- Data Mining: Concepts and Techniques (3rd ed.) — Chapter 1 — Farid Feyzi

Содержание
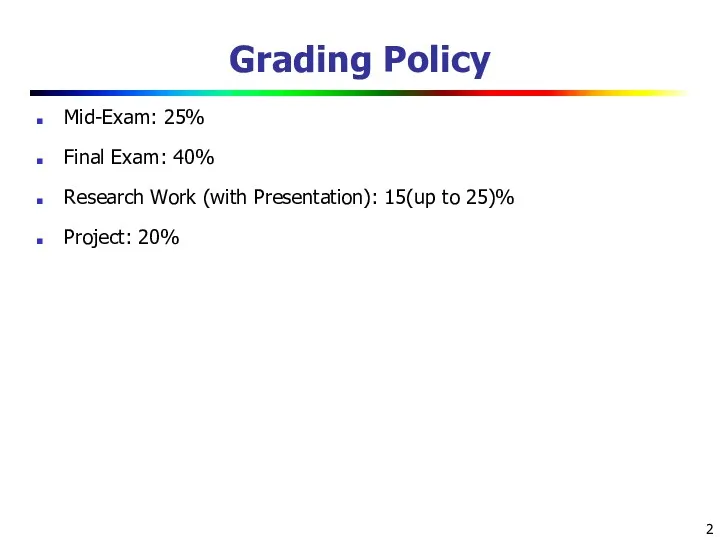
- 2. Grading Policy Mid-Exam: 25% Final Exam: 40% Research Work (with Presentation): 15(up to 25)% Project: 20%
- 3. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 4. Why Data Mining? The Explosive Growth of Data: from terabytes to petabytes Data collection and data
- 5. Why do we need data mining? Really, really huge amounts of raw data!! In the digital
- 6. Why do we need data mining? “The data is the computer” Large amounts of data can
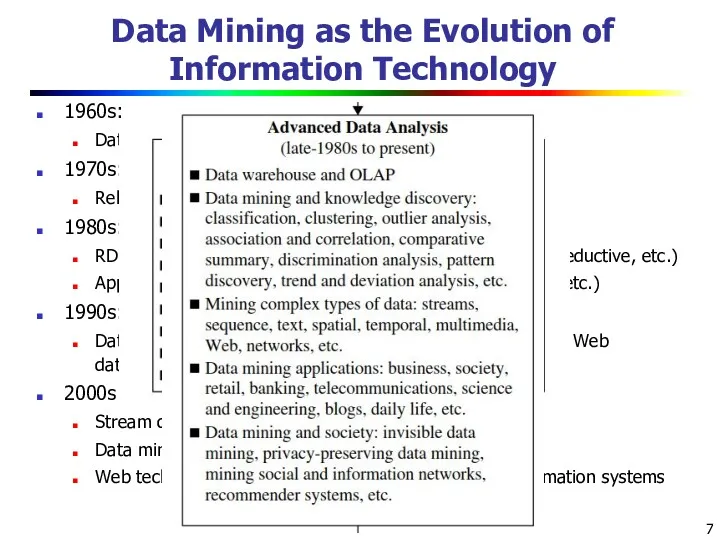
- 7. Data Mining as the Evolution of Information Technology 1960s: Data collection, database creation, IMS and network
- 8. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 9. What Is Data Mining? Data mining (knowledge discovery from data) Extraction of interesting (non-trivial, implicit, previously
- 10. Knowledge Discovery (KDD) Process The knowledge discovery process is an iterative sequence of the following steps:
- 11. Knowledge Discovery (KDD) Process The knowledge discovery process is an iterative sequence of the following steps:
- 12. Example: A Web Mining Framework Web mining usually involves Data cleaning Data integration from multiple sources
- 13. Data Mining in Business Intelligence Increasing potential to support business decisions End User Business Analyst Data
- 14. KDD Process: A Typical View from ML and Statistics Input Data Pattern Information Knowledge Data Mining
- 15. Example: Medical Data Mining Health care & medical data mining – often adopted such a view
- 16. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 17. Multi-Dimensional View of Data Mining Data to be mined Database data (extended-relational, object-oriented, heterogeneous, legacy), data
- 18. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 19. Data Mining: On What Kinds of Data? Database-oriented data sets and applications Relational database, data warehouse,
- 20. The data is also very complex Multiple types of data: tables, time series, images, graphs, etc
- 21. Example: transaction data Billions of real-life customers: WALMART: 20M transactions per day AT&T 300 M calls
- 22. Example: document data Web as a document repository: estimated 50 billions of web pages Wikipedia: 4
- 23. Example: network data Web: 50 billion pages linked via hyperlinks Facebook: 500 million users Twitter: 300
- 24. Example: genomic sequences http://www.1000genomes.org/page.php Full sequence of 1000 individuals 3*109 nucleotides per person ? 3*1012 nucleotides
- 25. Example: environmental data Climate data (just an example) http://www.ncdc.gov/oa/climate/ghcn-monthly/index.php “a database of temperature, precipitation and pressure
- 26. Behavioral data Mobile phones today record a large amount of information about the user behavior GPS
- 27. So, what is Data? Collection of data objects and their attributes An attribute is a property
- 28. Types of Attributes There are different types of attributes Categorical Examples: eye color, zip codes, words,
- 29. Numeric Record Data If data objects have the same fixed set of numeric attributes, then the
- 30. Categorical Data Data that consists of a collection of records, each of which consists of a
- 31. Document Data Each document becomes a `term' vector, each term is a component (attribute) of the
- 32. Transaction Data Each record (transaction) is a set of items. A set of items can also
- 33. Ordered Data Genomic sequence data Data is a long ordered string 33
- 34. Ordered Data Time series Sequence of ordered (over “time”) numeric values. 34
- 35. Graph Data Examples: Web graph and HTML Links 35
- 36. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 37. Data Mining Function: (1) Generalization Information integration and data warehouse construction Data cleaning, transformation, integration, and
- 38. Data cube technology داده ها در دو بعد ذخیره شده اند در مکعبداده، دادهها به صورت
- 39. Data Mining Function: (2) Association and Correlation Analysis Frequent patterns (or frequent itemsets) What items are
- 40. Data Mining Function: (3) Classification Classification and label prediction Construct models (functions) based on some training
- 41. Data Mining Function: (3) Classification
- 42. Data Mining Function: (4) Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to
- 43. Data Mining Function: (4) Cluster Analysis
- 44. Data Mining Function: (5) Outlier Analysis Outlier analysis Outlier: A data object that does not comply
- 45. What can you do with the data? Suppose that you are the owner of a supermarket
- 46. What can you do with the data? Suppose you are a search engine and you have
- 47. What can you do with the data? Suppose you are biologist who has microarray expression data:
- 48. What can you do with the data? Suppose you are a stock broker and you observe
- 49. What can you do with the data? You are the owner of a social network, and
- 50. Time and Ordering: Sequential Pattern, Trend and Evolution Analysis Sequence, trend and evolution analysis Trend, time-series,
- 51. Time and Ordering: Sequential Pattern, Trend and Evolution Analysis Sequential pattern mining: an important data mining
- 52. Structure and Network Analysis Graph mining Finding frequent subgraphs (e.g., chemical compounds-malware analysis), trees (XML), substructures
- 53. Evaluation of Knowledge Are all mined knowledge interesting? One can mine tremendous amount of “patterns” and
- 54. What can we do with data mining? Some examples: Frequent itemsets and Association Rules extraction Coverage
- 55. Frequent Itemsets and Association Rules Given a set of records each of which contain some number
- 56. Frequent Itemsets: Applications Text mining: finding associated phrases in text There are lots of documents that
- 57. Association Rule Discovery: Application Supermarket shelf management. Goal: To identify items that are bought together by
- 58. Clustering Definition Given a set of data points, each having a set of attributes, and a
- 59. Illustrating Clustering Euclidean Distance Based Clustering in 3-D space. Intracluster distances are minimized Intercluster distances are
- 60. Clustering: Application 1 Bioinformatics applications: Goal: Group genes and tissues together such that genes are coexpressed
- 61. Clustering: Application 2 Document Clustering: Goal: To find groups of documents that are similar to each
- 62. Clustering of S&P 500 Stock Data Observe Stock Movements every day. Cluster stocks if they change
- 63. Coverage Given a set of customers and items and the transaction relationship between the two, select
- 64. Classification: Definition Given a collection of records (training set ) Each record contains a set of
- 65. Classification Example categorical categorical continuous class Training Set Learn Classifier 63
- 66. Classification: Application 1 Ad Click Prediction Goal: Predict if a user that visits a web page
- 67. Classification: Application 2 Fraud Detection Goal: Predict fraudulent cases in credit card transactions. Approach: Use credit
- 68. Link Analysis Ranking Given a collection of web pages that are linked to each other, rank
- 69. Exploratory Analysis Trying to understand the data as a physical phenomenon, and describe them with simple
- 70. Exploratory Analysis: The Web What is the structure and the properties of the web? The Bow-Tie
- 71. Exploratory Analysis: The Web What is the distribution of the incoming links? 69
- 72. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 73. Data Mining: Confluence of Multiple Disciplines Data Mining Machine Learning Statistics Applications Algorithm Pattern Recognition High-Performance
- 74. Why Confluence of Multiple Disciplines? Tremendous amount of data Algorithms must be highly scalable to handle
- 75. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 76. Applications of Data Mining Web page analysis: from web page classification, clustering to PageRank & HITS
- 77. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 78. Major Issues in Data Mining (1) Mining Methodology Mining various and new kinds of knowledge Mining
- 79. Major Issues in Data Mining (2) Efficiency and Scalability Efficiency and scalability of data mining algorithms
- 80. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 81. A Brief History of Data Mining Society 1989 IJCAI Workshop on Knowledge Discovery in Databases Knowledge
- 82. Conferences and Journals on Data Mining KDD Conferences ACM SIGKDD Int. Conf. on Knowledge Discovery in
- 83. Where to Find References? DBLP, CiteSeer, Google Data mining and KDD (SIGKDD: CDROM) Conferences: ACM-SIGKDD, IEEE-ICDM,
- 84. Chapter 1. Introduction Why Data Mining? What Is Data Mining? A Multi-Dimensional View of Data Mining
- 85. Summary Data mining: Discovering interesting patterns and knowledge from massive amount of data A natural evolution
- 86. Recommended Reference Books S. Chakrabarti. Mining the Web: Statistical Analysis of Hypertex and Semi-Structured Data. Morgan
- 87. Additional Slides
- 89. Скачать презентацию
Grading Policy
Mid-Exam: 25%
Final Exam: 40%
Research Work (with Presentation): 15(up to 25)%
Project:
Grading Policy
Mid-Exam: 25%
Final Exam: 40%
Research Work (with Presentation): 15(up to 25)%
Project:

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Why Data Mining?
The Explosive Growth of Data: from terabytes to
Why Data Mining?
The Explosive Growth of Data: from terabytes to

Why do we need data mining?
Really, really huge amounts of raw
Why do we need data mining?
Really, really huge amounts of raw

Why do we need data mining?
“The data is the computer”
Large amounts
Why do we need data mining?
“The data is the computer”
Large amounts
Data Mining as the Evolution of Information Technology
1960s:
Data collection, database creation,
Data Mining as the Evolution of Information Technology
1960s:
Data collection, database creation,

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

What Is Data Mining?
Data mining (knowledge discovery from data)
Extraction of
What Is Data Mining?
Data mining (knowledge discovery from data)
Extraction of

Knowledge Discovery (KDD) Process
The knowledge discovery process is an iterative sequence
Knowledge Discovery (KDD) Process
The knowledge discovery process is an iterative sequence

Knowledge Discovery (KDD) Process
The knowledge discovery process is an iterative sequence
Knowledge Discovery (KDD) Process
The knowledge discovery process is an iterative sequence

Example: A Web Mining Framework
Web mining usually involves
Data cleaning
Data integration from
Example: A Web Mining Framework
Web mining usually involves
Data cleaning
Data integration from
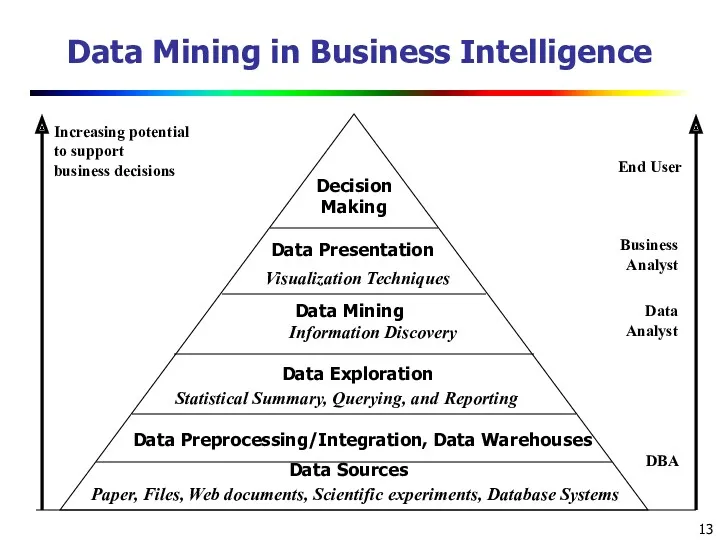
Data Mining in Business Intelligence
Increasing potential
to support
business decisions
End User
Business
Analyst
Data Mining in Business Intelligence
Increasing potential
to support
business decisions
End User
Business
Analyst
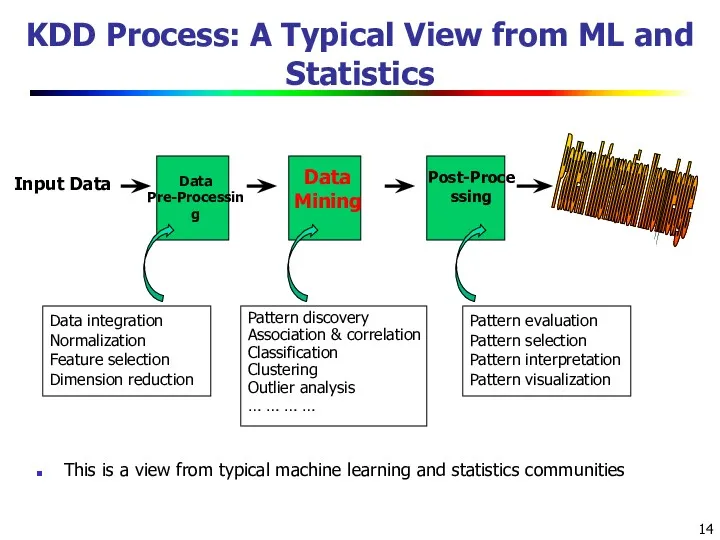
KDD Process: A Typical View from ML and Statistics
Input Data
Pattern Information
KDD Process: A Typical View from ML and Statistics
Input Data
Pattern Information

Example: Medical Data Mining
Health care & medical data mining –
Example: Medical Data Mining
Health care & medical data mining –

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Multi-Dimensional View of Data Mining
Data to be mined
Database data (extended-relational, object-oriented,
Multi-Dimensional View of Data Mining
Data to be mined
Database data (extended-relational, object-oriented,

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Data Mining: On What Kinds of Data?
Database-oriented data sets and applications
Relational
Data Mining: On What Kinds of Data?
Database-oriented data sets and applications
Relational

The data is also very complex
Multiple types of data: tables, time
The data is also very complex
Multiple types of data: tables, time

Example: transaction data
Billions of real-life customers:
WALMART: 20M transactions per day
AT&T
Example: transaction data
Billions of real-life customers:
WALMART: 20M transactions per day
AT&T

Example: document data
Web as a document repository: estimated 50 billions of
Example: document data
Web as a document repository: estimated 50 billions of

Example: network data
Web: 50 billion pages linked via hyperlinks
Facebook: 500 million
Example: network data
Web: 50 billion pages linked via hyperlinks
Facebook: 500 million

Example: genomic sequences
http://www.1000genomes.org/page.php
Full sequence of 1000 individuals
3*109 nucleotides per person ?
Example: genomic sequences
http://www.1000genomes.org/page.php
Full sequence of 1000 individuals
3*109 nucleotides per person ?

Example: environmental data
Climate data (just an example)
http://www.ncdc.gov/oa/climate/ghcn-monthly/index.php
“a database of temperature, precipitation
Example: environmental data
Climate data (just an example)
http://www.ncdc.gov/oa/climate/ghcn-monthly/index.php
“a database of temperature, precipitation

Behavioral data
Mobile phones today record a large amount of information about
Behavioral data
Mobile phones today record a large amount of information about

So, what is Data?
Collection of data objects and their attributes
An attribute
So, what is Data?
Collection of data objects and their attributes
An attribute

Types of Attributes
There are different types of attributes
Categorical
Examples:
Types of Attributes
There are different types of attributes
Categorical
Examples:
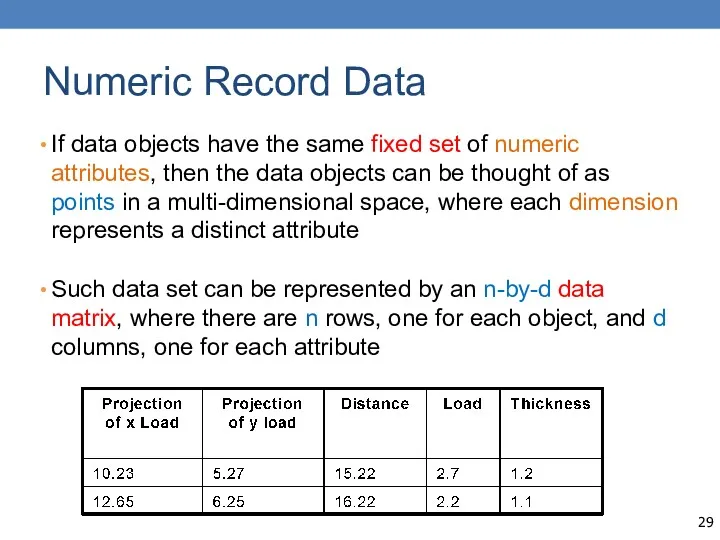
Numeric Record Data
If data objects have the same fixed set of
Numeric Record Data
If data objects have the same fixed set of
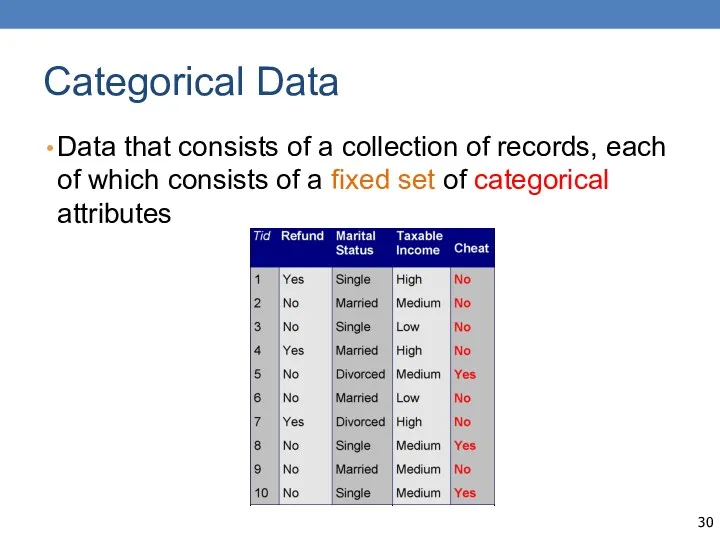
Categorical Data
Data that consists of a collection of records, each
Categorical Data
Data that consists of a collection of records, each

Document Data
Each document becomes a `term' vector,
each term is a
Document Data
Each document becomes a `term' vector,
each term is a

Transaction Data
Each record (transaction) is a set of items.
A set of
Transaction Data
Each record (transaction) is a set of items.
A set of

Ordered Data
Genomic sequence data
Data is a long ordered string
33
Ordered Data
Genomic sequence data
Data is a long ordered string
33
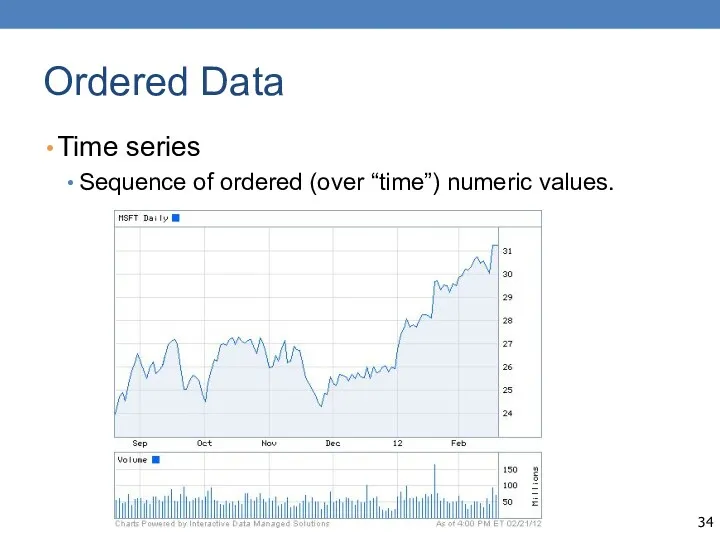
Ordered Data
Time series
Sequence of ordered (over “time”) numeric values.
34
Ordered Data
Time series
Sequence of ordered (over “time”) numeric values.
34
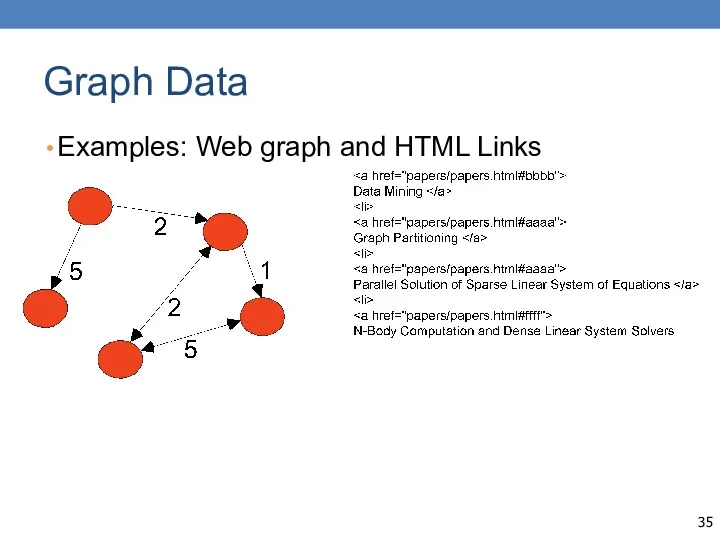
Graph Data
Examples: Web graph and HTML Links
35
Graph Data
Examples: Web graph and HTML Links
35

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Data Mining Function: (1) Generalization
Information integration and data warehouse construction
Data cleaning,
Data Mining Function: (1) Generalization
Information integration and data warehouse construction
Data cleaning,
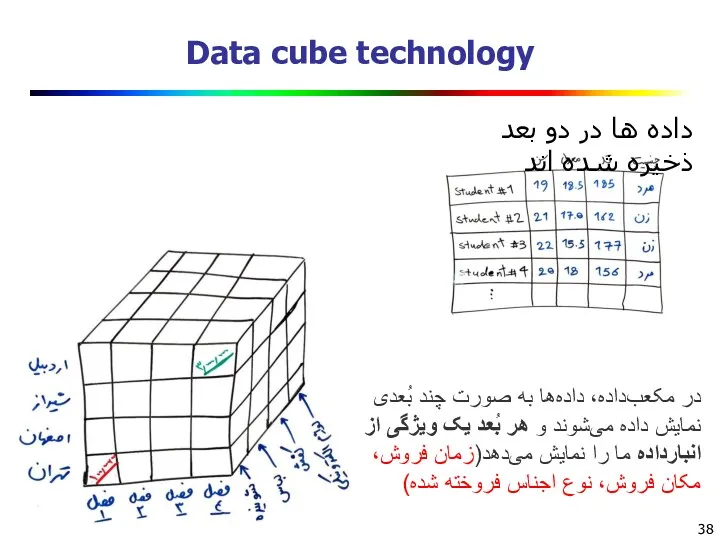
Data cube technology
داده ها در دو بعد ذخیره شده اند
در مکعبداده،
Data cube technology
داده ها در دو بعد ذخیره شده اند
در مکعبداده،

Data Mining Function: (2) Association and Correlation Analysis
Frequent patterns (or frequent
Data Mining Function: (2) Association and Correlation Analysis
Frequent patterns (or frequent

Data Mining Function: (3) Classification
Classification and label prediction
Construct models (functions)
Data Mining Function: (3) Classification
Classification and label prediction
Construct models (functions)
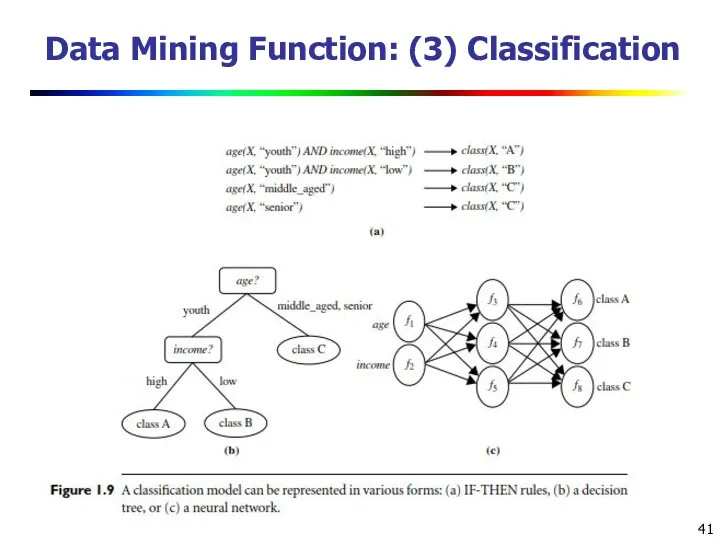
Data Mining Function: (3) Classification
Data Mining Function: (3) Classification

Data Mining Function: (4) Cluster Analysis
Unsupervised learning (i.e., Class label is
Data Mining Function: (4) Cluster Analysis
Unsupervised learning (i.e., Class label is
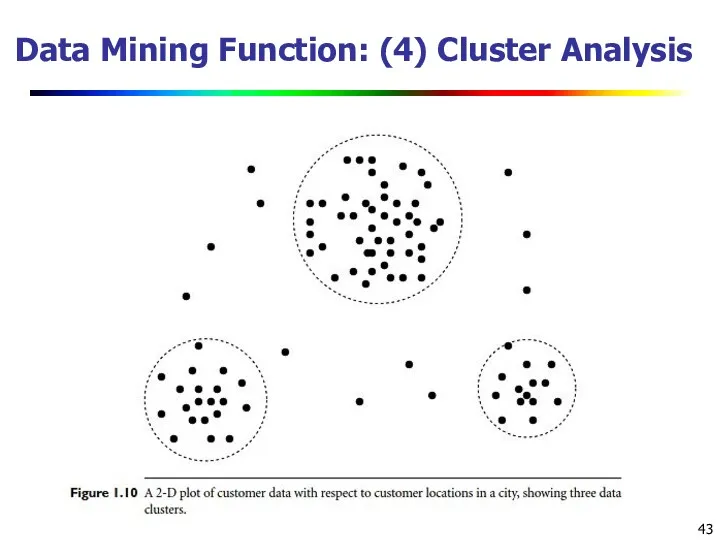
Data Mining Function: (4) Cluster Analysis
Data Mining Function: (4) Cluster Analysis

Data Mining Function: (5) Outlier Analysis
Outlier analysis
Outlier: A data object that
Data Mining Function: (5) Outlier Analysis
Outlier analysis
Outlier: A data object that

What can you do with the data?
Suppose that you are the
What can you do with the data?
Suppose that you are the

What can you do with the data?
Suppose you are a search
What can you do with the data?
Suppose you are a search

What can you do with the data?
Suppose you are biologist who
What can you do with the data?
Suppose you are biologist who
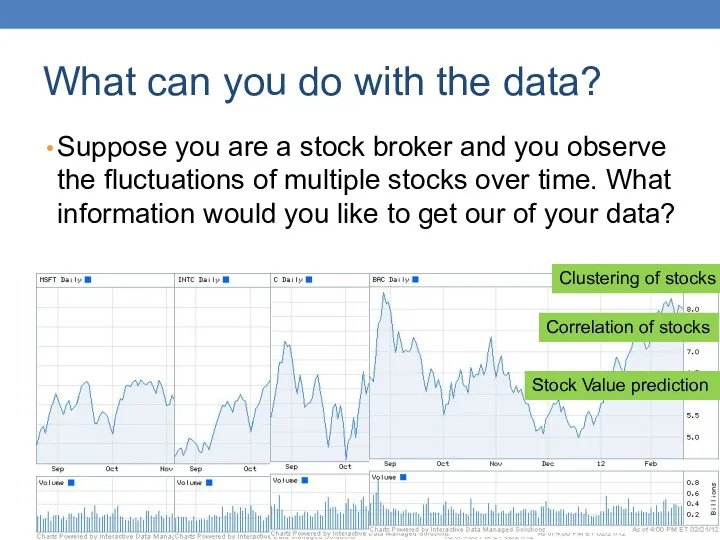
What can you do with the data?
Suppose you are a stock
What can you do with the data?
Suppose you are a stock

What can you do with the data?
You are the owner of
What can you do with the data?
You are the owner of

Time and Ordering: Sequential Pattern, Trend and Evolution Analysis
Sequence, trend and
Time and Ordering: Sequential Pattern, Trend and Evolution Analysis
Sequence, trend and

Time and Ordering: Sequential Pattern, Trend and Evolution Analysis
Sequential pattern mining:
an
Time and Ordering: Sequential Pattern, Trend and Evolution Analysis
Sequential pattern mining:
an
Structure and Network Analysis
Graph mining
Finding frequent subgraphs (e.g., chemical compounds-malware analysis),
Structure and Network Analysis
Graph mining
Finding frequent subgraphs (e.g., chemical compounds-malware analysis),

Evaluation of Knowledge
Are all mined knowledge interesting?
One can mine tremendous amount
Evaluation of Knowledge
Are all mined knowledge interesting?
One can mine tremendous amount

What can we do with data mining?
Some examples:
Frequent itemsets and Association
What can we do with data mining?
Some examples:
Frequent itemsets and Association

Frequent Itemsets and Association Rules
Given a set of records each of
Frequent Itemsets and Association Rules
Given a set of records each of

Frequent Itemsets: Applications
Text mining: finding associated phrases in text
There are lots
Frequent Itemsets: Applications
Text mining: finding associated phrases in text
There are lots

Association Rule Discovery: Application
Supermarket shelf management.
Goal: To identify items that are
Association Rule Discovery: Application
Supermarket shelf management.
Goal: To identify items that are

Clustering Definition
Given a set of data points, each having a set
Clustering Definition
Given a set of data points, each having a set
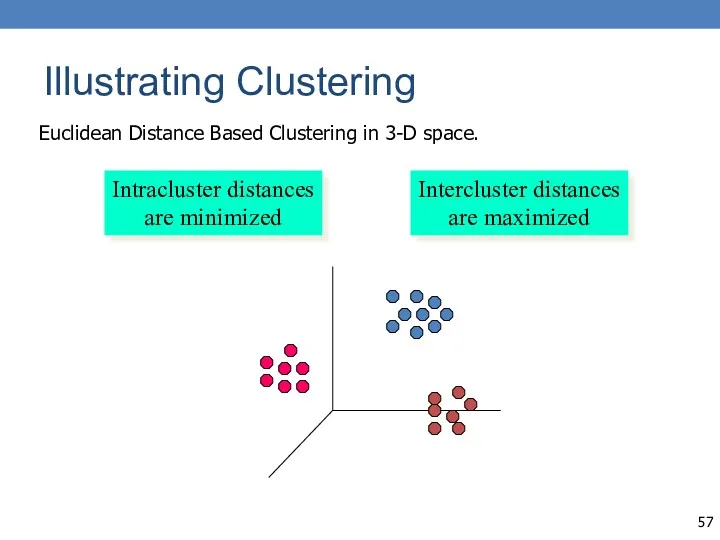
Illustrating Clustering
Euclidean Distance Based Clustering in 3-D space.
Intracluster distances
are minimized
Intercluster distances
are
Illustrating Clustering
Euclidean Distance Based Clustering in 3-D space.
Intracluster distances
are minimized
Intercluster distances
are

Clustering: Application 1
Bioinformatics applications:
Goal: Group genes and tissues together such that
Clustering: Application 1
Bioinformatics applications:
Goal: Group genes and tissues together such that

Clustering: Application 2
Document Clustering:
Goal: To find groups of documents that are
Clustering: Application 2
Document Clustering:
Goal: To find groups of documents that are
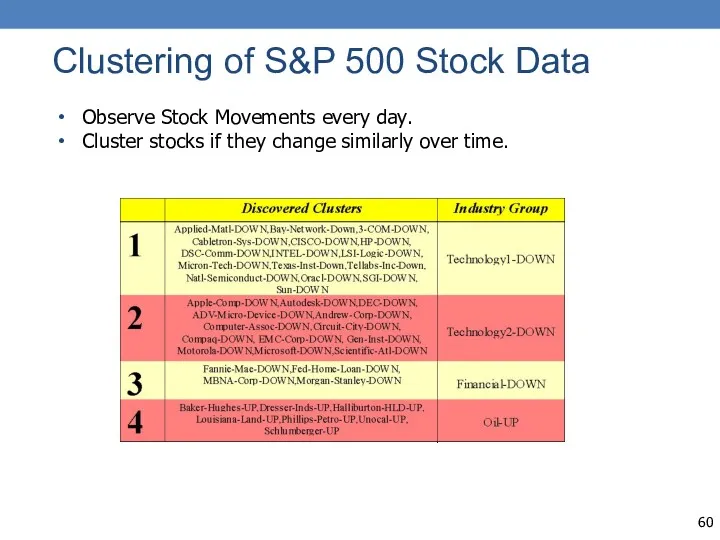
Clustering of S&P 500 Stock Data
Observe Stock Movements every day.
Cluster
Clustering of S&P 500 Stock Data
Observe Stock Movements every day.
Cluster

Coverage
Given a set of customers and items and the transaction relationship
Coverage
Given a set of customers and items and the transaction relationship

Classification: Definition
Given a collection of records (training set )
Each record contains
Classification: Definition
Given a collection of records (training set )
Each record contains
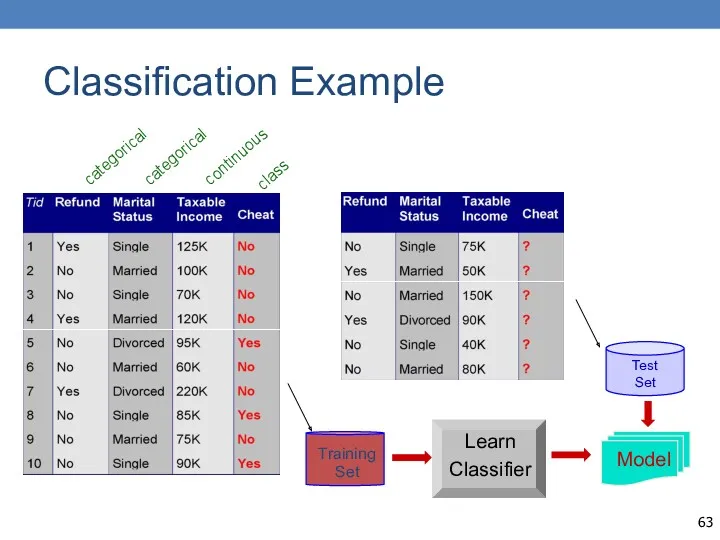
Classification Example
categorical
categorical
continuous
class
Training
Set
Learn
Classifier
63
Classification Example
categorical
categorical
continuous
class
Training
Set
Learn
Classifier
63

Classification: Application 1
Ad Click Prediction
Goal: Predict if a user that visits
Classification: Application 1
Ad Click Prediction
Goal: Predict if a user that visits

Classification: Application 2
Fraud Detection
Goal: Predict fraudulent cases in credit card transactions.
Approach:
Use
Classification: Application 2
Fraud Detection
Goal: Predict fraudulent cases in credit card transactions.
Approach:
Use

Link Analysis Ranking
Given a collection of web pages that are linked
Link Analysis Ranking
Given a collection of web pages that are linked

Exploratory Analysis
Trying to understand the data as a physical phenomenon, and
Exploratory Analysis
Trying to understand the data as a physical phenomenon, and
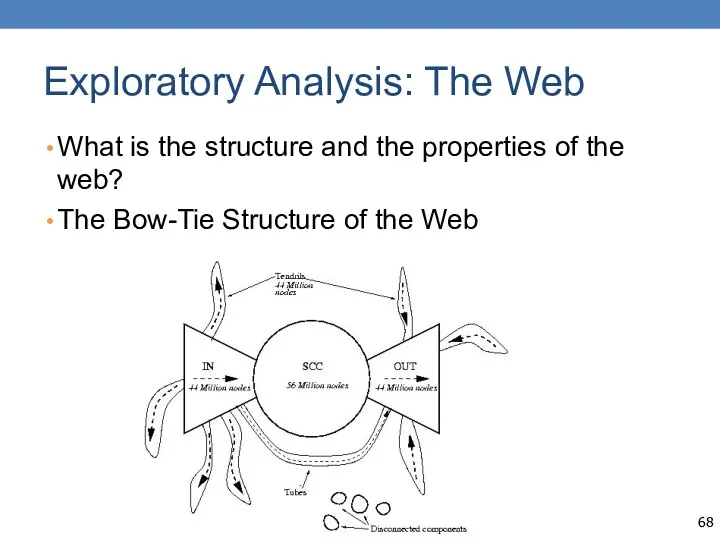
Exploratory Analysis: The Web
What is the structure and the properties of
Exploratory Analysis: The Web
What is the structure and the properties of
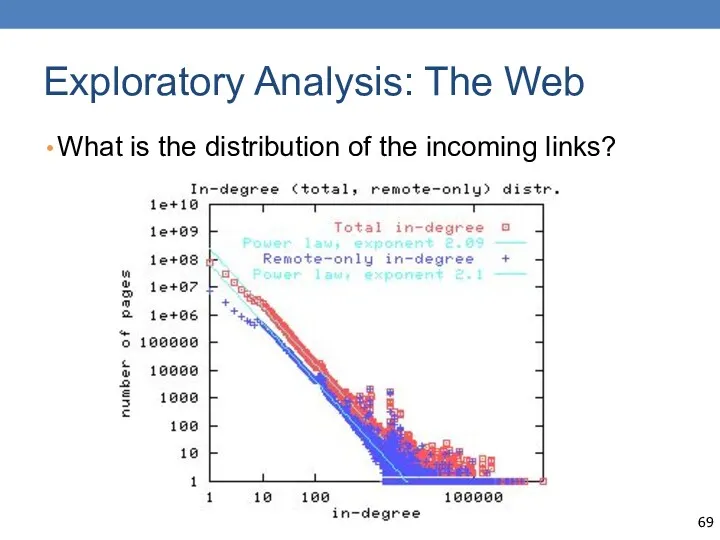
Exploratory Analysis: The Web
What is the distribution of the incoming links?
69
Exploratory Analysis: The Web
What is the distribution of the incoming links?
69

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
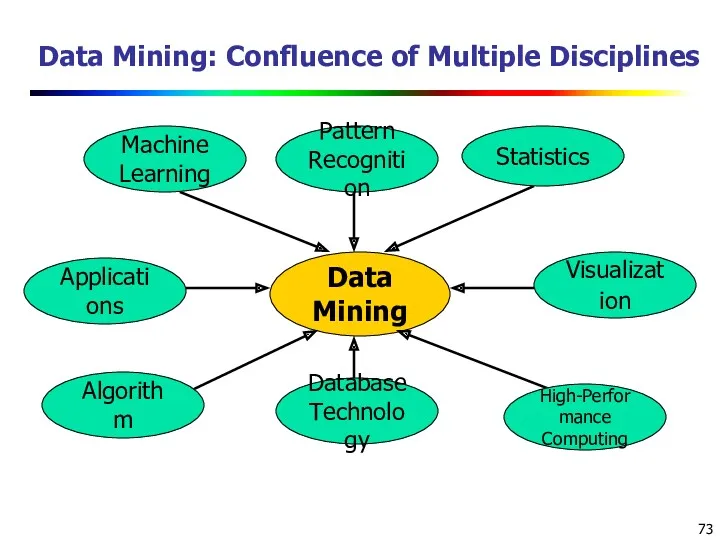
Data Mining: Confluence of Multiple Disciplines
Data Mining
Machine
Learning
Statistics
Applications
Algorithm
Pattern
Recognition
High-Performance
Computing
Visualization
Database
Technology
Data Mining: Confluence of Multiple Disciplines
Data Mining
Machine
Learning
Statistics
Applications
Algorithm
Pattern
Recognition
High-Performance
Computing
Visualization
Database
Technology

Why Confluence of Multiple Disciplines?
Tremendous amount of data
Algorithms must be highly
Why Confluence of Multiple Disciplines?
Tremendous amount of data
Algorithms must be highly

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Applications of Data Mining
Web page analysis: from web page classification, clustering
Applications of Data Mining
Web page analysis: from web page classification, clustering

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Major Issues in Data Mining (1)
Mining Methodology
Mining various and new kinds
Major Issues in Data Mining (1)
Mining Methodology
Mining various and new kinds

Major Issues in Data Mining (2)
Efficiency and Scalability
Efficiency and scalability of
Major Issues in Data Mining (2)
Efficiency and Scalability
Efficiency and scalability of

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

A Brief History of Data Mining Society
1989 IJCAI Workshop on Knowledge
A Brief History of Data Mining Society
1989 IJCAI Workshop on Knowledge

Conferences and Journals on Data Mining
KDD Conferences
ACM SIGKDD Int. Conf. on
Conferences and Journals on Data Mining
KDD Conferences
ACM SIGKDD Int. Conf. on

Where to Find References? DBLP, CiteSeer, Google
Data mining and KDD (SIGKDD:
Where to Find References? DBLP, CiteSeer, Google
Data mining and KDD (SIGKDD:

Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of

Summary
Data mining: Discovering interesting patterns and knowledge from massive amount of
Summary
Data mining: Discovering interesting patterns and knowledge from massive amount of

Recommended Reference Books
S. Chakrabarti. Mining the Web: Statistical Analysis of Hypertex
Recommended Reference Books
S. Chakrabarti. Mining the Web: Statistical Analysis of Hypertex

 Правила оформления отчетов
Правила оформления отчетов Общие сведения о компьютере
Общие сведения о компьютере Устройства памяти компьютера презентация
Устройства памяти компьютера презентация Информация
Информация Автоматизированное рабочее место коменданта общежития БГПК
Автоматизированное рабочее место коменданта общежития БГПК Matlab Simulink и SimInTech. Импортозамещение ПО для моделирования систем
Matlab Simulink и SimInTech. Импортозамещение ПО для моделирования систем Мова програмування Java 2 (Java SE 6, Java SE 7)
Мова програмування Java 2 (Java SE 6, Java SE 7) Огляд технології блокчейн
Огляд технології блокчейн ИКТ – компетенции педагога в условиях реализации ФГОС
ИКТ – компетенции педагога в условиях реализации ФГОС Вставка рисунка и гиперссылки Рисунки в таблице Фотогалерея
Вставка рисунка и гиперссылки Рисунки в таблице Фотогалерея HTML құжатында кестелерді қалыптастыру. Кесте параметрлерін тағайындау тегтері
HTML құжатында кестелерді қалыптастыру. Кесте параметрлерін тағайындау тегтері Технология создания и обработки текстовой информации
Технология создания и обработки текстовой информации Принципы концептуального проектирования баз данных. Лекция 1
Принципы концептуального проектирования баз данных. Лекция 1 Управляй персоналом грамотно. День деловой книги
Управляй персоналом грамотно. День деловой книги Сервисно-ориентированная архитектура
Сервисно-ориентированная архитектура Информация и информационные процессы
Информация и информационные процессы История развития ЭВМ
История развития ЭВМ Циклы while и for
Циклы while и for Company Apple
Company Apple Городская универсальная телекоммуникационная сеть ДОМ.RU
Городская универсальная телекоммуникационная сеть ДОМ.RU Транзакции и целостность баз данных
Транзакции и целостность баз данных Microsoft Access Мәліметтер қорын басқару жүйесі
Microsoft Access Мәліметтер қорын басқару жүйесі Функциональное моделирование. Правила IDEF0. (Лекция 5)
Функциональное моделирование. Правила IDEF0. (Лекция 5) Список. Обработка информации
Список. Обработка информации Данные и таблицы
Данные и таблицы Безопасность, диагностика и восстановление ОС после отказов
Безопасность, диагностика и восстановление ОС после отказов Работа с учетными записями пользователей в Windows 10 подробное руководство
Работа с учетными записями пользователей в Windows 10 подробное руководство Интернет-предпринимательство. Лекция О курсе
Интернет-предпринимательство. Лекция О курсе