- Двоичное кодирование символьной информации

Содержание
- 2. При двоичном кодировании текстовой информации каждому символу ставится в соответствие уникальный десятичный код от 0 до
- 3. По формуле, связывающей количество сообщений N и количество информации i, можно вычислить, какое количество информации необходимо,
- 4. Присвоение символу конкретного двоичного кода – это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33
- 5. Коды с 128 по 255 являются национальными, т. е. в национальных кодировках одному и тому же
- 6. Хронологически одним из первых стандартов кодирования русских букв на компьютерах был код КОИ – 8 («Код
- 7. Наиболее распространенная кодировка – это стандартная кириллистическая кодировка Microsoft Windows, обозначаемая сокращением CP1251 («CP» означает «Code
- 8. Для работы в среде операционной системы MS-DOS используется «альтернативная» кодировка, в терминологии фирмы Microsoft – кодировка
- 9. Фирма Apple разработала для компьютеров Macintosh свою собственную кодировку русских букв (Mac)
- 10. Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще
- 11. КОИ-8 - UNIX CP1251 («CP» означает «Code Page») - Microsoft Windows CP 866 - MS-DOS Mac
- 12. Таблица кодировки символов
- 13. В последнее время появился новый международный стандарт Unicode, который отводит на каждый символ не один байт,
- 14. Задание 1: определите символ по числовому коду. Запустите программу БЛОКНОТ Нажмите ALT и 0224 (на дополнительной
- 15. Задание 2: определите числовой код для символов Определите числовой код, который нужно ввести , удерживая клавишуAlt,
- 17. Скачать презентацию

При двоичном кодировании текстовой информации каждому символу ставится в соответствие уникальный
При двоичном кодировании текстовой информации каждому символу ставится в соответствие уникальный

По формуле, связывающей количество сообщений N и количество информации i, можно
По формуле, связывающей количество сообщений N и количество информации i, можно

Присвоение символу конкретного двоичного кода – это вопрос соглашения, которое фиксируется
Присвоение символу конкретного двоичного кода – это вопрос соглашения, которое фиксируется

Коды с 128 по 255 являются национальными, т. е. в национальных
Коды с 128 по 255 являются национальными, т. е. в национальных

Хронологически одним из первых стандартов кодирования русских букв на компьютерах был
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был

Наиболее распространенная кодировка – это стандартная кириллистическая кодировка Microsoft Windows, обозначаемая
Наиболее распространенная кодировка – это стандартная кириллистическая кодировка Microsoft Windows, обозначаемая

Для работы в среде операционной системы MS-DOS используется «альтернативная» кодировка, в
Для работы в среде операционной системы MS-DOS используется «альтернативная» кодировка, в

Фирма Apple разработала для компьютеров Macintosh свою собственную кодировку русских букв
Фирма Apple разработала для компьютеров Macintosh свою собственную кодировку русских букв

Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве
Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве

КОИ-8 - UNIX
CP1251 («CP» означает «Code Page») - Microsoft Windows
CP 866
КОИ-8 - UNIX
CP1251 («CP» означает «Code Page») - Microsoft Windows
CP 866
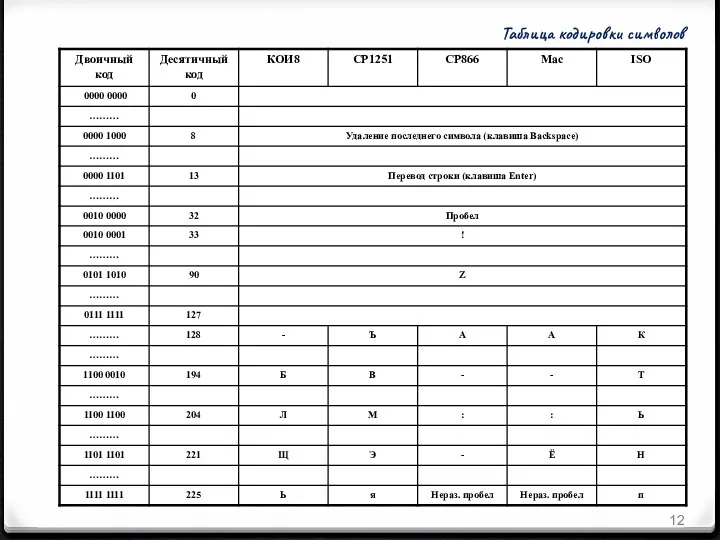
Таблица кодировки символов
Таблица кодировки символов

В последнее время появился новый международный стандарт Unicode, который отводит
В последнее время появился новый международный стандарт Unicode, который отводит

Задание 1: определите символ по числовому коду.
Запустите программу БЛОКНОТ
Нажмите ALT и
Задание 1: определите символ по числовому коду.
Запустите программу БЛОКНОТ
Нажмите ALT и

Задание 2: определите числовой код для символов
Определите числовой код, который нужно
Задание 2: определите числовой код для символов
Определите числовой код, который нужно
 Что представляет собой термин мультимедиа технология?
Что представляет собой термин мультимедиа технология? Основы кибербезопасности
Основы кибербезопасности Безопасность в глобальной паутине
Безопасность в глобальной паутине 1С:Підприємство 8
1С:Підприємство 8 Структура программы
Структура программы Базы данных
Базы данных Word Pad Мәтіндік редакторы
Word Pad Мәтіндік редакторы Компьютерная эстафета
Компьютерная эстафета Текстовые процессоры
Текстовые процессоры СУБД MS Access
СУБД MS Access JavaScript (2)
JavaScript (2) Профессиональные информационные ресурсы. Типы литературы и виды документов. (Тема 2)
Профессиональные информационные ресурсы. Типы литературы и виды документов. (Тема 2) Семантическая оптимизация
Семантическая оптимизация Проектирование информационной системы Планирование организационно-технических мероприятий предприятия
Проектирование информационной системы Планирование организационно-технических мероприятий предприятия Телекоммуникационные системы следующего поколения. Лекция 4
Телекоммуникационные системы следующего поколения. Лекция 4 Управляющий автомат, устройство управления процессором
Управляющий автомат, устройство управления процессором Программирование на языке Python. §54. Алгоритм и его свойства
Программирование на языке Python. §54. Алгоритм и его свойства Билл Гейтс
Билл Гейтс Формирование пользовательского интерфейса
Формирование пользовательского интерфейса Урок-игра Путешествие в страну множеств
Урок-игра Путешествие в страну множеств урок информатики на тему: Устройства ввода-вывода информации. 8 класс
урок информатики на тему: Устройства ввода-вывода информации. 8 класс Іскерлік графика
Іскерлік графика Рейтинг. Лучшая операционная система
Рейтинг. Лучшая операционная система Локальды компьютерлік желілер. Локальды желілердің түрлері
Локальды компьютерлік желілер. Локальды желілердің түрлері League of Legends
League of Legends Отношения объектов. Разновидности объектов и их классификация
Отношения объектов. Разновидности объектов и их классификация Высокоуровневые методы информатики и программирования
Высокоуровневые методы информатики и программирования Photoshop. Лабораторная работа №1
Photoshop. Лабораторная работа №1