by Step: Business as usual is the most important test run
- 205. Future Prediction Awareness Impacts Step by Step: In the dark scenario, awareness will decline. How far
- 206. SmartMix Suite
- 207. SmartMix Suite Purpose: The purpose of using the SmartMix Suite is to quickly find key information
- 208. SmartMix Suite Step-By-Step: There are two areas of the SmartMix user interface: the top and bottom
- 209. SmartMix Suite Differences in Top Portion Functionality within the SmartMix Suite: In SmartSpend you will want
- 210. SmartMix Suite – Top Portion Functionality Top Portion Functionality
- 211. SmartMix Suite Bottom Portion Functionality: The bottom portion of the user interface controls a number of
- 212. SmartMix Suite – Bottom Portion Functionality
- 213. SmartMix Suite General Notes: When SmartSpend, SmartROI or SmartPlan® completes, a new plan is generated in
- 214. SmartMix Tips and Tricks SmartMix is now more accurate and provides better recommendations but takes longer
- 215. Customer Specific Simulations
- 216. Customer Specific Simulations Purpose: Each customer will have a certain number of unique business questions that
- 217. Customer Specific Simulations Step by Step: The steps for these simulations will be different for each
- 218. Customer Specific Simulations Watch-outs: Be sure to review the results of the customer-specific simulations once they
- 219. Saturation volume input runs
- 220. Saturation volume input runs Purpose: Testing extremes of the model tactic-by-tactic to ensure saturation dynamics are
- 221. Saturation volume input runs Step by Step: The modeler needs to set up several runs of
- 222. Saturation volume input runs Step by Step: And ROI should follow: Set up of the runs
- 223. Saturation volume input runs Step by Step: As a tip, create a new folder for on
- 224. Saturation volume input runs Step by Step: After deriving these curves, the modeler must analyze the
- 225. Segment Performance Runs
- 226. Segment Performance Runs Purpose of this step: These runs will help identify which marketing activities are
- 227. Segment Performance Runs SmartMix can be used to optimize sales for a specific target group or
- 228. Segment Performance Runs Measure marketing performance by segment Navigate to Forecasts ? Marketing Performance Select the
- 229. Segment Performance Runs Copy the SmartMix plan, and any others you’d like to modify in order
- 230. Segment Performance Runs Watch-outs: As with any other SmartMix run, be sure to set maximums appropriately
- 231. Change in Sales Chart
- 232. Change in Sales Chart Purpose: Utilizing this chart will help determine that amount level in which
- 233. Change in Sales Chart Step by Step: To view the Change in Sales Chart, first: On
- 234. Change in Sales Chart Step Three: Set Chart Details Only one modeled item can be selected.
- 235. Change in Sales Chart After the chart is completed, the Change in Sales bar chart along
- 236. Change in Sales Chart Watch Outs: Though the software will allow to compare simulations of different
- 237. How are impacts calculated? While some may see this and claim synergy – this has more
- 238. Optimal Mix Runs
- 239. Optimal Mix Runs Purpose: The purpose of this part in the process is to arrive at
- 240. Optimal Mix Runs Step-By-Step: First step is to reach back into previous work on this account
- 241. Optimal Mix Runs Step-By-Step: Putting all of these together, the next step is to set up
- 242. Marginal ROI
- 243. Marginal ROI Analysis Purpose: How to set up plans and calculate the marginal return on incremental
- 244. Step by Step: Open the relevant marketplace From the dashboard, click on PLAN on the top
- 245. Step by Step: After the copied plan is created, select that plan and then click on
- 246. Pic 2 Pic 1 Create Patterns for Marketing Objects
- 247. Pic 3 Create Patterns for Marketing Objects
- 248. Noteworthy The most common incremental spend is $1 million. However, that amount could be $500K or
- 249. Training Software Prep
- 250. Training Software Prep (1/5) Purpose: Before customers are given access to a marketplace, it needs to
- 251. Training Software Prep (2/5) Add a chart to the Home Screen Login as a customer to
- 252. Training Software Prep (3/5) Make sure the Base Plan is 'Shared, Read-Only' and easily found Hide
- 253. Training Software Prep (4/5) Check drop-downs in all 3 SmartMix modules – Are your Base Plans
- 255. Скачать презентацию

Table of Contents
Table of Contents

Data Discovery Meeting
Data Discovery Meeting

Data Discovery Meeting (1/7)
Purpose:
To establish a global picture of all data
Data Discovery Meeting (1/7)
Purpose:
To establish a global picture of all data

Data Discovery Meeting (2/7)
Step by Step:
Prior to the meeting, send
Data Discovery Meeting (2/7)
Step by Step:
Prior to the meeting, send

Data Discovery Meeting (3/7)
Typical Media Activities and Breaks:
Television: Daypart, Duration,
Data Discovery Meeting (3/7)
Typical Media Activities and Breaks:
Television: Daypart, Duration,

Data Discovery Meeting (4/7)
Typical Trade/Promotional Activities:
Coupons
Temporary Price Reductions (TPRs)
Feature, Display, Feature
Data Discovery Meeting (4/7)
Typical Trade/Promotional Activities:
Coupons
Temporary Price Reductions (TPRs)
Feature, Display, Feature

(5/7)
Pic 1
(5/7)
Pic 1

(6/7)
Pic 2
(6/7)
Pic 2

(7/7)
Pic 3
(7/7)
Pic 3

Creating a New Project Instance
Creating a New Project Instance

Creating a New Project Instance (1/4)
Purpose:
A project instance holds a particular
Creating a New Project Instance (1/4)
Purpose:
A project instance holds a particular

Creating a New Project Instance (2/4)
Step by Step:
Open the relevant
Creating a New Project Instance (2/4)
Step by Step:
Open the relevant

Pic 1
Pic 2
(3/4)
Pic 1
Pic 2
(3/4)

Settings Field:
Sales Units: Typically set to “Millions”. Thousands or billions can
Settings Field:
Sales Units: Typically set to “Millions”. Thousands or billions can

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)
Configuring the marketplace (needs, channels, external factors, seasonality, brands, modeled items)

Configuring the Marketplace (sales, price, distribution)
Configuring the Marketplace (sales, price, distribution)

Configuring the Marketplace (sales, price, distribution (1/4)
Purpose:
Finalizing the marketplace so
Configuring the Marketplace (sales, price, distribution (1/4)
Purpose:
Finalizing the marketplace so

Configuring the Marketplace (sales, price, distribution) (2/4)
Sales: Inputting sales into
Configuring the Marketplace (sales, price, distribution) (2/4)
Sales: Inputting sales into

Configuring the Marketplace (sales, price, distribution) (3/4)
Price: Price can be
Configuring the Marketplace (sales, price, distribution) (3/4)
Price: Price can be

Configuring the Marketplace (sales, price, distribution) (4/4)
Often, traditional “distribution” is
Configuring the Marketplace (sales, price, distribution) (4/4)
Often, traditional “distribution” is

Defining Seasonality
Defining Seasonality

Defining Seasonality
Purpose:
Defining seasonality to determine when agents are most likely to
Defining Seasonality
Purpose:
Defining seasonality to determine when agents are most likely to

Defining Seasonality
Step by Step:
Seasonality is used to determine when agents are
Defining Seasonality
Step by Step:
Seasonality is used to determine when agents are

Defining Seasonality
Step by Step:
For each year of the calibration, divide each
Defining Seasonality
Step by Step:
For each year of the calibration, divide each

Sampling Variables to get to 100%
Sampling Variables to get to 100%

Sampling Variables to get to 100% (1/3)
Certain variables are required to
Sampling Variables to get to 100% (1/3)
Certain variables are required to

Sampling Variables to get to 100% (2/3)
How do you deal with
Sampling Variables to get to 100% (2/3)
How do you deal with

Sampling Variables to get to 100% (3/3)
Use solver, change the green
Sampling Variables to get to 100% (3/3)
Use solver, change the green

Agent Generation - Demographics
Agent Generation - Demographics

Agent Generation (1/7)
Purpose:
Agent characteristics typically include demographics, placement on a brand
Agent Generation (1/7)
Purpose:
Agent characteristics typically include demographics, placement on a brand

Agent Generation (2/7)
Step by Step:
Open the relevant marketplace
On the Agents
Agent Generation (2/7)
Step by Step:
Open the relevant marketplace
On the Agents

(3/7)
Pic 1
(3/7)
Pic 1

Agent Generation (4/7)
Step by Step:
In the example provided, Income is
Agent Generation (4/7)
Step by Step:
In the example provided, Income is

Agent Generation (5/7)
Probability Density Functions:
Beta(z, S)
Sampled values are between 0
Agent Generation (5/7)
Probability Density Functions:
Beta(z, S)
Sampled values are between 0

Agent Generation (6/7)
Demographics:
Many different distributions used: Income (gamma), Race (discrete),
Agent Generation (6/7)
Demographics:
Many different distributions used: Income (gamma), Race (discrete),

Agent Generation (7/7)
Watch outs:
If sampled values of media awareness are
Agent Generation (7/7)
Watch outs:
If sampled values of media awareness are

Weekly Data Collection Meetings
Weekly Data Collection Meetings

Weekly Data Collection Meetings (1/4)
Purpose:
To facilitate frequent and regular communication between
Weekly Data Collection Meetings (1/4)
Purpose:
To facilitate frequent and regular communication between

Weekly Data Collection Meetings (2/4)
Step by Step:
Prior to the meeting,
Weekly Data Collection Meetings (2/4)
Step by Step:
Prior to the meeting,

(3/4)
Pic 1
(3/4)
Pic 1

(4/4)
Pic 2
(4/4)
Pic 2

Agent Generation – Media Activities
Agent Generation – Media Activities

Agent Generation – Media Activities
Purpose:
In order to simulate media consumption behaviors
Agent Generation – Media Activities
Purpose:
In order to simulate media consumption behaviors

Step by Step:
Open the relevant marketplace
From the dashboard, click on
Step by Step:
Open the relevant marketplace
From the dashboard, click on

Step by Step (cont.):
A graph will appear on the right hand
Step by Step (cont.):
A graph will appear on the right hand

Pic 2
Pic 1
Pic 3
Agent Generation – Media Activities
Pic 2
Pic 1
Pic 3
Agent Generation – Media Activities

Pic 4
Agent Generation – Media Activities
Any tactic from the marketing plan
Pic 4
Agent Generation – Media Activities
Any tactic from the marketing plan

Noteworthy
Include as many media activities as available, even those that the
Noteworthy
Include as many media activities as available, even those that the

Agent Generation
(Targets, Needs, Influences, Weights)
Agent Generation
(Targets, Needs, Influences, Weights)

Agent Generation (Targets, Needs, Influences, Weights)
Purpose:
This step is important because the
Agent Generation (Targets, Needs, Influences, Weights)
Purpose:
This step is important because the

Agent Generation (Needs)
Step by Step:
Needs - for every need defined
Agent Generation (Needs)
Step by Step:
Needs - for every need defined

Agent Generation (Targets)
Targets
After establishing which targets you want to define (see
Agent Generation (Targets)
Targets
After establishing which targets you want to define (see

Agent Generation (Targets)
Targets (continued)
Note that if you used a Beta distribution
Agent Generation (Targets)
Targets (continued)
Note that if you used a Beta distribution

Agent Generation (Influences)
If you decide that you need to use the
Agent Generation (Influences)
If you decide that you need to use the

Agent Generation (Weights)
Again, each agent in the model represents an arbitrary
Agent Generation (Weights)
Again, each agent in the model represents an arbitrary

Agent Generation (Weights)
Watch-outs
Nearly every project will make use of Targets and
Agent Generation (Weights)
Watch-outs
Nearly every project will make use of Targets and

Correlating agent characteristics
Correlating agent characteristics

Correlating agent characteristics (1/8)
Purpose:
In order to make the agent population more
Correlating agent characteristics (1/8)
Purpose:
In order to make the agent population more

Correlating agent characteristics (2/8)
Step by Step:
Open the relevant marketplace
On the
Correlating agent characteristics (2/8)
Step by Step:
Open the relevant marketplace
On the

Correlating agent characteristics (3/8)
Viewing habits of younger people
Viewing habits of older
Correlating agent characteristics (3/8)
Viewing habits of younger people
Viewing habits of older

(4/8)
Gender value of 1 = Female
Less than/greater than agent value
Direction of
(4/8)
Gender value of 1 = Female
Less than/greater than agent value
Direction of

Correlating agent characteristics (5/8)
Step by Step:
In the example provided, the
Correlating agent characteristics (5/8)
Step by Step:
In the example provided, the

Correlating agent characteristics (6/8)
How is this handled:
If I want higher sampled
Correlating agent characteristics (6/8)
How is this handled:
If I want higher sampled

Correlating agent characteristics (7/8)
Export Agents:
The analyst can export data [Export
Correlating agent characteristics (7/8)
Export Agents:
The analyst can export data [Export

Correlating agent characteristics (7/8)
Pic 2
TV Minutes
Income
Age
TV Minutes
Correlating agent characteristics (7/8)
Pic 2
TV Minutes
Income
Age
TV Minutes

Agent Generation: All Variables, Final Variables
Agent Generation: All Variables, Final Variables

Agent Generation: All Variables, Final Variables
Purpose:
The purpose of the All Variables
Agent Generation: All Variables, Final Variables
Purpose:
The purpose of the All Variables

Agent Generation: All Variables, Final Variables
Step by Step – All Variables:
Agent Generation: All Variables, Final Variables
Step by Step – All Variables:

Agent Generation: All Variables, Final Variables
Step by Step – Final Variables:
Agent Generation: All Variables, Final Variables
Step by Step – Final Variables:

Agent Generation: All Variables, Final Variables
Watch-outs:
All Variables screen
Use this screen
Agent Generation: All Variables, Final Variables
Watch-outs:
All Variables screen
Use this screen

Agent Generation: All Variables, Final Variables
Watch-outs:
Final Variables screen
When initializing Ever
Agent Generation: All Variables, Final Variables
Watch-outs:
Final Variables screen
When initializing Ever

Importing/Exporting Agents
Importing/Exporting Agents

Exporting Agents
Purpose:
Exporting agents allows the analyst to document and store all
Exporting Agents
Purpose:
Exporting agents allows the analyst to document and store all

Exporting Agents
Step by Step:
To export agents, navigate to the Agents
Exporting Agents
Step by Step:
To export agents, navigate to the Agents

Exporting Agents
Exporting Agents

Agent Generation Calibration/Tweaking
Agent Generation Calibration/Tweaking

Agent Generation Calibration/Tweaking
Purpose:
Calibrating the agent population to ensure it is a
Agent Generation Calibration/Tweaking
Purpose:
Calibrating the agent population to ensure it is a

Agent Generation Calibration/Tweaking
Step by Step:
This step of the process is to
Agent Generation Calibration/Tweaking
Step by Step:
This step of the process is to

Agent Generation Calibration/Tweaking
Step by Step:
To that point, unless the modeled population
Agent Generation Calibration/Tweaking
Step by Step:
To that point, unless the modeled population

Agent Generation Calibration/Tweaking
Step by Step:
As a first step, the agent population
Agent Generation Calibration/Tweaking
Step by Step:
As a first step, the agent population

Agent Generation Calibration/Tweaking
Step by Step:
This makes for easy comparisons to see
Agent Generation Calibration/Tweaking
Step by Step:
This makes for easy comparisons to see

Agent Generation Calibration/Tweaking
Correlations are the most frequently used lever in agent
Agent Generation Calibration/Tweaking
Correlations are the most frequently used lever in agent

Agent Generation Calibration/Tweaking
That said, it likely impossible to “hit” every single
Agent Generation Calibration/Tweaking
That said, it likely impossible to “hit” every single

Reach Curve Generation
Reach Curve Generation

Reach Curve Generation – Calculate the Reach Conversion Rate
Purpose:
Help the marketplace
Reach Curve Generation – Calculate the Reach Conversion Rate
Purpose:
Help the marketplace

The marketplace calculates reach as follows:
Reach = (1-EXP(Conversion Rate*Execution Data))*Reach Constant
Therefore,
The marketplace calculates reach as follows:
Reach = (1-EXP(Conversion Rate*Execution Data))*Reach Constant
Therefore,

Step by Step (Calculate the Reach)
Below are some equations that may
Step by Step (Calculate the Reach)
Below are some equations that may

Step by Step (Calculate Conversion Rate)
Once you have calculated the reach,
Step by Step (Calculate Conversion Rate)
Once you have calculated the reach,

Pic 2
Pic 1
Reach Curve Generation – Calculate the Reach Conversion Rate
Step
Pic 2
Pic 1
Reach Curve Generation – Calculate the Reach Conversion Rate
Step

Noteworthy
For customers within an industry, their reach conversion rates should be
Noteworthy
For customers within an industry, their reach conversion rates should be

Put Marketing Activities into Model
Put Marketing Activities into Model

Put Marketing Activities into Model (1/5)
Purpose:
This step in implementation populates the
Put Marketing Activities into Model (1/5)
Purpose:
This step in implementation populates the

Put Marketing Activities into Model (2/5)
Step by Step:
Open the relevant
Put Marketing Activities into Model (2/5)
Step by Step:
Open the relevant

Step by Step (cont.):
Marketing Plan Grouping is where you have
Step by Step (cont.):
Marketing Plan Grouping is where you have

Picture 1 (4/5)
Picture 1 (4/5)

Picture 2 (5/5)
Picture 2 (5/5)

Create Patterns for Marketing Objects
Create Patterns for Marketing Objects

Create Patterns for Marketing Objects (1/5)
Purpose:
Some marketing tactics, such as coupon
Create Patterns for Marketing Objects (1/5)
Purpose:
Some marketing tactics, such as coupon

Step by Step:
Open the relevant marketplace
From the dashboard, click on
Step by Step:
Open the relevant marketplace
From the dashboard, click on

Step by Step (cont.):
Each box represents one week, therefore, enter the
Step by Step (cont.):
Each box represents one week, therefore, enter the

Pic 2
Pic 1
Pic 3
Create Patterns for Marketing Objects (4/5)
Pic 2
Pic 1
Pic 3
Create Patterns for Marketing Objects (4/5)

Noteworthy
Coupons, direct mail, and email are the most common marketing objects
Noteworthy
Coupons, direct mail, and email are the most common marketing objects

Set Up Base Marketing Plan
Set Up Base Marketing Plan

Set Up Base Marketing Plan
Purpose of this step
This step is required
Set Up Base Marketing Plan
Purpose of this step
This step is required

Set Up Base Marketing Plan
Prerequisites (continued)
The summaries must include, at a
Set Up Base Marketing Plan
Prerequisites (continued)
The summaries must include, at a

Set Up Base Marketing Plan
Step-by-step instructions:
Collect the files containing the weekly
Set Up Base Marketing Plan
Step-by-step instructions:
Collect the files containing the weekly

Set Up Base Marketing Plan
Click on the plan you just created,
Set Up Base Marketing Plan
Click on the plan you just created,

Set Up Base Marketing Plan
On the Import Plans screen, click “+
Set Up Base Marketing Plan
On the Import Plans screen, click “+

Set Up Base Marketing Plan
Watch-Outs
If you have data on marketing activities
Set Up Base Marketing Plan
Watch-Outs
If you have data on marketing activities

Set Up Base Marketing Plan
How long should this step take?
Summary of
Set Up Base Marketing Plan
How long should this step take?
Summary of

Set Up Calibrate/Scenarios Screen
Set Up Calibrate/Scenarios Screen

Setting up Calibrate/Scenarios Screen
Purpose of this step: This step is the
Setting up Calibrate/Scenarios Screen
Purpose of this step: This step is the

Pic 3
Setting up Calibrate/Scenarios Screen
Pic 3
Setting up Calibrate/Scenarios Screen

Setting up Calibrate/Scenarios Screen
Recommendations for starting values of
Saturation Constant of 1.0
Setting up Calibrate/Scenarios Screen
Recommendations for starting values of
Saturation Constant of 1.0

Run Regression
Run Regression

Running a Regression
Purpose:
Running a simple regression on your dependent variable and
Running a Regression
Purpose:
Running a simple regression on your dependent variable and

Running a Regression
Step by Step:
Open up a blank workbook in
Running a Regression
Step by Step:
Open up a blank workbook in

Running a Regression
Running a Regression

Running a Regression
For the next step you will need to have
Running a Regression
For the next step you will need to have

Running a Regression
If you don’t see it, try going to File->Options->Add-ins.
Make
Running a Regression
If you don’t see it, try going to File->Options->Add-ins.
Make

Running a Regression
So now you have the Data Analysis button on
Running a Regression
So now you have the Data Analysis button on

Running a Regression
Make the Y range equal to the range of
Running a Regression
Make the Y range equal to the range of

Running a Regression
Output should look something like this. I’ve highlighted the
Running a Regression
Output should look something like this. I’ve highlighted the

Running a Regression
You can use the coefficients to build a simple
Running a Regression
You can use the coefficients to build a simple

Running a Regression
To figure out how much volume the regression predicts
Running a Regression
To figure out how much volume the regression predicts

Running a Regression
A few more points to consider. T-stat is a
Running a Regression
A few more points to consider. T-stat is a

Bug Check (Calibration)
Bug Check (Calibration)

Bug Check
Purpose:
The model will not run if agents and/or marketing activities
Bug Check
Purpose:
The model will not run if agents and/or marketing activities

Bug Check (General)
Bug Check (General)

Bug Check
Purpose:
By bug checking, you’re ensuring the validity and accuracy of
Bug Check
Purpose:
By bug checking, you’re ensuring the validity and accuracy of

Step by Step (continued):
An email should be sent to support@thinkvine.com
In
Step by Step (continued):
An email should be sent to support@thinkvine.com
In
![Example Bug Check Email: SUBJECT: [Insert Name of Bug] TO:](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/9875/slide-141.jpg)
Example Bug Check Email:
SUBJECT: [Insert Name of Bug]
TO: support@thinkvine.com
FROM: marvin@thinkvine.com
CC: Anyone
Example Bug Check Email:
SUBJECT: [Insert Name of Bug]
TO: support@thinkvine.com
FROM: marvin@thinkvine.com
CC: Anyone

AutoCalibrate
AutoCalibrate

Autocalibration
Purpose:
Once the initial plan is run, use auto-calibration to save time
Autocalibration
Purpose:
Once the initial plan is run, use auto-calibration to save time

Autocalibration
Rough steps mimic what you do manually
Rotating rounds loop through your
Autocalibration
Rough steps mimic what you do manually
Rotating rounds loop through your

Autocalibration
You can set the initial value for any parameter
If that parameter
Autocalibration
You can set the initial value for any parameter
If that parameter

Autocalibration
Recommendations for best outcomes:
Use a narrow media forgetting range, like 0.1
Autocalibration
Recommendations for best outcomes:
Use a narrow media forgetting range, like 0.1

Autocalibration
Autocalibration will help with parameter choices of Exo Variables
Use the “Minimum”
Autocalibration
Autocalibration will help with parameter choices of Exo Variables
Use the “Minimum”

Autocalibration
In the Software:
Calibrate / Choose scenario
“Work on Scenario”
Autocalibration / Setting
Autocalibration
In the Software:
Calibrate / Choose scenario
“Work on Scenario”
Autocalibration / Setting

Autocalibration / Impacts and Results
Awareness goals: don’t need these, but can
Autocalibration / Impacts and Results
Awareness goals: don’t need these, but can

Autocalibration / Impacts and Results
Sales Goals:
You must enter at least one
Autocalibration / Impacts and Results
Sales Goals:
You must enter at least one

Autocalibration
Outputs:
A scenario, with the name you specified, seen on the
Autocalibration
Outputs:
A scenario, with the name you specified, seen on the

Autocalibration watch-out: noise in weekly sales
Because of the low number of
Autocalibration watch-out: noise in weekly sales
Because of the low number of

Set up MAPE Workbook
Set up MAPE Workbook

Set up MAPE Workbook
Purpose:
The purpose of setting up a MAPE Workbook
Set up MAPE Workbook
Purpose:
The purpose of setting up a MAPE Workbook

Set up MAPE Workbook
Step by Step (1/2):
To create your MAPE
Set up MAPE Workbook
Step by Step (1/2):
To create your MAPE

Set up MAPE Workbook
Step by Step (2/2):
In addition to the
Set up MAPE Workbook
Step by Step (2/2):
In addition to the

Set up MAPE Workbook
Watch-outs:
Most analysts already have templates, including the
Set up MAPE Workbook
Watch-outs:
Most analysts already have templates, including the

Set up the MAPE Calculator
Set up the MAPE Calculator

Set up MAPE Calculator
Purpose:
The MAPE calculator is a tool that allows
Set up MAPE Calculator
Purpose:
The MAPE calculator is a tool that allows

Set up MAPE Calculator
Step by Step: (1/4)
Obtain a copy of the
Set up MAPE Calculator
Step by Step: (1/4)
Obtain a copy of the

Set up MAPE Calculator
Step by Step: (2/4)
Click “Locate File…” and select
Set up MAPE Calculator
Step by Step: (2/4)
Click “Locate File…” and select

Set up MAPE Calculator
Step by Step: (3/4)
The calculator will output
Set up MAPE Calculator
Step by Step: (3/4)
The calculator will output

Set up MAPE Calculator
Step by Step: (4/4)
If there is a negative
Set up MAPE Calculator
Step by Step: (4/4)
If there is a negative

Flatten Awareness
Flatten Awareness

Flatten Awareness (1/4)
Purpose:
The probability that an agent purchases an item is
Flatten Awareness (1/4)
Purpose:
The probability that an agent purchases an item is

Flatten Awareness (2/4)
Step by Step:
Open the relevant marketplace
On the Calibrate
Flatten Awareness (2/4)
Step by Step:
Open the relevant marketplace
On the Calibrate

Flatten Awareness (3/4)
Step by Step:
An Excel file with weekly awareness
Flatten Awareness (3/4)
Step by Step:
An Excel file with weekly awareness

Flatten awareness (4/4)
How to adjust awareness
If awareness is trending up or
Flatten awareness (4/4)
How to adjust awareness
If awareness is trending up or

Improve Impacts
Improve Impacts

Improve Impacts
Purpose:
Highlight some common adjustments to improve the impacts of the
Improve Impacts
Purpose:
Highlight some common adjustments to improve the impacts of the

Step by Step:
What to think about when adjusting impacts:
Are tactics
Step by Step:
What to think about when adjusting impacts:
Are tactics

Step by Step:
Adjust the impact of individual marketing objects:
This process
Step by Step:
Adjust the impact of individual marketing objects:
This process

Step by Step:
Adjust the impact of all marketing objects:
This macro
Step by Step:
Adjust the impact of all marketing objects:
This macro

Step by Step:
Adjust the impact of all marketing objects (cont.):
The
Step by Step:
Adjust the impact of all marketing objects (cont.):
The

Pic 2
Pic 1
Improve Impacts
Pic 2
Pic 1
Improve Impacts

Pic 3
Improve Impacts
Pic 3
Improve Impacts

Pic 5
Pic 6
Pic 7
Pic 4
Pic 5
Pic 6
Pic 7
Pic 4

Noteworthy
A tool such as Parameter Solver, image below, can translate the
Noteworthy
A tool such as Parameter Solver, image below, can translate the

Improve Fit
Improve Fit

Improve Fit
Purpose:
Illustrate some common ways to improve your model fit.
Methods:
1.
Improve Fit
Purpose:
Illustrate some common ways to improve your model fit.
Methods:
1.

Improve Fit: Increase Number of Agents
Increasing the number of agents is
Improve Fit: Increase Number of Agents
Increasing the number of agents is

Improve Fit: Increase Number of Agents
Navigate to the correct marketplace, and
Improve Fit: Increase Number of Agents
Navigate to the correct marketplace, and

Improve Fit: Increase Number of Agents
Next, change the number of Agents
Improve Fit: Increase Number of Agents
Next, change the number of Agents

Improve Fit: Increase Number of Agents
Some things to watch out for:
Increasing
Improve Fit: Increase Number of Agents
Some things to watch out for:
Increasing

Improve Fit: Adjust based on number of over/under predictions.
Check your MAPE
Improve Fit: Adjust based on number of over/under predictions.
Check your MAPE

Improve Fit: Adjust based on number of over/under predictions.
First, let’s adjust
Improve Fit: Adjust based on number of over/under predictions.
First, let’s adjust

Improve Fit: Adjust based on number of over/under predictions.
The number of
Improve Fit: Adjust based on number of over/under predictions.
The number of

Improve Fit: Adjust based on number of over/under predictions.
You can also
Improve Fit: Adjust based on number of over/under predictions.
You can also

Improve Fit: Adjust based on number of over/under predictions.
Frequency can be
Improve Fit: Adjust based on number of over/under predictions.
Frequency can be

Improve Fit: Adjust based on number of over/under predictions.
Frequency is a
Improve Fit: Adjust based on number of over/under predictions.
Frequency is a

Target Your “Problem” Weeks
Some weeks will have more errors than others.
Target Your “Problem” Weeks
Some weeks will have more errors than others.

Target Your “Problem” Weeks
Open the plan once you’ve downloaded it and
Target Your “Problem” Weeks
Open the plan once you’ve downloaded it and

Diagnose common problems with the fit chart
(green bar is actuals, red
Diagnose common problems with the fit chart
(green bar is actuals, red

Diagnose common problems with the fit chart
(green bar is actuals, red
Diagnose common problems with the fit chart
(green bar is actuals, red

Fine Tuning
Fine Tuning

Fine Tuning
Purpose of this step: This step is designed to simultaneously
Fine Tuning
Purpose of this step: This step is designed to simultaneously

Fine Tuning
Step-by-step instructions:
Increase the number of agents in the simulation to
Fine Tuning
Step-by-step instructions:
Increase the number of agents in the simulation to

Fine Tuning
Seasonality may be worth revisiting – once you’ve teased out
Fine Tuning
Seasonality may be worth revisiting – once you’ve teased out

Fine Tuning
Watch-outs:
Because the scenarios will take longer to run, it’s usually
Fine Tuning
Watch-outs:
Because the scenarios will take longer to run, it’s usually

Future Prediction Awareness Impacts
Future Prediction Awareness Impacts

Future Prediction Awareness Impacts
Purpose:
To ensure that the model behaves as expected
Future Prediction Awareness Impacts
Purpose:
To ensure that the model behaves as expected

Future Prediction Awareness Impacts
Step by Step:
The goal of this step
Future Prediction Awareness Impacts
Step by Step:
The goal of this step

Future Prediction Awareness Impacts
Step by Step:
Business as usual is the
Future Prediction Awareness Impacts
Step by Step:
Business as usual is the

Future Prediction Awareness Impacts
Step by Step:
In the dark scenario, awareness
Future Prediction Awareness Impacts
Step by Step:
In the dark scenario, awareness

SmartMix Suite
SmartMix Suite

SmartMix Suite
Purpose:
The purpose of using the SmartMix Suite is to quickly
SmartMix Suite
Purpose:
The purpose of using the SmartMix Suite is to quickly

SmartMix Suite
Step-By-Step:
There are two areas of the SmartMix user interface: the
SmartMix Suite
Step-By-Step:
There are two areas of the SmartMix user interface: the

SmartMix Suite
Differences in Top Portion Functionality within the SmartMix Suite:
In SmartSpend
SmartMix Suite
Differences in Top Portion Functionality within the SmartMix Suite:
In SmartSpend

SmartMix Suite – Top Portion Functionality
Top Portion Functionality
SmartMix Suite – Top Portion Functionality
Top Portion Functionality

SmartMix Suite
Bottom Portion Functionality:
The bottom portion of the user interface controls
SmartMix Suite
Bottom Portion Functionality:
The bottom portion of the user interface controls

SmartMix Suite – Bottom Portion Functionality
SmartMix Suite – Bottom Portion Functionality

SmartMix Suite
General Notes:
When SmartSpend, SmartROI or SmartPlan® completes, a new plan
SmartMix Suite
General Notes:
When SmartSpend, SmartROI or SmartPlan® completes, a new plan

SmartMix Tips and Tricks
SmartMix is now more accurate and provides better
SmartMix Tips and Tricks
SmartMix is now more accurate and provides better

Customer Specific Simulations
Customer Specific Simulations

Customer Specific Simulations
Purpose:
Each customer will have a certain number of unique
Customer Specific Simulations
Purpose:
Each customer will have a certain number of unique

Customer Specific Simulations
Step by Step:
The steps for these simulations will
Customer Specific Simulations
Step by Step:
The steps for these simulations will

Customer Specific Simulations
Watch-outs:
Be sure to review the results of the
Customer Specific Simulations
Watch-outs:
Be sure to review the results of the

Saturation volume input runs
Saturation volume input runs

Saturation volume input runs
Purpose:
Testing extremes of the model tactic-by-tactic to ensure
Saturation volume input runs
Purpose:
Testing extremes of the model tactic-by-tactic to ensure

Saturation volume input runs
Step by Step:
The modeler needs to set
Saturation volume input runs
Step by Step:
The modeler needs to set

Saturation volume input runs
Step by Step:
And ROI should follow:
Set up
Saturation volume input runs
Step by Step:
And ROI should follow:
Set up

Saturation volume input runs
Step by Step:
As a tip, create a
Saturation volume input runs
Step by Step:
As a tip, create a

Saturation volume input runs
Step by Step:
After deriving these curves, the
Saturation volume input runs
Step by Step:
After deriving these curves, the

Segment Performance Runs
Segment Performance Runs

Segment Performance Runs
Purpose of this step: These runs will help identify
Segment Performance Runs
Purpose of this step: These runs will help identify

Segment Performance Runs
SmartMix can be used to optimize sales for a
Segment Performance Runs
SmartMix can be used to optimize sales for a

Segment Performance Runs
Measure marketing performance by segment
Navigate to Forecasts ? Marketing
Segment Performance Runs
Measure marketing performance by segment
Navigate to Forecasts ? Marketing

Segment Performance Runs
Copy the SmartMix plan, and any others you’d like
Segment Performance Runs
Copy the SmartMix plan, and any others you’d like

Segment Performance Runs
Watch-outs:
As with any other SmartMix run, be sure to
Segment Performance Runs
Watch-outs:
As with any other SmartMix run, be sure to

Change in Sales Chart
Change in Sales Chart

Change in Sales Chart
Purpose:
Utilizing this chart will help determine that amount
Change in Sales Chart
Purpose:
Utilizing this chart will help determine that amount

Change in Sales Chart
Step by Step:
To view the Change in
Change in Sales Chart
Step by Step:
To view the Change in

Change in Sales Chart
Step Three: Set Chart Details
Only one modeled item
Change in Sales Chart
Step Three: Set Chart Details Only one modeled item

Change in Sales Chart
After the chart is completed, the Change in
Change in Sales Chart
After the chart is completed, the Change in

Change in Sales Chart
Watch Outs:
Though the software will allow to compare
Change in Sales Chart
Watch Outs:
Though the software will allow to compare

How are impacts calculated?
While some may see this and claim synergy
How are impacts calculated?
While some may see this and claim synergy

Optimal Mix Runs
Optimal Mix Runs

Optimal Mix Runs
Purpose:
The purpose of this part in the process is
Optimal Mix Runs
Purpose:
The purpose of this part in the process is

Optimal Mix Runs
Step-By-Step:
First step is to reach back into previous work
Optimal Mix Runs
Step-By-Step:
First step is to reach back into previous work

Optimal Mix Runs
Step-By-Step:
Putting all of these together, the next step is
Optimal Mix Runs
Step-By-Step:
Putting all of these together, the next step is

Marginal ROI
Marginal ROI

Marginal ROI Analysis
Purpose:
How to set up plans and calculate the marginal
Marginal ROI Analysis
Purpose:
How to set up plans and calculate the marginal

Step by Step:
Open the relevant marketplace
From the dashboard, click on
Step by Step:
Open the relevant marketplace
From the dashboard, click on

Step by Step:
After the copied plan is created, select that
Step by Step:
After the copied plan is created, select that

Pic 2
Pic 1
Create Patterns for Marketing Objects
Pic 2
Pic 1
Create Patterns for Marketing Objects

Pic 3
Create Patterns for Marketing Objects
Pic 3
Create Patterns for Marketing Objects

Noteworthy
The most common incremental spend is $1 million. However, that amount
Noteworthy
The most common incremental spend is $1 million. However, that amount

Training Software Prep
Training Software Prep

Training Software Prep (1/5)
Purpose:
Before customers are given access to a marketplace,
Training Software Prep (1/5)
Purpose:
Before customers are given access to a marketplace,

Training Software Prep (2/5)
Add a chart to the Home Screen
Login as
Training Software Prep (2/5)
Add a chart to the Home Screen
Login as

Training Software Prep (3/5)
Make sure the Base Plan is 'Shared, Read-Only'
Training Software Prep (3/5)
Make sure the Base Plan is 'Shared, Read-Only'

Training Software Prep (4/5)
Check drop-downs in all 3 SmartMix modules –
Training Software Prep (4/5)
Check drop-downs in all 3 SmartMix modules –
 Последовательность
Последовательность Решение задач ЕГЭ типа В6
Решение задач ЕГЭ типа В6 Шаблон для друку статистичних звітів в Excel
Шаблон для друку статистичних звітів в Excel Set Theory
Set Theory Внеклассное мероприятие по информатике для 9 класса Турнир знатоков
Внеклассное мероприятие по информатике для 9 класса Турнир знатоков Складання та виконання алгоритмів з розгалуженням у середовищі Scratch. 7 клас. Урок №12
Складання та виконання алгоритмів з розгалуженням у середовищі Scratch. 7 клас. Урок №12 Занятие №7 Symfony, Composer, Реализация таблицы
Занятие №7 Symfony, Composer, Реализация таблицы Microsoft SQL Server 2008 кіріспе
Microsoft SQL Server 2008 кіріспе Интернет. СМИ
Интернет. СМИ Серия уроков по исполниелю Чертёжник
Серия уроков по исполниелю Чертёжник Тестирование программных средств
Тестирование программных средств Анимированные ребусы
Анимированные ребусы Основные понятия баз данных
Основные понятия баз данных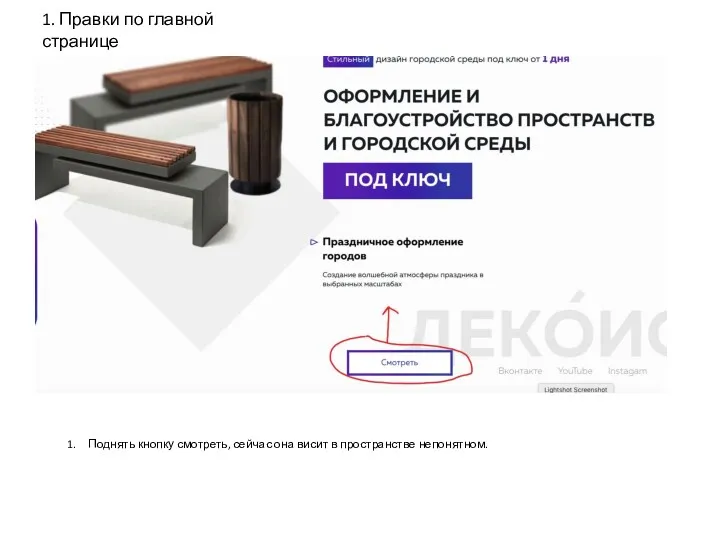 Корректировки по сайту
Корректировки по сайту Нормализация данных
Нормализация данных Подпрограммы
Подпрограммы Основы LINQ
Основы LINQ Материал к уроку
Материал к уроку Компьютерные презентации. Мультимедиа. Информатика. 7 класс
Компьютерные презентации. Мультимедиа. Информатика. 7 класс Основы информатики и программирования
Основы информатики и программирования Регулярные выражения. Библиотека regex
Регулярные выражения. Библиотека regex Предмет и задачи информатики. Свойства информации. Кодирование и измерение информации (Лекция 1)
Предмет и задачи информатики. Свойства информации. Кодирование и измерение информации (Лекция 1) Как мы храним большой социальный граф
Как мы храним большой социальный граф Лекція 18. Основи структурного програмування
Лекція 18. Основи структурного програмування Информационно-справочная система документооборота свадебного агентства
Информационно-справочная система документооборота свадебного агентства Начала программирования
Начала программирования Parts of the Computer
Parts of the Computer Механизмы реализации системы безопасности в UNIX (лекция 3)
Механизмы реализации системы безопасности в UNIX (лекция 3)