- Байесовские методы классификации. Анализ данных

Содержание
- 2. Байесовские методы. Байесовская классификация Классификация технологических методов ИАД [1]
- 3. Кросс-табуляция является простой формой анализа, широко используемой в генерации отчетов средствами систем оперативной аналитической обработки (OLAP).
- 4. Байесовская сеть (или байесова сеть, байесовская сеть доверия) - графическая вероятностная модель, представляющая собой множество переменных
- 5. Байесовская сеть - это полная модель для переменных и их отношений Следовательно, она может быть использована
- 6. Байесовская сеть позволяет получить ответы на следующие типы вероятностных запросов: 1) нахождение вероятности свидетельства, 2) определение
- 7. Ранее байесовская классификация использовалась для формализации знаний экспертов в экспертных системах. В настоящее время байесовская классификация
- 8. Байесовский метод опирается на теорему о том, что если плотности распределения классов известны, то алгоритм классификации,
- 9. Байесовские методы. Байесовская классификация
- 10. Байесовская классификация. Постановка задачи Рассмотрим обучающую выборку из ? объектов, каждый из которых принадлежит одному из
- 11. Байесовская классификация. Общая структура байесовского классификатора В основе классификатора лежит следующее правило. Классификатор вычисляет апостериорную вероятность
- 12. Аналитическое представление многомерной плотности вероятности известно только для нормального распределения. При этом многомерная нормальная плотность распределения
- 13. где μ – ?-компонентный вектор среднего значения, ? – ковариационная матрица размера ?×?, ? – знак
- 14. где ?? – ?-вектор-строка математических ожиданий значений признаков объектов класса ?, ?? – ?×?-матрица ковариаций векторов
- 15. в модели определяются зависимости между всеми переменными, это позволяет легко обрабатывать ситуации, в которых значения некоторых
- 16. Суть метода наивно-байесовской классификации В наивном байесовском классификаторе делается предположение о независимости признаков объекта. Если пренебречь
- 17. Наивно-байесовский подход имеет следующие недостатки: перемножать условные вероятности корректно только тогда, когда все входные переменные действительно
- 18. Одна из идей оптимизации наивно-байесовского классификатора состоит в том, чтобы, максимально используя обучающую выборку и гауссову
- 20. Скачать презентацию
![Байесовские методы. Байесовская классификация Классификация технологических методов ИАД [1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/334949/slide-1.jpg)
Байесовские методы. Байесовская классификация
Классификация технологических методов ИАД [1]
Байесовские методы. Байесовская классификация
Классификация технологических методов ИАД [1]

Кросс-табуляция является простой формой анализа, широко используемой в генерации отчетов средствами
Кросс-табуляция является простой формой анализа, широко используемой в генерации отчетов средствами

Байесовская сеть (или байесова сеть, байесовская сеть доверия) - графическая вероятностная
Байесовская сеть (или байесова сеть, байесовская сеть доверия) - графическая вероятностная

Байесовская сеть - это полная модель для переменных и их отношений
Следовательно,
Байесовская сеть - это полная модель для переменных и их отношений
Следовательно,

Байесовская сеть позволяет получить ответы на следующие типы вероятностных запросов:
1) нахождение
Байесовская сеть позволяет получить ответы на следующие типы вероятностных запросов:
1) нахождение

Ранее байесовская классификация использовалась для формализации знаний экспертов в экспертных системах.
В настоящее время
Ранее байесовская классификация использовалась для формализации знаний экспертов в экспертных системах.
В настоящее время

Байесовский метод опирается на теорему о том, что если плотности распределения
Байесовский метод опирается на теорему о том, что если плотности распределения

Байесовские методы. Байесовская классификация
Байесовские методы. Байесовская классификация

Байесовская классификация. Постановка задачи
Рассмотрим обучающую выборку из ? объектов, каждый из
Байесовская классификация. Постановка задачи
Рассмотрим обучающую выборку из ? объектов, каждый из

Байесовская классификация. Общая структура байесовского классификатора
В основе классификатора лежит следующее правило.
Байесовская классификация. Общая структура байесовского классификатора
В основе классификатора лежит следующее правило.

Аналитическое представление многомерной плотности вероятности известно только для нормального распределения.
При
Аналитическое представление многомерной плотности вероятности известно только для нормального распределения.
При

где μ – ?-компонентный вектор среднего значения,
? – ковариационная матрица
где μ – ?-компонентный вектор среднего значения,
? – ковариационная матрица

где ?? – ?-вектор-строка математических ожиданий значений признаков объектов класса ?,
где ?? – ?-вектор-строка математических ожиданий значений признаков объектов класса ?,

в модели определяются зависимости между всеми переменными, это позволяет легко обрабатывать
в модели определяются зависимости между всеми переменными, это позволяет легко обрабатывать

Суть метода наивно-байесовской классификации
В наивном байесовском классификаторе делается предположение о независимости
Суть метода наивно-байесовской классификации
В наивном байесовском классификаторе делается предположение о независимости

Наивно-байесовский подход имеет следующие недостатки:
перемножать условные вероятности корректно только тогда, когда
Наивно-байесовский подход имеет следующие недостатки:
перемножать условные вероятности корректно только тогда, когда

Одна из идей оптимизации наивно-байесовского классификатора состоит в том, чтобы, максимально
Одна из идей оптимизации наивно-байесовского классификатора состоит в том, чтобы, максимально
 Сервис Отвечает аудитор
Сервис Отвечает аудитор Типы данных и переменные
Типы данных и переменные Управление ремонтами и обслуживанием оборудования решение на основе 1С:Предприятие 8
Управление ремонтами и обслуживанием оборудования решение на основе 1С:Предприятие 8 Файловая система
Файловая система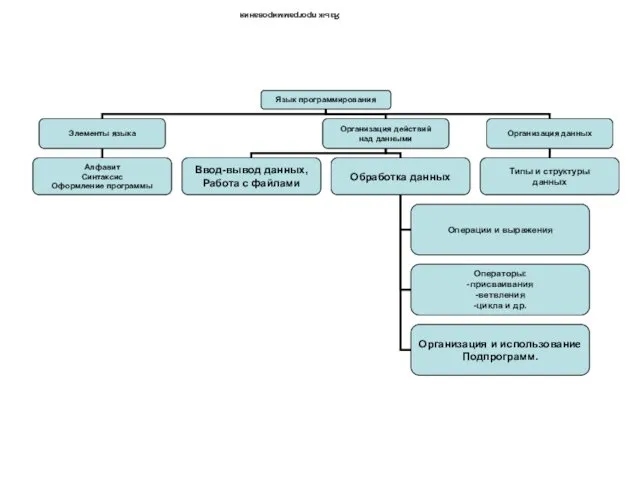 Язык программирования Pascal. Элементы языка
Язык программирования Pascal. Элементы языка Экспертные системы
Экспертные системы Арифметические операции в Паскале
Арифметические операции в Паскале Реализация виртуальных локальных сетей
Реализация виртуальных локальных сетей Электромагнитное излучение и его влияние на здоровье человека
Электромагнитное излучение и его влияние на здоровье человека Dressage Training Tips from Experts
Dressage Training Tips from Experts Трохи фактів про Excel…
Трохи фактів про Excel… Муниципальный этап Всероссийской олимпиады школьников по информатике
Муниципальный этап Всероссийской олимпиады школьников по информатике Работа с текстовыми объектами в текстовом редакторе
Работа с текстовыми объектами в текстовом редакторе Описание игры Dota2
Описание игры Dota2 Адресация в сетях TCP/IP
Адресация в сетях TCP/IP Строки. Лекция 4
Строки. Лекция 4 Приклад роботи з матрицями: створення матриці
Приклад роботи з матрицями: створення матриці Цвет и цветовые модели в компьютерной графике
Цвет и цветовые модели в компьютерной графике Представление нечисловой информации в компьютере.
Представление нечисловой информации в компьютере. Фреймворк JQuery
Фреймворк JQuery Введение в CSS. Лекция 2.1
Введение в CSS. Лекция 2.1 Построение диаграммы типа график в электронной таблице по значению функций
Построение диаграммы типа график в электронной таблице по значению функций Платформа Цифровой алфавит
Платформа Цифровой алфавит Объектные привилегии
Объектные привилегии История сети Интернет
История сети Интернет Знакомство с Интернетом
Знакомство с Интернетом Функциональное моделирование систем управления с использованием методологии IDEF0
Функциональное моделирование систем управления с использованием методологии IDEF0 Знакомство с Word
Знакомство с Word