- Кодирование информации

Содержание
- 2. Кодирование – преобразование информации из одного вида представления в другой, более удобный для хранения, передачи или
- 3. Для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от
- 4. Выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Используя русский алфавит, можно
- 5. Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в1837 году американцем Сэмюэлем Морзе. Телеграфное
- 6. 7 мая 1895 года российский ученый Александр Степанович Попов на заседании Русского Физико-Химического Общества продемонстрировал прибор,
- 7. В 1899 году Попов сконструировал модернизированный вариант приемника электромагнитных волн, где прием сигналов (азбукой Морзе) осуществлялся
- 8. Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце XIX века. В нем использовалось
- 9. Код Бодо — это первый в истории техники способ двоичного кодирования информации. Благодаря этой идее удалось
- 10. Например, запись текста на естественном языке можно рассматривать как способ кодирования речи с помощью графических элементов
- 11. Языки представления информации (языки кодирования) Формальные языки: Язык математики, языки программирования, язык мимики и жестов, язык
- 12. Кодирование информации в компьютере Вся информация, которою обработает компьютер, должна быть представлена двоичным кодом с помощью
- 13. С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым,
- 14. Способы кодирования информации в компьютере, в первую очередь, зависят от вида информации, а именно, что должно
- 15. кодирование текстовой информации Начиная с 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации.
- 16. При вводе в компьютер текстовой информации происходит её двоичное кодирование, изображение символа преобразуется в его двоичный
- 17. Традиционно для кодирования одного символа используется количество информации = 1 байту (1 байт = 8 битов).
- 18. Присвоение символу конкретного двоичного кода –это вопрос соглашения, которое фиксируется в кодовой таблице. Таблица, в которой
- 19. Таблица кодировки ASCII Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод
- 20. Таблица стандартной части ASCII
- 21. Таблица расширенного кода ASCII
- 22. В настоящее время существует 5 разных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO).
- 23. Обратите внимание! Цифры кодируются по стандарту ASCII в случае, когда они встречаются в тексте. Если цифры
- 24. Сегодня очень многие люди для подготовки писем, документов, статей, книг и пр. используют компьютерные текстовые редакторы.
- 26. Скачать презентацию

Кодирование – преобразование информации из одного вида представления в другой, более
Кодирование – преобразование информации из одного вида представления в другой, более

Для кодирования одной и той же информации могут быть использованы разные
Для кодирования одной и той же информации могут быть использованы разные

Выбор способа кодирования информации может быть связан с предполагаемым способом ее
Выбор способа кодирования информации может быть связан с предполагаемым способом ее

Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в1837
Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в1837

7 мая 1895 года российский ученый
Александр Степанович Попов на заседании
Русского
7 мая 1895 года российский ученый
Александр Степанович Попов на заседании
Русского

В 1899 году Попов сконструировал модернизированный вариант приемника электромагнитных волн, где
В 1899 году Попов сконструировал модернизированный вариант приемника электромагнитных волн, где

Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце
Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце

Код Бодо — это первый в истории техники способ двоичного кодирования
Код Бодо — это первый в истории техники способ двоичного кодирования

Например, запись текста на естественном языке можно рассматривать как способ кодирования
Например, запись текста на естественном языке можно рассматривать как способ кодирования

Языки представления информации
(языки кодирования)
Формальные языки:
Язык математики, языки программирования, язык мимики
Языки представления информации
(языки кодирования)
Формальные языки:
Язык математики, языки программирования, язык мимики

Кодирование информации в компьютере
Вся информация, которою обработает компьютер, должна быть представлена
Кодирование информации в компьютере
Вся информация, которою обработает компьютер, должна быть представлена

С точки зрения технической реализации использование двоичной системы счисления для кодирования
С точки зрения технической реализации использование двоичной системы счисления для кодирования

Способы кодирования информации в компьютере, в первую очередь, зависят от вида
Способы кодирования информации в компьютере, в первую очередь, зависят от вида

кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использоваться
кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использоваться

При вводе в компьютер текстовой информации происходит её двоичное кодирование, изображение

Традиционно для кодирования одного символа используется количество информации = 1 байту
Традиционно для кодирования одного символа используется количество информации = 1 байту

Присвоение символу конкретного двоичного кода –это вопрос соглашения, которое фиксируется в
Присвоение символу конкретного двоичного кода –это вопрос соглашения, которое фиксируется в

Таблица кодировки ASCII
Первые 33 кода (с 0 до 32) соответствуют не
Таблица кодировки ASCII
Первые 33 кода (с 0 до 32) соответствуют не
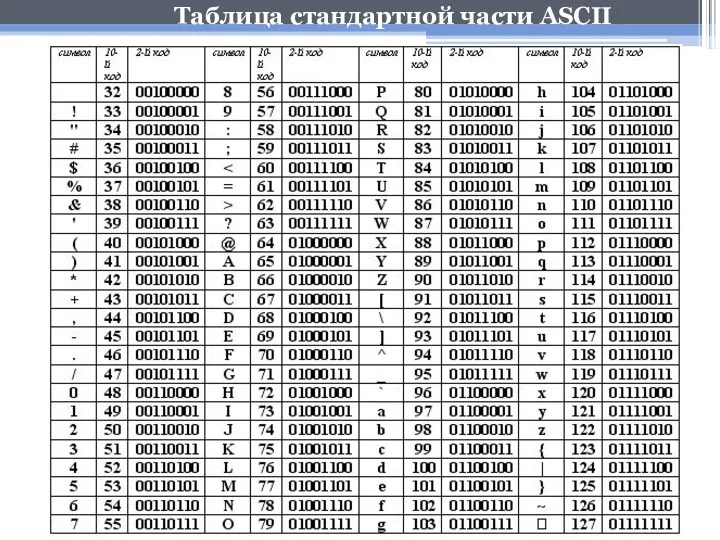
Таблица стандартной части ASCII
Таблица стандартной части ASCII
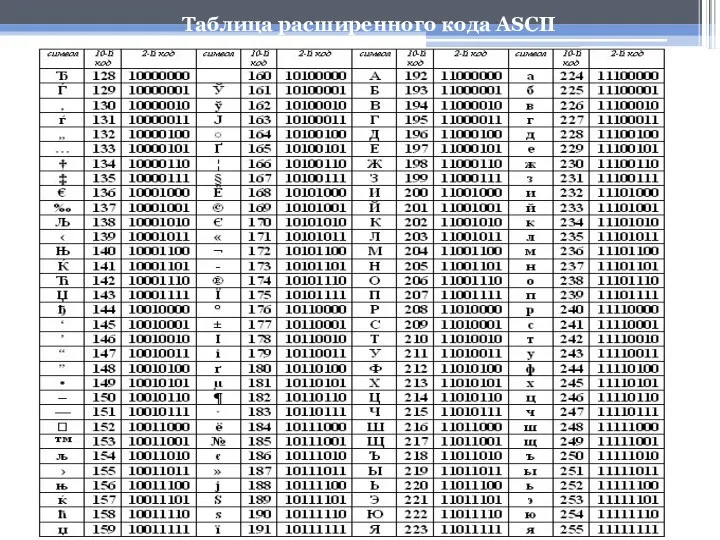
Таблица расширенного кода ASCII
Таблица расширенного кода ASCII

В настоящее время существует 5 разных кодовых таблиц для русских букв
В настоящее время существует 5 разных кодовых таблиц для русских букв

Обратите внимание!
Цифры кодируются по стандарту ASCII в случае, когда они встречаются
Обратите внимание!
Цифры кодируются по стандарту ASCII в случае, когда они встречаются

Сегодня очень многие люди для подготовки писем, документов, статей, книг и
Сегодня очень многие люди для подготовки писем, документов, статей, книг и
 Кодирование информации. Изучение единиц измерения информации. Носители информации
Кодирование информации. Изучение единиц измерения информации. Носители информации Теоретическое моделирование перевода
Теоретическое моделирование перевода Правила информационной безопасности при работе в сети Интернет
Правила информационной безопасности при работе в сети Интернет Этапы подготовки документов на компьютере
Этапы подготовки документов на компьютере Программирование. Лекция 1
Программирование. Лекция 1 Геометрическое моделирование
Геометрическое моделирование Этика и философия искусственного интеллекта
Этика и философия искусственного интеллекта Welcome. Цели и задачи курса
Welcome. Цели и задачи курса Текст и текстовый редактор
Текст и текстовый редактор Текстовая информация
Текстовая информация Кодирование информации
Кодирование информации Построение корпоративных Порталов на базе IBM WEBSPH
Построение корпоративных Порталов на базе IBM WEBSPH Антивирусные программы. Антивирусная защита информации
Антивирусные программы. Антивирусная защита информации Варианты занятости
Варианты занятости Информационная профессиональная деятельность
Информационная профессиональная деятельность Основы алгоритмизации и программирования
Основы алгоритмизации и программирования Базы данных и системы управления базами данных
Базы данных и системы управления базами данных Проблемы правового регулирования рекламы в сети Интернет
Проблемы правового регулирования рекламы в сети Интернет Программное обеспечение
Программное обеспечение Системы автоматизированного проектирования (САПР)
Системы автоматизированного проектирования (САПР) Файлы и файловая система (8 класс)
Файлы и файловая система (8 класс) Программное обеспечение (ПО)
Программное обеспечение (ПО) Работа в Excel. Электронные таблицы
Работа в Excel. Электронные таблицы Основы WEB технологий
Основы WEB технологий Word
Word Безопасный интернет. Информационная безопасность детей
Безопасный интернет. Информационная безопасность детей Триггеры (триггерная система)
Триггеры (триггерная система) Организация ветвления на языке Паскаль
Организация ветвления на языке Паскаль