- History of Cologne Digital Lexicons

Содержание
- 3. Digital Lexicons Digital Lexicons 1988-1994 1994-2005 pre-2014 2014-2019
- 4. Austin 1988 “Many Sanskritists are highly computer literate” “Bright hopes” by D. Wujastyk Undoing sandhi, conjunct
- 5. Post-Austin 1988 (Kharagpur 2019) Undoing sandhi solved, opensource 1992-2000, Peter Scharf (Pascal) 2009 Jim Funderburk (Perl,
- 6. Post-Austin 1988 (Kharagpur 2019) Sanskrit text archive (GRETIL), 2001 "simply rapid access library“ no “grammatical and
- 7. Post-Austin 1988 (Kharagpur 2019) Full contextual reference (Panini) GRA links to RV, not yet Panini 2018
- 8. Cologne 1997 Edition Coding yet to be done supplement transliteration of Greek botanical terms verbal forms
- 9. MW 2019: Supplement MW supplement (additions and corrections) fully integrated AFAIK 2018? Jim Funderburk https://www.sanskrit-lexicon.uni-koeln.de/talkMay2008/markingMonier.html
- 10. MW 2019: Translitate Greek transliteration of Greek (16 out of 34 dictionaries) 2007, 2010 Beta Code
- 11. MW 2017: Botanical Terms to recognise and to renew plant names, Linnaean taxonomy changed over time
- 12. MW 2017: Botanical Terms Mis-markup (surnames coded as plants) Roxb., Hex., Gaertn., Nees., Schott., Bl., Wall.,
- 13. MW 2017: Verbal Forms Compare verbal forms databases Gérard Huet (gitlab INRIA) Amba Kulkarni (Uni of
- 14. MW 2019: Literary Sources Interlinking with Pāṇini was meant initially Cologne interlinking only for GRA to
- 15. Cologne 2019: Useful Byproducts List of all Sanskrit headwords from dictionaries sanhw1.txt & sanhw2.txt dīpita:dīpita:AP,AP90,MW,MW72,SHS,STC,WIL,YAT dīpitar:dīpitar:PW,PWG
- 16. MW 2017: Misc User Interface Replica of Printed Fonts for Web Display https://github.com/sanskrit-lexicon/MWS/issues/51
- 17. PW 2017: Code Reorganization Sample meta-line format; addition of div markup (breaking huge blobs of text
- 18. Simple Search
- 19. Cologne 2020: Simple Search How `simple` at Cologne works (#3) Searching for khan: kāma kaṇa khan
- 20. Sanskrit Dataset Crowdsourcing Carthago delenda est When we say DCS is the source, we are not
- 21. Sanskrit Dataset Crowdsourcing Carthago delenda est At the level of Cologne I’ve seen what 2.5 people
- 23. Скачать презентацию


Digital Lexicons
Digital Lexicons
1988-1994
1994-2005
pre-2014
2014-2019
Digital Lexicons
Digital Lexicons
1988-1994
1994-2005
pre-2014
2014-2019

Austin 1988
“Many Sanskritists are
highly computer literate”
“Bright hopes” by D. Wujastyk
Undoing
Austin 1988
“Many Sanskritists are
highly computer literate”
“Bright hopes” by D. Wujastyk
Undoing

Post-Austin 1988 (Kharagpur 2019)
Undoing sandhi solved, opensource
1992-2000, Peter Scharf (Pascal)
2009 Jim
Post-Austin 1988 (Kharagpur 2019)
Undoing sandhi solved, opensource
1992-2000, Peter Scharf (Pascal)
2009 Jim

Post-Austin 1988 (Kharagpur 2019)
Sanskrit text archive (GRETIL), 2001
"simply rapid access library“
Post-Austin 1988 (Kharagpur 2019)
Sanskrit text archive (GRETIL), 2001
"simply rapid access library“

Post-Austin 1988 (Kharagpur 2019)
Full contextual reference (Panini)
GRA links to RV,
Post-Austin 1988 (Kharagpur 2019)
Full contextual reference (Panini)
GRA links to RV,

Cologne 1997 Edition
Coding yet to be done
supplement
transliteration of
Cologne 1997 Edition
Coding yet to be done
supplement
transliteration of

MW 2019: Supplement
MW supplement
(additions and corrections)
fully integrated AFAIK
2018? Jim
MW 2019: Supplement
MW supplement
(additions and corrections)
fully integrated AFAIK
2018? Jim

MW 2019: Translitate Greek
transliteration of Greek
(16 out of 34 dictionaries)
2007,
MW 2019: Translitate Greek
transliteration of Greek
(16 out of 34 dictionaries)
2007,

MW 2017: Botanical Terms
to recognise and to renew plant names, Linnaean
MW 2017: Botanical Terms
to recognise and to renew plant names, Linnaean

MW 2017: Botanical Terms
Mis-markup (surnames coded as plants)
Roxb., Hex., Gaertn., Nees.,
MW 2017: Botanical Terms
Mis-markup (surnames coded as plants)
Roxb., Hex., Gaertn., Nees.,

MW 2017: Verbal Forms
Compare verbal forms databases
Gérard Huet (gitlab INRIA)
Amba Kulkarni
MW 2017: Verbal Forms
Compare verbal forms databases
Gérard Huet (gitlab INRIA)
Amba Kulkarni

MW 2019: Literary Sources
Interlinking with Pāṇini was meant initially
Cologne interlinking only
MW 2019: Literary Sources
Interlinking with Pāṇini was meant initially
Cologne interlinking only

Cologne 2019: Useful Byproducts
List of all Sanskrit headwords from dictionaries sanhw1.txt
Cologne 2019: Useful Byproducts
List of all Sanskrit headwords from dictionaries sanhw1.txt

MW 2017: Misc User Interface
Replica of Printed Fonts for Web Display
https://github.com/sanskrit-lexicon/MWS/issues/51
MW 2017: Misc User Interface
Replica of Printed Fonts for Web Display
https://github.com/sanskrit-lexicon/MWS/issues/51

PW 2017: Code Reorganization Sample
meta-line format;
addition of div markup (breaking huge
PW 2017: Code Reorganization Sample
meta-line format;
addition of div markup (breaking huge

Simple Search
Simple Search

Cologne 2020: Simple Search
How `simple` at Cologne works (#3)
Searching for khan:
Cologne 2020: Simple Search
How `simple` at Cologne works (#3)
Searching for khan:

Sanskrit Dataset Crowdsourcing
Carthago delenda est
When we say DCS is the source,
Sanskrit Dataset Crowdsourcing
Carthago delenda est
When we say DCS is the source,

Sanskrit Dataset Crowdsourcing
Carthago delenda est
At the level of Cologne I’ve seen
Sanskrit Dataset Crowdsourcing
Carthago delenda est
At the level of Cologne I’ve seen
 Стандартизация в области информационных технологий
Стандартизация в области информационных технологий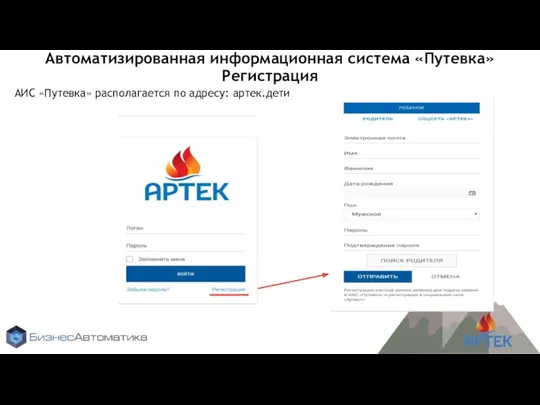 Автоматизированная информационная система Путевка. Регистрация
Автоматизированная информационная система Путевка. Регистрация Создание виртуальной машины VirtualBox
Создание виртуальной машины VirtualBox Ввод информации в память компьютера
Ввод информации в память компьютера Классификация ЭВМ
Классификация ЭВМ Алгоритмы с возвращением, их реализация с помощью рекурсий и динамических структур
Алгоритмы с возвращением, их реализация с помощью рекурсий и динамических структур Оператор перехода Goto. Цикл метки. Язык программирования Pascal
Оператор перехода Goto. Цикл метки. Язык программирования Pascal Исполнитель робот
Исполнитель робот Cmpe 466 computer graphics. A survey of graphics applications. (Chapter 1)
Cmpe 466 computer graphics. A survey of graphics applications. (Chapter 1) Пользовательский интерфейс и его разновидности
Пользовательский интерфейс и его разновидности Массивы. Операции с массивами
Массивы. Операции с массивами Information technologies in the professional sphere. Industrial ICT
Information technologies in the professional sphere. Industrial ICT Защита информации. Основные термины и определения
Защита информации. Основные термины и определения LDI Plus Presentation EN
LDI Plus Presentation EN Комп’ютерні мережі
Комп’ютерні мережі Операции и выражения. (Лекция 4)
Операции и выражения. (Лекция 4) Упрощенный прием РПО
Упрощенный прием РПО Бесплатные антивирусные программы
Бесплатные антивирусные программы Basic Switch. Setup
Basic Switch. Setup Формирование УУД при изучении графических и текстовых редакторов на уроках информатики и ИКТ
Формирование УУД при изучении графических и текстовых редакторов на уроках информатики и ИКТ Стандартны оформления программного кода
Стандартны оформления программного кода Совершенствование организации проектирования уникальных зданий на основе строительно-информационного моделирования
Совершенствование организации проектирования уникальных зданий на основе строительно-информационного моделирования Соглашение об уровне сервиса, или что такое SLA (Service Level Agreement)
Соглашение об уровне сервиса, или что такое SLA (Service Level Agreement) Информационные системы и технологии. Система высокого уровня CATIA V5 (продолжение). Лекция 9
Информационные системы и технологии. Система высокого уровня CATIA V5 (продолжение). Лекция 9 Электронный учебник по информатике
Электронный учебник по информатике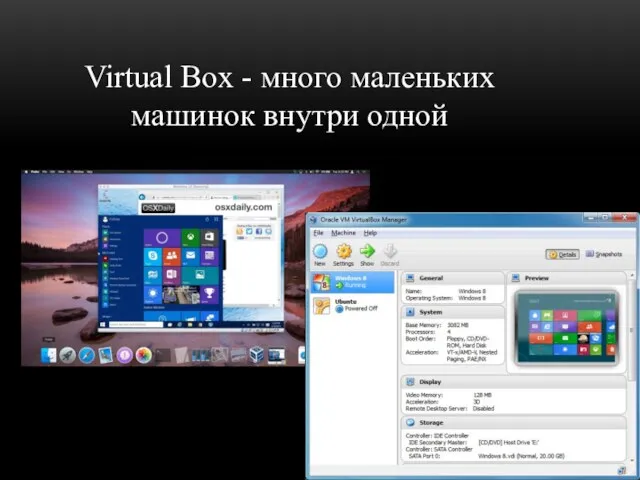 Virtual Box - много маленьких машинок внутри одной
Virtual Box - много маленьких машинок внутри одной Автоматизированное проектирование ИС. (Лекция 5)
Автоматизированное проектирование ИС. (Лекция 5) MS DOS операциялық жүйе
MS DOS операциялық жүйе