- История развития СУБД. (Лекция 2)

Содержание
- 2. Области использования ВТ Численные расчеты Характерной особенностью данной области применения вычислительной техники является 1. наличие сложных
- 3. 2-ая область применения Автоматизированные информационные системы Особенности : Большие объемы информации, Сложную структура данных
- 4. История развития СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная
- 5. Три основных этапа развития Начальный этап был связан с созданием первого поколения СУБД, опиравшихся на иерархическую
- 6. Начальный этап К сожалению, СУБД первого поколения были в подавляющем большинстве закрытыми системами: отсутствовал стандарт внешних
- 7. Создание реляционной модели данных Простота и гибкость модели привлекли к ней внимание разработчиков и снискали ей
- 8. Эпоха персональных компьютеров Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. Большинство
- 9. Распределенные базы данных Практически все современные СУБД обеспечивают поддержку полной реляционной модели, а именно: структурной целостности
- 10. Системы, основанные на инвертированных списках, иерархические и сетевые СУБД. Сильные места и недостатки ранних систем
- 11. Общие характеристики Эти системы активно использовались в течение многих лет, дольше, чемиспользуется какая-либо из реляционных СУБД.
- 12. Основные особенности систем, основанных на инвертированных списках
- 13. Структуры данных Строки таблиц упорядочены системой в некоторой физической последовательности. Физическая упорядоченность строк всех таблиц может
- 14. Манипулирование данными Операторы, устанавливающие адрес записи, среди которых: прямые поисковые операторы (например, найти первую запись таблицы
- 15. Типичный набор операторов: LOCATE FIRST - найти первую запись таблицы T в физическом порядке; возвращает адрес
- 16. Ограничения целостности Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых
- 17. Иерархические модели данных
- 18. Иерархические структуры данных Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких
- 19. Один экземпляр дерева
- 20. Манипулирование данными Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие: Найти указанное дерево БД
- 21. Ограничения целостности Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может
- 22. Сетевые модели данных
- 23. Структуры данных
- 24. Тип связи Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит
- 25. Пример сетевой схемы БД:
- 26. Манипулирование данными Найти конкретную запись в наборе однотипных записей (инженера Сидорова); Перейти от предка к первому
- 28. Скачать презентацию

Области использования ВТ
Численные расчеты
Характерной особенностью данной области применения вычислительной техники является
1.
Области использования ВТ
Численные расчеты
Характерной особенностью данной области применения вычислительной техники является
1.

2-ая область применения
Автоматизированные информационные системы
Особенности :
Большие объемы информации,
Сложную структура данных
2-ая область применения
Автоматизированные информационные системы
Особенности :
Большие объемы информации,
Сложную структура данных

История развития СУБД насчитывает более 30 лет.
В 1968 году была
История развития СУБД насчитывает более 30 лет.
В 1968 году была

Три основных этапа развития
Начальный этап был связан с созданием первого поколения
Три основных этапа развития
Начальный этап был связан с созданием первого поколения

Начальный этап
К сожалению, СУБД первого поколения были в подавляющем большинстве закрытыми
Начальный этап
К сожалению, СУБД первого поколения были в подавляющем большинстве закрытыми

Создание реляционной модели данных
Простота и гибкость модели привлекли к ней
Создание реляционной модели данных
Простота и гибкость модели привлекли к ней

Эпоха персональных компьютеров
Все СУБД были рассчитаны на создание БД в основном
Эпоха персональных компьютеров
Все СУБД были рассчитаны на создание БД в основном

Распределенные базы данных
Практически все современные СУБД обеспечивают поддержку полной реляционной модели,
Распределенные базы данных
Практически все современные СУБД обеспечивают поддержку полной реляционной модели,

Системы, основанные на инвертированных списках, иерархические и сетевые СУБД.
Сильные места
Системы, основанные на инвертированных списках, иерархические и сетевые СУБД.
Сильные места

Общие характеристики
Эти системы активно использовались в течение многих лет, дольше,
Общие характеристики
Эти системы активно использовались в течение многих лет, дольше,

Основные особенности систем, основанных на инвертированных списках
Основные особенности систем, основанных на инвертированных списках

Структуры данных
Строки таблиц упорядочены системой в некоторой физической последовательности.
Физическая упорядоченность
Структуры данных
Строки таблиц упорядочены системой в некоторой физической последовательности.
Физическая упорядоченность

Манипулирование данными
Операторы, устанавливающие адрес записи, среди которых:
прямые поисковые операторы (например,
Манипулирование данными
Операторы, устанавливающие адрес записи, среди которых:
прямые поисковые операторы (например,

Типичный набор операторов:
LOCATE FIRST - найти первую запись таблицы T
Типичный набор операторов:
LOCATE FIRST - найти первую запись таблицы T

Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются

Иерархические модели данных
Иерархические модели данных
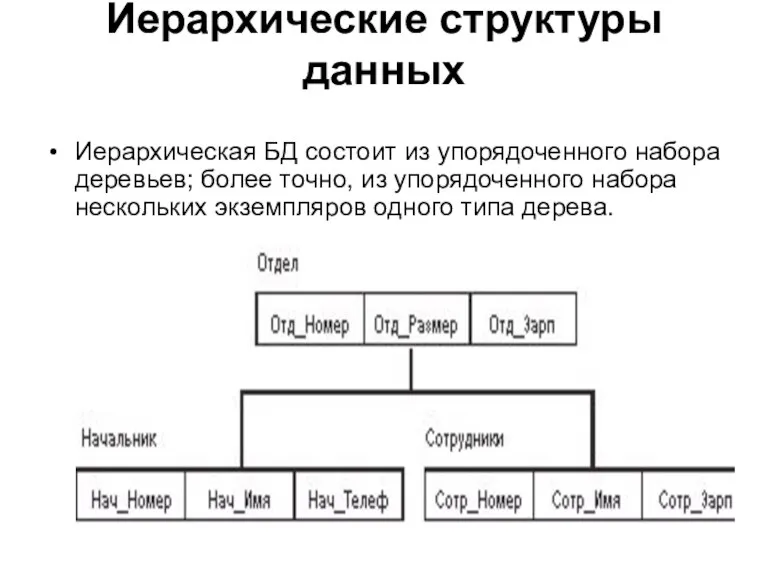
Иерархические структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно,
Иерархические структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно,
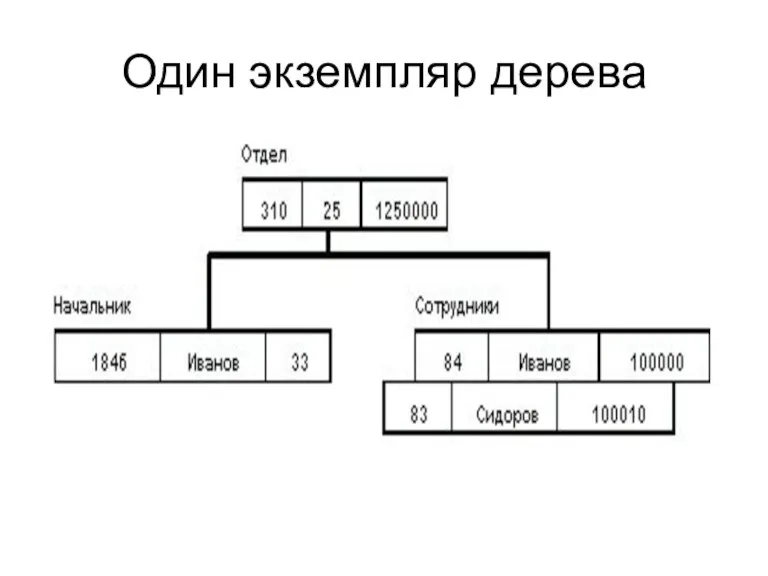
Один экземпляр дерева
Один экземпляр дерева

Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:

Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками.
Основное правило:
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками.
Основное правило:

Сетевые модели данных
Сетевые модели данных
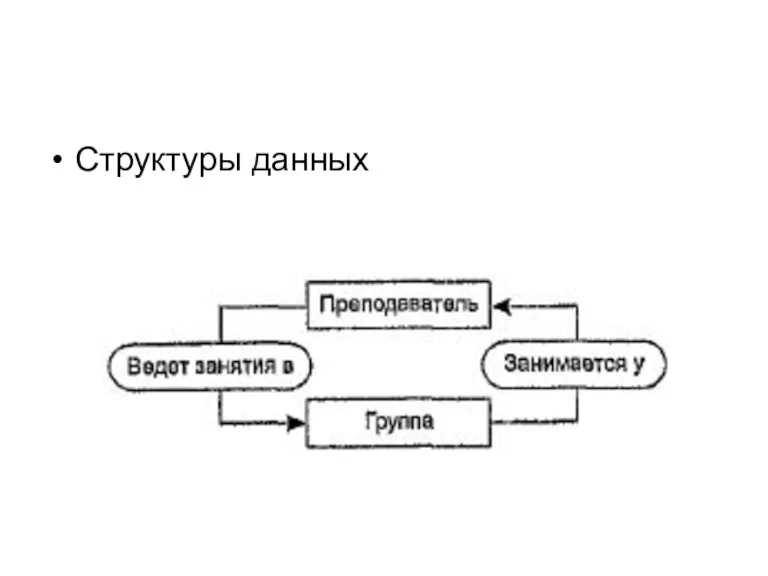
Структуры данных
Структуры данных

Тип связи
Тип связи определяется для двух типов записи: предка и потомка.
Тип связи
Тип связи определяется для двух типов записи: предка и потомка.
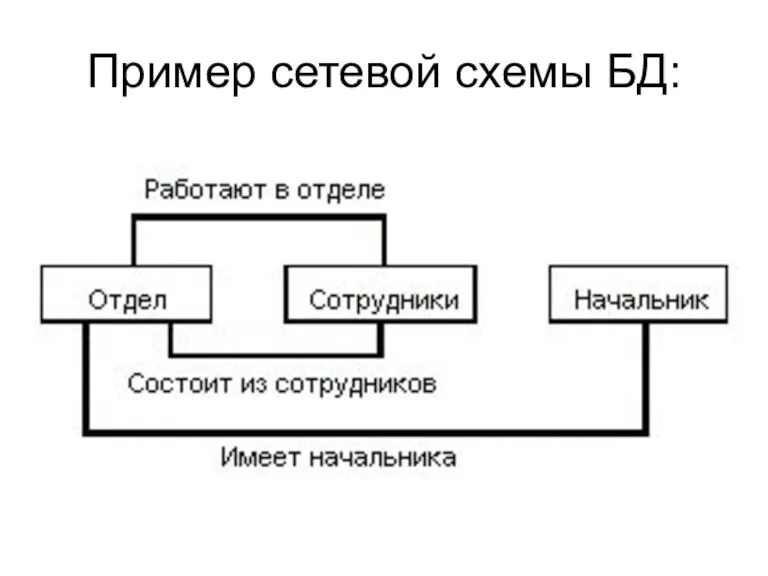
Пример сетевой схемы БД:
Пример сетевой схемы БД:

Манипулирование данными
Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
Перейти
Манипулирование данными
Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
Перейти
 Нейросеть: враг или друг?
Нейросеть: враг или друг? Сложные структуры данных. Связные списки
Сложные структуры данных. Связные списки GDAL (Geospatial Data Abstraction Library). Библиотека GDAL
GDAL (Geospatial Data Abstraction Library). Библиотека GDAL Высокопроизводительные вычисления
Высокопроизводительные вычисления Алгоритмы
Алгоритмы Электронная проходная. Электронная столовая
Электронная проходная. Электронная столовая Технологии разработки программного обеспечения. Лекция 1. Введение. SDLC
Технологии разработки программного обеспечения. Лекция 1. Введение. SDLC Игры со стратегией
Игры со стратегией Пиктограмма
Пиктограмма Финансовая отчетность для владельца бизнеса. 1С:Управление небольшой фирмой 8
Финансовая отчетность для владельца бизнеса. 1С:Управление небольшой фирмой 8 Создаем мощный канал продаж из Periscope
Создаем мощный канал продаж из Periscope Интернет желісіне жалпы сипаттама
Интернет желісіне жалпы сипаттама Информационная культура студента
Информационная культура студента Разработка в HighLoad. Нужен ли эксперт?
Разработка в HighLoad. Нужен ли эксперт? ЗАДАНИЯ для интер доски к уроку ОБЪЕКТ
ЗАДАНИЯ для интер доски к уроку ОБЪЕКТ Мистерия Игры Богов – IV. Квадрант Мутации
Мистерия Игры Богов – IV. Квадрант Мутации Архитектура ORACLE. Внешняя память (Лекция 3)
Архитектура ORACLE. Внешняя память (Лекция 3) IMS. Подсистема IP мультимедиа
IMS. Подсистема IP мультимедиа Желілік технологиялар
Желілік технологиялар Использование различных сервисов для визуализации учебного материала
Использование различных сервисов для визуализации учебного материала Применение технологий интернета вещей в сфере образования. Информационная безопасность интернета вещей
Применение технологий интернета вещей в сфере образования. Информационная безопасность интернета вещей Методы обеспечения качества обслуживания. Механизмы применения QoS. Методы инжиниринга трафика
Методы обеспечения качества обслуживания. Механизмы применения QoS. Методы инжиниринга трафика Интернет зияны Анти-интернет тобы
Интернет зияны Анти-интернет тобы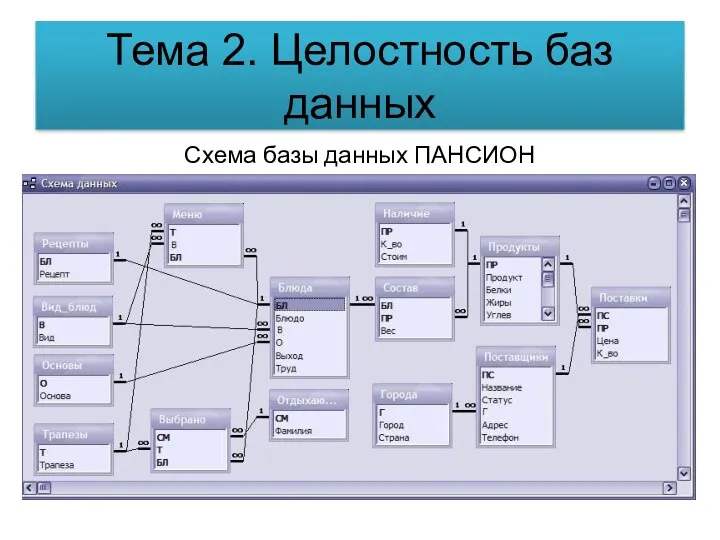 Целостность баз данных. Схема базы данных Пансион
Целостность баз данных. Схема базы данных Пансион Programming ASP
Programming ASP Издательство Росмэн
Издательство Росмэн Анализ технологий поиска уязвимостей современными сканерами безопасности
Анализ технологий поиска уязвимостей современными сканерами безопасности Теоретические основы информатики. Информация
Теоретические основы информатики. Информация