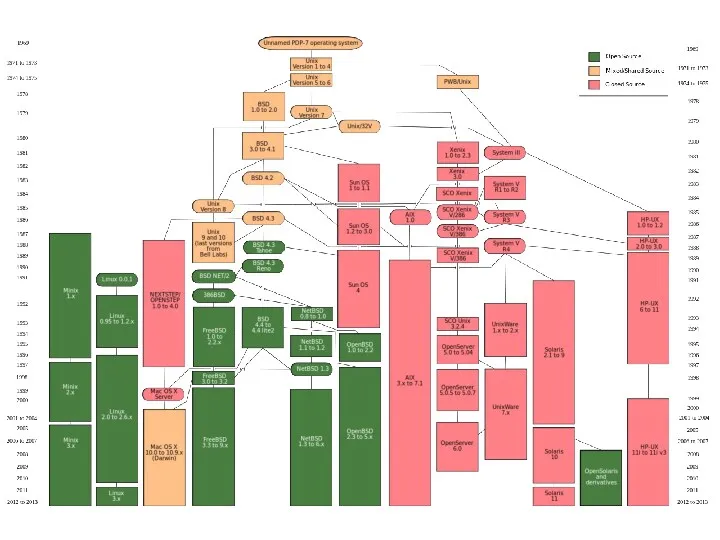
- История создания UNIX

Содержание
- 2. Дуг Макилрой, изобретатель каналов UNIX и один из основателей традиции UNIX, обобщил философию следующим образом: «Философия
- 4. Общая характеристика системы UNIX Общие черты Unix независимо от версии: 1. Многопользовательский режим со средствами защиты
- 5. Интерфейс системы UNIX Пользователи Стандартные обслуживающие программы ( оболочка, компиляторы, утилиты для работы с файлами и
- 6. Структура ядра системы Unix Системные вызовы Аппаратные и эмулированные прерывания Управление терминалом Сокеты Именование файла Отображение
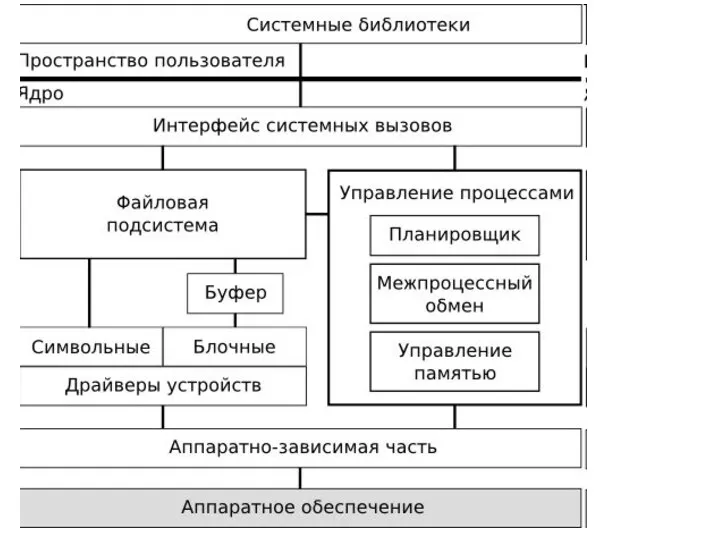
- 7. Ядро операционной системы Ядро ОС – низкоуровневая программа компьютера. Для большинства устройств, ядро – единственная программа,
- 9. Оболочка системы UNIX Система поддерживает графическое окружение X Windows, но многие программисты предпочитают интерфейс командной строки,
- 10. Утилиты системы Unix Кроме оболочки пользовательский интерфейс содержит большое число обслуживающих программ (утилит): Программы (команды) управления
- 11. Процессы в ОС UNIX Процесс в ОС создается при запуске приложения со стороны пользователя или самой
- 12. Атрибуты процесса Каждый процесс характеризуется набором атрибутов. К их числу относятся: PID – идентификатор процесса PPID
- 13. Атрибуты процесса Таблица, содержащая список процессов имеет примерно следующий вид: USER PID %CPU %MEM VSZ RSS
- 14. pid = fork ( ); /* если fork завершился успешно, pid > 0 в родит. процессе
- 15. Механизм создания нового процесса : для процесса-потомка создается новая ячейка в таблице процессов, которая заполняется по
- 16. Процессы взаимодействуют с помощью каналов. Синхронизация процессов достигается путем блокировки процесса при попытке прочитать данные из
- 18. Каждый запущенный процесс в любой момент времени находится в одном из следующих состояний (которое называют еще
- 19. Реализация процессов в системе Unix Ядро поддерживает две ключевые структуры данных, относящиеся к процессам: таблицу процессов
- 20. Планирование в системе UNIX Низкоуровневый алгоритм выбирает процесс, готовый к работе из очереди, имеющей высший приоритет
- 22. Команды управления процессами Существует ряд команд, позволяющих просматривать и управлять процессами в системе: ps – выводит
- 23. Средства администрирования Для управления операционной системой в UNIX часто используются конфигурационные файлы. Такие файлы определяют параметры
- 24. Учетные записи пользователей Для упорядочивания работы с пользователями, хранения информации о их персональных настройках используются учетные
- 25. Хранение информации об учетных записях Информация об учетных записях хранится в нескольких структурах данных: /etc/passwd –
- 26. Монтирование файловой системы Доступ к разделу на носителе информации обеспечивается монтированием раздела в общую файловую систему.
- 27. Файловая система 1 Файловая система 2 Общая файловая система после монтирования Обычный файл Каталог Специальный файл-устройство
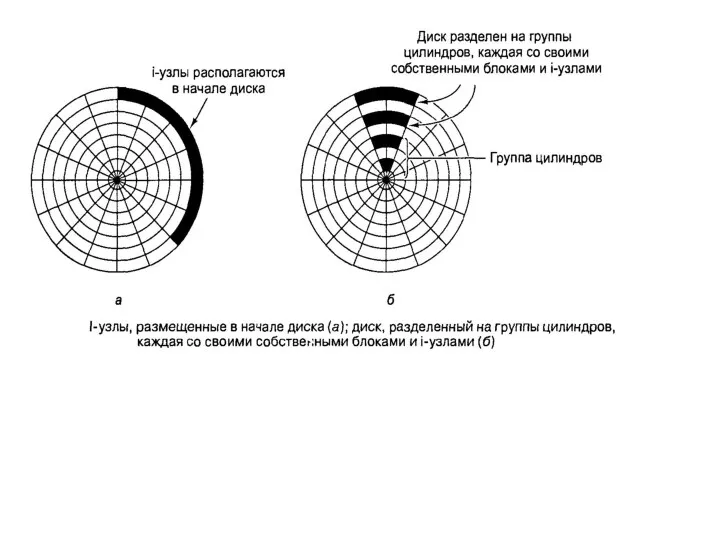
- 28. Физическая организация S5 и ufs Расположение файловой системы s5 на диске
- 29. Все дисковое пространство, отведенное под файловую систему, делится на четыре области: загрузочный блок (boot), в котором
- 31. Структура индексного дескриптора (i-node) идентификатор владельца и группы владельца файла; тип файла: - (дефис) — обычный
- 33. Копирование индексного дескриптора входит в процедуру открытия файла. При открытии файла ядро выполняет следующие действия: Проверяет,
- 34. Стандарт POSIX (Portable Operating System Interface) требует реализовать поддержку двух типов связей - жестких и символических.
- 35. Имя файла является указателем на индексный дескриптор (i-node), который содержит атрибуты файла и массив адресов дисковых
- 36. Удаление файла представляет собой уменьшение на 1 счетчика его имен в индексном дескрипторе. Физически файл удаляется
- 37. Символическая ссылка имеет ряд преимуществ по сравнению с жёсткой ссылкой: она может использоваться для связи файлов
- 38. Структура каталога Для каталога число связей - число его подкаталогов. Текущий каталог обозначается точкой (.); родительский
- 39. Права доступа к файлу Для управления доступом к файлу используются специальные атрибуты, определяющие права доступа –
- 40. В UNIX существует три основных права доступа: чтение, запись и исполнение. Право исполнения трактуется по-разному для
- 41. Sticky bit Помимо комбинации из этих девяти прав доступа, каждый файл может иметь дополнительные флаги доступа:
- 42. Suid-бит Программа с установленным битом suid является «потенциально опасной». Если установлены права доступа SUID и файл
- 43. Поиск файла /bin/ my_shell/print
- 44. 1. просматривается корневой каталог с целью поиска первого составляющего символьного имени – это bin. Определяется номер
- 45. Атрибуты файлов Аналогично файловой системе FAT, имеющей атрибуты файлов (архивный, системный файл, скрытый), в файловой системе
- 46. d («no dump»): dump - это стандартная утилита UNIX для резервного копирования. Она делает дамп любой
- 47. Физическая организация файловой системы ufs Таблицы inodes содержатся в блоке группы цилиндров, наряду с картами свободных/занятых
- 49. С каждым процессом UNIX связаны два идентификатора: пользователя, от имени которого был создан этот процесс, и
- 50. Проверка прав доступа в UNIX
- 51. Смена эффективных идентификаторов процесса
- 52. Система ввода-вывода Основу системы ввода-вывода ОС UNIX составляют драйверы внешних устройств и средства буферизации данных. ОС
- 55. Специальные файлы как универсальный интерфейс Специальный файл (СФ), называемый также виртуальным файлом, связан с некоторым устройством
- 57. Для этого используются системные вызовы для работы с обычными файлами: open, create, read, write и close.
- 58. Файловый интерфейс, оперирующий только с неструктурированным потоком байт, оказывается полезным и для устройств со сложной организацией
- 59. Работа с диском как со специальным файлом
- 60. В UNIX специальные файлы традиционно помещаются в каталог /dev, хотя ничто не мешает созданию их в
- 61. $ ls -l /dev/sd* brw-rw---T 1 root disk 8, 0 Окт 18 11:15 /dev/sda brw-rw---T 1
- 62. Адресная информация специального файла состоит из двух элементов: major — номер драйвера; minor — номер устройства.
- 63. Например, следующая команда создает блок-ориентированный специальный файл для представления третьего раздела на втором диске четвертого SCSI-контроллера:
- 64. ОС UNIX использует для хранения информации об установленных аппаратных драйверах две системные таблицы: bdevsw — таблица
- 65. Организация связи ядра UNIX с драйверами
- 66. Структура драйвера UNIX Драйвер блок-ориентированного устройства состоит из следующих функций: open — выполняет процедуру логического открытия
- 67. Указатели на эти функции (то есть их адреса) составляют строку в таблице bdevsw, описывающую один драйвер
- 68. Процедуры обработки прерываний драйвера в таблице bdevsw не указываются, их адреса помещаются в специальную системную структуру
- 69. В обязанности верхней части входит быстрая реакция на событие в устройстве, вызвавшее генерирование сигнала прерывания. При
- 70. В качестве примера можно рассмотреть обработчик прерывания от сетевой карты, сообщающего, что принят ethernet-пакет. Он обязан
- 71. Драйвер байт-ориентированного устройства состоит из следующих стандартных функций: open — открывает устройство; close — закрывает устройство;
- 72. Функции чтения и записи данных выполняют обмен заданной последовательности байт из буфера в области пользователя с
- 73. Например, функция записи осуществляет передачу данных из пользовательского буфера процесса, выдавшего запрос на обмен, в системный
- 74. Дисковый кэш Запросы к блок-ориентированным внешним устройствам с прямым доступом (типичными представителями которых являются диски) перехватываются
- 75. Дисковый кэш обычно занимает достаточно большую часть оперативной системной памяти, чтобы максимально повысить вероятность попадания в
- 76. Существуют два способа организации дискового кэша. Способ, который можно назвать традиционным, основан на автономном диспетчере кэша,
- 77. Способ основан на использовании возможностей подсистемы виртуальной памяти. При этом способе функции диспетчера дискового кэша значительно
- 78. Организация традиционного дискового кэша
- 79. С каждым буфером связана специальная структура - заголовок буфера, в котором содержится следующая информация: Данные о
- 80. Схема выполнения запросов подсистемой буферизации
- 81. Функция bwrite - синхронная запись. Процесс, выдавший запрос, ожидает результат выполнения операции ввода-вывода. Функция bawrite -
- 82. Управление памятью ОС UNIX В UNIX реализована сегментно-страничная модель памяти. Наряду с механизмом управления страницами используется
- 83. Структуры, описывающие виртуальное адресное пространство отдельного процесса В дескрипторе процесса proc содержится указатель на структуру as,
- 85. Имеются следующие типы виртуальных сегментов: Текст (text) - содержит коды команд исполняемого модуля процесса. Он обычно
- 86. Есть еще два типа сегментов: Разделяемая память (shared memory) - область памяти, доступная для чтения и
- 87. Ядро системы не выгружается на диск, остальная часть памяти доступна для страниц пользователей. Кроме того Unix
- 88. Unix различает 4 разных типа страниц: 1) Неиспользуемые страницы – страницы, которые не могут вытесняться в
- 89. Во время загрузки процесс init запускает страничные демоны kswapd и настраивает их на периодическое срабатывание. При
- 90. При каждом выполнении алгоритма PFRA (Page Frame Reclaming algorithm), он сначала пытается востребовать легкодоступные страницы, после
- 91. Процесс загрузки ОС Unix
- 92. BIOS BIOS отвечает за базовый ввод/вывод данных с устройств/на устройства. Делает проверки целостности устройств. За тестирование
- 93. 3. GRUB GRUB — Grand Unified Bootloader. Если в системе установлено более, чем одно ядро, есть
- 94. 4. Ядро или Kernel Ядро монтирует файловую систему в соответствии с настройкой «root=» в фале grub.conf
- 95. 5. Init Смотрит в файл /etc/inittab для того, чтобы определить уровень выполнения (run level). Есть следующие
- 96. 6. Уровень выполнения программ (Runlevel) Когда ОС выполняет свою загрузку, вы можете наблюдать загрузку различных служб.
- 97. В каталогах /etc/rc.d/rc*.d/ вы можете увидеть список программ, имя которых начинается из букв S и K.
- 98. Планирование заданий. 1. Очень часто в Linux администратор встречается с проблемой, когда выполнение какой-либо программы (или
- 99. Составляется расписание на каждый день месяца. Совместно с ней составляется форма по дням недели, которая позволяет
- 100. После того, как будут выписаны все задания, стоящие в текущий момент, нужно будет найти подходящее место
- 101. Вся информация о пользователе обычно хранится в файлах /etc/passwd и /etc/grpoup. /etc/passwd – этот файл содержит
- 102. /etc/group – этот файл содержит информацию о группах, к которым принадлежат пользователи: project: $1$QydTRu2w$Cm5gk.6w6nmNdUjerh5pu:100:root,bin,daemon Имя группы
- 103. Файл shadow хранит защищенную информацию о пользователях, а также обеспечивает механизмы устаревания паролей и учетных записей.
- 104. Файл shadow хранит защищенную информацию о пользователях, а также обеспечивает механизмы устаревания паролей и учетных записей.
- 105. Тип операционной системы, установленной на компьютере. Для получения такой информации существует утилита uname (Unix NAME) .
- 106. Команда free показывает объем памяти и объем ее использования, а также использование swap : $ free
- 107. Состояние системы в данный момент, степень ее загруженности и время без перезагрузок показывает команда uptime :
- 108. Другим средством мониторинга производительности является команда vmstat : Эта команда выдает за раз достаточно большой объем
- 109. Раздел cpu : us — время выполнения кода уровня пользователя (в процентах от общего времени) sy
- 111. Скачать презентацию

Дуг Макилрой, изобретатель каналов UNIX и один из основателей традиции UNIX, обобщил философию
Дуг Макилрой, изобретатель каналов UNIX и один из основателей традиции UNIX, обобщил философию

Общая характеристика системы UNIX
Общие черты Unix независимо от версии: 1. Многопользовательский
Общая характеристика системы UNIX
Общие черты Unix независимо от версии: 1. Многопользовательский
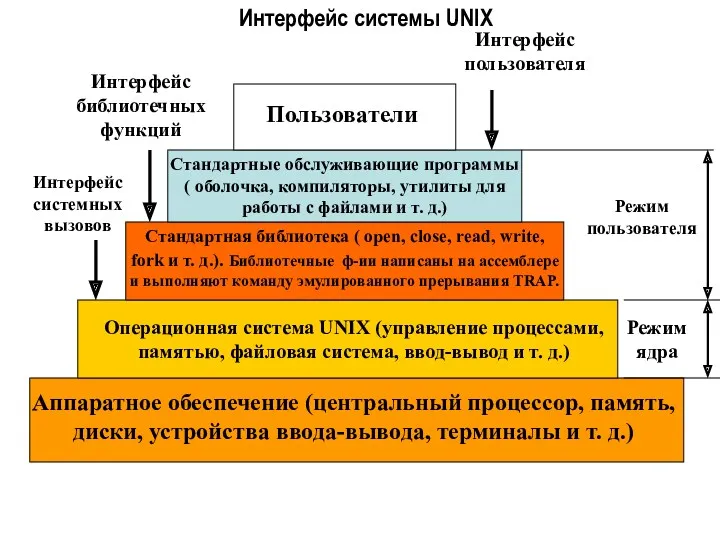
Интерфейс системы UNIX
Пользователи
Стандартные обслуживающие программы ( оболочка, компиляторы, утилиты для работы
Интерфейс системы UNIX
Пользователи
Стандартные обслуживающие программы ( оболочка, компиляторы, утилиты для работы
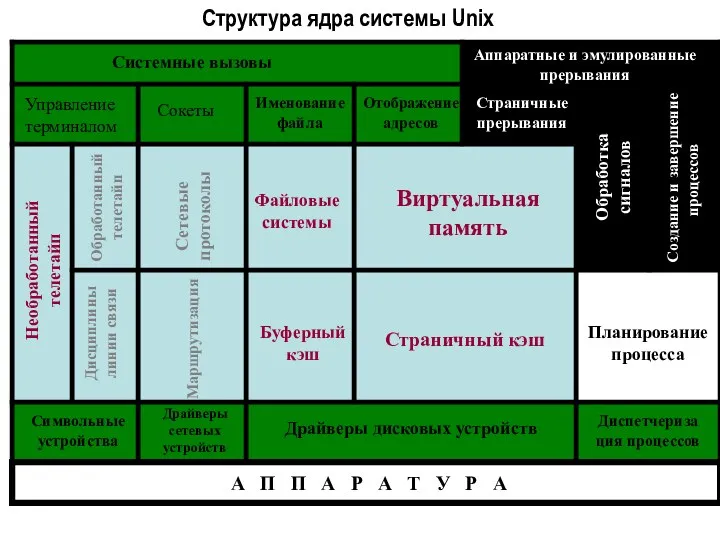
Структура ядра системы Unix
Системные вызовы
Аппаратные и эмулированные прерывания
Управление терминалом
Сокеты
Именование файла
Отображение
Структура ядра системы Unix
Системные вызовы
Аппаратные и эмулированные прерывания
Управление терминалом
Сокеты
Именование файла
Отображение

Ядро операционной системы
Ядро ОС – низкоуровневая программа компьютера. Для большинства устройств,
Ядро операционной системы
Ядро ОС – низкоуровневая программа компьютера. Для большинства устройств,

Оболочка системы UNIX
Система поддерживает графическое окружение X Windows, но многие программисты
Оболочка системы UNIX
Система поддерживает графическое окружение X Windows, но многие программисты

Утилиты системы Unix
Кроме оболочки пользовательский интерфейс содержит большое число обслуживающих
Утилиты системы Unix
Кроме оболочки пользовательский интерфейс содержит большое число обслуживающих

Процессы в ОС UNIX
Процесс в ОС создается при запуске приложения со
Процессы в ОС UNIX
Процесс в ОС создается при запуске приложения со

Атрибуты процесса
Каждый процесс характеризуется набором атрибутов. К их числу относятся:
PID –
Атрибуты процесса
Каждый процесс характеризуется набором атрибутов. К их числу относятся:
PID –
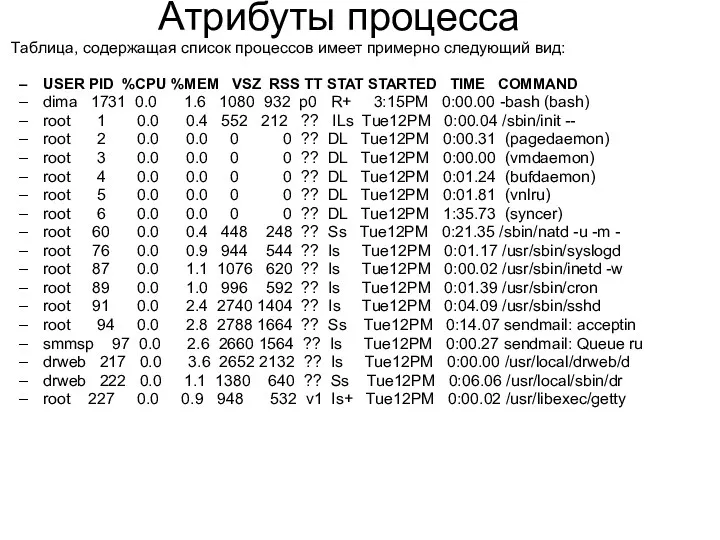
Атрибуты процесса
Таблица, содержащая список процессов имеет примерно следующий вид:
USER PID %CPU
Атрибуты процесса
Таблица, содержащая список процессов имеет примерно следующий вид:
USER PID %CPU

pid = fork ( ); /* если fork завершился успешно, pid
pid = fork ( ); /* если fork завершился успешно, pid

Механизм создания нового процесса : для процесса-потомка создается
новая ячейка в
Механизм создания нового процесса : для процесса-потомка создается
новая ячейка в

Процессы взаимодействуют с помощью каналов. Синхронизация процессов достигается путем блокировки процесса
Процессы взаимодействуют с помощью каналов. Синхронизация процессов достигается путем блокировки процесса
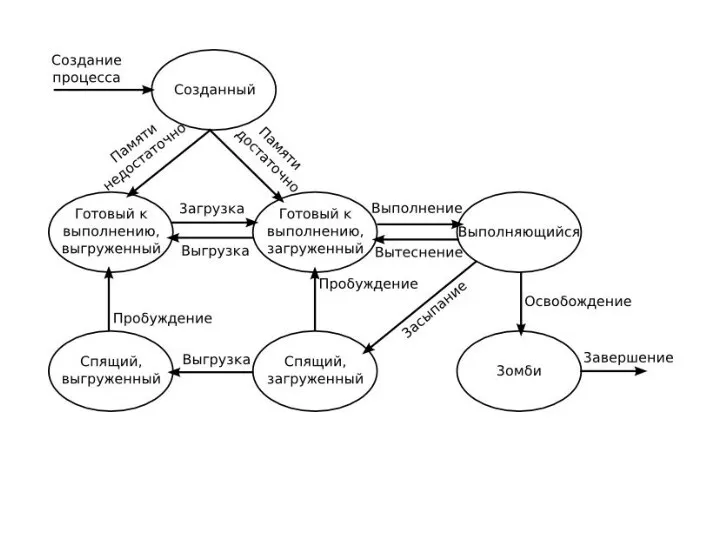

Каждый запущенный процесс в любой момент времени находится в одном из
Каждый запущенный процесс в любой момент времени находится в одном из

Реализация процессов в системе Unix
Ядро поддерживает две ключевые структуры данных, относящиеся
Реализация процессов в системе Unix
Ядро поддерживает две ключевые структуры данных, относящиеся

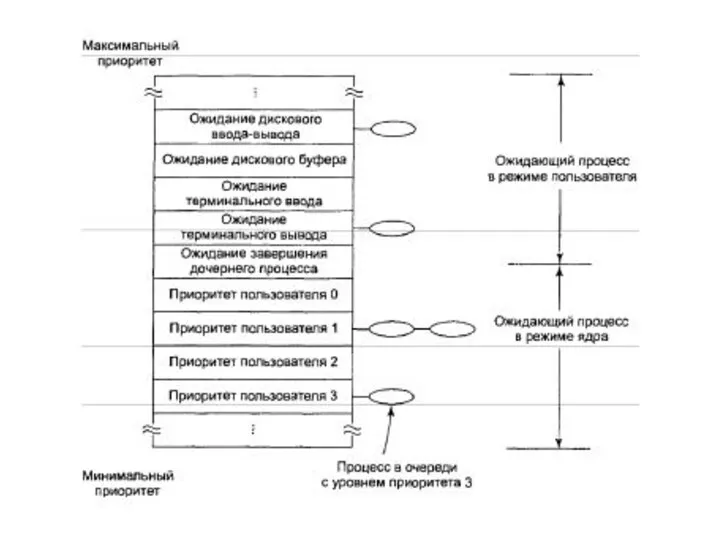
Планирование в системе UNIX
Низкоуровневый алгоритм выбирает процесс, готовый к работе из
Планирование в системе UNIX
Низкоуровневый алгоритм выбирает процесс, готовый к работе из

Команды управления процессами
Существует ряд команд, позволяющих просматривать и управлять процессами в
Команды управления процессами
Существует ряд команд, позволяющих просматривать и управлять процессами в

Средства администрирования
Для управления операционной системой в UNIX часто используются конфигурационные файлы.
Средства администрирования
Для управления операционной системой в UNIX часто используются конфигурационные файлы.

Учетные записи пользователей
Для упорядочивания работы с пользователями, хранения информации о их
Учетные записи пользователей
Для упорядочивания работы с пользователями, хранения информации о их

Хранение информации об учетных записях
Информация об учетных записях хранится в нескольких
Хранение информации об учетных записях
Информация об учетных записях хранится в нескольких

Монтирование файловой системы
Доступ к разделу на носителе информации обеспечивается монтированием раздела
Монтирование файловой системы
Доступ к разделу на носителе информации обеспечивается монтированием раздела
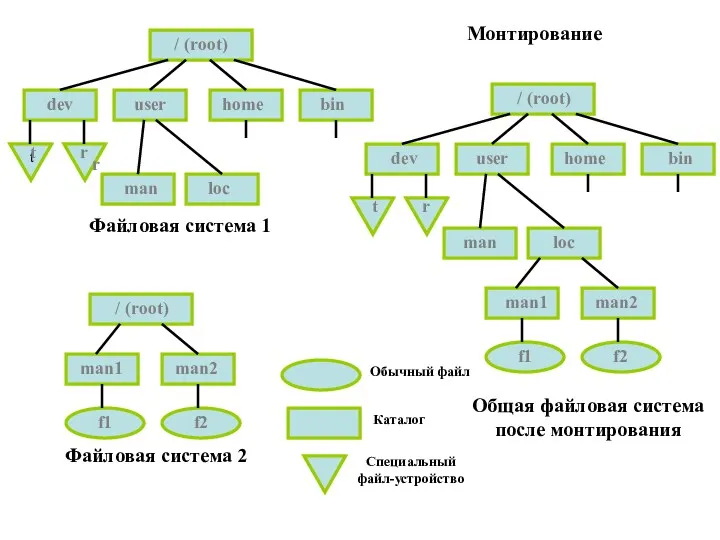
Файловая система 1
Файловая система 2
Общая файловая система после монтирования
Обычный файл
Каталог
Специальный файл-устройство
Монтирование
/
Файловая система 1
Файловая система 2
Общая файловая система после монтирования
Обычный файл
Каталог
Специальный файл-устройство
Монтирование
/
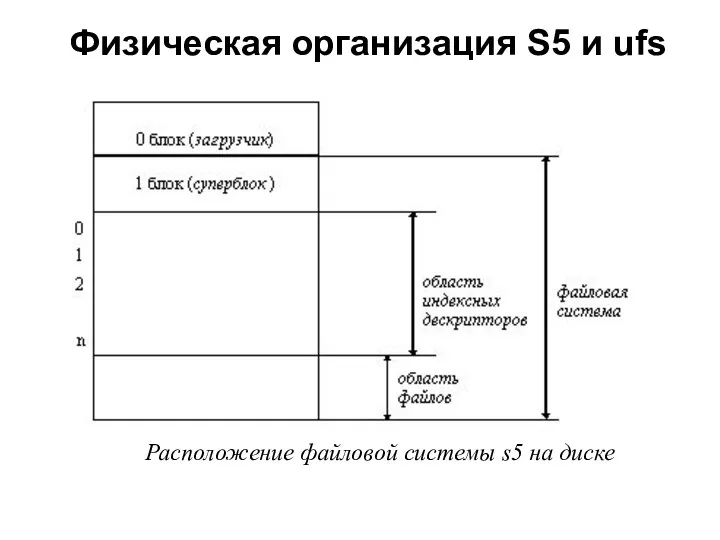
Физическая организация S5 и ufs
Расположение файловой системы s5 на диске
Физическая организация S5 и ufs
Расположение файловой системы s5 на диске

Все дисковое пространство, отведенное под файловую систему, делится на четыре области:
Все дисковое пространство, отведенное под файловую систему, делится на четыре области:

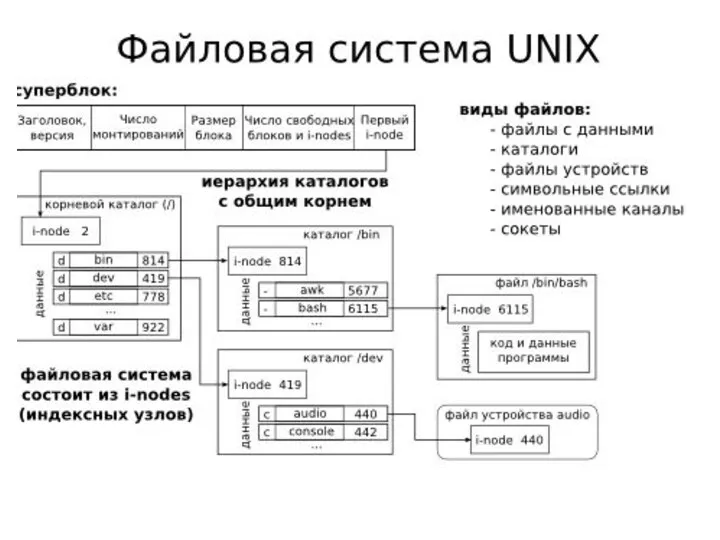
Структура индексного дескриптора (i-node)
идентификатор владельца и группы владельца файла;
тип файла:
- (дефис)
Структура индексного дескриптора (i-node)
идентификатор владельца и группы владельца файла;
тип файла:
- (дефис)

Копирование индексного дескриптора входит в процедуру открытия файла. При открытии файла
Копирование индексного дескриптора входит в процедуру открытия файла. При открытии файла

Стандарт POSIX (Portable Operating System Interface) требует реализовать поддержку двух типов
Стандарт POSIX (Portable Operating System Interface) требует реализовать поддержку двух типов
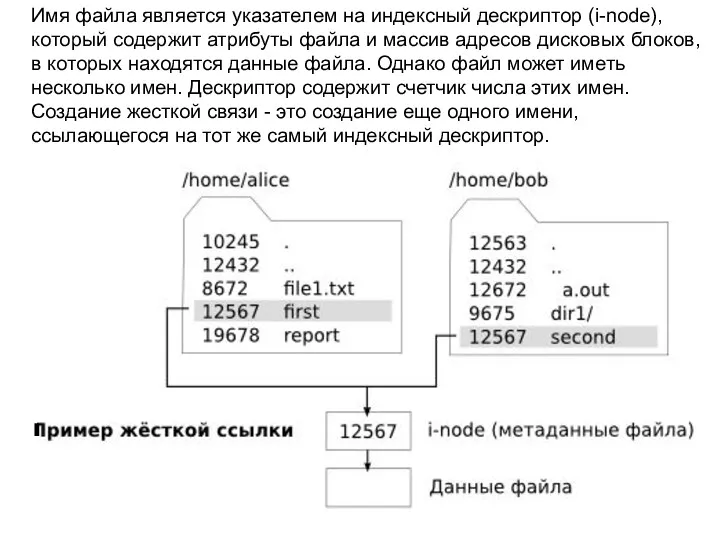
Имя файла является указателем на индексный дескриптор (i-node), который содержит атрибуты
Имя файла является указателем на индексный дескриптор (i-node), который содержит атрибуты
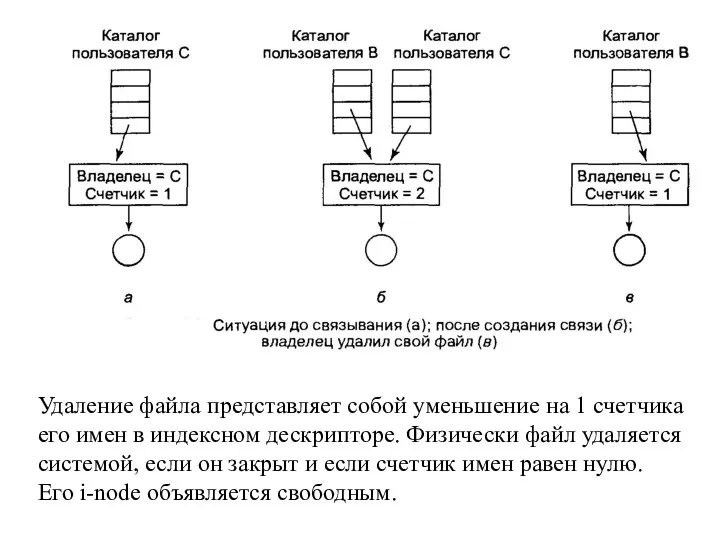
Удаление файла представляет собой уменьшение на 1 счетчика его имен в
Удаление файла представляет собой уменьшение на 1 счетчика его имен в
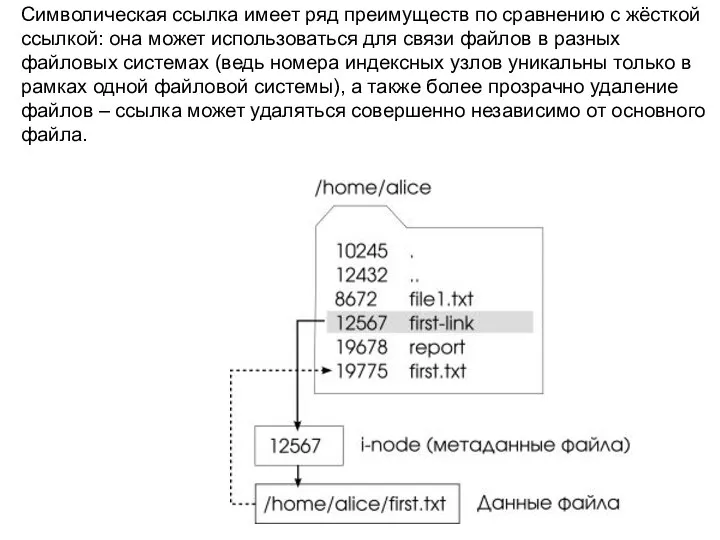
Символическая ссылка имеет ряд преимуществ по сравнению с жёсткой ссылкой: она
Символическая ссылка имеет ряд преимуществ по сравнению с жёсткой ссылкой: она
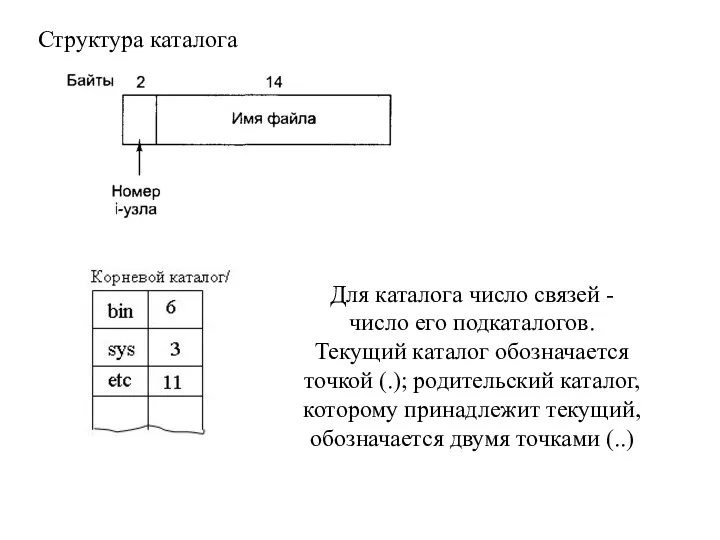
Структура каталога
Для каталога число связей - число его подкаталогов.
Текущий каталог обозначается
Структура каталога
Для каталога число связей - число его подкаталогов.
Текущий каталог обозначается
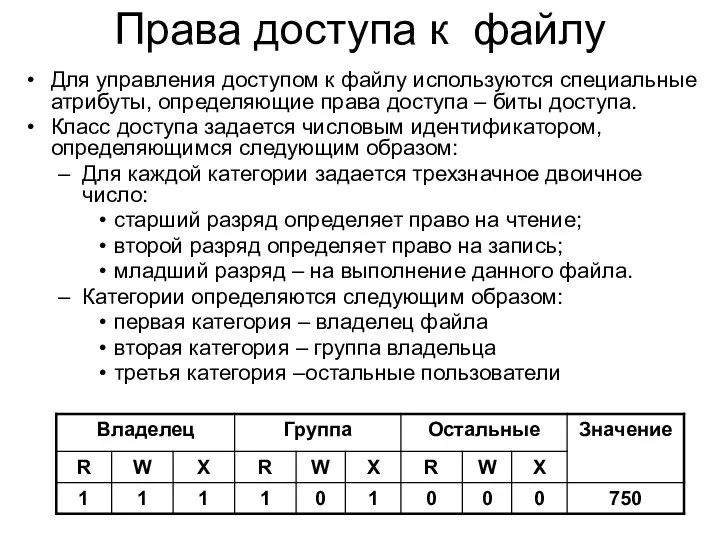
Права доступа к файлу
Для управления доступом к файлу используются специальные атрибуты,
Права доступа к файлу
Для управления доступом к файлу используются специальные атрибуты,
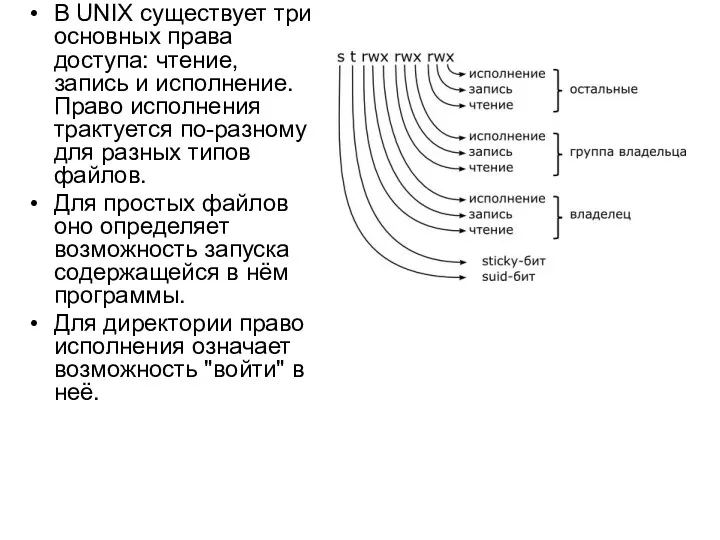
В UNIX существует три основных права доступа: чтение, запись и исполнение.
В UNIX существует три основных права доступа: чтение, запись и исполнение.

Sticky bit
Помимо комбинации из этих девяти прав доступа, каждый файл может
Sticky bit
Помимо комбинации из этих девяти прав доступа, каждый файл может
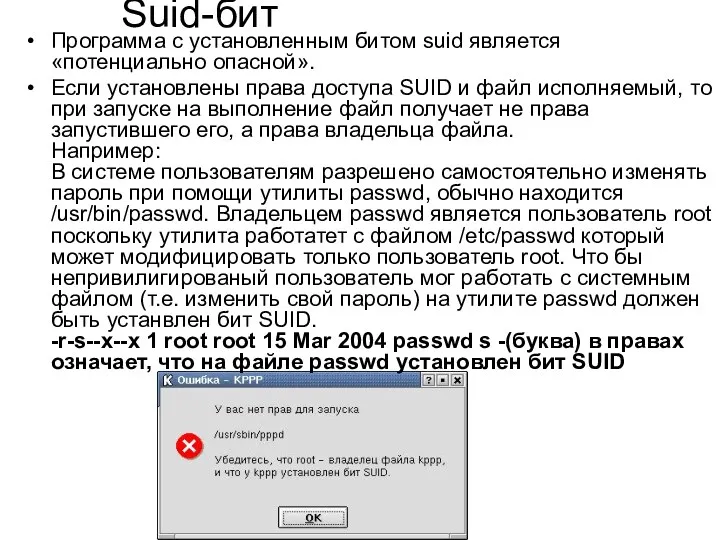
Suid-бит
Программа с установленным битом suid является «потенциально опасной».
Если установлены права
Suid-бит
Программа с установленным битом suid является «потенциально опасной».
Если установлены права
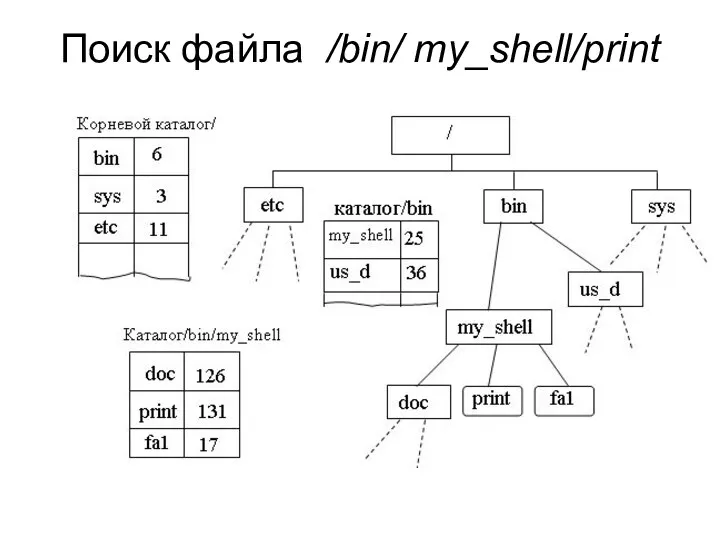
Поиск файла /bin/ my_shell/print
Поиск файла /bin/ my_shell/print

1. просматривается корневой каталог с целью поиска первого составляющего символьного имени
1. просматривается корневой каталог с целью поиска первого составляющего символьного имени

Атрибуты файлов
Аналогично файловой системе FAT, имеющей атрибуты файлов (архивный, системный
Атрибуты файлов
Аналогично файловой системе FAT, имеющей атрибуты файлов (архивный, системный

d («no dump»): dump - это стандартная утилита UNIX для резервного
d («no dump»): dump - это стандартная утилита UNIX для резервного

Физическая организация файловой системы ufs
Таблицы inodes содержатся в блоке группы цилиндров, наряду
Физическая организация файловой системы ufs
Таблицы inodes содержатся в блоке группы цилиндров, наряду

С каждым процессом UNIX связаны два идентификатора: пользователя, от имени которого
С каждым процессом UNIX связаны два идентификатора: пользователя, от имени которого
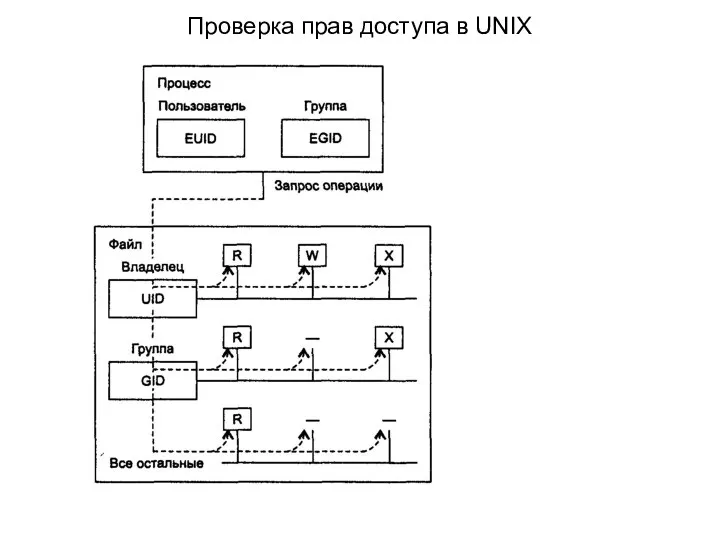
Проверка прав доступа в UNIX
Проверка прав доступа в UNIX
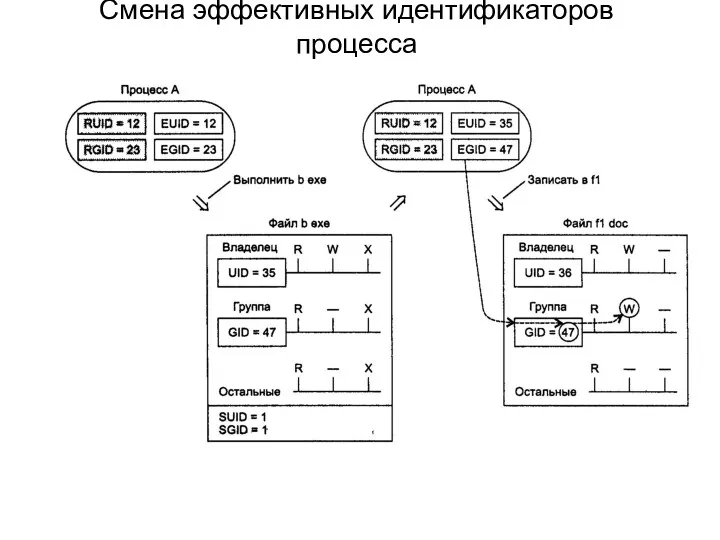
Смена эффективных идентификаторов процесса
Смена эффективных идентификаторов процесса

Система ввода-вывода
Основу системы ввода-вывода ОС UNIX составляют драйверы внешних устройств и
Система ввода-вывода
Основу системы ввода-вывода ОС UNIX составляют драйверы внешних устройств и
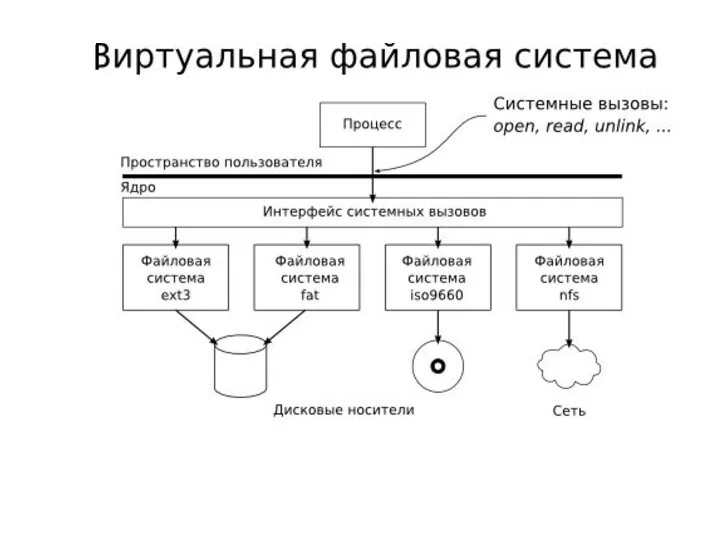
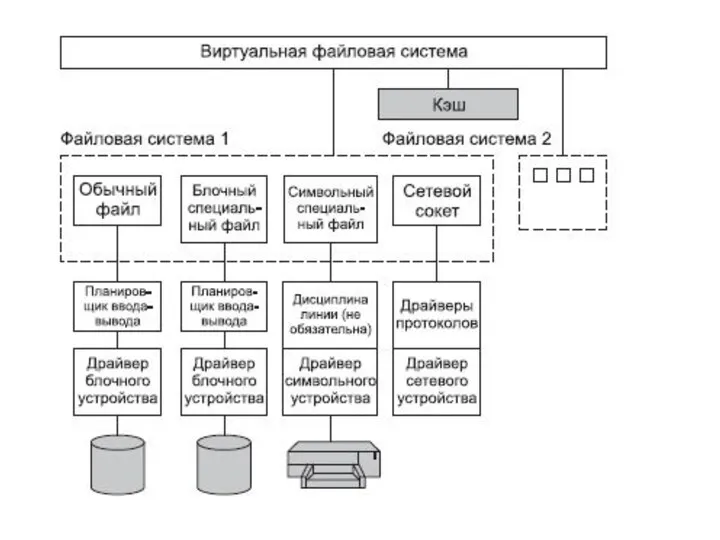

Специальные файлы как универсальный интерфейс
Специальный файл (СФ), называемый также виртуальным файлом,
Специальные файлы как универсальный интерфейс
Специальный файл (СФ), называемый также виртуальным файлом,


Для этого используются системные вызовы для работы с обычными файлами: open,
Для этого используются системные вызовы для работы с обычными файлами: open,

Файловый интерфейс, оперирующий только с неструктурированным потоком байт, оказывается полезным и
Файловый интерфейс, оперирующий только с неструктурированным потоком байт, оказывается полезным и
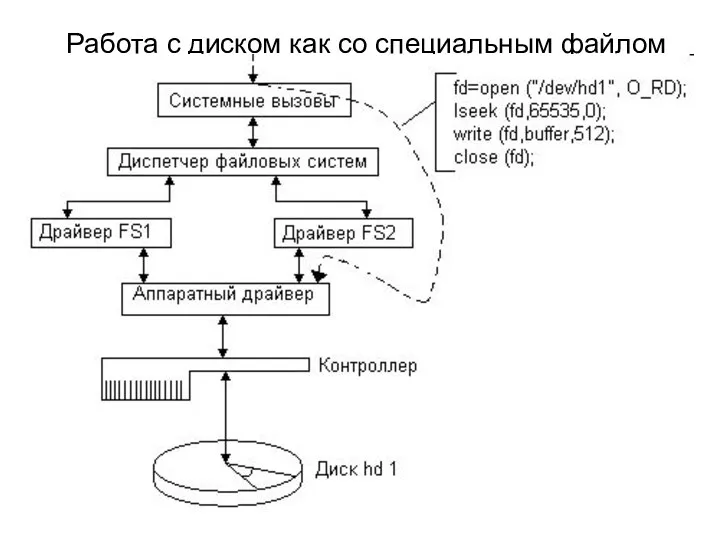
Работа с диском как со специальным файлом
Работа с диском как со специальным файлом

В UNIX специальные файлы традиционно помещаются в каталог /dev, хотя ничто
В UNIX специальные файлы традиционно помещаются в каталог /dev, хотя ничто

$ ls -l /dev/sd*
brw-rw---T 1 root disk 8, 0 Окт 18
$ ls -l /dev/sd*
brw-rw---T 1 root disk 8, 0 Окт 18

Адресная информация специального файла состоит из двух элементов:
major
Адресная информация специального файла состоит из двух элементов:
major

Например, следующая команда создает блок-ориентированный специальный файл для представления третьего раздела
Например, следующая команда создает блок-ориентированный специальный файл для представления третьего раздела

ОС UNIX использует для хранения информации об установленных аппаратных драйверах две
ОС UNIX использует для хранения информации об установленных аппаратных драйверах две
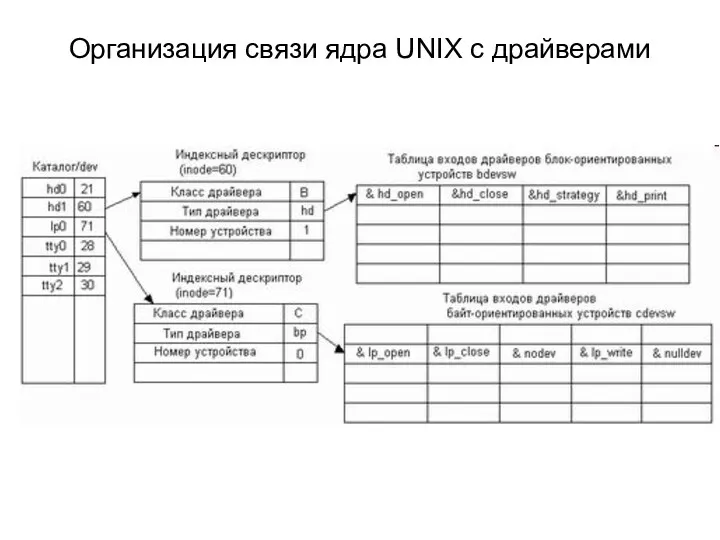
Организация связи ядра UNIX с драйверами
Организация связи ядра UNIX с драйверами

Структура драйвера UNIX
Драйвер блок-ориентированного устройства состоит из следующих функций:
open
Структура драйвера UNIX
Драйвер блок-ориентированного устройства состоит из следующих функций:
open

Указатели на эти функции (то есть их адреса) составляют строку в
Указатели на эти функции (то есть их адреса) составляют строку в

Процедуры обработки прерываний драйвера в таблице bdevsw не указываются, их адреса
Процедуры обработки прерываний драйвера в таблице bdevsw не указываются, их адреса

В обязанности верхней части входит быстрая реакция на событие в устройстве,
В обязанности верхней части входит быстрая реакция на событие в устройстве,

В качестве примера можно рассмотреть обработчик прерывания от сетевой карты, сообщающего,
В качестве примера можно рассмотреть обработчик прерывания от сетевой карты, сообщающего,

Драйвер байт-ориентированного устройства состоит из следующих стандартных функций:
open —
Драйвер байт-ориентированного устройства состоит из следующих стандартных функций:
open —

Функции чтения и записи данных выполняют обмен заданной последовательности байт из
Функции чтения и записи данных выполняют обмен заданной последовательности байт из

Например, функция записи осуществляет передачу данных из пользовательского буфера процесса, выдавшего
Например, функция записи осуществляет передачу данных из пользовательского буфера процесса, выдавшего

Дисковый кэш
Запросы к блок-ориентированным внешним устройствам с прямым доступом (типичными представителями
Дисковый кэш
Запросы к блок-ориентированным внешним устройствам с прямым доступом (типичными представителями

Дисковый кэш обычно занимает достаточно большую часть оперативной системной памяти, чтобы
Дисковый кэш обычно занимает достаточно большую часть оперативной системной памяти, чтобы

Существуют два способа организации дискового кэша.
Способ, который можно назвать традиционным,
Существуют два способа организации дискового кэша.
Способ, который можно назвать традиционным,

Способ основан на использовании возможностей подсистемы виртуальной памяти. При этом способе
Способ основан на использовании возможностей подсистемы виртуальной памяти. При этом способе
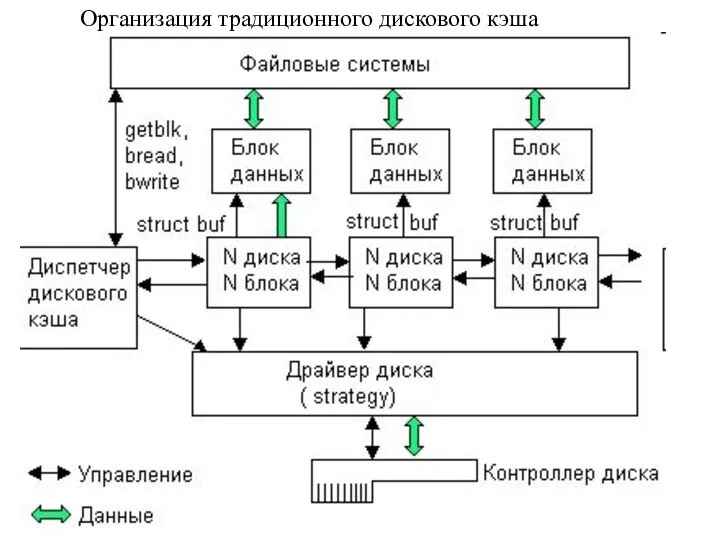
Организация традиционного дискового кэша
Организация традиционного дискового кэша

С каждым буфером связана специальная структура - заголовок буфера, в котором
С каждым буфером связана специальная структура - заголовок буфера, в котором
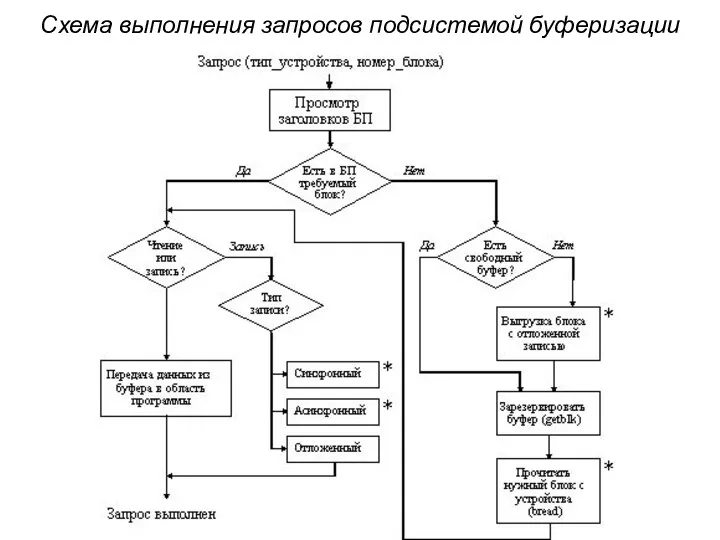
Схема выполнения запросов подсистемой буферизации
Схема выполнения запросов подсистемой буферизации

Функция bwrite - синхронная запись. Процесс, выдавший запрос, ожидает результат выполнения
Функция bwrite - синхронная запись. Процесс, выдавший запрос, ожидает результат выполнения

Управление памятью ОС UNIX
В UNIX реализована сегментно-страничная модель памяти. Наряду с
Управление памятью ОС UNIX
В UNIX реализована сегментно-страничная модель памяти. Наряду с

Структуры, описывающие виртуальное адресное пространство отдельного процесса
В дескрипторе процесса proc содержится
Структуры, описывающие виртуальное адресное пространство отдельного процесса
В дескрипторе процесса proc содержится
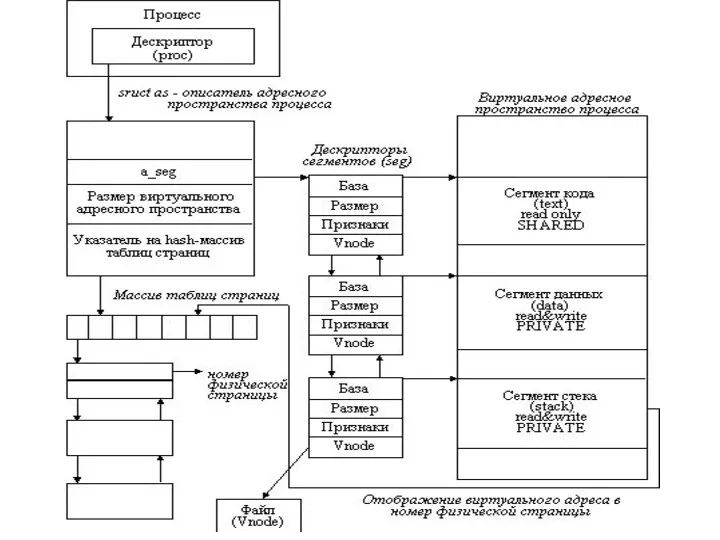

Имеются следующие типы виртуальных сегментов:
Текст (text) - содержит коды команд
Имеются следующие типы виртуальных сегментов:
Текст (text) - содержит коды команд

Есть еще два типа сегментов:
Разделяемая память (shared memory) - область
Есть еще два типа сегментов:
Разделяемая память (shared memory) - область

Ядро системы не выгружается на диск, остальная часть памяти доступна для
Ядро системы не выгружается на диск, остальная часть памяти доступна для

Unix различает 4 разных типа страниц:
1) Неиспользуемые страницы – страницы, которые
Unix различает 4 разных типа страниц:
1) Неиспользуемые страницы – страницы, которые

Во время загрузки процесс init запускает страничные демоны kswapd и настраивает их на
Во время загрузки процесс init запускает страничные демоны kswapd и настраивает их на

При каждом выполнении алгоритма PFRA (Page Frame Reclaming algorithm), он сначала
При каждом выполнении алгоритма PFRA (Page Frame Reclaming algorithm), он сначала
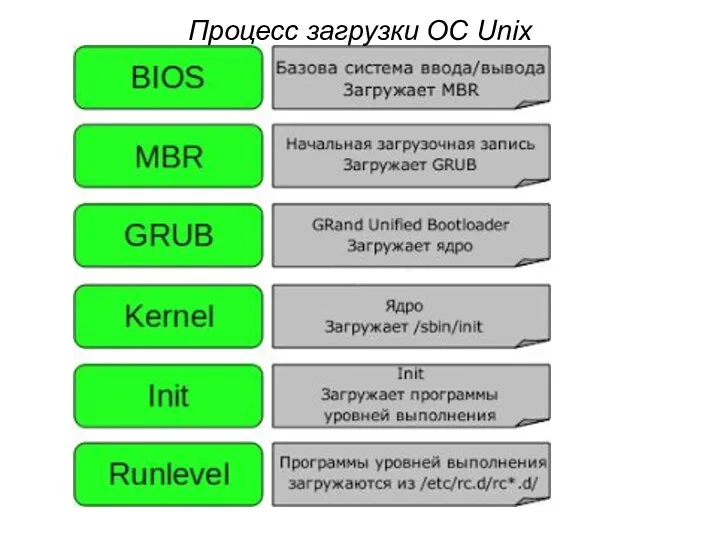
Процесс загрузки ОС Unix
Процесс загрузки ОС Unix

BIOS
BIOS отвечает за базовый ввод/вывод данных с устройств/на устройства.
Делает проверки целостности
BIOS BIOS отвечает за базовый ввод/вывод данных с устройств/на устройства. Делает проверки целостности

3. GRUB
GRUB — Grand Unified Bootloader.
Если в системе установлено более, чем
3. GRUB GRUB — Grand Unified Bootloader. Если в системе установлено более, чем

4. Ядро или Kernel
Ядро монтирует файловую систему в соответствии с настройкой
4. Ядро или Kernel Ядро монтирует файловую систему в соответствии с настройкой

5. Init
Смотрит в файл /etc/inittab для того, чтобы определить уровень выполнения
5. Init Смотрит в файл /etc/inittab для того, чтобы определить уровень выполнения

6. Уровень выполнения программ (Runlevel)
Когда ОС выполняет свою загрузку, вы можете
6. Уровень выполнения программ (Runlevel) Когда ОС выполняет свою загрузку, вы можете

В каталогах /etc/rc.d/rc*.d/ вы можете увидеть список программ, имя которых начинается
В каталогах /etc/rc.d/rc*.d/ вы можете увидеть список программ, имя которых начинается

Планирование заданий.
1. Очень часто в Linux администратор встречается с проблемой,
Планирование заданий.
1. Очень часто в Linux администратор встречается с проблемой,
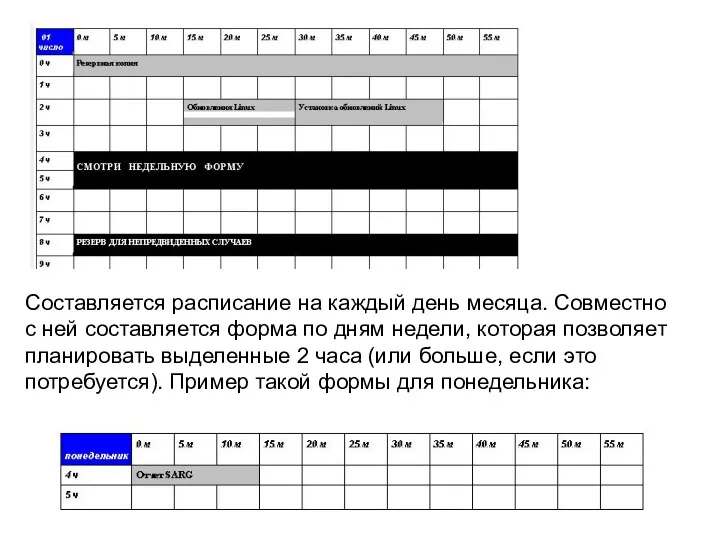
Составляется расписание на каждый день месяца. Совместно с ней составляется форма
Составляется расписание на каждый день месяца. Совместно с ней составляется форма

После того, как будут выписаны все задания, стоящие в текущий момент,
После того, как будут выписаны все задания, стоящие в текущий момент,

Вся информация о пользователе обычно хранится в файлах /etc/passwd и /etc/grpoup.
Вся информация о пользователе обычно хранится в файлах /etc/passwd и /etc/grpoup.

/etc/group – этот файл содержит информацию о группах, к которым принадлежат
/etc/group – этот файл содержит информацию о группах, к которым принадлежат

Файл shadow хранит защищенную информацию о пользователях, а также обеспечивает механизмы
Файл shadow хранит защищенную информацию о пользователях, а также обеспечивает механизмы

Файл shadow хранит защищенную информацию о пользователях, а также обеспечивает механизмы
Файл shadow хранит защищенную информацию о пользователях, а также обеспечивает механизмы

Тип операционной системы, установленной на компьютере. Для получения такой информации существует утилита uname
Тип операционной системы, установленной на компьютере. Для получения такой информации существует утилита uname

Команда free показывает объем памяти и объем ее использования, а также
Команда free показывает объем памяти и объем ее использования, а также

Состояние системы в данный момент, степень ее загруженности и время без перезагрузок
Состояние системы в данный момент, степень ее загруженности и время без перезагрузок

Другим средством мониторинга производительности является команда vmstat :
Эта команда выдает за раз достаточно большой объем информации.
Раздел procs :
r —
Другим средством мониторинга производительности является команда vmstat :
Эта команда выдает за раз достаточно большой объем информации.
Раздел procs :
r —

Раздел cpu :
us — время выполнения кода уровня пользователя (в процентах от общего времени)
sy — время выполнения кода уровня
Раздел cpu :
us — время выполнения кода уровня пользователя (в процентах от общего времени)
sy — время выполнения кода уровня
 Excel. Абсолютная и относительная адресация
Excel. Абсолютная и относительная адресация Programming for Engineers in Python. Fall 2018
Programming for Engineers in Python. Fall 2018 Шифрование с открытым ключом. Алгоритм RSA
Шифрование с открытым ключом. Алгоритм RSA Опыт внедрения и реализации в ДОУ программы Кидсмарт.
Опыт внедрения и реализации в ДОУ программы Кидсмарт. Интегрированный урок информатика, технология на тему Олимпийский день
Интегрированный урок информатика, технология на тему Олимпийский день Платформа learningapps.org, как один из способов дистанционного взаимодействия учителя – логопеда с родителями
Платформа learningapps.org, как один из способов дистанционного взаимодействия учителя – логопеда с родителями Диалоги и диалоговые окна. Диалоговые окна Windows
Диалоги и диалоговые окна. Диалоговые окна Windows Применение электронной презентации на уроке истории искусств
Применение электронной презентации на уроке истории искусств Бази даних. Інформаційні системи. (Тема 1)
Бази даних. Інформаційні системи. (Тема 1) Эквивалентность семафоров, мониторов и сообщений
Эквивалентность семафоров, мониторов и сообщений Основы криптографической защиты информации
Основы криптографической защиты информации Презентация по информатике Представление переменных целого типа в памяти компьютера
Презентация по информатике Представление переменных целого типа в памяти компьютера Тест Электронные таблицы
Тест Электронные таблицы ADS:lab session #2
ADS:lab session #2 Основы сетевых технологий. Топологии компьютерных сетей. Часть 1. Лекция 4
Основы сетевых технологий. Топологии компьютерных сетей. Часть 1. Лекция 4 Помехоустойчивое кодирование. Циклические коды – подкласс линейных кодов
Помехоустойчивое кодирование. Циклические коды – подкласс линейных кодов Future of technology and newest inventions
Future of technology and newest inventions Алгоритм ветвления. Условный оператор в языке Турбо Паскаль
Алгоритм ветвления. Условный оператор в языке Турбо Паскаль Табличная форма представления информации. Урок информатики в 5 классе
Табличная форма представления информации. Урок информатики в 5 классе Роскомнадзор. Безопасность несовершеннолетних в сети Интернет
Роскомнадзор. Безопасность несовершеннолетних в сети Интернет Partnership System ZORAN
Partnership System ZORAN Смешарики : London Gloom – 3 эпизод
Смешарики : London Gloom – 3 эпизод Главный коммуникационный центр
Главный коммуникационный центр Data types and databases
Data types and databases Оценка стоимости информационной системы
Оценка стоимости информационной системы Жаңа технология жетістіктері
Жаңа технология жетістіктері Алгоритмы и исполнители. Основы алгоритмизации. 8 класс
Алгоритмы и исполнители. Основы алгоритмизации. 8 класс О браузерах в интернете
О браузерах в интернете