- Clusters

Содержание
- 2. Кратко о главном Что? 1. Распределенная компьютерная система - отказоустойчивая виртуально единая система компьютерных ресурсов, для
- 3. Кратко о главном Зачем? Увеличение скорости вычислений Балансировка нагрузки Обеспечение надежности Как? Volunteer Computing (Grid) GNU/Linux
- 4. Grid & Supercomputer Grid: Узлы разнородны (Win, UNIX) подключены к сети (локальной или глобальной) при помощи
- 5. Grid & Supercomputer Пример Grid: Моделирование свертывания белка в Стэнфорде FOLDING@HOME 222 000 CPU & 23
- 6. Grid & Supercomputer Пример Supercomputer: Оборонный научно-технический университет НОАК 天河二號, Tiānhé-2 33,86 PetaFLOPS состоит из 16
- 7. Аппаратная архитектура. Supercomputer Node Node Node Node FC Switch FC Switch SP A C1 SP B
- 8. Computational clusters Использование: ресурсоемкие вычисления MPI (MPICH, Open MPI) Hadoop
- 9. LB & HA clusters Задача кластеров высокой доступности High-availability clusters / failover clusters - организовать надежный
- 10. LB & HA clusters. Example (Normal) Frontend1 Frontend2 HA Proxy Virtual IP Virtual IP Pacemaker +
- 11. LB & HA clusters. Example (Fail) frontend1 Frontend2 Pacemaker + Corosync 192.168.72.222 HA Proxy Virtual IP
- 12. Принцип работы HA. Ресурсы Все, что может быть заскриптовано, то может быть ресурсом. Все, что требуется
- 13. Принцип работы HA. Ресурсы
- 14. Split-Brain Кластер: 3 ноды A, B, C. Ресурс R находится на ноде A Теряется связь между
- 15. R Split-Brain Node A Node B Node C R Иллюстрация сломанного ресурса
- 16. Fencing Решение проблемы со Split-Brain: отрезать «выпавшей» ноде доступ к ресурсу и самим управлять им Два
- 17. Fencing Node fencing: Киллер на службе у кластера (тупо гасит «плохую» ноду) stonithd daemon STONITH plugin
- 18. Resource fencing Resource fencing: Кластер может иметь возможность контролировать определенные устройства (например, дисковые массивы, свитчи и
- 19. Quorum При Split-Brain каждая независимая группа нод будет пытаться сделать STONITH другой группе нод. Т. о.
- 20. Архитектура HA-Cluster Node Node Node Node Коммуникация между нодами Управление ресурсами Ресурс Ресурс
- 21. ПО HA-Cluster. Heartbeat Node Node Node Node Heartbeat + Cluster Resource Manager Управление ресурсами Ресурс Ресурс
- 22. ПО HA-Cluster. Heartbeat + Pacemaker Node Node Node Node Heartbeat Pacemaker (CRM) Ресурс Ресурс
- 23. ПО HA-Cluster. Corosync + Pacemaker Node Node Node Node Corosync/OpenAIS Pacemaker (CRM) Ресурс Ресурс
- 24. ПО HA-Cluster. Corosync + RGManager Node Node Node Node Corosync/OpenAIS RGManager Ресурс Ресурс CMAN (RedHat Cluster
- 25. ПО HA-Cluster.
- 26. Что умеет Pacemaker
- 27. Что умеет Pacemaker
- 28. Что умеет Pacemaker
- 29. Что умеет Pacemaker
- 30. Задание для получения 5 на экзамене Сделать кластер с балансировкой нагрузки, похожий на тот, который демонстрировался
- 32. Скачать презентацию

Кратко о главном
Что?
1. Распределенная компьютерная система - отказоустойчивая виртуально единая система
Кратко о главном
Что?
1. Распределенная компьютерная система - отказоустойчивая виртуально единая система

Кратко о главном
Зачем?
Увеличение скорости вычислений
Балансировка нагрузки
Обеспечение надежности
Как?
Volunteer Computing (Grid)
GNU/Linux (MOSIX, Linux-HA),
Кратко о главном
Зачем?
Увеличение скорости вычислений
Балансировка нагрузки
Обеспечение надежности
Как?
Volunteer Computing (Grid)
GNU/Linux (MOSIX, Linux-HA),

Grid & Supercomputer
Grid:
Узлы разнородны (Win, UNIX) подключены к сети (локальной или
Grid & Supercomputer
Grid:
Узлы разнородны (Win, UNIX) подключены к сети (локальной или

Grid & Supercomputer
Пример Grid:
Моделирование свертывания белка в Стэнфорде
FOLDING@HOME
222 000 CPU
Grid & Supercomputer
Пример Grid:
Моделирование свертывания белка в Стэнфорде
FOLDING@HOME
222 000 CPU

Grid & Supercomputer
Пример Supercomputer:
Оборонный научно-технический университет НОАК
天河二號, Tiānhé-2
33,86 PetaFLOPS
состоит
Grid & Supercomputer
Пример Supercomputer:
Оборонный научно-технический университет НОАК
天河二號, Tiānhé-2
33,86 PetaFLOPS
состоит
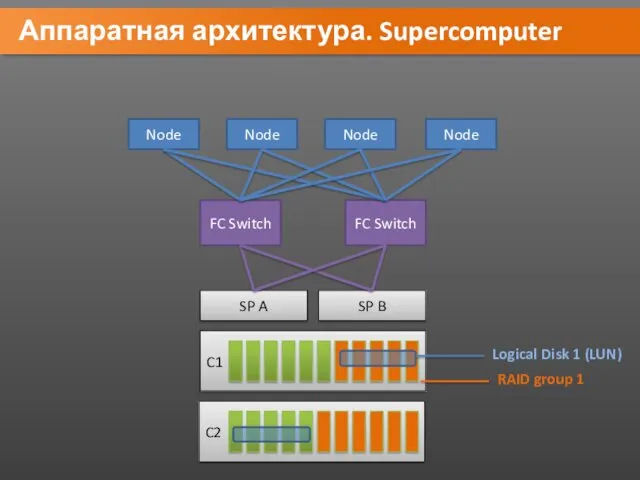
Аппаратная архитектура. Supercomputer
Node
Node
Node
Node
FC Switch
FC Switch
SP A
C1
SP B
RAID group 1
Logical Disk 1
Аппаратная архитектура. Supercomputer
Node
Node
Node
Node
FC Switch
FC Switch
SP A
C1
SP B
RAID group 1
Logical Disk 1

Computational clusters
Использование: ресурсоемкие вычисления
MPI (MPICH, Open MPI)
Hadoop
Computational clusters
Использование: ресурсоемкие вычисления
MPI (MPICH, Open MPI)
Hadoop

LB & HA clusters
Задача кластеров высокой доступности
High-availability clusters / failover
LB & HA clusters
Задача кластеров высокой доступности High-availability clusters / failover
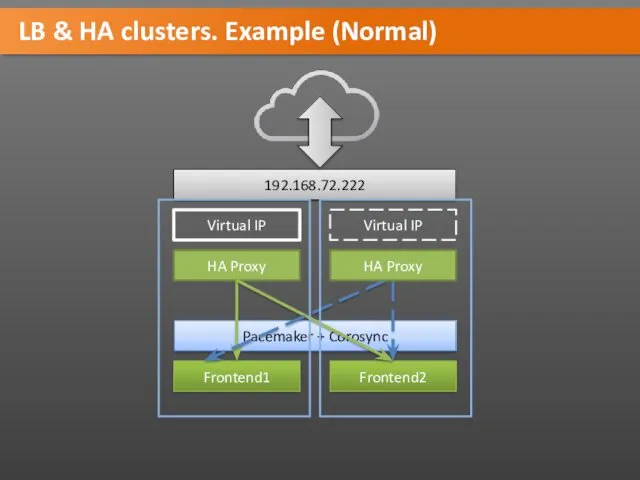
LB & HA clusters. Example (Normal)
Frontend1
Frontend2
HA Proxy
Virtual IP
Virtual IP
Pacemaker + Corosync
192.168.72.222
HA
LB & HA clusters. Example (Normal)
Frontend1
Frontend2
HA Proxy
Virtual IP
Virtual IP
Pacemaker + Corosync
192.168.72.222
HA
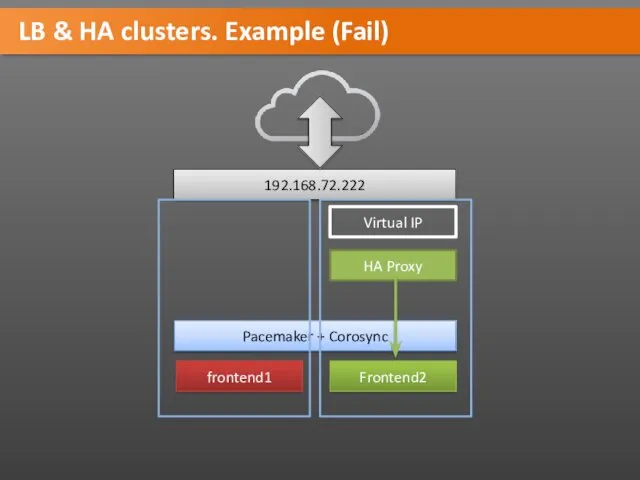
LB & HA clusters. Example (Fail)
frontend1
Frontend2
Pacemaker + Corosync
192.168.72.222
HA Proxy
Virtual IP
LB & HA clusters. Example (Fail)
frontend1
Frontend2
Pacemaker + Corosync
192.168.72.222
HA Proxy
Virtual IP

Принцип работы HA. Ресурсы
Все, что может быть заскриптовано, то может быть
Принцип работы HA. Ресурсы
Все, что может быть заскриптовано, то может быть
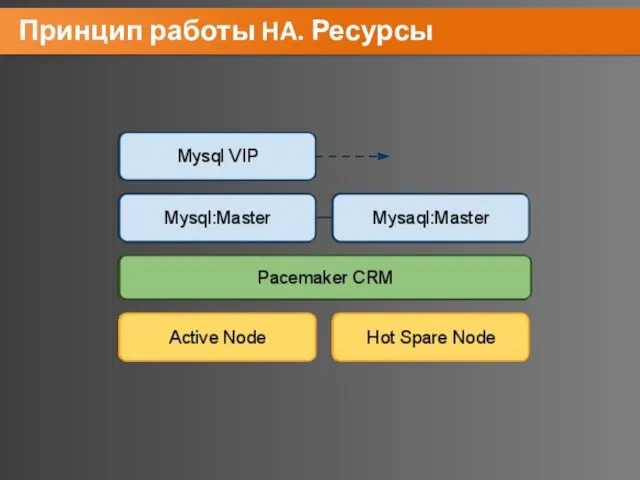
Принцип работы HA. Ресурсы
Принцип работы HA. Ресурсы

Split-Brain
Кластер: 3 ноды A, B, C. Ресурс R находится на ноде
Split-Brain
Кластер: 3 ноды A, B, C. Ресурс R находится на ноде
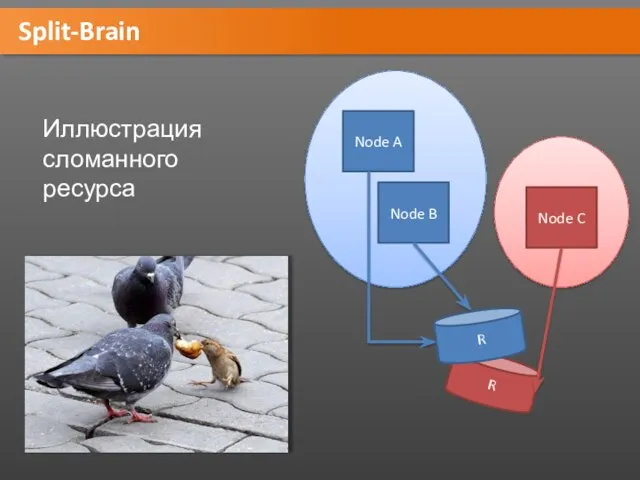
R
Split-Brain
Node A
Node B
Node C
R
Иллюстрация сломанного ресурса
R
Split-Brain
Node A
Node B
Node C
R
Иллюстрация сломанного ресурса
Fencing
Решение проблемы со Split-Brain: отрезать «выпавшей» ноде доступ к ресурсу и
Fencing
Решение проблемы со Split-Brain: отрезать «выпавшей» ноде доступ к ресурсу и

Fencing
Node fencing:
Киллер на службе у кластера
(тупо гасит «плохую» ноду)
stonithd daemon
STONITH
Fencing
Node fencing:
Киллер на службе у кластера
(тупо гасит «плохую» ноду)
stonithd daemon
STONITH

Resource fencing
Resource fencing:
Кластер может иметь возможность контролировать определенные устройства (например, дисковые
Resource fencing
Resource fencing:
Кластер может иметь возможность контролировать определенные устройства (например, дисковые

Quorum
При Split-Brain каждая независимая группа нод будет пытаться сделать STONITH другой
Quorum
При Split-Brain каждая независимая группа нод будет пытаться сделать STONITH другой
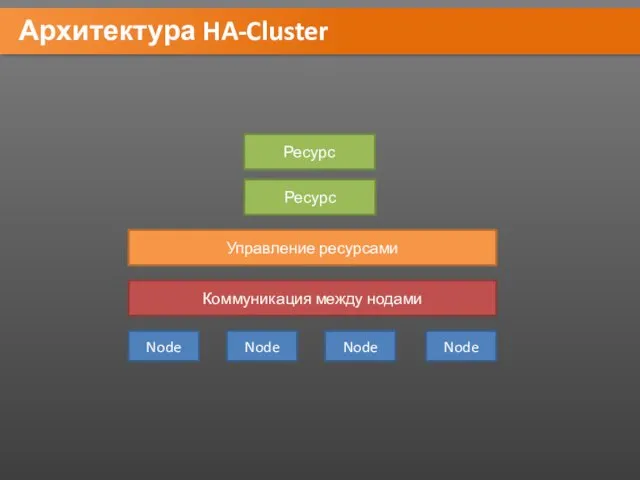
Архитектура HA-Cluster
Node
Node
Node
Node
Коммуникация между нодами
Управление ресурсами
Ресурс
Ресурс
Архитектура HA-Cluster
Node
Node
Node
Node
Коммуникация между нодами
Управление ресурсами
Ресурс
Ресурс

ПО HA-Cluster. Heartbeat
Node
Node
Node
Node
Heartbeat + Cluster Resource Manager
Управление ресурсами
Ресурс
Ресурс
ПО HA-Cluster. Heartbeat
Node
Node
Node
Node
Heartbeat + Cluster Resource Manager
Управление ресурсами
Ресурс
Ресурс

ПО HA-Cluster. Heartbeat + Pacemaker
Node
Node
Node
Node
Heartbeat
Pacemaker (CRM)
Ресурс
Ресурс
ПО HA-Cluster. Heartbeat + Pacemaker
Node
Node
Node
Node
Heartbeat
Pacemaker (CRM)
Ресурс
Ресурс
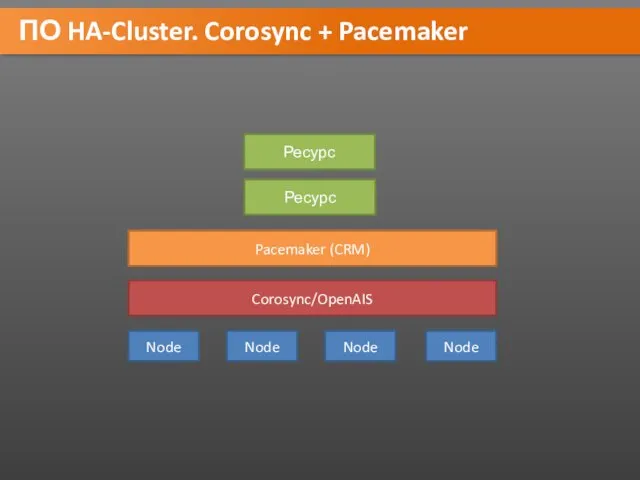
ПО HA-Cluster. Corosync + Pacemaker
Node
Node
Node
Node
Corosync/OpenAIS
Pacemaker (CRM)
Ресурс
Ресурс
ПО HA-Cluster. Corosync + Pacemaker
Node
Node
Node
Node
Corosync/OpenAIS
Pacemaker (CRM)
Ресурс
Ресурс
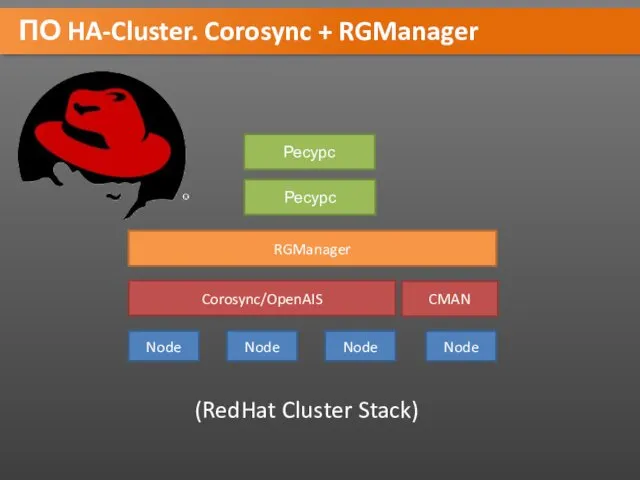
ПО HA-Cluster. Corosync + RGManager
Node
Node
Node
Node
Corosync/OpenAIS
RGManager
Ресурс
Ресурс
CMAN
(RedHat Cluster Stack)
ПО HA-Cluster. Corosync + RGManager
Node
Node
Node
Node
Corosync/OpenAIS
RGManager
Ресурс
Ресурс
CMAN
(RedHat Cluster Stack)
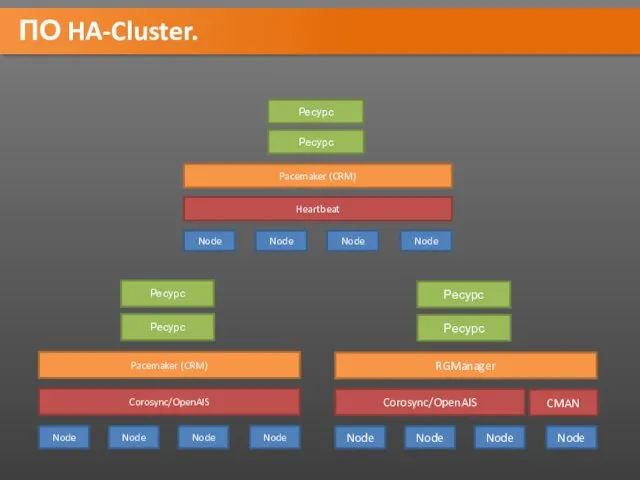
ПО HA-Cluster.
ПО HA-Cluster.

Что умеет Pacemaker
Что умеет Pacemaker
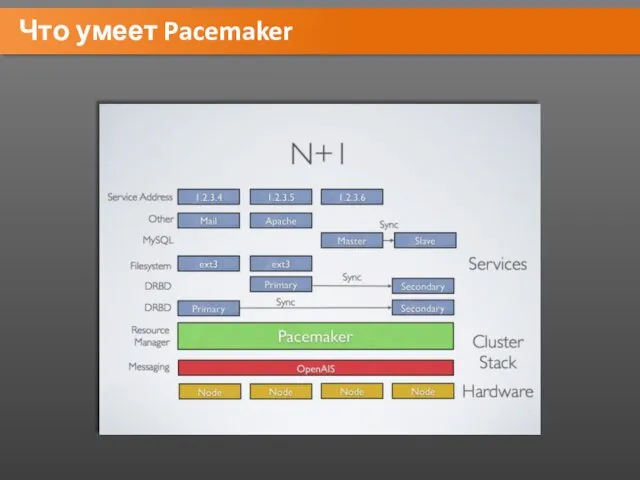
Что умеет Pacemaker
Что умеет Pacemaker

Что умеет Pacemaker
Что умеет Pacemaker
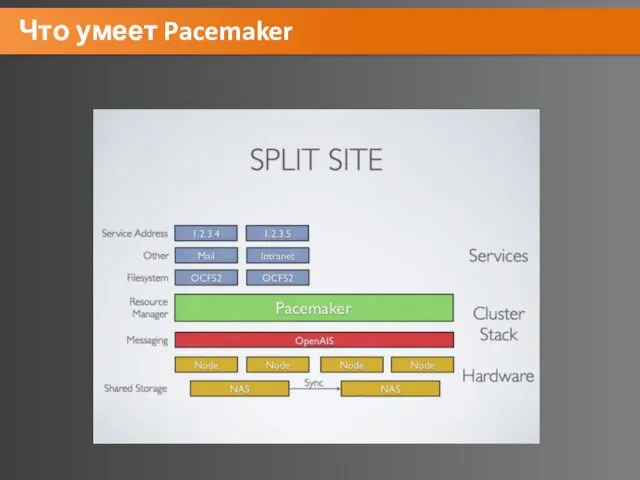
Что умеет Pacemaker
Что умеет Pacemaker

Задание для получения 5 на экзамене
Сделать кластер с балансировкой нагрузки, похожий
Задание для получения 5 на экзамене
Сделать кластер с балансировкой нагрузки, похожий
 Система команд микропроцессора Intel 80x86. (Тема 4)
Система команд микропроцессора Intel 80x86. (Тема 4) Безопасный Интернет
Безопасный Интернет Производственная практика. ADO.NET и COM при работе с MS ACCESS и MS EXCEL в десктопном приложении
Производственная практика. ADO.NET и COM при работе с MS ACCESS и MS EXCEL в десктопном приложении Хэш-функции. Лекция 12
Хэш-функции. Лекция 12 Характеристика программы GRAFIS, основные правила
Характеристика программы GRAFIS, основные правила Моделирование. Системный подход в моделировании
Моделирование. Системный подход в моделировании Создание сайта
Создание сайта Защищенные мультисервисные телекоммуникационные системы
Защищенные мультисервисные телекоммуникационные системы Безопасный Интернет
Безопасный Интернет Microsoft Word
Microsoft Word Разработка кода программного продукта на уровне модуля. Тема 2
Разработка кода программного продукта на уровне модуля. Тема 2 Ехсеl. Компьютерные технологи обработки табличных данных
Ехсеl. Компьютерные технологи обработки табличных данных Компьютерная графика и анимация. Многослойные изображения. Каналы. Иллюстрации для веб-сайтов
Компьютерная графика и анимация. Многослойные изображения. Каналы. Иллюстрации для веб-сайтов Основные понятия ОС
Основные понятия ОС Потоки и файлы
Потоки и файлы Создание Web-сайта. Коммуникационные технологии
Создание Web-сайта. Коммуникационные технологии Электронный тест по теме Информация
Электронный тест по теме Информация Информационные системы
Информационные системы Программирование на языке PL/SQL. Часть 1. Введение в Oracle PL/SQL
Программирование на языке PL/SQL. Часть 1. Введение в Oracle PL/SQL Табличные базы данных
Табличные базы данных Средства информационных и коммуникационных технологий как инструмент оценивания образовательных результатов
Средства информационных и коммуникационных технологий как инструмент оценивания образовательных результатов Обеспечение информационной безопасности посредством управления usb портами
Обеспечение информационной безопасности посредством управления usb портами Построение треугольника по двум сторонам и углу между ними в системе компьютерного черчения КОМПАС
Построение треугольника по двум сторонам и углу между ними в системе компьютерного черчения КОМПАС Компьютерные сети. История развития, разновидности, модель OSI, стандартизация и основные протоколы
Компьютерные сети. История развития, разновидности, модель OSI, стандартизация и основные протоколы Неуправляемое движение объектов
Неуправляемое движение объектов Пошаговое создание мнемосхемы проекта
Пошаговое создание мнемосхемы проекта Chapter 3. Transport Layer
Chapter 3. Transport Layer Data snap RAD studio communication
Data snap RAD studio communication