- Грамматический разбор. Распознаватели. (Лекция 3)

Содержание
- 2. Разбор цепочек. Задача разбора Задача разбора в общем виде: на основе имеющейся грамматики некоторого языка построить
- 3. Выводы в грамматике Определение: вывод цепочки b ∈ (VT)* из S ∈ VN в КС-грамматике G
- 4. Пример. Выводы Для цепочки a+b+a в грамматике G = ({a,b}, {S,T}, {S → T | T+S;
- 5. Дерево вывода для цепочки a+b+a Определение: КС-грамматика G называется неоднозначной, если существует хотя бы одна цепочка
- 6. Пример неоднозначной грамматики G = ({if, then, else, a, b}, {S}, P, S), где P =
- 7. Еще раз вернемся к неоднозначным грамматикам G({+,-,*,/,(,),a,b},{S},P,S): Р: S → S+S | S-S | S*S |
- 8. Построение эквивалентной однозначной грамматики G'({+,-,*./,(,),a,b},{S,Т,E},P',S); Р‘ = {S → S+T | S-T | Т ; Т
- 9. Распознаватели
- 10. Распознаватели. Условная схема распознавателя
- 11. Компоненты распознавателя лента, содержащая исходную цепочку входных символов, и считывающая головки, обозревающей очередной символ в этой
- 12. Работа распознавателя состоит из последовательности тактов В начале каждого такта состояние распознавателя определяется его конфигурацией. В
- 13. Работа распознавателя. Язык, определенный распознавателем В начальной конфигурации: считывающая головка на первом символе входной цепочки, УУ
- 14. Виды распознавателей По видам считывающего устройства двусторонние и односторонние По видам устройства управления детерминированные и недетерминированные
- 15. Классификация распознавателей по типам языков Для языков с фразовой структурой (тип 0) необходим распознаватель, равномощный машине
- 16. Задача разбора Задача разбора в общем виде: на основе имеющейся грамматики некоторого языка построить распознаватель для
- 18. Скачать презентацию

Разбор цепочек. Задача разбора
Задача разбора в общем виде: на основе имеющейся
Разбор цепочек. Задача разбора
Задача разбора в общем виде: на основе имеющейся

Выводы в грамматике
Определение:
вывод цепочки b ∈ (VT)* из S ∈
Выводы в грамматике
Определение: вывод цепочки b ∈ (VT)* из S ∈

Пример. Выводы
Для цепочки a+b+a в грамматике
G = ({a,b}, {S,T}, {S →
Пример. Выводы
Для цепочки a+b+a в грамматике G = ({a,b}, {S,T}, {S →
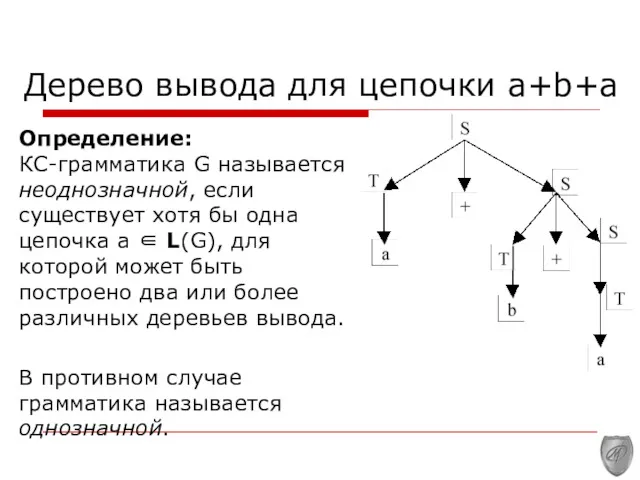
Дерево вывода для цепочки a+b+a
Определение:
КС-грамматика G называется неоднозначной, если существует
Дерево вывода для цепочки a+b+a
Определение: КС-грамматика G называется неоднозначной, если существует

Пример неоднозначной грамматики
G = ({if, then, else, a, b}, {S}, P,
Пример неоднозначной грамматики
G = ({if, then, else, a, b}, {S}, P,
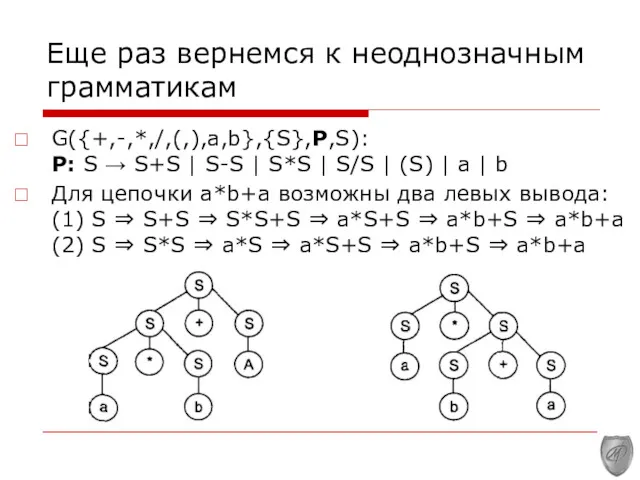
Еще раз вернемся к неоднозначным грамматикам
G({+,-,*,/,(,),a,b},{S},P,S):
Р: S → S+S | S-S
Еще раз вернемся к неоднозначным грамматикам
G({+,-,*,/,(,),a,b},{S},P,S): Р: S → S+S | S-S
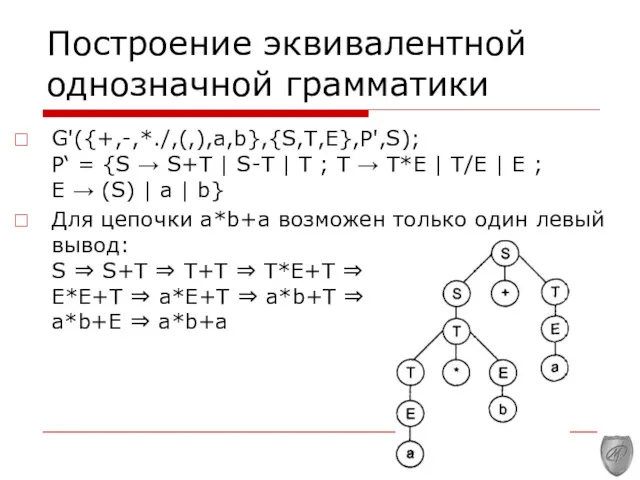
Построение эквивалентной однозначной грамматики
G'({+,-,*./,(,),a,b},{S,Т,E},P',S);
Р‘ = {S → S+T | S-T |
Построение эквивалентной однозначной грамматики
G'({+,-,*./,(,),a,b},{S,Т,E},P',S); Р‘ = {S → S+T | S-T |

Распознаватели
Распознаватели
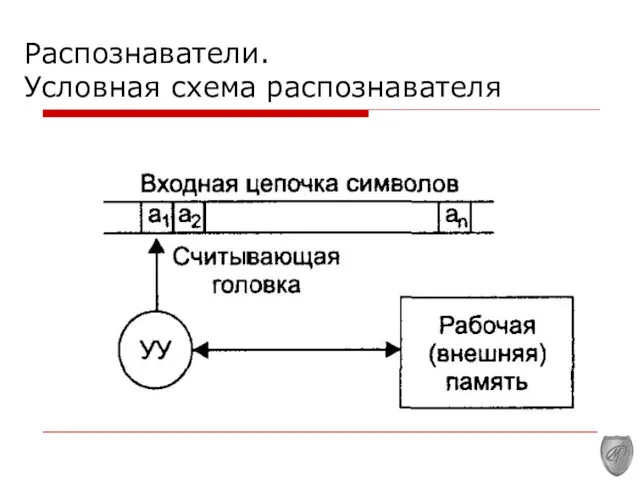
Распознаватели.
Условная схема распознавателя
Распознаватели.
Условная схема распознавателя

Компоненты
распознавателя
лента, содержащая исходную цепочку входных символов, и считывающая головки, обозревающей
Компоненты
распознавателя
лента, содержащая исходную цепочку входных символов, и считывающая головки, обозревающей

Работа распознавателя состоит из последовательности тактов
В начале каждого такта состояние распознавателя
Работа распознавателя состоит из последовательности тактов
В начале каждого такта состояние распознавателя

Работа распознавателя.
Язык, определенный распознавателем
В начальной конфигурации:
считывающая головка на первом символе входной
Работа распознавателя.
Язык, определенный распознавателем
В начальной конфигурации:
считывающая головка на первом символе входной

Виды распознавателей
По видам считывающего устройства
двусторонние и односторонние
По видам устройства управления
детерминированные
Виды распознавателей
По видам считывающего устройства
двусторонние и односторонние
По видам устройства управления
детерминированные

Классификация распознавателей по типам языков
Для языков с фразовой структурой (тип 0)
Классификация распознавателей по типам языков
Для языков с фразовой структурой (тип 0)

Задача разбора
Задача разбора в общем виде:
на основе имеющейся грамматики
Задача разбора
Задача разбора в общем виде:
на основе имеющейся грамматики
 Методы генетического программирования. Модификации генетических алгоритмов
Методы генетического программирования. Модификации генетических алгоритмов Системы счисления
Системы счисления Информационные технологии в научной деятельности
Информационные технологии в научной деятельности Компьютерная графика. Лабораторная работа
Компьютерная графика. Лабораторная работа Разработка информационной системы для сотрудников компании ВТИ-сервис
Разработка информационной системы для сотрудников компании ВТИ-сервис Электронная почта. Адресация в системе электронной почты
Электронная почта. Адресация в системе электронной почты Презентация Создание анимации
Презентация Создание анимации Автоматизированное проектирование ИС
Автоматизированное проектирование ИС Оформление списка литературы. Библиографические БД
Оформление списка литературы. Библиографические БД Передача информации между компьютерами. Проводная и беспроводная связь
Передача информации между компьютерами. Проводная и беспроводная связь Содержание школьного образования в области информатики
Содержание школьного образования в области информатики Виды базы данных
Виды базы данных Моделирование. Модели и моделирование
Моделирование. Модели и моделирование Взаимодействие с сервером Oracle
Взаимодействие с сервером Oracle Принципы подходов к моделированию систем
Принципы подходов к моделированию систем Компьютерные вирусы и защита от них
Компьютерные вирусы и защита от них Двоичная система счисления. Перевод из двоичной с.с в десятичную
Двоичная система счисления. Перевод из двоичной с.с в десятичную Линейное программирование
Линейное программирование Технологии проектирования компьютерных систем. Представление системы в VHDL. (Лекция 7)
Технологии проектирования компьютерных систем. Представление системы в VHDL. (Лекция 7) История развития вычислительной техники
История развития вычислительной техники Создание музыкального бота с голосовыми командами для приложения Discord на языке программирования Python
Создание музыкального бота с голосовыми командами для приложения Discord на языке программирования Python Компьютер или книга - что лучше
Компьютер или книга - что лучше Информационно-коммуникационные технологии
Информационно-коммуникационные технологии Табличный способ решения логических задач
Табличный способ решения логических задач Основы разработки серверной части Web-приложения
Основы разработки серверной части Web-приложения Программирование циклов на языке Паскаль
Программирование циклов на языке Паскаль Топологии компьютерных сетей
Топологии компьютерных сетей Урок по теме Редактор формул в Word
Урок по теме Редактор формул в Word