- Базы данных. Введение в базы данных. Общая характеристика основных понятий

Содержание
- 2. Содержание Введение в базы данных. Общая характеристика основных понятий. Термины БД. Классификация БД. Ограничения целостности данных.
- 3. Зачем нужно изучать базы данных? Практически в каждом приложение реализована БД
- 4. 2) Почти в каждой вакансии упоминается SQL (Structured query language — «язык структурированных запросов»)
- 5. 3) Базы данных позволяют хранить большие объемы данных. 4) Возможность анализ накопленных данных.
- 6. Разработчик программного обеспечения. Аналитик данных (Data Analyst). Data Scientist. QA инженер (Quality Assurance обеспечение качества ).
- 7. данные; предметная область; бизнес ̶ правила. Основные понятия БД
- 8. Пример фрагмента предметной области «Муниципальная библиотека» UML (Unified Modeling Language) диаграмма вариантов использования Правило: по абонементу,
- 9. База данных (БД) (Database, BD) – это организованная совокупность данных о некоторой предметной области, предназначенная для
- 10. Надежное хранение данных. Быстрый поиск нужной информации. Многопользовательский доступ. Разграничение прав доступа. Доступ к базе данных
- 11. Информационная система Информационная система – это система, реализующая автоматизированный сбор, хранение, поиск, извлечение и модификацию данных
- 12. Классификация баз данных 1) По модели данных Модель данных – это метод (принцип) логической организации данных,
- 13. Иерархическая модель данных Иерархическая модель данных имеет форму дерева с дугами-связями и узлами-элементами данных.
- 14. Сетевая модель данных Сетевую модель данных можно рассматривать как расширенную версию иерархической модели. Основное различие между
- 15. Реляционная база данных – это набор простых таблиц (отношений, сущностей), между которыми установлены связи с помощью
- 16. Атомарные значения полей
- 17. Документно-ориентированная модель данных Реляционная модель данных
- 18. 2) по способу хранения данных Базы данных Централизованные (БД хранится на одном сервере) Распределенные (составные части
- 19. Базы данных Локальные (БД , СУБД и клиентские программы установлены на рабочей станции (PC)) Удаленные (сетевые)
- 20. Облачные платформы Облачные платформы предоставляют возможность разработки, выполнения приложений и хранения данных на серверах, расположенных в
- 21. Главные законы об информации и информационной безопасности 149-ФЗ Об информационной безопасности — устанавливает основные права и
- 22. Программа курса «Базы данных»
- 23. MS Access, MS SQL Server от компании Microsoft Corporation. Oracle, MySQL от компании Oracle Corporation. PostgreSQL
- 24. Основные элементы реляционной БД ID Отношение 1 2 3 Домен: ID Иванов Сидоров Синицина Домен: Surname
- 25. Ключи Первичный ключ (сокращенно РК - Primary Key) – это поле (или совокупность полей), значения которого
- 26. Простой, составной ключ Простой первичный ключ состоит из одного поля. Составной первичный ключ состоит из более
- 27. Ключи по способу задания Логический (естественный) первичный ключ – поле, данные в котором логически связанны с
- 28. Ключи Внешний ключ (сокращенно FK - Foreign Key) – поле (совокупность полей) таблицы, связанное с первичным
- 29. Ключи Потенциальный ключ (Candidate key) - простой или составной ключ, который уникально идентифицирует каждую запись таблицы.
- 30. Ограничения целостности данных Целостностью данных можно назвать механизм поддержания соответствия базы данных предметной области. Ограничения целостности
- 31. Задачи Какие поля в таб.1 и таб.2 могут быть первичными ключами? Определите названия ключей по типу
- 32. Задачи 3) Сколько строительных компаний в городе Москва? 4) Сколько строительных компаний в городе Уфа? 2)
- 33. Задачи 5) Определите какие материалы отправлены в каждый из городов? 6) Сколько единиц огнеупорных кирпичей отправлено
- 34. Виды связей между реляционными таблицами Виды связей между таблицами: Один к одному (1:1, 1−1). Один ко
- 35. Вид связи один к одному Связь один к одному означает, что одной записи в главной таблице
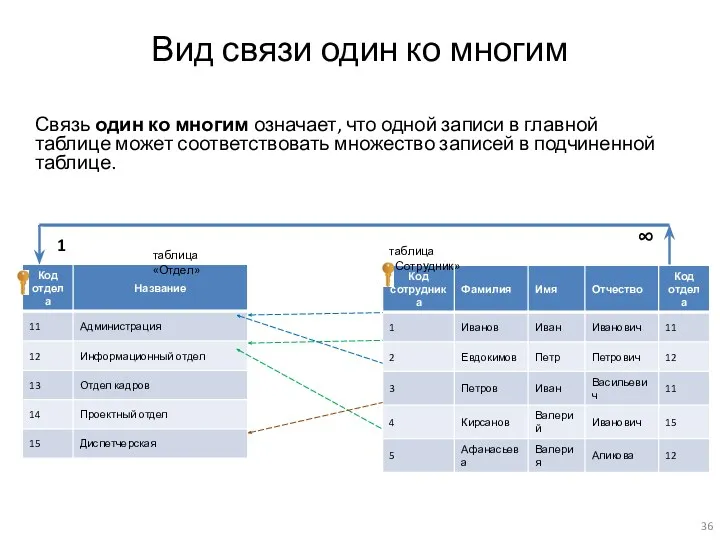
- 36. Вид связи один ко многим Связь один ко многим означает, что одной записи в главной таблице
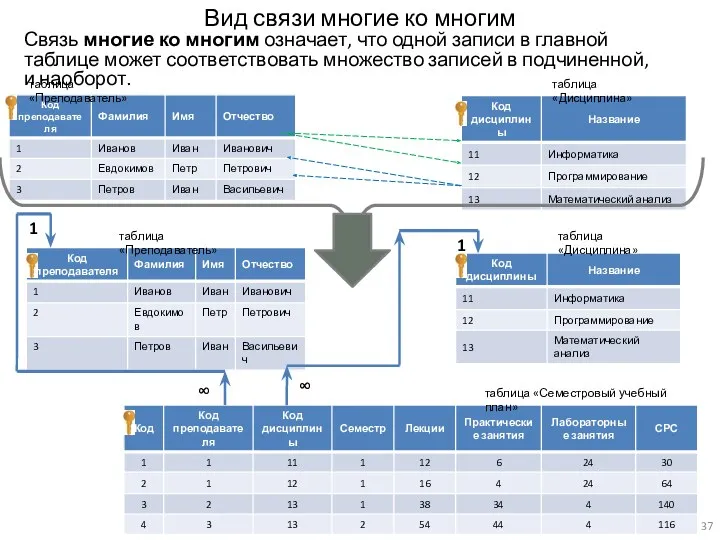
- 37. Вид связи многие ко многим Связь многие ко многим означает, что одной записи в главной таблице
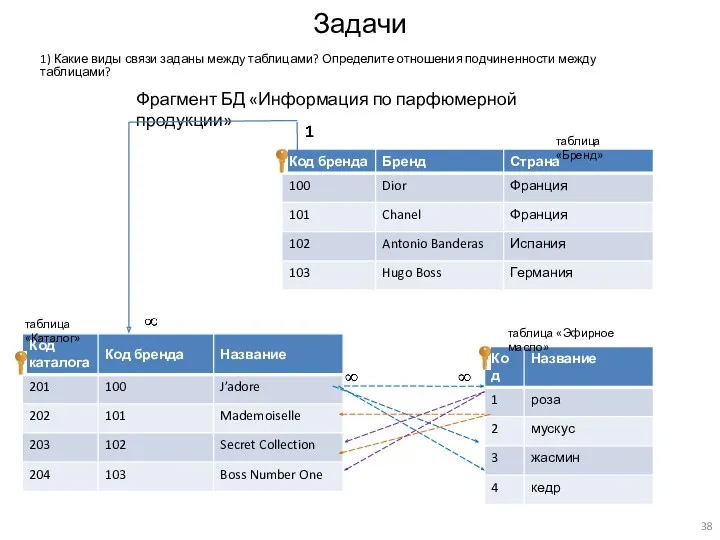
- 38. Задачи 1) Какие виды связи заданы между таблицами? Определите отношения подчиненности между таблицами? таблица «Каталог» таблица
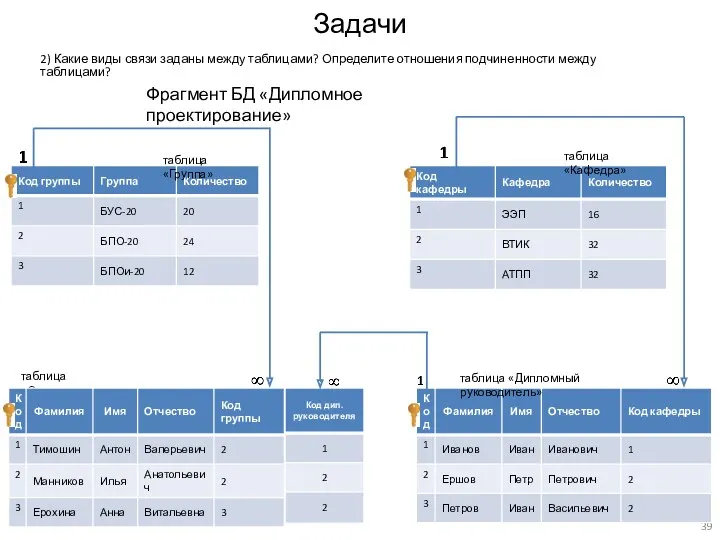
- 39. Задачи 2) Какие виды связи заданы между таблицами? Определите отношения подчиненности между таблицами? Фрагмент БД «Дипломное
- 40. Задачи 3) Какая из двух таблиц главная, какая подчинённая? Какой вид связи между таблицей 1 и
- 41. Поддержка целостности сущностей и целостности ссылок. Синтаксис : 1) PRIMARY KEY 2) FOREIGN KEY REFERENCES [
- 42. Поддержка целостности данных при использовании команд UPDATE и DELETE FOREIGN KEY () REFERENCES [[ ] [ON
- 43. Поддержка целостности данных при использовании команд UPDATE и DELETE FOREIGN KEY ( ) REFERENCES [[ ]
- 44. Поддержка целостности данных при использовании команд UPDATE и DELETE FOREIGN KEY ( ) REFERENCES [[ ]
- 45. Поддержка целостности данных при использовании команд UPDATE и DELETE FOREIGN KEY ( ) REFERENCES [[ ]
- 46. Язык SQL
- 47. Диалекты языка SQL (расширения SQL) Transact-SQL (или T-SQL) — СУБД MS SQL Server (Microsoft). Jet SQL
- 48. Команды
- 49. Команды языка определения данных (DDL - Data Definition Language)
- 50. Примеры применения команд DDL Создание таблицы «Плата за электроэнергию» CREATE TABLE Rent_for_light (Id INT PRIMARY KEY
- 51. Команды языка манипулирования данными (DML - Data Manipulation Language)
- 52. Примеры применения команд DML INSERT INTO Rent_for_light VALUES (‘Республика Башкортостан’, 1, 20, 0.1), (‘Республика Татарстан’, 1,
- 53. Синтаксис SELECT SELECT column_name1, column_name2, … FROM table_name WHERE condition поля для вывода таблица, данные которой
- 54. Транзакция Транзакция − это последовательность операций с данными, выполняющаяся как единое целое. Транзакции повышают надежность баз
- 55. Пример транзакции 1) UPDATE Bank_account SET Balance = Balance - 500 WHERE Number_account = 101 2)
- 56. 3) Isolation (изолированность). 1) Atomicity (атомарность). Транзакции и целостность баз данных Количество операций, входящих в транзакцию,
- 57. Команды языка управления транзакциями (TCL - Тгаnsасtiоn Соntrol Language)
- 58. База данных База данных Команда 1 Команда 2 COMMIT ROLLBACK Начальное состояние БД Состояние БД после
- 59. Команды языка управления данными (DCL - Data Control Language)
- 60. GRANT SELECT ON Student TO User2; REVOKE SELECT ON Student TO User2; DENY CREATE DATABASE, CREATE
- 61. Значение NULL Значение NULL - универсальное значение, не зависимое от типа данных поля. Данное значение свидетельствует
- 62. Использование значения NULL в условиях поиска IS NULL – предикат, применяется для выявления равенства значения некоторого
- 63. Оператор SQL состоит из: зарезервированных слов; пользовательских названий. Пользовательские названия могут быть идентификаторами или именами различных
- 64. Подзапросы SQL (вложенные SQL запросы) Пример структуры вложенного запроса: SELECT FROM WHERE [поле]|[значение] оператор_сравнения|логический_оператор (SELECT FROM
- 65. Синтаксис оператора SELECT (продолжение) SELECT [ALL | DISTINCT | TOP [PERCENT] ] FROM [WHERE ] [GROUP
- 66. Операторы: 1. Арифметические операторы. 2. Операторы присваивания. 3. Операторы сравнения. 4. Логические операторы. 5. Унарные операторы.
- 67. Арифметические операторы Арифметические операторы выполняют математические операции над двумя значениями числовых типов данных или символьных. Результатом
- 68. Арифметические операторы. Сложение Select Surname, Name, Salary+1000 From Cooperator Select Surname, Name, Salary+ Increase From Cooperator
- 69. Операторы присваивания Оператор присваивания «=» присваивает значение переменной. В качестве оператора для присваивания псевдонимов таблицам или
- 70. Операторы сравнения Операторы сравнения проверяют равенство или неравенство двух выражений. Результатом операции является булево значение –
- 71. Операторы сравнения SELECT Surname AS [Фамилия сотрудника], Name AS [Имя сотрудника] FROM Cooperator WHERE Salary >3000
- 72. Побитовые операторы Побитовые операторы выполняют побитовые действия над двумя выражениями с любым типом данных, относящихся к
- 73. Побитовое И SELECT Value_a & Value_b AS Результат FROM Table1 0010 & 0011 = 0010 0100
- 74. Побитовое «исключающее ИЛИ» SELECT Value_a ^ Value_b AS Результат FROM Table1 0010 ^ 0011 = 0001
- 75. Логические операторы Логические операторы проверяют истину некоторого условия. Логические операторы возвращают булево значение TRUE или FALSE.
- 76. Оператор AND (И) Table. Cooperator Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата From
- 77. Оператор OR (ИЛИ) Table. Cooperator Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата, City
- 78. Оператор NOT (НЕ) Table. Cooperator Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата, City
- 79. Оператор IN Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата, City AS Город From
- 80. Оператор NOT IN Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата, City AS Город
- 81. Оператор LIKE Table. Cooperator Select Surname AS ‘Фамилия’, Name AS ‘Имя’, Salary AS ‘Зарплата’ From Cooperator
- 82. Оператор BETWEEN Оператор BETWEEN используется для проверки условия вхождения значения поля в заданный интервал, то есть
- 83. Оператор ANY (SOME) SELECT Surname, Name, Birthday FROM Student s WHERE Student_Id=ANY(SELECT Student_Id FROM Exam_mark e
- 84. Оператор ALL SELECT Surname, Name, Birthday FROM Student s WHERE 5=All(SELECT Mark FROM Exam_mark e WHERE
- 85. Оператор EXISTS SELECT Surname, Name FROM Student s WHERE EXISTS (SELECT * FROM Exam_mark e WHERE
- 86. Унарные операторы Унарные операторы выполняют операцию над одним выражением любого типа, относящимся к числу.
- 87. Примеры, унарные операторы SELECT -Value_a AS Результат FROM Table1 ~0010=1101 ~0100 =1011 SELECT ~Value_a AS Результат
- 88. Приоритет операторов 1. () – выражения в скобках. 2. +, -, ~ – унарные операторы. 3.
- 89. Задачи Какие данные будут получены в результате выполнения запросов? Какие операторы применялись в запросах? SELECT *
- 90. Агрегатные функции Общая структура запроса с агрегатной (или агрегатными) функциями и GROUP BY: SELECT [ ,]
- 91. Агрегатная функция SUM Table. Product Посчитать сколько всего продукции в магазине: SELECT SUM(Number) AS Сумма FROM
- 92. Агрегатная функция AVG Table. Product Вычислить среднею цену продукции в магазине: SELECT AVG(Price) AS ‘Средняя цена’
- 93. Агрегатные функции MAX, MIN Table. Product Вывести максимальную и минимальную цену по каждому наименованию продукции, а
- 94. Агрегатная функция COUNT Table. Product Посчитать количество различных наименований продукции: SELECT COUNT(DISTINCT Product_name) AS 'Количество наименований'
- 95. Многотабличные запросы Table Cooperator Table Department SELECT coop.Coop_id , coop.Surname, coop.Name, dep.Dept_id ,dep.Name FROM Cooperator coop,
- 96. Многотабличные запросы Table Cooperator Table Department SELECT coop.Surname, coop.Name, dep.Dept_id ,dep.Name FROM Cooperator coop, Department dep
- 97. Многотабличные запросы, оператор соединения JOIN Ключевое слово JOIN в SQL используется при построении запросов на выборку,
- 98. Оператор соединения INNER JOIN Table Cooperator Table Department SELECT coop.Coop_id , coop.Surname, coop.Name, dep. Dept_id ,dep.Name
- 99. Оператор соединения LEFT OUTER JOIN Table Cooperator Table Department SELECT coop.Coop_id , coop.Surname, coop.Name, dep.Dept_id ,dep.Name
- 100. Оператор соединения RIGHT OUTER JOIN Table Cooperator Table Department SELECT Coop_id , coop.Surname, coop.Name, dep.Dept_id ,dep.Name
- 101. Оператор соединения FULL OUTER JOIN Table Cooperator Table Department SELECT Coop_id , coop.Surname, coop.Name, dep.Dept_id ,dep.Name
- 102. Оператор соединения CROSS JOIN Table. Fabric Table. model_of_clothes Select * From Fabric CROSS JOIN Model_of_clothes Результат
- 103. Типы данных MS SQL Server Числовые типы данных: BIT: хранит значение 0 или 1. Фактически является
- 104. Типы данных MS SQL Server Типы данных, представляющие дату и время: DATE: ГГГГ-ММ-ДД. Хранит даты от
- 105. Типы данных MS SQL Server Строковые типы данных: CHAR: хранит строку длиной от 1 до 8
- 106. Типы данных MS SQL Server Бинарные типы данных: BINARY: хранит бинарные данные в виде последовательности от
- 107. Проектирование баз данных Основные задачи: 1) Сохранить необходимые данные о конкретной предметной области. 2) Получить данные
- 108. Проблемы, возникающие при проектировании БД Таблица «Сотрудник отдела» Нужно добавить новый отдел, а сотрудников пока не
- 109. Аномалии в таблицах БД При неправильно спроектированной схеме реляционной БД могут возникнуть аномалии при выполнении операций
- 110. таблица «Сотрудник отдела» Декомпозиция Решение проблемы таблица «Сотрудник» таблица «Отдел»
- 111. Проектирование баз данных Нормализация – это процесс преобразования отношения в состояние, обеспечивающее лучшие условия выборки, добавления,
- 112. Проектирование баз данных Появляется избыточность данных => что можно предпринять? (см. следующий слайд) таблица «Учебный план
- 113. таблица «Учебный план ВУЗа» Декомпозиция таблица «Дисциплина» таблица «Учебный план ВУЗа» Вопросы: 1) Сколько таблиц будет
- 114. Нормальные формы Эдгар Кодд. Нормальные формы: Первая нормальная форма (1NF, 1НФ). Вторая нормальная форма (2NF, 2НФ).
- 115. Первая нормальная форма (1НФ) Определение. Отношение находится в 1НФ тогда и только тогда, когда все его
- 116. Вторая нормальная форма (2НФ) Определение. Отношение находится во 2НФ тогда и только тогда, когда соответствует 1НФ
- 117. Третья нормальная форма (3НФ) Определение. Отношение находится в 3НФ тогда и только тогда, когда соответствует 2
- 118. Таблица «Менеджер» Таблица «Банка» Таблица «Клиент банка» Таблица «Банковский счет» таблица «Информация о счете»
- 119. Таблица «Грузовые морские перевозки» 1 НФ Задание: Определите название ключа по типу и по способу задания.
- 120. Таблица «Грузовые морские перевозки» 2 НФ Таблица «Информация о судне» таблица «Информация о рейсе» Задание: 1)
- 121. Таблица «Морские перевозки» 3 НФ таблица «Информация о рейсе» таблица «Капитан»
- 122. Результат приведения исходной таблицы к 3НФ Таблица «Информация о судне» таблица «Информация о рейсе» таблица «Капитан»
- 123. Проектирование баз данных Проектирование базы данных осуществляется в три этапа: 1) концептуальное проектирование (инфологическое); 2) логическое
- 124. Концептуальное (инфологическое) проектирование Цель – построение независимой от СУБД информационной структуры путем объединения требований пользователей. Задачи:
- 125. Концептуальное проектирование, пример, предметная область «Успеваемость студентов». Уточнение
- 126. Концептуальное проектирование Примеры значений для заполнения. Программа обучения: бакалавриат, магистратура, специалитет, аспирантура Форма обучения: очная, заочная,
- 127. Логическое (даталогическое) проектирование Цель – создание схемы базы данных на основе конкретной модели данных. Задачи: Выбор
- 128. Логическое проектирование
- 129. Физическое проектирование Цель – создание схемы базы данных для конкретной СУБД. Задачи: Проектирование таблиц базы данных
- 130. СХЕМА БАЗЫ ДАННЫХ Схема данных – графическое отображение логической структуры базы данных в СУБД.
- 131. Представления/VIEW в SQL (Виртуальные таблицы) Представления/VIEW или виртуальная таблица – это поименованная таблица, получаемая в результате
- 132. Представления/VIEW в SQL (Виртуальные таблицы) Представления позволяют Ограничить число столбцов Ограничить число строк Выводить дополнительные столбцы
- 133. Синтаксис: [CREATE|ALTER ] VIEW [(column_list)] [WITH {ENCRYPTION | SCHEMABINDING| VIEW_METADATA}] AS SELECT FROM [WHERE condition] [WITH
- 134. Представления/VIEW (Виртуальные таблицы) Например, нужно создать представление для просмотра информации о студентах из города Уфа: CREATE
- 135. Представления таблиц и представления столбцов CREATE VIEW New_tab1_stud AS SELECT * FROM Student Вызов представления: SELECT
- 136. Представление с вложенным запросом, представление с группировкой Задание: создайте представление, которое представит информацию по сотрудникам, работающим
- 137. Представления c командами модификации Создание представления Student_view: CREATE VIEW Student_view AS SELECT Surname, Name, City, Birthday
- 138. Применение команд модификации к представлениям, скрывающим поля Создадим таблицу «Издательство»: CREATE TABLE Publishing_house (Id_publ INT PRIMARY
- 139. Представления/VIEW, скрывающие строки и команды модификации Создание представления Publishing_house_view_more_than_5 : CREATE VIEW Publishing_house_view_more_than_5 AS SELECT Name_publ,
- 140. Агрегатные функции в представлениях Представление для просмотра успеваемости: CREATE VIEW Total_day AS SELECT Surname, Name, COUNT(Subj_id)
- 141. Представление для просмотра сколько сотрудников однофамильцев есть в каждом отделе: CREATE VIEW Сount_сooperator_homonym AS SELECT d.Name
- 142. Модифицируемые и немодифицируемые представления Модифицируемое представление — это представление, относительно которого можно применить команды модификации UPDATE/INSERT/DELETE.
- 143. Пример, модифицируемого представления с оператором соединения JOIN Создадим таблицу «Книга» для хранения данных о книге: CREATE
- 144. Команда обновления данных выполнится: UPDATE Publishing_house_view SET Name_book='Молекулярная физика' WHERE Id_publ =3 Вызов представления: Select* From
- 145. Команды изменения описания представления, удаления представления ALTER VIEW описание представления DROP VIEW Например, добавим условие в
- 146. Оператор CASE позволяет осуществить проверку условий и возвратить в зависимости от выполнения того или иного условия
- 147. Пример с условным оператором CASE Премировать сотрудников: IT-отдела - 50% от ЗП; Бухгалтерии - 40% от
- 148. Пример с условным оператором CASE Вывести средние оценки по студентам и расшифровать значения оценок SELECT Surname,
- 149. Посчитать сколько на каждом курсе оценок со значениями 2, 3, 4, 5 SELECT Surname, Name, Kurse
- 150. Задать имя и тип переменной в Transact-SQL можно с помощью оператора DECLARE. Синтаксис: DECLARE @local_variable data_type
- 151. Оператор PRINT возвращает сообщение. Синтаксис: PRINT Пример 1: PRINT 'Вывод сообщения' Пример 2: DECLARE @Surname VARCHAR(20),
- 152. Условный оператор IF...ELSE Конструкция IF...ELSE используется для наложения условий, определяющих, какие операторы T-SQL нужно выполнить. Синтаксис:
- 153. Цикл в языке Transact-SQL Синтаксис: WHILE Boolean_expression {sql_statement|statement_block} [ BREAK] {sql_statement|statement_block} [CONTINUE} END Пример, представить, какой
- 154. Хранимые процедуры в Transact−SQL Хранимая процедура (Stored Procedure) – это именованный набор команд языка Transact-SQL, хранящийся
- 155. Хранимые процедуры в Transact−SQL Типы хранимых процедур Пользовательские процедуры Временные процедуры Системные процедуры хранятся в базе
- 156. Синтаксис создания (изменения) процедуры: {CREATE|ALTER} PROCEDURE|PROC procedure_name [; number] [{@name_paramet data_type} [VARYING] [=DEFAULT][OUTPUT]][,...n] [WITH {RECOMPILE|ENCRYPTION|RECOMPILE, ENCRYPTION}]
- 157. Синтаксис удаления процедуры: DROP PROCEDURE {имя_процедуры} [,...n] Хранимые процедуры в Transact−SQL Синтаксис вызова: [EXECUTE|EXEC] имя_процедуры [;номер]
- 158. Пример создания процедуры без параметров Создадим процедуру для получения названий экзаменов и оценок, полученных студентом Ивановым:
- 159. Пример создания процедуры для вычисления значений поля Cost_product Table. Product Table. Ingredient CREATE PROCEDURE Cost_product AS
- 160. Пример создания процедуры с входным параметром Создать процедуру для увеличения размера стипендии у студентов со средней
- 161. Пример создания процедуры с входными параметрами Создать процедуру для выдачи списка студентов, получивших оценку, значение которой
- 162. Создать процедуру для подсчета числа студентов, сдававших экзамен по дисциплине у преподавателя фамилия и имя которого
- 163. Получение информации о процедурах Системные процедуры: 1) sp_help Синтаксис: sp_help proc1 2) sp_helptext Синтаксис: sp_helptext proc1
- 164. Пользовательские функции (User Defined Functions, UDF) в Transact-SQL CREATE PROCEDURE Count_student_proc @count SMALLINT OUTPUT AS SELECT
- 165. Пользовательские функции (User defined functions, UDF) Transact-SQL Поддерживаются следующие типы пользовательских функций: 1) Скалярная функция (Scalar)
- 166. Скалярные функции (Scalar) в Transact-SQL {CREATE | ALTER} FUNCTION [владелец.] имя_функции ([{@имя_параметра скалярный_тип_данных [=DEFAULT]}[,...n]]) RETURNS скалярный_тип_данных
- 167. Скалярные функции (Scalar) в Transact-SQL Например, создание скалярной функции для подсчета количества студентов, у которых дата
- 168. Табличные функции (Inline)в Transact-SQL {CREATE | ALTER } FUNCTION [владелец.] имя_функции ([{ @имя_параметра скалярный_тип_данных [=DEFAULT]}[,...n]]) RETURNS
- 169. Табличные функции (Inline)в Transact-SQL Пример, функции табличного типа для определения двух дисциплин с наибольшими оценками. CREATE
- 170. Многооператорные функции (Multi-statement)в Transact-SQL {CREATE | ALTER }FUNCTION [владелец.] имя_функции ([{ @имя_параметра скалярый_тип_данных [=DEFAULT]}[,...n]]) RETURNS @имя_параметра
- 171. Многооператорные функции (Multi-statement)в Transact-SQL CREATE FUNCTION [dbo].[get_FIO_student]() RETURNS @fio_sudent TABLE (ФИО varchar(50), [Дата рождения] DATE) AS
- 172. Удаление пользовательской функции в Transact−SQL Синтаксис удаления функции: DROP FUNCTION {[владелец.] имя_функции} [,...n]]
- 173. Пример создания табличной функции Создание функции для расчета количества различных оценок и определения их среднего значения
- 174. Пример вызова функции из хранимой процедуры Создание процедуры для определения кандидатов на получение красного диплома. Название
- 175. Пример вызова функции из хранимой процедуры Создание процедуры для увеличения стипендии тем студентом у которых ср.оценка
- 176. Транзакции и целостность баз данных
- 177. Пример CREATE TABLE Bank_account (Id INT PRIMARY KEY IDENTITY(1,1), Number_account decimal(10,0), Balance float) INSERT INTO Bank_account
- 178. 3) Isolation (изолированность). Результаты транзакции не должны быть видены другим транзакциям, пока она не завершиться. 4)
- 179. Модели одновременного конкурентного доступа Пессимистичная модель Оптимистичная модель В многопользовательской среде предусмотрены две модели обновления данных
- 180. Уровни изоляции транзакций Уровни изоляции транзакций — это мера степени успешной изоляции транзакций данных от возможности
- 181. Уровень изоляции READ UNCOMMITTED Клиент 1 выполняет транзакцию: BEGIN TRANSACTION UPDATE Bank_account SET Balance = Balance
- 182. Владелец счета 102 решив, что средств достаточно пытается совершить транзакцию для снятия наличных в размере 2000,
- 183. Уровень изоляции READ COMMITTED Владелец счета 102 не может узнать свой баланс, пока в предыдущей транзакции
- 184. Уровень изоляции READ COMMITTED. Проблема: неповторяющееся чтение (non-repeatable read) SET TRANSACTION ISOLATION LEVEL READ COMMITTED
- 185. Уровень изоляции REPEATABLE READ SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
- 186. Уровень изоляции REPEATABLE READ. Проблема: фантомное чтение (phantom reads) SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
- 187. Уровень изоляции SERIALIZABLE SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
- 188. Проблемы одновременного доступа При одновременном изменении данных различными пользователями возможно возникновение следующих проблем: Скорость Надежность
- 189. Уровень изоляции SNAPSHOT Разрешение на уровни СУБД: ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON SET TRANSACTION ISOLATION
- 190. Уровень изоляции SNAPSHOT Разрешение на уровни СУБД: ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON SET TRANSACTION ISOLATION
- 191. Уровень изоляции SNAPSHOT Разрешение на уровни СУБД: ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON SET TRANSACTION ISOLATION
- 192. Журнал транзакций (Write-Ahead Logging (WAL)) Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого
- 193. Триггеры (Triggers) в Transact−SQL Триггер –это специальный вид хранимой процедуры, который выполняется автоматически при наступлении определенного
- 194. Триггеры (Triggers) в Transact−SQL События: INSERT – определяет действия, которые будут выполняться после добавления новой записи
- 195. Синтаксис создания/изменения триггера Основной формат команды: {CREATE | ALTER} TRIGGER [имя_триггера] ON имя_таблицы {FOR | AFTER
- 196. Триггеры и виртуальные таблицы deleted и inserted Таблицы deleted и inserted создаются автоматически. Таблицы deleted и
- 197. Синтаксис удаления триггера DROP TRIGGER {имя_триггера} [,...n].
- 198. Реализовать ограничение на вводимое значение Создание триггера проверки возраста студента при добавления записи в таблицу Student.
- 199. Триггер сохраняющий дату последнего изменения записи в таблице Student CREATE TRIGGER Update_time_in_the_column ON Student AFTER UPDATE
- 200. Триггер запрещающий изменение значения поля Mark и Exam_Date RAISERROR – системная функция, позволяющая создавать сообщение об
- 201. Триггер, не допускающий добавление более трех записей о результатах сдачи по одной и той же дисциплине
- 202. Триггер перемещает удаленную запись из таблицы Student в архивную таблицу Archive_delete CREATE TRIGGER Insert_in_table_Archive_delete ON Student
- 203. Индексы Индекс (Index)- это объект базы данных, создаваемый для повышения производительности выборки данных. Индекс создается для
- 204. Структура сбалансированного B дерева На примере таблицы «Студент» SELECT * FROM Student WHERE Id_student = 71
- 205. Способы задания индекса 1) Автоматическое создание индекса при добавлении ограничения первичного ключа PRIMARY KEY. Например, CREATE
- 206. Создание индексов в MS SQL Server Команда создания индекса для таблицы CREATE INDEX имеет следующий синтаксис:
- 207. Увидеть индексы в таблице EXECUTE sp_helpindex name_table Пример, EXECUTE sp_helpindex Student SELECT * FROM dbo.Student
- 208. 2) Некластеризованный индекс (Nonclustered index). При определении некластеризованного индекса в таблице (представлении), физическая структура данных не
- 209. Пример, работа кластеризованного индекс
- 210. Ключевые различия между кластеризованными и неклстеризованными индексами
- 211. Результаты тестов кластеризованного и некластеризованного индексов на объем занимаемого пространства и производительность Созданы две таблицы testtable
- 212. Результаты тестов кластеризованного и некластеризованного индексов на объем занимаемого пространства и производительность Этап 3. Из таблиц
- 213. Запрос -> Оптимизатор запросов -> План выполнения запроса Чтобы проанализировать производительность запроса и улучшить ее, необходимо
- 214. Оптимизация БД и СУБД Основных рекомендации по оптимизации БД и СУБД: перестройка/реорганизация индексов; очистка процедурного кэша;
- 215. Статистика Системная процедура для обновления статистики: sp_updatestats Команда обновления статистики для определенной таблицы: UPDATE STATISTICS название_таблицы
- 216. Перестройка индекса/реорганизация индекса Команды в SQL Server для борьбы с фрагментацией индексов: ALTER INDEX REBUILD /
- 217. Очистка кэш плана Синтаксис для SQL Server: DBCC FREEPROCCACHE Подавление вывода всех регулярных информационных сообщений: DBCC
- 218. Оптимизация структуры таблиц Рекомендации: При создании таблиц выбирать выбирайте самый маленький из допустимых типов данных. Выбирать
- 219. Оптимизация запросов. Как найти проблемные запросы? Activity Monitor – это утилита, позволяющая оценивать активность пользователей приложения
- 220. Как найти проблемные запросы? (SET STATISTICS IO, SET STATISTICS TIME) Инструкция позволяет получить информацию о времени
- 221. Оптимизация запросов Рекомендации: Кроме тех случаев, когда индекс создается автоматически, индексы можно добавить к полям, которые
- 222. Индексы для ускорения поиска Кроме тех случаев, когда индекс создается автоматически, индексы можно добавить к полям,
- 223. Индексы для ускорения поиска (покрывающий индекс)
- 224. Не коррелирующий подзапрос Обычно не коррелирующие подзапросы применяются в запросах, в которых значение определённого столбца сравнивается
- 225. Коррелирующий подзапрос Коррелирующий подзапрос содержит ссылку на таблицу, которая была объявлена во внешнем запросе.
- 226. Оператор JOIN (выборка из всех столбцов)
- 227. Оператор JOIN (выборка данных не из всех столбцов таблиц) Выборка данных из определенного количества столбов быстрее
- 228. Поиск по каждому индексному полю отдельно Если оба поля выборки имеют не кластеризованные индексы
- 229. Зачем нужна оптимизация запросов? Запросы — это критически важный компонент для повышения общей производительности базы данных.
- 230. Рекомендации для увеличения производительности: Для увеличения производительности, то есть для быстрого выполнения запросов, следует помнить некоторые
- 231. Оптимизация запросов SELECT Не читайте больше данных, чем надо. Не используйте * Не возвращайте клиенту большее
- 232. Корректно используйте JOIN Если Вы имеете две или более таблиц, которые часто соединяются, тогда столбцы, используемые
- 233. Оптимизация WHERE в запросе SELECT Если where состоит из условий, объединенных AND, они должны располагаться в
- 234. Советы по оптимизации хранимых процедур и SQL пакетов 1) Для обработки данных используйте хранимые SQL процедуры.
- 235. Рекомендации для увеличения производительности: временные таблицы для больших таблиц, табличные переменные - для малых (меньше 1000).
- 236. Обобщенные табличные выражения Кроме временных таблиц MS SQL Server позволяет создавать обобщенные табличные выражения (common table
- 237. Лучшие кандидаты на установку индекса Это поля, по которым идет JOIN Поля связи, участвующие в подзапросах
- 238. SQL инъекция (SQL injection - SQLi) SQL инъекция – это уязвимость веб-безопасности, которая позволяет злоумышленнику вмешиваться
- 239. Проблемы, вызванные SQL Инъекцией: Утечка данных: Злоумышленники могут получить доступ к конфиденциальным данным, таким как пароли,
- 240. Возможные SQL инъекции (SQL внедрения) Наиболее простые: 1. Добавление к WHERE дополнительное условие, которое заведомо вернет
- 241. Способы обнаружения SQL инъекции Существует несколько способов обнаружения SQL инъекций: Использование специализированных инструментов. Существуют различные инструменты,
- 242. Возможные решения: Использование подготовленных запросов: используйте параметризованные запросы, чтобы передавать данные в базу данных, вместо конкатенации
- 243. Службы Microsoft SQL Server
- 244. Database Engine Database Engine является ядром системы управления реляционной БД. Может быть установлено несколько экземпляров службы
- 245. Системные базы данных
- 246. Утилиты Microsoft SQL Server: SQL Server Management Studio. SQL Server Books Online. SQLCMD Microsoft. SQL Configuration
- 247. Система управления базами данных Основные функции СУБД: управление данными во внешней памяти (на дисках); управление данными
- 248. Обычно современная СУБД содержит следующие компоненты: ядро, которое отвечает за управление данными во внешней и оперативной
- 249. Реляционная алгебра Реляциционная алгебра состоит из операций над множествами (атрибутами и кортежами). Операции реляционной алгебры также
- 250. Операция реляционной алгебры: проекция Операция проекции (унарная операция) выделяет атрибуты только из указанных доменов. πa1,…,an(R) где
- 251. Операция реляционной алгебры: объединение (union) Операция объединения над двумя отношениями, создает новое отношение, состоящее из всех
- 252. Операция реляционной алгебры: выборка (селекция) (selection) Операция выборки производится над кортежами одного отношения (унарная операция). Результат
- 253. Операция реляционной алгебры: пересечение (intersection) Операция пересечения над двумя отношениями, создает новое отношение, состоящее из кортежей,
- 254. Операция реляционной алгебры: разность Операция разность над двумя отношениями создает новое отношение, состоящее из кортежей, принадлежащих
- 255. Операция реляционной алгебры: произведение (декартовое произведение) (сartesian product) Table Cooperator Table Department Эквивалентный SQL-запрос: SELECT Coop_id,
- 256. Операция реляционной алгебры: соединение (join) Операция соединения над двумя отношениями создает новое отношение, состоящее из всех
- 257. Операция реляционной алгебры: деление (division) Операция деления над двумя отношениями создает новое отношение, состоящее из всех
- 258. Термин NoSQL обозначает нереляционные базы данных, которые хранят данные в формате, отличном от реляционных таблиц. Термин
- 259. Модель данных «Ключ-значение» Большинство БД поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично
- 260. Документно-ориентированная модель данных Возможно реализовать большую вложенность и сложность структуры данных, чем в БД «ключ-значение» (например,
- 261. Колоночная модель данных Основная идея колоночной модели данных — это хранение данных не по строкам, как
- 262. Графовая модель данных Графовая модель данных основана на узлах и рёбрах, представляющих взаимосвязанные данные (например, отношения
- 263. Основные черты
- 264. Теорема САР (или теорема Брюера)
- 265. Примеры NoSQL СУБД Документно-ориентированные: CouchDB (Couchbase), MongoDB (MongoDB). Колоночные: Cassandra (Apache Software Foundation), ClickHouse (Яндекс). Графовые:
- 267. Скачать презентацию

Содержание
Введение в базы данных. Общая характеристика основных понятий.
Термины БД.
Классификация БД.
Ограничения целостности
Содержание
Введение в базы данных. Общая характеристика основных понятий.
Термины БД.
Классификация БД.
Ограничения целостности
Зачем нужно изучать базы данных?
Практически в каждом приложение реализована БД
Зачем нужно изучать базы данных?
Практически в каждом приложение реализована БД
2) Почти в каждой вакансии упоминается SQL (Structured query language —
2) Почти в каждой вакансии упоминается SQL (Structured query language —
3) Базы данных позволяют хранить большие объемы данных.
4) Возможность анализ накопленных
3) Базы данных позволяют хранить большие объемы данных.
4) Возможность анализ накопленных
Разработчик программного обеспечения.
Аналитик данных (Data Analyst).
Data Scientist.
QA инженер (Quality Assurance обеспечение
Разработчик программного обеспечения.
Аналитик данных (Data Analyst).
Data Scientist.
QA инженер (Quality Assurance обеспечение
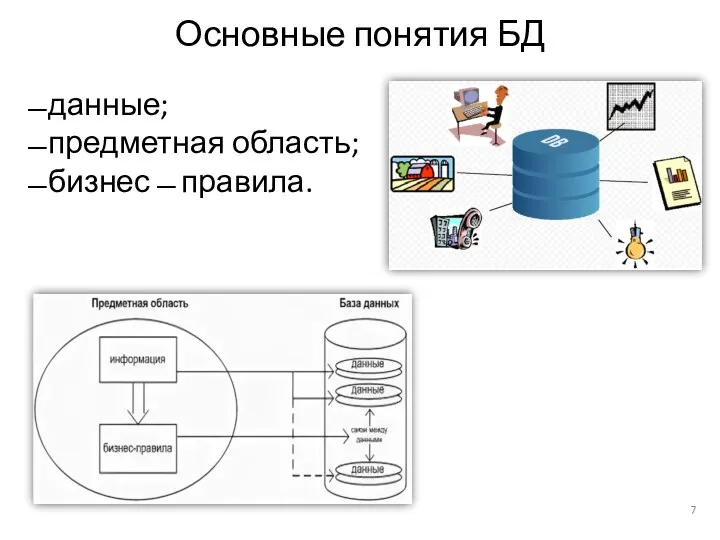
данные;
предметная область;
бизнес ̶ правила.
Основные понятия БД
данные;
предметная область;
бизнес ̶ правила.
Основные понятия БД
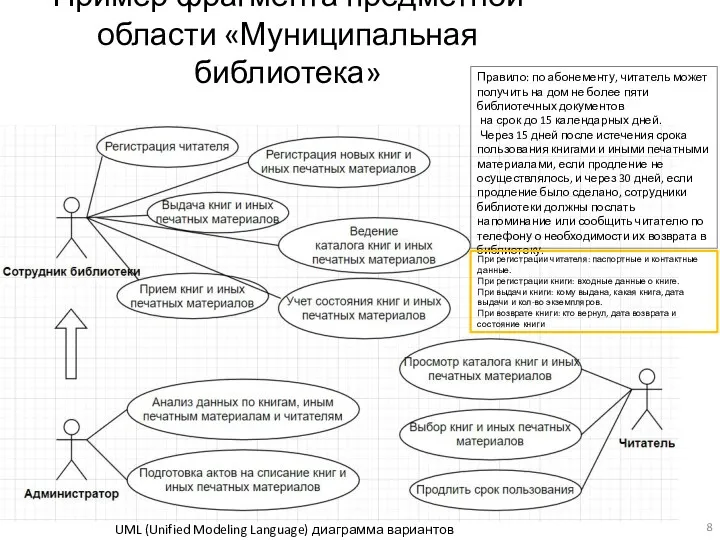
Пример фрагмента предметной области «Муниципальная библиотека»
UML (Unified Modeling Language) диаграмма вариантов
Пример фрагмента предметной области «Муниципальная библиотека»
UML (Unified Modeling Language) диаграмма вариантов
База данных (БД) (Database, BD) – это организованная совокупность данных о
База данных (БД) (Database, BD) – это организованная совокупность данных о

Надежное хранение данных.
Быстрый поиск нужной информации.
Многопользовательский доступ.
Разграничение прав
Надежное хранение данных.
Быстрый поиск нужной информации.
Многопользовательский доступ.
Разграничение прав
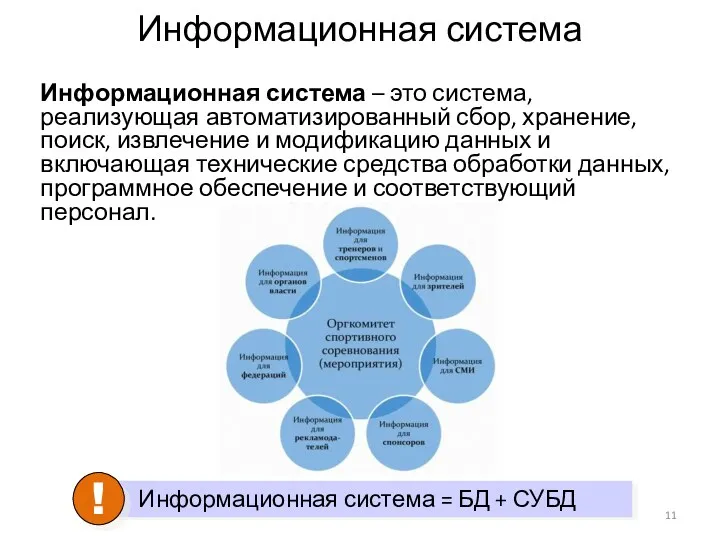
Информационная система
Информационная система – это система, реализующая автоматизированный сбор, хранение,
Информационная система
Информационная система – это система, реализующая автоматизированный сбор, хранение,
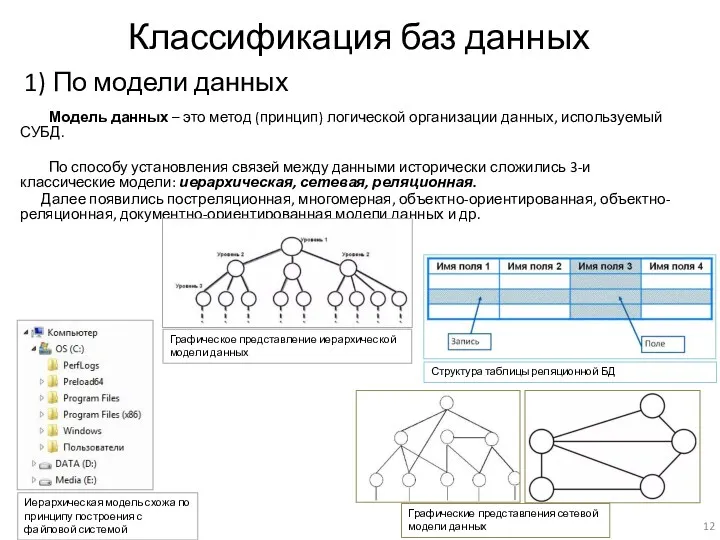
Классификация баз данных
1) По модели данных
Модель данных – это метод (принцип)
Классификация баз данных
1) По модели данных
Модель данных – это метод (принцип)
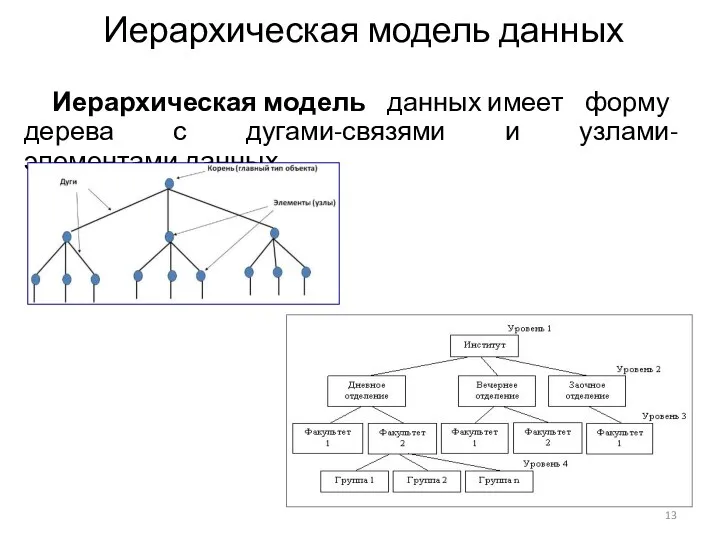
Иерархическая модель данных
Иерархическая модель данных имеет форму дерева с дугами-связями и узлами-элементами данных.
Иерархическая модель данных
Иерархическая модель данных имеет форму дерева с дугами-связями и узлами-элементами данных.
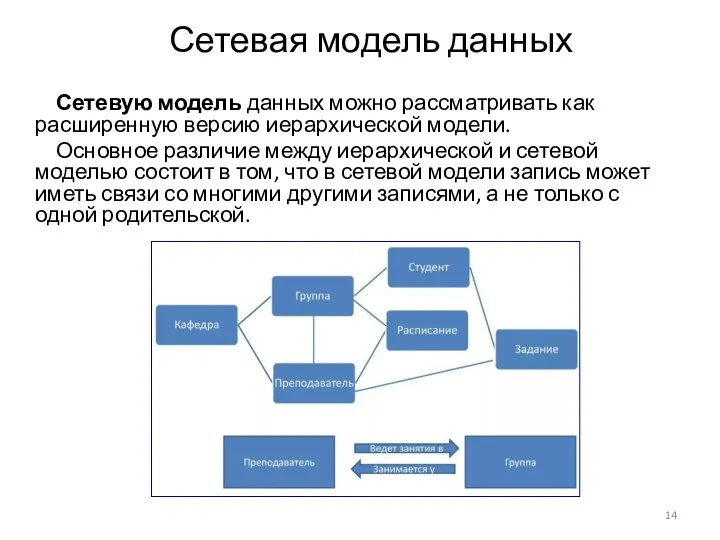
Сетевая модель данных
Сетевую модель данных можно рассматривать как расширенную версию иерархической
Сетевая модель данных
Сетевую модель данных можно рассматривать как расширенную версию иерархической
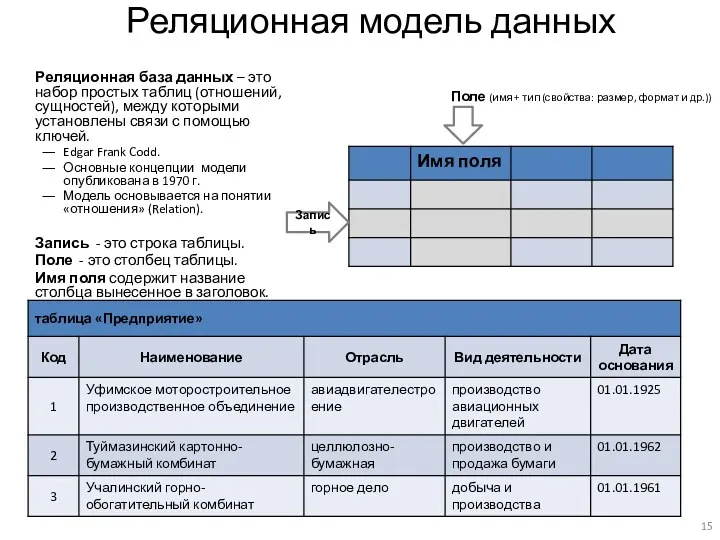
Реляционная база данных – это набор простых таблиц (отношений, сущностей), между
Реляционная база данных – это набор простых таблиц (отношений, сущностей), между
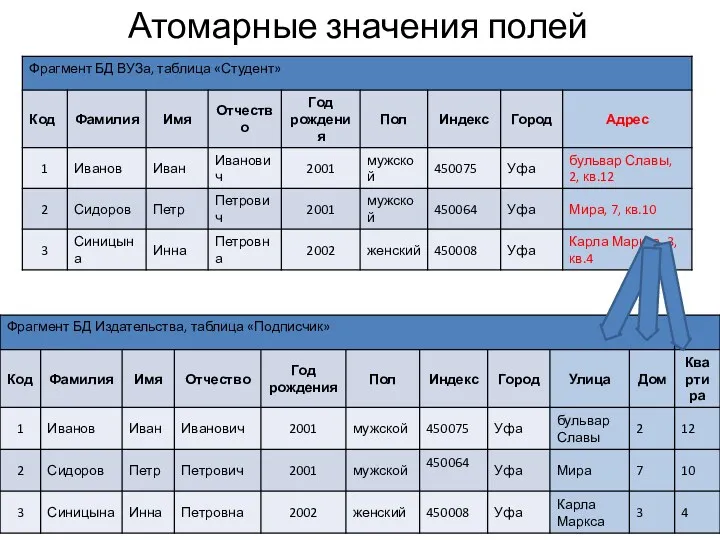
Атомарные значения полей
Атомарные значения полей
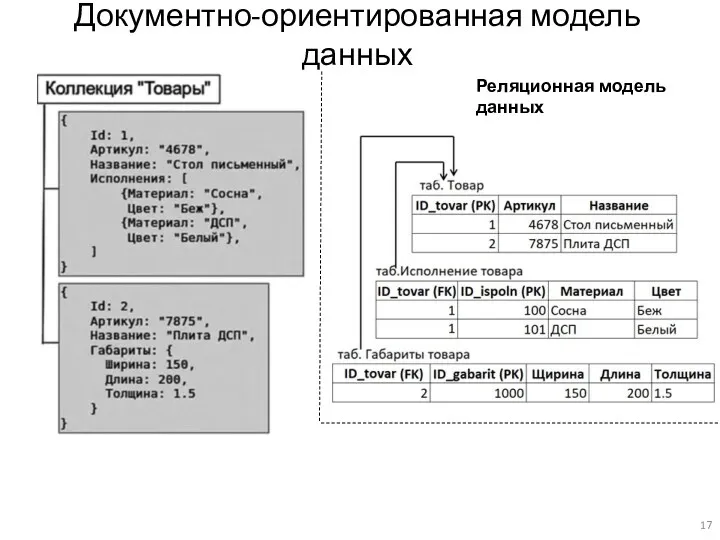
Документно-ориентированная модель данных
Реляционная модель данных
Документно-ориентированная модель данных
Реляционная модель данных
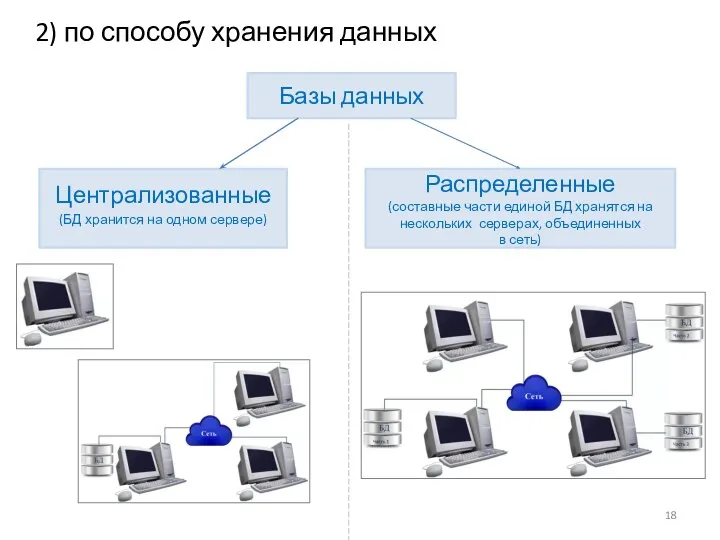
2) по способу хранения данных
Базы данных
Централизованные
(БД хранится на одном сервере)
Распределенные
2) по способу хранения данных
Базы данных
Централизованные
(БД хранится на одном сервере)
Распределенные
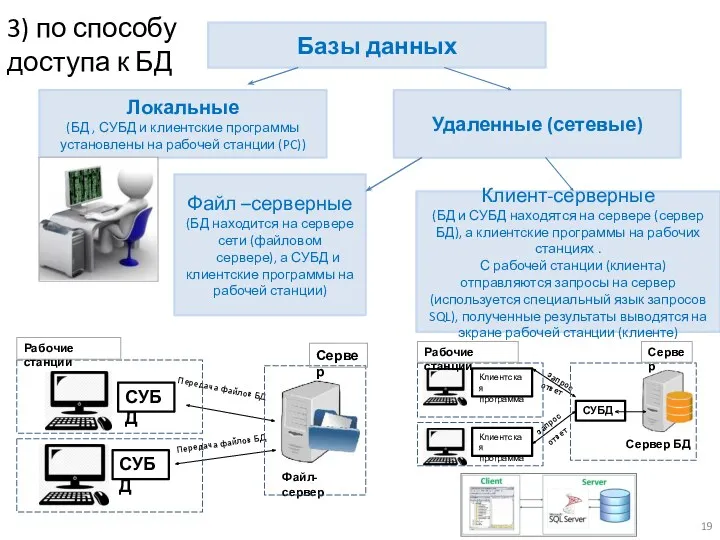
Базы данных
Локальные
(БД , СУБД и клиентские программы установлены на рабочей станции
Базы данных
Локальные
(БД , СУБД и клиентские программы установлены на рабочей станции
Облачные платформы
Облачные платформы предоставляют возможность разработки, выполнения приложений и хранения данных
Облачные платформы
Облачные платформы предоставляют возможность разработки, выполнения приложений и хранения данных

Главные законы об информации и информационной безопасности
149-ФЗ Об информационной безопасности —
Главные законы об информации и информационной безопасности
149-ФЗ Об информационной безопасности —

Программа курса «Базы данных»
Программа курса «Базы данных»

MS Access, MS SQL Server от компании Microsoft Corporation.
Oracle, MySQL от
MS Access, MS SQL Server от компании Microsoft Corporation.
Oracle, MySQL от
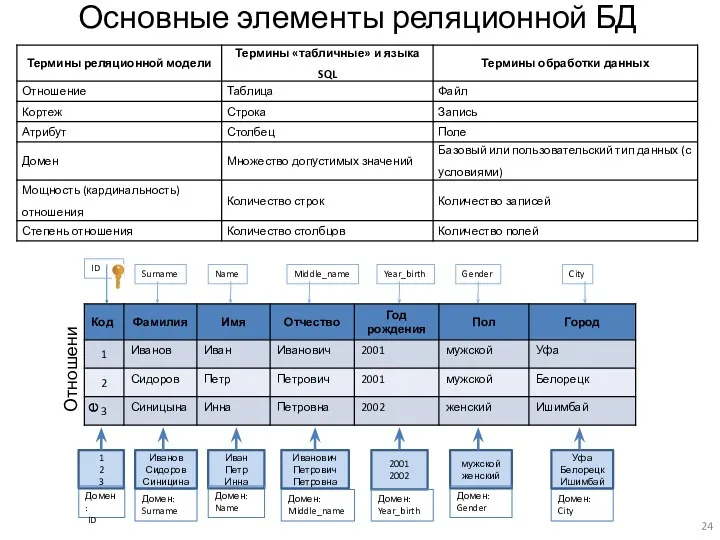
Основные элементы реляционной БД
ID
Отношение
1
2
3
Домен:
ID
Иванов
Сидоров
Синицина
Домен:
Surname
Иван
Петр
Инна
Домен:
Name
Иванович
Петрович
Петровна
Домен:
Middle_name
2001
2002
Домен:
Year_birth
мужской
женский
Домен:
Gender
Уфа
Белорецк
Ишимбай
Домен:
City
Основные элементы реляционной БД
ID
Отношение
1
2
3
Домен:
ID
Иванов
Сидоров
Синицина
Домен:
Surname
Иван
Петр
Инна
Домен:
Name
Иванович
Петрович
Петровна
Домен:
Middle_name
2001
2002
Домен:
Year_birth
мужской
женский
Домен:
Gender
Уфа
Белорецк
Ишимбай
Домен:
City
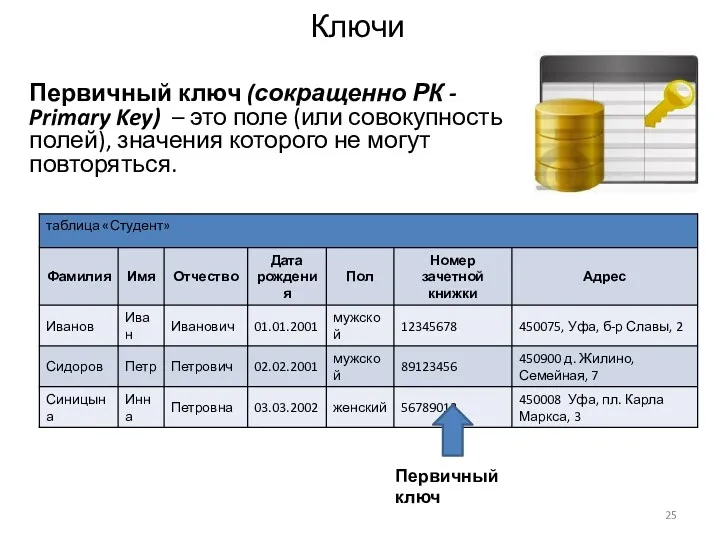
Ключи
Первичный ключ (сокращенно РК - Primary Key) – это поле (или
Ключи
Первичный ключ (сокращенно РК - Primary Key) – это поле (или
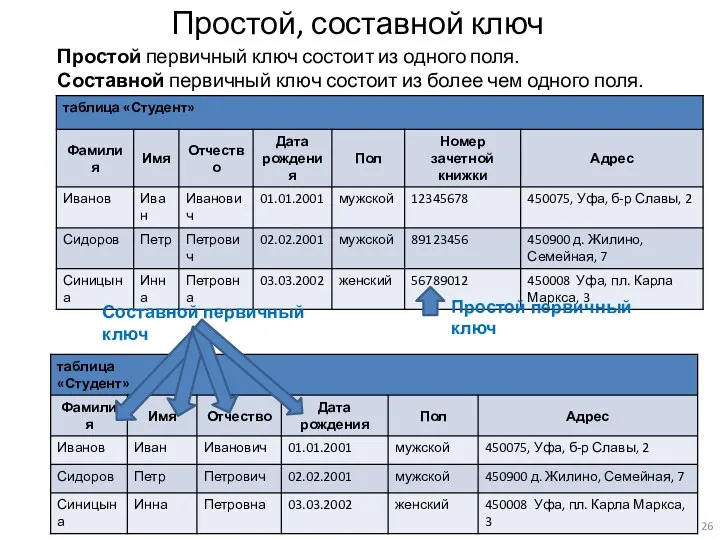
Простой, составной ключ
Простой первичный ключ состоит из одного поля.
Составной первичный ключ
Простой, составной ключ
Простой первичный ключ состоит из одного поля.
Составной первичный ключ
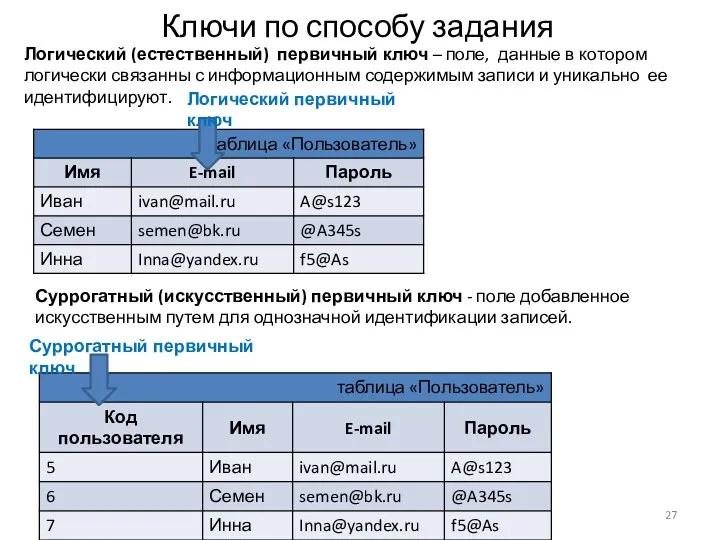
Ключи по способу задания
Логический (естественный) первичный ключ – поле, данные в
Ключи по способу задания
Логический (естественный) первичный ключ – поле, данные в
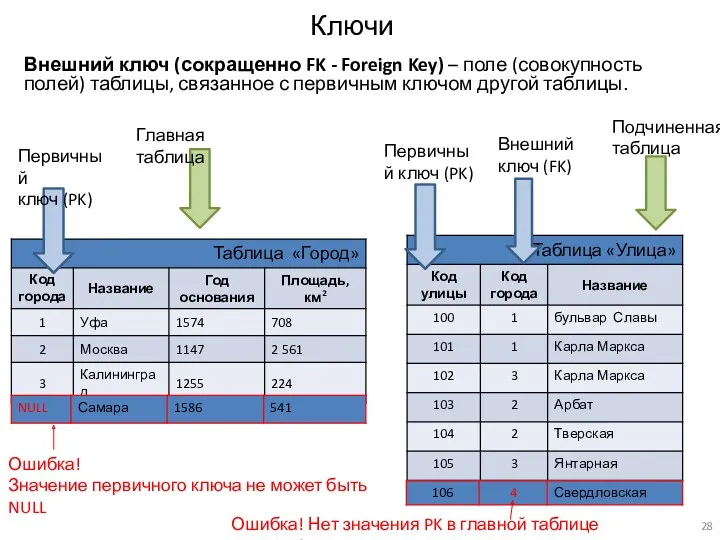
Ключи
Внешний ключ (сокращенно FK - Foreign Key) – поле (совокупность полей)
Ключи
Внешний ключ (сокращенно FK - Foreign Key) – поле (совокупность полей)
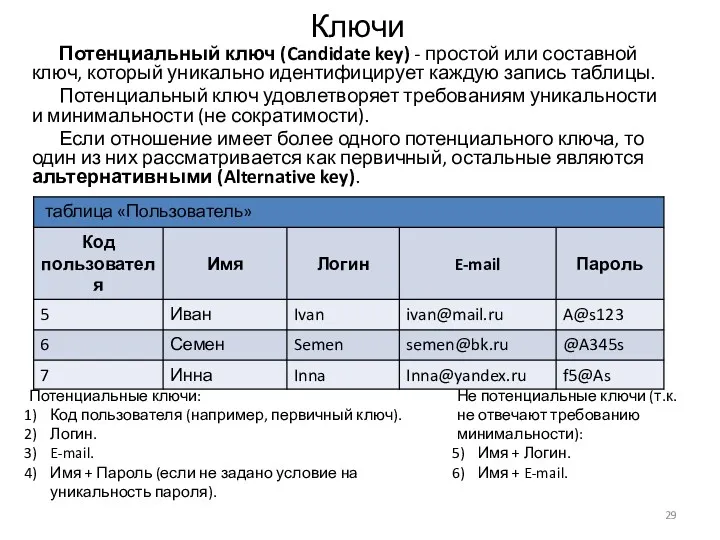
Ключи
Потенциальный ключ (Candidate key) - простой или составной ключ, который уникально
Ключи
Потенциальный ключ (Candidate key) - простой или составной ключ, который уникально

Ограничения целостности данных
Целостностью данных можно назвать механизм поддержания соответствия базы данных
Ограничения целостности данных
Целостностью данных можно назвать механизм поддержания соответствия базы данных
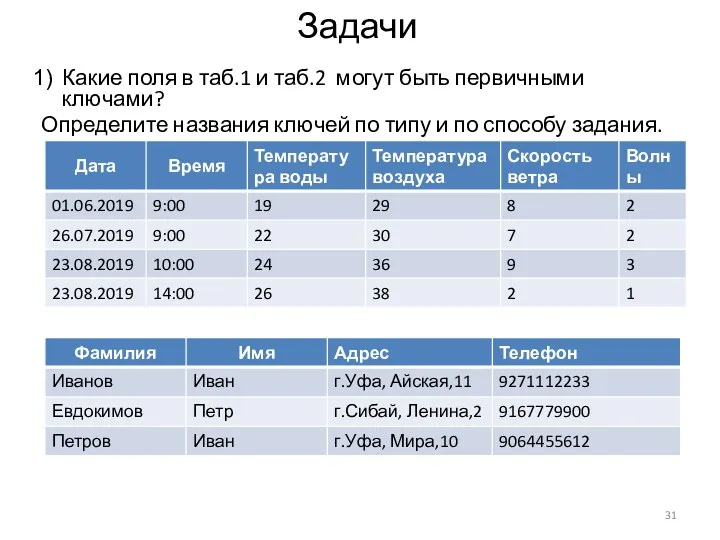
Задачи
Какие поля в таб.1 и таб.2 могут быть первичными ключами?
Определите названия
Задачи
Какие поля в таб.1 и таб.2 могут быть первичными ключами?
Определите названия
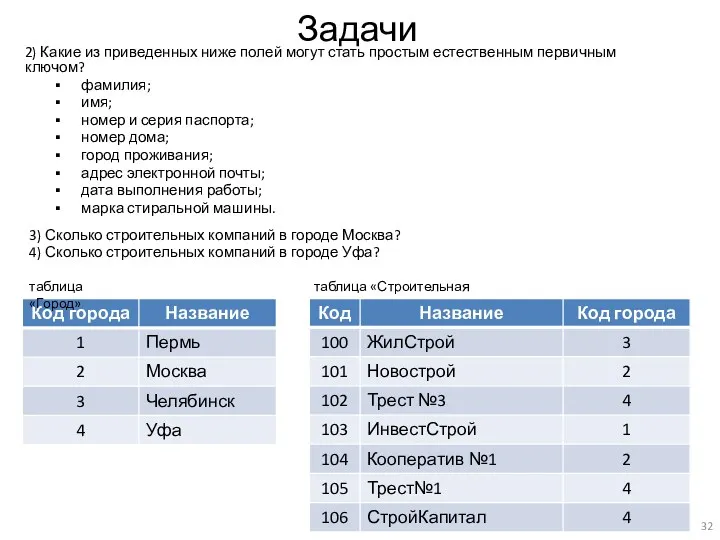
Задачи
3) Сколько строительных компаний в городе Москва?
4) Сколько строительных компаний
Задачи
3) Сколько строительных компаний в городе Москва?
4) Сколько строительных компаний
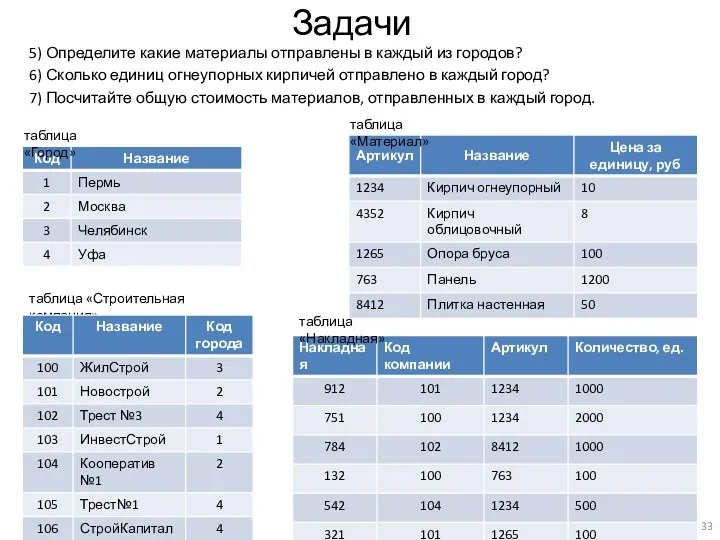
Задачи
5) Определите какие материалы отправлены в каждый из городов?
6) Сколько единиц
Задачи
5) Определите какие материалы отправлены в каждый из городов?
6) Сколько единиц
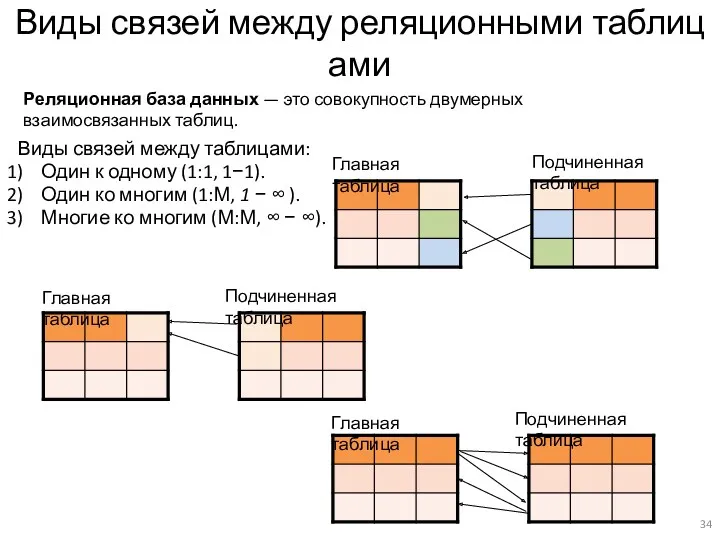
Виды связей между реляционными таблицами
Виды связей между таблицами:
Один к одному (1:1, 1−1).
Один ко многим (1:М,
Виды связей между реляционными таблицами
Виды связей между таблицами:
Один к одному (1:1, 1−1).
Один ко многим (1:М,
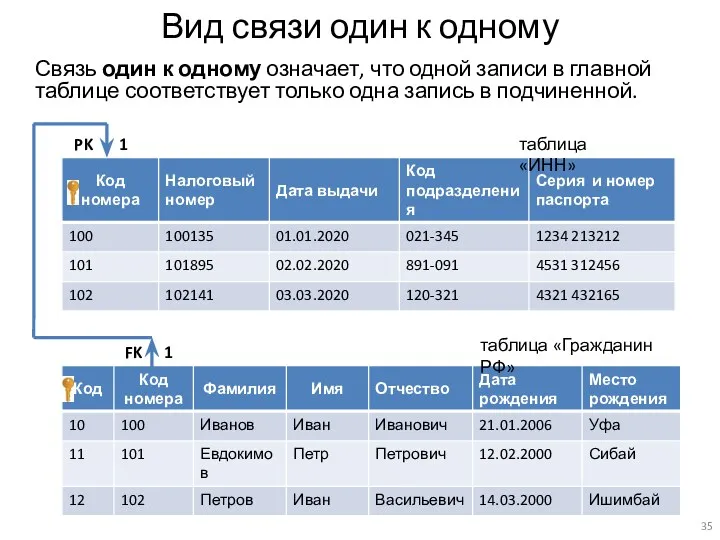
Вид связи один к одному
Связь один к одному означает, что одной записи в
Вид связи один к одному
Связь один к одному означает, что одной записи в
Вид связи один ко многим
Связь один ко многим означает, что одной записи в
Вид связи один ко многим
Связь один ко многим означает, что одной записи в
Вид связи многие ко многим
Связь многие ко многим означает, что одной записи в
Вид связи многие ко многим
Связь многие ко многим означает, что одной записи в
Задачи
1) Какие виды связи заданы между таблицами? Определите отношения подчиненности между
Задачи
1) Какие виды связи заданы между таблицами? Определите отношения подчиненности между
Задачи
2) Какие виды связи заданы между таблицами? Определите отношения подчиненности между
Задачи
2) Какие виды связи заданы между таблицами? Определите отношения подчиненности между
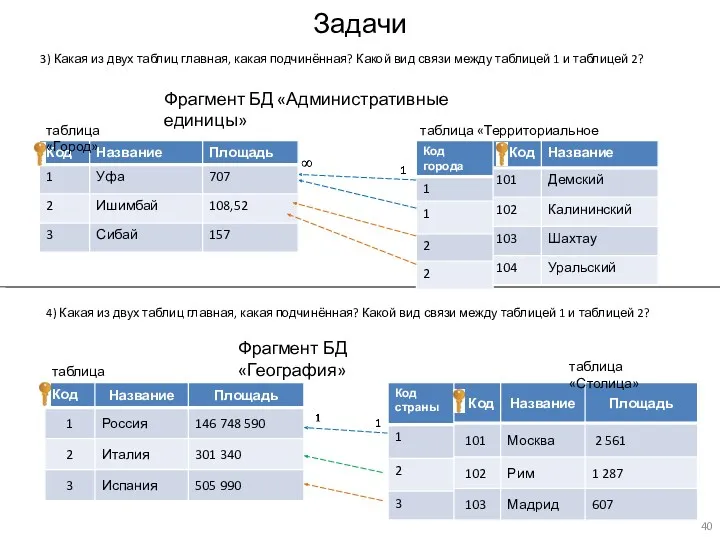
Задачи
3) Какая из двух таблиц главная, какая подчинённая? Какой вид связи
Задачи
3) Какая из двух таблиц главная, какая подчинённая? Какой вид связи
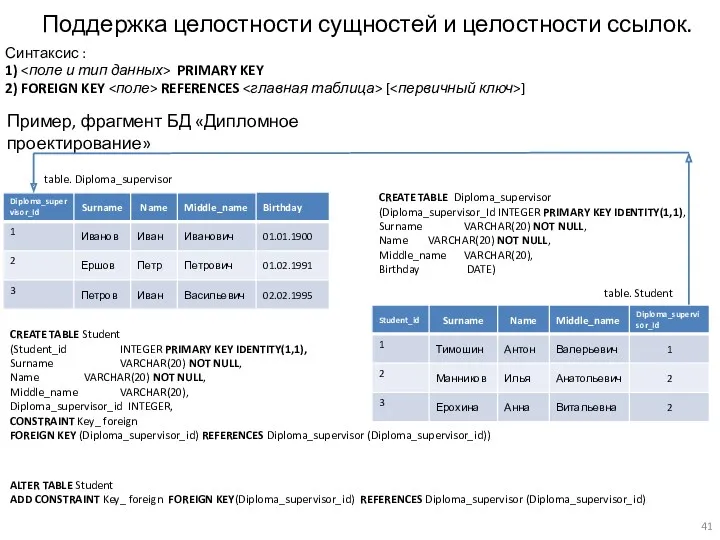
Поддержка целостности сущностей и целостности ссылок.
Синтаксис :
1) <поле и тип
Поддержка целостности сущностей и целостности ссылок.
Синтаксис :
1) <поле и тип

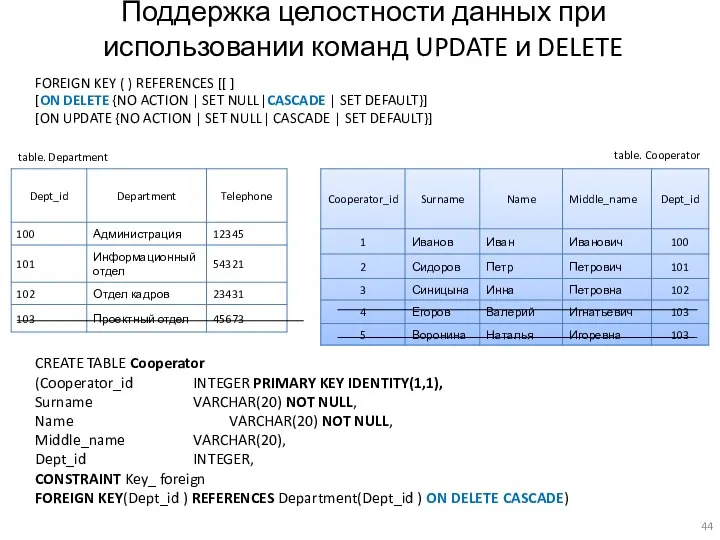
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY ()
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY ()

Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY (
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY (
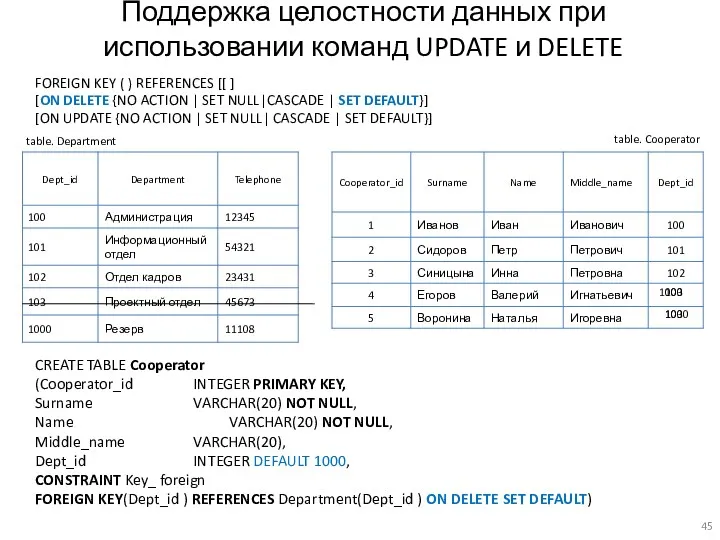
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY (
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY (
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY (
Поддержка целостности данных при использовании команд UPDATE и DELETE
FOREIGN KEY (
Язык SQL
Язык SQL

Диалекты языка SQL (расширения SQL)
Transact-SQL (или T-SQL) — СУБД MS SQL Server (Microsoft).
Jet
Диалекты языка SQL (расширения SQL)
Transact-SQL (или T-SQL) — СУБД MS SQL Server (Microsoft).
Jet
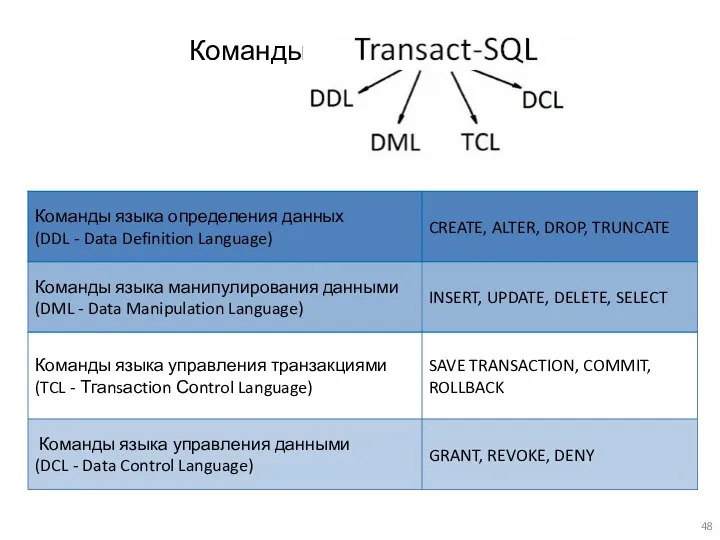
Команды
Команды
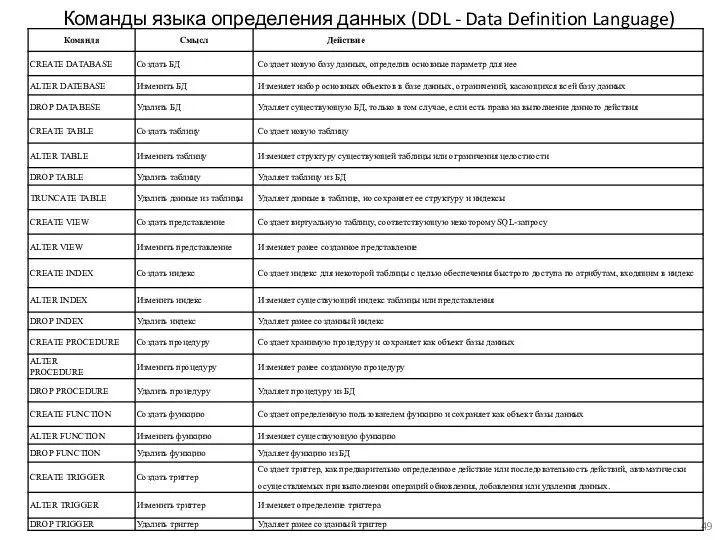
Команды языка определения данных (DDL - Data Definition Language)
Команды языка определения данных (DDL - Data Definition Language)
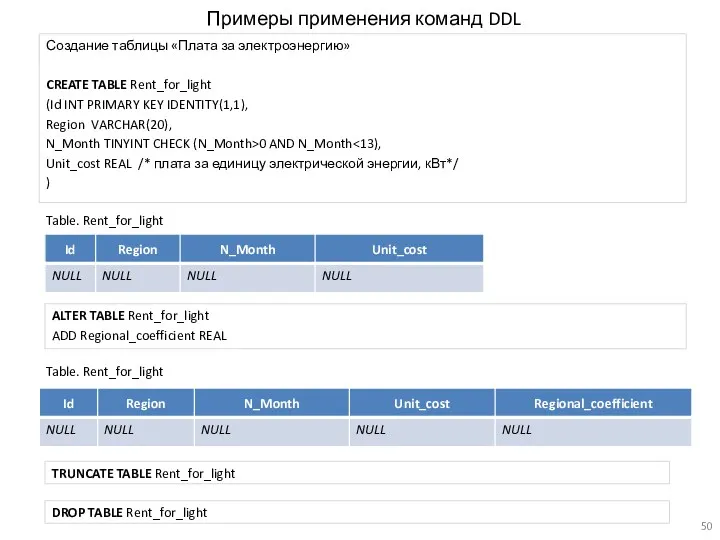
Примеры применения команд DDL
Создание таблицы «Плата за электроэнергию»
CREATE TABLE Rent_for_light
(Id INT
Примеры применения команд DDL
Создание таблицы «Плата за электроэнергию»
CREATE TABLE Rent_for_light
(Id INT
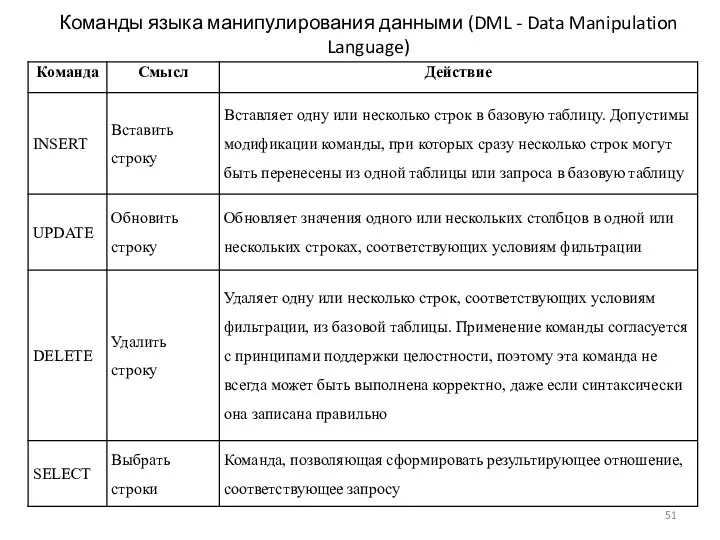
Команды языка манипулирования данными (DML - Data Manipulation Language)
Команды языка манипулирования данными (DML - Data Manipulation Language)
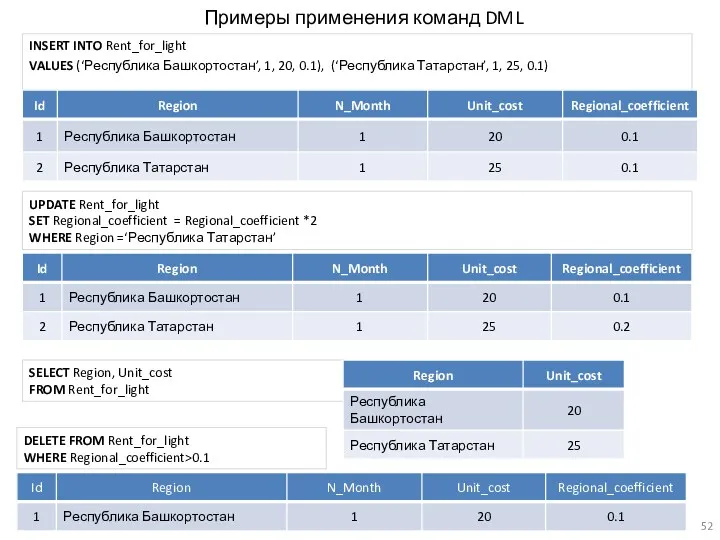
Примеры применения команд DML
INSERT INTO Rent_for_light
VALUES (‘Республика Башкортостан’, 1, 20, 0.1),
Примеры применения команд DML
INSERT INTO Rent_for_light
VALUES (‘Республика Башкортостан’, 1, 20, 0.1),
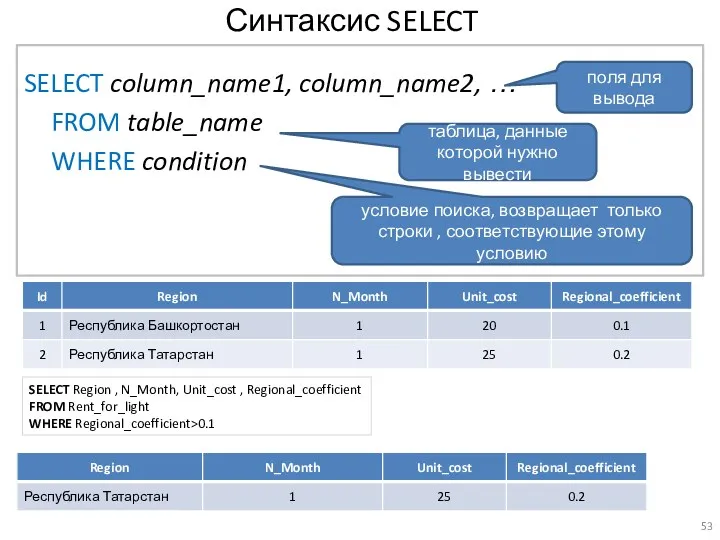
Синтаксис SELECT
SELECT column_name1, column_name2, …
FROM table_name
WHERE condition
поля для вывода
таблица, данные которой
Синтаксис SELECT
SELECT column_name1, column_name2, …
FROM table_name
WHERE condition
поля для вывода
таблица, данные которой
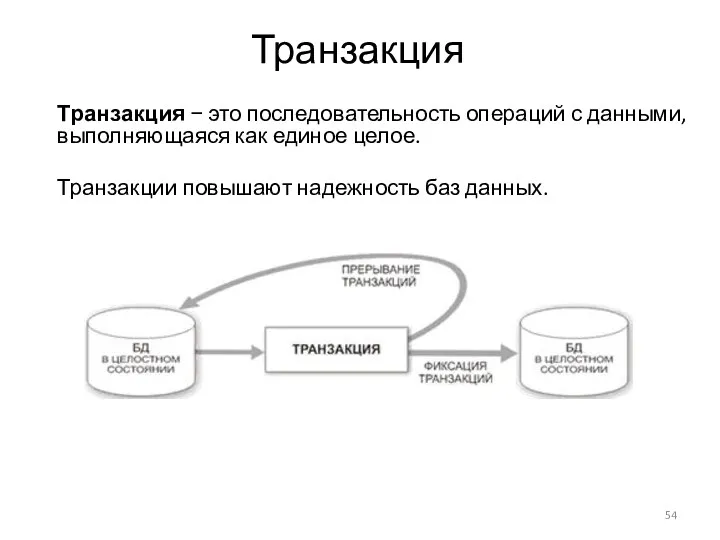
Транзакция
Транзакция − это последовательность операций с данными, выполняющаяся как единое целое.
Транзакции повышают надежность
Транзакция
Транзакция − это последовательность операций с данными, выполняющаяся как единое целое.
Транзакции повышают надежность

Пример транзакции
1) UPDATE Bank_account
SET Balance = Balance - 500
Пример транзакции
1) UPDATE Bank_account
SET Balance = Balance - 500
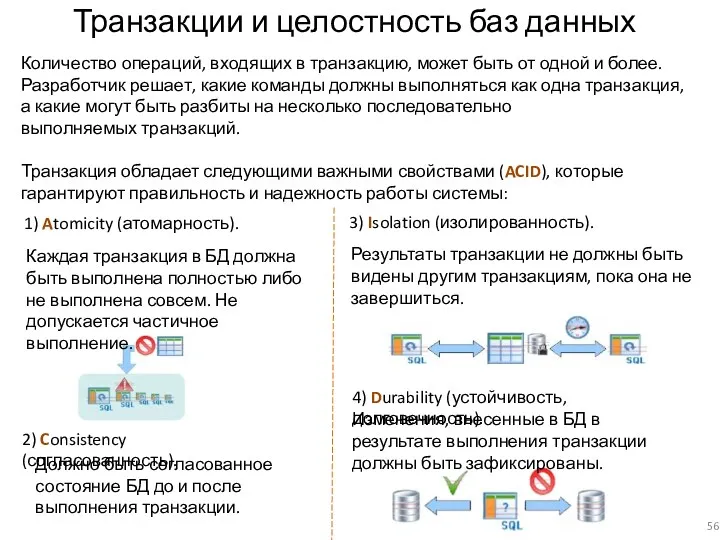
3) Isolation (изолированность).
1) Atomicity (атомарность).
Транзакции и целостность баз данных
Количество операций, входящих
3) Isolation (изолированность).
1) Atomicity (атомарность).
Транзакции и целостность баз данных
Количество операций, входящих
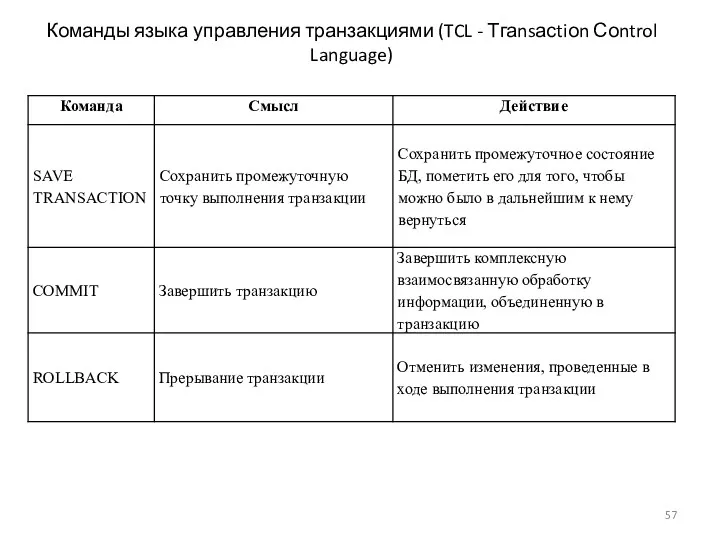
Команды языка управления транзакциями (TCL - Тгаnsасtiоn Соntrol Language)
Команды языка управления транзакциями (TCL - Тгаnsасtiоn Соntrol Language)
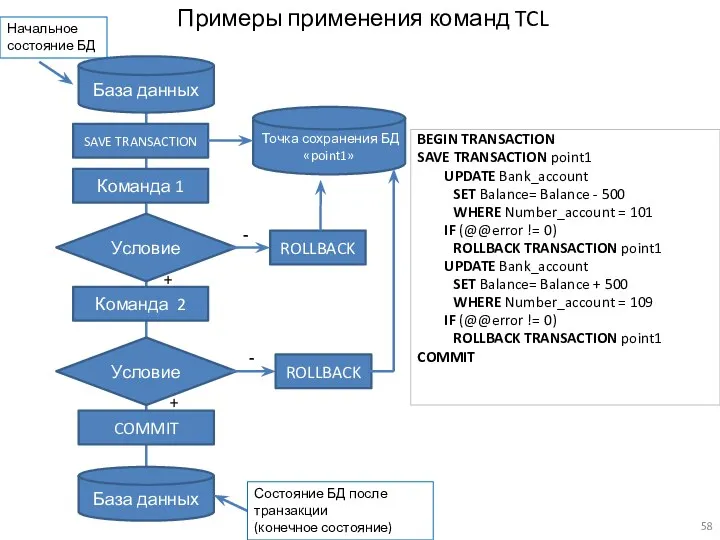
База данных
База данных
Команда 1
Команда 2
COMMIT
ROLLBACK
Начальное состояние БД
Состояние БД после транзакции
(конечное
База данных
База данных
Команда 1
Команда 2
COMMIT
ROLLBACK
Начальное состояние БД
Состояние БД после транзакции
(конечное
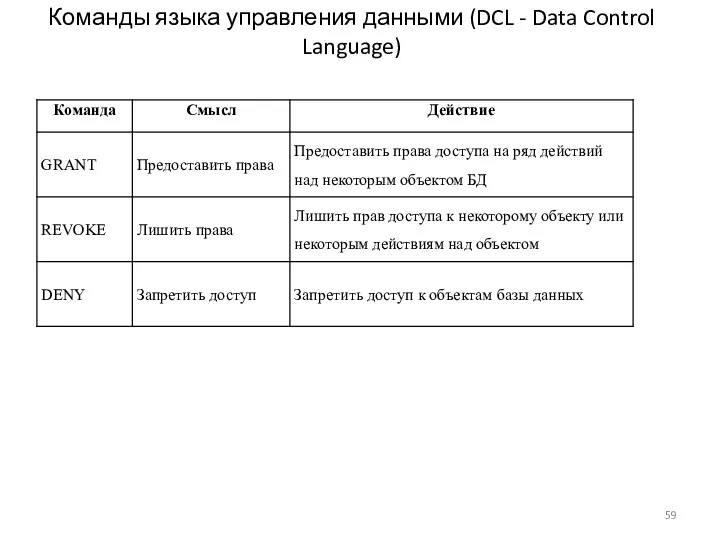
Команды языка управления данными (DCL - Data Control Language)
Команды языка управления данными (DCL - Data Control Language)

GRANT SELECT ON Student TO User2;
REVOKE SELECT ON Student TO User2;
DENY
GRANT SELECT ON Student TO User2;
REVOKE SELECT ON Student TO User2;
DENY
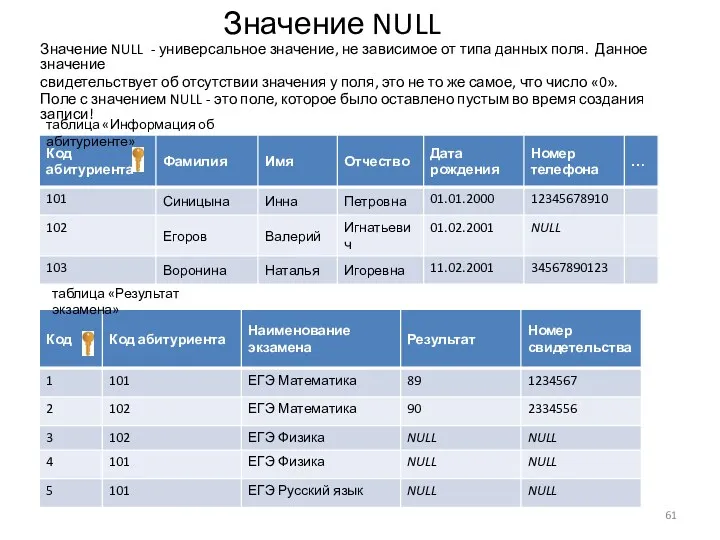
Значение NULL
Значение NULL - универсальное значение, не зависимое от типа данных
Значение NULL
Значение NULL - универсальное значение, не зависимое от типа данных

Использование значения NULL в условиях поиска
IS NULL – предикат, применяется для
Использование значения NULL в условиях поиска
IS NULL – предикат, применяется для

Оператор SQL состоит из:
зарезервированных слов;
пользовательских названий.
Пользовательские названия могут быть идентификаторами или
Оператор SQL состоит из:
зарезервированных слов;
пользовательских названий.
Пользовательские названия могут быть идентификаторами или

Подзапросы SQL (вложенные SQL запросы)
Пример структуры вложенного запроса:
SELECT <поле или список
Подзапросы SQL (вложенные SQL запросы)
Пример структуры вложенного запроса:
SELECT <поле или список
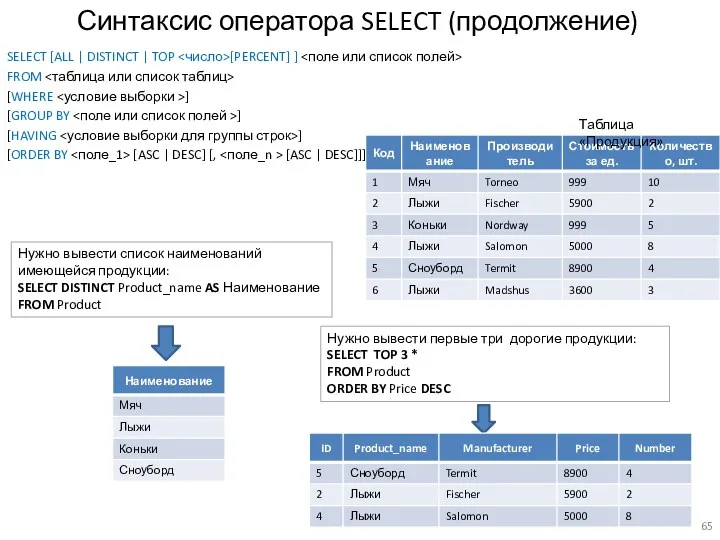
Синтаксис оператора SELECT (продолжение)
SELECT [ALL | DISTINCT | TOP <число>[PERCENT] ] <поле
Синтаксис оператора SELECT (продолжение)
SELECT [ALL | DISTINCT | TOP <число>[PERCENT] ] <поле

Операторы:
1. Арифметические операторы.
2. Операторы присваивания.
3. Операторы сравнения.
4. Логические операторы.
5. Унарные операторы.
6.
Операторы:
1. Арифметические операторы.
2. Операторы присваивания.
3. Операторы сравнения.
4. Логические операторы.
5. Унарные операторы.
6.
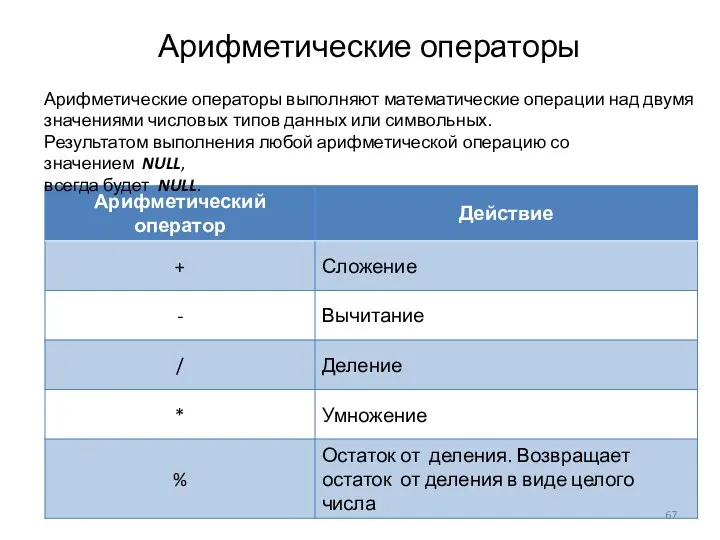
Арифметические операторы
Арифметические операторы выполняют математические операции над двумя значениями числовых типов
Арифметические операторы
Арифметические операторы выполняют математические операции над двумя значениями числовых типов
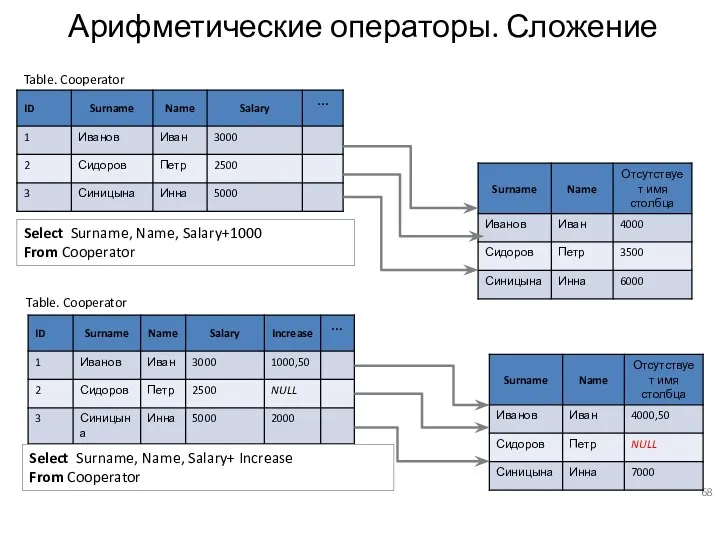
Арифметические операторы. Сложение
Select Surname, Name, Salary+1000
From Cooperator
Select Surname, Name, Salary+
Арифметические операторы. Сложение
Select Surname, Name, Salary+1000
From Cooperator
Select Surname, Name, Salary+
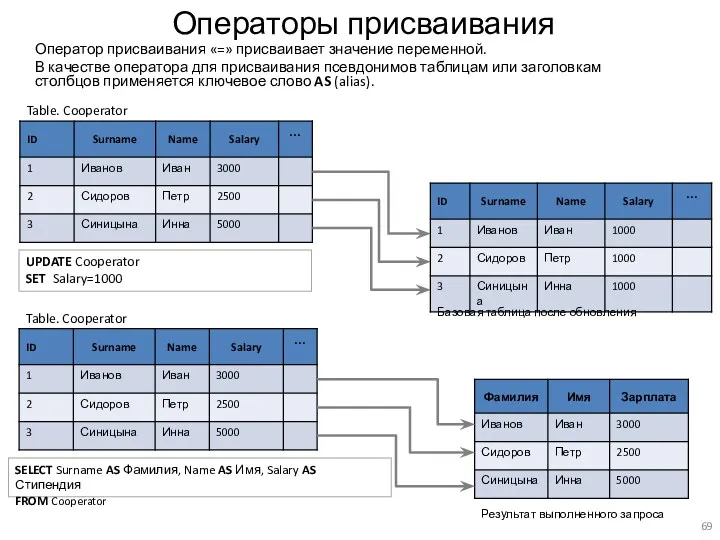
Операторы присваивания
Оператор присваивания «=» присваивает значение переменной.
В качестве оператора для присваивания
Операторы присваивания
Оператор присваивания «=» присваивает значение переменной.
В качестве оператора для присваивания
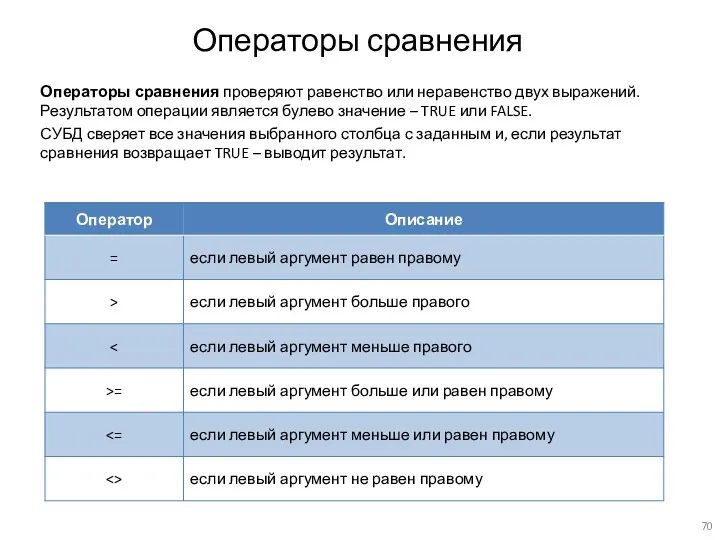
Операторы сравнения
Операторы сравнения проверяют равенство или неравенство двух выражений. Результатом операции
Операторы сравнения
Операторы сравнения проверяют равенство или неравенство двух выражений. Результатом операции
![Операторы сравнения SELECT Surname AS [Фамилия сотрудника], Name AS [Имя](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-70.jpg)
Операторы сравнения
SELECT Surname AS [Фамилия сотрудника], Name AS [Имя сотрудника]
FROM Cooperator
Операторы сравнения
SELECT Surname AS [Фамилия сотрудника], Name AS [Имя сотрудника]
FROM Cooperator
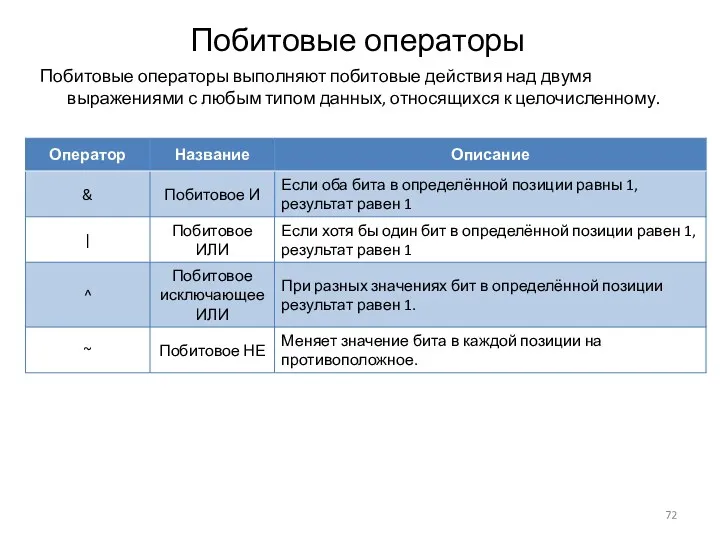
Побитовые операторы
Побитовые операторы выполняют побитовые действия над двумя выражениями с любым
Побитовые операторы
Побитовые операторы выполняют побитовые действия над двумя выражениями с любым
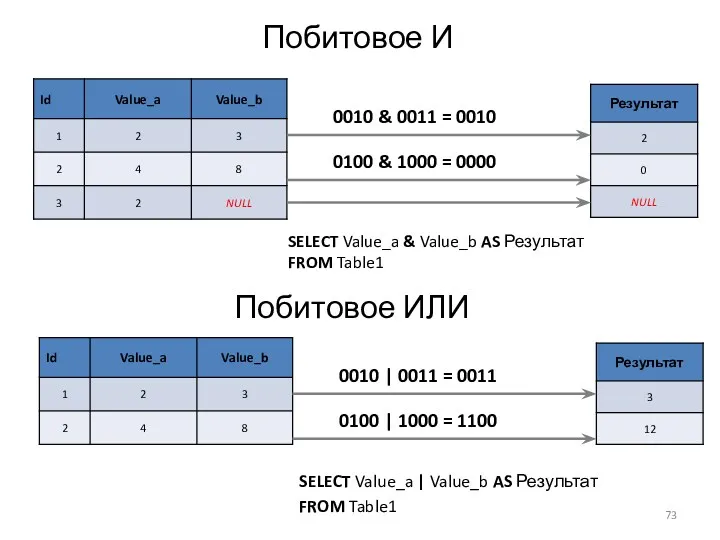
Побитовое И
SELECT Value_a & Value_b AS Результат
FROM Table1
0010 & 0011
Побитовое И
SELECT Value_a & Value_b AS Результат
FROM Table1
0010 & 0011
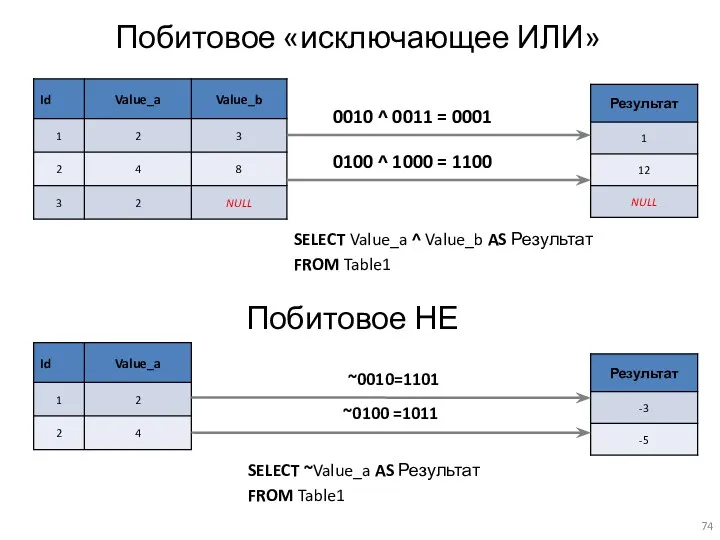
Побитовое «исключающее ИЛИ»
SELECT Value_a ^ Value_b AS Результат
FROM Table1
0010 ^ 0011
Побитовое «исключающее ИЛИ»
SELECT Value_a ^ Value_b AS Результат
FROM Table1
0010 ^ 0011
Логические операторы
Логические операторы проверяют истину некоторого условия. Логические операторы возвращают булево значение
Логические операторы
Логические операторы проверяют истину некоторого условия. Логические операторы возвращают булево значение
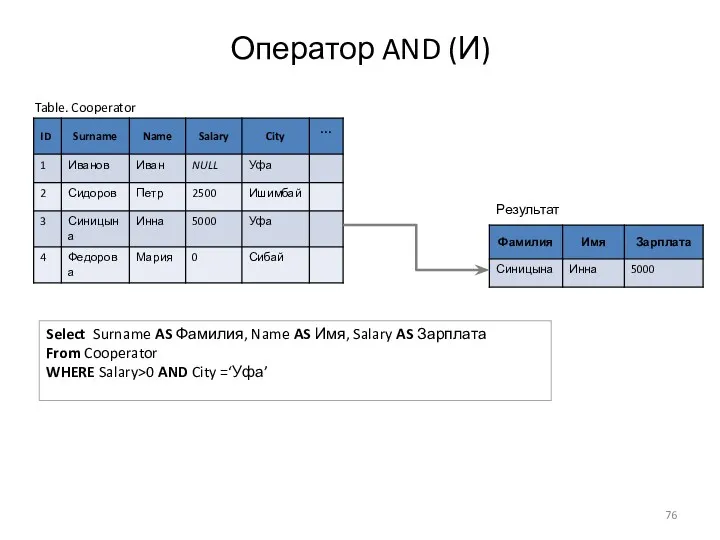
Оператор AND (И)
Table. Cooperator
Select Surname AS Фамилия, Name AS Имя, Salary
Оператор AND (И)
Table. Cooperator
Select Surname AS Фамилия, Name AS Имя, Salary
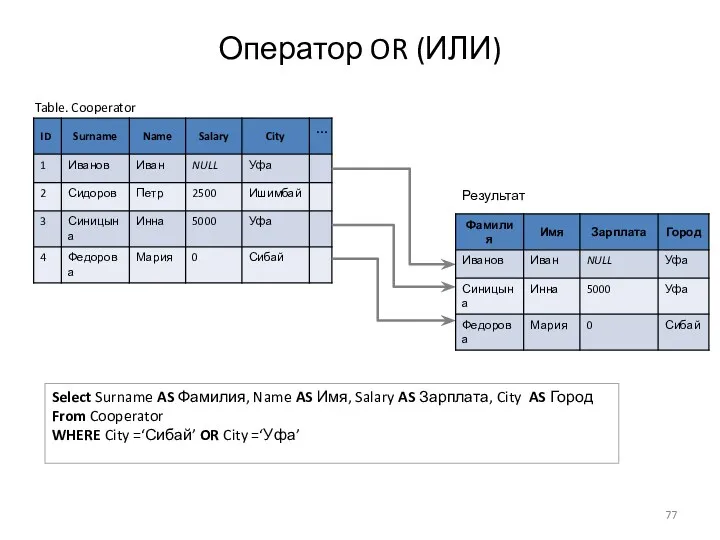
Оператор OR (ИЛИ)
Table. Cooperator
Select Surname AS Фамилия, Name AS Имя, Salary
Оператор OR (ИЛИ)
Table. Cooperator
Select Surname AS Фамилия, Name AS Имя, Salary
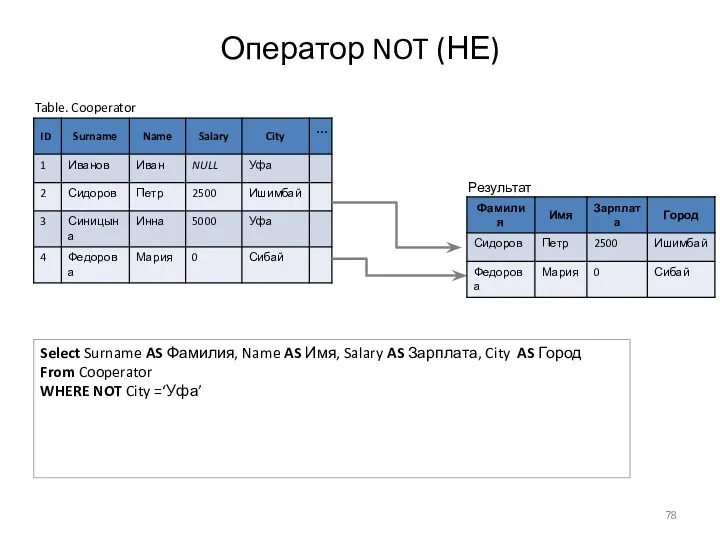
Оператор NOT (НЕ)
Table. Cooperator
Select Surname AS Фамилия, Name AS Имя, Salary
Оператор NOT (НЕ)
Table. Cooperator
Select Surname AS Фамилия, Name AS Имя, Salary
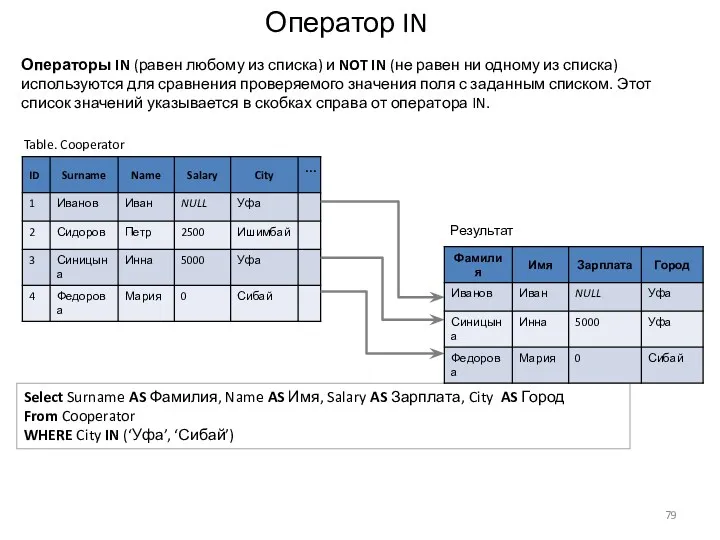
Оператор IN
Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата,
Оператор IN
Select Surname AS Фамилия, Name AS Имя, Salary AS Зарплата,
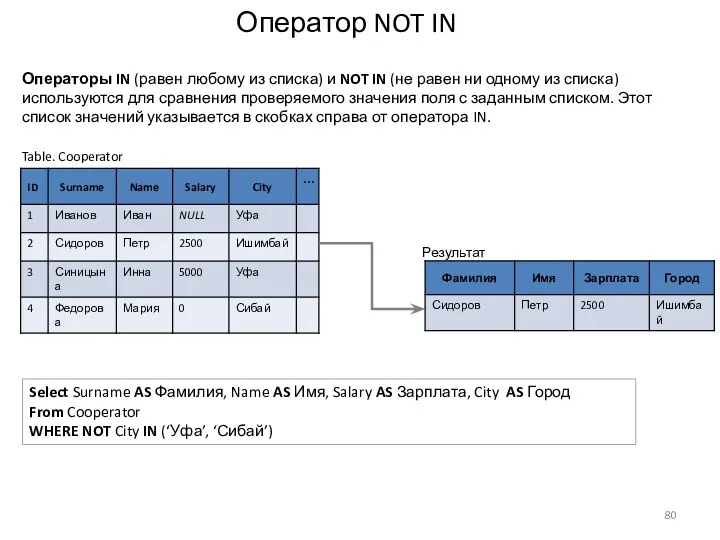
Оператор NOT IN
Select Surname AS Фамилия, Name AS Имя, Salary AS
Оператор NOT IN
Select Surname AS Фамилия, Name AS Имя, Salary AS
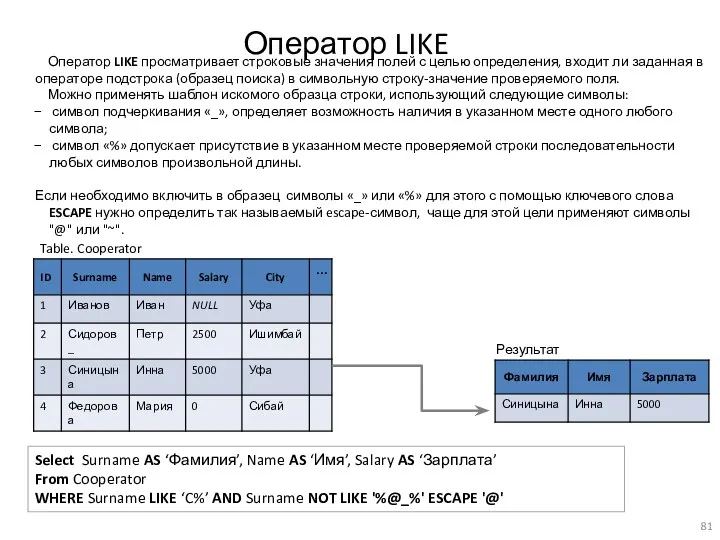
Оператор LIKE
Table. Cooperator
Select Surname AS ‘Фамилия’, Name AS ‘Имя’, Salary AS
Оператор LIKE
Table. Cooperator
Select Surname AS ‘Фамилия’, Name AS ‘Имя’, Salary AS
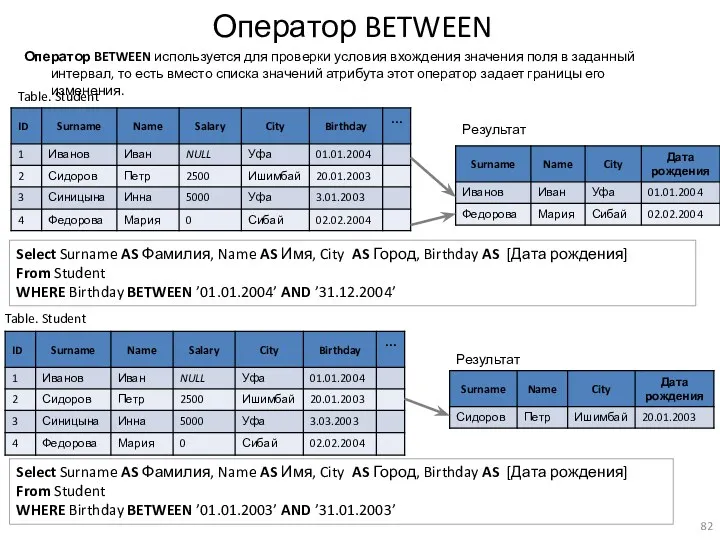
Оператор BETWEEN
Оператор BETWEEN используется для проверки условия вхождения значения поля в
Оператор BETWEEN
Оператор BETWEEN используется для проверки условия вхождения значения поля в

Оператор ANY (SOME)
SELECT Surname, Name, Birthday
FROM Student s
WHERE Student_Id=ANY(SELECT Student_Id
FROM
Оператор ANY (SOME)
SELECT Surname, Name, Birthday
FROM Student s
WHERE Student_Id=ANY(SELECT Student_Id
FROM
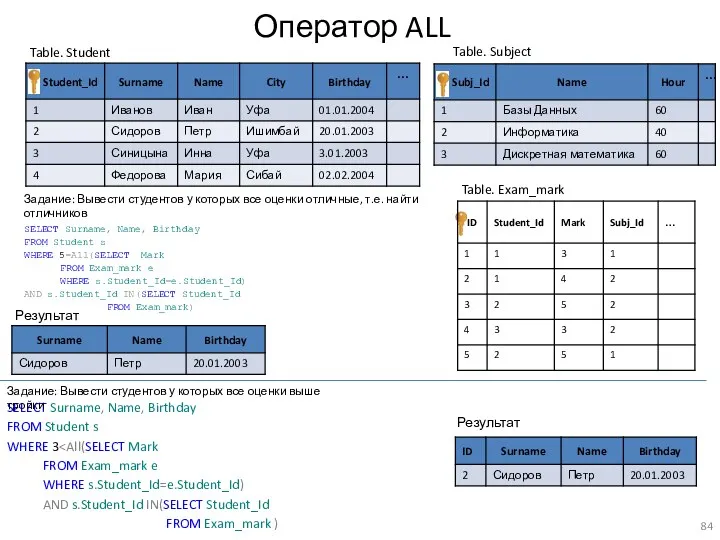
Оператор ALL
SELECT Surname, Name, Birthday
FROM Student s
WHERE 5=All(SELECT Mark
FROM Exam_mark e
WHERE
Оператор ALL
SELECT Surname, Name, Birthday
FROM Student s
WHERE 5=All(SELECT Mark
FROM Exam_mark e
WHERE

Оператор EXISTS
SELECT Surname, Name
FROM Student s
WHERE EXISTS (SELECT *
FROM Exam_mark
Оператор EXISTS
SELECT Surname, Name
FROM Student s
WHERE EXISTS (SELECT *
FROM Exam_mark

Унарные операторы
Унарные операторы выполняют операцию над одним выражением любого типа, относящимся
Унарные операторы
Унарные операторы выполняют операцию над одним выражением любого типа, относящимся
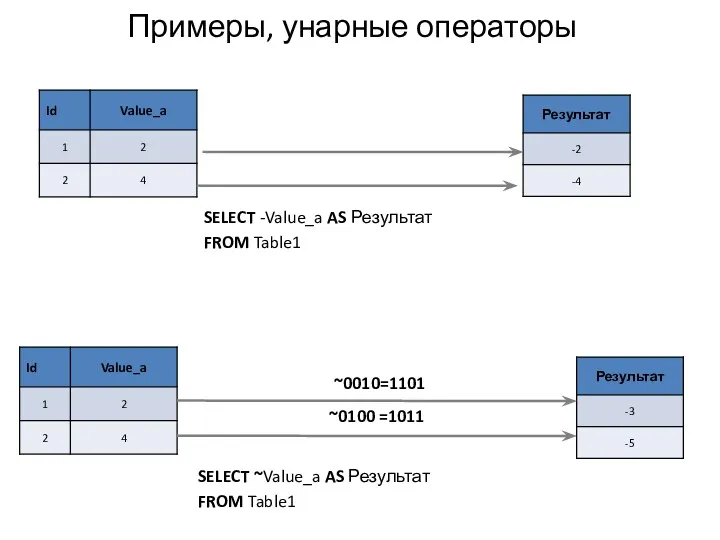
Примеры, унарные операторы
SELECT -Value_a AS Результат
FROM Table1
~0010=1101
~0100 =1011
SELECT ~Value_a
Примеры, унарные операторы
SELECT -Value_a AS Результат
FROM Table1
~0010=1101
~0100 =1011
SELECT ~Value_a
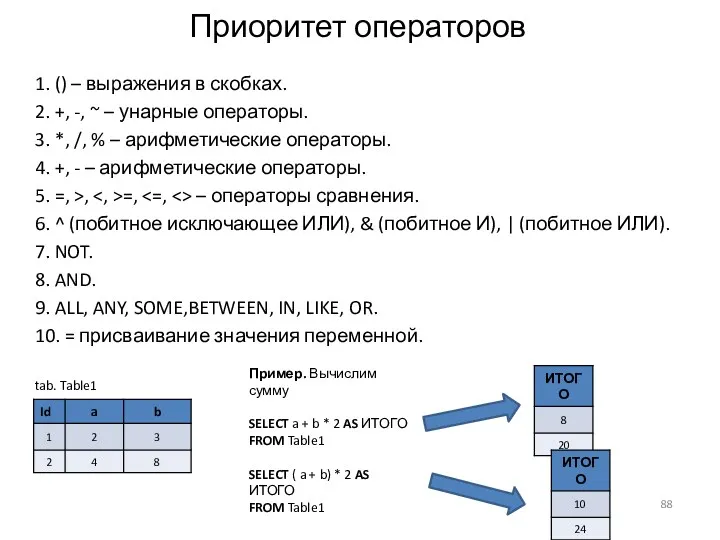
Приоритет операторов
1. () – выражения в скобках.
2. +, -, ~ –
Приоритет операторов
1. () – выражения в скобках.
2. +, -, ~ –
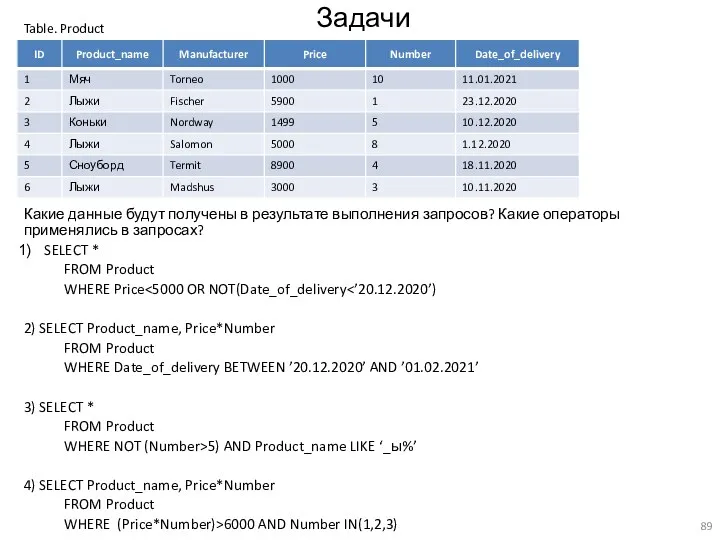
Задачи
Какие данные будут получены в результате выполнения запросов? Какие операторы применялись
Задачи
Какие данные будут получены в результате выполнения запросов? Какие операторы применялись
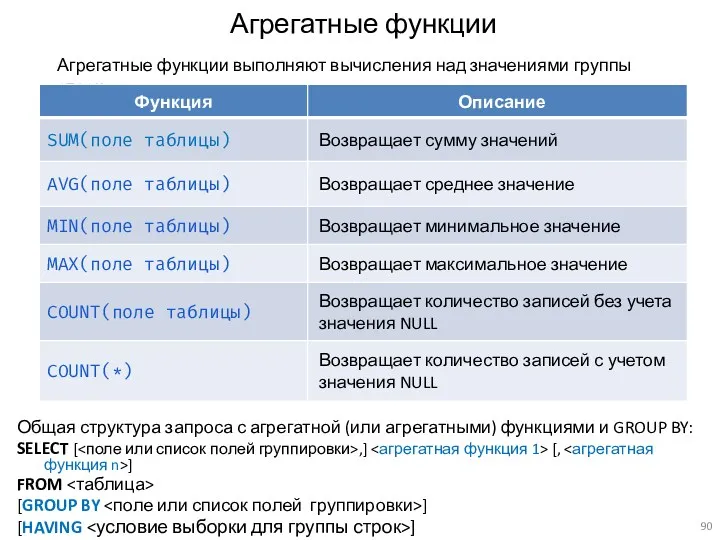
Агрегатные функции
Общая структура запроса с агрегатной (или агрегатными) функциями и GROUP
Агрегатные функции
Общая структура запроса с агрегатной (или агрегатными) функциями и GROUP
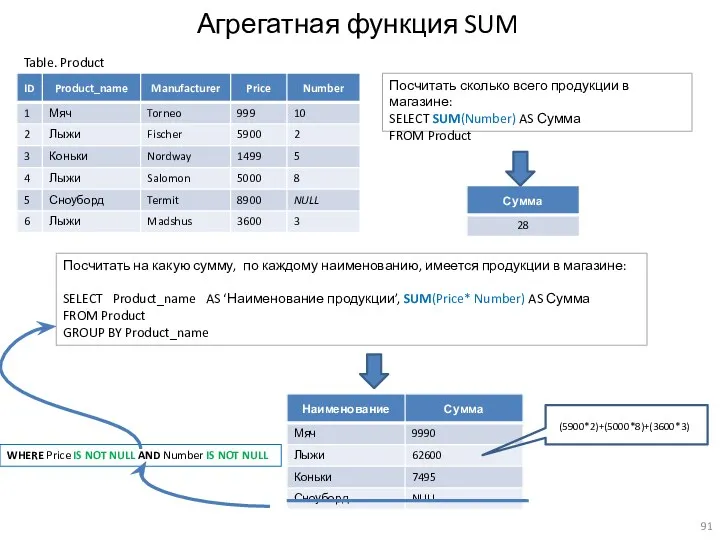
Агрегатная функция SUM
Table. Product
Посчитать сколько всего продукции в магазине:
SELECT SUM(Number) AS Сумма
FROM
Агрегатная функция SUM
Table. Product
Посчитать сколько всего продукции в магазине:
SELECT SUM(Number) AS Сумма
FROM
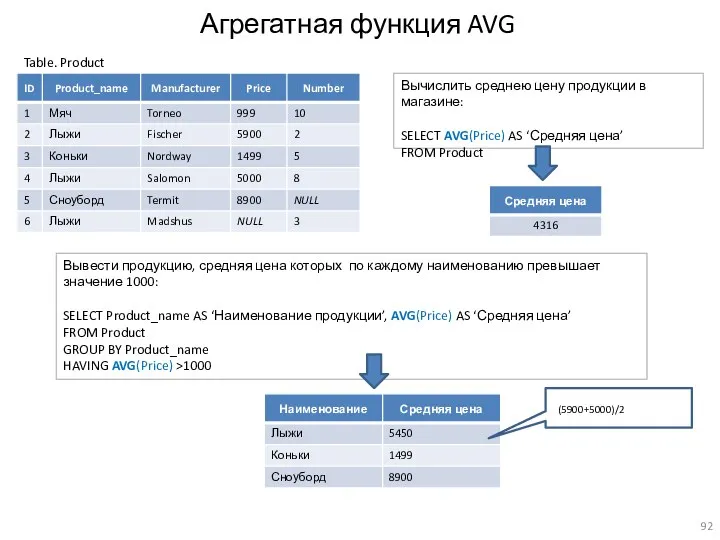
Агрегатная функция AVG
Table. Product
Вычислить среднею цену продукции в магазине:
SELECT AVG(Price) AS ‘Средняя
Агрегатная функция AVG
Table. Product
Вычислить среднею цену продукции в магазине:
SELECT AVG(Price) AS ‘Средняя
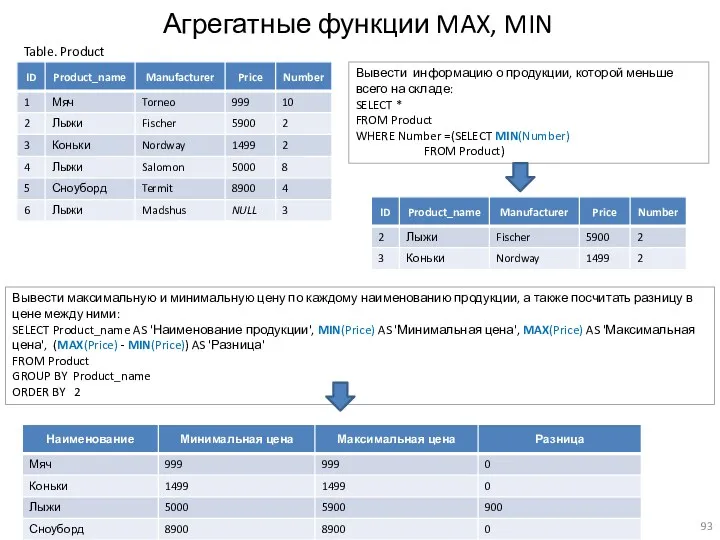
Агрегатные функции MAX, MIN
Table. Product
Вывести максимальную и минимальную цену по каждому наименованию
Агрегатные функции MAX, MIN
Table. Product
Вывести максимальную и минимальную цену по каждому наименованию
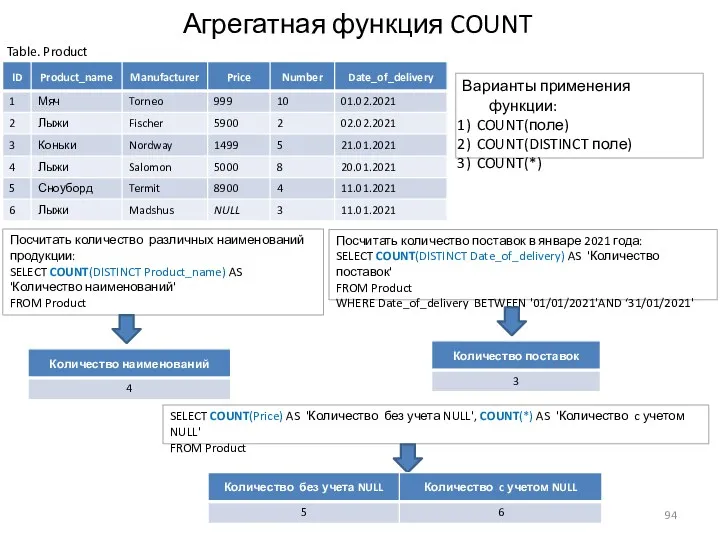
Агрегатная функция COUNT
Table. Product
Посчитать количество различных наименований продукции:
SELECT COUNT(DISTINCT Product_name) AS 'Количество
Агрегатная функция COUNT
Table. Product
Посчитать количество различных наименований продукции:
SELECT COUNT(DISTINCT Product_name) AS 'Количество
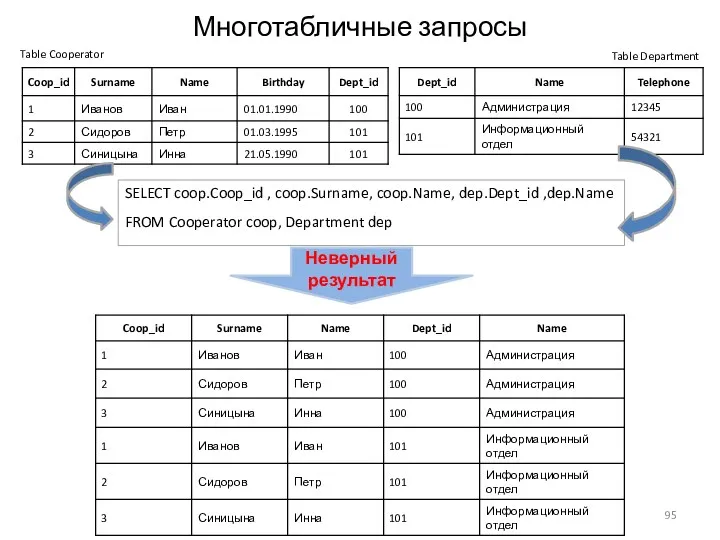
Многотабличные запросы
Table Cooperator
Table Department
SELECT coop.Coop_id , coop.Surname, coop.Name, dep.Dept_id ,dep.Name
FROM
Многотабличные запросы
Table Cooperator
Table Department
SELECT coop.Coop_id , coop.Surname, coop.Name, dep.Dept_id ,dep.Name
FROM
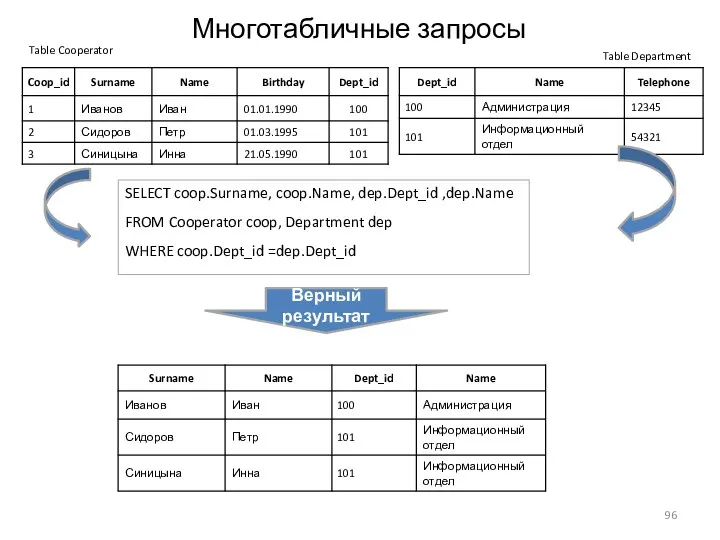
Многотабличные запросы
Table Cooperator
Table Department
SELECT coop.Surname, coop.Name, dep.Dept_id ,dep.Name
FROM Cooperator coop,
Многотабличные запросы
Table Cooperator
Table Department
SELECT coop.Surname, coop.Name, dep.Dept_id ,dep.Name
FROM Cooperator coop,

Многотабличные запросы, оператор соединения JOIN
Ключевое слово JOIN в SQL используется при
Многотабличные запросы, оператор соединения JOIN
Ключевое слово JOIN в SQL используется при
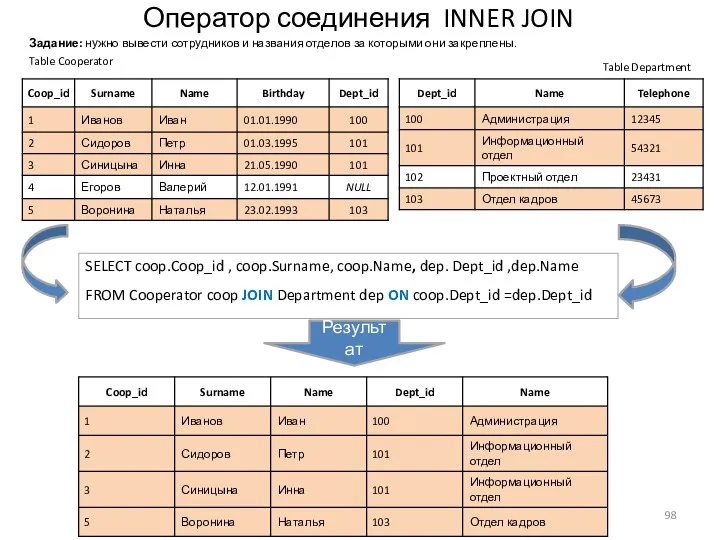
Оператор соединения INNER JOIN
Table Cooperator
Table Department
SELECT coop.Coop_id , coop.Surname, coop.Name, dep.
Оператор соединения INNER JOIN
Table Cooperator
Table Department
SELECT coop.Coop_id , coop.Surname, coop.Name, dep.
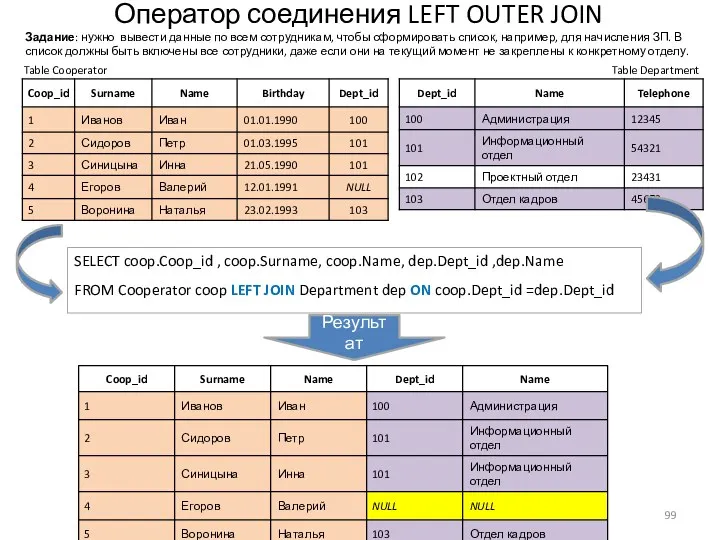
Оператор соединения LEFT OUTER JOIN
Table Cooperator
Table Department
SELECT coop.Coop_id , coop.Surname, coop.Name,
Оператор соединения LEFT OUTER JOIN
Table Cooperator
Table Department
SELECT coop.Coop_id , coop.Surname, coop.Name,
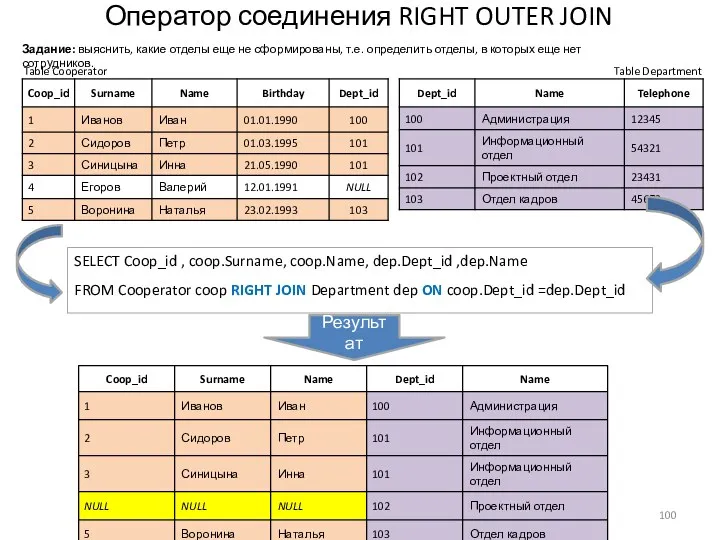
Оператор соединения RIGHT OUTER JOIN
Table Cooperator
Table Department
SELECT Coop_id , coop.Surname, coop.Name,
Оператор соединения RIGHT OUTER JOIN
Table Cooperator
Table Department
SELECT Coop_id , coop.Surname, coop.Name,
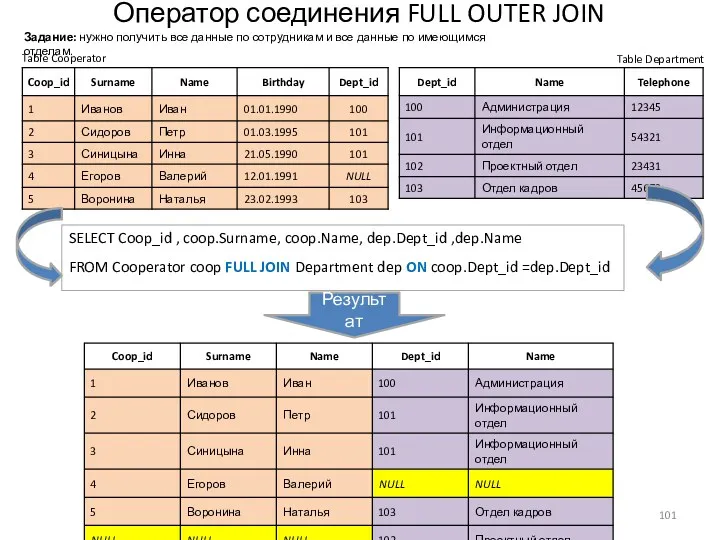
Оператор соединения FULL OUTER JOIN
Table Cooperator
Table Department
SELECT Coop_id , coop.Surname, coop.Name,
Оператор соединения FULL OUTER JOIN
Table Cooperator
Table Department
SELECT Coop_id , coop.Surname, coop.Name,
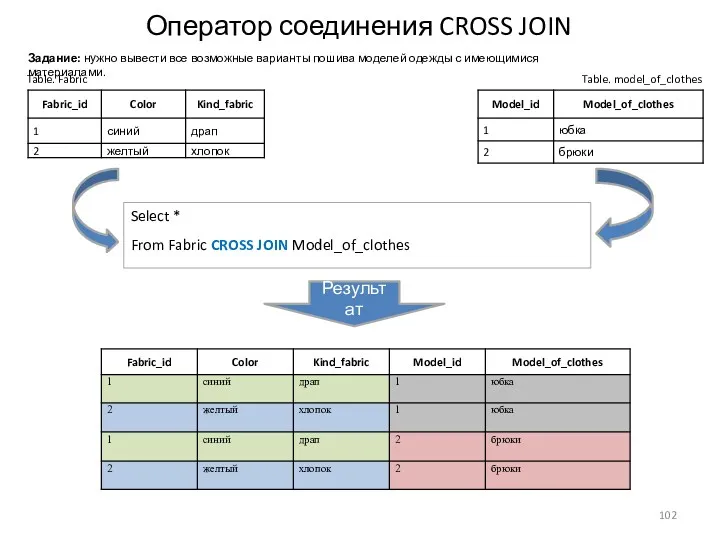
Оператор соединения CROSS JOIN
Table. Fabric
Table. model_of_clothes
Select *
From Fabric CROSS JOIN
Оператор соединения CROSS JOIN
Table. Fabric
Table. model_of_clothes
Select *
From Fabric CROSS JOIN

Типы данных MS SQL Server
Числовые типы данных:
BIT: хранит значение 0 или
Типы данных MS SQL Server
Числовые типы данных:
BIT: хранит значение 0 или

Типы данных MS SQL Server
Типы данных, представляющие дату и время:
DATE: ГГГГ-ММ-ДД.
Типы данных MS SQL Server
Типы данных, представляющие дату и время:
DATE: ГГГГ-ММ-ДД.

Типы данных MS SQL Server
Строковые типы данных:
CHAR: хранит строку длиной от
Типы данных MS SQL Server
Строковые типы данных:
CHAR: хранит строку длиной от

Типы данных MS SQL Server
Бинарные типы данных:
BINARY: хранит бинарные данные в
Типы данных MS SQL Server
Бинарные типы данных:
BINARY: хранит бинарные данные в
Проектирование баз данных
Основные задачи:
1) Сохранить необходимые данные о конкретной предметной области.
2)
Проектирование баз данных
Основные задачи:
1) Сохранить необходимые данные о конкретной предметной области.
2)
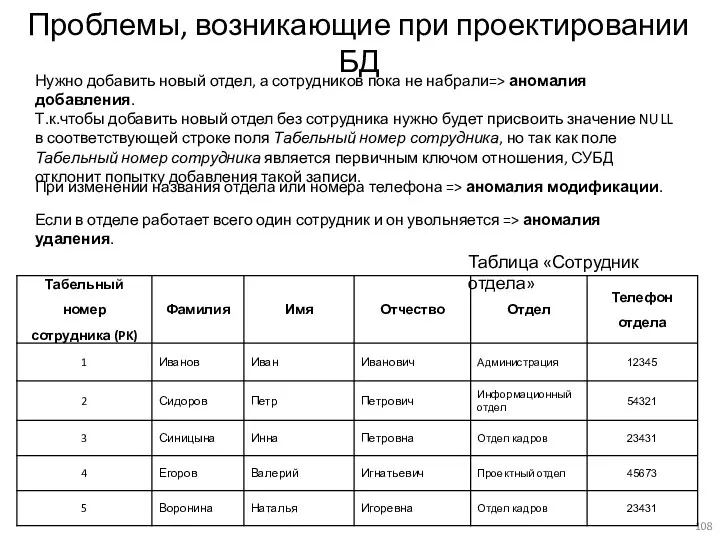
Проблемы, возникающие при проектировании БД
Таблица «Сотрудник отдела»
Нужно добавить новый отдел, а
Проблемы, возникающие при проектировании БД
Таблица «Сотрудник отдела»
Нужно добавить новый отдел, а
Аномалии в таблицах БД
При неправильно спроектированной схеме реляционной БД могут возникнуть
Аномалии в таблицах БД
При неправильно спроектированной схеме реляционной БД могут возникнуть
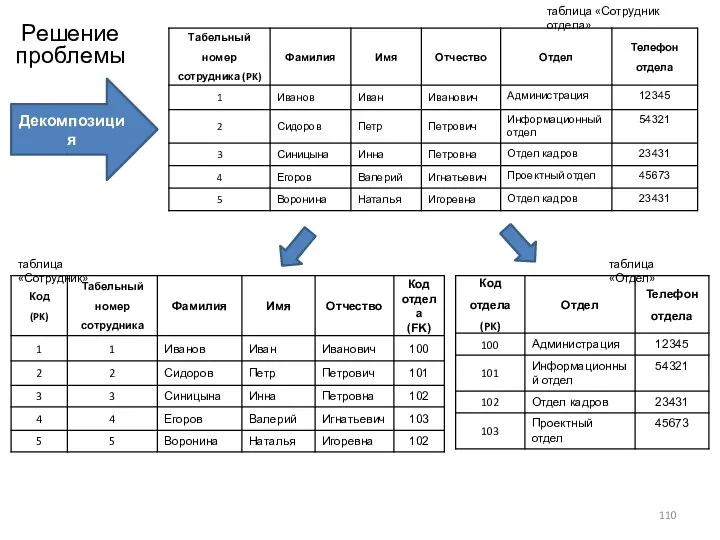
таблица «Сотрудник отдела»
Декомпозиция
Решение проблемы
таблица «Сотрудник»
таблица «Отдел»
таблица «Сотрудник отдела»
Декомпозиция
Решение проблемы
таблица «Сотрудник»
таблица «Отдел»
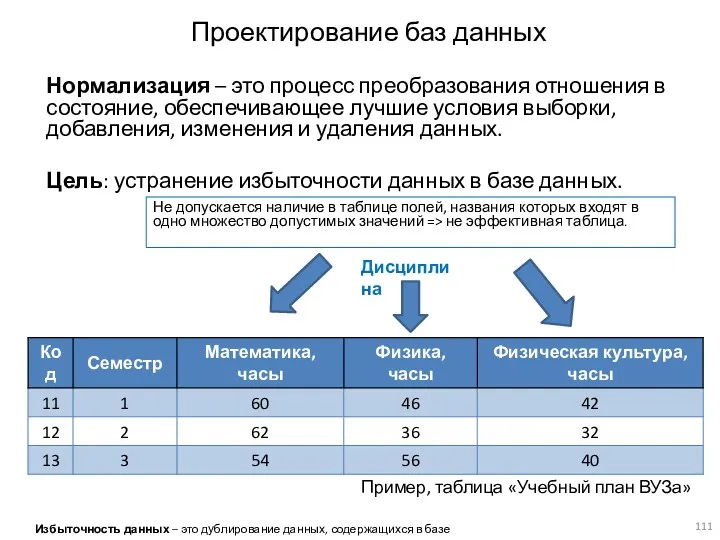
Проектирование баз данных
Нормализация – это процесс преобразования отношения в состояние, обеспечивающее
Проектирование баз данных
Нормализация – это процесс преобразования отношения в состояние, обеспечивающее
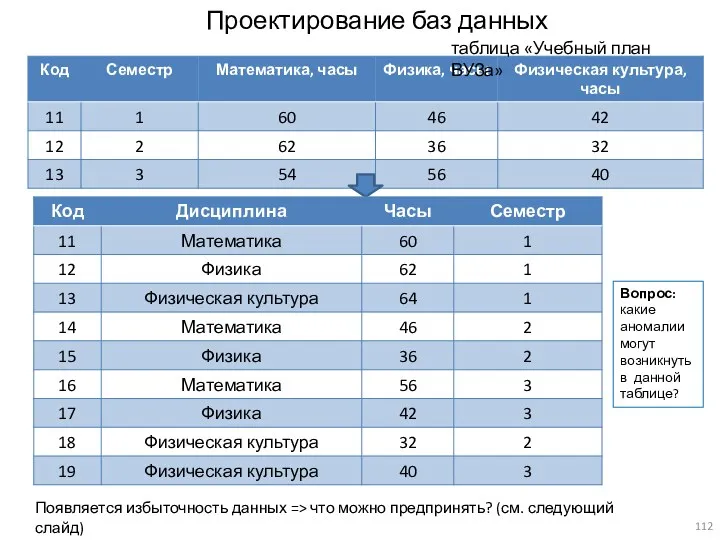
Проектирование баз данных
Появляется избыточность данных => что можно предпринять? (см. следующий
Проектирование баз данных
Появляется избыточность данных => что можно предпринять? (см. следующий
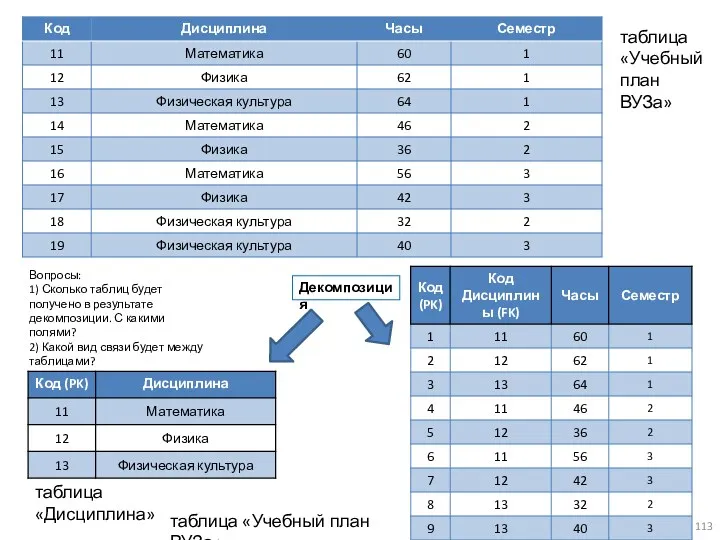
таблица «Учебный план ВУЗа»
Декомпозиция
таблица «Дисциплина»
таблица «Учебный план ВУЗа»
Вопросы:
1) Сколько таблиц
таблица «Учебный план ВУЗа»
Декомпозиция
таблица «Дисциплина»
таблица «Учебный план ВУЗа»
Вопросы:
1) Сколько таблиц

Нормальные формы
Эдгар Кодд.
Нормальные формы:
Первая нормальная форма (1NF, 1НФ).
Вторая нормальная форма
Нормальные формы
Эдгар Кодд.
Нормальные формы:
Первая нормальная форма (1NF, 1НФ).
Вторая нормальная форма
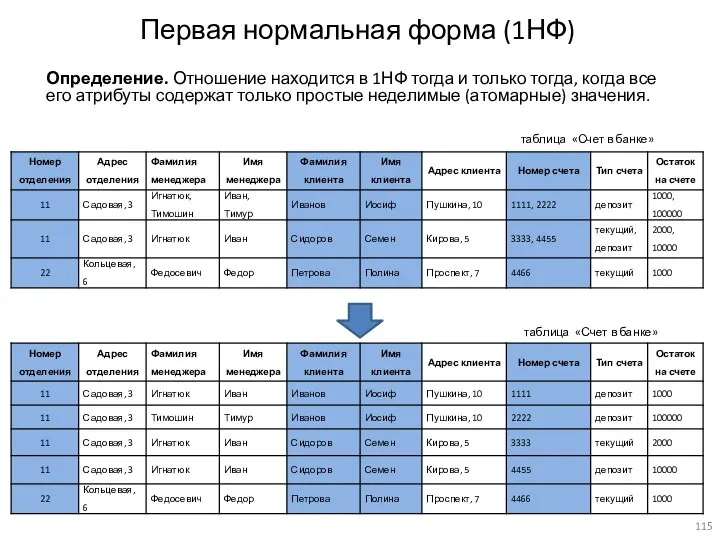
Первая нормальная форма (1НФ)
Определение. Отношение находится в 1НФ тогда и только
Первая нормальная форма (1НФ)
Определение. Отношение находится в 1НФ тогда и только
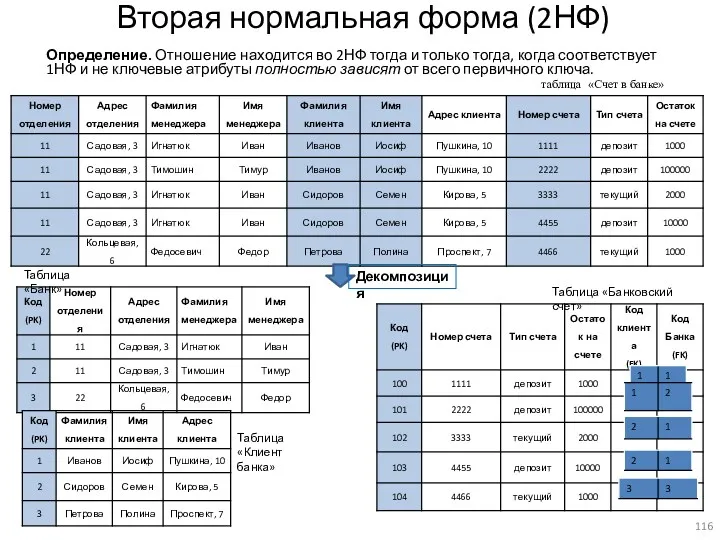
Вторая нормальная форма (2НФ)
Определение. Отношение находится во 2НФ тогда и только
Вторая нормальная форма (2НФ)
Определение. Отношение находится во 2НФ тогда и только
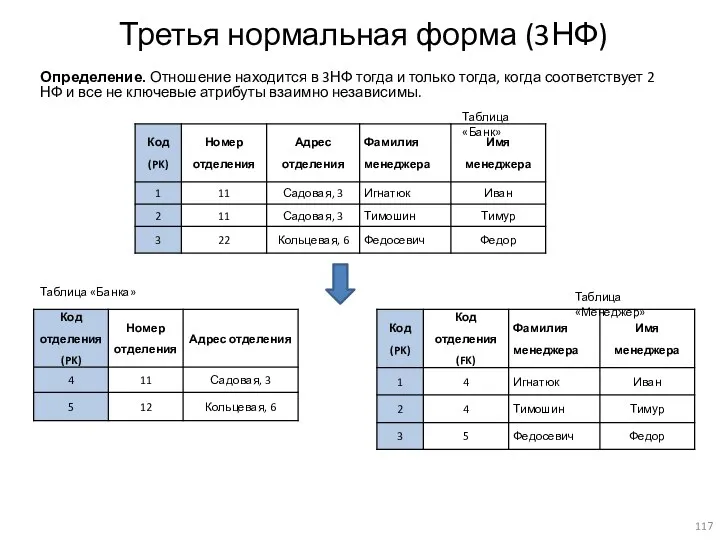
Третья нормальная форма (3НФ)
Определение. Отношение находится в 3НФ тогда и только
Третья нормальная форма (3НФ)
Определение. Отношение находится в 3НФ тогда и только
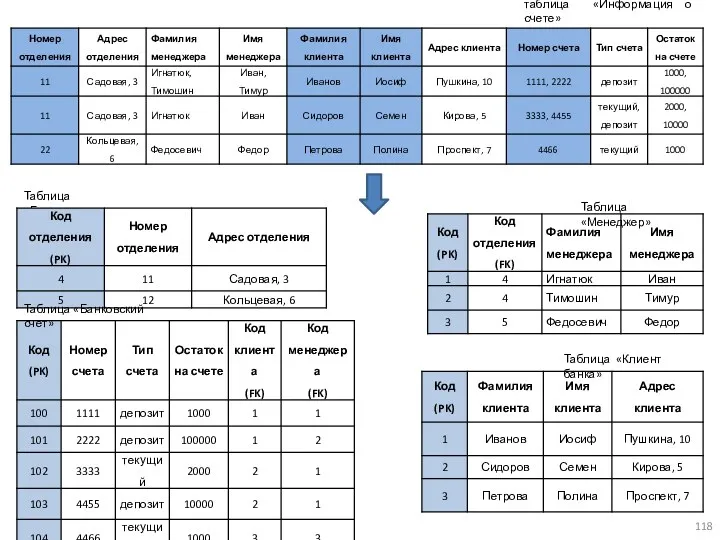
Таблица «Менеджер»
Таблица «Банка»
Таблица «Клиент банка»
Таблица «Банковский счет»
таблица «Информация о счете»
Таблица «Менеджер»
Таблица «Банка»
Таблица «Клиент банка»
Таблица «Банковский счет»
таблица «Информация о счете»
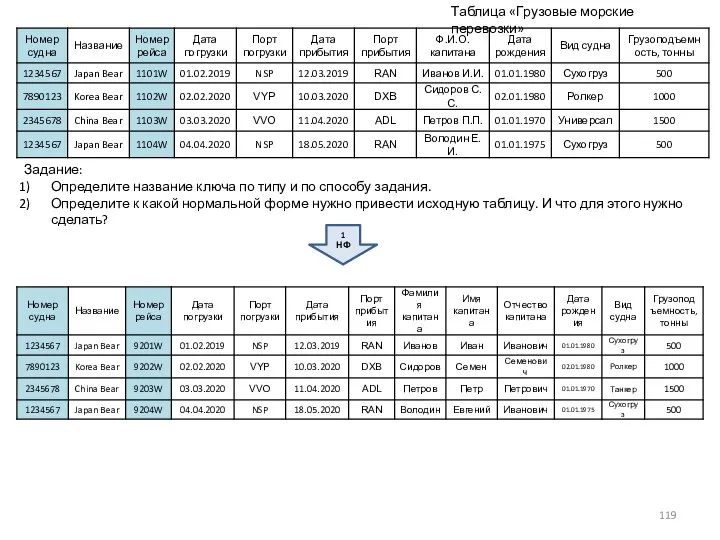
Таблица «Грузовые морские перевозки»
1 НФ
Задание:
Определите название ключа по типу и по
Таблица «Грузовые морские перевозки»
1 НФ
Задание:
Определите название ключа по типу и по
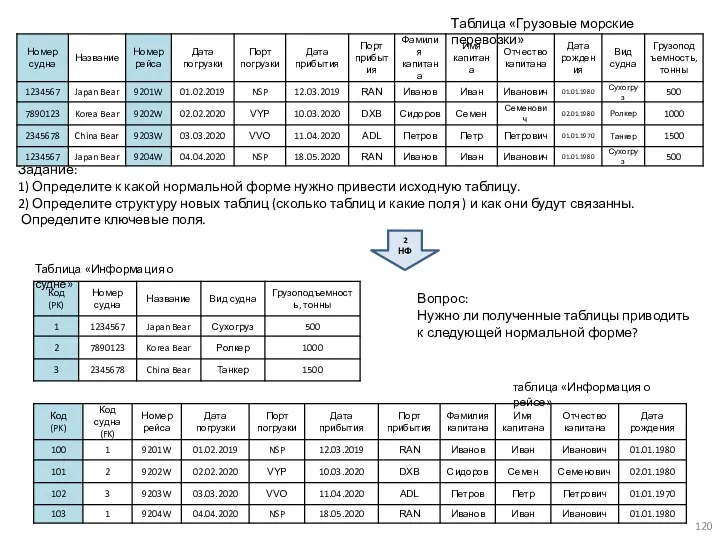
Таблица «Грузовые морские перевозки»
2 НФ
Таблица «Информация о судне»
таблица «Информация о рейсе»
Задание:
1)
Таблица «Грузовые морские перевозки»
2 НФ
Таблица «Информация о судне»
таблица «Информация о рейсе»
Задание:
1)
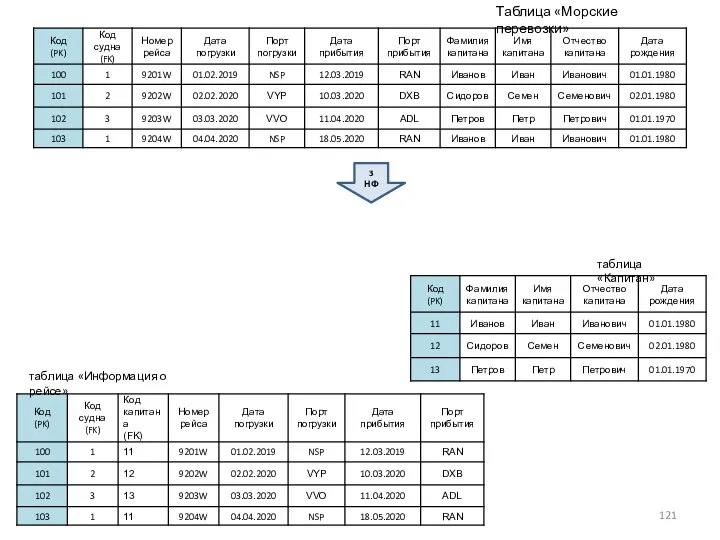
Таблица «Морские перевозки»
3 НФ
таблица «Информация о рейсе»
таблица «Капитан»
Таблица «Морские перевозки»
3 НФ
таблица «Информация о рейсе»
таблица «Капитан»
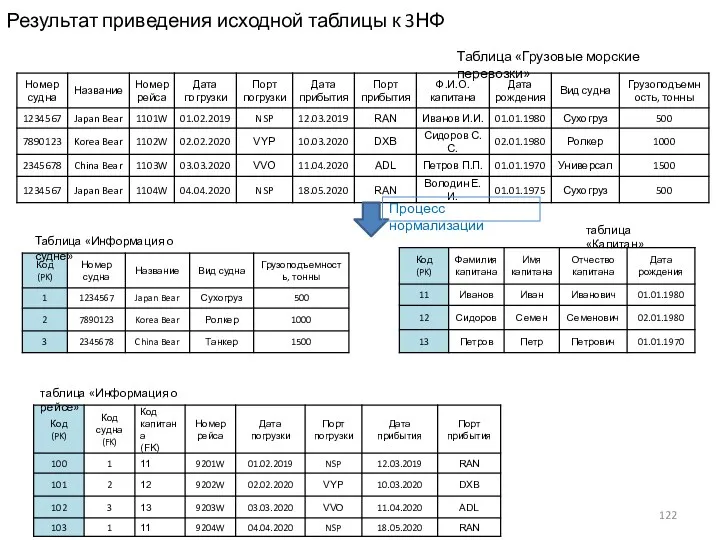
Результат приведения исходной таблицы к 3НФ
Таблица «Информация о судне»
таблица «Информация
Результат приведения исходной таблицы к 3НФ
Таблица «Информация о судне»
таблица «Информация
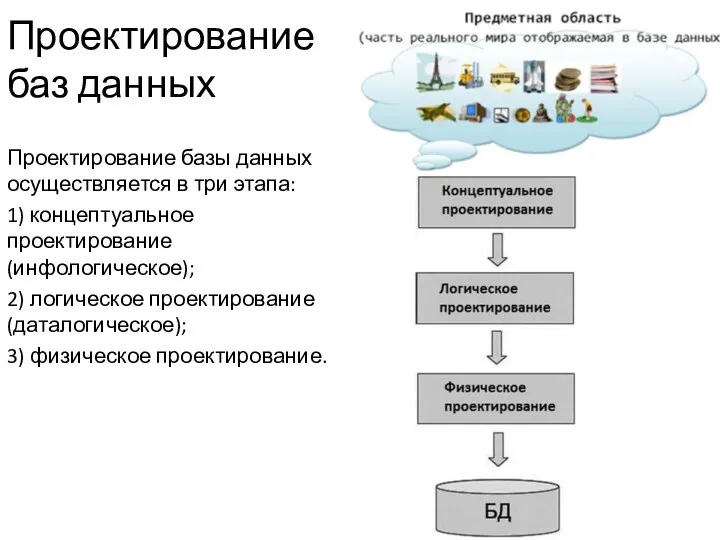
Проектирование баз данных
Проектирование базы данных осуществляется в три этапа:
1) концептуальное проектирование
Проектирование баз данных
Проектирование базы данных осуществляется в три этапа:
1) концептуальное проектирование

Концептуальное (инфологическое) проектирование
Цель – построение независимой от СУБД информационной структуры путем
Концептуальное (инфологическое) проектирование
Цель – построение независимой от СУБД информационной структуры путем
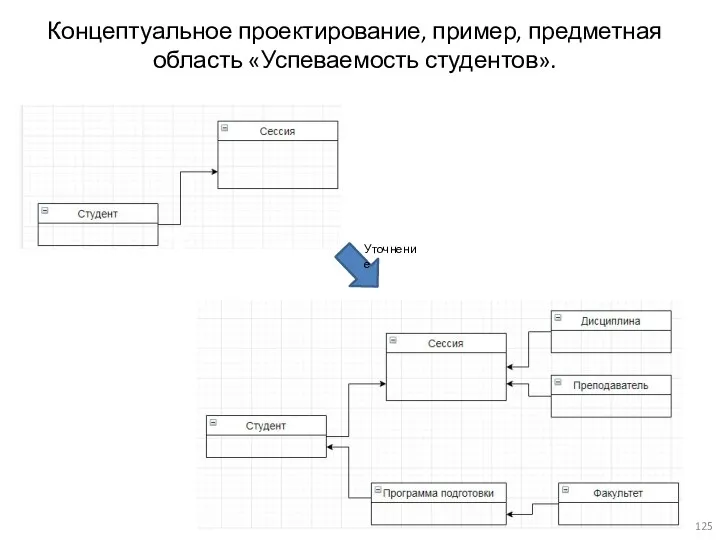
Концептуальное проектирование, пример, предметная область «Успеваемость студентов».
Уточнение
Концептуальное проектирование, пример, предметная область «Успеваемость студентов».
Уточнение
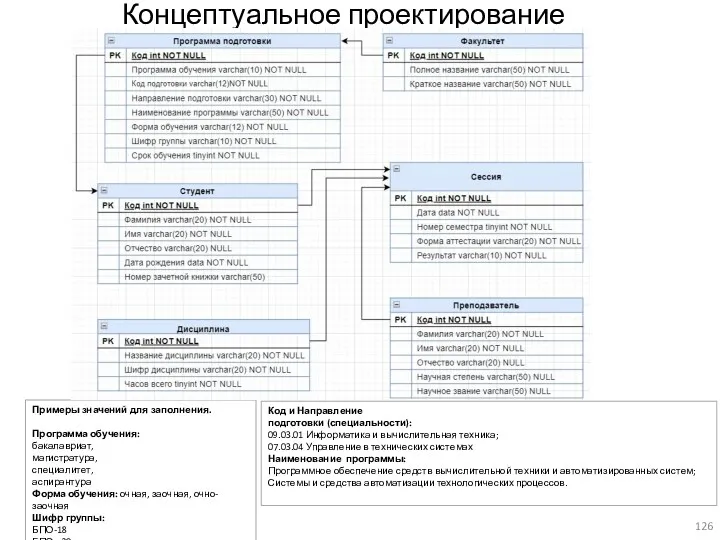
Концептуальное проектирование
Примеры значений для заполнения.
Программа обучения:
бакалавриат,
магистратура,
специалитет,
аспирантура
Форма обучения: очная, заочная, очно-заочная
Шифр группы:
БПО-18
БПОз-20
Код
Концептуальное проектирование
Примеры значений для заполнения.
Программа обучения:
бакалавриат,
магистратура,
специалитет,
аспирантура
Форма обучения: очная, заочная, очно-заочная
Шифр группы:
БПО-18
БПОз-20
Код

Логическое (даталогическое) проектирование
Цель – создание схемы базы данных на основе конкретной
Логическое (даталогическое) проектирование
Цель – создание схемы базы данных на основе конкретной
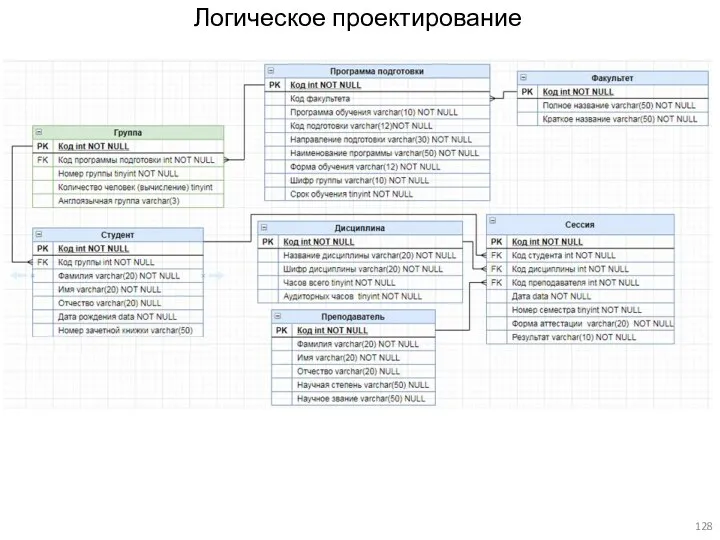
Логическое проектирование
Логическое проектирование

Физическое проектирование
Цель – создание схемы базы данных для конкретной СУБД.
Задачи:
Проектирование
Физическое проектирование
Цель – создание схемы базы данных для конкретной СУБД.
Задачи:
Проектирование
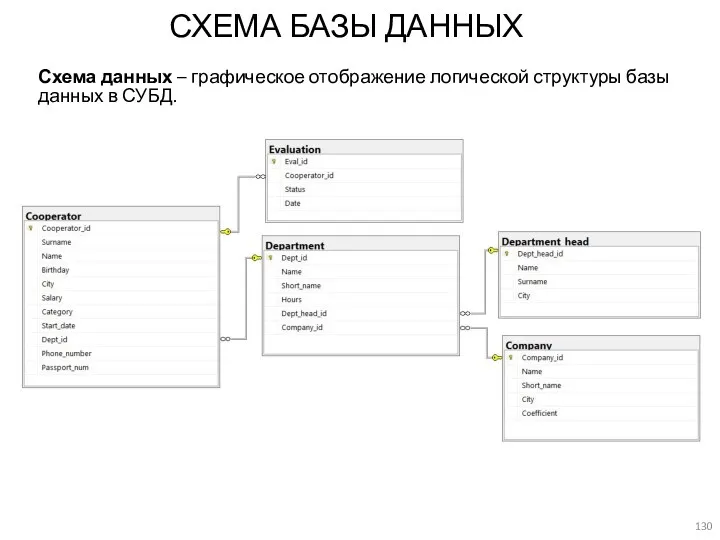
СХЕМА БАЗЫ ДАННЫХ
Схема данных – графическое отображение логической структуры базы данных
СХЕМА БАЗЫ ДАННЫХ
Схема данных – графическое отображение логической структуры базы данных
Представления/VIEW в SQL (Виртуальные таблицы)
Представления/VIEW или виртуальная таблица – это поименованная
Представления/VIEW в SQL (Виртуальные таблицы)
Представления/VIEW или виртуальная таблица – это поименованная
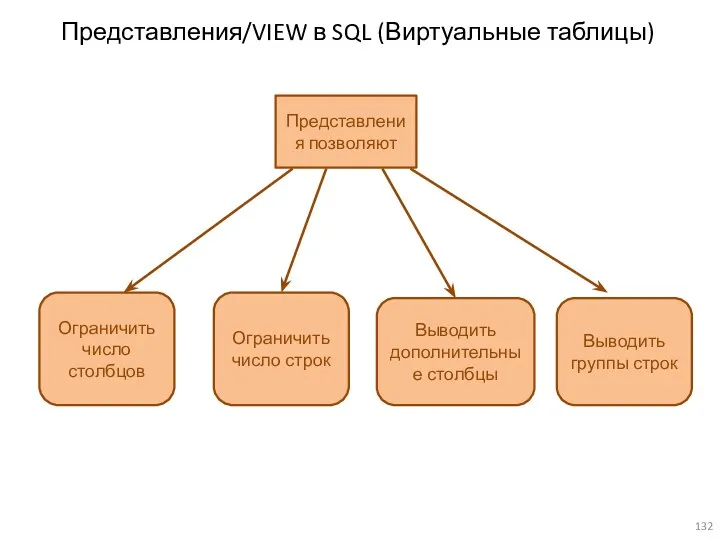
Представления/VIEW в SQL (Виртуальные таблицы)
Представления позволяют
Ограничить число столбцов
Ограничить число строк
Выводить
Представления/VIEW в SQL (Виртуальные таблицы)
Представления позволяют
Ограничить число столбцов
Ограничить число строк
Выводить
![Синтаксис: [CREATE|ALTER ] VIEW [(column_list)] [WITH {ENCRYPTION | SCHEMABINDING| VIEW_METADATA}]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-132.jpg)
Синтаксис:
[CREATE|ALTER ] VIEW [(column_list)]
[WITH {ENCRYPTION | SCHEMABINDING| VIEW_METADATA}]
AS
SELECT
FROM
Синтаксис:
[CREATE|ALTER ] VIEW
[WITH {ENCRYPTION | SCHEMABINDING| VIEW_METADATA}]
AS
SELECT
FROM

Представления/VIEW (Виртуальные таблицы)
Например, нужно создать представление для просмотра информации о студентах
Представления/VIEW (Виртуальные таблицы)
Например, нужно создать представление для просмотра информации о студентах
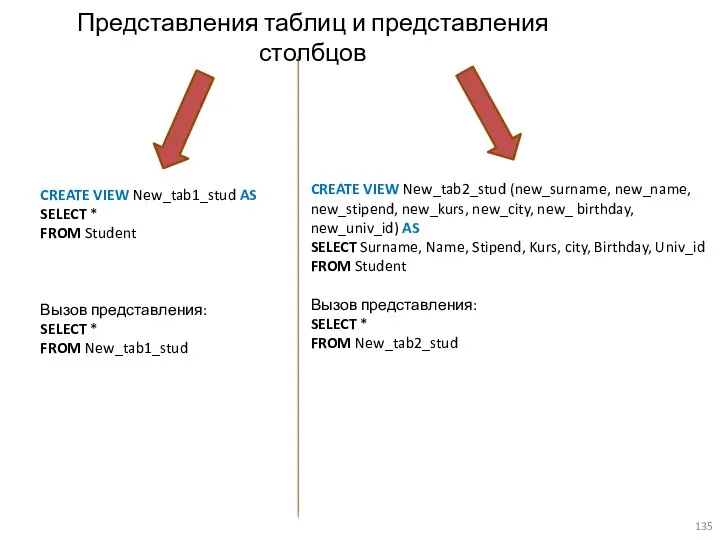
Представления таблиц и представления столбцов
CREATE VIEW New_tab1_stud AS
SELECT *
FROM
Представления таблиц и представления столбцов
CREATE VIEW New_tab1_stud AS
SELECT *
FROM

Представление с вложенным запросом, представление с группировкой
Задание: создайте представление, которое представит
Представление с вложенным запросом, представление с группировкой
Задание: создайте представление, которое представит

Представления c командами модификации
Создание представления Student_view:
CREATE VIEW Student_view
AS
SELECT Surname, Name, City,
Представления c командами модификации
Создание представления Student_view:
CREATE VIEW Student_view
AS
SELECT Surname, Name, City,

Применение команд модификации к представлениям, скрывающим поля
Создадим таблицу «Издательство»:
CREATE TABLE Publishing_house
(Id_publ
Применение команд модификации к представлениям, скрывающим поля
Создадим таблицу «Издательство»:
CREATE TABLE Publishing_house
(Id_publ

Представления/VIEW, скрывающие строки и команды модификации
Создание представления Publishing_house_view_more_than_5 :
CREATE VIEW Publishing_house_view_more_than_5
AS
SELECT
Представления/VIEW, скрывающие строки и команды модификации
Создание представления Publishing_house_view_more_than_5 :
CREATE VIEW Publishing_house_view_more_than_5
AS
SELECT

Агрегатные функции в представлениях
Представление для просмотра успеваемости:
CREATE VIEW Total_day
AS
SELECT Surname,
Агрегатные функции в представлениях
Представление для просмотра успеваемости:
CREATE VIEW Total_day
AS
SELECT Surname,

Представление для просмотра сколько сотрудников однофамильцев есть в каждом отделе:
CREATE VIEW
Представление для просмотра сколько сотрудников однофамильцев есть в каждом отделе:
CREATE VIEW

Модифицируемые и немодифицируемые представления
Модифицируемое представление — это представление, относительно которого можно применить
Модифицируемые и немодифицируемые представления
Модифицируемое представление — это представление, относительно которого можно применить

Пример, модифицируемого представления с оператором соединения JOIN
Создадим таблицу «Книга» для хранения
Пример, модифицируемого представления с оператором соединения JOIN
Создадим таблицу «Книга» для хранения
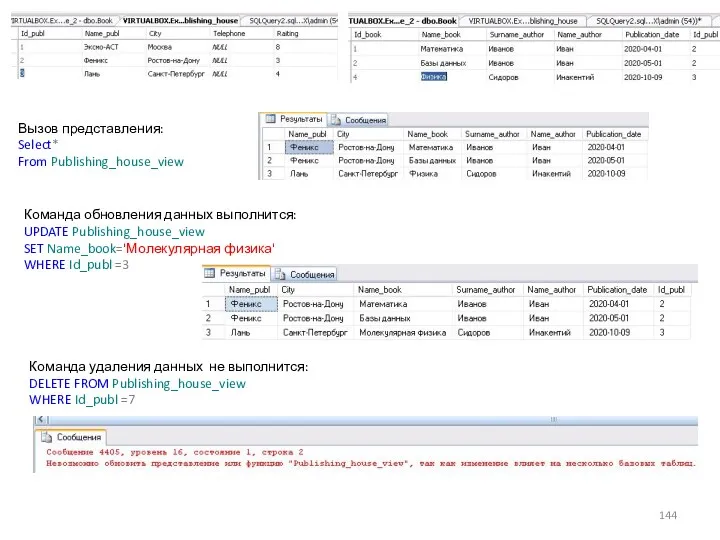
Команда обновления данных выполнится:
UPDATE Publishing_house_view
SET Name_book='Молекулярная физика'
WHERE Id_publ =3
Вызов представления:
Команда обновления данных выполнится:
UPDATE Publishing_house_view
SET Name_book='Молекулярная физика'
WHERE Id_publ =3
Вызов представления:

Команды изменения описания представления, удаления представления
ALTER VIEW <имя представления>
описание
Команды изменения описания представления, удаления представления
ALTER VIEW <имя представления>
описание

Оператор CASE позволяет осуществить проверку условий и возвратить в зависимости от
Оператор CASE позволяет осуществить проверку условий и возвратить в зависимости от
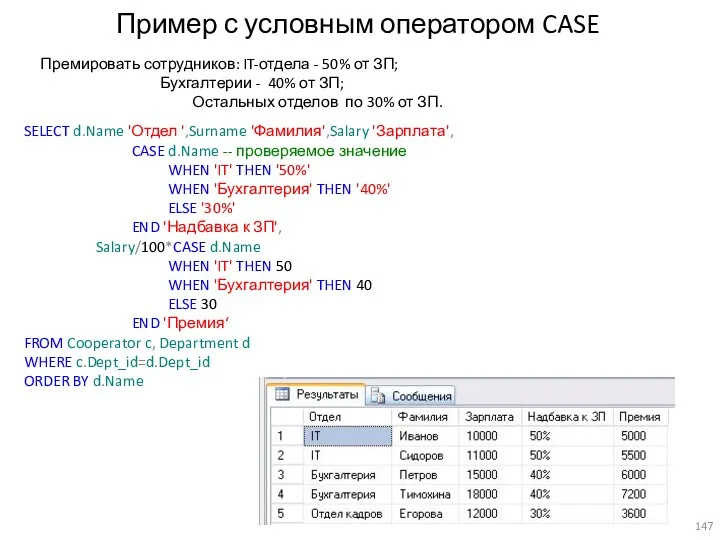
Пример с условным оператором CASE
Премировать сотрудников: IT-отдела - 50% от ЗП;
Пример с условным оператором CASE
Премировать сотрудников: IT-отдела - 50% от ЗП;

Пример с условным оператором CASE
Вывести средние оценки по студентам и расшифровать
Пример с условным оператором CASE
Вывести средние оценки по студентам и расшифровать
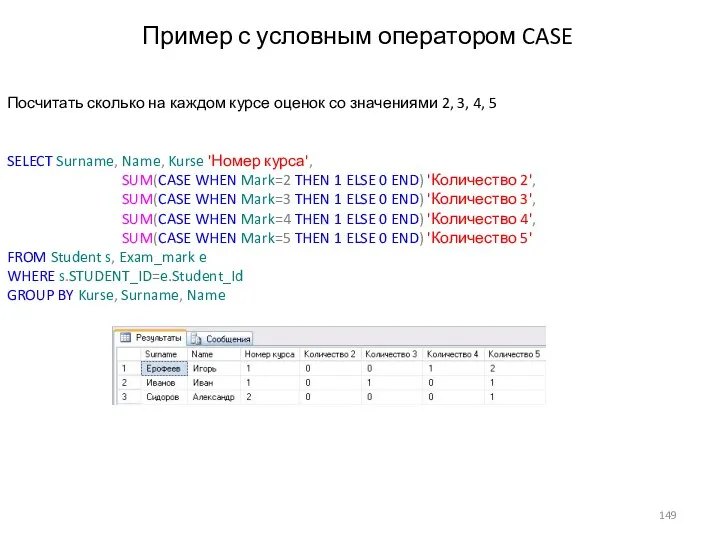
Посчитать сколько на каждом курсе оценок со значениями 2, 3, 4,
Посчитать сколько на каждом курсе оценок со значениями 2, 3, 4,

Задать имя и тип переменной в Transact-SQL можно с помощью оператора
Задать имя и тип переменной в Transact-SQL можно с помощью оператора

Оператор PRINT возвращает сообщение.
Синтаксис:
PRINT
Пример 1:
PRINT 'Вывод сообщения'
Пример 2:
DECLARE @Surname VARCHAR(20), @Order_date DATE,
Оператор PRINT возвращает сообщение.
Синтаксис:
PRINT
Пример 1:
PRINT 'Вывод сообщения'
Пример 2:
DECLARE @Surname VARCHAR(20), @Order_date DATE,

Условный оператор IF...ELSE
Конструкция IF...ELSE используется для наложения условий, определяющих, какие операторы T-SQL нужно выполнить.
Синтаксис:
IF Boolean_expression
{sql_statement
Условный оператор IF...ELSE
Конструкция IF...ELSE используется для наложения условий, определяющих, какие операторы T-SQL нужно выполнить.
Синтаксис:
IF Boolean_expression
{sql_statement
![Цикл в языке Transact-SQL Синтаксис: WHILE Boolean_expression {sql_statement|statement_block} [ BREAK]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-152.jpg)
Цикл в языке Transact-SQL
Синтаксис:
WHILE Boolean_expression
{sql_statement|statement_block}
[ BREAK]
{sql_statement|statement_block}
[CONTINUE}
END
Пример, представить, какой будет стипендия
Цикл в языке Transact-SQL
Синтаксис:
WHILE Boolean_expression
{sql_statement|statement_block}
[ BREAK]
{sql_statement|statement_block}
[CONTINUE}
END
Пример, представить, какой будет стипендия
Хранимые процедуры в Transact−SQL
Хранимая процедура (Stored Procedure) – это именованный набор
Хранимые процедуры в Transact−SQL
Хранимая процедура (Stored Procedure) – это именованный набор
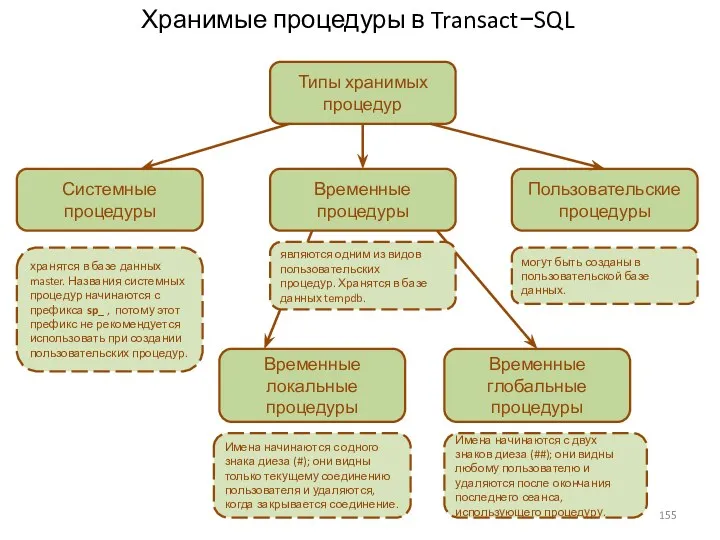
Хранимые процедуры в Transact−SQL
Типы хранимых процедур
Пользовательские процедуры
Временные процедуры
Системные процедуры
хранятся в
Хранимые процедуры в Transact−SQL
Типы хранимых процедур
Пользовательские процедуры
Временные процедуры
Системные процедуры
хранятся в
![Синтаксис создания (изменения) процедуры: {CREATE|ALTER} PROCEDURE|PROC procedure_name [; number] [{@name_paramet](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-155.jpg)
Синтаксис создания (изменения) процедуры:
{CREATE|ALTER} PROCEDURE|PROC procedure_name [; number]
[{@name_paramet data_type} [VARYING] [=DEFAULT][OUTPUT]][,...n]
[WITH
Синтаксис создания (изменения) процедуры:
{CREATE|ALTER} PROCEDURE|PROC procedure_name [; number]
[{@name_paramet data_type} [VARYING] [=DEFAULT][OUTPUT]][,...n]
[WITH
![Синтаксис удаления процедуры: DROP PROCEDURE {имя_процедуры} [,...n] Хранимые процедуры в](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-156.jpg)
Синтаксис удаления процедуры:
DROP PROCEDURE {имя_процедуры} [,...n]
Хранимые процедуры в Transact−SQL
Синтаксис вызова:
[EXECUTE|EXEC] имя_процедуры
Синтаксис удаления процедуры:
DROP PROCEDURE {имя_процедуры} [,...n]
Хранимые процедуры в Transact−SQL
Синтаксис вызова:
[EXECUTE|EXEC] имя_процедуры
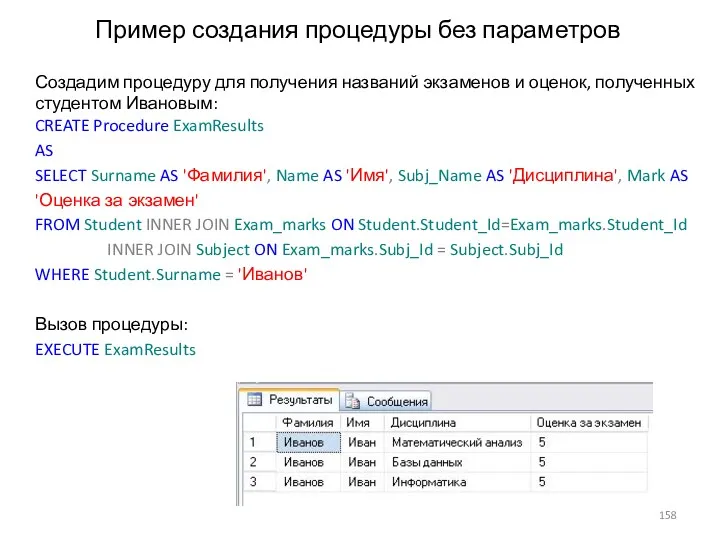
Пример создания процедуры без параметров
Создадим процедуру для получения названий экзаменов и
Пример создания процедуры без параметров
Создадим процедуру для получения названий экзаменов и
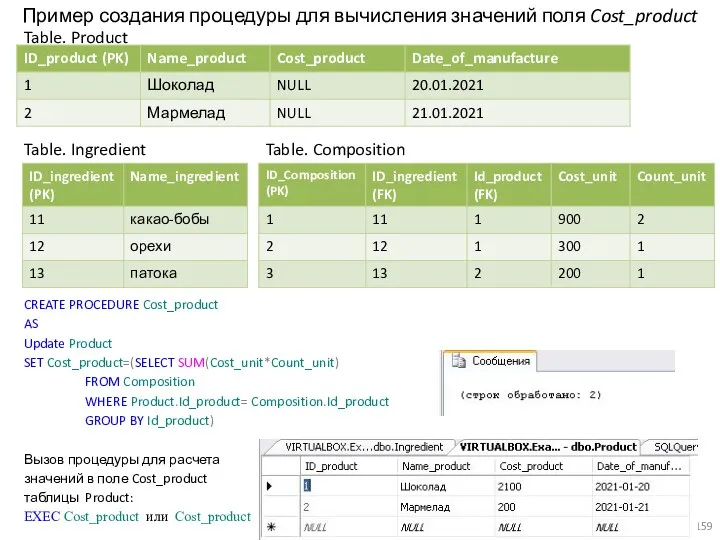
Пример создания процедуры для вычисления значений поля Cost_product
Table. Product
Table. Ingredient
CREATE
Пример создания процедуры для вычисления значений поля Cost_product
Table. Product
Table. Ingredient
CREATE

Пример создания процедуры с входным параметром
Создать процедуру для увеличения размера стипендии
Пример создания процедуры с входным параметром
Создать процедуру для увеличения размера стипендии

Пример создания процедуры с входными параметрами
Создать процедуру для выдачи списка студентов,
Пример создания процедуры с входными параметрами
Создать процедуру для выдачи списка студентов,

Создать процедуру для подсчета числа студентов, сдававших экзамен по дисциплине у
Создать процедуру для подсчета числа студентов, сдававших экзамен по дисциплине у

Получение информации о процедурах
Системные процедуры:
1) sp_help
Синтаксис: sp_help proc1
2) sp_helptext
Синтаксис: sp_helptext proc1
Например,
Получение информации о процедурах
Системные процедуры:
1) sp_help
Синтаксис: sp_help proc1
2) sp_helptext
Синтаксис: sp_helptext proc1
Например,

Пользовательские функции (User Defined Functions, UDF) в Transact-SQL
CREATE PROCEDURE Count_student_proc
@count SMALLINT
Пользовательские функции (User Defined Functions, UDF) в Transact-SQL
CREATE PROCEDURE Count_student_proc
@count SMALLINT

Пользовательские функции (User defined functions, UDF) Transact-SQL
Поддерживаются следующие типы пользовательских функций:
1)
Пользовательские функции (User defined functions, UDF) Transact-SQL
Поддерживаются следующие типы пользовательских функций:
1)
![Скалярные функции (Scalar) в Transact-SQL {CREATE | ALTER} FUNCTION [владелец.]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-165.jpg)
Скалярные функции (Scalar) в Transact-SQL
{CREATE | ALTER} FUNCTION [владелец.] имя_функции
([{@имя_параметра
Скалярные функции (Scalar) в Transact-SQL
{CREATE | ALTER} FUNCTION [владелец.] имя_функции
([{@имя_параметра

Скалярные функции (Scalar) в Transact-SQL
Например, создание скалярной функции для подсчета количества
Скалярные функции (Scalar) в Transact-SQL
Например, создание скалярной функции для подсчета количества
![Табличные функции (Inline)в Transact-SQL {CREATE | ALTER } FUNCTION [владелец.]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-167.jpg)
Табличные функции (Inline)в Transact-SQL
{CREATE | ALTER } FUNCTION [владелец.] имя_функции
([{ @имя_параметра
Табличные функции (Inline)в Transact-SQL
{CREATE | ALTER } FUNCTION [владелец.] имя_функции
([{ @имя_параметра

Табличные функции (Inline)в Transact-SQL
Пример, функции табличного типа для определения двух дисциплин
Табличные функции (Inline)в Transact-SQL
Пример, функции табличного типа для определения двух дисциплин
![Многооператорные функции (Multi-statement)в Transact-SQL {CREATE | ALTER }FUNCTION [владелец.] имя_функции](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-169.jpg)
Многооператорные функции (Multi-statement)в Transact-SQL
{CREATE | ALTER }FUNCTION [владелец.] имя_функции
([{ @имя_параметра скалярый_тип_данных
Многооператорные функции (Multi-statement)в Transact-SQL
{CREATE | ALTER }FUNCTION [владелец.] имя_функции
([{ @имя_параметра скалярый_тип_данных
![Многооператорные функции (Multi-statement)в Transact-SQL CREATE FUNCTION [dbo].[get_FIO_student]() RETURNS @fio_sudent TABLE](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-170.jpg)
Многооператорные функции (Multi-statement)в Transact-SQL
CREATE FUNCTION [dbo].[get_FIO_student]()
RETURNS @fio_sudent TABLE (ФИО varchar(50), [Дата
Многооператорные функции (Multi-statement)в Transact-SQL
CREATE FUNCTION [dbo].[get_FIO_student]()
RETURNS @fio_sudent TABLE (ФИО varchar(50), [Дата
![Удаление пользовательской функции в Transact−SQL Синтаксис удаления функции: DROP FUNCTION {[владелец.] имя_функции} [,...n]]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-171.jpg)
Удаление пользовательской функции в Transact−SQL
Синтаксис удаления функции:
DROP FUNCTION {[владелец.] имя_функции} [,...n]]
Удаление пользовательской функции в Transact−SQL
Синтаксис удаления функции:
DROP FUNCTION {[владелец.] имя_функции} [,...n]]
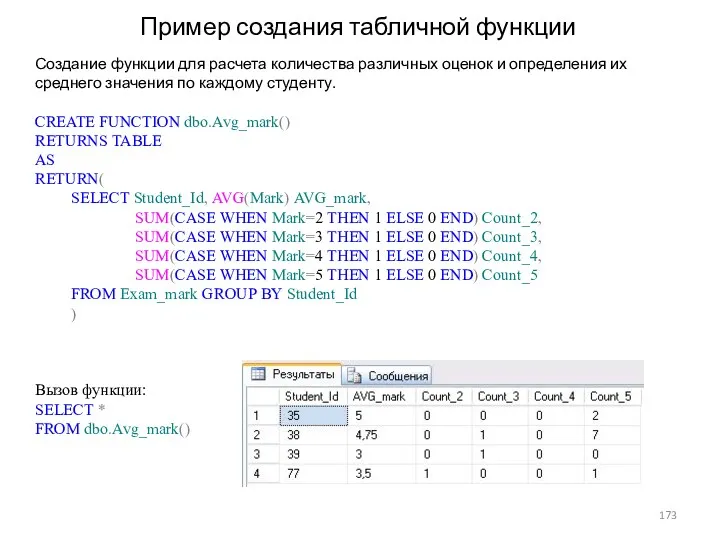
Пример создания табличной функции
Создание функции для расчета количества различных оценок и
Пример создания табличной функции
Создание функции для расчета количества различных оценок и
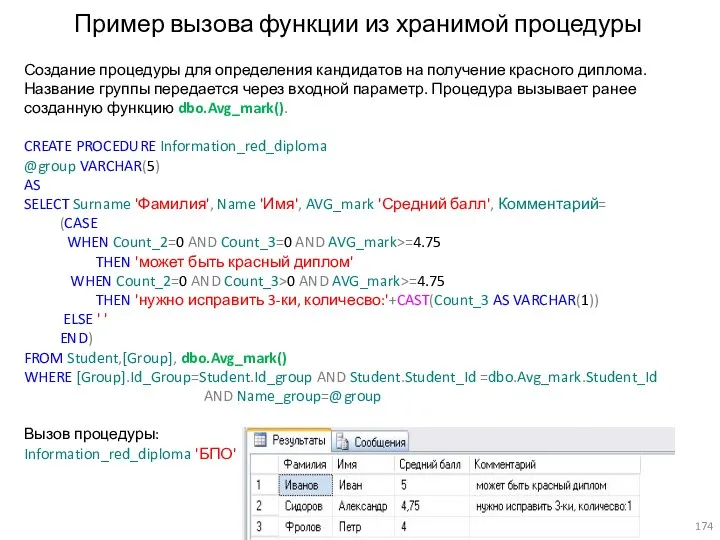
Пример вызова функции из хранимой процедуры
Создание процедуры для определения кандидатов на
Пример вызова функции из хранимой процедуры
Создание процедуры для определения кандидатов на
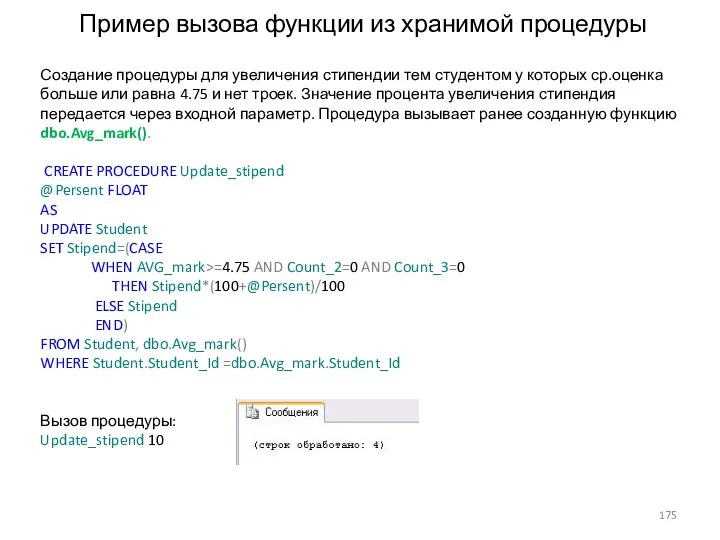
Пример вызова функции из хранимой процедуры
Создание процедуры для увеличения стипендии тем
Пример вызова функции из хранимой процедуры
Создание процедуры для увеличения стипендии тем
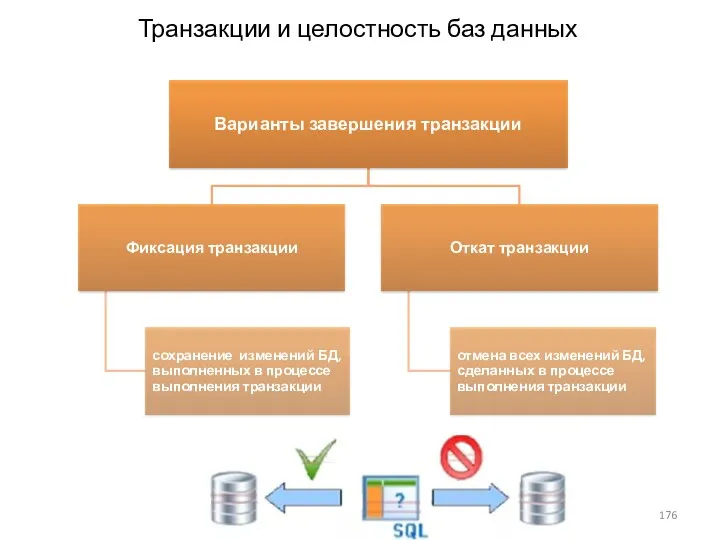
Транзакции и целостность баз данных
Транзакции и целостность баз данных

Пример
CREATE TABLE Bank_account
(Id INT PRIMARY KEY IDENTITY(1,1),
Number_account decimal(10,0),
Balance float)
INSERT INTO Bank_account
VALUES(101,
Пример
CREATE TABLE Bank_account
(Id INT PRIMARY KEY IDENTITY(1,1),
Number_account decimal(10,0),
Balance float)
INSERT INTO Bank_account
VALUES(101,
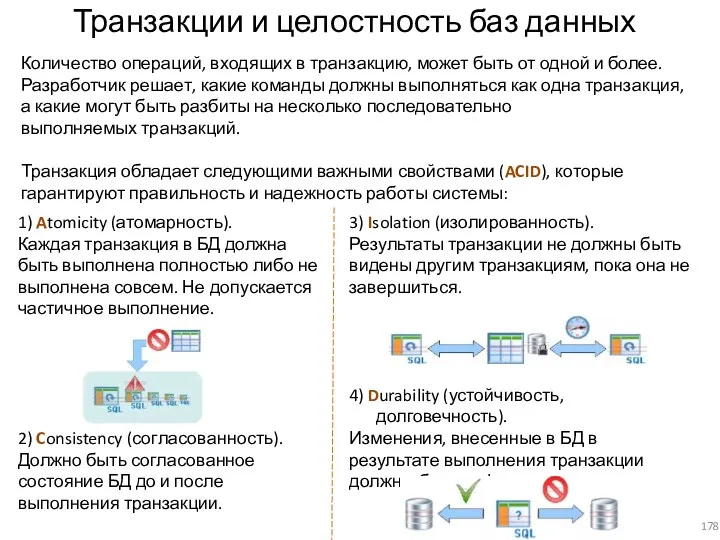
3) Isolation (изолированность).
Результаты транзакции не должны быть видены другим транзакциям,
3) Isolation (изолированность).
Результаты транзакции не должны быть видены другим транзакциям,
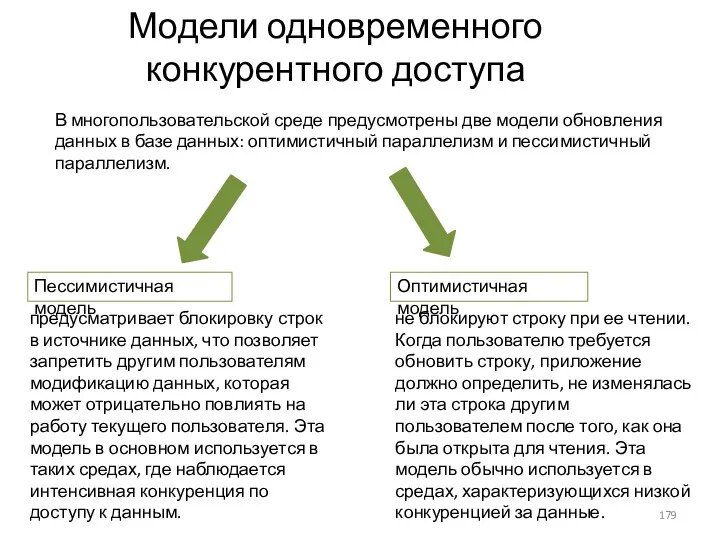
Модели одновременного конкурентного доступа
Пессимистичная модель
Оптимистичная модель
В многопользовательской среде предусмотрены две модели
Модели одновременного конкурентного доступа
Пессимистичная модель
Оптимистичная модель
В многопользовательской среде предусмотрены две модели
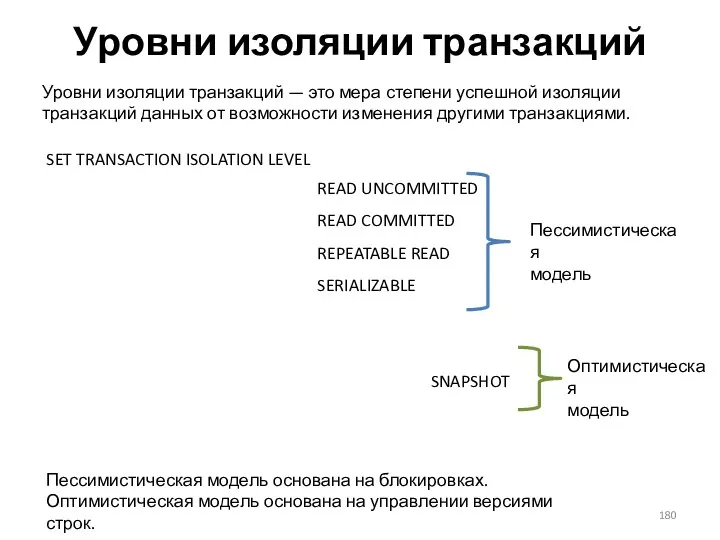
Уровни изоляции транзакций
Уровни изоляции транзакций — это мера степени успешной изоляции
Уровни изоляции транзакций
Уровни изоляции транзакций — это мера степени успешной изоляции

Уровень изоляции READ UNCOMMITTED
Клиент 1 выполняет транзакцию:
BEGIN TRANSACTION
UPDATE Bank_account
SET Balance
Уровень изоляции READ UNCOMMITTED
Клиент 1 выполняет транзакцию:
BEGIN TRANSACTION
UPDATE Bank_account
SET Balance
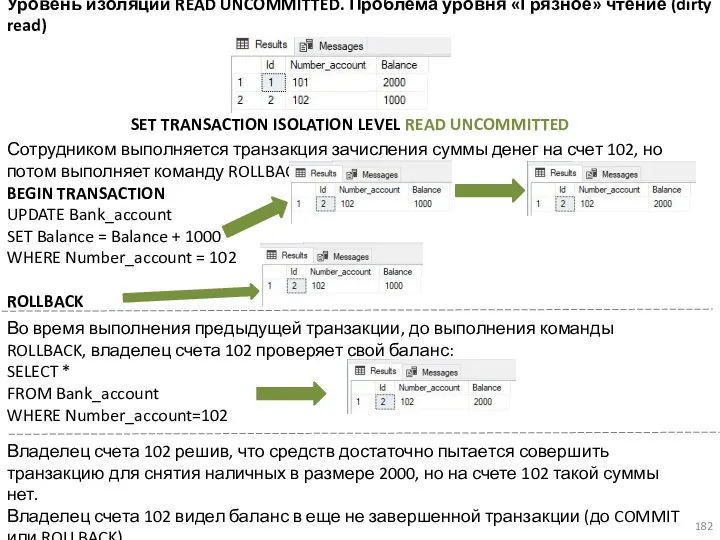
Владелец счета 102 решив, что средств достаточно пытается совершить транзакцию для
Владелец счета 102 решив, что средств достаточно пытается совершить транзакцию для

Уровень изоляции READ COMMITTED
Владелец счета 102 не может узнать свой баланс,
Уровень изоляции READ COMMITTED
Владелец счета 102 не может узнать свой баланс,
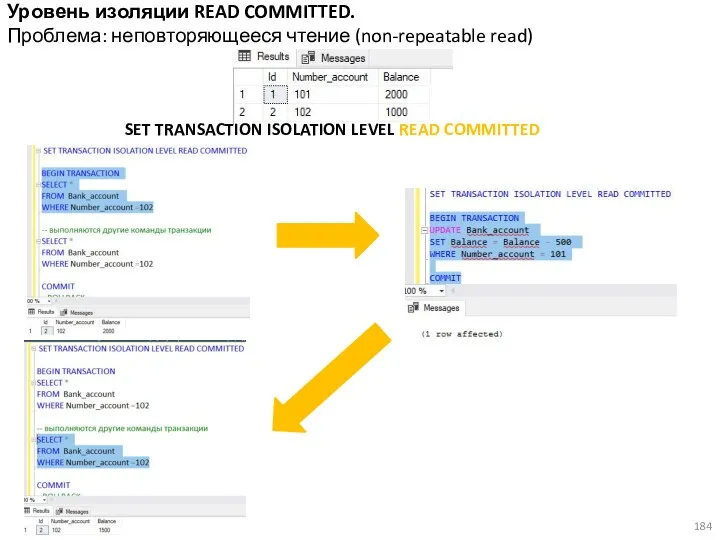
Уровень изоляции READ COMMITTED.
Проблема: неповторяющееся чтение (non-repeatable read)
SET TRANSACTION ISOLATION
Уровень изоляции READ COMMITTED.
Проблема: неповторяющееся чтение (non-repeatable read)
SET TRANSACTION ISOLATION

Уровень изоляции REPEATABLE READ
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
Уровень изоляции REPEATABLE READ
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ

Уровень изоляции REPEATABLE READ.
Проблема: фантомное чтение (phantom reads)
SET TRANSACTION
Уровень изоляции REPEATABLE READ.
Проблема: фантомное чтение (phantom reads)
SET TRANSACTION
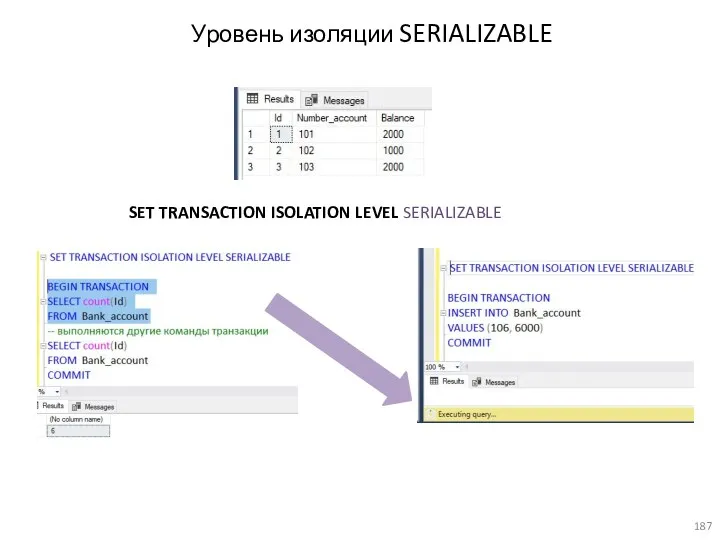
Уровень изоляции SERIALIZABLE
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
Уровень изоляции SERIALIZABLE
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
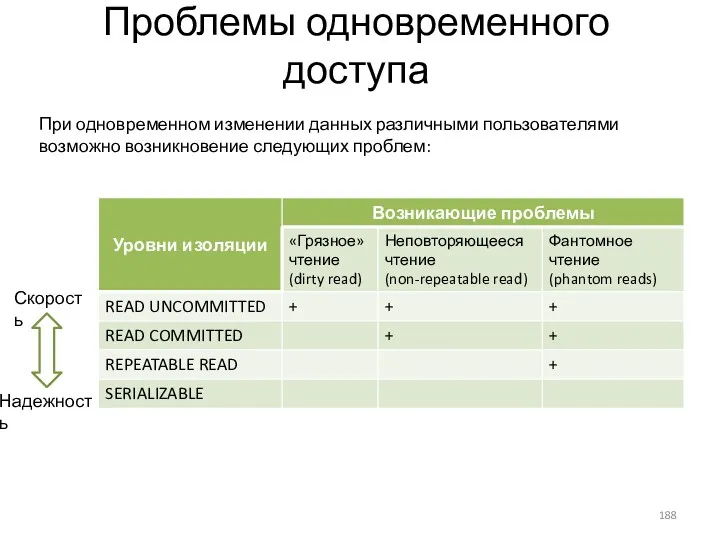
Проблемы одновременного доступа
При одновременном изменении данных различными пользователями возможно возникновение следующих
Проблемы одновременного доступа
При одновременном изменении данных различными пользователями возможно возникновение следующих
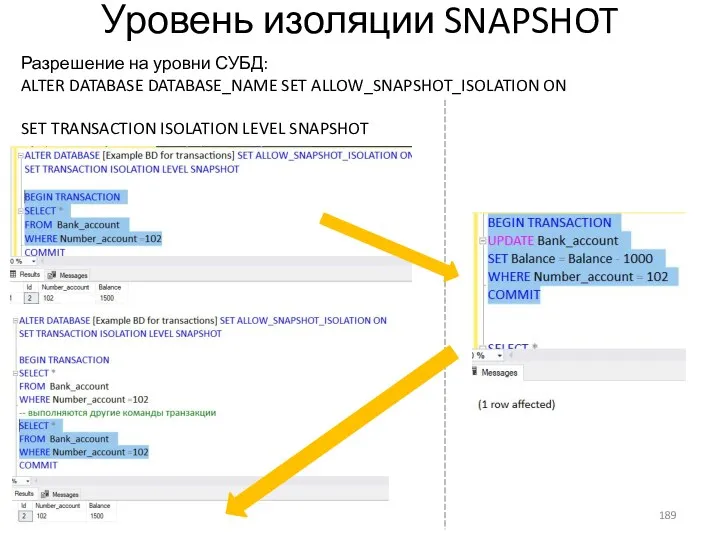
Уровень изоляции SNAPSHOT
Разрешение на уровни СУБД:
ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON
SET
Уровень изоляции SNAPSHOT
Разрешение на уровни СУБД:
ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON
SET
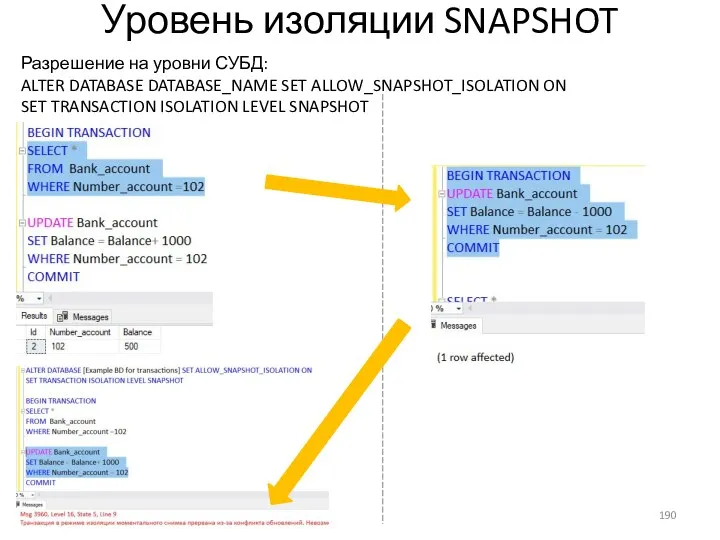
Уровень изоляции SNAPSHOT
Разрешение на уровни СУБД:
ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON
SET
Уровень изоляции SNAPSHOT
Разрешение на уровни СУБД:
ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON
SET
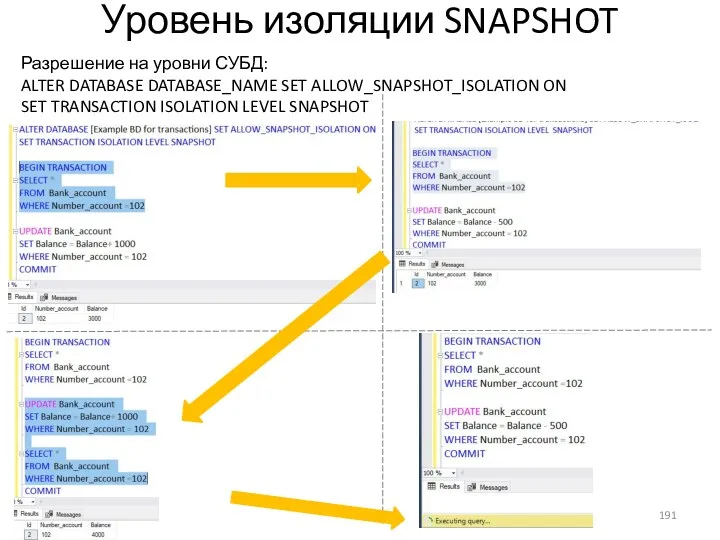
Уровень изоляции SNAPSHOT
Разрешение на уровни СУБД:
ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON
SET
Уровень изоляции SNAPSHOT
Разрешение на уровни СУБД:
ALTER DATABASE DATABASE_NAME SET ALLOW_SNAPSHOT_ISOLATION ON
SET

Журнал транзакций (Write-Ahead Logging (WAL))
Во всех случаях придерживаются стратегии "упреждающей" записи
Журнал транзакций (Write-Ahead Logging (WAL))
Во всех случаях придерживаются стратегии "упреждающей" записи
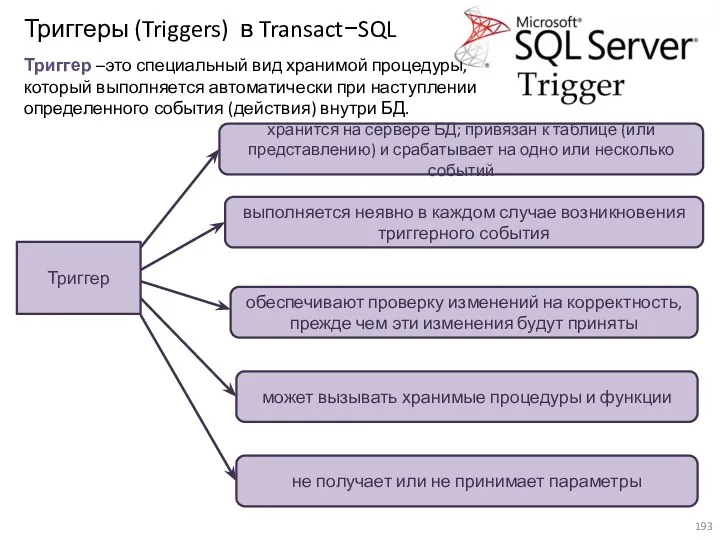
Триггеры (Triggers) в Transact−SQL
Триггер –это специальный вид хранимой процедуры, который выполняется
Триггеры (Triggers) в Transact−SQL
Триггер –это специальный вид хранимой процедуры, который выполняется

Триггеры (Triggers) в Transact−SQL
События:
INSERT – определяет действия, которые будут выполняться после
Триггеры (Triggers) в Transact−SQL
События:
INSERT – определяет действия, которые будут выполняться после

Синтаксис создания/изменения триггера
Основной формат команды:
{CREATE | ALTER} TRIGGER [имя_триггера]
ON имя_таблицы
{FOR
Синтаксис создания/изменения триггера
Основной формат команды:
{CREATE | ALTER} TRIGGER [имя_триггера]
ON имя_таблицы
{FOR

Триггеры и виртуальные таблицы deleted и inserted
Таблицы deleted и inserted создаются
Триггеры и виртуальные таблицы deleted и inserted
Таблицы deleted и inserted создаются
![Синтаксис удаления триггера DROP TRIGGER {имя_триггера} [,...n].](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/612142/slide-196.jpg)
Синтаксис удаления триггера
DROP TRIGGER {имя_триггера} [,...n].
Синтаксис удаления триггера
DROP TRIGGER {имя_триггера} [,...n].
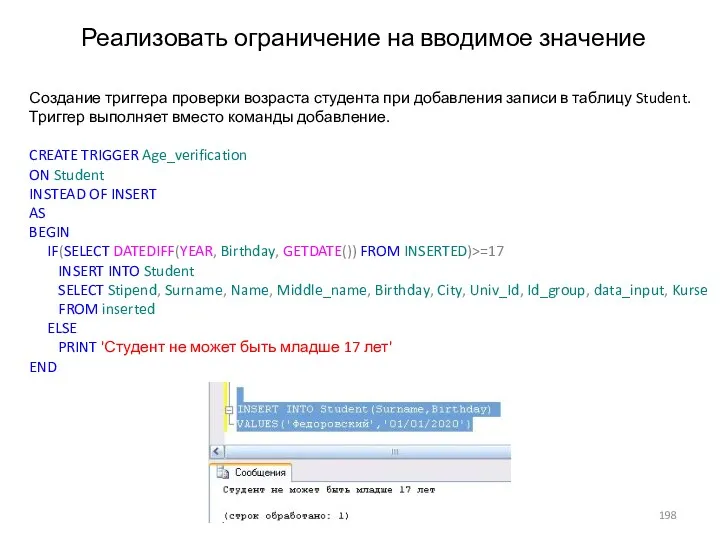
Реализовать ограничение на вводимое значение
Создание триггера проверки возраста студента при добавления
Реализовать ограничение на вводимое значение
Создание триггера проверки возраста студента при добавления

Триггер сохраняющий дату последнего изменения записи в таблице Student
CREATE TRIGGER Update_time_in_the_column
ON
Триггер сохраняющий дату последнего изменения записи в таблице Student
CREATE TRIGGER Update_time_in_the_column
ON

Триггер запрещающий изменение значения поля Mark и Exam_Date
RAISERROR – системная функция,
Триггер запрещающий изменение значения поля Mark и Exam_Date
RAISERROR – системная функция,

Триггер, не допускающий добавление более трех записей о результатах сдачи по
Триггер, не допускающий добавление более трех записей о результатах сдачи по

Триггер перемещает удаленную запись из таблицы Student в архивную таблицу Archive_delete
CREATE
Триггер перемещает удаленную запись из таблицы Student в архивную таблицу Archive_delete
CREATE
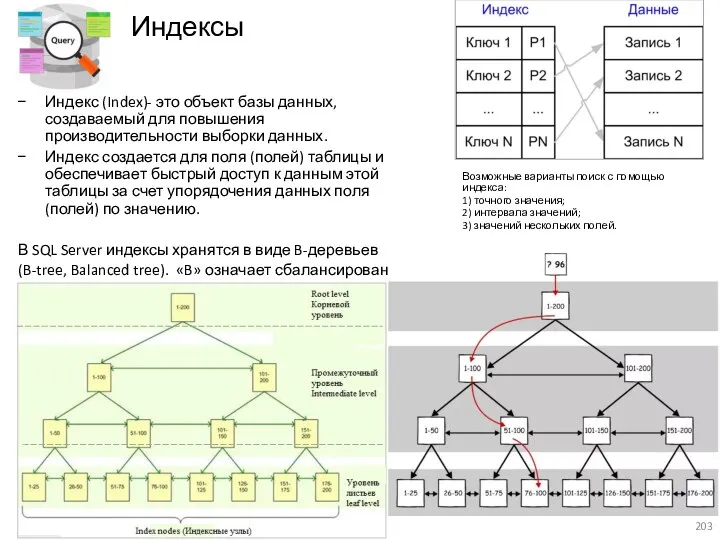
Индексы
Индекс (Index)- это объект базы данных, создаваемый для повышения производительности выборки
Индексы
Индекс (Index)- это объект базы данных, создаваемый для повышения производительности выборки
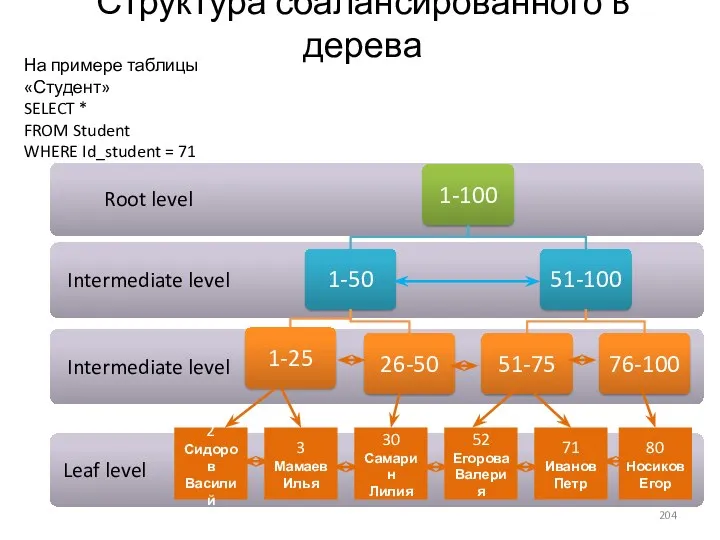
Структура сбалансированного B дерева
На примере таблицы «Студент»
SELECT *
FROM Student
WHERE Id_student
Структура сбалансированного B дерева
На примере таблицы «Студент»
SELECT *
FROM Student
WHERE Id_student

Способы задания индекса
1) Автоматическое создание индекса при добавлении ограничения первичного ключа
Способы задания индекса
1) Автоматическое создание индекса при добавлении ограничения первичного ключа

Создание индексов в MS SQL Server
Команда создания индекса для таблицы CREATE
Создание индексов в MS SQL Server
Команда создания индекса для таблицы CREATE

Увидеть индексы в таблице
EXECUTE sp_helpindex name_table
Пример, EXECUTE sp_helpindex Student
SELECT *
FROM
Увидеть индексы в таблице
EXECUTE sp_helpindex name_table
Пример, EXECUTE sp_helpindex Student
SELECT *
FROM
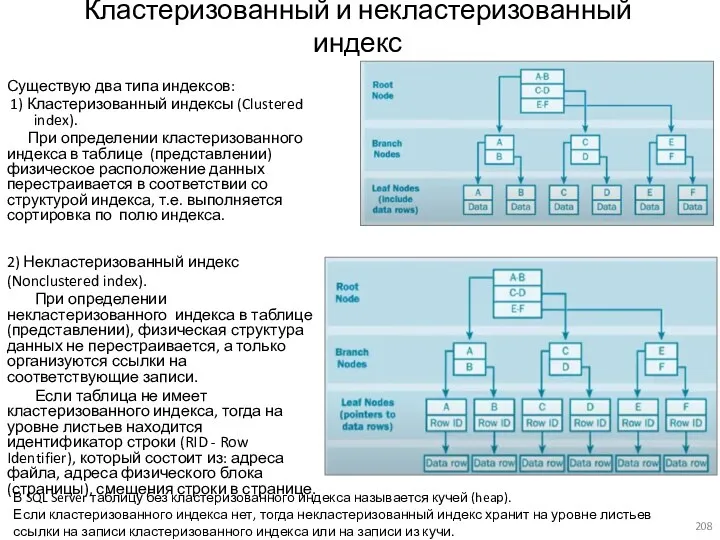
2) Некластеризованный индекс
(Nonclustered index).
При определении некластеризованного индекса в таблице
2) Некластеризованный индекс
(Nonclustered index).
При определении некластеризованного индекса в таблице
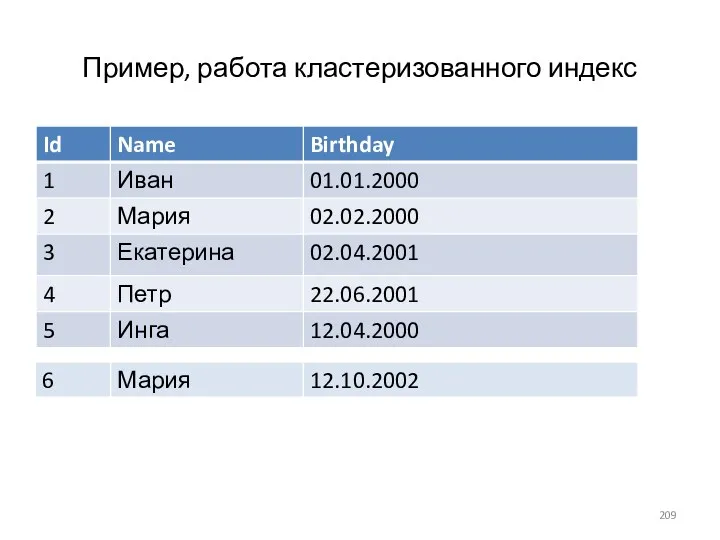
Пример, работа кластеризованного индекс
Пример, работа кластеризованного индекс
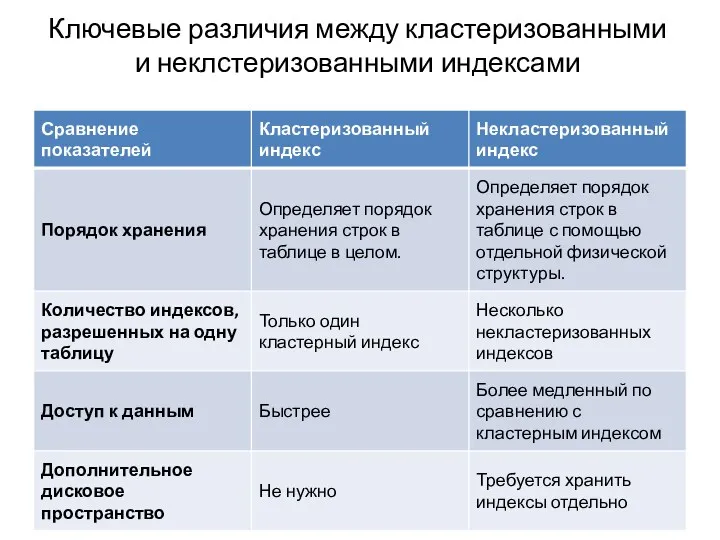
Ключевые различия между кластеризованными и неклстеризованными индексами
Ключевые различия между кластеризованными и неклстеризованными индексами
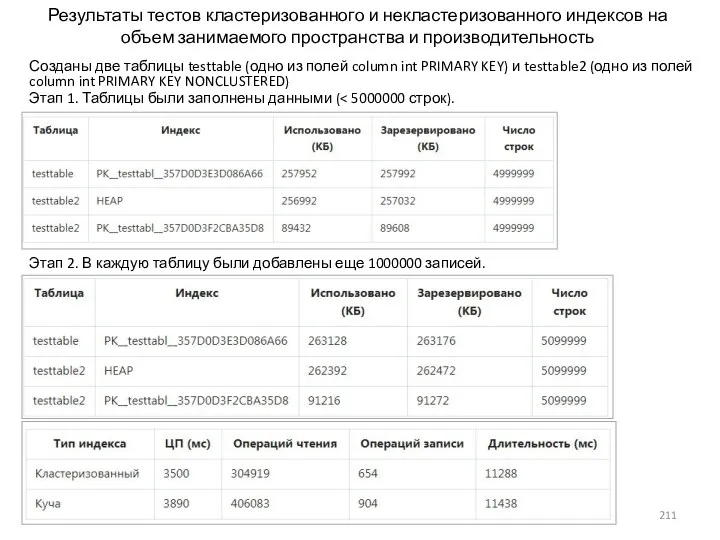
Результаты тестов кластеризованного и некластеризованного индексов на объем занимаемого пространства и
Результаты тестов кластеризованного и некластеризованного индексов на объем занимаемого пространства и
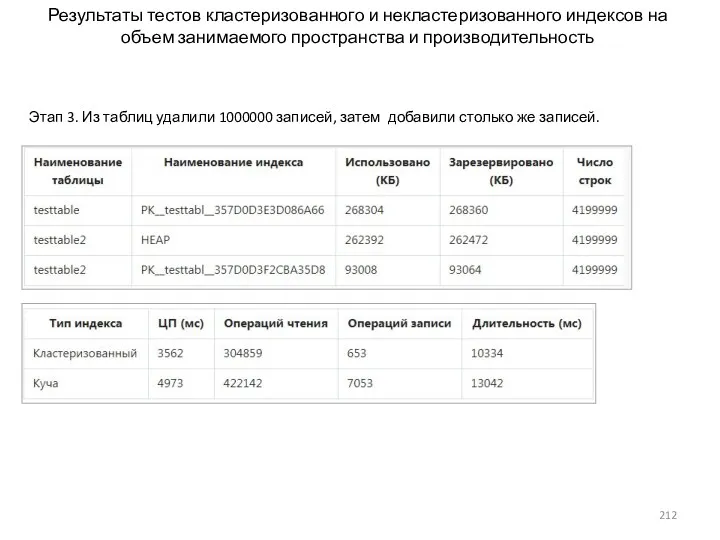
Результаты тестов кластеризованного и некластеризованного индексов на объем занимаемого пространства и
Результаты тестов кластеризованного и некластеризованного индексов на объем занимаемого пространства и
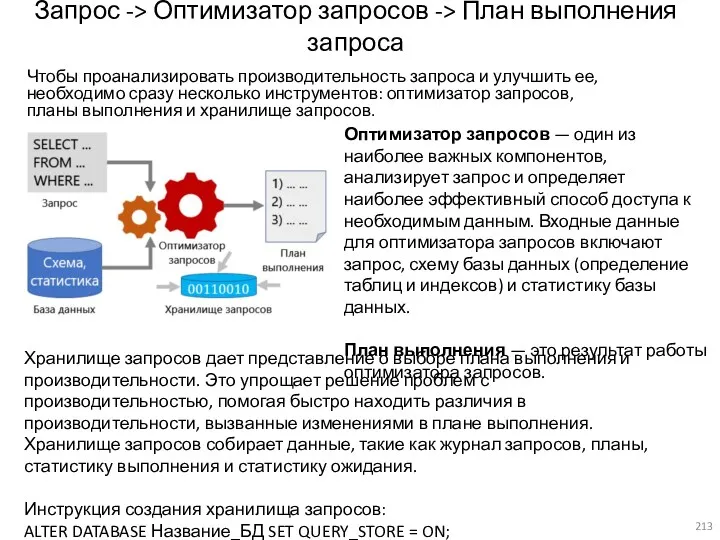
Запрос -> Оптимизатор запросов -> План выполнения запроса
Чтобы проанализировать производительность запроса
Запрос -> Оптимизатор запросов -> План выполнения запроса
Чтобы проанализировать производительность запроса

Оптимизация БД и СУБД
Основных рекомендации по оптимизации БД и СУБД:
перестройка/реорганизация индексов;
очистка
Оптимизация БД и СУБД
Основных рекомендации по оптимизации БД и СУБД:
перестройка/реорганизация индексов;
очистка

Статистика
Системная процедура для обновления статистики:
sp_updatestats
Команда обновления статистики для определенной таблицы:
Статистика
Системная процедура для обновления статистики:
sp_updatestats
Команда обновления статистики для определенной таблицы:

Перестройка индекса/реорганизация индекса
Команды в SQL Server для борьбы с фрагментацией индексов:
Перестройка индекса/реорганизация индекса
Команды в SQL Server для борьбы с фрагментацией индексов:

Очистка кэш плана
Синтаксис для SQL Server:
DBCC FREEPROCCACHE
Подавление вывода всех регулярных информационных
Очистка кэш плана
Синтаксис для SQL Server:
DBCC FREEPROCCACHE
Подавление вывода всех регулярных информационных

Оптимизация структуры таблиц
Рекомендации:
При создании таблиц выбирать выбирайте самый маленький из допустимых типов
Оптимизация структуры таблиц
Рекомендации:
При создании таблиц выбирать выбирайте самый маленький из допустимых типов
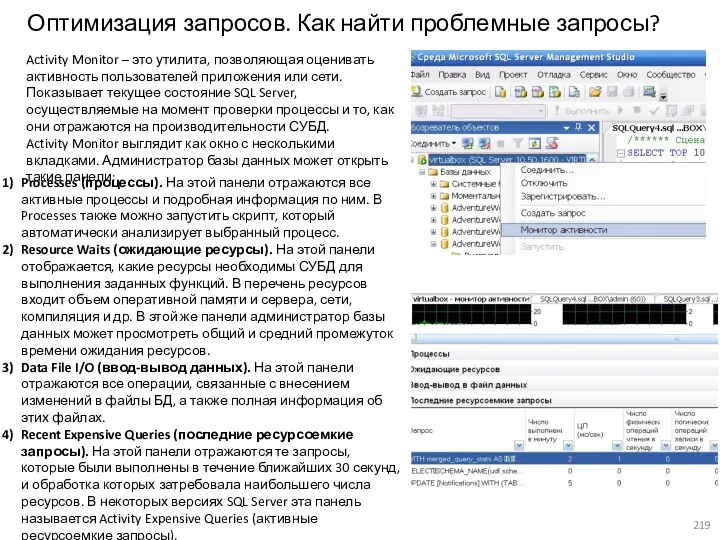
Оптимизация запросов. Как найти проблемные запросы?
Activity Monitor – это утилита,
Оптимизация запросов. Как найти проблемные запросы?
Activity Monitor – это утилита,
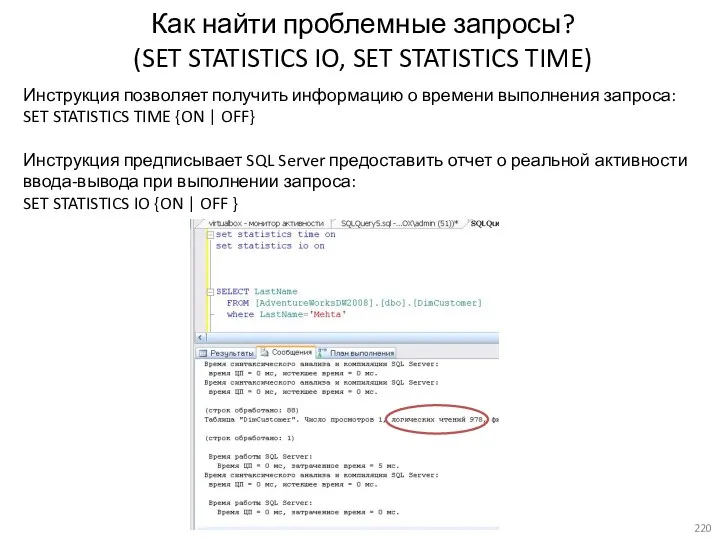
Как найти проблемные запросы?
(SET STATISTICS IO, SET STATISTICS TIME)
Инструкция позволяет
Как найти проблемные запросы?
(SET STATISTICS IO, SET STATISTICS TIME)
Инструкция позволяет

Оптимизация запросов
Рекомендации:
Кроме тех случаев, когда индекс создается автоматически, индексы можно добавить
Оптимизация запросов
Рекомендации:
Кроме тех случаев, когда индекс создается автоматически, индексы можно добавить
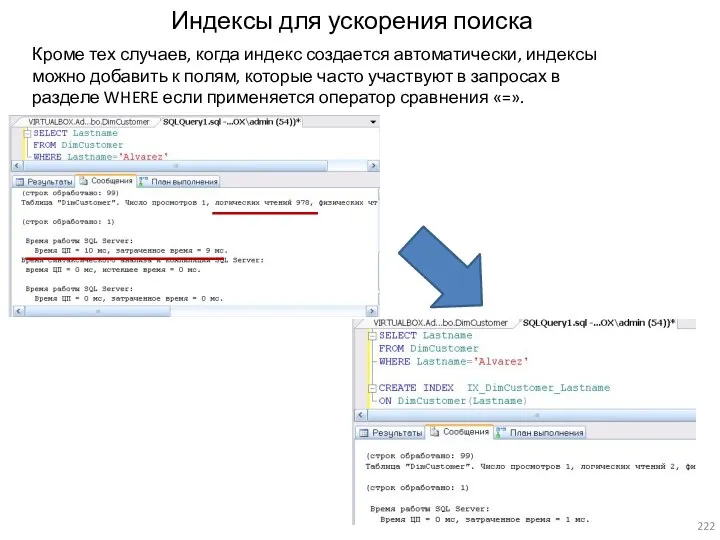
Индексы для ускорения поиска
Кроме тех случаев, когда индекс создается автоматически, индексы
Индексы для ускорения поиска
Кроме тех случаев, когда индекс создается автоматически, индексы
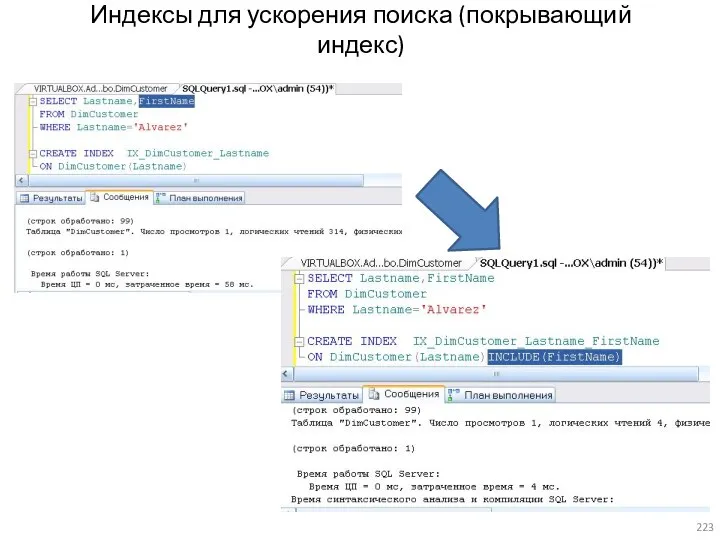
Индексы для ускорения поиска (покрывающий индекс)
Индексы для ускорения поиска (покрывающий индекс)
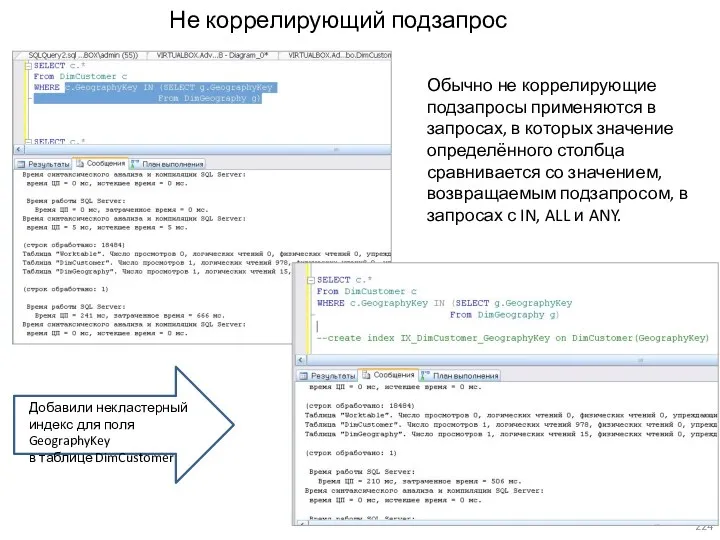
Не коррелирующий подзапрос
Обычно не коррелирующие подзапросы применяются в запросах, в которых
Не коррелирующий подзапрос
Обычно не коррелирующие подзапросы применяются в запросах, в которых
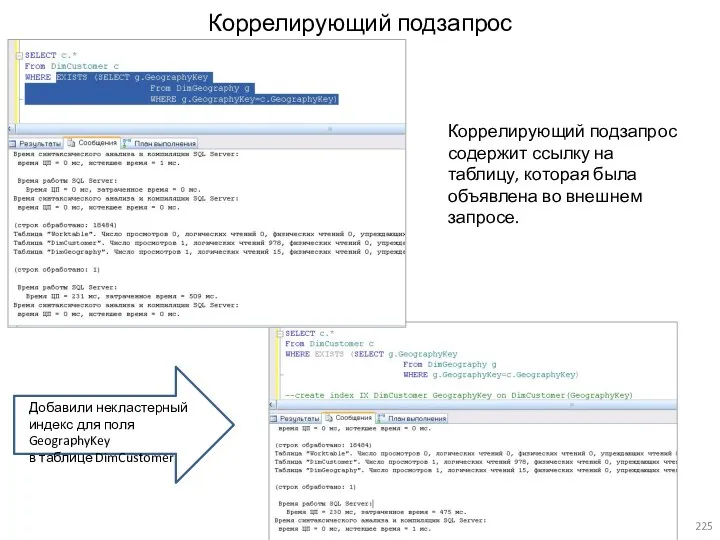
Коррелирующий подзапрос
Коррелирующий подзапрос содержит ссылку на таблицу, которая была объявлена во
Коррелирующий подзапрос
Коррелирующий подзапрос содержит ссылку на таблицу, которая была объявлена во
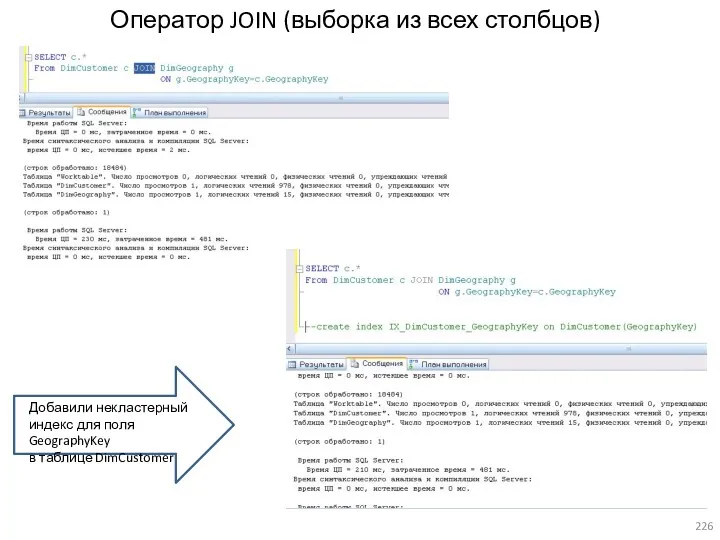
Оператор JOIN (выборка из всех столбцов)
Оператор JOIN (выборка из всех столбцов)
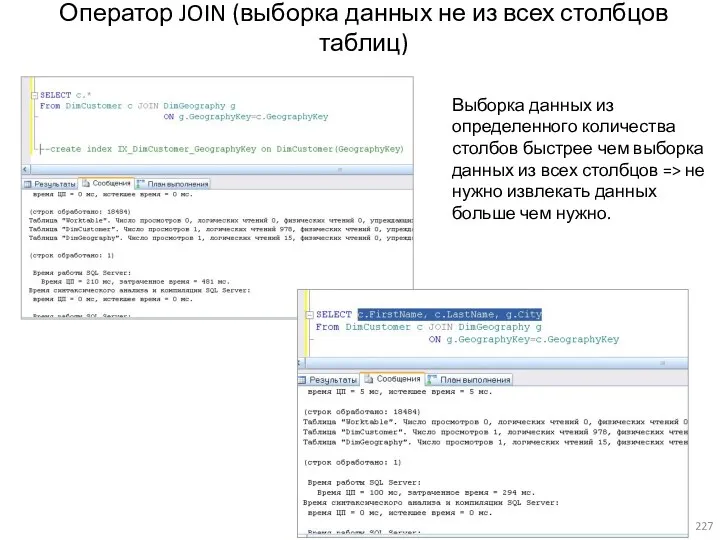
Оператор JOIN (выборка данных не из всех столбцов таблиц)
Выборка данных из
Оператор JOIN (выборка данных не из всех столбцов таблиц)
Выборка данных из
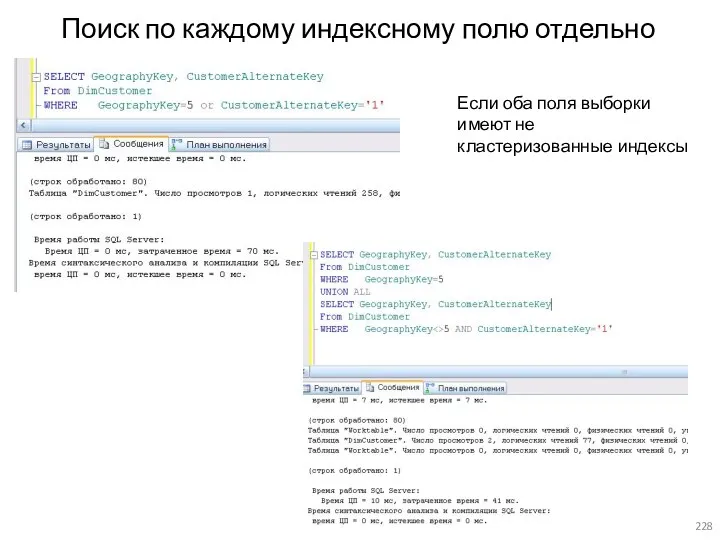
Поиск по каждому индексному полю отдельно
Если оба поля выборки имеют не
Поиск по каждому индексному полю отдельно
Если оба поля выборки имеют не

Зачем нужна оптимизация запросов?
Запросы — это критически важный компонент для повышения
Зачем нужна оптимизация запросов?
Запросы — это критически важный компонент для повышения

Рекомендации для увеличения производительности:
Для увеличения производительности, то есть для быстрого выполнения
Рекомендации для увеличения производительности:
Для увеличения производительности, то есть для быстрого выполнения

Оптимизация запросов SELECT
Не читайте больше данных, чем надо. Не используйте
Оптимизация запросов SELECT
Не читайте больше данных, чем надо. Не используйте

Корректно используйте JOIN
Если Вы имеете две или более таблиц, которые часто
Корректно используйте JOIN
Если Вы имеете две или более таблиц, которые часто

Оптимизация WHERE в запросе SELECT
Если where состоит из условий, объединенных AND, они должны
Оптимизация WHERE в запросе SELECT
Если where состоит из условий, объединенных AND, они должны

Советы по оптимизации хранимых процедур и SQL пакетов
1) Для обработки данных
Советы по оптимизации хранимых процедур и SQL пакетов
1) Для обработки данных

Рекомендации для увеличения производительности: временные таблицы для больших таблиц, табличные переменные
Рекомендации для увеличения производительности: временные таблицы для больших таблиц, табличные переменные

Обобщенные табличные выражения
Кроме временных таблиц MS SQL Server позволяет создавать обобщенные
Обобщенные табличные выражения
Кроме временных таблиц MS SQL Server позволяет создавать обобщенные

Лучшие кандидаты на установку индекса
Это поля, по которым идет JOIN
Поля связи,
Лучшие кандидаты на установку индекса
Это поля, по которым идет JOIN
Поля связи,
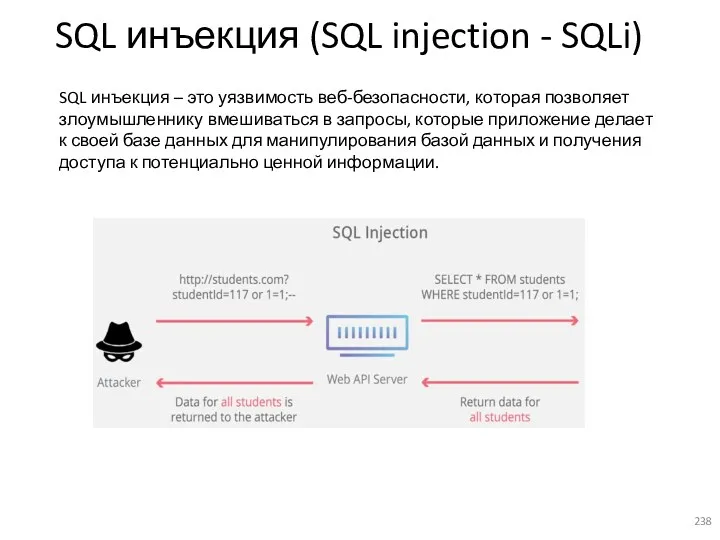
SQL инъекция (SQL injection - SQLi)
SQL инъекция – это уязвимость веб-безопасности,
SQL инъекция (SQL injection - SQLi)
SQL инъекция – это уязвимость веб-безопасности,

Проблемы, вызванные SQL Инъекцией:
Утечка данных: Злоумышленники могут получить доступ к конфиденциальным
Проблемы, вызванные SQL Инъекцией:
Утечка данных: Злоумышленники могут получить доступ к конфиденциальным

Возможные SQL инъекции (SQL внедрения)
Наиболее простые:
1. Добавление к WHERE дополнительное условие,
Возможные SQL инъекции (SQL внедрения)
Наиболее простые:
1. Добавление к WHERE дополнительное условие,

Способы обнаружения SQL инъекции
Существует несколько способов обнаружения SQL инъекций:
Использование специализированных инструментов.
Способы обнаружения SQL инъекции
Существует несколько способов обнаружения SQL инъекций:
Использование специализированных инструментов.

Возможные решения:
Использование подготовленных запросов: используйте параметризованные запросы, чтобы передавать данные в
Возможные решения:
Использование подготовленных запросов: используйте параметризованные запросы, чтобы передавать данные в
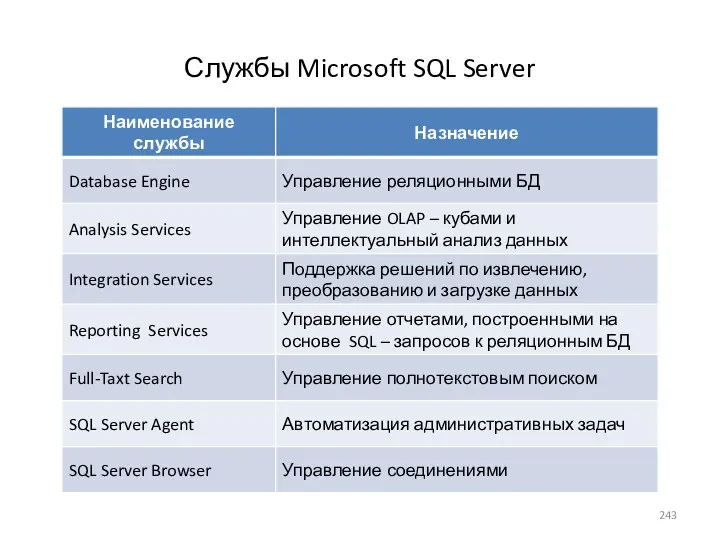
Службы Microsoft SQL Server
Службы Microsoft SQL Server

Database Engine
Database Engine является ядром системы управления реляционной БД.
Может быть
Database Engine
Database Engine является ядром системы управления реляционной БД.
Может быть
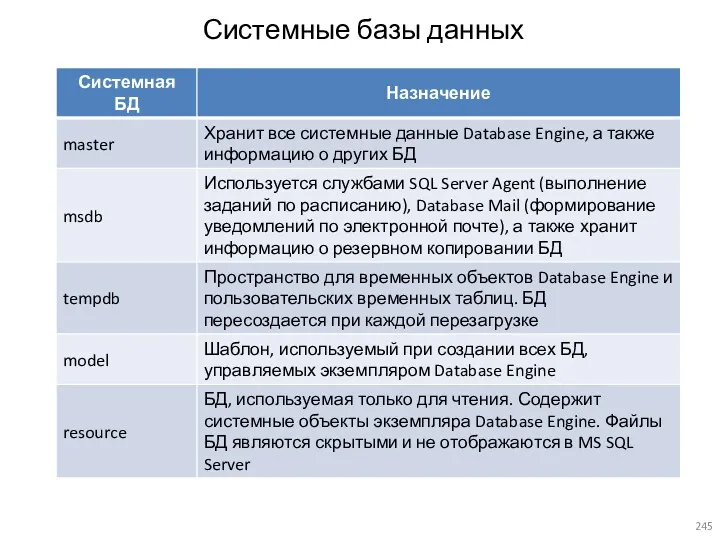
Системные базы данных
Системные базы данных

Утилиты Microsoft SQL Server:
SQL Server Management Studio.
SQL Server
Утилиты Microsoft SQL Server:
SQL Server Management Studio.
SQL Server

Система управления базами данных
Основные функции СУБД:
управление данными во внешней памяти (на
Система управления базами данных
Основные функции СУБД:
управление данными во внешней памяти (на

Обычно современная СУБД содержит следующие компоненты:
ядро, которое отвечает за управление данными
Обычно современная СУБД содержит следующие компоненты:
ядро, которое отвечает за управление данными
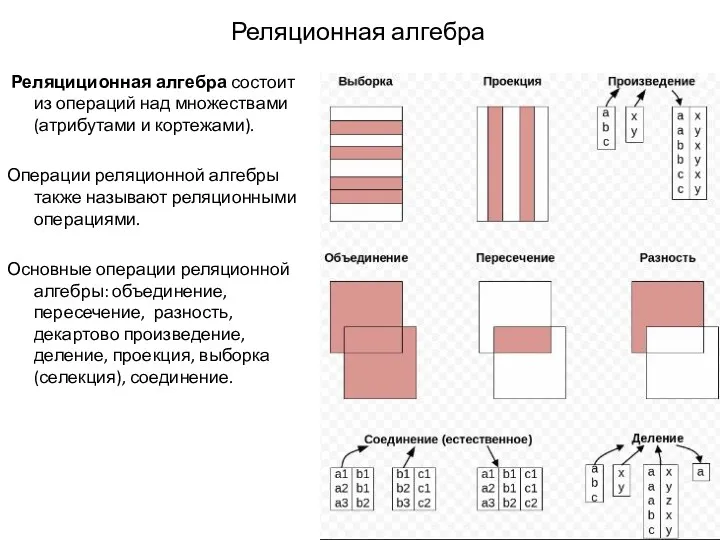
Реляционная алгебра
Реляциционная алгебра состоит из операций над множествами (атрибутами и кортежами).
Операции реляционной алгебры
Реляционная алгебра
Реляциционная алгебра состоит из операций над множествами (атрибутами и кортежами).
Операции реляционной алгебры
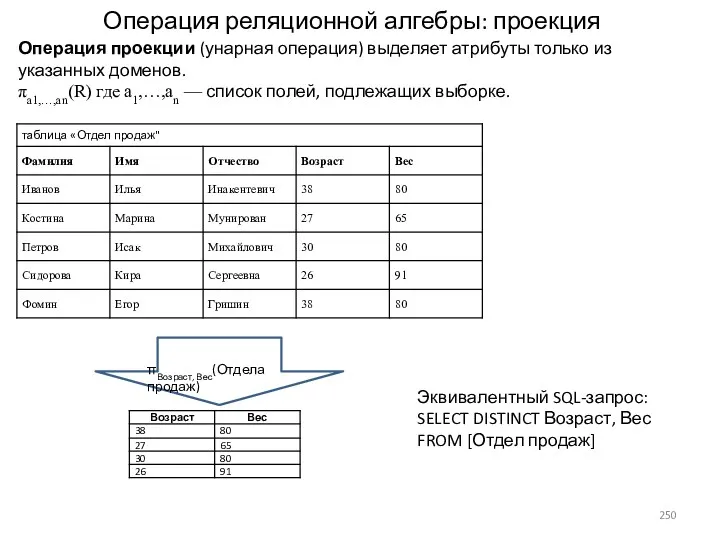
Операция реляционной алгебры: проекция
Операция проекции (унарная операция) выделяет атрибуты только из
Операция реляционной алгебры: проекция
Операция проекции (унарная операция) выделяет атрибуты только из
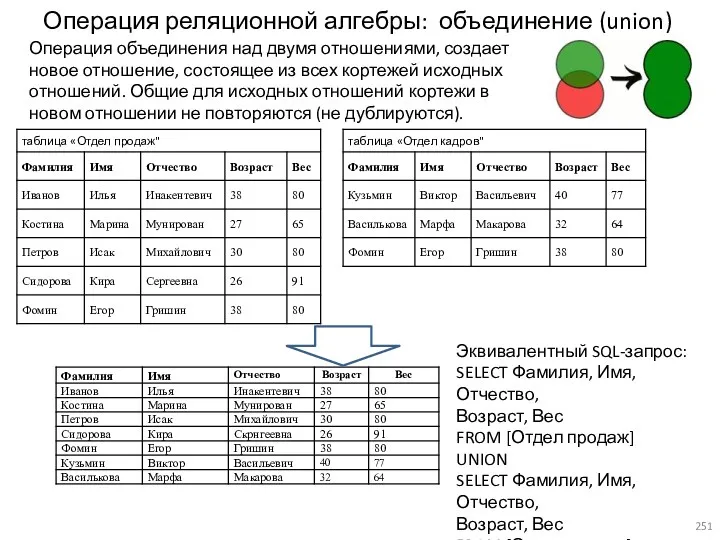
Операция реляционной алгебры: объединение (union)
Операция объединения над двумя отношениями, создает новое
Операция реляционной алгебры: объединение (union)
Операция объединения над двумя отношениями, создает новое
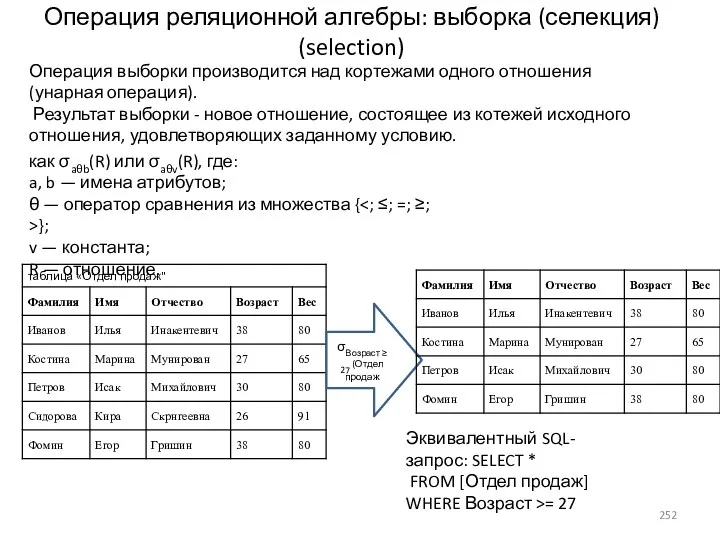
Операция реляционной алгебры: выборка (селекция) (selection)
Операция выборки производится над кортежами одного
Операция реляционной алгебры: выборка (селекция) (selection)
Операция выборки производится над кортежами одного
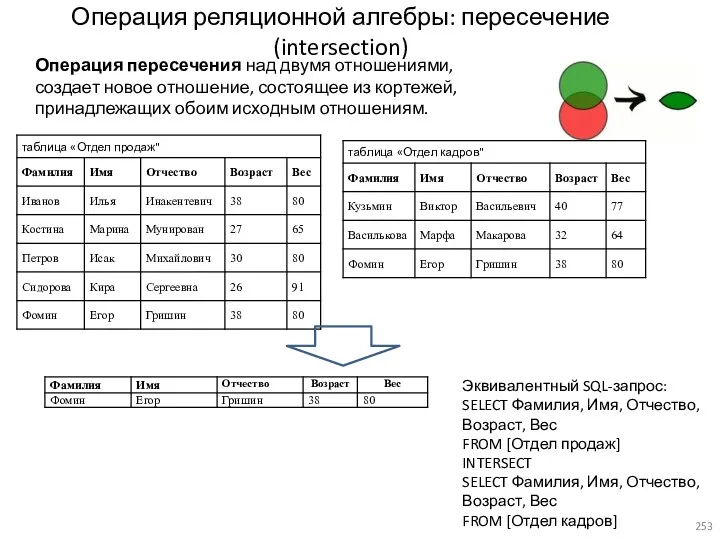
Операция реляционной алгебры: пересечение (intersection)
Операция пересечения над двумя отношениями, создает новое
Операция реляционной алгебры: пересечение (intersection)
Операция пересечения над двумя отношениями, создает новое
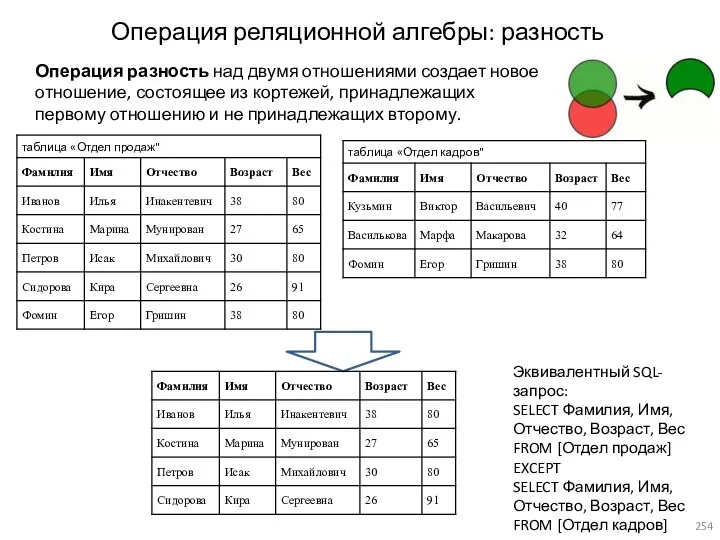
Операция реляционной алгебры: разность
Операция разность над двумя отношениями создает новое отношение, состоящее
Операция реляционной алгебры: разность
Операция разность над двумя отношениями создает новое отношение, состоящее
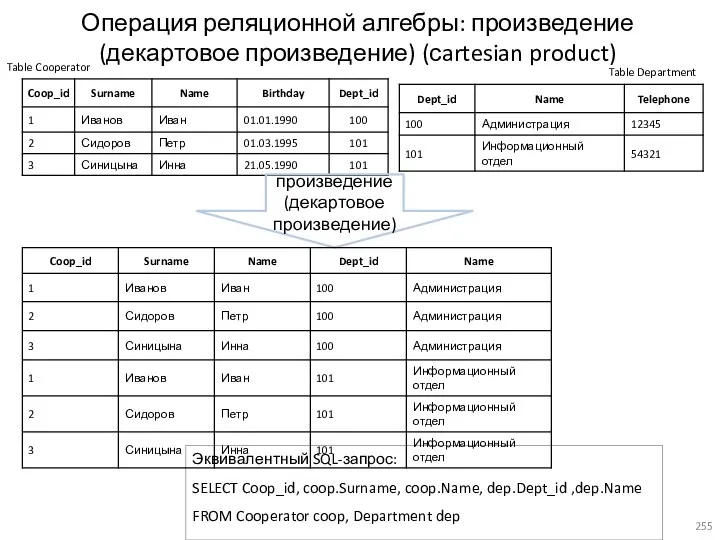
Операция реляционной алгебры: произведение (декартовое произведение) (сartesian product)
Table Cooperator
Table Department
Эквивалентный SQL-запрос:
SELECT
Операция реляционной алгебры: произведение (декартовое произведение) (сartesian product)
Table Cooperator
Table Department
Эквивалентный SQL-запрос:
SELECT
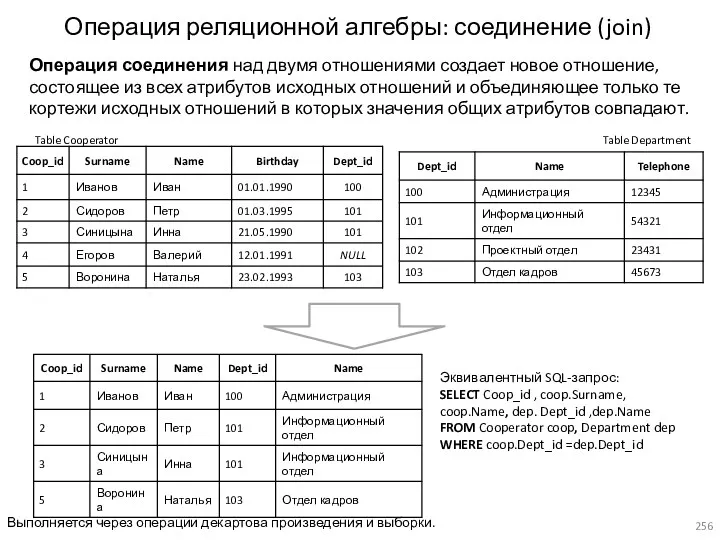
Операция реляционной алгебры: соединение (join)
Операция соединения над двумя отношениями создает новое
Операция реляционной алгебры: соединение (join)
Операция соединения над двумя отношениями создает новое
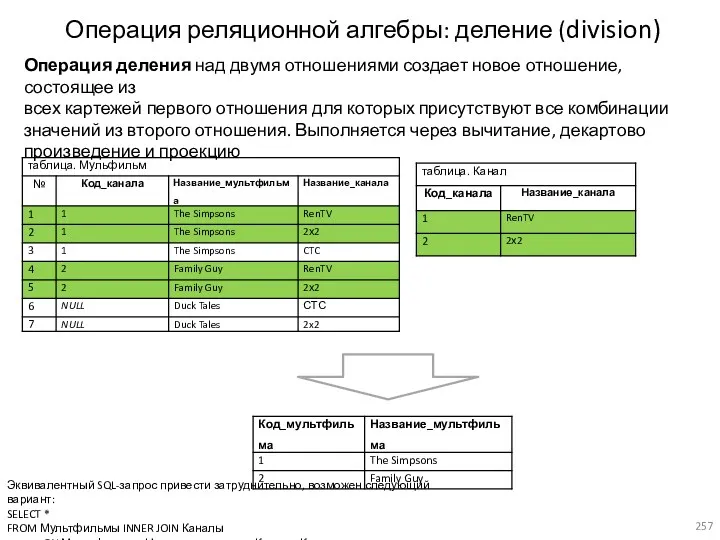
Операция реляционной алгебры: деление (division)
Операция деления над двумя отношениями создает новое
Операция реляционной алгебры: деление (division)
Операция деления над двумя отношениями создает новое

Термин NoSQL обозначает нереляционные базы данных, которые хранят данные в формате,
Термин NoSQL обозначает нереляционные базы данных, которые хранят данные в формате,
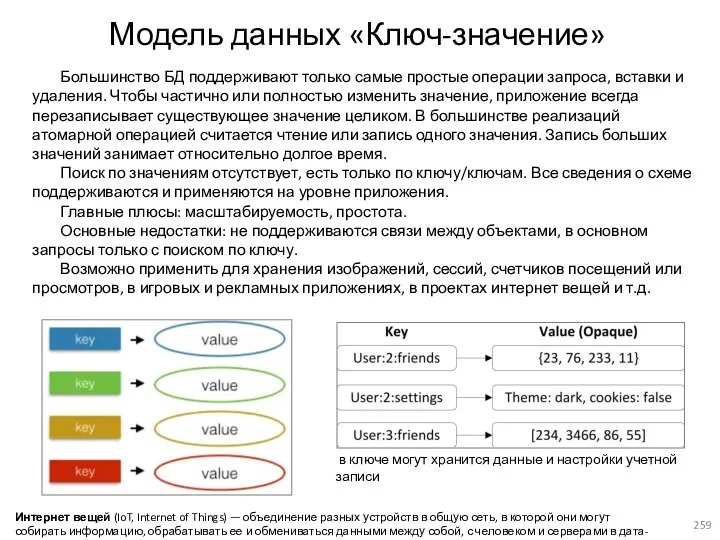
Модель данных «Ключ-значение»
Большинство БД поддерживают только самые простые операции запроса, вставки
Модель данных «Ключ-значение»
Большинство БД поддерживают только самые простые операции запроса, вставки

Документно-ориентированная модель данных
Возможно реализовать большую вложенность и сложность структуры данных, чем
Документно-ориентированная модель данных
Возможно реализовать большую вложенность и сложность структуры данных, чем
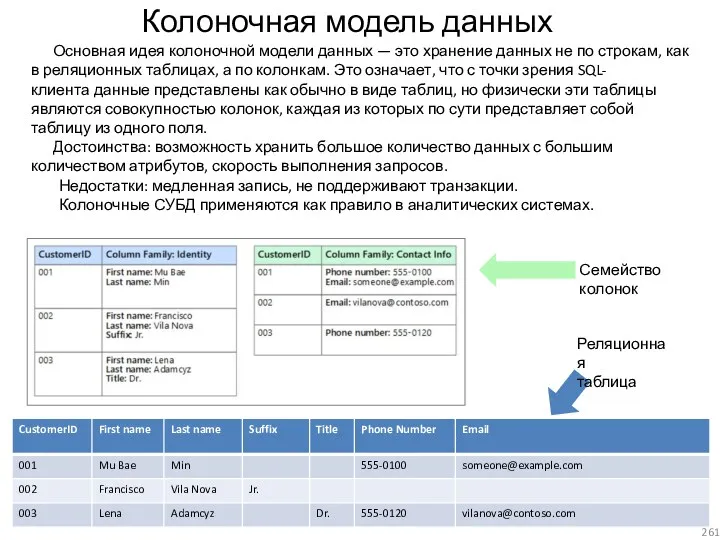
Колоночная модель данных
Основная идея колоночной модели данных — это хранение данных не по строкам, как в
Колоночная модель данных
Основная идея колоночной модели данных — это хранение данных не по строкам, как в
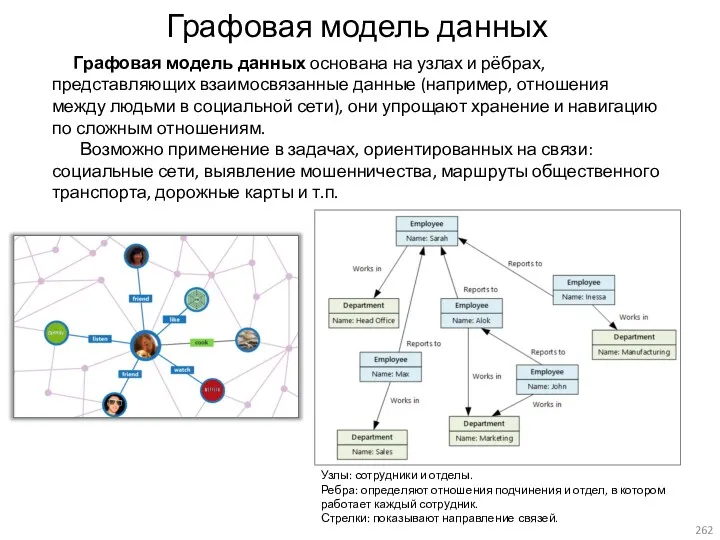
Графовая модель данных
Графовая модель данных основана на узлах и рёбрах, представляющих взаимосвязанные данные (например,
Графовая модель данных
Графовая модель данных основана на узлах и рёбрах, представляющих взаимосвязанные данные (например,
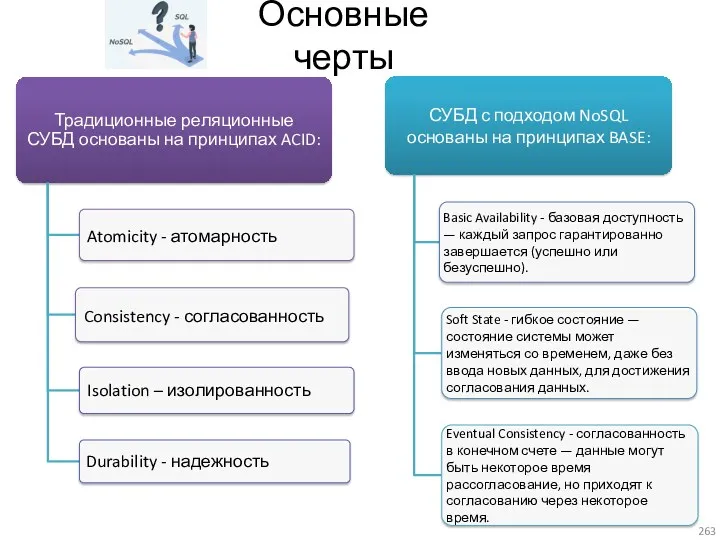
Основные черты
Основные черты
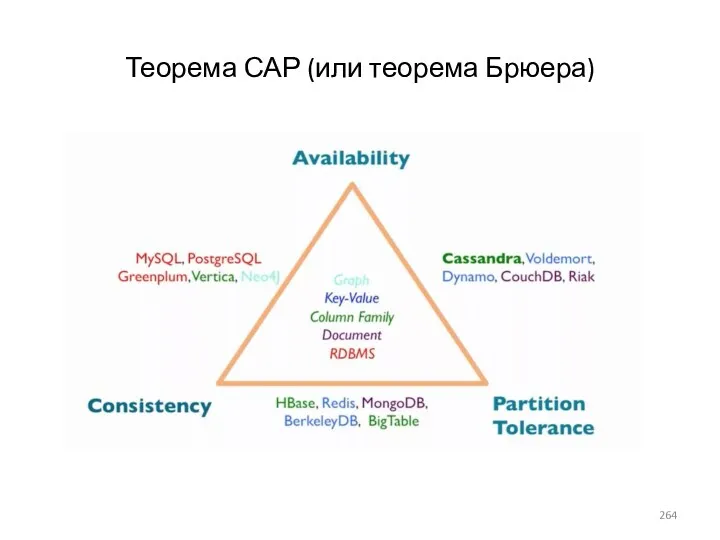
Теорема САР (или теорема Брюера)
Теорема САР (или теорема Брюера)

Примеры NoSQL СУБД
Документно-ориентированные: CouchDB (Couchbase), MongoDB (MongoDB).
Колоночные: Cassandra (Apache Software Foundation),
Примеры NoSQL СУБД
Документно-ориентированные: CouchDB (Couchbase), MongoDB (MongoDB).
Колоночные: Cassandra (Apache Software Foundation),
 Кодирование информации. Изучение единиц измерения информации. Носители информации
Кодирование информации. Изучение единиц измерения информации. Носители информации Теоретическое моделирование перевода
Теоретическое моделирование перевода Правила информационной безопасности при работе в сети Интернет
Правила информационной безопасности при работе в сети Интернет Этапы подготовки документов на компьютере
Этапы подготовки документов на компьютере Программирование. Лекция 1
Программирование. Лекция 1 Геометрическое моделирование
Геометрическое моделирование Этика и философия искусственного интеллекта
Этика и философия искусственного интеллекта Welcome. Цели и задачи курса
Welcome. Цели и задачи курса Текст и текстовый редактор
Текст и текстовый редактор Текстовая информация
Текстовая информация Кодирование информации
Кодирование информации Построение корпоративных Порталов на базе IBM WEBSPH
Построение корпоративных Порталов на базе IBM WEBSPH Антивирусные программы. Антивирусная защита информации
Антивирусные программы. Антивирусная защита информации Варианты занятости
Варианты занятости Информационная профессиональная деятельность
Информационная профессиональная деятельность Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Базы данных и системы управления базами данных
Базы данных и системы управления базами данных Проблемы правового регулирования рекламы в сети Интернет
Проблемы правового регулирования рекламы в сети Интернет Программное обеспечение
Программное обеспечение Системы автоматизированного проектирования (САПР)
Системы автоматизированного проектирования (САПР) Файлы и файловая система (8 класс)
Файлы и файловая система (8 класс) Программное обеспечение (ПО)
Программное обеспечение (ПО) Работа в Excel. Электронные таблицы
Работа в Excel. Электронные таблицы Основы WEB технологий
Основы WEB технологий Word
Word Безопасный интернет. Информационная безопасность детей
Безопасный интернет. Информационная безопасность детей Триггеры (триггерная система)
Триггеры (триггерная система) Организация ветвления на языке Паскаль
Организация ветвления на языке Паскаль