- Фундаментальные структуры данных

Содержание
- 2. Понятие Структура данных – это класс однородных математических объектов, ориентированный на эффективное представление данных в некотором
- 3. Классификация Простые Статические Полустатические Динамические Файловые
- 4. Простые структуры данных Числовые Символьные Логические Перечисление Интервал Указатели
- 5. Статические структуры данных Вектор Массивы Множества Записи Таблицы
- 6. Полустатические структуры данных Стеки Очереди Деки Строки
- 7. Динамические структуры данных Связные списки Графы Деревья
- 8. Файловые структуры Последовательные Прямого доступа Комбинированного доступа
- 9. Требования, предъявляемые к структурам данных: Эффективность представления Экономное расходование памяти Быстрый доступ к элементам структуры.
- 10. Массив Массив – структура данных для представления множества элементов, однотипных по структуре и способу использования. Массивы
- 11. Базовые операции поиск элемента, равного x В произвольном массиве T(n) = Θ(n). В отсортированном массиве T(n)
- 12. Базовые операции Обычный прием работы с массивами – это поиск выборочное изменение отдельных компонент массива. Основные
- 13. Линейный список Список – упорядоченная последовательность данных, характеризующих однородные объекты, отличающиеся значениями своих признаков. – конечная
- 14. Базовые операции формирование списка (T(n) = Θ(n)) просмотр списка (T(n) = Θ(n)) поиск некоторого заданного элемента
- 15. Виды списков Однонаправленный список – список, в котором предусмотрен жесткий порядок перебора элементов – от первого
- 16. Способы реализации В виде двух массивов А и В: Пусть i - индекс элемента в списке,
- 17. Способы реализации Список: 8, 13, 5 A: B: nz = 1, ns = 4
- 18. Способы реализации 2. С использованием последовательности связанных компонент (линейный список): Каждая компонента списка состоит из двух
- 19. Способы реализации Список: 8, 13, 5
- 20. Включение элемента в начало (конец) списка до (после) элемента, на который указывает заданная ссылка p
- 21. Включение элемента
- 22. Формирование списка Начиная с пустого списка последовательно включаем элементы в начало списка. не надо обрабатывать отдельно
- 23. Исключение элемента из списка стоящего после элемента, на который указывает заданная ссылка p. на который указывает
- 24. Поиск элемента x в неупорядоченном списке Осуществляется последовательным просмотром элементов заканчивается либо при обнаружении требуемого элемента,
- 25. Поиск элемента x в упорядоченном списке можно заканчивать при обнаружении первого ключа, со значением большем x.
- 26. Операции работы со списками Конкатенация (сцепление) двух списков. В результате образуется единый список. T = Θ(1),
- 27. Стек Стек – линейный однонаправленный список, в котором все включения и исключения элементов (и обычно всякий
- 28. Представление стека Если заранее известно максимальное количество элементов, одновременно хранящихся в стеке, то целесообразно моделировать стек
- 29. Базовые операции Операция добавления элемента в стек часто обозначается Push, а операция удаления – Pop. Трудоемкость
- 30. Очередь Очередь – линейный список, в котором все включения элементов производятся в одном конце списка, а
- 31. Очередь Если максимальное количество элементов, одновременно хранящихся в очереди не превосходит l, то можно смоделировать очередь
- 32. Очередь Если количество элементов очереди заранее не известно, то для реализации очереди используются списковые структуры. Переменная
- 34. Скачать презентацию

Понятие
Структура данных –
это класс однородных математических объектов, ориентированный на эффективное представление
Понятие
Структура данных –
это класс однородных математических объектов, ориентированный на эффективное представление

Классификация
Простые
Статические
Полустатические
Динамические
Файловые
Классификация
Простые
Статические
Полустатические
Динамические
Файловые

Простые структуры данных
Числовые
Символьные
Логические
Перечисление
Интервал
Указатели
Простые структуры данных
Числовые
Символьные
Логические
Перечисление
Интервал
Указатели

Статические структуры данных
Вектор
Массивы
Множества
Записи
Таблицы
Статические структуры данных
Вектор
Массивы
Множества
Записи
Таблицы

Полустатические структуры данных
Стеки
Очереди
Деки
Строки
Полустатические структуры данных
Стеки
Очереди
Деки
Строки

Динамические структуры данных
Связные списки
Графы
Деревья
Динамические структуры данных
Связные списки
Графы
Деревья

Файловые структуры
Последовательные
Прямого доступа
Комбинированного доступа
Файловые структуры
Последовательные
Прямого доступа
Комбинированного доступа

Требования, предъявляемые к структурам данных:
Эффективность представления
Экономное расходование памяти
Быстрый доступ к элементам
Требования, предъявляемые к структурам данных:
Эффективность представления
Экономное расходование памяти
Быстрый доступ к элементам

Массив
Массив – структура данных для представления множества элементов, однотипных по структуре
Массив
Массив – структура данных для представления множества элементов, однотипных по структуре

Базовые операции
поиск элемента, равного x
В произвольном массиве T(n) = Θ(n).
Базовые операции
поиск элемента, равного x
В произвольном массиве T(n) = Θ(n).

Базовые операции
Обычный прием работы с массивами – это
поиск
выборочное изменение отдельных компонент
Базовые операции
Обычный прием работы с массивами – это
поиск
выборочное изменение отдельных компонент

Линейный список
Список
– упорядоченная последовательность данных, характеризующих однородные объекты, отличающиеся
Линейный список
Список
– упорядоченная последовательность данных, характеризующих однородные объекты, отличающиеся

Базовые операции
формирование списка (T(n) = Θ(n))
просмотр списка (T(n) = Θ(n))
поиск некоторого
Базовые операции
формирование списка (T(n) = Θ(n))
просмотр списка (T(n) = Θ(n))
поиск некоторого

Виды списков
Однонаправленный список – список, в котором предусмотрен жесткий порядок перебора
Виды списков
Однонаправленный список – список, в котором предусмотрен жесткий порядок перебора

Способы реализации
В виде двух массивов А и В:
Пусть i -
Способы реализации
В виде двух массивов А и В:
Пусть i -

Способы реализации
Список: 8, 13, 5
A:
B:
nz = 1, ns = 4
Способы реализации
Список: 8, 13, 5
A:
B:
nz = 1, ns = 4

Способы реализации
2. С использованием последовательности связанных компонент (линейный список): Каждая компонента
Способы реализации
2. С использованием последовательности связанных компонент (линейный список): Каждая компонента
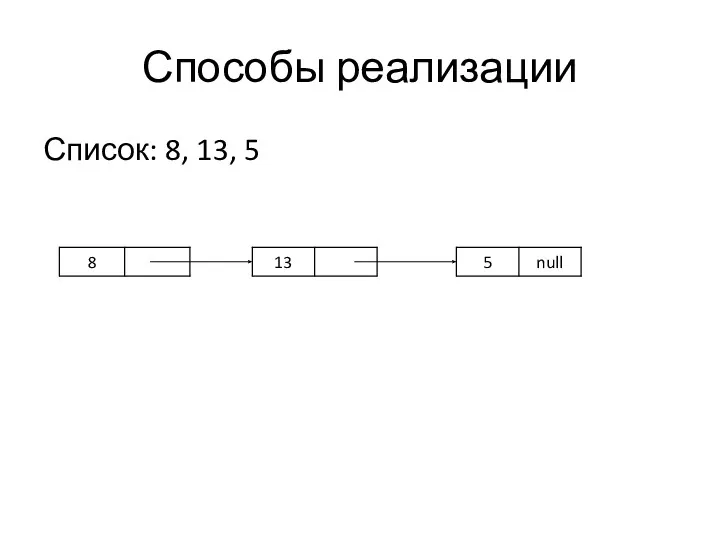
Способы реализации
Список: 8, 13, 5
Способы реализации
Список: 8, 13, 5

Включение элемента
в начало (конец) списка
до (после) элемента, на который указывает
Включение элемента
в начало (конец) списка
до (после) элемента, на который указывает
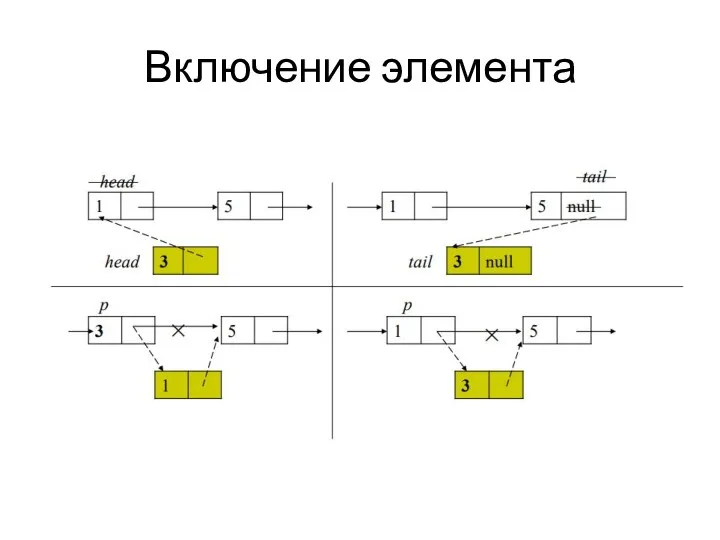
Включение элемента
Включение элемента

Формирование списка
Начиная с пустого списка последовательно включаем элементы в начало списка.
не
Формирование списка
Начиная с пустого списка последовательно включаем элементы в начало списка.
не

Исключение элемента из списка
стоящего после элемента, на который указывает заданная ссылка
Исключение элемента из списка
стоящего после элемента, на который указывает заданная ссылка

Поиск элемента x в неупорядоченном списке
Осуществляется последовательным просмотром элементов
заканчивается либо при
Поиск элемента x в неупорядоченном списке
Осуществляется последовательным просмотром элементов
заканчивается либо при

Поиск элемента x в упорядоченном списке
можно заканчивать при обнаружении первого ключа,
Поиск элемента x в упорядоченном списке
можно заканчивать при обнаружении первого ключа,

Операции работы со списками
Конкатенация (сцепление) двух списков. В результате образуется единый
Операции работы со списками
Конкатенация (сцепление) двух списков. В результате образуется единый

Стек
Стек – линейный однонаправленный список, в котором все включения и исключения
Стек
Стек – линейный однонаправленный список, в котором все включения и исключения

Представление стека
Если заранее известно максимальное количество элементов, одновременно хранящихся в стеке,
Представление стека
Если заранее известно максимальное количество элементов, одновременно хранящихся в стеке,

Базовые операции
Операция добавления элемента в стек часто обозначается Push, а операция
Базовые операции
Операция добавления элемента в стек часто обозначается Push, а операция
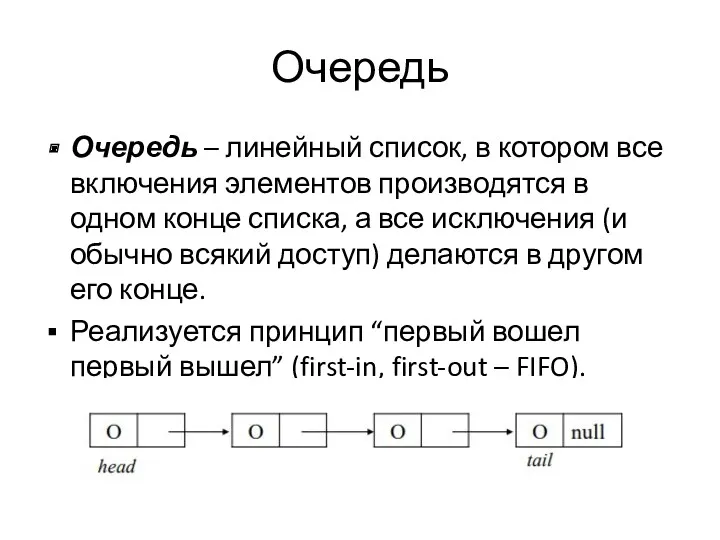
Очередь
Очередь – линейный список, в котором все включения элементов производятся
Очередь
Очередь – линейный список, в котором все включения элементов производятся

Очередь
Если максимальное количество элементов, одновременно хранящихся в очереди не превосходит
Очередь
Если максимальное количество элементов, одновременно хранящихся в очереди не превосходит

Очередь
Если количество элементов очереди заранее не известно, то для реализации очереди
Очередь
Если количество элементов очереди заранее не известно, то для реализации очереди
 Технические элементы игрового движка
Технические элементы игрового движка Условный оператор
Условный оператор Стек
Стек Роскомнадзор. Безопасность несовершеннолетних в сети Интернет
Роскомнадзор. Безопасность несовершеннолетних в сети Интернет Геолокация в HTML5
Геолокация в HTML5 Сайт РазноЧтения: речевая практика
Сайт РазноЧтения: речевая практика Топология локальных сетей
Топология локальных сетей Применение технологии Web 2.0 в библиотеках
Применение технологии Web 2.0 в библиотеках Презентация по теме Создание реляционной базы данных
Презентация по теме Создание реляционной базы данных Бабушки и дедушки online
Бабушки и дедушки online Безопасность детей в интернете. Информационная памятка
Безопасность детей в интернете. Информационная памятка Тема 4. Занятие 3. Функции
Тема 4. Занятие 3. Функции Разработка движка для сайта “Музыкальный портал”
Разработка движка для сайта “Музыкальный портал” Понятие модели и моделирования. Цели и принципы моделирования
Понятие модели и моделирования. Цели и принципы моделирования Автоматизация делопроизводства
Автоматизация делопроизводства Складання та виконання алгоритмів з повтореннями та розгалуженнями для опрацювання величин
Складання та виконання алгоритмів з повтореннями та розгалуженнями для опрацювання величин Типы, переменные, управляющие инструкции. Примитивные типы. (Тема 2.2)
Типы, переменные, управляющие инструкции. Примитивные типы. (Тема 2.2) Оглавление. Создание автоматического оглавления. Microsoft Office Word 2007
Оглавление. Создание автоматического оглавления. Microsoft Office Word 2007 Haskell тіліндегі деректердің күрделі құрылымын өңдеу. Зертханалық жұмыс №6
Haskell тіліндегі деректердің күрделі құрылымын өңдеу. Зертханалық жұмыс №6 Что такое Wi-Fi
Что такое Wi-Fi Метод – это набор операторов, организованный в соответствии с синтаксисом
Метод – это набор операторов, организованный в соответствии с синтаксисом virusy-klassifikatsiya-virusov
virusy-klassifikatsiya-virusov Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16)
Методы разработки параллельных программ для многопроцессорных систем с общей памятью OpenMP. (Лекция 16) Технологический слой
Технологический слой Компьютер - лучший друг человека
Компьютер - лучший друг человека База данных
База данных Условная компиляция
Условная компиляция Принцип построения логической пирамиды при создании деловых документов. (Тема 9)
Принцип построения логической пирамиды при создании деловых документов. (Тема 9)