- Caching Architectures and Graphics Processing

Содержание
- 2. Overview Cache Crash Course Quick review of the basics Some traditional profile-based optimizations Static: compile-time Dynamic:
- 3. Part I: Cache Review Why Cache? CPU/GPU Speed increasing at a much higher rate than memory
- 4. So what to do? DRAM not the only option Can use SRAM, which uses flip-flops for
- 5. Use memory hierarchy Small, fast memory close to CPU (even on-die) Progressively slower, larger memories further
- 6. Locality How does this speed things up? Key observation: Most programs do not access all code
- 7. Working Set Set of data a program needs during a certain time to complete a certain
- 8. Cache Implementation Cache is transparent CPU still fetches with same addresses, can be completely unaware of
- 9. Direct mapped cache Blocks of memory map to their address modulo cache size Evict on conflict
- 10. Associative Cache Now have sets of “associated” blocks in cache Blocks from memory can map to
- 11. Fully associative cache Any block in memory can map to any block in cache. Most expensive
- 12. Measuring misses Need some way to itemize why cache misses occur “Three C’s” of cache misses:
- 13. Compulsory Misses Caused when data first comes into the cache Can think of these as misses
- 14. Conflict Misses Caused when data needs to be fetched again because it was evicted when another
- 15. Capacity Misses If the cache cannot contain the whole working set, then capacity misses will occur
- 16. Part 2: Some traditional cache optimizations Not graphics hardware related, but maybe these can give us
- 17. 1. Compile-time code layout Want to optimize instruction cache performance In code with branches and loops,
- 18. Map profile data to the code Pettis & Hansen investigated code layout based on profile info
- 19. Lay out code based on chains Try to lay out chains contiguously, so they will not
- 20. 2. Smaller scale: Struct layout We saw instructions, now what about data? Most languages today use
- 21. Split structs for better prefetching Chilimbi suggests breaking structs into pieces based on profile data: Profile
- 22. 3. Dynamic approach: Garbage collection Chilimbi suggests using runtime profiling to make garbage collectors smarter Need
- 23. More garbage Garbage collector copies data when it runs: Determines which objects are alive, which are
- 24. Other dynamic approaches Similar techniques suggested for VM system by Bershad, et. al. Involves a table
- 25. Big picture Things to think about when optimizing for cache: How much data do I need
- 26. Part 3: Caching on the GPU Architectural Overview Optimization Example: Texture cache architecture Matrix-matrix Multiplication Why
- 27. GPU Pipeline Recall GPU pipeline at high level (from Cg manual) Naga talked about vertex cache,
- 28. NV40 architecture Blue areas are memory & cache Notice 2 vertex caches (pre and post) Only
- 29. Some points about the architecture Seems pretty ad-hoc I feel like this will gradually merge together
- 30. GPU Optimmization example: Texture cache on the GPU We do not know exact specs for texture
- 31. MIP Mapping Textures on card are stored in multiple levels of hierarchy Precompute small versions of
- 32. MIP Mapping (cont’d) Trilinear filtering used to interpolate pixels from MIP maps during rasterization references pixels
- 33. Rasterization Another pitfall for texture caches We saw in matrix multiplication how column-major memory accesses can
- 34. Solution: blocking Igehy, et. al. use a blocked texture representation with special addressing to avoid these
- 36. Locality in the texture representation First level of blocking keeps working set in cache. Blocks are
- 37. Rasterization direction Igehy architecture uses 2 banks of memory, for alternating level MIP maps This avoids
- 38. Matrix-Matrix multiplication GPU implementations so far: Larsen, et. al. - heard about this the other day
- 39. Cache pitfall in matrix-matrix multiply Imagine each row in matrices below is 2 cache blocks To
- 40. Typical solution Use blocking to compute partial dot-products from submatrices Make sure that the total size
- 41. Optimizing on the GPU Fatahalian, et. al. tried: blocked access to texture pixels Unrolling loops Single-
- 42. Performance ATLAS profiles a CPU and compiles itself based on cache parameters Fully optimized to cache
- 43. Bandwidth Cards aren’t operating too far from peak bandwidth ATI Multi is above 95%
- 44. GPU Utilization & Bandwidth GPU’s get no better than 17-19% utilization of ALU’s for matrix multiplication
- 45. Shaders limit GPU utilization Paper tried blocking within shaders Shaders have few registers available For multiplying,
- 46. How to increase bandwidth Igehy, et. al. suggest: Improve the cache Wider bus to cache Closer
- 47. Another alternative: Stream processing Dally suggests using stream processing for computation Calls his architecture Imagine Eliminate
- 48. Words from Mark Mark Harris has the following to offer on Dally’s proposal: He's right that
- 49. Conclusions Bandwidth is the big problem right now Not enough data to compute on per cycle
- 51. Скачать презентацию

Overview
Cache Crash Course
Quick review of the basics
Some traditional profile-based optimizations
Static: compile-time
Overview
Cache Crash Course
Quick review of the basics
Some traditional profile-based optimizations
Static: compile-time

Part I: Cache Review
Why Cache?
CPU/GPU Speed increasing at a much higher
Part I: Cache Review
Why Cache?
CPU/GPU Speed increasing at a much higher

So what to do?
DRAM not the only option
Can use SRAM, which
So what to do?
DRAM not the only option
Can use SRAM, which
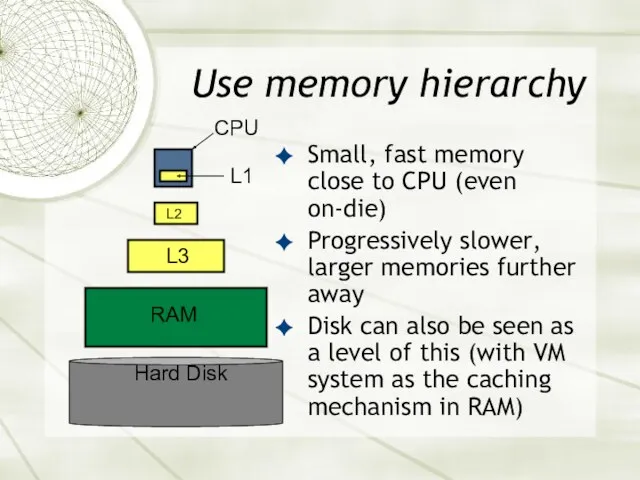
Use memory hierarchy
Small, fast memory close to CPU (even on-die)
Progressively slower,
Use memory hierarchy
Small, fast memory close to CPU (even on-die)
Progressively slower,

Locality
How does this speed things up?
Key observation: Most programs do not
Locality
How does this speed things up?
Key observation: Most programs do not

Working Set
Set of data a program needs during a certain time
Working Set
Set of data a program needs during a certain time

Cache Implementation
Cache is transparent
CPU still fetches with same addresses, can be
Cache Implementation
Cache is transparent
CPU still fetches with same addresses, can be
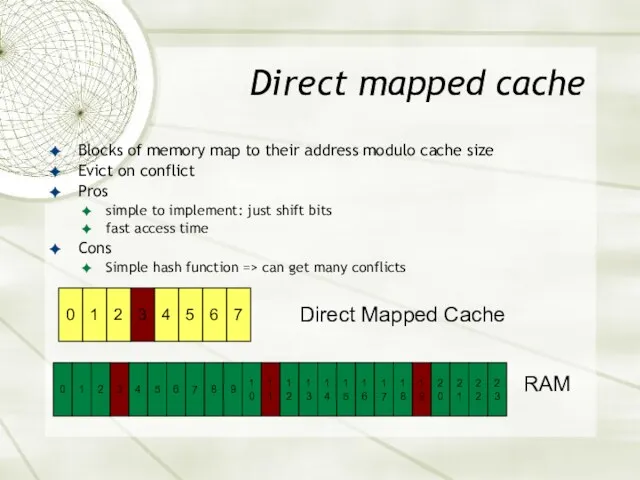
Direct mapped cache
Blocks of memory map to their address modulo cache
Direct mapped cache
Blocks of memory map to their address modulo cache

Associative Cache
Now have sets of “associated” blocks in cache
Blocks from memory
Associative Cache
Now have sets of “associated” blocks in cache
Blocks from memory

Fully associative cache
Any block in memory can map to any block
Fully associative cache
Any block in memory can map to any block

Measuring misses
Need some way to itemize why cache misses occur
“Three C’s”
Measuring misses
Need some way to itemize why cache misses occur
“Three C’s”

Compulsory Misses
Caused when data first comes into the cache
Can think of
Compulsory Misses
Caused when data first comes into the cache
Can think of

Conflict Misses
Caused when data needs to be fetched again because it
Conflict Misses
Caused when data needs to be fetched again because it

Capacity Misses
If the cache cannot contain the whole working set, then
Capacity Misses
If the cache cannot contain the whole working set, then

Part 2: Some traditional cache optimizations
Not graphics hardware related, but maybe
Part 2: Some traditional cache optimizations
Not graphics hardware related, but maybe

1. Compile-time code layout
Want to optimize instruction cache performance
In code with
1. Compile-time code layout
Want to optimize instruction cache performance
In code with

Map profile data to the code
Pettis & Hansen investigated code layout
Map profile data to the code
Pettis & Hansen investigated code layout

Lay out code based on chains
Try to lay out chains contiguously,
Lay out code based on chains
Try to lay out chains contiguously,

2. Smaller scale: Struct layout
We saw instructions, now what about data?
2. Smaller scale: Struct layout
We saw instructions, now what about data?

Split structs for better prefetching
Chilimbi suggests breaking structs into pieces based
Split structs for better prefetching
Chilimbi suggests breaking structs into pieces based

3. Dynamic approach:
Garbage collection
Chilimbi suggests using runtime profiling to make
3. Dynamic approach:
Garbage collection
Chilimbi suggests using runtime profiling to make

More garbage
Garbage collector copies data when it runs:
Determines which objects are
More garbage
Garbage collector copies data when it runs:
Determines which objects are

Other dynamic approaches
Similar techniques suggested for VM system by Bershad, et.
Other dynamic approaches
Similar techniques suggested for VM system by Bershad, et.

Big picture
Things to think about when optimizing for cache:
How much data
Big picture
Things to think about when optimizing for cache:
How much data

Part 3: Caching on the GPU
Architectural Overview
Optimization Example:
Texture cache architecture
Matrix-matrix Multiplication
Why
Part 3: Caching on the GPU
Architectural Overview
Optimization Example:
Texture cache architecture
Matrix-matrix Multiplication
Why
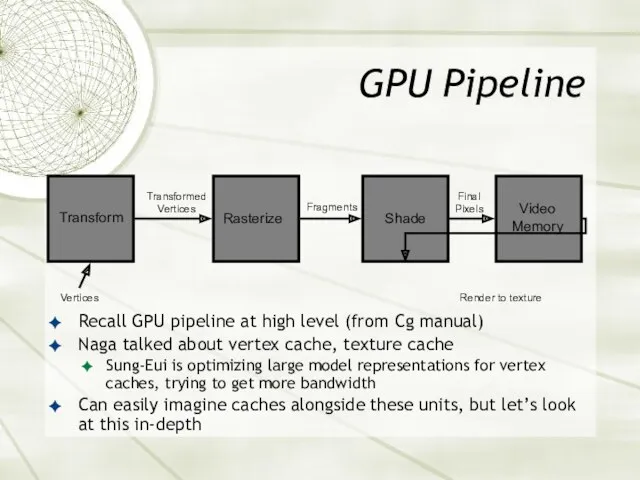
GPU Pipeline
Recall GPU pipeline at high level (from Cg manual)
Naga talked
GPU Pipeline
Recall GPU pipeline at high level (from Cg manual)
Naga talked

NV40 architecture
Blue areas are memory & cache
Notice 2 vertex caches (pre
NV40 architecture
Blue areas are memory & cache
Notice 2 vertex caches (pre

Some points about the architecture
Seems pretty ad-hoc
I feel like this will
Some points about the architecture
Seems pretty ad-hoc
I feel like this will

GPU Optimmization example:
Texture cache on the GPU
We do not know exact
GPU Optimmization example:
Texture cache on the GPU
We do not know exact

MIP Mapping
Textures on card are stored in multiple levels of hierarchy
Precompute
MIP Mapping
Textures on card are stored in multiple levels of hierarchy
Precompute

MIP Mapping (cont’d)
Trilinear filtering used to interpolate pixels from MIP maps
MIP Mapping (cont’d)
Trilinear filtering used to interpolate pixels from MIP maps

Rasterization
Another pitfall for texture caches
We saw in matrix multiplication how column-major
Rasterization
Another pitfall for texture caches
We saw in matrix multiplication how column-major

Solution: blocking
Igehy, et. al. use a blocked texture representation with special
Solution: blocking
Igehy, et. al. use a blocked texture representation with special


Locality in the texture representation
First level of blocking keeps working set
Locality in the texture representation
First level of blocking keeps working set

Rasterization direction
Igehy architecture uses 2 banks of memory, for alternating level
Rasterization direction
Igehy architecture uses 2 banks of memory, for alternating level

Matrix-Matrix multiplication
GPU implementations so far:
Larsen, et. al. - heard about this
Matrix-Matrix multiplication
GPU implementations so far:
Larsen, et. al. - heard about this

Cache pitfall in matrix-matrix multiply
Imagine each row in matrices below is
Cache pitfall in matrix-matrix multiply
Imagine each row in matrices below is

Typical solution
Use blocking to compute partial dot-products from submatrices
Make sure that
Typical solution
Use blocking to compute partial dot-products from submatrices
Make sure that

Optimizing on the GPU
Fatahalian, et. al. tried:
blocked access to texture pixels
Unrolling
Optimizing on the GPU
Fatahalian, et. al. tried:
blocked access to texture pixels
Unrolling
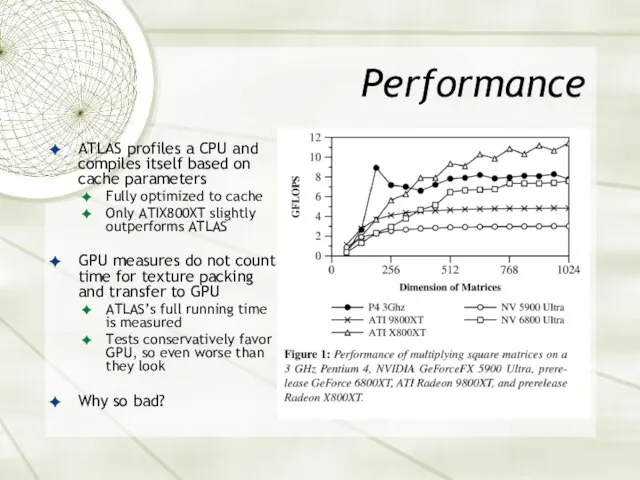
Performance
ATLAS profiles a CPU and compiles itself based on cache parameters
Fully
Performance
ATLAS profiles a CPU and compiles itself based on cache parameters
Fully
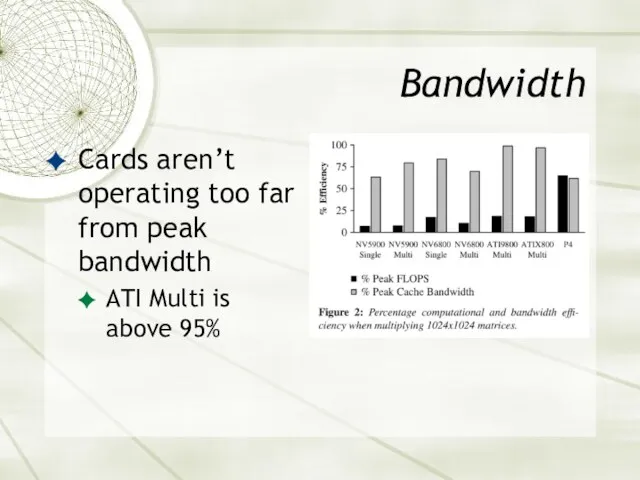
Bandwidth
Cards aren’t operating too far from peak bandwidth
ATI Multi is above
Bandwidth
Cards aren’t operating too far from peak bandwidth
ATI Multi is above

GPU Utilization & Bandwidth
GPU’s get no better than 17-19% utilization of
GPU Utilization & Bandwidth
GPU’s get no better than 17-19% utilization of

Shaders limit GPU utilization
Paper tried blocking within shaders
Shaders have few registers
Shaders limit GPU utilization
Paper tried blocking within shaders
Shaders have few registers

How to increase bandwidth
Igehy, et. al. suggest:
Improve the cache
Wider bus to
How to increase bandwidth
Igehy, et. al. suggest:
Improve the cache
Wider bus to

Another alternative: Stream processing
Dally suggests using stream processing for computation
Calls his
Another alternative: Stream processing
Dally suggests using stream processing for computation
Calls his

Words from Mark
Mark Harris has the following to offer on Dally’s
Words from Mark
Mark Harris has the following to offer on Dally’s

Conclusions
Bandwidth is the big problem right now
Not enough data to compute
Conclusions
Bandwidth is the big problem right now
Not enough data to compute
 Сервисы для создания презентаций
Сервисы для создания презентаций Организация защиты информации в локальной сети компании ООО MAN Truck and Bus Rus
Организация защиты информации в локальной сети компании ООО MAN Truck and Bus Rus Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма
Алгоритм и его свойства. Понятие алгоритма и исполнителя. Свойства алгоритма Модифицированный симплекс метод
Модифицированный симплекс метод Исполнители алгоритмов
Исполнители алгоритмов Python.Основы Циклы While. For. Лекция 3.2
Python.Основы Циклы While. For. Лекция 3.2 Що таке джинса
Що таке джинса Feed back
Feed back Modeling space from picture. Musical instruments
Modeling space from picture. Musical instruments Урок на тему Единицы измерения информации 6 класс
Урок на тему Единицы измерения информации 6 класс Зачем человек приходит в этот мир?
Зачем человек приходит в этот мир? Защита от несанкционированного доступа к информации
Защита от несанкционированного доступа к информации Цифровое фото и видео
Цифровое фото и видео Transition headline. Let’s start with the first set of slides
Transition headline. Let’s start with the first set of slides Графический интерфейс. Библиотека Tkinter
Графический интерфейс. Библиотека Tkinter Строковый и символьный тип данных
Строковый и символьный тип данных Виртуальные экскурсии: технологии создания
Виртуальные экскурсии: технологии создания Google. История создания
Google. История создания Криптография. История развития и базовые знания
Криптография. История развития и базовые знания Модель ISO/OSI
Модель ISO/OSI Научно-техническая и патентная информация Часть 2
Научно-техническая и патентная информация Часть 2 Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары
Ақпараттық коммуникациялықтехнологияны қолдану негізінде білім сапасын арттыру жолдары Телеграмм-бот по игре Dota
Телеграмм-бот по игре Dota Подпрограммы в авс pascal
Подпрограммы в авс pascal Інформаційна система Ідентифікації шляхом розпізнавання обличчя
Інформаційна система Ідентифікації шляхом розпізнавання обличчя Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16)
Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16) Протоколы распределения ключей
Протоколы распределения ключей Сбор данных
Сбор данных