- Динамические структуры данных и их организация с помощью указателей

Содержание
- 2. Линейные списки (однонаправленные цепочки) Списком называется структура данных, каждый элемент которой посредством указателя связывается со следующим
- 3. Лишь на самый первый элемент списка (голову) имеется отдельный указатель. Последний элемент списка никуда не указывает.
- 4. Для иллюстрации работы с линейными списками рассмотрим задачу: Разработайте программу работы с односвязным списком. Программа должна
- 5. Описание списка Пример описания списка type ukaz=^spisok; spisok=record inf:integer; next:ukaz; end; В Паскале существует основное правило:
- 6. Разработаем программу методом пошаговой детализации. Чтобы список существовал, надо определить указатель на его начало. Создадим список:
- 7. Организуем бесконечный цикл, и в зависимости от выбранного пользователем пункта меню будем вызывать соответствующие процедуры. while
- 8. 3: begin udalenie1(ug); vivod(ug); end; 4: halt; else writeln('Net punkta') end; end; end. Теперь детализируем каждую
- 9. А) Добавим элемент в голову списка. Для этого необходимо выполнить последовательность действий: получить память для нового
- 10. Б)Добавление элемента в конец списка. Для этого необходимо выполнить последовательность действий: Найти последний элемент списка. Выделить
- 11. new(y); {Выделяем память для нового элемента} y^.inf:=z; {Помещаем информацию в поле inf } y^.next:=nil; {Следующего за
- 12. Вывод списка на экран procedure vivod( ug:ukaz); var x:ukaz; begin x:=ug^.next; {Копируем указатель на голову в
- 13. while x nil do {Выполняем цикл до тех пор, пока x не указывает на «пусто» (пока
- 14. Удаление первого элемента из списка Во вспомогательном указателе запомним указатель на первый элемент. Поле next указателя
- 15. else begin x:=ug^.next; {Во вспомогательном указателе запомним адрес первого элемента} ug^.next:=x^.next; {Поле next указателя на голову
- 16. Продемонстрируем применение вышеприведенных процедур в итоговой программе: type ukaz=^spisok; spisok=record inf:integer; next:ukaz; end; var ug:ukaz; a:integer;
- 17. begin writeln('Spisok pust'); exit; end else begin x:=ug^.next; ug^.next:=x^.next; dispose(x); end; end; procedure vivod( ug:ukaz);
- 18. var x:ukaz; begin x:=ug^.next; write('spisok '); if ug^.next=nil then writeln('pust') else while x nil do begin
- 19. procedure dobavlenieVxvost(ug:ukaz; z:integer); var x,y:ukaz; begin x:=ug; while x^.next nil do x:=x^.next; new(y); y^.inf:=z; y^.next:=nil; x^.next:=y;
- 20. procedure dobavlenieVgol(var ug:ukaz; z:integer); var x:ukaz; begin new(x); x^.inf:=z; x^.next:=ug^.next; ug^.next:=x; end; begin new(ug); ug^.next:=nil;
- 21. writeln('1. Dobavit element v nachalo'); writeln('2. Dobavit element v konets'); writeln('3. udalit 1 element'); writeln('4. exit');
- 22. 2: begin writeln('Vvedite element'); readln(a); dobavlenieVxvost(ug,a); vivod(ug); end; 3: begin udalenie1(ug); vivod(ug); end; 4: halt; else
- 23. Двунаправленный список Использование однонаправленных списков при решении ряда задач может вызвать определенные трудности. По однонаправленному списку
- 24. Type ukazat= ^S; S= record Inf: integer; Next: ukazat; Pred: ukazat; End; Динамическая структура, состоящая из
- 25. Наличие в каждом звене двунаправленного списка ссылки как на следующее, так и на предыдущее звено позволяет
- 26. Кольцевые списки В программировании двунаправленные списки часто обобщают следующим образом: в качестве значения поля Next последнего
- 27. Как видно, здесь список замыкается в своеобразное «кольцо»: двигаясь по ссылкам, можно от последнего звена переходить
- 28. Стек и очередь Стек –вид списка, обращение к которому идет только через указатель на первый элемент.
- 29. Деревья Дерево – это совокупность элементов, называемых узлами (один из которых определен как корень), и отношений,
- 30. Т.е. каждый узел дерева является корнем некоторого поддерева данного дерева. Количество поддеревьев узла называется степенью этого
- 31. Узел A является корнем, который имеет два поддерева {B} и {C, D, E, F, G}. Корнем
- 32. Обходы дерева Существует несколько способов обхода всех узлов дерева. Три наиболее часто используемых способа обхода называются
- 33. Прямой обход. Сначала посещается корень n , затем в прямом порядке узлы поддерева T1, далее все
- 34. Порядок узлов данного дерева в случае прямого обхода будет следующим: 1 2 3 5 8 9
- 35. Двоичные деревья Двоичное или бинарное дерево – это наиболее важный тип деревьев. Каждый узел бинарного дерева
- 36. По аналогии с элементами списков, узлы дерева удобно представить в виде записей, хранящих информацию и два
- 37. Дерево поиска Способ построения дерева, при котором для каждого узла все ключи (значения узлов) его левого
- 38. Дерево поиска может быть использовано для построения упорядоченной последовательности ключей узлов. Например, если мы используем симметричный
- 39. Разработайте программу работы с бинарным деревом. Программа должна содержать следующие процедуры, вызываемые из меню: построение пустого
- 40. Создание пустого дерева type ptree=^tree; tree=record inf:integer; left,right:ptree; end; procedure sozdanie(var kor:ptree); begin new(kor); kor:=nil; end;
- 41. Добавление элемента Для того чтобы вставить узел, необходимо найти его место. Для этого мы сравниваем вставляемое
- 42. p^.inf:=z; {Записываем в поле inf информацию} p^.left:=nil;{Левые и правые сыновья нового элемента nil} p^.right:=nil; {т.к. в
- 43. begin new(p); p^.inf:=z; p^.left:=nil; p^.right:=nil; kor^.left:=p end else {если у корня есть левый сын, то вызываем
- 44. end else if kor^.right=nil then {если вставляемое значение не меньше корня, то, если у корня нет
- 45. Обход дерева и вывод на экран (левая ветвь, корень, правая ветвь) procedure vivod(kor:ptree); begin if kor^.left
- 46. Поиск узла с заданным значением Функция poisk не только возвращает значение true, если в дереве есть
- 47. parent:=p; {текущее значение указателя p сохраняем в переменной parent как предка} if z else p:=p^.right; {Если
- 48. Удаление узла Если узел является конечным (то есть не имеет потомков), то его удаление не вызывает
- 49. Если у удаляемого узла есть только один потомок, то он заменяет удаляемый узел.
- 50. Сложнее всего случай, когда у удаляемого узла есть оба потомка. Есть простой особый случай: если у
- 51. В общем же случае на место удаляемого узла ставится самый левый узел его правого поддерева (или
- 52. procedure del(var kor:ptree; z:integer); {Удаляет узел со значением z из дерева с корнем kor} var p:ptree;
- 53. function findZamena(p:ptree):ptree; var y:ptree; {Указатель на узел, замещающий удаляемый} predy:ptree; {Указатель на предка узла, замещающего удаляемый}
- 54. if y^.left=nil then y^.left:=p^.left {Если у правого сына удаляемого узла (на него указывает y) нет левого
- 55. y^.left:=p^.left; {Подключаем к узлу y, замещающему удаляемый узел p, левого потомка удаляемого узла (своего левого у
- 56. begin {начало самой процедуры удаления del } {При вызове процедуры poisk, которая возвращает значение булевского типа,
- 57. if p=kor then kor:=y {Если удаляемый элемент является корнем дерева, надо указателю на корень присвоить указатель
- 58. Вся программа: Разработайте программу работы с бинарным деревом. Программа должна содержать следующие процедуры, вызываемые из меню:
- 59. Type ptree=^tree; tree=record inf:integer; left,right:ptree; end; Var p,kor,parent:ptree; a, z:integer;
- 60. procedure Sozdanie(var kor:ptree); begin new(kor); kor:=nil; end; procedure Dobavl(var kor:ptree; z:integer); begin if kor=nil then begin
- 61. kor:=p; end else begin if z begin if kor^.left=nil then begin new(p); p^.inf:=z; p^.left:=nil; p^.right:=nil; kor^.left:=p
- 62. else begin Dobavl(kor^.left, z); end; end else if kor^.right=nil then begin new(p); p^.inf:=z; p^.left:=nil; p^.right:=nil; kor^.right:=p
- 63. else Dobavl(kor^.right, z); end; end;
- 64. procedure Vivod(kor:ptree); begin if kor^.left nil then Vivod(kor^.left); Writeln(kor^.inf); if kor^.right nil then Vivod(kor^.right); end; function
- 65. if z=p^.inf then begin poisk:=true; exit; end; parent:=p; if z p:=p^.left else p:=p^.right; end; poisk:=false; end;
- 66. procedure del(var kor:ptree; z:integer); var p:ptree; {udaljaemij el} parent:ptree; {predok p} y:ptree; {zamenit p} function findZamena(p:ptree):ptree;
- 67. begin y:=p^.right; if y^.left=nil then y^.left:=p^.left else begin repeat predy:=y; y:=y^.left; until y^.left nil; y^.left:=p^.left; predy^.left:=y^.right;
- 68. begin if not poisk(kor, z,p,parent) then begin writeln(‘Нет элемента’); exit; end; y:=findZamena(p); if p=kor then kor:=y
- 69. Begin while a 6 do begin Writeln('1. Sozdanie'); Writeln('2. Dobavlenie elementa'); Writeln('3. Delete'); Writeln('4. Poisk'); Writeln('5.
- 70. 2: begin writeln('Vvedite chislo'); readln(z); Dobavl(kor, z); Vivod(kor); writeln; end; 3: begin Write('Vvedite chislo '); Readln(a);
- 71. 4: begin Write('Vvedite chislo'); Readln(a); if Poisk(kor,a,p,parent) then Writeln(‘yes!') else Writeln(‘no!'); end; 5: begin Vivod(kor); end;
- 73. Скачать презентацию

Линейные списки (однонаправленные цепочки)
Списком называется структура данных, каждый элемент которой посредством
Линейные списки (однонаправленные цепочки)
Списком называется структура данных, каждый элемент которой посредством

Лишь на самый первый элемент списка (голову) имеется отдельный указатель. Последний
Лишь на самый первый элемент списка (голову) имеется отдельный указатель. Последний

Для иллюстрации работы с линейными списками рассмотрим задачу:
Разработайте программу работы с
Для иллюстрации работы с линейными списками рассмотрим задачу:
Разработайте программу работы с

Описание списка
Пример описания списка
type ukaz=^spisok;
spisok=record
inf:integer;
next:ukaz;
end;
В Паскале
Описание списка
Пример описания списка
type ukaz=^spisok;
spisok=record
inf:integer;
next:ukaz;
end;
В Паскале

Разработаем программу методом пошаговой детализации.
Чтобы список существовал, надо определить указатель на
Разработаем программу методом пошаговой детализации.
Чтобы список существовал, надо определить указатель на

Организуем бесконечный цикл, и в зависимости от выбранного пользователем пункта меню
Организуем бесконечный цикл, и в зависимости от выбранного пользователем пункта меню

3: begin
udalenie1(ug); vivod(ug);
end;
4: halt;
else writeln('Net punkta')
end;
end;
3: begin
udalenie1(ug); vivod(ug);
end;
4: halt;
else writeln('Net punkta')
end;
end;

А) Добавим элемент в голову списка. Для этого необходимо выполнить последовательность
А) Добавим элемент в голову списка. Для этого необходимо выполнить последовательность

Б)Добавление элемента в конец списка. Для этого необходимо выполнить последовательность действий:
Найти
Б)Добавление элемента в конец списка. Для этого необходимо выполнить последовательность действий:
Найти

new(y); {Выделяем память для нового элемента}
y^.inf:=z; {Помещаем информацию в
new(y); {Выделяем память для нового элемента}
y^.inf:=z; {Помещаем информацию в

Вывод списка на экран
procedure vivod( ug:ukaz);
var x:ukaz;
begin
x:=ug^.next; {Копируем указатель
Вывод списка на экран
procedure vivod( ug:ukaz);
var x:ukaz;
begin
x:=ug^.next; {Копируем указатель

while x<>nil do {Выполняем цикл до тех пор, пока x
while x<>nil do {Выполняем цикл до тех пор, пока x

Удаление первого элемента из списка
Во вспомогательном указателе запомним указатель на первый
Удаление первого элемента из списка
Во вспомогательном указателе запомним указатель на первый

else
begin
x:=ug^.next; {Во вспомогательном указателе запомним адрес первого элемента}
ug^.next:=x^.next; {Поле
else
begin
x:=ug^.next; {Во вспомогательном указателе запомним адрес первого элемента}
ug^.next:=x^.next; {Поле

Продемонстрируем применение вышеприведенных процедур в итоговой программе:
type ukaz=^spisok;
spisok=record
inf:integer;
next:ukaz;
Продемонстрируем применение вышеприведенных процедур в итоговой программе:
type ukaz=^spisok;
spisok=record
inf:integer;
next:ukaz;

begin
writeln('Spisok pust');
exit;
end
else
begin
x:=ug^.next;
ug^.next:=x^.next;
dispose(x);
end;
end;
procedure
begin
writeln('Spisok pust');
exit;
end
else
begin
x:=ug^.next;
ug^.next:=x^.next;
dispose(x);
end;
end;
procedure

var x:ukaz;
begin
x:=ug^.next;
write('spisok ');
if ug^.next=nil then
writeln('pust')
else
while
var x:ukaz;
begin
x:=ug^.next;
write('spisok ');
if ug^.next=nil then
writeln('pust')
else
while

procedure dobavlenieVxvost(ug:ukaz; z:integer);
var x,y:ukaz;
begin
x:=ug;
while x^.next<>nil do
x:=x^.next;
new(y);
procedure dobavlenieVxvost(ug:ukaz; z:integer);
var x,y:ukaz;
begin
x:=ug;
while x^.next<>nil do
x:=x^.next;
new(y);

procedure dobavlenieVgol(var ug:ukaz; z:integer);
var x:ukaz;
begin
new(x);
x^.inf:=z;
x^.next:=ug^.next;
ug^.next:=x;
end;
begin
new(ug);
procedure dobavlenieVgol(var ug:ukaz; z:integer);
var x:ukaz;
begin
new(x);
x^.inf:=z;
x^.next:=ug^.next;
ug^.next:=x;
end;
begin
new(ug);

writeln('1. Dobavit element v nachalo');
writeln('2. Dobavit element v konets');
writeln('1. Dobavit element v nachalo');
writeln('2. Dobavit element v konets');

2: begin
writeln('Vvedite element'); readln(a);
dobavlenieVxvost(ug,a); vivod(ug);
end;
3: begin
2: begin
writeln('Vvedite element'); readln(a);
dobavlenieVxvost(ug,a); vivod(ug);
end;
3: begin

Двунаправленный список
Использование однонаправленных списков при решении ряда задач может вызвать определенные
Двунаправленный список
Использование однонаправленных списков при решении ряда задач может вызвать определенные

Type ukazat= ^S;
S= record
Inf: integer;
Next: ukazat;
Pred: ukazat;
Type ukazat= ^S; S= record Inf: integer; Next: ukazat; Pred: ukazat;

Наличие в каждом звене двунаправленного списка ссылки как на следующее, так
Наличие в каждом звене двунаправленного списка ссылки как на следующее, так

Кольцевые списки
В программировании двунаправленные списки часто обобщают следующим образом: в качестве
Кольцевые списки
В программировании двунаправленные списки часто обобщают следующим образом: в качестве

Как видно, здесь список замыкается в своеобразное «кольцо»: двигаясь по ссылкам,
Как видно, здесь список замыкается в своеобразное «кольцо»: двигаясь по ссылкам,

Стек и очередь
Стек –вид списка, обращение к которому идет только через
Стек и очередь
Стек –вид списка, обращение к которому идет только через

Деревья
Дерево – это совокупность элементов, называемых узлами (один из которых определен
Деревья
Дерево – это совокупность элементов, называемых узлами (один из которых определен

Т.е. каждый узел дерева является корнем некоторого поддерева данного дерева.
Количество
Т.е. каждый узел дерева является корнем некоторого поддерева данного дерева.
Количество
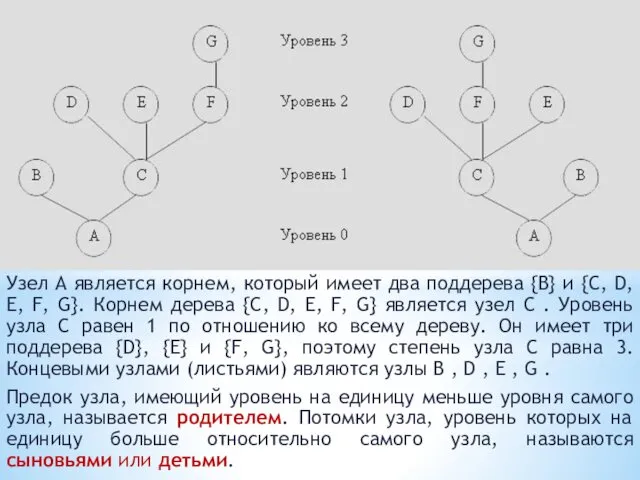
Узел A является корнем, который имеет два поддерева {B} и {C,
Узел A является корнем, который имеет два поддерева {B} и {C,

Обходы дерева
Существует несколько способов обхода всех узлов дерева. Три наиболее часто
Обходы дерева
Существует несколько способов обхода всех узлов дерева. Три наиболее часто

Прямой обход. Сначала посещается корень n , затем в прямом порядке
Прямой обход. Сначала посещается корень n , затем в прямом порядке
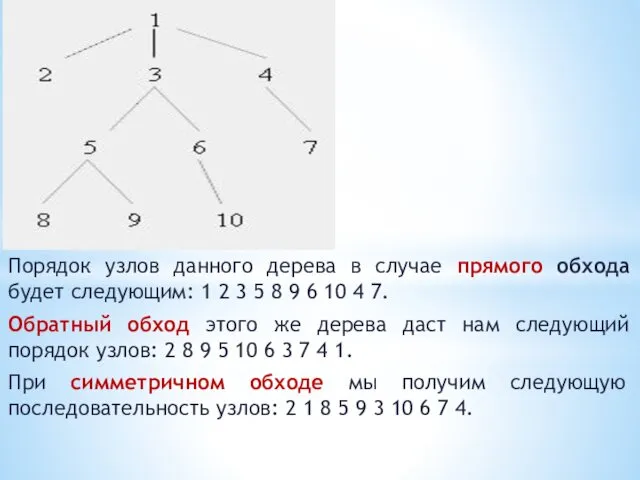
Порядок узлов данного дерева в случае прямого обхода будет следующим: 1
Порядок узлов данного дерева в случае прямого обхода будет следующим: 1

Двоичные деревья
Двоичное или бинарное дерево – это наиболее важный тип деревьев.
Двоичные деревья
Двоичное или бинарное дерево – это наиболее важный тип деревьев.

По аналогии с элементами списков, узлы дерева удобно представить в виде
По аналогии с элементами списков, узлы дерева удобно представить в виде

Дерево поиска
Способ построения дерева, при котором для каждого узла все ключи
Дерево поиска
Способ построения дерева, при котором для каждого узла все ключи

Дерево поиска может быть использовано для построения упорядоченной последовательности ключей узлов.
Дерево поиска может быть использовано для построения упорядоченной последовательности ключей узлов.

Разработайте программу работы с бинарным деревом. Программа должна содержать следующие процедуры,
Разработайте программу работы с бинарным деревом. Программа должна содержать следующие процедуры,

Создание пустого дерева
type ptree=^tree;
tree=record
inf:integer;
left,right:ptree;
end;
procedure sozdanie(var kor:ptree);
begin
new(kor);
kor:=nil;
Создание пустого дерева
type ptree=^tree;
tree=record
inf:integer;
left,right:ptree;
end;
procedure sozdanie(var kor:ptree);
begin
new(kor);
kor:=nil;

Добавление элемента
Для того чтобы вставить узел, необходимо найти его место. Для
Добавление элемента
Для того чтобы вставить узел, необходимо найти его место. Для

p^.inf:=z; {Записываем в поле inf информацию}
p^.left:=nil;{Левые и правые сыновья
p^.inf:=z; {Записываем в поле inf информацию}
p^.left:=nil;{Левые и правые сыновья

begin
new(p);
p^.inf:=z;
p^.left:=nil;
p^.right:=nil;
kor^.left:=p
end
else {если у корня
begin
new(p);
p^.inf:=z;
p^.left:=nil;
p^.right:=nil;
kor^.left:=p
end
else {если у корня

end
else if kor^.right=nil then {если вставляемое значение не меньше
end
else if kor^.right=nil then {если вставляемое значение не меньше

Обход дерева и вывод на экран (левая ветвь, корень, правая ветвь)
procedure
Обход дерева и вывод на экран (левая ветвь, корень, правая ветвь)
procedure

Поиск узла с заданным значением
Функция poisk не только возвращает значение true,
Поиск узла с заданным значением
Функция poisk не только возвращает значение true,

parent:=p; {текущее значение указателя p сохраняем в переменной parent как
parent:=p; {текущее значение указателя p сохраняем в переменной parent как
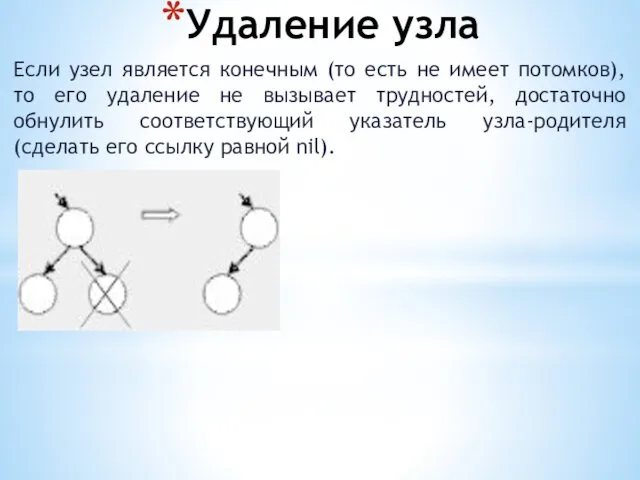
Удаление узла
Если узел является конечным (то есть не имеет потомков), то
Удаление узла
Если узел является конечным (то есть не имеет потомков), то
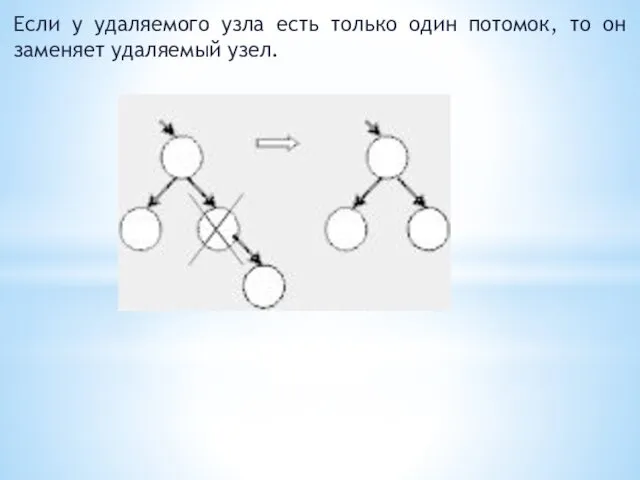
Если у удаляемого узла есть только один потомок, то он заменяет
Если у удаляемого узла есть только один потомок, то он заменяет
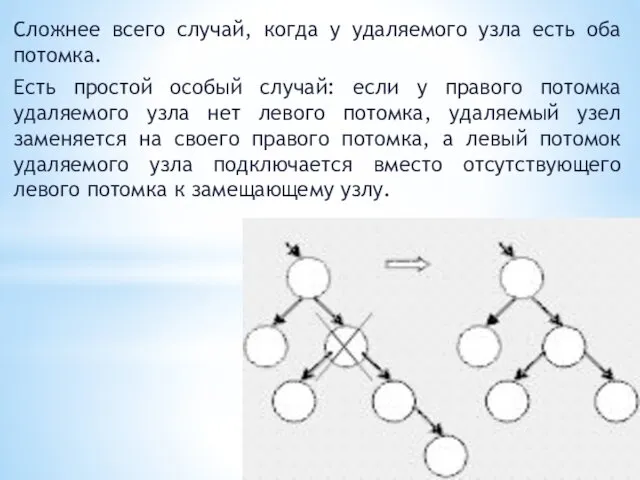
Сложнее всего случай, когда у удаляемого узла есть оба потомка.
Есть
Сложнее всего случай, когда у удаляемого узла есть оба потомка.
Есть
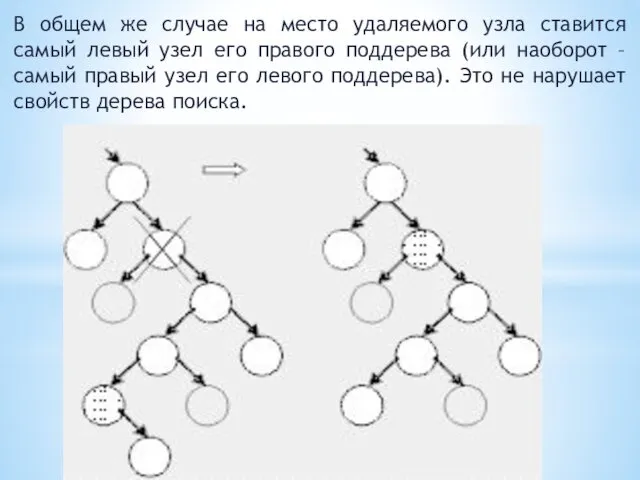
В общем же случае на место удаляемого узла ставится самый левый
В общем же случае на место удаляемого узла ставится самый левый

procedure del(var kor:ptree; z:integer); {Удаляет узел со значением z из дерева
procedure del(var kor:ptree; z:integer); {Удаляет узел со значением z из дерева

function findZamena(p:ptree):ptree;
var
y:ptree; {Указатель на узел, замещающий удаляемый}
predy:ptree;
function findZamena(p:ptree):ptree;
var
y:ptree; {Указатель на узел, замещающий удаляемый}
predy:ptree;

if y^.left=nil then y^.left:=p^.left {Если у правого сына удаляемого узла
if y^.left=nil then y^.left:=p^.left {Если у правого сына удаляемого узла

y^.left:=p^.left; {Подключаем к узлу y, замещающему удаляемый узел p, левого
y^.left:=p^.left; {Подключаем к узлу y, замещающему удаляемый узел p, левого

begin {начало самой процедуры удаления del }
{При вызове процедуры poisk, которая
begin {начало самой процедуры удаления del }
{При вызове процедуры poisk, которая

if p=kor then kor:=y {Если удаляемый элемент является корнем дерева,
if p=kor then kor:=y {Если удаляемый элемент является корнем дерева,

Вся программа:
Разработайте программу работы с бинарным деревом. Программа должна содержать следующие
Вся программа:
Разработайте программу работы с бинарным деревом. Программа должна содержать следующие

Type
ptree=^tree;
tree=record
inf:integer;
left,right:ptree;
end;
Var
p,kor,parent:ptree;
a,
Type
ptree=^tree;
tree=record
inf:integer;
left,right:ptree;
end;
Var
p,kor,parent:ptree;
a,

procedure Sozdanie(var kor:ptree);
begin
new(kor);
kor:=nil;
end;
procedure Dobavl(var kor:ptree; z:integer);
begin
if kor=nil then
procedure Sozdanie(var kor:ptree);
begin
new(kor);
kor:=nil;
end;
procedure Dobavl(var kor:ptree; z:integer);
begin
if kor=nil then

kor:=p;
end
else
begin
if z begin
if kor^.left=nil then
kor:=p;
end
else
begin
if z
if kor^.left=nil then

else
begin
Dobavl(kor^.left, z);
end;
end
else
if kor^.right=nil then
else
begin
Dobavl(kor^.left, z);
end;
end
else
if kor^.right=nil then

else Dobavl(kor^.right, z);
end;
end;
else Dobavl(kor^.right, z);
end;
end;

procedure Vivod(kor:ptree);
begin
if kor^.left<>nil then
Vivod(kor^.left);
Writeln(kor^.inf);
if kor^.right<>nil then
procedure Vivod(kor:ptree);
begin
if kor^.left<>nil then
Vivod(kor^.left);
Writeln(kor^.inf);
if kor^.right<>nil then

if z=p^.inf then
begin
poisk:=true;
exit;
end;
parent:=p;
if z=p^.inf then
begin
poisk:=true;
exit;
end;
parent:=p;

procedure del(var kor:ptree; z:integer);
var
p:ptree; {udaljaemij el}
parent:ptree; {predok p}
y:ptree;
procedure del(var kor:ptree; z:integer);
var
p:ptree; {udaljaemij el}
parent:ptree; {predok p}
y:ptree;

begin
y:=p^.right;
if y^.left=nil then
y^.left:=p^.left
else
begin
repeat
begin
y:=p^.right;
if y^.left=nil then
y^.left:=p^.left
else
begin
repeat

begin
if not poisk(kor, z,p,parent) then
begin
writeln(‘Нет элемента’);
exit;
begin
if not poisk(kor, z,p,parent) then
begin
writeln(‘Нет элемента’);
exit;

Begin
while a<>6 do
begin
Writeln('1. Sozdanie');
Writeln('2. Dobavlenie elementa');
Writeln('3.
Begin
while a<>6 do
begin
Writeln('1. Sozdanie');
Writeln('2. Dobavlenie elementa');
Writeln('3.

2: begin
writeln('Vvedite chislo');
readln(z);
Dobavl(kor, z);
Vivod(kor);
writeln;
end;
2: begin
writeln('Vvedite chislo');
readln(z);
Dobavl(kor, z);
Vivod(kor);
writeln;
end;

4: begin
Write('Vvedite chislo');
Readln(a);
if Poisk(kor,a,p,parent) then Writeln(‘yes!')
else
4: begin
Write('Vvedite chislo');
Readln(a);
if Poisk(kor,a,p,parent) then Writeln(‘yes!')
else
 Логические законы и правила преобразования логических выражений
Логические законы и правила преобразования логических выражений Работа с электронным листком нетрудоспособности (ЭЛН)
Работа с электронным листком нетрудоспособности (ЭЛН) Pseudocode
Pseudocode Автоматизация ресторана в гостинице
Автоматизация ресторана в гостинице Моделирование деловых процессов. Методология функционального моделирования IDEF0
Моделирование деловых процессов. Методология функционального моделирования IDEF0 Фотоаппараты и программы обработки фото
Фотоаппараты и программы обработки фото Профессия прграммист
Профессия прграммист Создание резервной копии БД. Восстановление БД. Запуск скриптов SQL из командной строки. Запись запросов в bat-файл
Создание резервной копии БД. Восстановление БД. Запуск скриптов SQL из командной строки. Запись запросов в bat-файл Система команд Intel. Условные переходы
Система команд Intel. Условные переходы Московский государственный медико-стоматологический университет им. А.И.Евдокимова
Московский государственный медико-стоматологический университет им. А.И.Евдокимова Скилл в онлайн играх
Скилл в онлайн играх Оформление КД. Генерация Gerber-файлов. Вывод чертежей на печать
Оформление КД. Генерация Gerber-файлов. Вывод чертежей на печать Графічний редактор Paint
Графічний редактор Paint Традиционные архитектуры информационных систем. Файл-серверная архитектура
Традиционные архитектуры информационных систем. Файл-серверная архитектура Оператор цикла. Базовые программы обработки одномерного массива. Вложенные циклы
Оператор цикла. Базовые программы обработки одномерного массива. Вложенные циклы Символьный тип
Символьный тип Информационная безопасность
Информационная безопасность Программирование на языке Python. §62. Массивы. 10 класс
Программирование на языке Python. §62. Массивы. 10 класс Green technologies use in computer science and programming
Green technologies use in computer science and programming Разработка мобильных приложений. Введение
Разработка мобильных приложений. Введение Школьная библиотека: Копилочка. Инновационные формы профессионального взаимодействия
Школьная библиотека: Копилочка. Инновационные формы профессионального взаимодействия Библиотека, как технологическая система. (Лекция 2)
Библиотека, как технологическая система. (Лекция 2) ООП 8. Варианты наследования
ООП 8. Варианты наследования Программирование на языке Си (§1-14)
Программирование на языке Си (§1-14) Основы работы с компьютерной графикой
Основы работы с компьютерной графикой Алгоритм
Алгоритм Основы профессиональной карьеры. Поиск и подбор свежих вакансий с популярных сайтов поиска работы
Основы профессиональной карьеры. Поиск и подбор свежих вакансий с популярных сайтов поиска работы Безопасный интернет
Безопасный интернет